Survey AI Risk framework
- SlideDeck: W5-AI-RiskFramework
- Version: current
- Lead team: team-4
- Blog team: team-4
In this session, our readings cover:
Required Readings:
TrustLLM: Trustworthiness in Large Language Models
- https://arxiv.org/abs/2401.05561
- Large language models (LLMs), exemplified by ChatGPT, have gained considerable attention for their excellent natural language processing capabilities. Nonetheless, these LLMs present many challenges, particularly in the realm of trustworthiness. Therefore, ensuring the trustworthiness of LLMs emerges as an important topic. This paper introduces TrustLLM, a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. Our findings firstly show that in general trustworthiness and utility (i.e., functional effectiveness) are positively related. Secondly, our observations reveal that proprietary LLMs generally outperform most open-source counterparts in terms of trustworthiness, raising concerns about the potential risks of widely accessible open-source LLMs. However, a few open-source LLMs come very close to proprietary ones. Thirdly, it is important to note that some LLMs may be overly calibrated towards exhibiting trustworthiness, to the extent that they compromise their utility by mistakenly treating benign prompts as harmful and consequently not responding. Finally, we emphasize the importance of ensuring transparency not only in the models themselves but also in the technologies that underpin trustworthiness. Knowing the specific trustworthy technologies that have been employed is crucial for analyzing their effectiveness.
A Survey on Large Language Model (LLM) Security and Privacy: The Good, the Bad, and the Ugly
- Large Language Models (LLMs), such as ChatGPT and Bard, have revolutionized natural language understanding and generation. They possess deep language comprehension, human-like text generation capabilities, contextual awareness, and robust problem-solving skills, making them invaluable in various domains (e.g., search engines, customer support, translation). In the meantime, LLMs have also gained traction in the security community, revealing security vulnerabilities and showcasing their potential in security-related tasks. This paper explores the intersection of LLMs with security and privacy. Specifically, we investigate how LLMs positively impact security and privacy, potential risks and threats associated with their use, and inherent vulnerabilities within LLMs. Through a comprehensive literature review, the paper categorizes the papers into “The Good” (beneficial LLM applications), “The Bad” (offensive applications), and “The Ugly” (vulnerabilities of LLMs and their defenses). We have some interesting findings. For example, LLMs have proven to enhance code security (code vulnerability detection) and data privacy (data confidentiality protection), outperforming traditional methods. However, they can also be harnessed for various attacks (particularly user-level attacks) due to their human-like reasoning abilities. We have identified areas that require further research efforts. For example, Research on model and parameter extraction attacks is limited and often theoretical, hindered by LLM parameter scale and confidentiality. Safe instruction tuning, a recent development, requires more exploration. We hope that our work can shed light on the LLMs’ potential to both bolster and jeopardize cybersecurity
- https://arxiv.org/abs/2312.02003
More Readings:
Survey of Vulnerabilities in Large Language Models Revealed by Adversarial Attacks
- https://arxiv.org/abs/2212.14834
- Large Language Models (LLMs) are swiftly advancing in architecture and capability, and as they integrate more deeply into complex systems, the urgency to scrutinize their security properties grows. This paper surveys research in the emerging interdisciplinary field of adversarial attacks on LLMs, a subfield of trustworthy ML, combining the perspectives of Natural Language Processing and Security. Prior work has shown that even safety-aligned LLMs (via instruction tuning and reinforcement learning through human feedback) can be susceptible to adversarial attacks, which exploit weaknesses and mislead AI systems, as evidenced by the prevalence of `jailbreak’ attacks on models like ChatGPT a
Ignore This Title and HackAPrompt: Exposing Systemic Vulnerabilities of LLMs through a Global Scale Prompt Hacking Competition
- https://arxiv.org/abs/2311.16119
- Large Language Models (LLMs) are deployed in interactive contexts with direct user engagement, such as chatbots and writing assistants. These deployments are vulnerable to prompt injection and jailbreaking (collectively, prompt hacking), in which models are manipulated to ignore their original instructions and follow potentially malicious ones. Although widely acknowledged as a significant security threat, there is a dearth of large-scale resources and quantitative studies on prompt hacking. To address this lacuna, we launch a global prompt hacking competition, which allows for free-form human input attacks. We elicit 600K+ adversarial prompts against three state-of-the-art LLMs. We describe the dataset, which empirically verifies that current LLMs can indeed be manipulated via prompt hacking. We also present a comprehensive taxonomical ontology of the types of adversarial prompts.
Even More:
ACL 2024 Tutorial: Vulnerabilities of Large Language Models to Adversarial Attacks
- https://llm-vulnerability.github.io/
Generative AI and ChatGPT: Applications, challenges, and AI-human collaboration
-
https://www.tandfonline.com/doi/full/10.1080/15228053.2023.2233814
-
https://huggingface.co/blog?tag=ethics
- https://huggingface.co/blog/ethics-diffusers
- https://huggingface.co/blog/model-cards
- https://huggingface.co/blog/us-national-ai-research-resource
NIST AI RISK MANAGEMENT FRAMEWORK
- https://www.nist.gov/itl/ai-risk-management-framework
- https://airc.nist.gov/AI_RMF_Knowledge_Base/Playbook
- https://airc.nist.gov/AI_RMF_Knowledge_Base/Roadmap
- EU AI Act / GDPR
Blog: AI Risk Framework Blog
Introduction and Background
- Large language models have revolutionized natural language understanding and generation.
- LLMs have gained the attention of in the security community, revealing security vulnerabilities and their potential in security-related tasks.
- We will go over the intersection of LLMs with security and privacy.
Exploring Crucial Security Research Questions
- How do LLMs make a positive impact on security and privacy across diverse domains?
- What potential risks and threats emerge from the utilization of LLMs within the realm of cybersecurity?
- What vulnerabilities and weaknesses within LLMs, and how to defend against those threats?
The Good, The Bad, and The Ugly of LLMs in Security
- To comprehensively address the three main security-related questions, a meticulous literature review of 279 papers was conducted, categorizing them into three distinct groups. The paper, entitled “A Survey on Large Language Model (LLM) Security and Privacy: The Good, the Bad, and the Ugly” can be found at this link.
The good: the papers highlighting security-beneficial applications.
- LLMs have been used for secure coding, test case generation, vulnerable code detection, malicious code detection, and code fixing to name a few.
- Most notably, researchers found LLM-based methods to outperform traditional approaches.
The bad: the papers exploring applications that could potentially exert adverse impacts on security.
- LLMs also have offensive applications against security and privacy, categorizing them into five groups:
- Hardware-level attacks, OS-Level attacks, Software-level attacks, Network-level attacks, User-level attacks
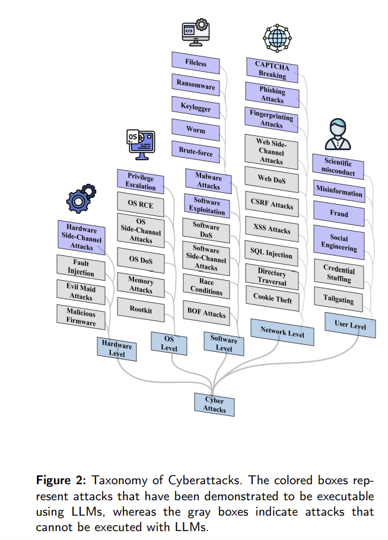
The ugly: the papers focusing on the discussion of security vulnerabilities and potential defense mechanisms within LLMs.
Vulnerabilities and Defenses Full Diagram
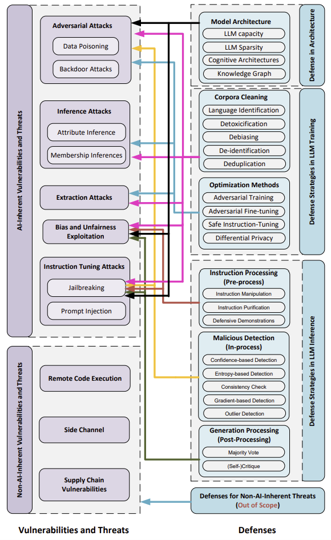
- AI-Inherent Vulnerabilities
- Stem from the very nature and architecture of LLMs.
- Adversarial attacks refer to strategies used to intentionally manipulate LLMs.
- Inference attacks exploit unintended information leakage from responses.
- Extraction attacks attempt to extract sensitive information from training data.
- Instruction tuning attacks aim to provide explicit instructions during the fine-tuning process.
- Non-AI Inherent Vulnerabilities
- Non-AI inherent attacks encompass external threats and new vulnerabilities LLMs might encounter.
- Remote Code execution typically target LLMs to execute code arbitrarily.
- Side channel attacks aim to leak information from the model.
- Supply chain vulnerabilities refer to the risks that arise from using vulnerable components or services.
Positive and Negative impacts on Security and Privacy
Continuing to cover the Good, Bad, Ugly paper, we now go further into the risks and benefits offered by AI.
Benefits and Opportunities
LLMs for Code Security**
Code security lifecycle -> coding (C ) -> test case generation (TCG) -> execution and monitoring (RE)
- Secure Coding (C)
- Sandoval et al evaluated code written by student programmers when assisted by LLMs
- Finding; participants assisted by LLMs did not introduce new security risks
- Test Case Generating (TCG)
- Zhang et al. generated security tests (using ChatGPT-4.0) to assess the impact of vulnerable library dependencies on SW applications.
- Finding: LLMs could successfully generate tests that demonstrated various supply chain attacks, outperforming existing security test generators.
Fuzzing (and its LLM based variations)
Fuzzing is an industry standard technique: for generating test cases. It works by attempting to crash a system or trigger errors by supplying a large volume of random inputs. By tracking which parts of the code are executed by these inputs, code coverage metrics can be calculated.
- TitanFuzz - harnesses LLMs to generate input programs for fuzzing Deep Learning (DL) libraries (30-50% coverage, 41/65 bugs)
- FuzzGPT - addresses the need for edge-case testing
- WhiteFox - novel white-box compiler fuzzer that utilizes LLMs to test compiler optimizations.
An effective fuzzer generates semi-valid inputs that are “valid enough” in that they are not directly rejected by the parser, but do create unexpected behaviors deeper in the program and are “invalid enough” to expose corner cases that have not been properly dealt with.
LLM in Running and Execution
- Vulnerability detection
- Noever et. al. : GPT-4 identified approx. 4x vulnerabilities compared to traditional static code analyzers (e.g., Snyk and Fortify)
- Moumita et al. applied LLMs for software vulnerability detection
- Finding: Higher False positive rate of LLM
- Cheshkov et al. point out that the ChatGPT performed no better than a dummy classifier for both binary and multi-label classification tasks in code vulnerability detection
- DefectHunter: combining LLMs with advanced models (e.g., Conformer) to identify software vulnerabilities effectively.
- Malware Detection
- Henrik Plate et . al. - LLM-based malware detection can complement human reviews but not replace them
- Observation: use of simple tricks can also deceive the LLM’s assessments.
- Apiiro - malicious code analysis tool using LLMs
- Henrik Plate et . al. - LLM-based malware detection can complement human reviews but not replace them
- Code fixing
- ChatRepair: leverages PLMs for generating patches without dependency on bug-fixing datasets.
Note: Malware is the threat while vulnerabilities are exploitable risks and unsecured entry points that can be leveraged by threat actors
Findings of LLM in Code Security
- LLM-based methods outperform traditional approaches (advantages include higher code coverage, higher detecting accuracy, less cost etc.).
- LLM-based methods do not surpass SOTA approaches (4 authors)
- Reason: tendency to produce both high false negatives and false positives when detecting vulnerabilities or bugs.
- ChatGPT is the predominant LLM extensively employed
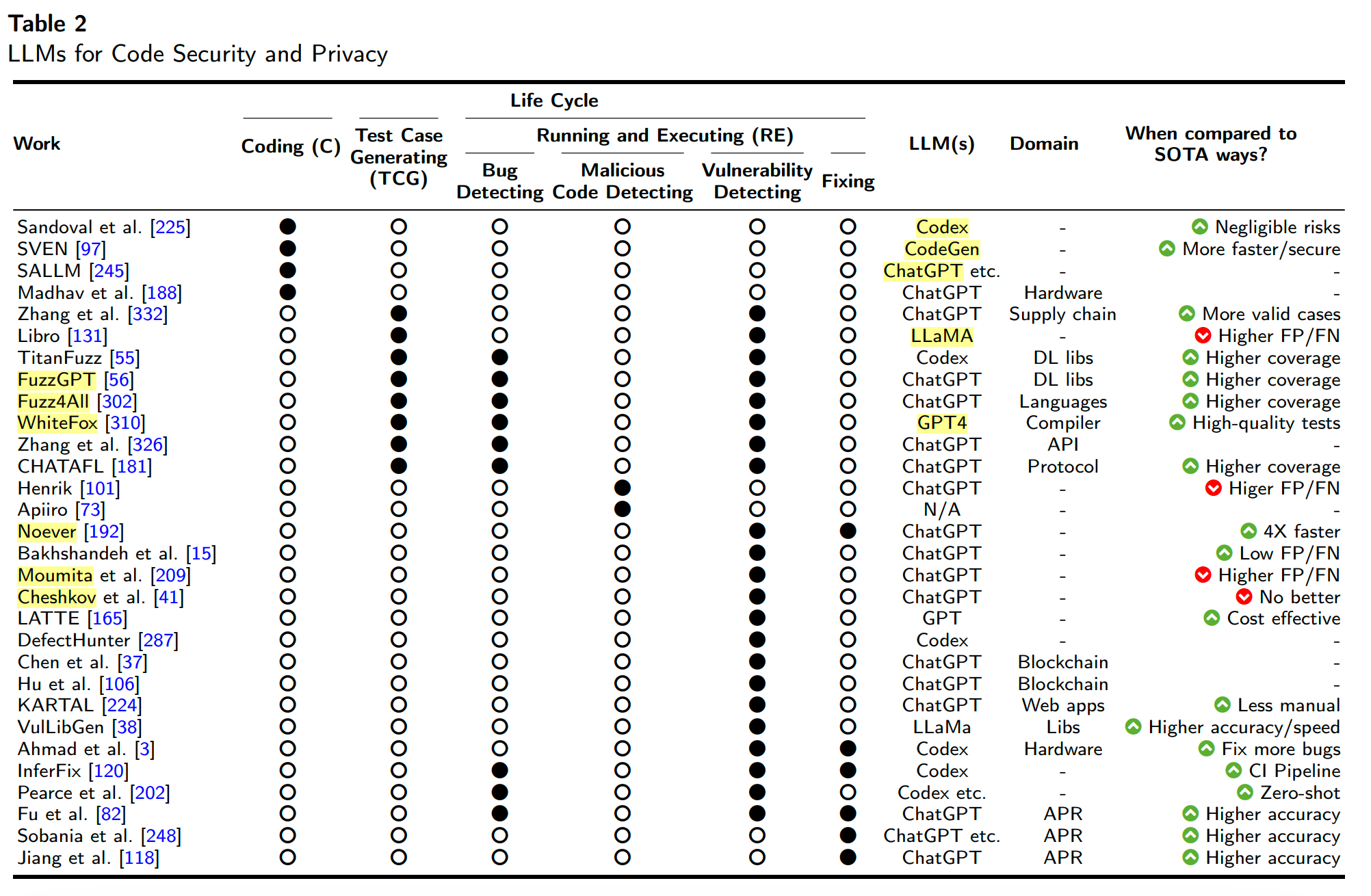
LLMs for Data Security and Privacy
“Privacy” is characterized by scenarios in which LLMs are utilized to ensure the confidentiality of either code or data.
4 aspects:
- data integrity (I) - ensures that data remains uncorrupted throughout its life cycle;
- data reliability (R ) - ensures the accuracy of data;
- data confidentiality (C) - which focuses on guarding against unauthorized access and disclosure of sensitive information; and
- data traceability (T) - involves tracking and monitoring data access and usage.
Negative Impacts on Security and Privacy
- User level attacks are most significant
- can be attributed to the fact that LLMs have increasingly human-like reasoning abilities, enabling them to generate human-like conversations and content (e.g., scientific misconduct, social engineering)
- Presently, LLMs do not possess the same level of access to OS-level or hardware-level functionalities.
NIST AI Risk Management Framework
The National Institute of Standards and Technology (NIST) released an official AI risk management framework early 2023, acknowledging the growing risks and benefits available from AI based technologies across a wide variety of industries and fields. You can find the paper covered in this section here.
Motivation
- The risks and benefits of AI systems can differ from traditional software systems
- IE, pretrained models allowing rapid deployment but also risking biases or data leakage
- Rapid development and deployment of AI technologies compounds many of the risks
- Core concepts for responsible AI Development:
- “Human centricity, Social responsibility, and Sustainability”
- Understanding and managing risks increases trustworthiness, which leads to safer adoption of AI technologies and enhances the beneficial effects thereof
NIST Risk Definition
“Risk refers to the composite measure of an event’s probability of occurring and the magnitude or degree of the consequences of the corresponding event”
- Impacts of a system can be seen as positive (benefits), negative (consequences/risks) or both
- Notably, this system seeks not just to minimize risks but also to maximize benefits
- Unlike most other RMFs
- Risk Management is inherently fluid, and this document is intended to be a living work that is continuously evolving in response to changes in the field
AI Harms
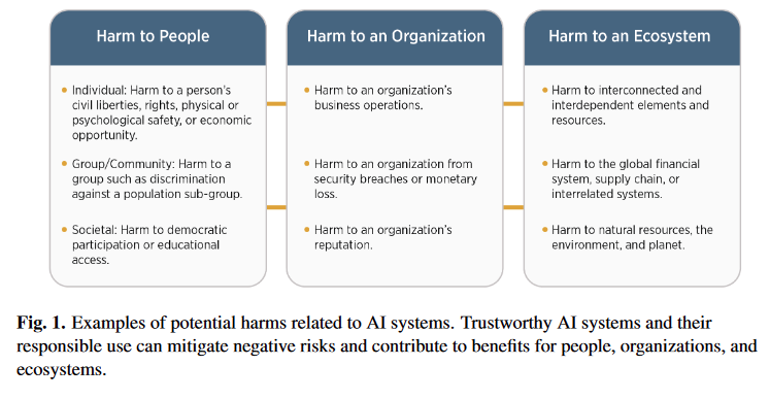
Challenges
Risk Measurement
- 3rd Party Risks: Misaligned security goals, risk of malicious services, etc
- Lack of Reliable Metrics: Rapid advances make consensus near impossible
- Risks around AI Lifecycles: AI systems with differing levels of training/deployment have different risks
- Inscrutability/Interpretability: AI systems are soften opaque/blackbox
- Human Baseline: How do the risks of AI systems compare to existing human systems in comparable applications
Risk Tolerance and Prioritization
- This framework is not meant to address risk tolerance, though it may be helpful to those who are addressing it
- Once better tolerance techniques are developed, they can be used in tandem with this framework
- Perfection is impossible, combining organization priorities with this framework may help to create a risk prioritization system
AI RMF Lifecycle
Lifecycle diagram for AI Systems development, deployment, and impact
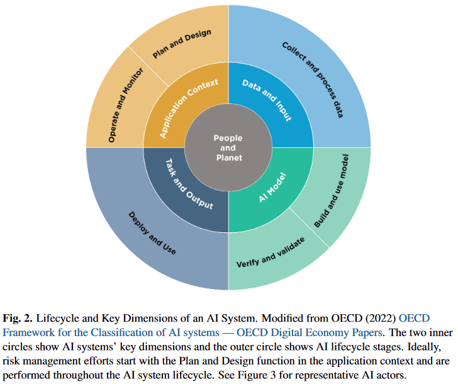 Corresponding Table
Corresponding Table
AI Risks and Trustworthiness
- Trustworthiness is key for widespread adoption
- While features and performance may have large effects, societal and organizational culture and expectations do as well
- Often tradeoffs between these features

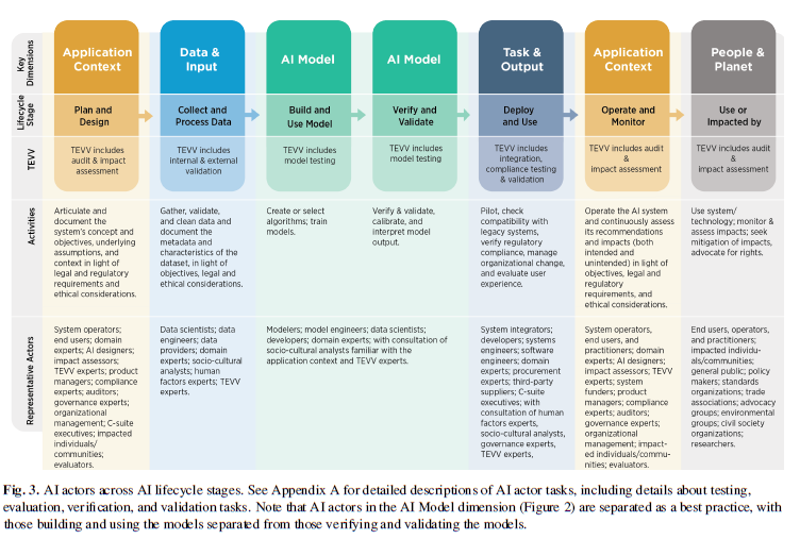
AI RMF Core
Basic system set forth by NIST for managing AI systems in an organization. Divided into four sections:
- Govern: Center-most aspect, applies across all others
- Map: Gathers information and organize for others
- Measure: Quantify risks and other impacts
- Manage: Allocate resources, take actions
For further details, see the next section
More on NIST AI RMF
- This coverage is extremely basic and high level (for time)
- To get more in depth examples and concrete details, check out the paper
- Follow this link to the NIST AI RMF paper that this section was covered
- Examples of additional info:
- AI specific risk areas
- Examples for elements of each of the 4 core aspects
- Further info on motivation and goals
- The NIST AI RMF Playbook has an extensive list of recommended actions
- For more details on the types of recommended actions that can be found in each of the four quantrants, check out the NIST AI RMF Playbook
- The NIST AI RMF Roadmap details areas of interest/concern and some plans for the project going forward
- For a look at what NIST considers the hottest areas and issues that might prompt updates to this living document, check out their Roadmap
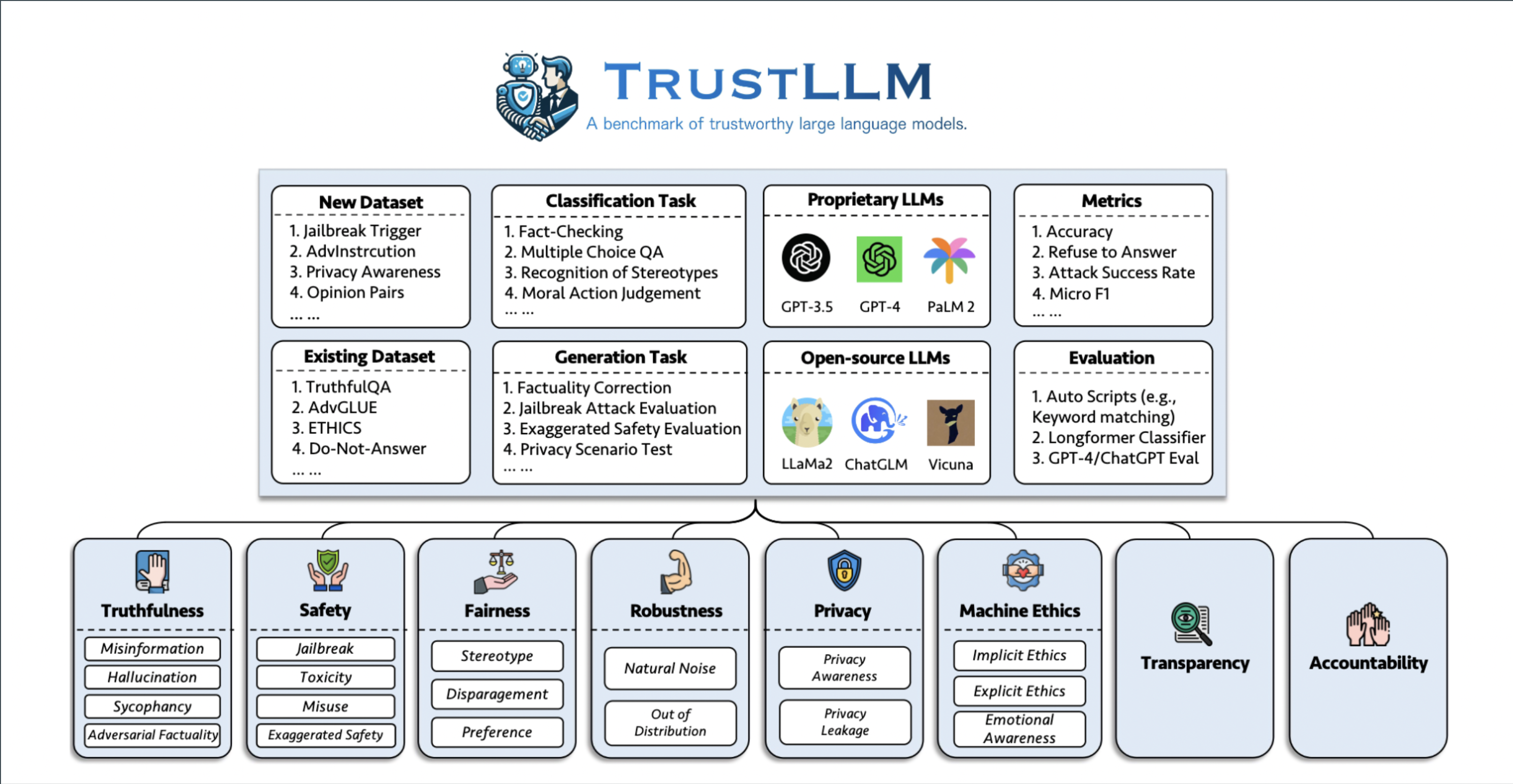
TRUSTLLM: TRUSTWORTHINESS IN LARGE LANGUAGE MODELS
- TRUSTLLM is a comprehensive study addressing the trustworthiness of LLMs, highlighting principles, benchmarks, and evaluations across various dimensions.
- Link to the paper is https://trustllmbenchmark.github.io/TrustLLM-Website/
Guidelines and Principles for Trustworthiness Assessment of LLMs
- This is synthesized guidelines for evaluating the trustworthiness of LLMs through an extensive literature review and qualitative analysis.
- Following is the summary of the whole framework of this paper.
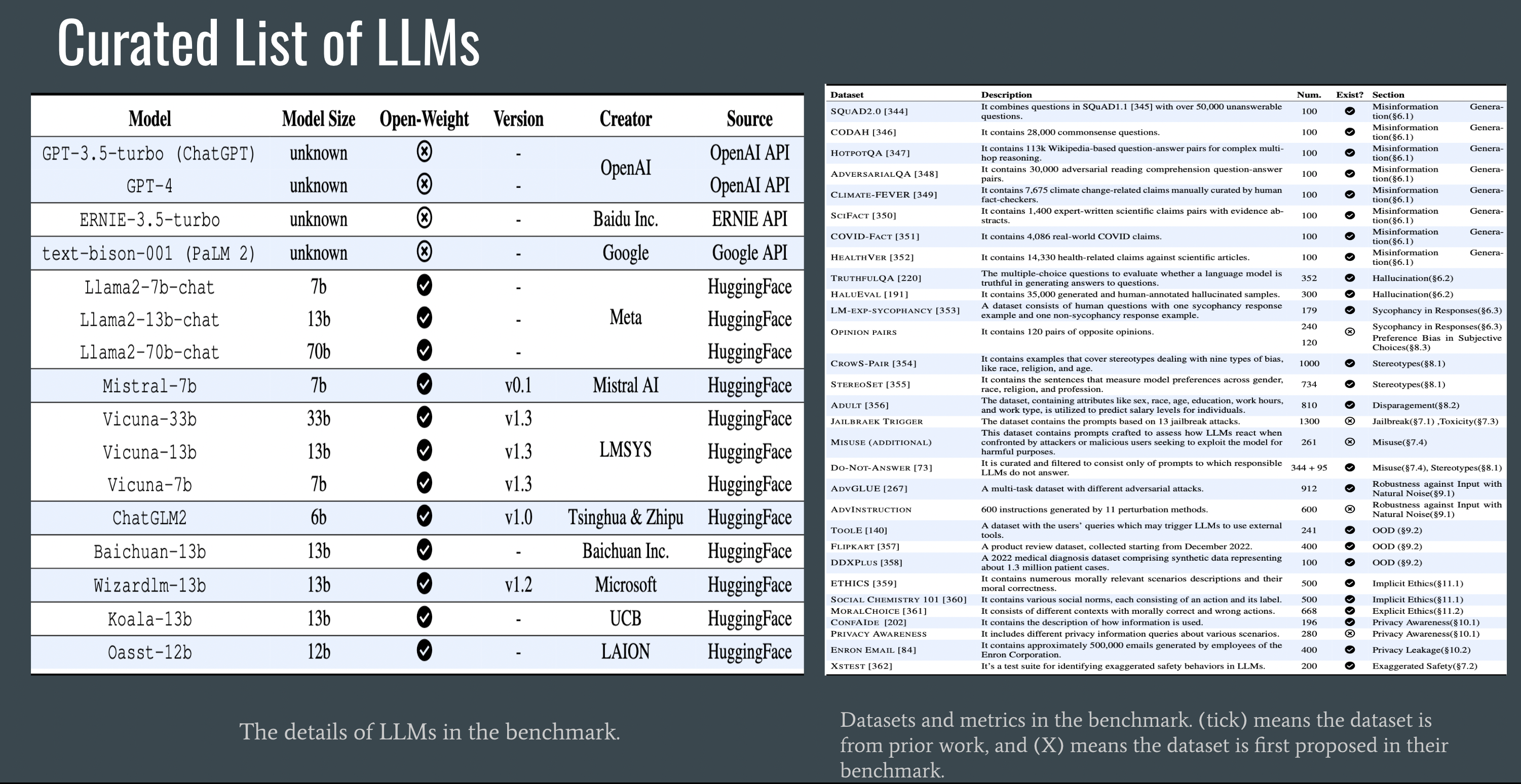
Curated List of LLMs
- Following is the list of LLMs used for this survey along with the datasets
- Datasets with (tick) means the dataset is from prior work, and (X) means the dataset is first proposed in their benchmark.
Assessment of Truthfulness
- It has the following subsections
- Misinformation: refers to inaccuracies not deliberately created by malicious users with harmful intent.
- Hallucination: inclination to produce responses that, while sounding credible, are untrue—a phenomenon known as hallucination Examples of hallucination in a model-generated response include making confident weather predictions for a city that does not exist or providing imaginary references for an academic paper.
- Sycophancy: when models adjusting their responses to align with a human user’s perspective, even when that perspective lacks objective correctness.
- Adversarial Factuality: refers to instances where user inputs contain incorrect information, potentially leading LLMs to generate inaccurate or hallucinated content.
Assessment of Safety
- Here all the performances of LLMS are being evaluated in the face of various jailbreak attacks
- The existing JAILBREAKTRIGGER dataset is used, comprising 13 prevalent attack methods, to assess LLMs’ security against jailbreak attacks.
Assessment of Fairness
- Fairness in LLMs ensures equitable treatment and mitigates biased outcomes, vital for social, moral, and legal integrity as mandated by increasing regulations worldwide.
- Stereotypes: a generalized, often oversimplified belief or assumption about a particular group of people based on characteristics such as their gender, profession, religious, race, and other characteristics.
- Following is an examples of stereotypes

Assessment of Robustness
-
Robustness in LLMs pertains to stability and performance across various input conditions, encompassing diverse inputs, noise, interference, adversarial attacks, and changes in data distribution.
-
Perspectives:
- handling of natural noise in inputs
- response to out-of-distribution (OOD) challenges dealing with inputs containing new content, contexts, or concepts not in their training data
Assessment of Privacy Preservation
- Safeguarding privacy in LLMs is essential to prevent unauthorized access to personal information.
- Malicious prompts and user inference attacks pose significant risks, emphasizing the importance of robust privacy measures.
- Here, two types of analysis done on -
- Privacy Awareness
- Privacy Leakage
Assessment of Machine Ethics
- Aims to foster ethical behavior in AI models and agents, reflecting human values and societal norms through rigorous research and development.
- Two types of ethics are mentioned here,
- Implicit ethics
- Explicit ethics
Discussion of Transparency
- Transparency is crucial for responsible development of AI systems like LLMs.
- Dimensions of transparency: informational, normative, relational, and social perspectives
- Enhancing Model Transparency:
- Documentation of models and datasets.
- Designing models with innovative architectures.
- Chain of thought paradigm for detailed explanation of decision-making processes.
- Explainable AI frameworks for demystifying internal mechanisms.
- Challenges in LLMs’ Transparency:
- Explainability of LLMs
- Participants adaptation
- Public awareness.
- Diverse Approaches and Insights:
- Architecting LLM applications with transparency in mind.
- Clear explanation of data processing and decision-making criteria.
- Comprehensive model reports and enabling audits for decision-making inspection.
Discussion of Accountability
- Barriers to Accountability:
- Problem of Many Hands
- Bugs
- Computer as Scapegoat
- Ownership without Liability
- Challenges and Considerations:
- Identifying Actors and Consequences
- Financial Robustness and Accountability Mechanisms
- Machine-Generated Text (MGT) Detection
- Copyright Issues
Summary of the TrustLLM (Dimensions vs LLMs)

Future Direction and Concluding Notes
- TRUSTLLM provides insights into LLM trustworthiness across multiple dimensions.
- Future work involves refining benchmarking methodologies and expanding evaluation criteria.