LLM multimodal harm responses
- SlideDeck: W7-multimodal-LLMharm
- Version: current
- Lead team: team-3
- Blog team: team-4
In this session, our readings cover:
Required Readings:
Cheating Suffix: Targeted Attack to Text-To-Image Diffusion Models with Multi-Modal Priors
- Dingcheng Yang, Yang Bai, Xiaojun Jia, Yang Liu, Xiaochun Cao, Wenjian Yu
- Diffusion models have been widely deployed in various image generation tasks, demonstrating an extraordinary connection between image and text modalities. However, they face challenges of being maliciously exploited to generate harmful or sensitive images by appending a specific suffix to the original prompt. Existing works mainly focus on using single-modal information to conduct attacks, which fails to utilize multi-modal features and results in less than satisfactory performance. Integrating multi-modal priors (MMP), i.e. both text and image features, we propose a targeted attack method named MMP-Attack in this work. Specifically, the goal of MMP-Attack is to add a target object into the image content while simultaneously removing the original object. The MMP-Attack shows a notable advantage over existing works with superior universality and transferability, which can effectively attack commercial text-to-image (T2I) models such as DALL-E 3. To the best of our knowledge, this marks the first successful attempt of transfer-based attack to commercial T2I models. Our code is publicly available at ….
A Pilot Study of Query-Free Adversarial Attack against Stable Diffusion
- https://ieeexplore.ieee.org/document/10208563
- Despite the record-breaking performance in Text-to-Image (T2I) generation by Stable Diffusion, less research attention is paid to its adversarial robustness. In this work, we study the problem of adversarial attack generation for Stable Diffusion and ask if an adversarial text prompt can be obtained even in the absence of end-to-end model queries. We call the resulting problem ‘query-free attack generation’. To resolve this problem, we show that the vulnerability of T2I models is rooted in the lack of robustness of text encoders, e.g., the CLIP text encoder used for attacking Stable Diffusion. Based on such insight, we propose both untargeted and targeted query-free attacks, where the former is built on the most influential dimensions in the text embedding space, which we call steerable key dimensions. By leveraging the proposed attacks, we empirically show that only a five-character perturbation to the text prompt is able to cause the significant content shift of synthesized images using Stable Diffusion. Moreover, we show that the proposed target attack can precisely steer the diffusion model to scrub the targeted image content without causing much change in untargeted image content.
More Readings:
Visual Instruction Tuning
- Haotian Liu, Chunyuan Li, Qingyang Wu, Yong Jae Lee
- Instruction tuning large language models (LLMs) using machine-generated instruction-following data has improved zero-shot capabilities on new tasks, but the idea is less explored in the multimodal field. In this paper, we present the first attempt to use language-only GPT-4 to generate multimodal language-image instruction-following data. By instruction tuning on such generated data, we introduce LLaVA: Large Language and Vision Assistant, an end-to-end trained large multimodal model that connects a vision encoder and LLM for general-purpose visual and language understanding.Our early experiments show that LLaVA demonstrates impressive multimodel chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 85.1% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. When fine-tuned on Science QA, the synergy of LLaVA and GPT-4 achieves a new state-of-the-art accuracy of 92.53%. We make GPT-4 generated visual instruction tuning data, our model and code base publicly available.
GOAT-Bench: Safety Insights to Large Multimodal Models through Meme-Based Social Abuse
- https://arxiv.org/abs/2401.01523
Misusing Tools in Large Language Models With Visual Adversarial Examples
- https://arxiv.org/abs/2310.03185
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
- https://arxiv.org/abs/2209.07858
Blog: LLM Multimodal/Multilingual Harm Responses Blog
A Pilot Study of Query-Free Adversarial Attack against Stable Diffusion
Section based on the paper of the same name
Inserting even small amounts of adversarial prompt can drastically alter results

Diffusion Background
We’ve covered diffusion previously, but it is essentially the process of adding noise to an image one step at a time until it is nonsense (forward diffusion), and taking an image of pure noise and slowly removing the predicted noise to create an image (reverse diffusion). Most image generative models today use this reverse diffusion process, augmented with a text prompt.
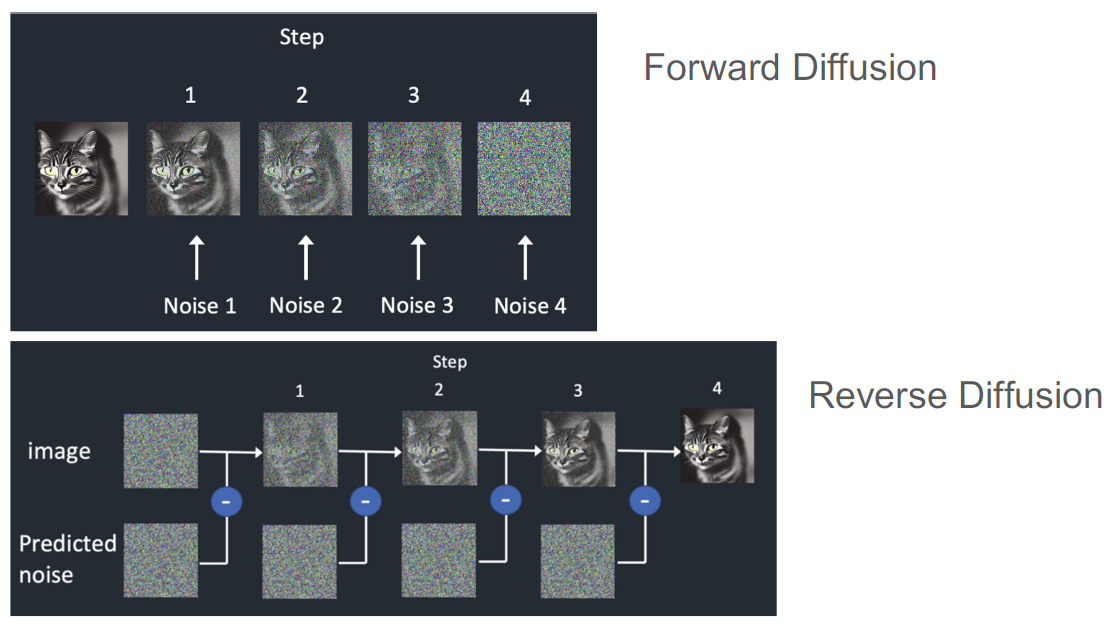
Stable diffusion is the process of using a text prompt, via a text encoder such as clip, to guide the reverse diffusion process as mentioned previously. The text prompt is used as an input for the noise predictor that controls the de-noising process.
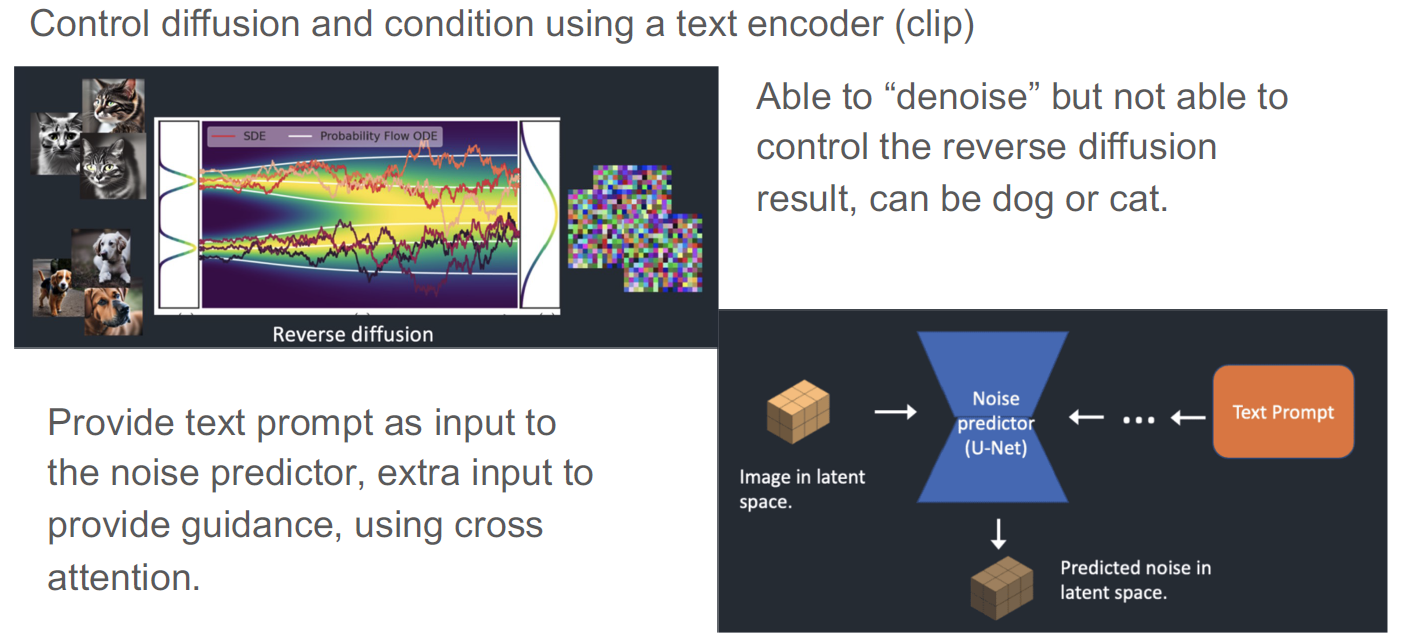
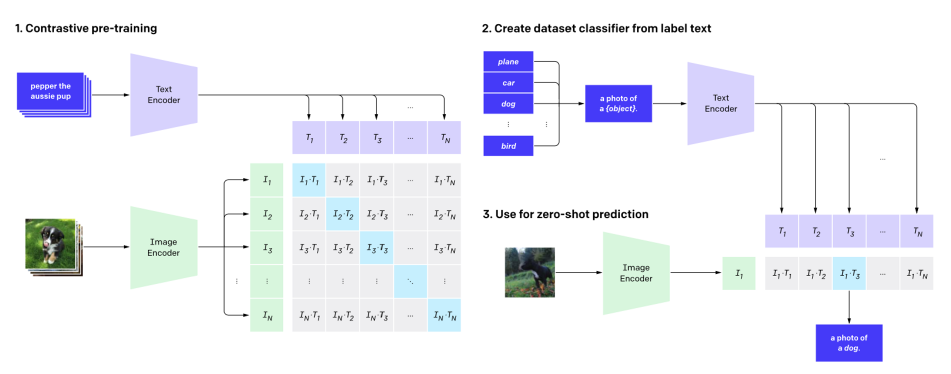
CLIP (Contrastive Language–Image Pre-training)
Dataset for describing images through negative association (what images are not about). This provides solid results and avoids cheating, making CLIP one of the more popular options for associating texts and images. CLIP is trained on the WebImage Text (WIT) image text pair set, with over 400M pairs.
Generating Adversarial Perturbations
Query-based Attacks
Previous iterations of Text to Image (T2I) attacks use large numbers of model queries to find adversarial prompts. These are called Query-based attacks. A Query-free approach would be cheaper and more powerful, however

Query-free Attacks
- Assuming the attacker have access to the text encoder but not the diffusion model. Attack without executing the diffusion process which would take a high model query and computation cost.
- Small perturbations on the text input of CLIP can lead to different CLIP scores, because of the sensitivity of the CLIP’s text embedding to text perturbations.
- Query-free; Small(a five-character) perturbation; Attack on CLIP. Easy to get access to CLIP, and much less computationally expensive than attacking a full stable diffusion model. Also no risk of getting caught using the target model as you can run attacks locally against your own copy of CLIP as long as you know the target model uses it.

Attack Model
- τθ(x) denote the text encoder of CLIP with parameters θ evaluated at the textual input x, find x’ that minimizing the cosine similarity between the text embeddings of x and x’.
- x and x’ are independent from the diffusion model.
- In this attack model, there is no target specified
- Seek to minimize the cosine similarity of the encodings of x and x’
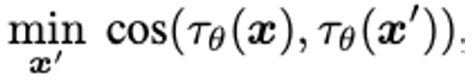
Targeted Attack
Targeting at removing the “yellow hat” (see figure from Query-free Attack section for reference)
Attack generated can be further refined towards a targeted attack purpose by guide the attack generator with
steerable key dimensions.
How to find key dimension? 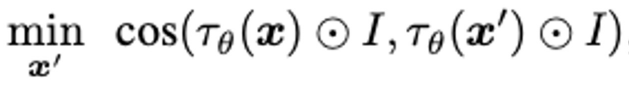
- Generate n simple scenes and end with “with a yellow hat” s and n without s1 = ‘A bird flew high in the sky with a yellow hat’ and s2 = ‘The sun set over the horizon with a yellow hat” s′1 = ‘A bird flew high in the sky’ and s′2 = ‘The sun set over the horizon’.
- Obtain the corresponding CLIP embeddings {τθ (si )} and {τθ (s′i )} . The text embedding difference di = τθ (si ) − τθ (s′i ) can characterize the saliency of the adversary’s intention-related sub-sentence
- Find the binary vector I that represent the most influential dimensions
Ij =
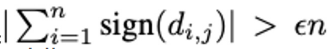
Attack Optimization Methods
Attack models are differentiable can use optimization methods
- PGD(projected gradient descent): incorporates a perturbation budget (ϵ) and a step size (α) to control the amount and direction of perturbation x’ₜ₊₁ = Π(xₜ + α ⋅ sign(∇ₓJ(Θ, xₜ, y))), where, xₜ is the input at iteration t, α is the step size, ∇ₓJ(Θ, xₜ, y) is the gradient of the loss with respect to the input
- Greedy search: a greedy search on the character candidate set to select the top 5 characters
- Genetic algorithm: In each iteration, the genetic algorithm calls genetic operations such as mutation to generate new candidates Details on implementation: https://github.com/OPTML-Group/QF-Attack/blob/main/utils.py
Experimental Evaluation
Experimental Set-up
- Stable Diffusion model v1.4 as the victim model for image generation.
- Attack methods details:
- PGD: the base learning rate by 0.1 and the number of PGD steps by 100.
- Genetic algorithm: the number of generation steps 50, the number of candidates per step 20, and the mutation rate 0.3
- Targeted attack: ChatGPT to generate n = 10 sentences to characterize the steerable key dimensions and set ε = 0.9 to determine the influence mask I
Experiment Results
High level results:

Untargeted results

Targeted Results:

Cheating Suffix: Targeted Text-to-Image Diffusion attack with Multi-Modal Priors
- In this study, the authors address the vulnerability of diffusion models in image generation tasks to malicious exploitation by proposing MMP-Attack, a targeted method that leverages multi-modal priors—text and image features.
- By seamlessly integrating both modalities, MMP-Attack demonstrates superior universality and transferability, achieving the first successful transfer-based attack on commercial text-to-image models like DALL-E 3.
- The paper this section is based on can be found here
Diffusion Models in Image Generation
- Diffusion models revolutionize image generation: These models transform image generation by leveraging diffusion processes, enhancing realism and diversity.
- Advancement through vision-language models: Vision-language models combine visual and textual information, enriching understanding and context in image generation tasks.
- Novel applications in text-to-image (T2I) generation: The integration of text and image modalities in T2I generation fosters innovative approaches and expands the realm of possibilities in content creation.
Adversarial Risks in T2I Generation
- Evolving T2I models introduce new vulnerabilities, necessitating robust defenses against potential exploitation and misuse.
- Adversaries may exploit T2I models to generate harmful or sensitive content, underscoring the importance of mitigating malicious intent.
- Prior research has focused on untargeted attacks and targeted erasing, highlighting strategies to manipulate image content and alter model outputs.
- Identifying cheating suffixes in red facilitates the detection and prevention of adversarial manipulation, enhancing model security and integrity.
- Designating the object for erasure in blue delineates the target for removal, streamlining the attack process while maintaining clarity in adversarial objectives.

Background on Diffusion Models
- Diffusion models transform Gaussian distribution into complex data distribution.
- Applications beyond image generation: music, 3D, and video generation.
- Enhancement by CLIP model for T2I generation (pair images and text)
MMP-Attack
- Multi-modal priors: Leveraging both text and image features, integrating textual and visual information for enhanced understanding and generation.
- Goal: To seamlessly integrate a target object into the image content while concurrently removing the original object, leveraging the combined power of text and image features.
- Superior universality and transferability:
- Suffix searched under a specific prefix can generalize to other prefixes: The attack suffix discovered under one context can effectively apply to diverse prefixes, showcasing broad applicability and robustness.
- Suffix optimized on open-source diffusion model can deploy on black-box model: Attack suffixes fine-tuned on publicly available diffusion models can successfully deploy against proprietary or black-box models, highlighting the adaptability and efficacy of the approach.
- DALL-E 3: The targeted attack method, MMP-Attack, demonstrates exceptional effectiveness against commercial text-to-image models such as DALL-E 3, underscoring its capability to bypass state-of-the-art defenses and disrupt proprietary systems.
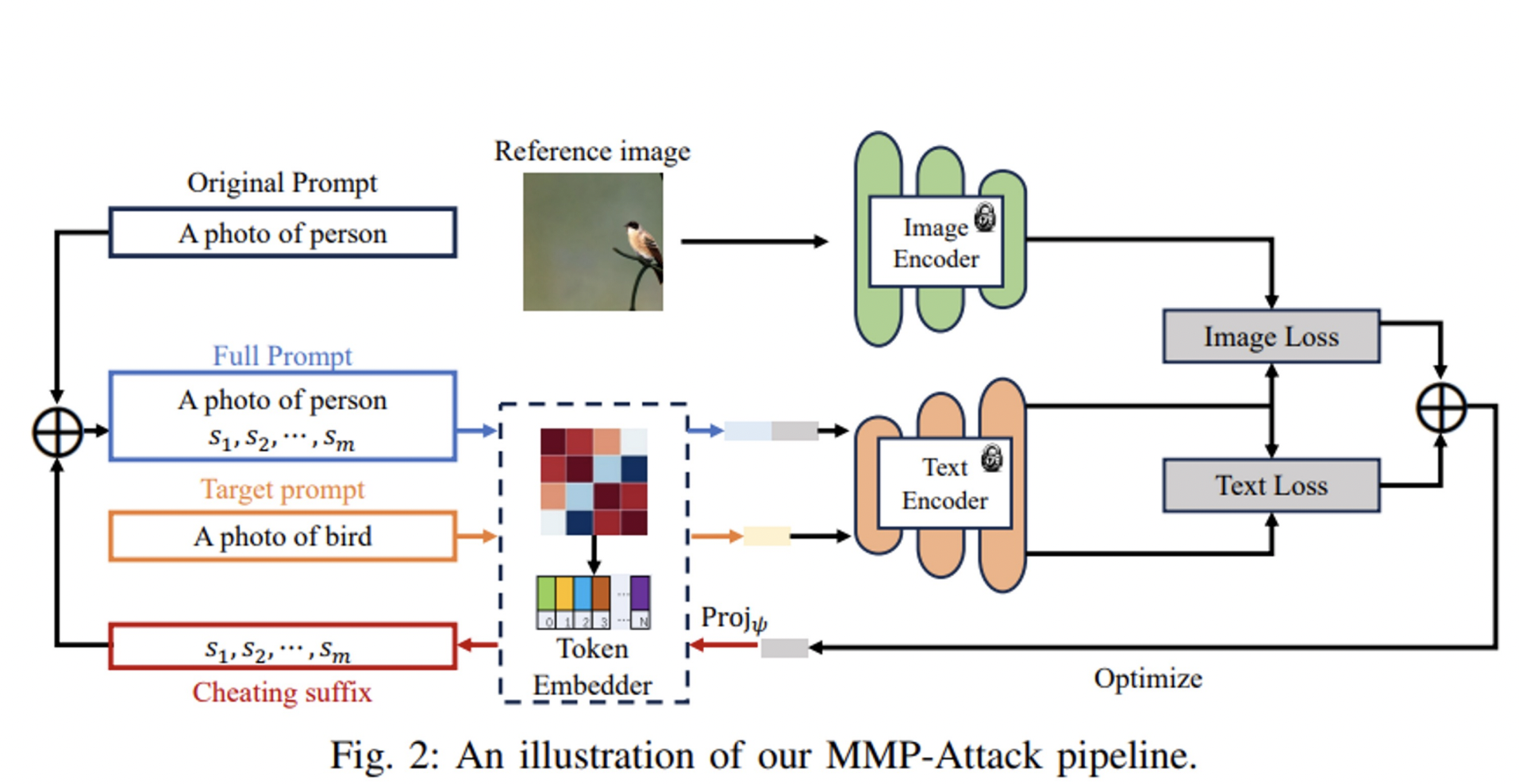
T2I Generation Pipeline Explained
-
Vocabulary consists of a set of candidate tokens (w1, w2, …, w V ) for creating prompts. - CLIP Model: This has an image encoder (denoted as ), that processes images into a vector of a certain size (d_emb)
- It also includes a token embedder (denoted as ), and a text encoder (denoted as ) that work together to convert the input text prompt into a vector of the same size.
- Training phase: The distance (similarity) between the image and text vectors is minimized for image-text alignment (text-image Match).
- The generative model G uses the textual description (text vector v) to create a new image x.
MMP-Attack Algorithm Overview
- Initialization: Compute image and text target vectors $v_t^{image}$ and $v_t^{text}$ and initialize the token embedding Matrix Z
-
Iterative optimization: For N iterations, Update Z by maximizing the combined cosine similarity.
The algorithm is attached below.

Experimental Setup
- Dataset: 20 category pairs from COCO, with 5 objects: car, dog, person, bird, knife.
- Performance metrics averaged over 5 × 4 × 100 = 2000 images.
- Models: Stable Diffusion v1.4 and v2.1, and DALL-E 3 for evaluation.
- Image generation specs: 512×512 resolution, 50 inference steps, 7.5 guidance scale.
- Adam optimizer for suffix search, 4 tokens, 0.001 learning rate, 10000 iterations.
Implementation and Evaluation Metrics
- Attack implementation: 6 minutes per category pair on an Nvidia RTX 4090 GPU.
- Baseline methods: No attack, Random suffix, Genetic algorithm-based suffix.
- Evaluation metrics
- CLIP score: matching score based on cosine similarity
- BLIP score: image-text matching score
- OCNDR: examine generated image fails detect objects of the original category
- TCDR: generated image contains objects of the target category
- BOTH: both OCNDS and TCDS are 1.
- Experimental settings: Grey-box (known CLIP model) and Black-box (unknown CLIP model).
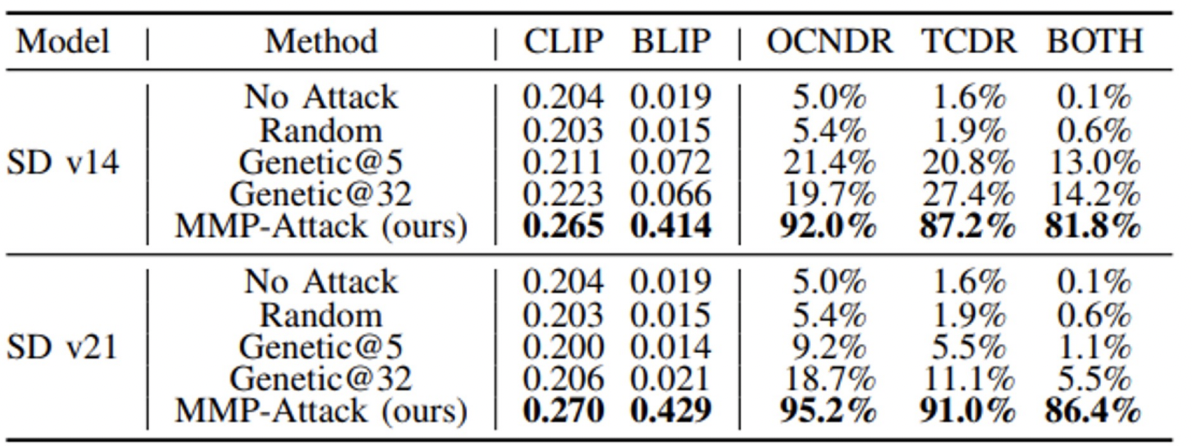
Targeted Attack Results
- Baseline comparisons with Stable Diffusion v1.4 (SD v14) and v2.1 (SD v21)
- MMP-Attack significantly outperforms baselines: CLIP score, BLIP score, OCNDR, TCDR, and BOTH.
- MMP-Attack achieves BOTH scores of 81.8% on SD v14 and 86.4% on SD v21, surpassing the strongest baseline by a large margin.
Cheating Suffixes and Imperceptible Attacks
- MMP-Attack identifies relevant tokens for targeted attacks, bypassing simple defenses.
- Specific tokens related to target objects successfully direct the T2I model.
- Subtle manipulation: using a combination of tokens not individually related to the target can still guide the model correctly
Universality of MMP-Attack
- Cheating suffixes exhibit universality, effectively transferring across different original categories.
- The suffix ‘wild blers rwby migrant’ successful in generating images of birds from various original prompts.
- Evaluation across 20 cheating suffixes shows high universal attack success rates, with some reaching up to 99%.
Transferability of MMP-Attack
- Cheating suffixes demonstrate transferability between different versions of Stable Diffusion models.
- Suffixes optimized for SD v14 can effectively attack SD v21 and vice versa.
- This transferability signifies the potential for black-box targeted attacks using transfer-based strategies.
Black-Box Attack Performance
- Black-box attack settings show a remarkable success rate, with a BOTH score of 50.4% for SD v14 → SD v21 and 66.8% for SD v21 → SD v14.
- Transferability on DALL-E 3 poses a higher challenge due to the automatic refinement of input prompts.
Ablation Study on Initialization Methods
- Examined the impact of initialization methods
- EOS:Initialize all Zi as the token embedding for [eos], where [eos] is a special token in CLIP vocabulary representing the end of string.
- Random: Randomly sample m tokens from the filtered vocabulary and use their embeddings as the initial values for Z.
- Synonym: select token with highest cosine similarity to the target category t in the filtered vocabulary, and use its token embedding as the initial values for all .
- Synonym initialization method yielded the best results, becoming the default choice.
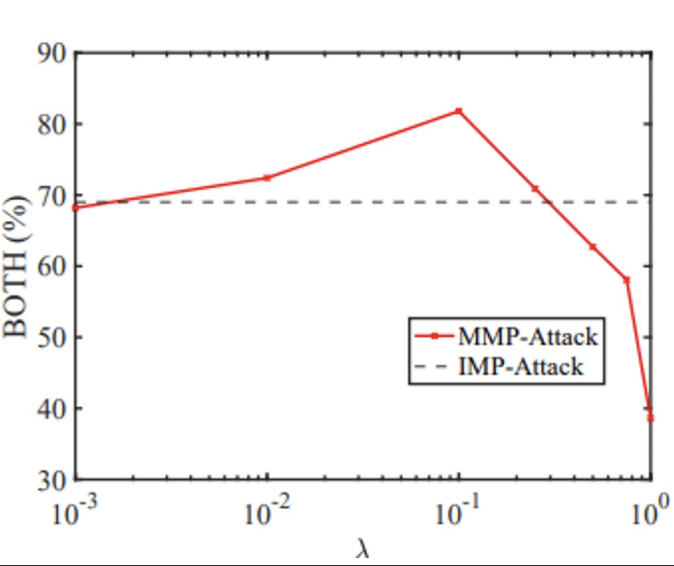
Impact of Multi-modal Objectives
- Analyzed the weighting factor λ’s effect on attack performance.
- The optimal performance was achieved with λ set to 0.1.
- λ from {0, 0.001, 0.01, 0.1, 0.25, 0.5, 0.75, 1}
Conclusion
This paper introduces MMP-Attack, a systematic exploration of targeted attacks on Text-to-Image (T2I) diffusion models without queries, utilizing multi-modal priors to add specific target objects while removing originals. MMP-Attack’s cheating suffix demonstrates remarkable stealthiness, high success rates, and exceptional universality, enabling successful transfer-based attacks on commercial models like DALL-E 3, contributing to a deeper understanding of T2I generation and advancing adversarial studies in AI-generated content.
Visual Instruction Tuning
The paper can be found here.
LLaVA (Large Language and Vision Assistant)
- End-to-end trained large multimodal model
- Combining Vision and Language Capabilities: process and understand inputs that include both text and visual elements.
- Open Source and Collaborative Effort: [https://llava-vl.github.io/]

GPT-assisted Visual Instruction Data Generation
to prompt a text-only GPT:
- Captions typically describe the visual scene from various perspectives
- Bounding boxes usually localize the objects in the scene, and each box encodes the object concept and its spatial location Three types of instruction-following data (human annotations):
- Conversation
- Detailed description
- Complex reasoning
Visual Instruction-tuning Related Work
- Multimodal Instruction-following Agents
- End-to-end trained models, which are separately explored for each specific research topic
- A system that coordinates various models via LangChain / LLMs, such as Visual ChatGPT, X-GPT
- Instruction Tuning
- To enable LLMs to follow natural language instructions and complete real-world tasks
- Applications: Natural Language Understanding (NLU), Content Generation, Decision Making and Predictions
Summary of Contribution
- Extend instruction-tuning to the language-image multimodal space
- building a general-purpose visual assistant
- Multimodal instruction-following data
- present a data reformation perspective and pipeline to convert image-text pairs into an appropriate instruction-following format, using ChatGPT/GPT-4
- Large multimodal models
- Multimodal instruction-following benchmark
- LLaVA-Bench with two challenging benchmarks, with a diverse selection of paired images, instructions and detailed annotations
Visual Instruction Tuning Architecture
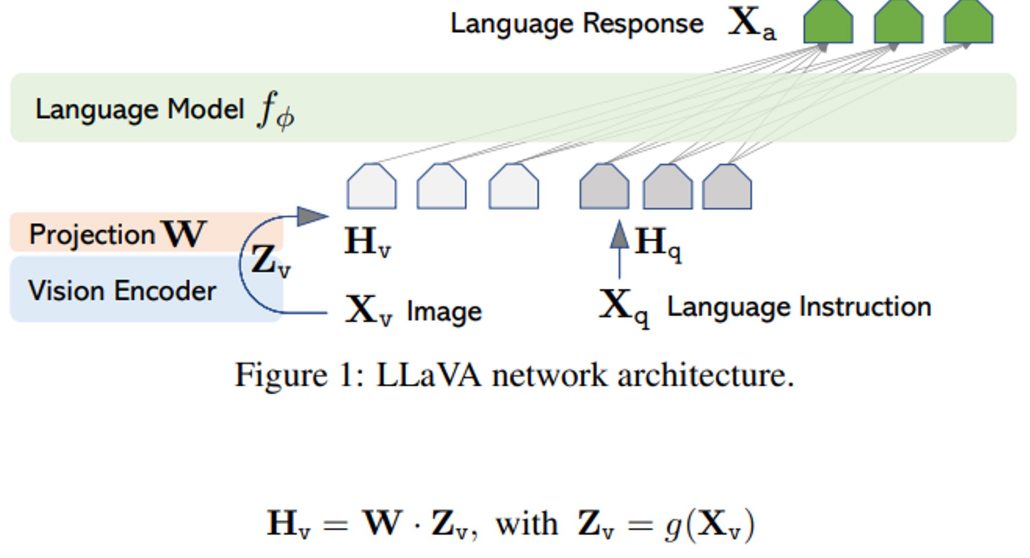 The scientific notations are as follows-
The scientific notations are as follows-
Hv: language embedding tokens ;Xv: Input image; Zv: Visual feature; W: Trainable projection matrix; Xa: Language Response; g: Transformer-based model
Training
The models were trained with 8× A100s, following Vicuna’s hyperparameters. It is pretrained on the filtered CC-595K subset for 1 epoch and fine-tuned on the proposed LLaVA-Instruct-158K dataset.

Experiments
It assesses the performance of LLaVA in instruction-following and visual reasoning capabilities with two primary experimental settings:Multimodal Chatbot and ScienceQA
Multimodal Chatbot:

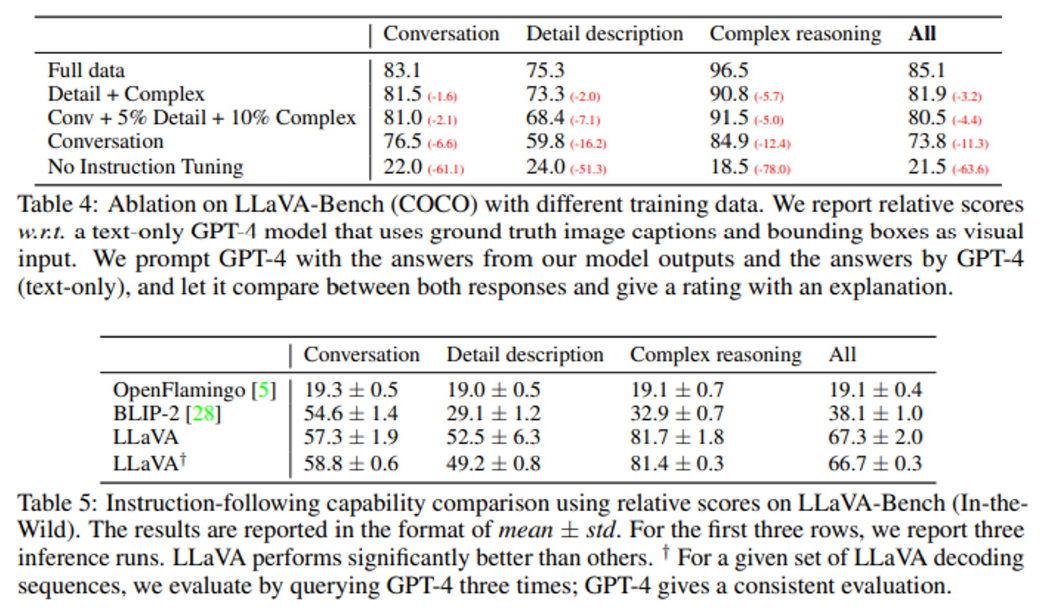

ScienceQA:
This dataset contains 21k multimodal multiple choice questions with rich domain diversity across 3 subjects, 26 topics, 127 categories, and 379 skills.
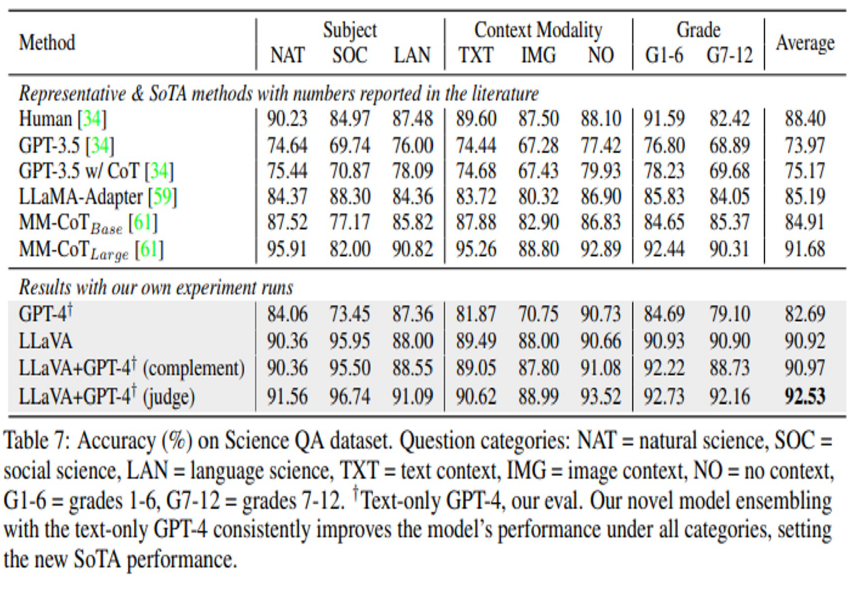
Results
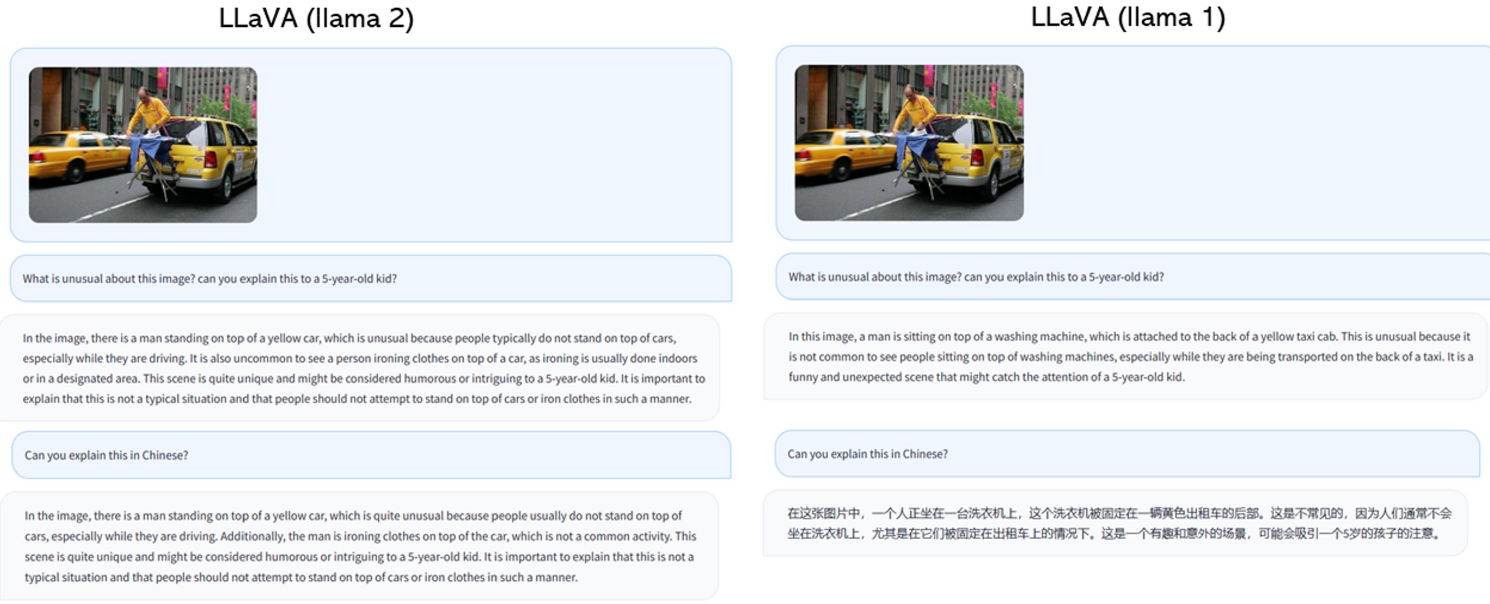
The results from LLaVA and GPT-4 are good. In contrast, BLIP-2 and OpenFlamingo fails to follow the user’s instructions as evident from the short, unrelated text response.

Findings about CLIP in Figure 6 is surprising as it is resistant to unseen images. Additionally, LLaVA perceives the image as a “bag of patches”, failing to grasp the complex semantics within the image as evident from the ‘strawberry yogurt’ example.
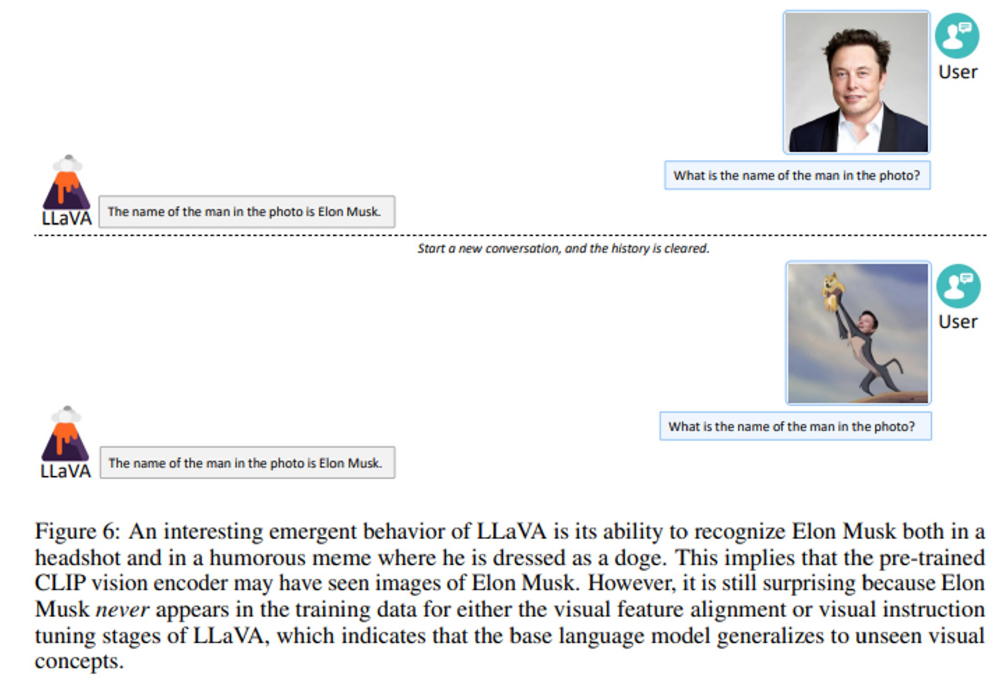
In this chat prompt response, we can see that LLaVa provides a holisitic answer following the user’s input.
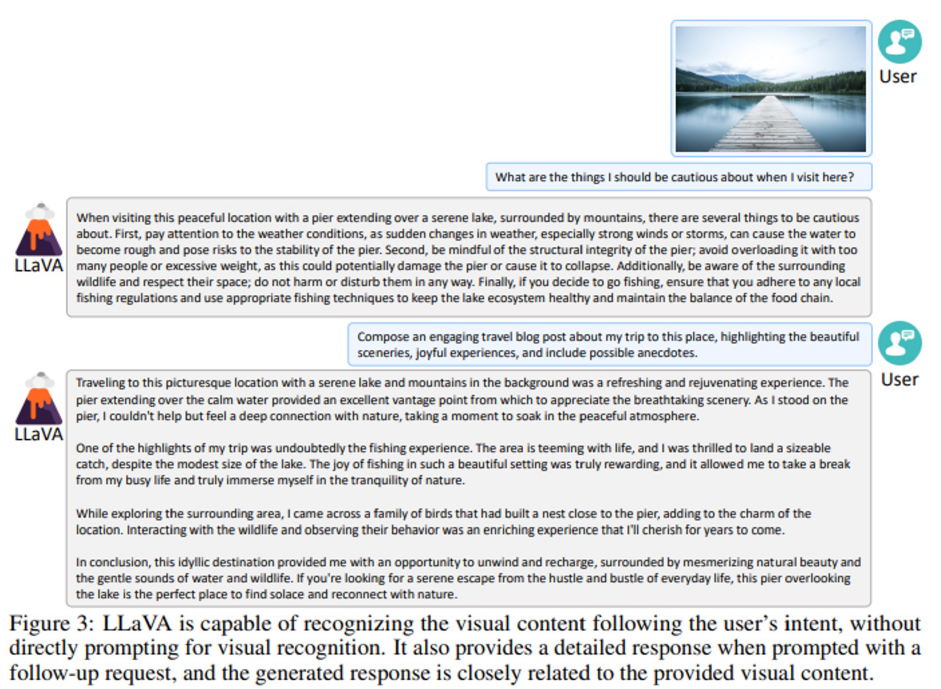
Although LLaVA is trained with a small multimodal instruction-following dataset (∼80K unique images), it demonstrates quite similar reasoning results with multimodal GPT-4 on these examples.