LLM Hallucination
- SlideDeck: W9-Team3-P4-hallucination
- Version: current
- Lead team: team-3
- Blog team: team-1
In this session, our readings cover:
Required Readings:
A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions
- https://arxiv.org/abs/2311.05232
- The emergence of large language models (LLMs) has marked a significant breakthrough in natural language processing (NLP), leading to remarkable advancements in text understanding and generation. Nevertheless, alongside these strides, LLMs exhibit a critical tendency to produce hallucinations, resulting in content that is inconsistent with real-world facts or user inputs. This phenomenon poses substantial challenges to their practical deployment and raises concerns over the reliability of LLMs in real-world scenarios, which attracts increasing attention to detect and mitigate these hallucinations. In this survey, we aim to provide a thorough and in-depth overview of recent advances in the field of LLM hallucinations. We begin with an innovative taxonomy of LLM hallucinations, then delve into the factors contributing to hallucinations. Subsequently, we present a comprehensive overview of hallucination detection methods and benchmarks. Additionally, representative approaches designed to mitigate hallucinations are introduced accordingly. Finally, we analyze the challenges that highlight the current limitations and formulate open questions, aiming to delineate pathways for future research on hallucinations in LLMs.
More Readings:
LLMs as Factual Reasoners: Insights from Existing Benchmarks and Beyond
- https://arxiv.org/abs/2305.14540
- With the recent appearance of LLMs in practical settings, having methods that can effectively detect factual inconsistencies is crucial to reduce the propagation of misinformation and improve trust in model outputs. When testing on existing factual consistency benchmarks, we find that a few large language models (LLMs) perform competitively on classification benchmarks for factual inconsistency detection compared to traditional non-LLM methods. However, a closer analysis reveals that most LLMs fail on more complex formulations of the task and exposes issues with existing evaluation benchmarks, affecting evaluation precision. To address this, we propose a new protocol for inconsistency detection benchmark creation and implement it in a 10-domain benchmark called SummEdits. This new benchmark is 20 times more cost-effective per sample than previous benchmarks and highly reproducible, as we estimate inter-annotator agreement at about 0.9. Most LLMs struggle on SummEdits, with performance close to random chance. The best-performing model, GPT-4, is still 8\% below estimated human performance, highlighting the gaps in LLMs’ ability to reason about facts and detect inconsistencies when they occur.
Survey of Hallucination in Natural Language Generation
- https://arxiv.org/abs/2202.03629
- Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Yejin Bang, Delong Chen, Ho Shu Chan, Wenliang Dai, Andrea Madotto, Pascale Fung
- Natural Language Generation (NLG) has improved exponentially in recent years thanks to the development of sequence-to-sequence deep learning technologies such as Transformer-based language models. This advancement has led to more fluent and coherent NLG, leading to improved development in downstream tasks such as abstractive summarization, dialogue generation and data-to-text generation. However, it is also apparent that deep learning based generation is prone to hallucinate unintended text, which degrades the system performance and fails to meet user expectations in many real-world scenarios. To address this issue, many studies have been presented in measuring and mitigating hallucinated texts, but these have never been reviewed in a comprehensive manner before. In this survey, we thus provide a broad overview of the research progress and challenges in the hallucination problem in NLG. The survey is organized into two parts: (1) a general overview of metrics, mitigation methods, and future directions; (2) an overview of task-specific research progress on hallucinations in the following downstream tasks, namely abstractive summarization, dialogue generation, generative question answering, data-to-text generation, machine translation, and visual-language generation; and (3) hallucinations in large language models (LLMs). This survey serves to facilitate collaborative efforts among researchers in tackling the challenge of hallucinated texts in NLG.
Do Language Models Know When They’re Hallucinating References?
- https://arxiv.org/abs/2305.18248
Trustworthy LLMs: a Survey and Guideline for Evaluating Large Language Models’ Alignment
- https://arxiv.org/abs/2308.05374
Blog: LLM Hallucination
A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions
Brief introduction to LLM Hallucinations
-
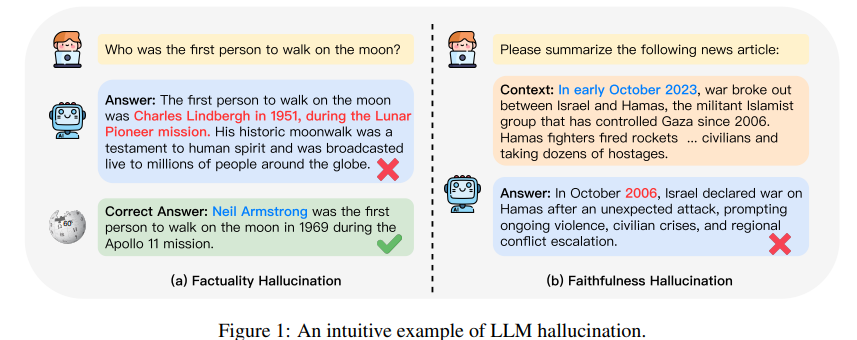
The current definition of hallucinations characterizes them as generated content that is nonsensical or unfaithful to the provided source content.
-
These hallucinations are further categorized into intrinsic hallucination and extrinsic hallucination types, depending on the contradiction with the source content.
-
In LLMs, the scope of hallucination encompasses a broader and more comprehensive concept, primarily centering on factual errors.
-
In light of the evolution of the LLM era, there arises a need to adjust the existing hallucination taxonomy, enhancing its applicability and adaptability.
Types of Hallucinations
- Factuality Hallucination: inconsistent with real-world facts or potentially misleading
- Factual Inconsistency: facts relate to real-world information, but has contradictions
- Factual Fabrication: unverifiable against established real-world knowledge

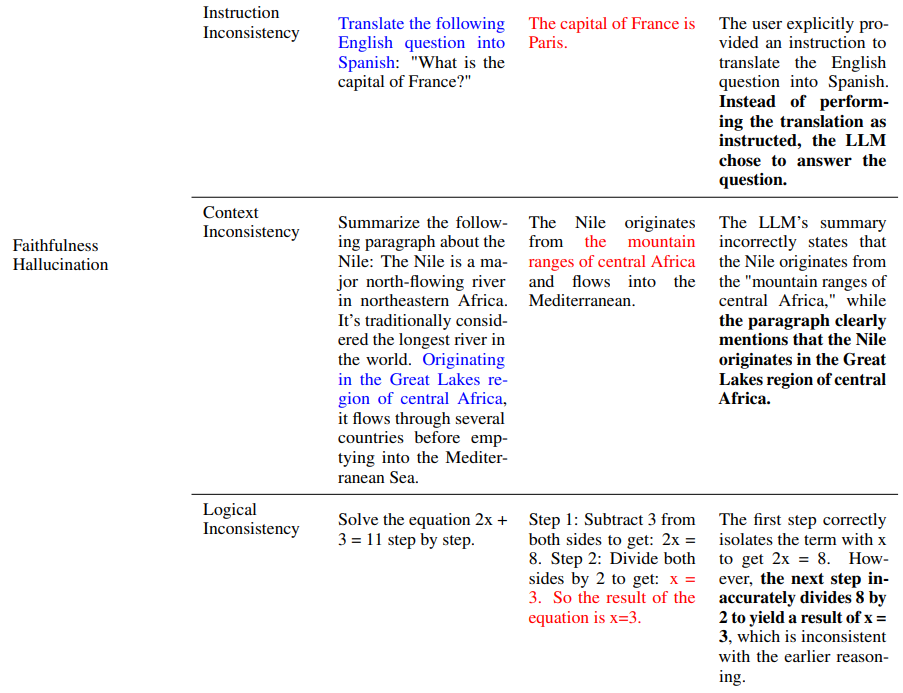
- Faithfulness Hallucination: inconsistency with user provided instructions and contextual information
- Instruction inconsistency: deviate from a user’s instructions
- Context inconsistency: unfaithful with the provided contextual information
- Logical inconsistency: exhibit internal logical contradictions
Hallucination Causes
-
Data
-
Training
-
Inference

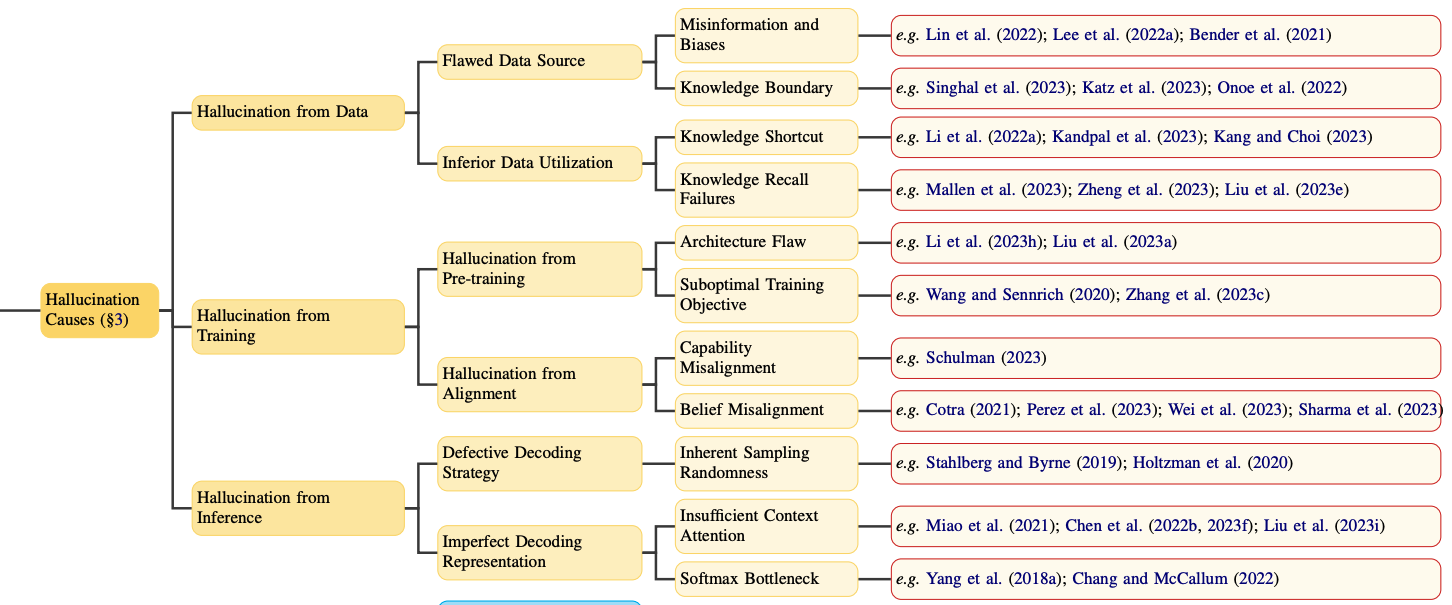
1.Hallucination from Data
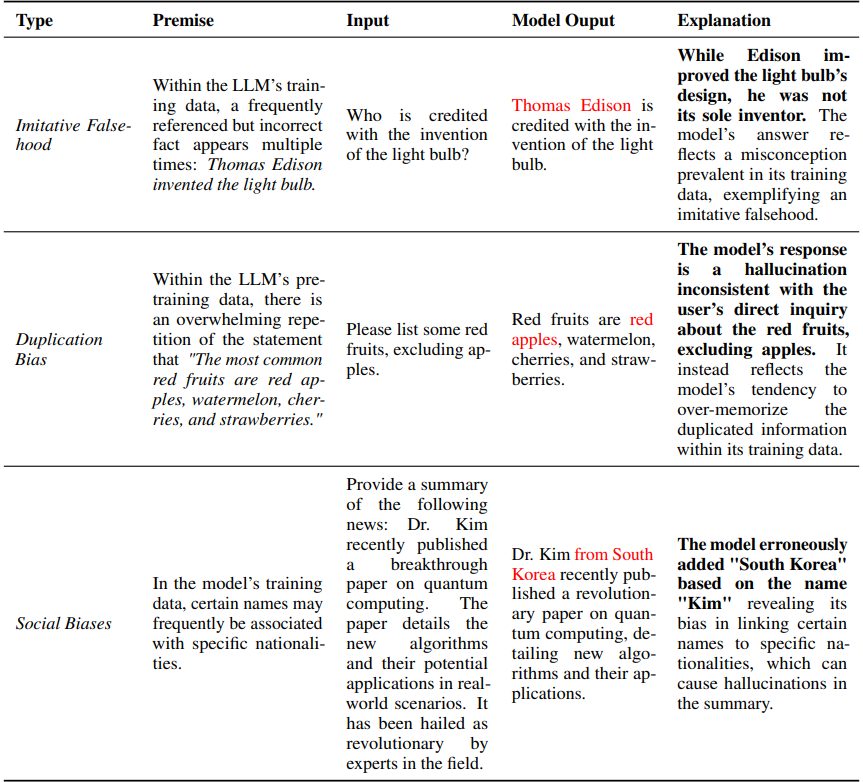
- Misinformation and Biases
- Imitative Falsehoods: trained on factual incorrect data
- Duplication Bias: over-prioritize the recall of duplicated data
- Social Biases: Gender, Race
- Knowledge Boundary
- Domain Knowledge Deficiency: Lack of proprietary data lead to less expertise
- Outdated Factual Knowledge
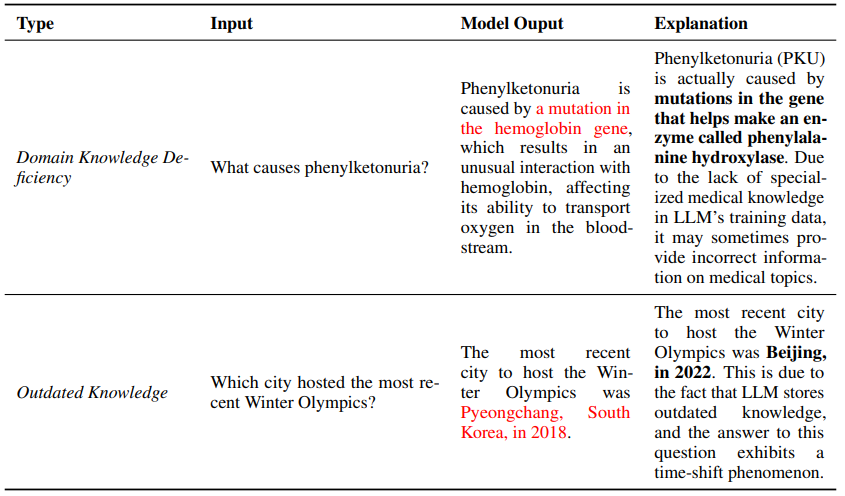
- Inferior Data Utilization
- Knowledge Shortcut: overly rely on co-occurrence statistics, relevant document count
- Knowledge Recall Failures
- Long-tail Knowledge: rare, specialized, or highly specific information not widely known or discussed.
- Complex Scenario: multi-hop reasoning and logical deduction
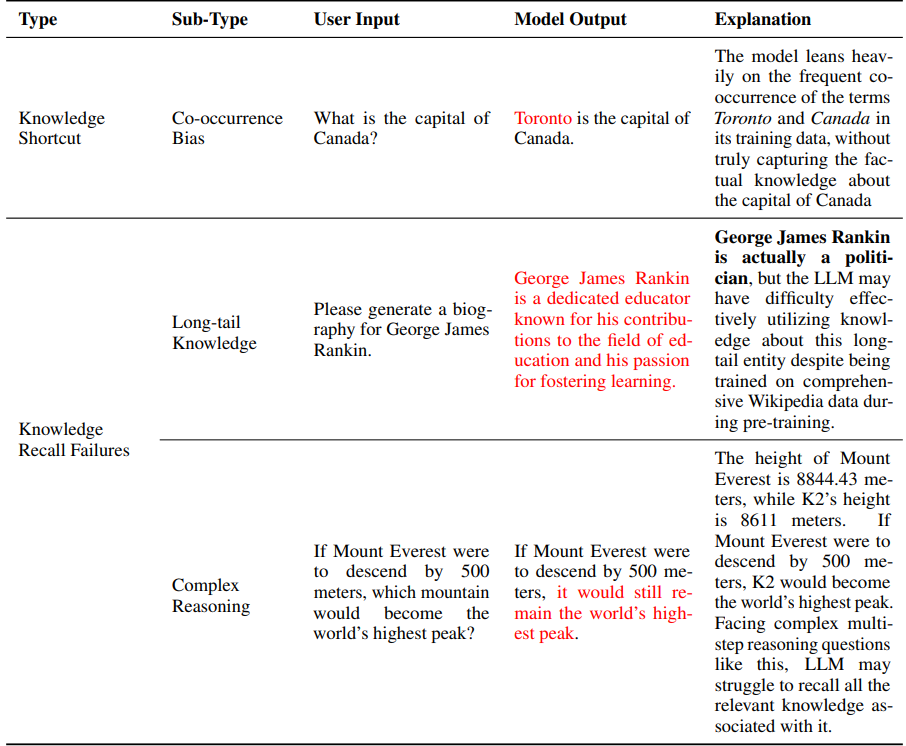
2.Hallucination from Training
- Hallucination from Pre-training
- Architecture Flaw
- Inadequate Unidirectional Representation: predict the subsequent token based solely on preceding tokens in a left-to-right manner
- Attention Glitches: limitations of soft attention
- attention diluted across positions as sequence length increases
- Exposure Bias: teacher forcing
- Hallucination from Alignment
- Capability Misalignment: mismatch between LLMs’ pre-trained capabilities and the expectations from fine-tuning data
- Belief Misalignment: prioritize appeasing perceived user preferences over truthfulness
3.Hallucination from Inference
- Inherent Sampling Randomness
- Stochastic Sampling: controlled randomness enhance creativity and diversity
- likelihood trap: high-probability, low-quality text
- Imperfect Decoding Representation
- Insufficient Context Attention: prioritize recent or nearby words in attention (Over-Confidence Issue)
- Softmax Bottleneck: inability manage multi-modal distributions, irrelevant or inaccurate content
Hallucination Detection and Benchmarks
As LLMs have garnered substantial attention in recent times, distinguishing accurate and hallucinated content has become a pivotal concern these days. Two primary facets encompass the broad spectrum of hallucination mitigation: detection mechanisms and evaluation benchmarks.
Traditional metrics fall short in differentiating the nuanced discrepancies between plausible and hallucinated content, which highlights the necessity of more sophisticated detection methods.
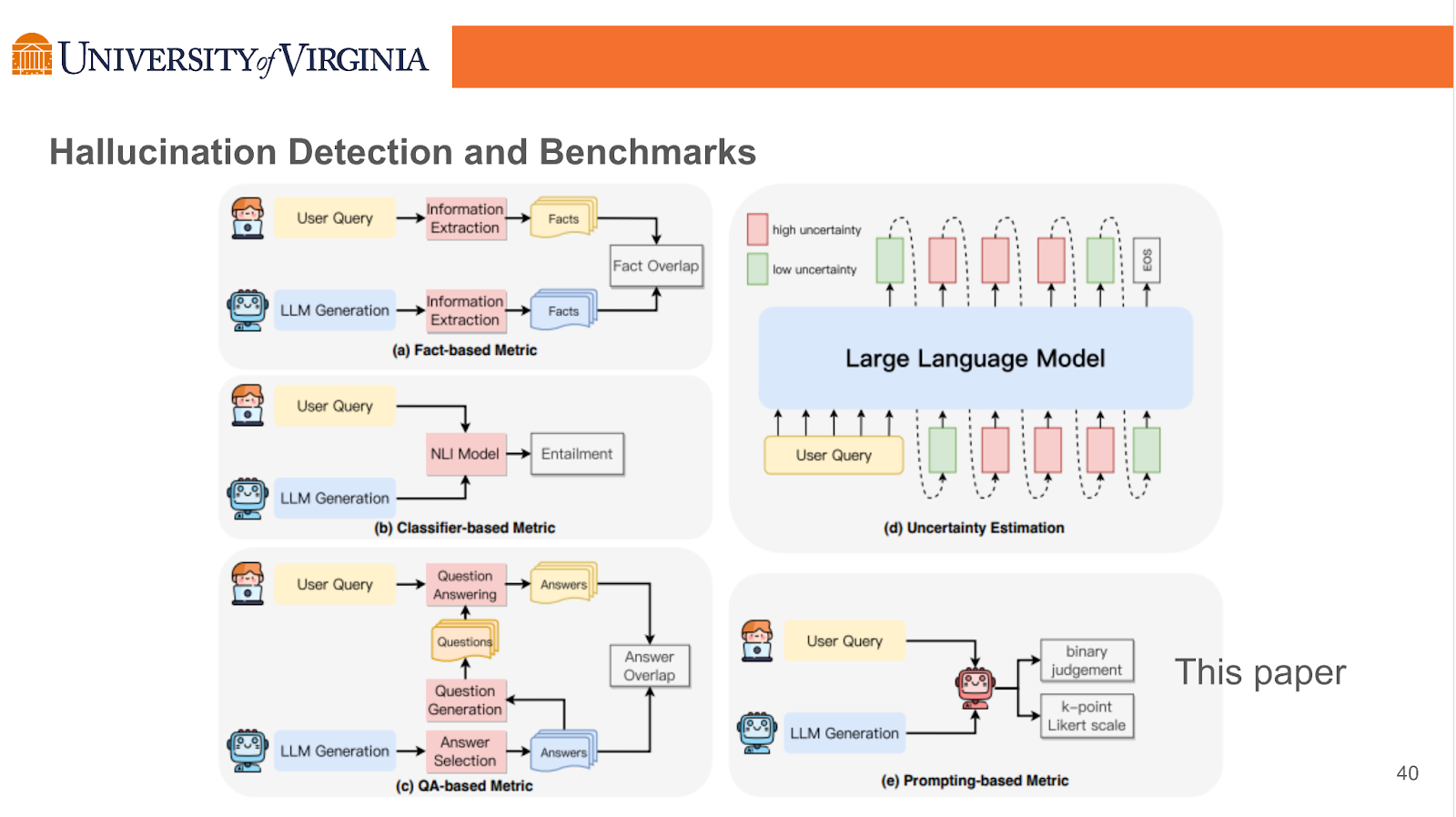
1. Factuality Hallucination Detection
- Retrieve External Facts
Comparing the model generated content against reliable knowledge sources. Here is an example of detecting factuality hallucination by retrieving external facts:

- Uncertainty Estimation
Premise: the origin of LLM hallucinations is inherently tied to the model’s uncertainty.
Zero-resource settings. Categorized into 2 approaches:
-
LLM Internal States: operates under the assumption that one can access the model’s internal state
-
LLM Behavior: leveraging solely the model’s observable behaviors to infer its underlying uncertainty
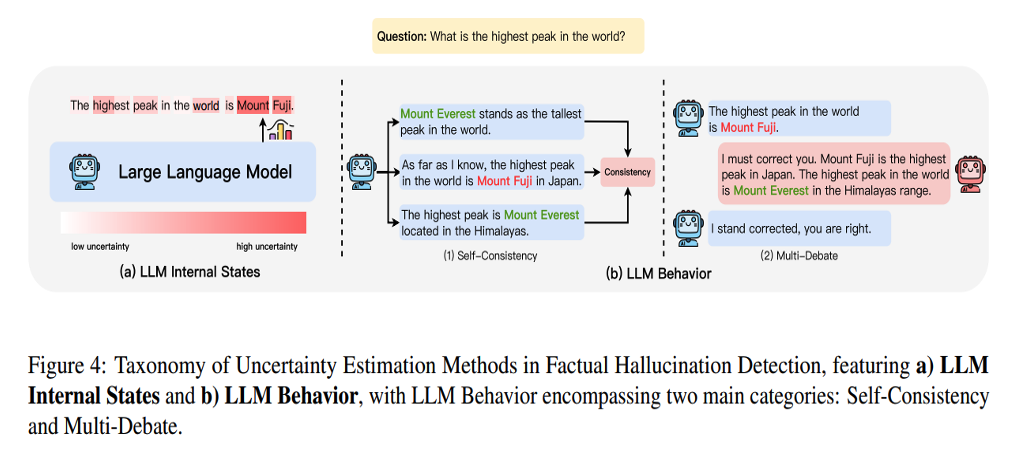
2. Faithfulness Hallucination Detection
Focuses on ensuring the alignment of the generated content with the given context, sidestepping the potential pitfalls of extraneous or contradictory output.
-
Fact-based Metrics: assesses faithfulness by measuring the overlap of facts between the generated content and the source content
-
Classifier-based Metrics: utilizing trained classifiers to distinguish the level of entailment between the generated content and the source content
-
Question-Answering based Metrics: employing question-answering systems to validate the consistency of information between the source content and the generated content
-
Uncertainty Estimation: assesses faithfulness by measuring the model’s confidence in its generated outputs
-
Prompting-based Metrics: induced to serve as evaluators, assessing the faithfulness of generated content through specific prompting strategies.
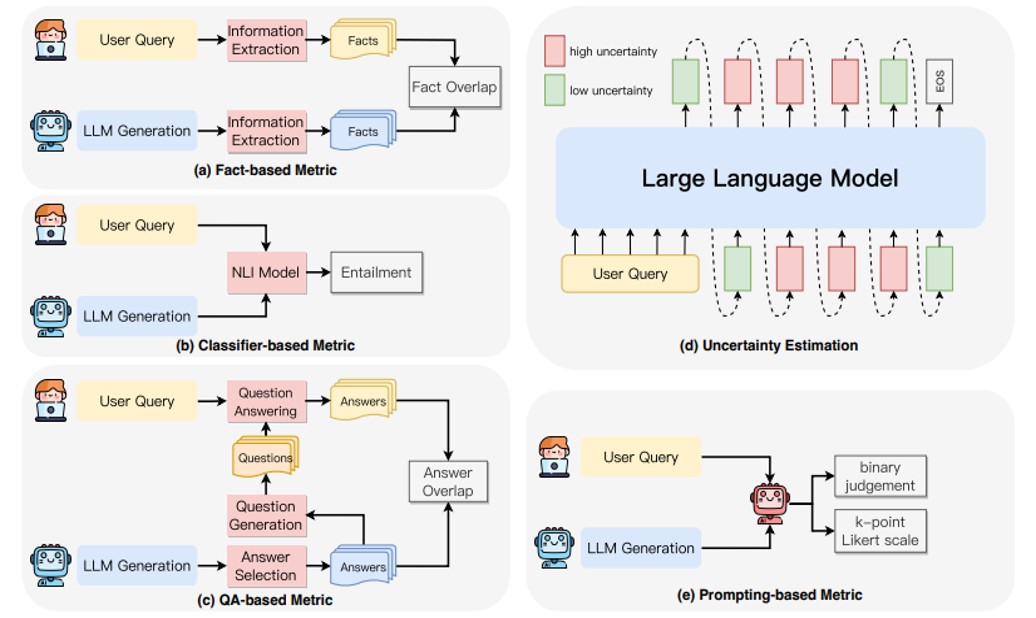
Figure 5: The illustration of detection methods for faithfulness hallucinations: a) Fact-based Metrics, which assesses faithfulness by measuring the overlap of facts between the generated content and the source content; b) Classifier-based Metrics, utilizing trained classifiers to distinguish the level of entailment between the generated content and the source content; c) QA-based Metrics, employing question-answering systems to validate the consistency of information between the source content and the generated content; d) Uncertainty Estimation, which assesses faithfulness by measuring the model’s confidence in its generated outputs; e) Prompting-based Metrics, wherein LLMs are induced to serve as evaluators, assessing the faithfulness of generated content through specific prompting strategies.
3. Benchmarks
- Hallucination Evaluation Benchmarks
Assess LLMs’ proclivity to produce hallucinations, with a particular emphasis on identifying factual inaccuracies and measuring deviations from original contexts
- Hallucination Detection Benchmarks
Evaluate the performance of existing hallucination detection methods.
Primarily concentrated on task specific hallucinations, such as abstractive summarization, data-to-text, and machine translation.

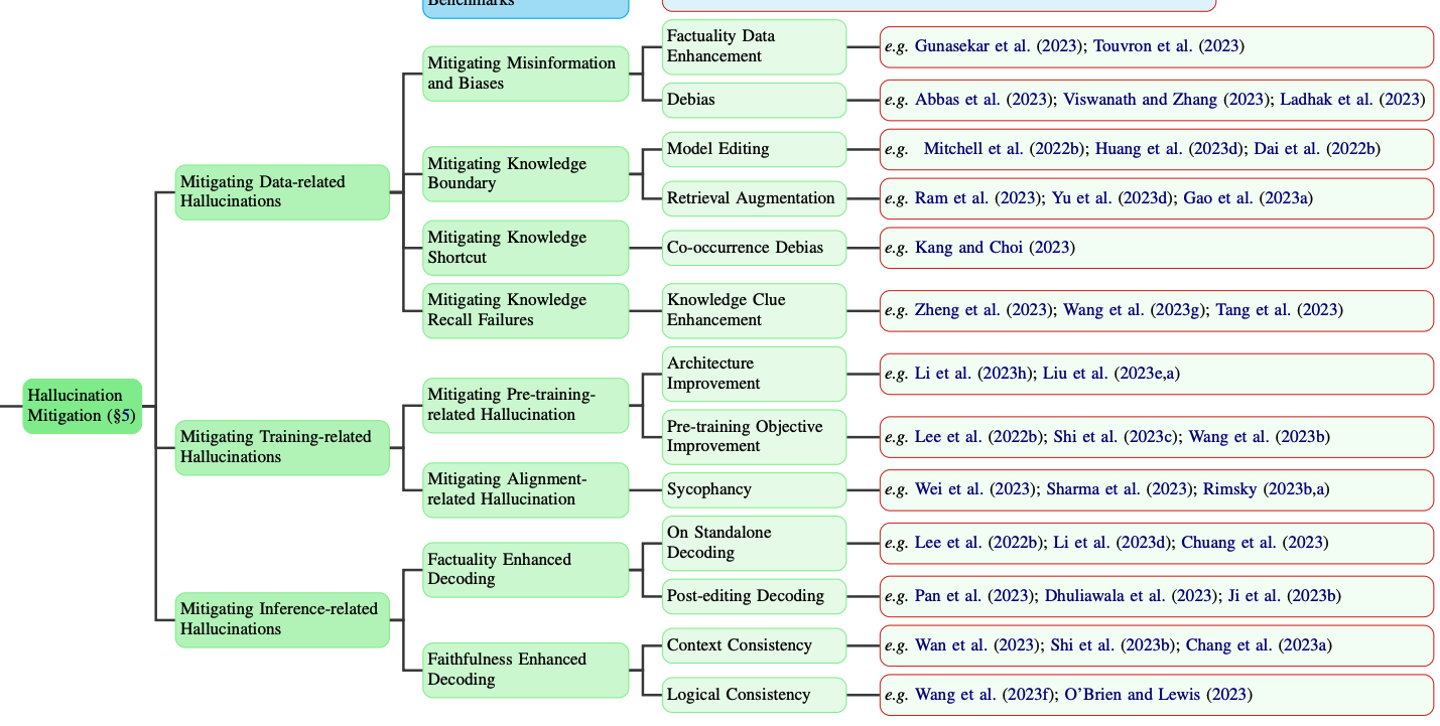
Mitigation Strategies
4. Mitigating Data-related Hallucinations
- Mitigating Misinformation and Biases:
- Factuality Data Enhancement: Gathering high-quality data, Up-sampling factual data during the pre-training
- Duplication Bias: Exact Duplicates, Near-Duplicates
- Societal Biases: Focusing on curated, diverse, balanced, and representative training corpora
- Mitigating Knowledge Boundary:
- Knowledge Editing: Modifying Model Parameter(Locate-then-edit methods, Meta-learning methods), Preserving Model Parameters
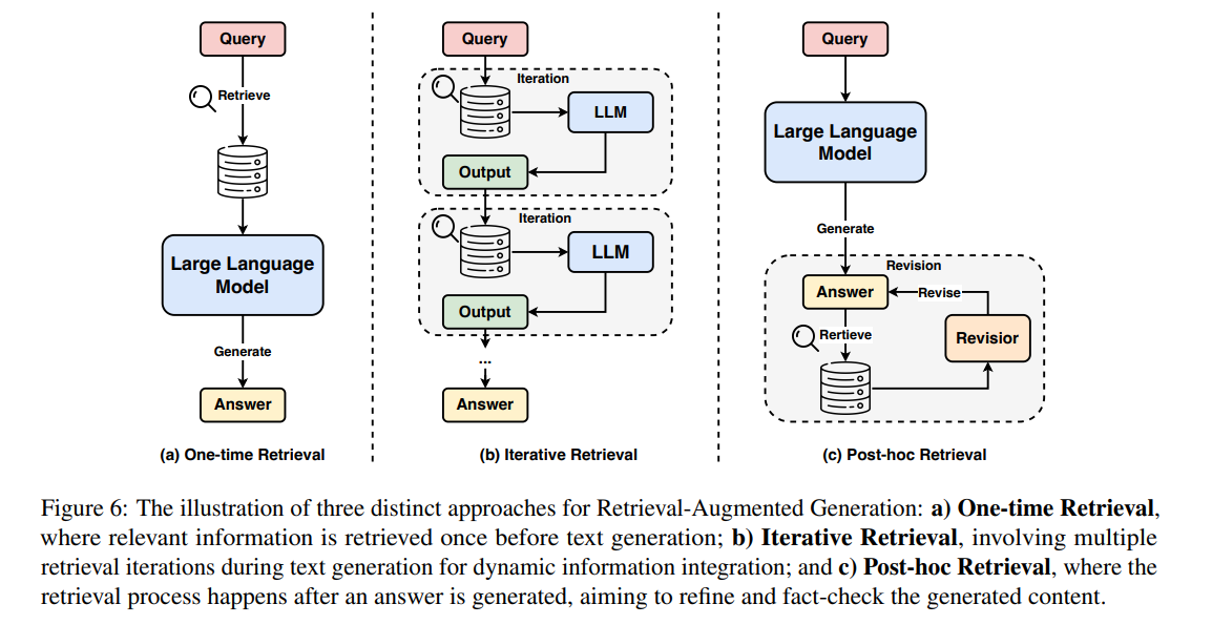
- Retrieval Augmentation: One-time Retrieval, Iterative Retrieval, Post-hoc Retrieval
- Mitigating Knowledge Shortcut:
- **Fine-tuning on a debiased dataset by excluding biased samples
- Mitigating Knowledge Recall Failures:
- Adding relevant information to questions to aid recall, Encourages LLMs to reason through steps to improve recall
Mitigating Data-related Hallucinations
5. Mitigating Training-related Hallucination
Mitigating Pretraining-related Hallucination
The majority of research emphasizes the exploration of novel model architectures and the improvement of pre-training objectives
- Mitigating Flawed Model Architecture:
- Mitigating Unidirectional Representation: BATGPT introduces a bidirectional autoregressive approach, enhancing context comprehension by considering both past and future contexts
- Mitigating Attention Glitches: Attention-sharpening regularizers promote sparsity in self-attention, reducing reasoning errors
- Mitigating Suboptimal Pre-training Objective:
- Training Objective: Incorporation of factual contexts as TOPIC PREFIX to ensure accurate entity associations and reduce factual errors
- Exposure Bias: Techniques like intermediate sequence supervision and Minimum Bayes Risk decoding reduce error accumulation and domain-shift hallucinations
Mitigating Misalignment Hallucination
-
Improving Human Preference Judgments: Enhancing the quality of human-annotated data and preference models to reduce the propensity for reward hacking and sycophantic responses
-
Modifying LLMs’ Internal Activations: Fine-Tuning with Synthetic Data by training LLMs on data with truth claims independent of user opinions to curb sycophantic tendencies
Mitigating Inference-related Hallucination
Factuality Enhanced Decoding
- On Standalone Decoding:
- Factual-Nucleus Sampling: Adjusts nucleus probability dynamically for a balance between factual accuracy and output diversity.
- Inference-Time Intervention (ITI): Utilizes activation space directionality for factually correct statements, steering LLMs towards accuracy during inference.
- Post-editing Decoding:
- Chain-of-Verification (COVE): Employs self-correction capabilities to refine generated content through a systematic verification and revision process
Faithfulness Enhanced Decoding
- Context Consistency:
- Context-Aware Decoding (CAD): Adjusting output distribution to enhance focus on contextual information, balancing between diversity and attribution
- Logical Consistency:
- Knowledge Distillation and Contrastive Decoding: Generating consistent rationale and fine-tuning with counterfactual reasoning to eliminate reasoning shortcuts, ensuring logical progression in multi-step reasoning
Challenges and Open Questions
Challenges in LLM Hallucination
- Hallucination in Long-form Text Generation
Absence of manually annotated hallucination benchmarks in the domain of long-form text generation
- Hallucination in Retrieval Augmented Generation
Irrelevant evidence can be propagated into the generation phase, possibly tainting the output
- Hallucination in Large Vision-Language Models
LVLMs sometimes mix or miss parts of the visual context, as well as fail to understand temporal or logical connections between them
Open Questions in LLM Hallucination
- Can Self-Correct Mechanisms Help in Mitigating Reasoning Hallucinations?
Occasionally exhibit unfaithful reasoning characterized by inconsistencies within the reasoning steps or conclusions that do not logically follow the reasoning chain.
- Can We Accurately Capture LLM Knowledge Boundaries?
LLMs still face challenges in recognizing their own knowledge boundaries. This shortfall leads to the occurrence of hallucinations, where LLMs confidently produce falsehoods without an awareness of their own knowledge limits.
- How Can We Strike a Balance between Creativity and Factuality?
Hallucinations can sometimes offer valuable perspectives, particularly in creative endeavors such as storytelling, brainstorming, and generating solutions that transcend conventional thinking.
LLMs as Factual Reasoners: Insights from Existing Benchmarks and Beyond

LLMs are used to summarize documents across different domains. The summarizations must be accurate and factual. 
LLMs have some issues as factual reasoners.
-
Not all LLMs can generate explanations that locate factual inaccuracies
-
Many mislabeled samples of factual inconsistencies are undetected by annotators.
Laban et. al discusses LLMs as factual reasoners, propose a new protocol for creating inconsistency detection benchmarks, and release SummEdits, which applies their protocol across 10 domains. 
 Laban et. al test different LLMs on the FactCC dataset to find which LLMs are potentially factual reasoners.
Laban et. al test different LLMs on the FactCC dataset to find which LLMs are potentially factual reasoners. 
In-context learning and prompt engineering can optimize the desired output of LLMs.
The authors the factual accuracy of many LLMs and non-LLM models.
Their experiment yields a few interesting findings for the binary classification test:
-
non-LLM outperforms the LLM.
-
Few-shot will improve performance compared to zero-shot (not GPT4 and PaLM2).
-
Generate-with-Evidence outperforms Chain-of-Thought.
-
Persona-based improves GPT3.5-turbo performance.

They also found that the models are mostly accurate when detecting positive samples, but are very bad at detecting factual inconsistencies, particularly pronoun swaps.
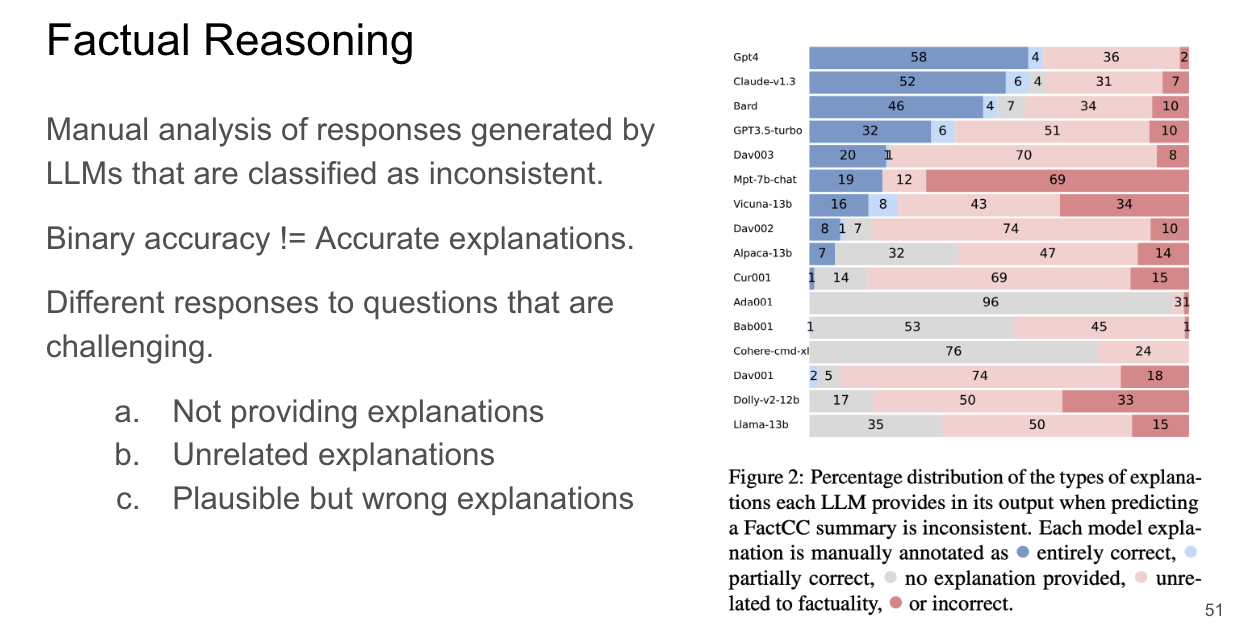 Through manual analysis of the LLM outputs, they found that response explanations for challenging questions were either not given, irrelevant, or plausible but wrong.
Through manual analysis of the LLM outputs, they found that response explanations for challenging questions were either not given, irrelevant, or plausible but wrong.

The authors also conducted a fine-grain analysis to evaluate each document sentence pair concerning individual error types while ignoring other types of errors. They recorded low precision but a high recall score, and they were not able to distinguish error types.
The authors also discuss the limitations of existing AggreFact and DialSumEval crowd-sourced benchmarks. The authors filtered out all models that did not achieve a balanced accuracy above 60% on FactCC and used a single Zero-Shot (ZS) prompt for all LLM models on these benchmarks.

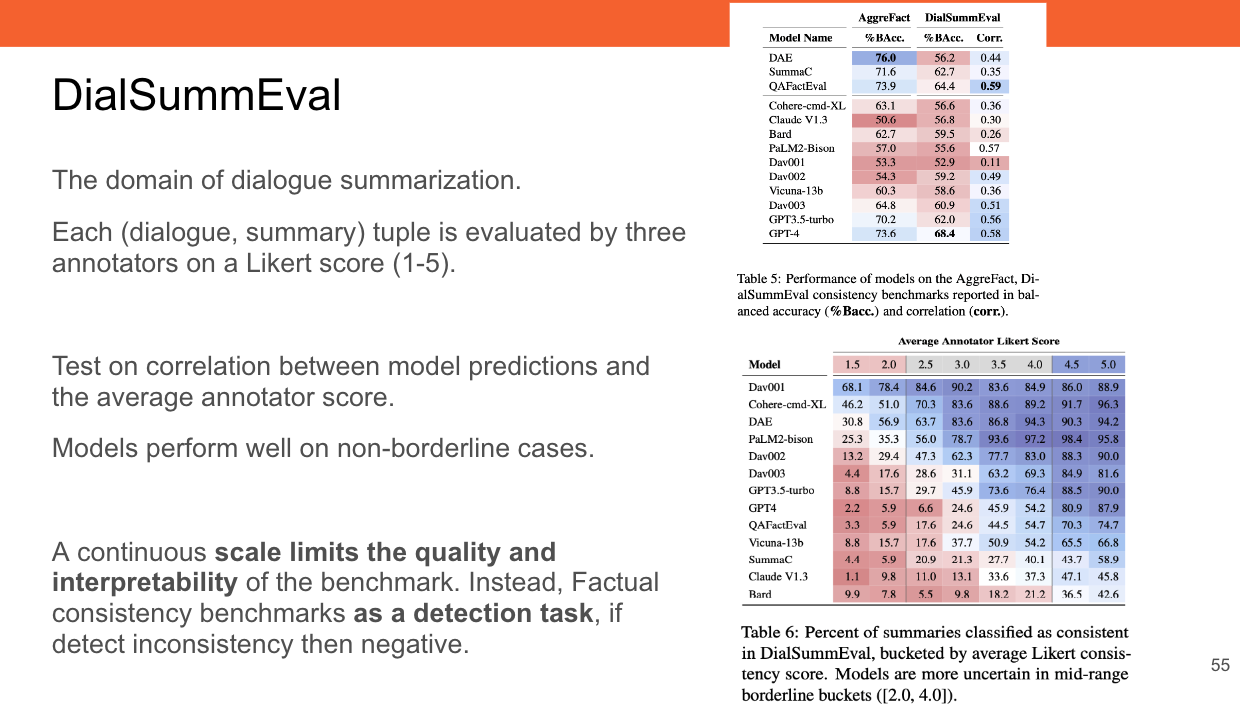
The authors conclude there is low reliability for these crowd-sourced benchmarks. Further, the scale of these benchmarks limits their quality and interpretability.
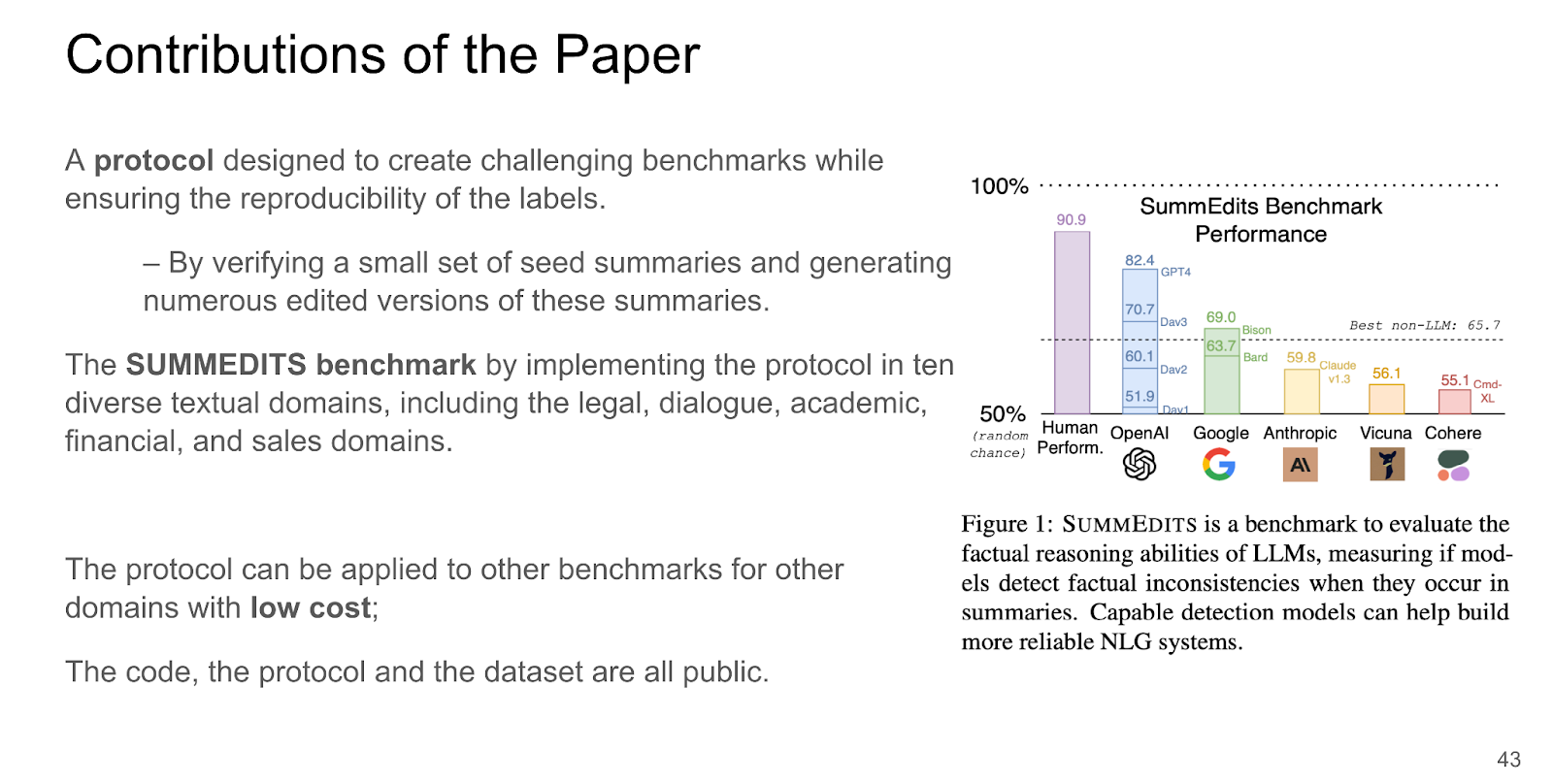
The authors propose a new protocol for inconsistency detection benchmark creation and implement it in a 10-domain benchmark called SummEdits. This new benchmark is 20 times more cost-effective per sample than previous benchmarks and highly reproducible, as they estimate inter-annotator agreement at about 0.9.
Based on the analysis of previous benchmarks, the authors set several design principles that can help create higher quality factual consistency benchmark:
-
P1: Binary Classification Task: summary is either consistent or inconsistent
-
P2: Focus on Factual Consistency: summary is flawless on attributes unrelated to consistency
-
P3: Reproducibility: labels should be independent of annotator
-
P4: Benchmark Diversity: inconsistencies should represent a wide range of errors in real textual domains
They introduce a protocol designed to create challenging benchmarks while ensuring the reproducibility of the labels. The protocol involves manually verifying the consistency of a small set of seed summaries and subsequently generating numerous edited versions of these summaries.

More details are shown as follows

The procedure is visualized below
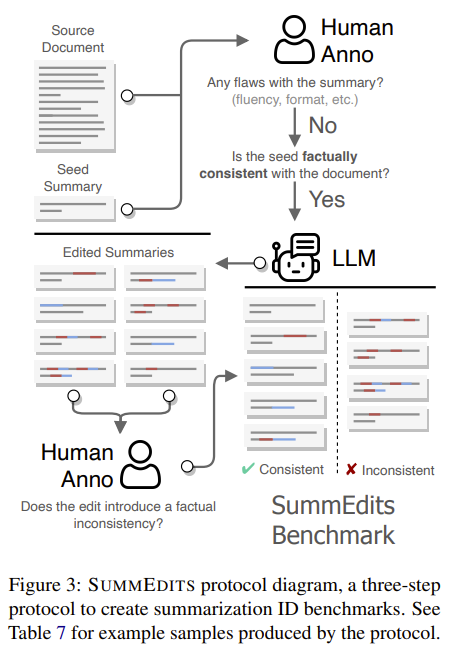
Some example samples produced by the protocol are presented as follows

The SummEdits benchmark was created by implementing the protocol in ten diverse textual domains, including the legal, dialogue, academic, financial, and sales domains. Specifically, it contains:
-
News: Articles and summaries from Google News top events from February 2023
-
Podcasts: 40 transcripts from Spotify dataset, automatic summaries
-
BillSum: 40 US bills and their summaries
-
SamSum: 40 dialogues and their summaries from a dialogue summarization dataset
-
Shakespeare: 40 scenes, automatic summaries
-
SciTLDR: 40 research paper abstracts and their summaries
-
QMSum: 40 documents and summaries from query-based meeting summarization dataset
-
ECTSum: 40 documents from financial earnings call dataset, automatic summaries
-
Sales Call & Email: 40 fictional sales calls & emails generated along with summaries
For the statistics of SummEdits, the authors report that
-
At least 20% of each domain’s samples were annotated by multiple annotators
-
Cohen’s Kappa varied between 0.72-0.90 for the domains when considering the three labels, averaging 0.82
- After removing ‘borderline’ samples, average Kappa rose to 0.92 -> high agreement
- Total cost: $3,000 for 150 hours of annotator work
- Average domain cost is $300
- Using processes of other benchmarks would have had a 20x increase in cost
- If each sample required 30 min of annotator time, as in the FRANK benchmark
The following table reports the average performance of specialized models, LLMs with a zero-shot prompt, an oracle version for the LLM in which it has access to additional information and an estimate of human performance computed on the subset of the benchmark which was plurally annotated.
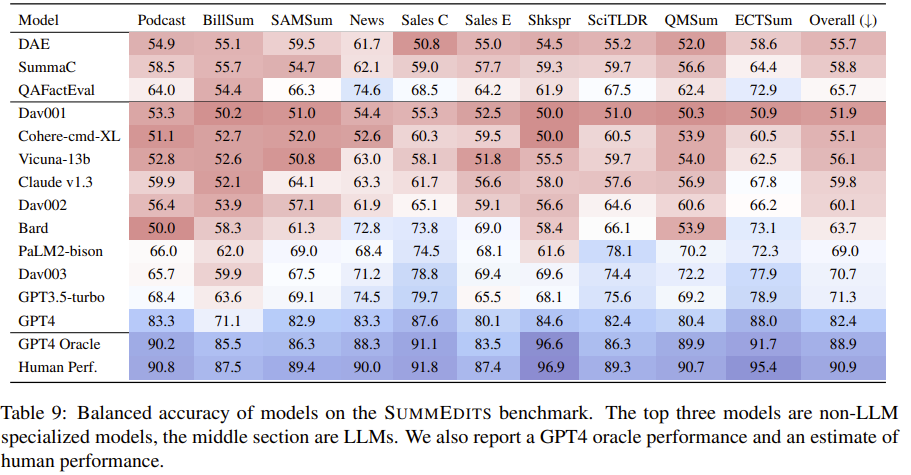
From the table, we can see that
-
Low performance overall - only GPT-4 comes within 10% of human performance
-
Only 4 LLMs outperform non-LLM QAFactEval - most LLMs are not capable of reasoning about the consistency of facts out-of-the-box
-
Specialized models performed best on News, probably because it was similar to their training data
-
BillSum and Shakespeare are particularly challenging
-
Oracle test: model is given document, seed, and edited summary
- Large boost in performance, within 2% of human performance
- Shows that high performance is indeed attainable
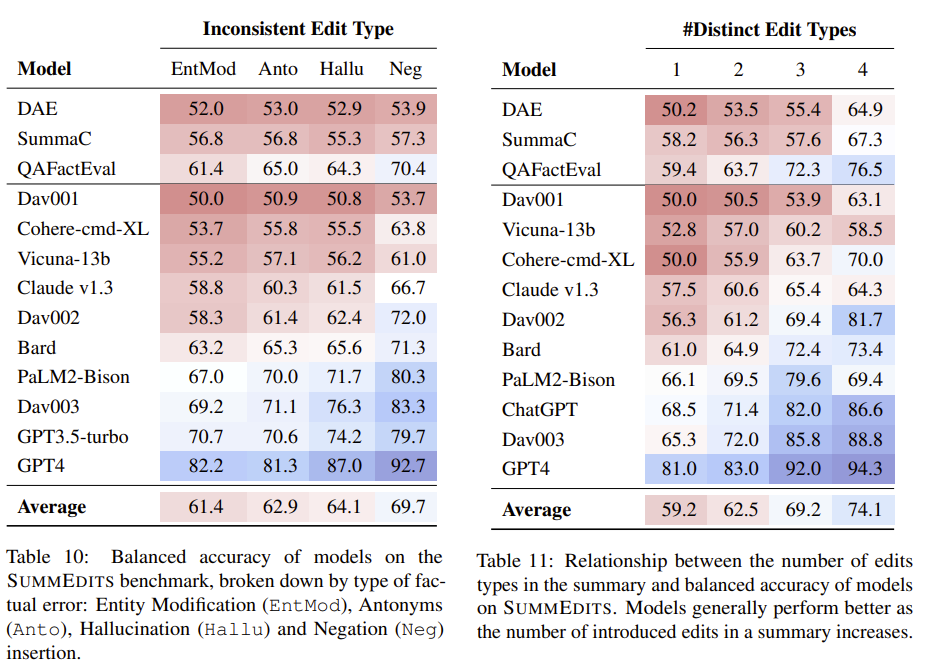
To gain more specific insights into the types of edits present in SUMMEDITS, the authors annotated each inconsistent sample in the benchmark with tags of edit types that lead to factual inconsistency, including the following four edit types:
-
Entity modification
-
Antonym Swap
-
Hallucinated Fact Insertion
-
Negation Insertion
- SummEdits distribution: 78% of inconsistent summaries contain entity modification, 48% antonym swap, 22% hallucinated fact insertion, 18% negation insertion
- Distribution influenced by the LLM used to produce the edits
Table 10 presents model performance across each of the edit types. Additionally, the authors grouped inconsistent summaries by the number of distinct edit types they contain (1 to 4) and computed model performance on each group, with results summarized in Table 11.
In conclusion, the authors of this paper
-
simplified annotation process for improved reproducibility
-
created SummEdits benchmark which spans 10 domains
- Highly reproducible and more cost-effective than previous benchmarks
- Challenging for most current LLMs
- A valuable tool for evaluating LLMs’ ability to reason about facts and detect factual errors
- encouraged LLM developers to report their performance on the benchmark
Survey of Hallucination in Natural Language Generation
Link: https://arxiv.org/abs/2202.03629
Following previous works, the authors categorize different hallucinations into two main types, namely intrinsic hallucination and extrinsic hallucination:

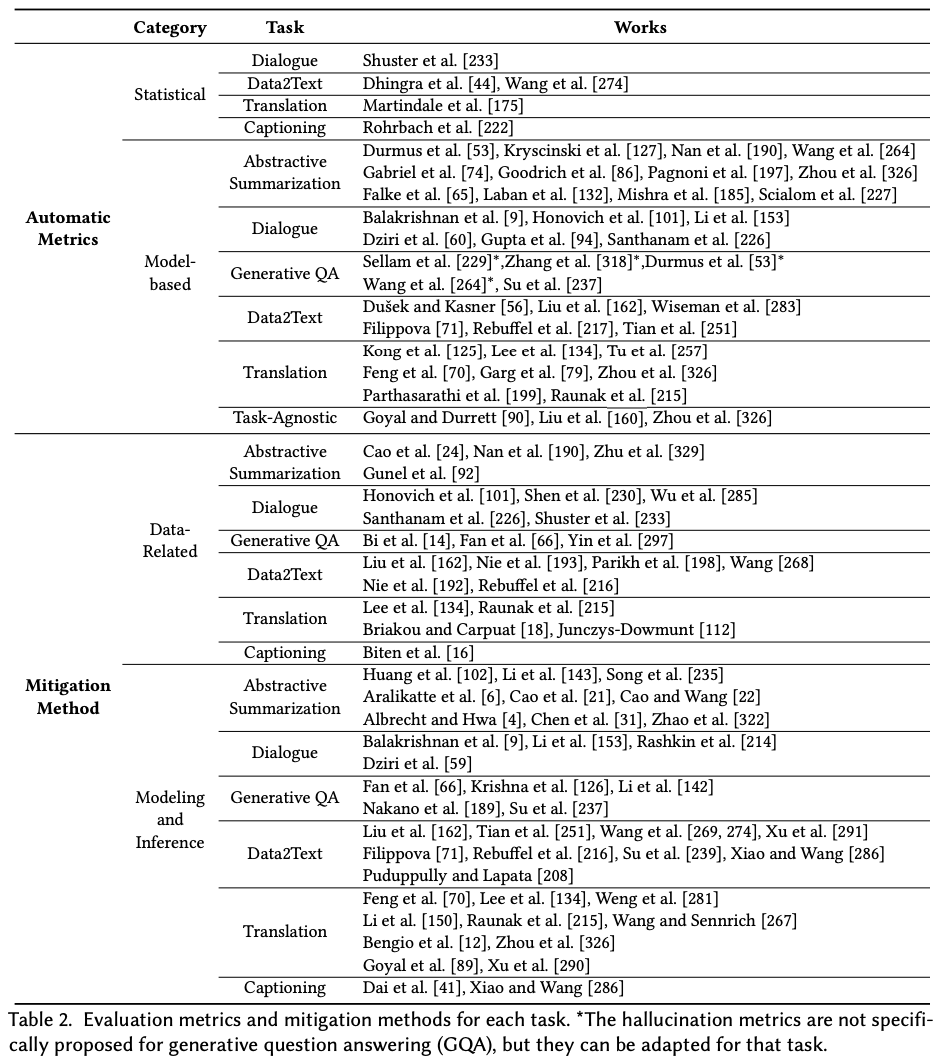
The authors of this paper present a general overview of evaluation metrics and mitigation methods for different NLG task, which is summarized here:
References
- Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., … & Liu, T. (2023). A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. arXiv preprint arXiv:2311.05232.
- Laban, P., Kryściński, W., Agarwal, D., Fabbri, A. R., Xiong, C., Joty, S., & Wu, C. S. (2023). Llms as factual reasoners: Insights from existing benchmarks and beyond. arXiv preprint arXiv:2305.14540.
- Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., … & Fung, P. (2023). Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12), 1-38.