Domain Centered FMs
- SlideDeck: W9-T2-domain-LLM
- Version: current
- Lead team: team-2
- Blog team: team-2
In this session, our readings cover:
Required Readings:
Large Language Models for Software Engineering: A Systematic Literature Review
- Large Language Models (LLMs) have significantly impacted numerous domains, including Software Engineering (SE). Many recent publications have explored LLMs applied to various SE tasks. Nevertheless, a comprehensive understanding of the application, effects, and possible limitations of LLMs on SE is still in its early stages. To bridge this gap, we conducted a systematic literature review on LLM4SE, with a particular focus on understanding how LLMs can be exploited to optimize processes and outcomes. We collect and analyze 229 research papers from 2017 to 2023 to answer four key research questions (RQs). In RQ1, we categorize different LLMs that have been employed in SE tasks, characterizing their distinctive features and uses. In RQ2, we analyze the methods used in data collection, preprocessing, and application highlighting the role of well-curated datasets for successful LLM for SE implementation. RQ3 investigates the strategies employed to optimize and evaluate the performance of LLMs in SE. Finally, RQ4 examines the specific SE tasks where LLMs have shown success to date, illustrating their practical contributions to the field. From the answers to these RQs, we discuss the current state-of-the-art and trends, identifying gaps in existing research, and flagging promising areas for future study.
More Readings:
Large language models generate functional protein sequences across diverse families
- https://pubmed.ncbi.nlm.nih.gov/36702895/
- Deep-learning language models have shown promise in various biotechnological applications, including protein design and engineering. Here we describe ProGen, a language model that can generate protein sequences with a predictable function across large protein families, akin to generating grammatically and semantically correct natural language sentences on diverse topics. The model was trained on 280 million protein sequences from >19,000 families and is augmented with control tags specifying protein properties. ProGen can be further fine-tuned to curated sequences and tags to improve controllable generation performance of proteins from families with sufficient homologous samples. Artificial proteins fine-tuned to five distinct lysozyme families showed similar catalytic efficiencies as natural lysozymes, with sequence identity to natural proteins as low as 31.4%. ProGen is readily adapted to diverse protein families, as we demonstrate with chorismate mutase and malate dehydrogenase.
Large Language Models in Law: A Survey
- https://arxiv.org/abs/2312.03718
- The advent of artificial intelligence (AI) has significantly impacted the traditional judicial industry. Moreover, recently, with the development of AI-generated content (AIGC), AI and law have found applications in various domains, including image recognition, automatic text generation, and interactive chat. With the rapid emergence and growing popularity of large models, it is evident that AI will drive transformation in the traditional judicial industry. However, the application of legal large language models (LLMs) is still in its nascent stage. Several challenges need to be addressed. In this paper, we aim to provide a comprehensive survey of legal LLMs. We not only conduct an extensive survey of LLMs, but also expose their applications in the judicial system. We first provide an overview of AI technologies in the legal field and showcase the recent research in LLMs. Then, we discuss the practical implementation presented by legal LLMs, such as providing legal advice to users and assisting judges during trials. In addition, we explore the limitations of legal LLMs, including data, algorithms, and judicial practice. Finally, we summarize practical recommendations and propose future development directions to address these challenges.
ChemLLM: A Chemical Large Language Model
- https://arxiv.org/abs/2402.06852
- Large language models (LLMs) have made impressive progress in chemistry applications, including molecular property prediction, molecular generation, experimental protocol design, etc. However, the community lacks a dialogue-based model specifically designed for chemistry. The challenge arises from the fact that most chemical data and scientific knowledge are primarily stored in structured databases, and the direct use of these structured data compromises the model’s ability to maintain coherent dialogue. To tackle this issue, we develop a novel template-based instruction construction method that transforms structured knowledge into plain dialogue, making it suitable for language model traini…
FunSearch: Making new discoveries in mathematical sciences using Large Language Models
- https://deepmind.google/discover/blog/funsearch-making-new-discoveries-in-mathematical-sciences-using-large-language-models/
Transforming the future of music creation
- https://deepmind.google/discover/blog/transforming-the-future-of-music-creation/
Segment Anything
- https://arxiv.org/abs/2304.02643
- We introduce the Segment Anything (SA) project: a new task, model, and dataset for image segmentation. Using our efficient model in a data collection loop, we built the largest segmentation dataset to date (by far), with over 1 billion masks on 11M licensed and privacy respecting images. The model is designed and trained to be promptable, so it can transfer zero-shot to new image distributions and tasks. We evaluate its capabilities on numerous tasks and find that its zero-shot performance is impressive – often competitive with or even superior to prior fully supervised results. We are releasing the Segment Anything Model (SAM) and corresponding dataset (SA-1B) of 1B masks and 11M images at this https URL to foster research into foundation models for computer vision.
EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions
- In this work, we tackle the challenge of enhancing the realism and expressiveness in talking head video generation by focusing on the dynamic and nuanced relationship between audio cues and facial movements. We identify the limitations of traditional techniques that often fail to capture the full spectrum of human expressions and the uniqueness of individual facial styles. To address these issues, we propose EMO, a novel framework that utilizes a direct audio-to-video synthesis approach, bypassing the need for intermediate 3D models or facial landmarks. Our method ensures seamless frame transitions and consistent identity preservation throughout the video, resulting in highly expressive and lifelike animations. Experimental results demonsrate that EMO is able to produce not only convincing speaking videos but also singing videos in various styles, significantly outperforming existing state-of-the-art methodologies in terms of expressiveness and realism.
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
- Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Huang, Hanchi Sun, Jianfeng Gao, Lifang He, Lichao Sun
- Sora is a text-to-video generative AI model, released by OpenAI in February 2024. The model is trained to generate videos of realistic or imaginative scenes from text instructions and show potential in simulating the physical world. Based on public technical reports and reverse engineering, this paper presents a comprehensive review of the model’s background, related technologies, applications, remaining challenges, and future directions of text-to-video AI models. We first trace Sora’s development and investigate the underlying technologies used to build this “world simulator”. Then, we describe in detail the applications and potential impact of Sora in multiple industries ranging from film-making and education to marketing. We discuss the main challenges and limitations that need to be addressed to widely deploy Sora, such as ensuring safe and unbiased video generation. Lastly, we discuss the future development of Sora and video generation models in general, and how advancements in the field could enable new ways of human-AI interaction, boosting productivity and creativity of video generation.
BloombergGPT: A Large Language Model for Finance
- https://arxiv.org/abs/2303.17564
- The use of NLP in the realm of financial technology is broad and complex, with applications ranging from sentiment analysis and named entity recognition to question answering. Large Language Models (LLMs) have been shown to be effective on a variety of tasks; however, no LLM specialized for the financial domain has been reported in literature. In this work, we present BloombergGPT, a 50 billion parameter language model that is trained on a wide range of financial data. We construct a 363 billion token dataset based on Bloomberg’s extensive data sources, perhaps the largest domain-specific dataset yet, augmented with 345 billion tokens from general purpose datasets. We validate BloombergGPT on standard LLM benchmarks, open financial benchmarks, and a suite of internal benchmarks that most accurately reflect our intended usage. Our mixed dataset training leads to a model that outperforms existing models on financial tasks by significant margins without sacrificing performance on general LLM benchmarks. Additionally, we explain our modeling choices, training process, and evaluation methodology. We release Training Chronicles (Appendix C) detailing our experience in training BloombergGPT.
Emu Video: Factorizing Text-to-Video Generation by Explicit Image Conditioning
- https://arxiv.org/abs/2311.10709
- We present Emu Video, a text-to-video generation model that factorizes the generation into two steps: first generating an image conditioned on the text, and then generating a video conditioned on the text and the generated image. We identify critical design decisions–adjusted noise schedules for diffusion, and multi-stage training–that enable us to directly generate high quality and high resolution videos, without requiring a deep cascade of models as in prior work. In human evaluations, our generated videos are strongly preferred in quality compared to all prior work–81% vs. Google’s Imagen Video, 90% vs. Nvidia’s PYOCO, and 96% vs. Meta’s Make-A-Video. Our model outperforms commercial solutions such as RunwayML’s Gen2 and Pika Labs. Finally, our factorizing approach naturally lends itself to animating images based on a user’s text prompt, where our generations are preferred 96% over prior work.
Blog: In this session, our blog covers:
Large Language Models for Software Engineering: A Systematic Literature Review
1 Overview
1.1 Software Engineering
- SE is a discipline focused on the development, implementation, and maintenance of software systems.
- The utilization of LLMs in SE emerges from the perspective where numerous SE challenges can be effectively reframed into data, code, or text analysis tasks.
1.2 Main Contributions
- It covers 229 papers published between 2017 and 2023.
- It summarizes usage and trends of different LLM categories within the SE domain.
- It describes the data processing stages.
- It discusses optimizers and evaluationg metrics used.
- It analyzes key applications of LLMs in SE encompassing a diverse range of 55 specific SE tasks, grouped into six core SE activities.
- It presents key challenges and potential research directions.
2 What LLMs have been employed?
2.1 Models Distribution
- There are more than 50 different LLMs used for SE tasks in the papers collected.
- They are grouped into 3 categories based on their underlying architecture, i.e., encoder-only, encoder-decoder, and decoder-only LLMs.
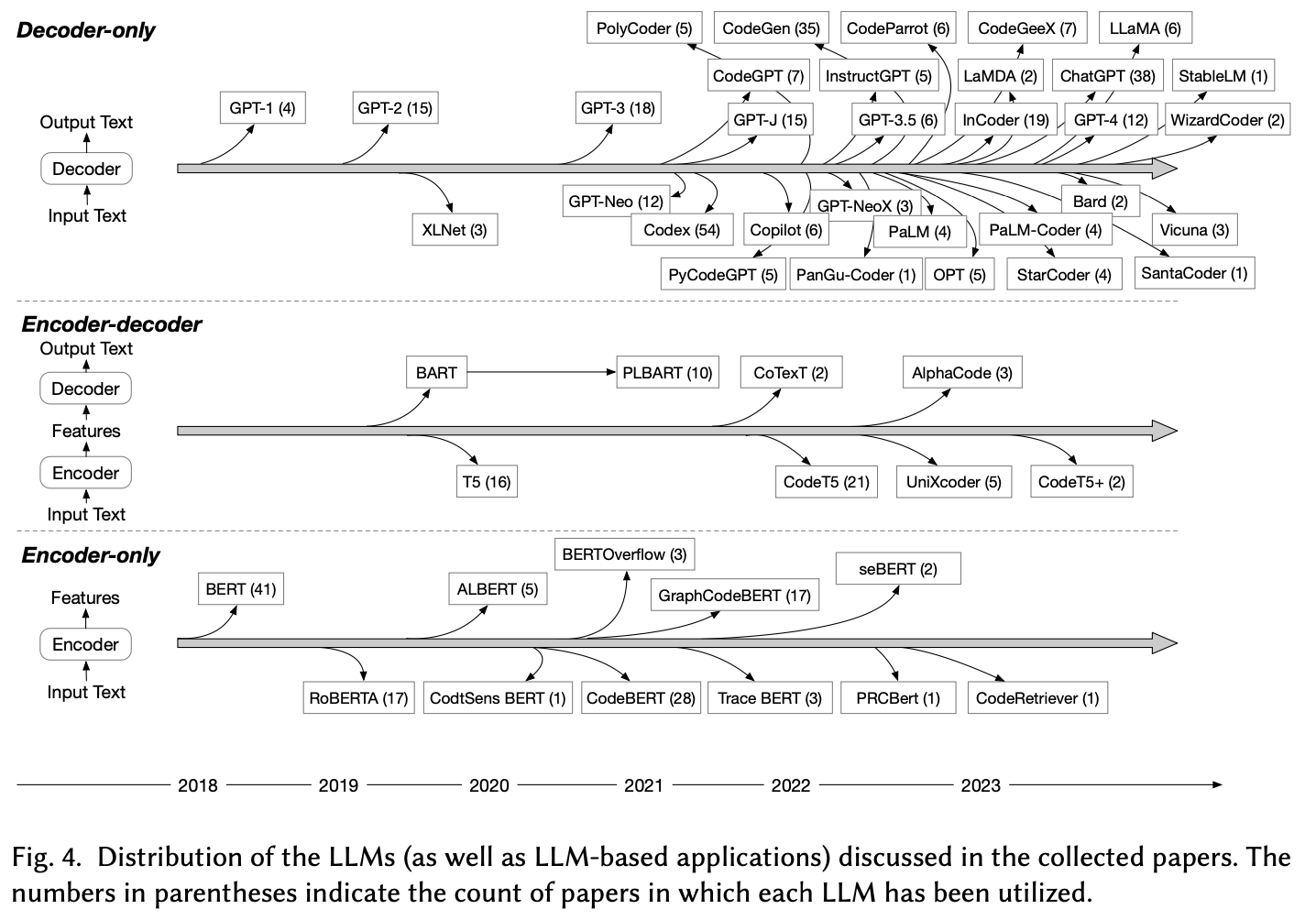
- Encoder-only models: Bert has been referenced in 41 of the papers, and its variants are also widely employed
- Encoder-decoder models: there are fewer models and applications. CodeT5 is the most popular one.
- Decoder-only models: Codex is used the most frequently.
- Models that are specialized for code-related tasks are the most popular, because these models have shown efficacy in tasks requiring a nuanced understanding of the entire code snippet, which is very important in software engineering.
2.2 Trends Analysis
- Evolution of LLM architectures in 2021: We see the emergence of decoder-only and encoder-decoder models in 2021.
- Diversity of LLM architectures in 2022: 2022 experienced a significant increase in diversity, with more varied LLM architectures finding representation.
- Dominance of the decoder-only architecture in 2023: 2023 signaled a strong shift towards decoder-only LLMs.
- We see an increasing number of studies utilizing LLMs for software engineering.
- There is a shift in focus and resources toward exploring and harnessing the decoder-only architecture as the primary approach.
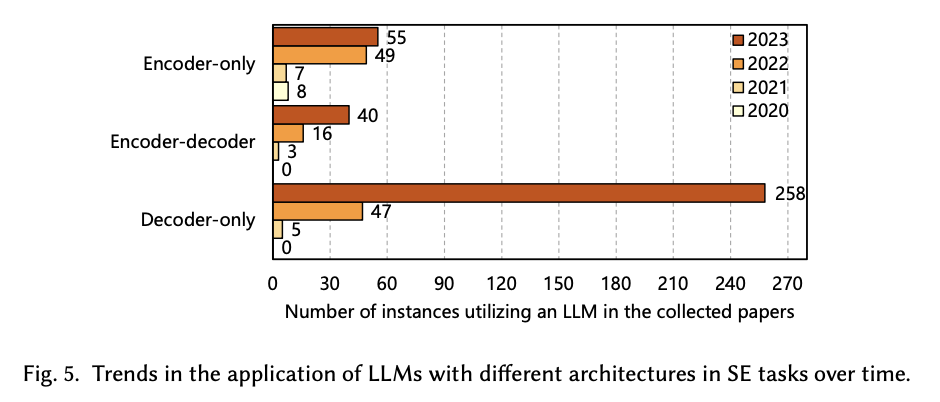
3 What types of SE datasets have been used in existing LLM4SE studies?
- There are 5 categories based on data types: code-based, text-based, graph-based, software repository-based, and combined data types.
- Most of the studies used text-based datasets, accounting for a total of 104.
- Prompts dataset is the most common among all the text-based datasets, as prompt engineering is largely utilized.
- Source code is the most abundant data type in code-based datasets, since source codes serve as the foundation of any software project.
- There is a noticeable scarcity of graph-based datasets. Exploring graph-based datasets could be important for addressing complex code scenarios since graphs can better capture the structural relationships and dependencies in code.
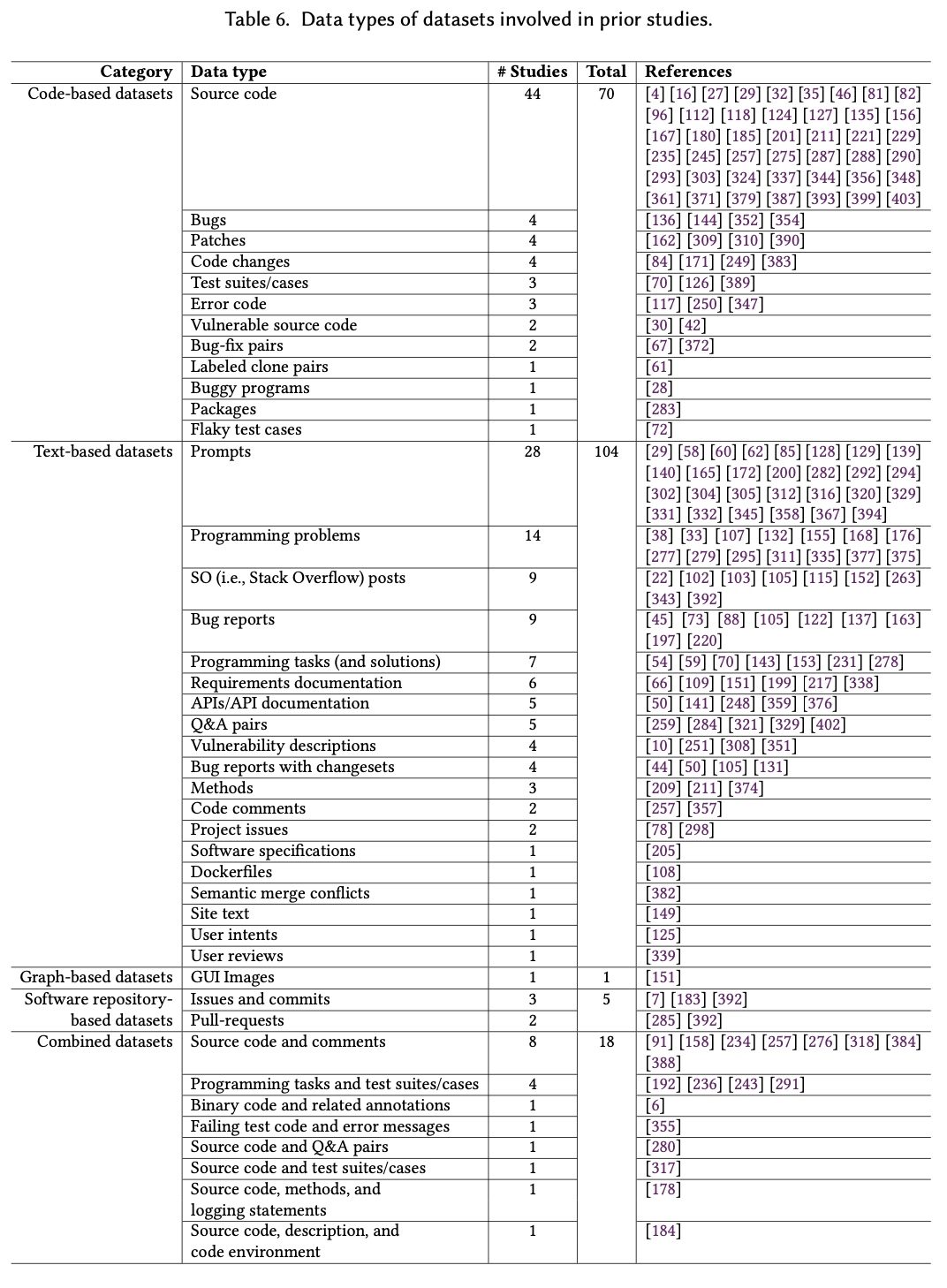
4 What techniques are used to optimize and evaluate LLM4SE?
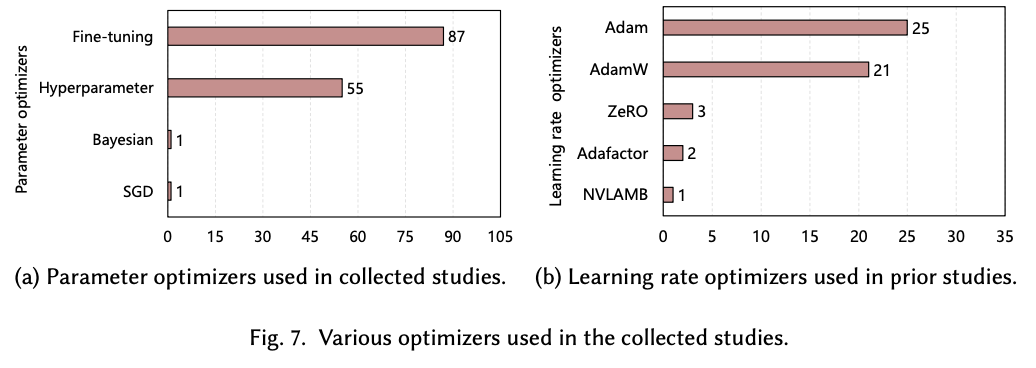
- Fine-tuning emerges as the most widely used optimization algorithm in LLM studies, appearing in 87 research works, which actually signifies the dominance of fine-tuning in adapting pre-trained models to specific downstream tasks.
- Among the learning rate optimization algorithms, Adam stands out with 25 occurrences in the studies. It is an adaptive optimization algorithm that combines adaptive learning rates with momentum, facilitating faster convergence and reducing the risk of getting stuck in local minima during training.
- Prompt engineering has shown to be particularly advantageous in providing task-relevant knowledge and enhancing LLMs’ versatility and efficacy across different code intelligence tasks.
5 What SE tasks have been efficiently addressed by LLMs?
- Based on the six phases of the Software Development Life Cycle (SDLC), the tasks are grouped into requirements engineering, software design, software development, software quality assurance, software maintenance, and software management.
- The highest number of studies is observed in software development, which underscores the primary focus on utilizing LLMs to enhance coding and development processes.
- Software maintenance tasks account for about 24.89% of the research share, highlighting the significance of LLMs in aiding software updates and improvements.
- Based on the types of problems, the studies are classified into generation, classification, recommendation, and regression.
- The majority of studies, about 64.34%, center around generation tasks, showing the significance of LLMs in producing code or text.
- Following this, around 24.48% of studies fall under classification tasks, which indicates the relevance of LLMs in categorizing software elements.
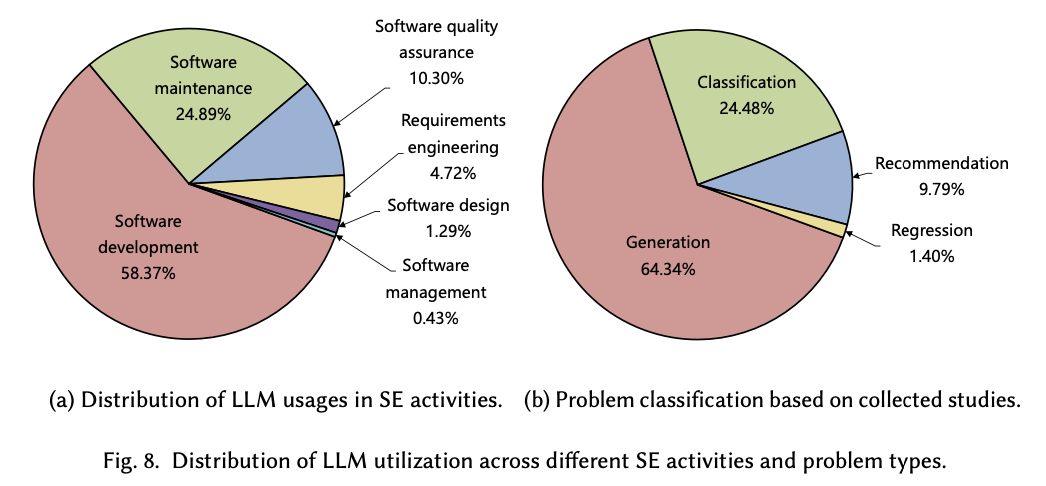
5 Distribution of SE Tasks Over Six SE activities
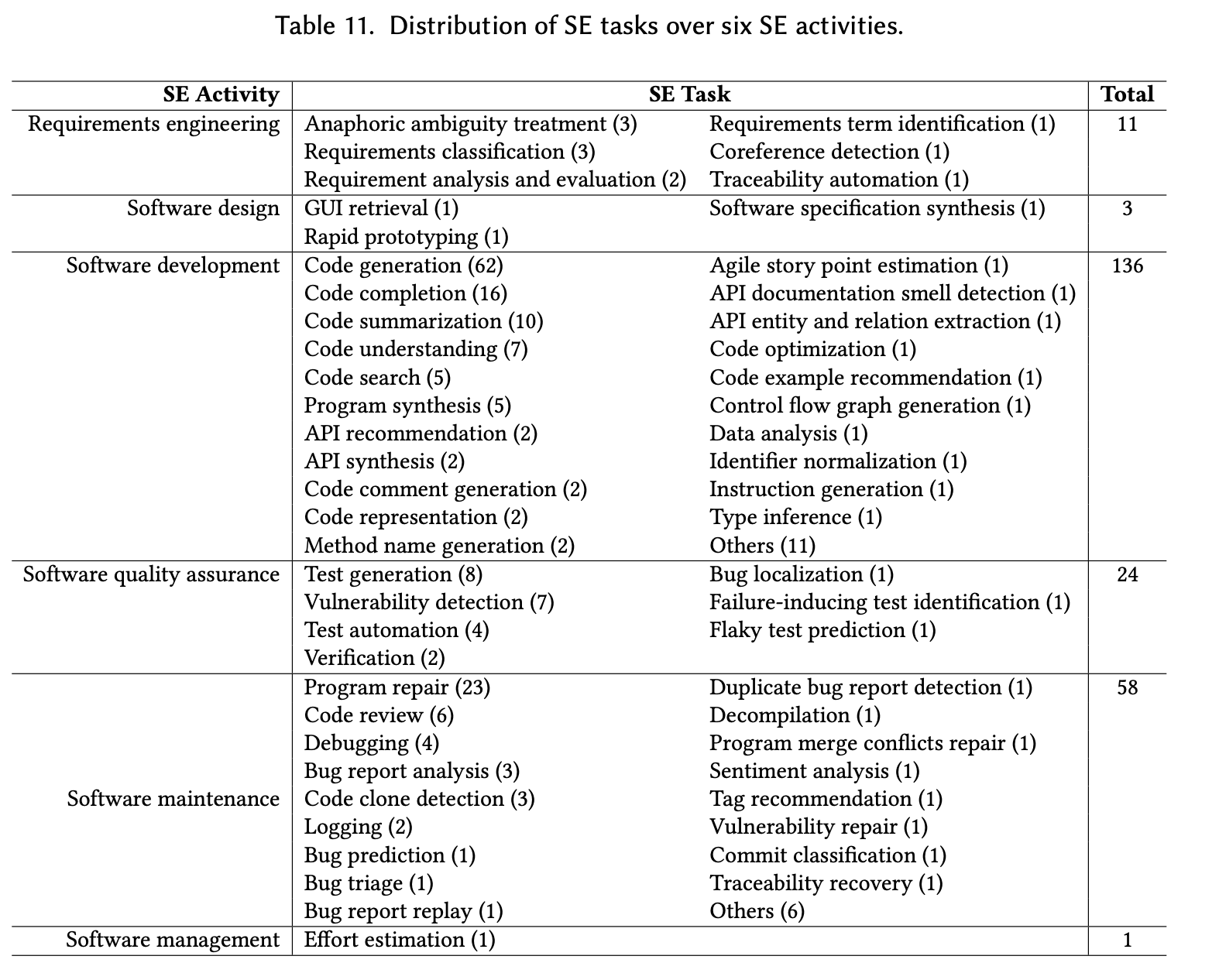
5.1 SE Activity 1: Requirements Engineering
5.1.1 Anaphoric Ambiguity
- Varying interpretations by readers of the same natural language requirement.

- Can cause misinterpretations, affecting later development stages.
- LLMs like BERT and SpanBERT can efficiently resolve such ambiguity [Moharil et al. and Ezzini et al.]
- ChatGPT showed remarkable ability in detecting and resolving this issue [Sridhara et al.]
5.2 SE Activity 2: Software Design
5.2.1 Rapid Prototyping
- Enables developers to quickly visualize and iterate on software designs, accelerating the development process

- White et al. showed that LLMs can be leveraged for rapid prototyping by introducing prompt design patterns.
5.2.2 Traceability Automation
- Traceability links SE artifacts: requirements, designs, code, and tests

- T-BERT can generate trace links between source code and natural language artifacts with few training instances.
5.2.2 Software Specification Synthesis
- Software specification is a valuable artifact, but manually synthesizing specification is very costly.
- LLM can automatically synthesize specification from natural language, outperforming previous SOTA by 21% in F1 score.
Natural Language Specification: Users can upload photos to their profile, but only JPG and PNG files are allowed. Each photo must be less than 5MB in size.
Formal Specification:
∀Photo(upload(Photo) → (fileType(Photo, JPG) ∨ fileType(Photo, PNG)))
∀Photo (upload(Photo) → fileSize(Photo, Size) < 5)
5.3 SE Activity 3: Software Development
5.3.1 Code Generation with LLMs
- Code generation has long been a task of interest.
- Natural language specification: Create a function that takes a list of numbers as input and returns the sum of all the even numbers in the list.

- LLMs are effective in method-level generation, with ongoing research to improve class-level generation accuracy.
- The integration of LLMs with SE tools and practices presents new opportunities for collaborative software development.
5.3.2 Control Flow Graph Generation with LLMs
- Control Flow Graphs (CFGs) are sequences of statements and their execution order.
- Critical in many SE tasks: code search, clone detection, code classification.

- Huang et al. introduced a novel LLM-based approach for generating behaviorally correct CFGs from partial code, using Chain of Thoughts (CoT).
- CoT works in four steps: structure hierarchy, nested block extraction, individual CFG generation, and CFG fusion.
- LLM-based method achieves superior node and edge coverage in CFGs, demonstrating the potential of LLMs in enhancing program analysis techniques.
5.4 SE Activity 4: Software Testing
5.4.1 Test Generation
- Automates test case creation.
Example Test Cases:
assertEqual(sum of even numbers([1, 2, 3, 4, 5, 6]), 12)
assertEqual(sum of even numbers([1, 3, 5, 7]), 0) - LLMs generate diverse test cases, achieve good coverage, detect unique bugs.
- NLD to test generation improves collaboration between developers and testers.
- LLMs identify test coverage gaps and suggest relevant test cases to close them.
5.4.2 Failure-Inducing Test Identification.
- Distinguishing between pass-through and fault-inducing test cases is crucial for debugging.
- ChatGPT can effectively detect subtle code discrepancies and generate fault-inducing test cases

5.5 SE Activity 5: Software Maintenance
5.5.1 Program Repair with LLMs.
- LLMs can be leveraged for automated bug identification and fixing.
- BERT, CodeBERT, Codex and GPT series excel in generating correct patches.
- Incorporating additional context can boost LLM’s program repair performance.

5.6 SE Activity 6: Software Management
5.6.1 Effort estimation.
- Effort estimation is crucial for planning the time, resources, and manpower needed for software projects.
- BERT’s showed potential to significantly aid in the accurate prediction of resources and manpower needed for software maintenance, streamlining project planning and resource allocation.
6 Summary
- SE tasks categorized into six areas show LLMs’ diverse applications.
- LLM usage spans 55 SE tasks, predominantly in software development, with minimal application in software management.
- Code generation and program repair emerge as prominent LLM tasks.
7 Challenges
- Model size and deployment
- Data dependency (lack of data, overlapping issue, privacy issue)
- Ambiguity in code generation
- Generalizability
- Evaluation metrics issue (typical metrics)
- Interpretability, Trustworthiness, and Ethical Usage
Exploring the Impact of Large Language Models (LLMs) on Bioengineering
1 Motivation
Understanding biological trajectories can be applied to medicine, biotechnology, bioinformatics, and environmental sciences.
- Genetic Dogma: The biological trajectory of any organism (e.x. Human) is a complex interplay between genetics and environment.
- Central Dogma: genetic information flows only in one direction, from DNA, to RNA, to protein, or RNA directly to protein.
- Hiearchy of Biological Entities: Nucleotide → DNA → Gene → Chromosome → Cell → Organism
2 Basic Terms
-
Nucleic Acids: Macromolecules for thestorage, transmission, and expression of genetic information.
-
Nucleotide: Building blocks of nucleic acids such as DNA (deoxyribonucleic acid) and RNA (ribonucleic acid).
-
Amino Acids: Building blocks of proteins for biological processes such as the synthesis of proteins, enzymes, hormones, and neurotransmitters.
-
Residues: A specific unit or component within a larger molecule, such as a protein or nucleic acid.
-
Genetic Code: A set of rules that defines the correspondence between the nucleotide sequence of a DNA or RNA molecule and theamino acid sequence of a protein.
3 AlphaFold
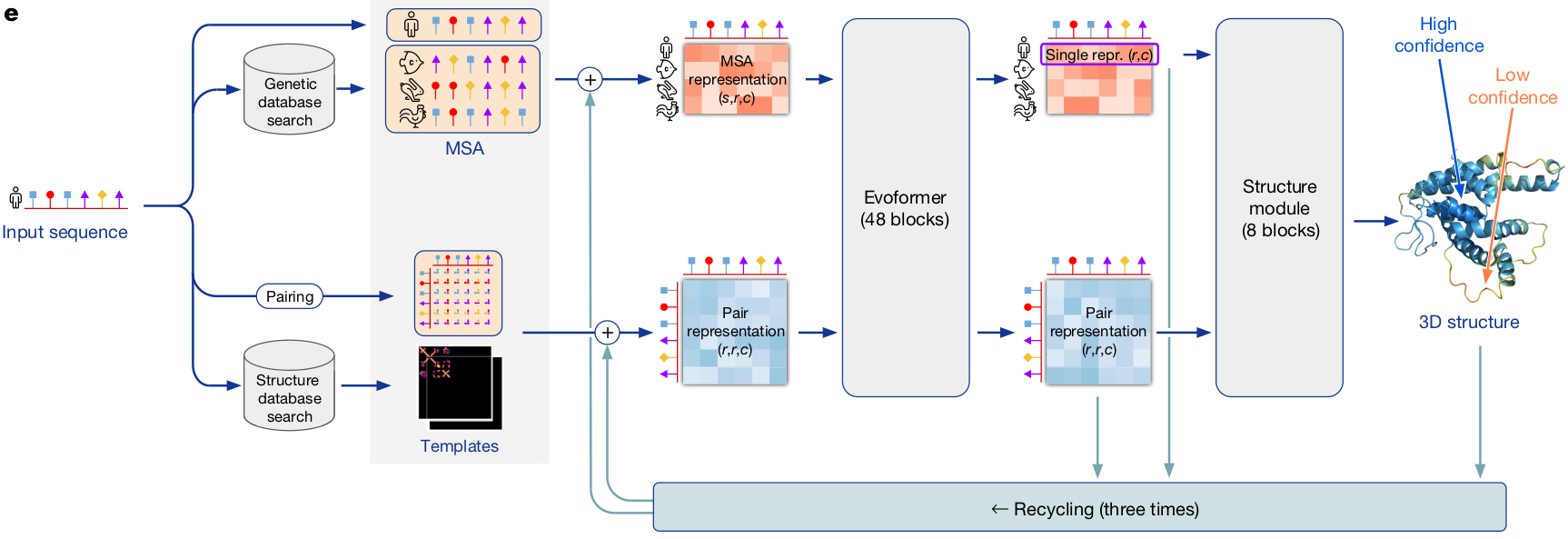
Principles about the Folding of Protein Chains: A protein’s amino acid sequence should fully determine its structure.
- Alpha fold is the first model designed by a variation of transformer architecture solving the principle.
- In order to generate 3D structure from protein’s amino acid sequence, they use multiple sequence alignment (MSA) and geometric structure inherent in protein sequence considering relative distance bewteen two amino acid.
- They use triangular transformer architecture to recover the geometric structure.
4 Pre-training process
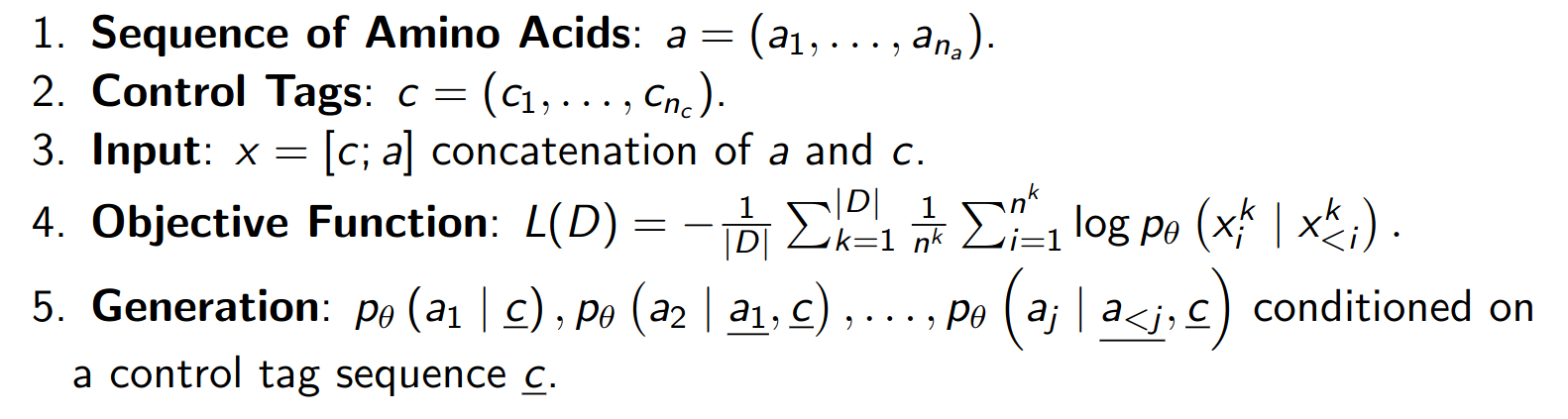
Control tage can be (partial) 3D structure of protein or protein family or specific function of target protein.
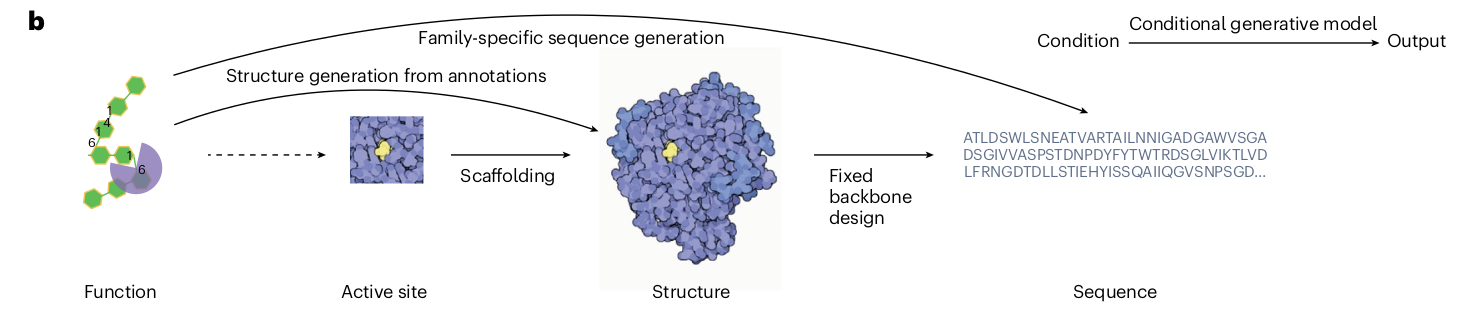
5 Protein Objective
We can categorize three different objective for protein generation in terms of existence for protein and target function. Each objective might deploy a different model structure.
6 Topology of Protein Design
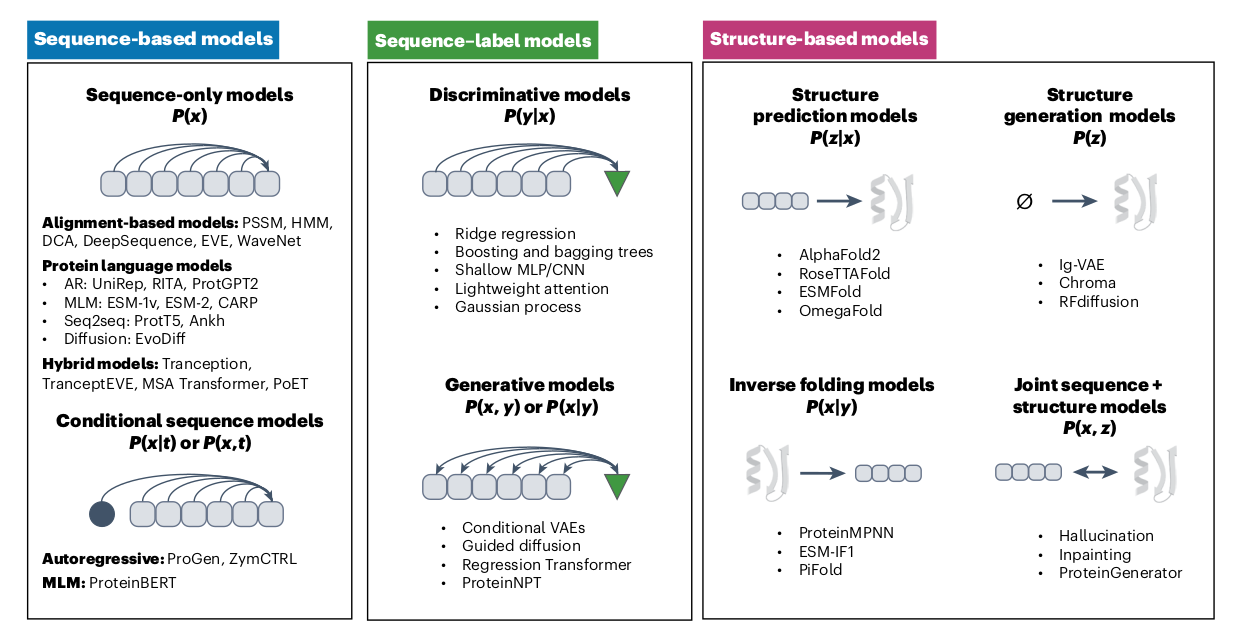
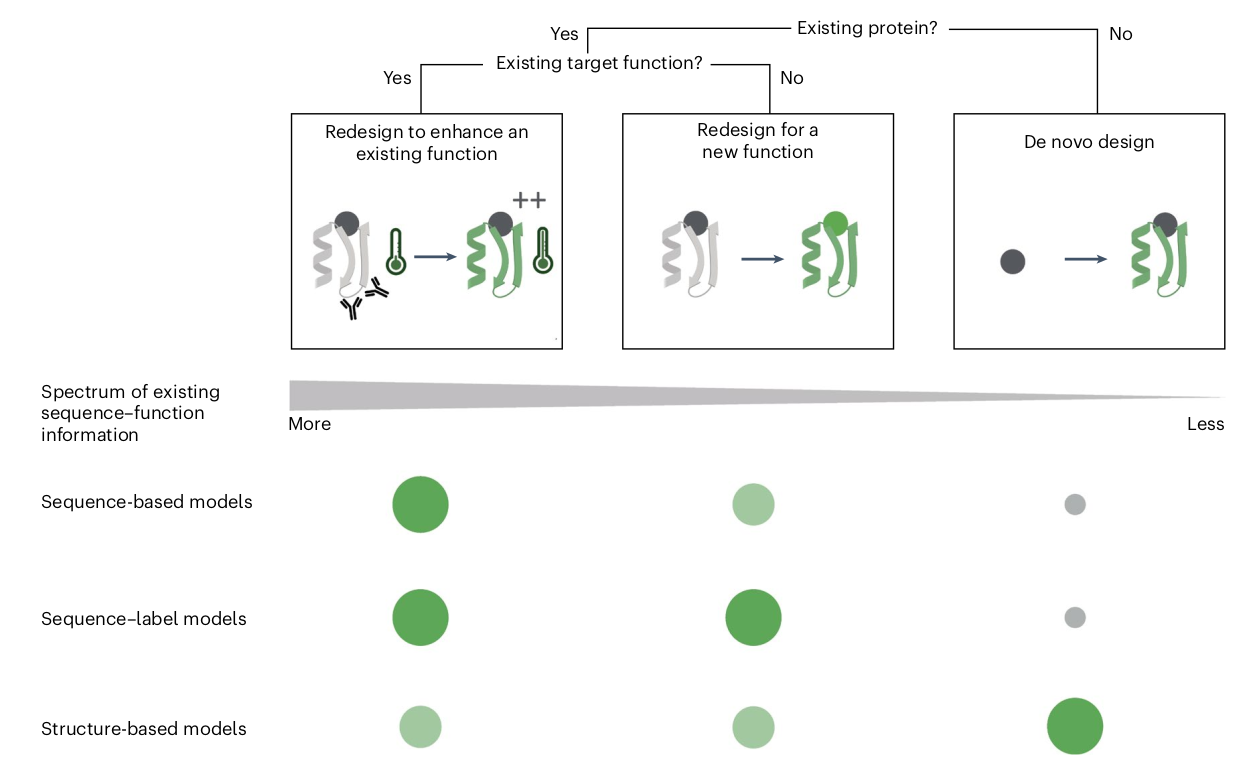
Protein generation models can be categorized into three different types 1) Sequence based models: Encompass sequence generation. 2) Sequence-label models: Encompass label (e.g., target function). 3) Structure based models: Encompass 3D structure generation.
7 A Genomic Foundation Model
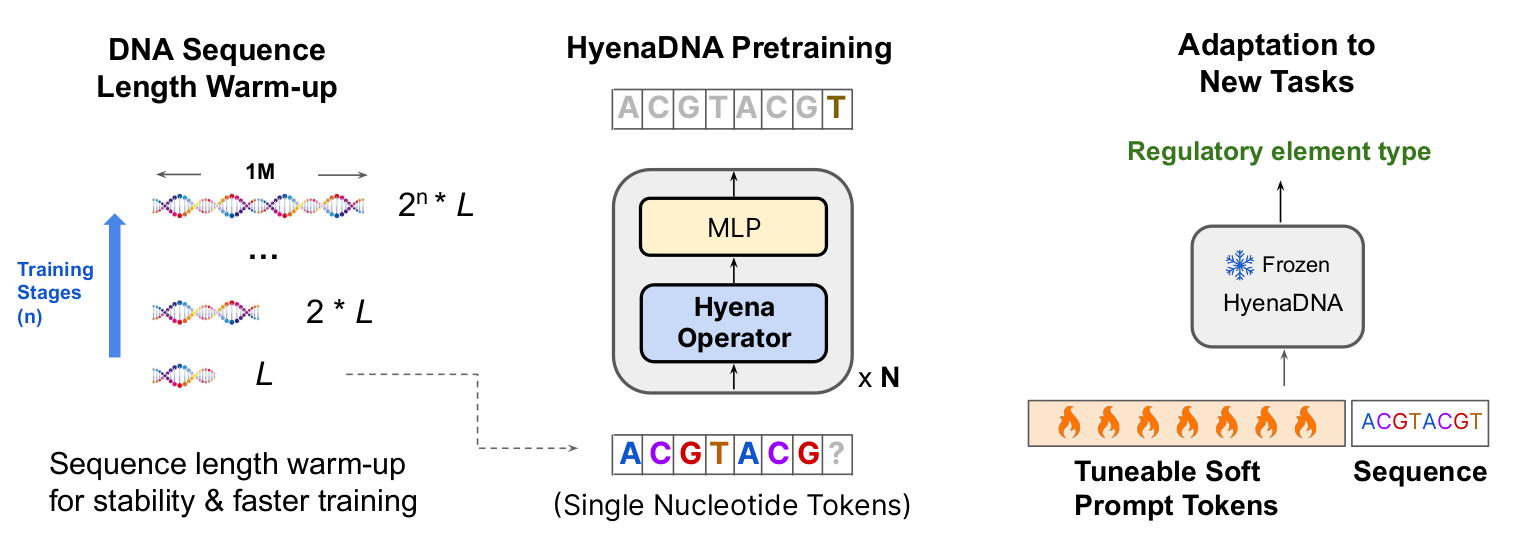
This model is trained on nucleotide level (smaller than protein).
-
Model architecture relies on Convolutional Neural Network (CNN) based architecture.
-
Replace multi-head attention of transformer with Hyena Operator which is based on CNN.
-
Because of long-term dependancy of very long (100k) sequences of nucleotide, use warm-up training starting with relatively smaller size of the sequence.
8 A Genomic Foundation Model
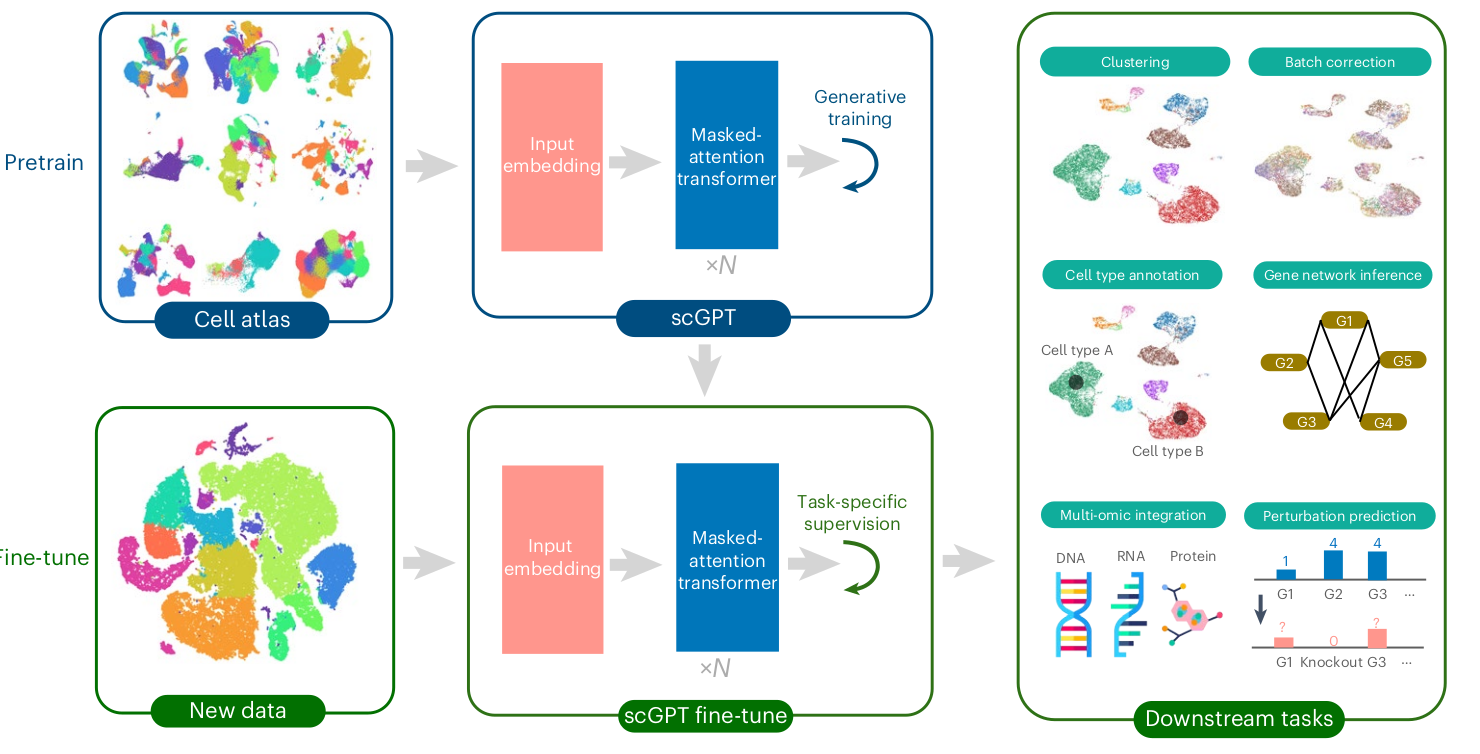
This model is trained on single cell level (larger than protein).
-
Pre-training process will be done on single cell dataset with transformer architecture.
-
The pre-trained model can be applied to many different downstream tasks (e.g., cell classification)
9 Design of Full-atom Ligand-binding Protein Pockets
![]()
Drug design can benefit from protein generation.
-
Ligand Molecule could function as back bone structure for new drug design.
-
We can generate a specific region to enhance or design a drug for target function
10 Protein Structure Generation
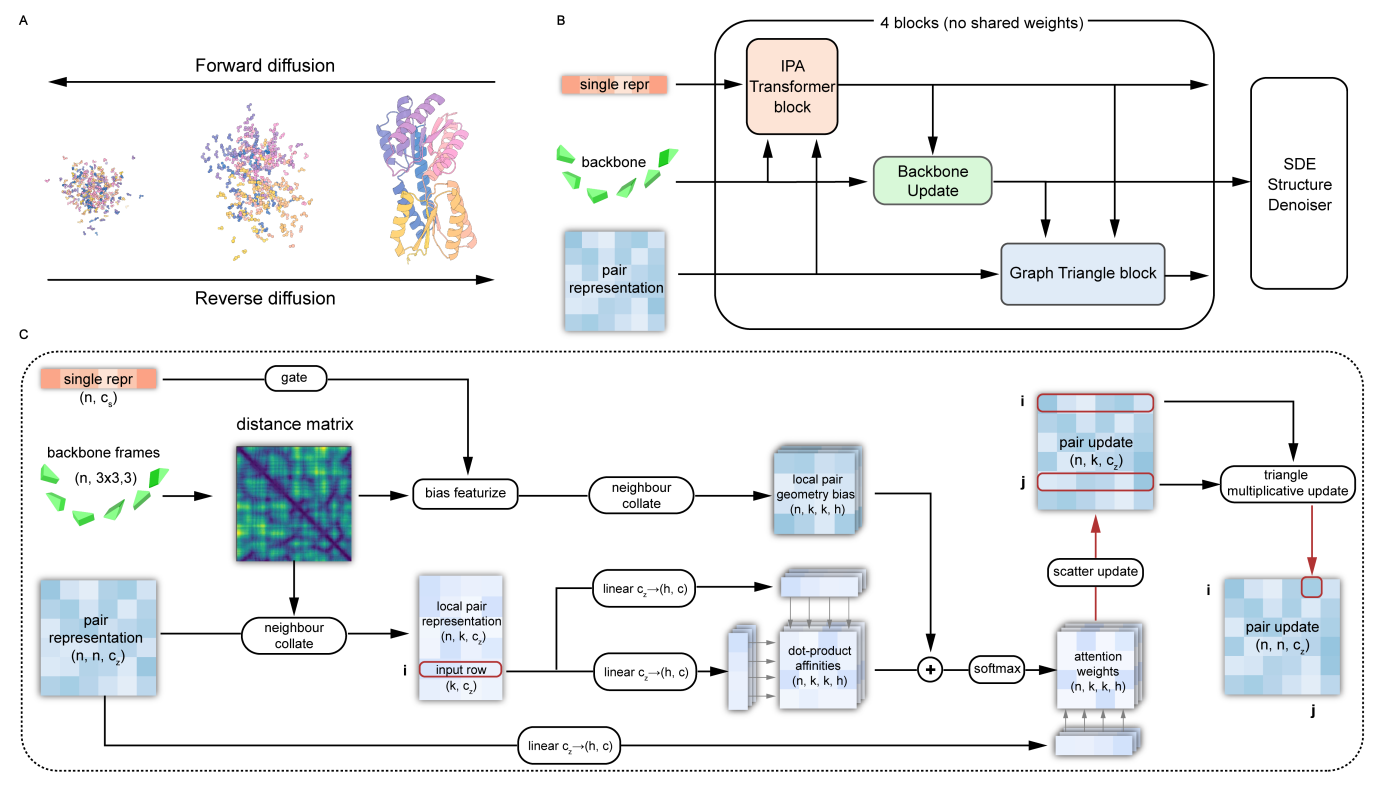
This model is based on diffusion framework.
-
Diffusion is processed over 3D structure of proteins.
-
For the process, we consider roation matrix and translation vector.
11 Molecular to Genome
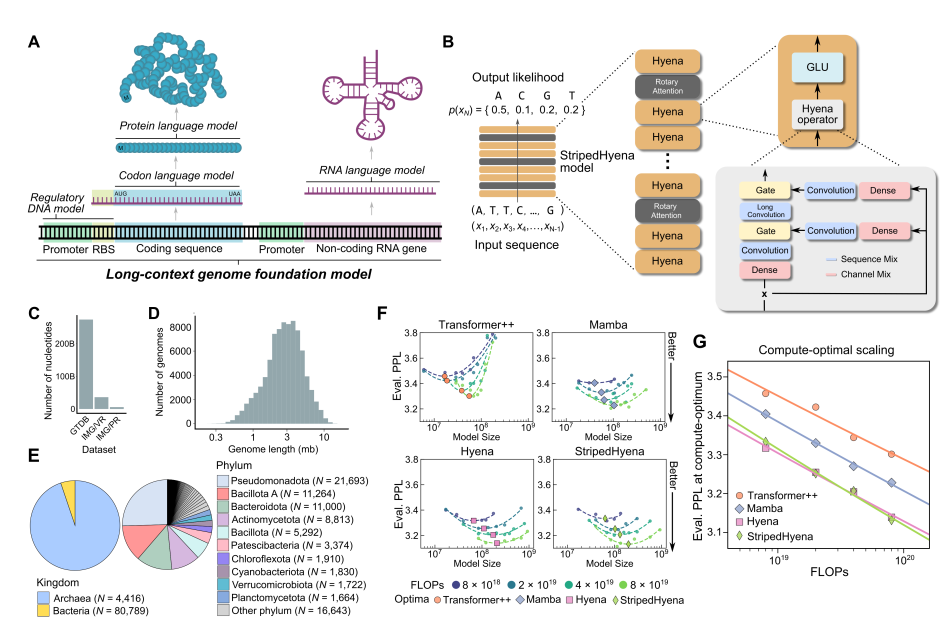
This model is based on dilated CNN architecture.
-
They compare performance over Perplexity and Computional efficiency.
-
CNN-based model constantly outperforms Transformer or Mamba based architecture.
-
Long term dependancy over 100k sequences might requires us to use CNN based architecture, which could be more capable of finding long-term dependacy.
-
Genomic foundation model can be applied to protein, single cell level too.
12 Chem LLM
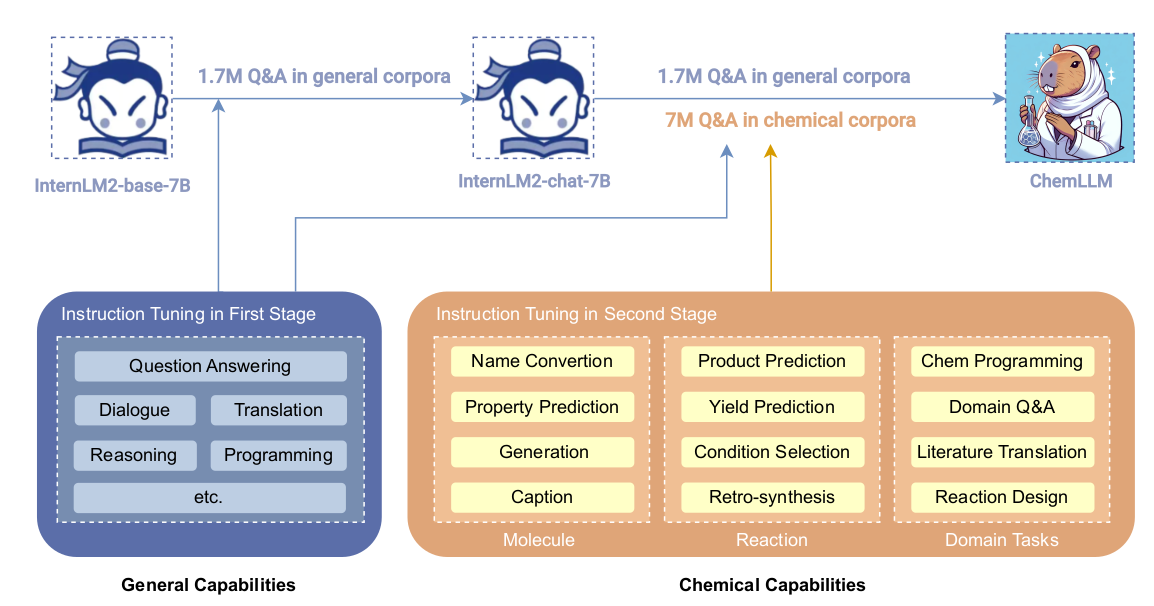
LLMs can be applied to specific domain in bioengineering with well curated training process.
Large Language Models in Law: A Survey
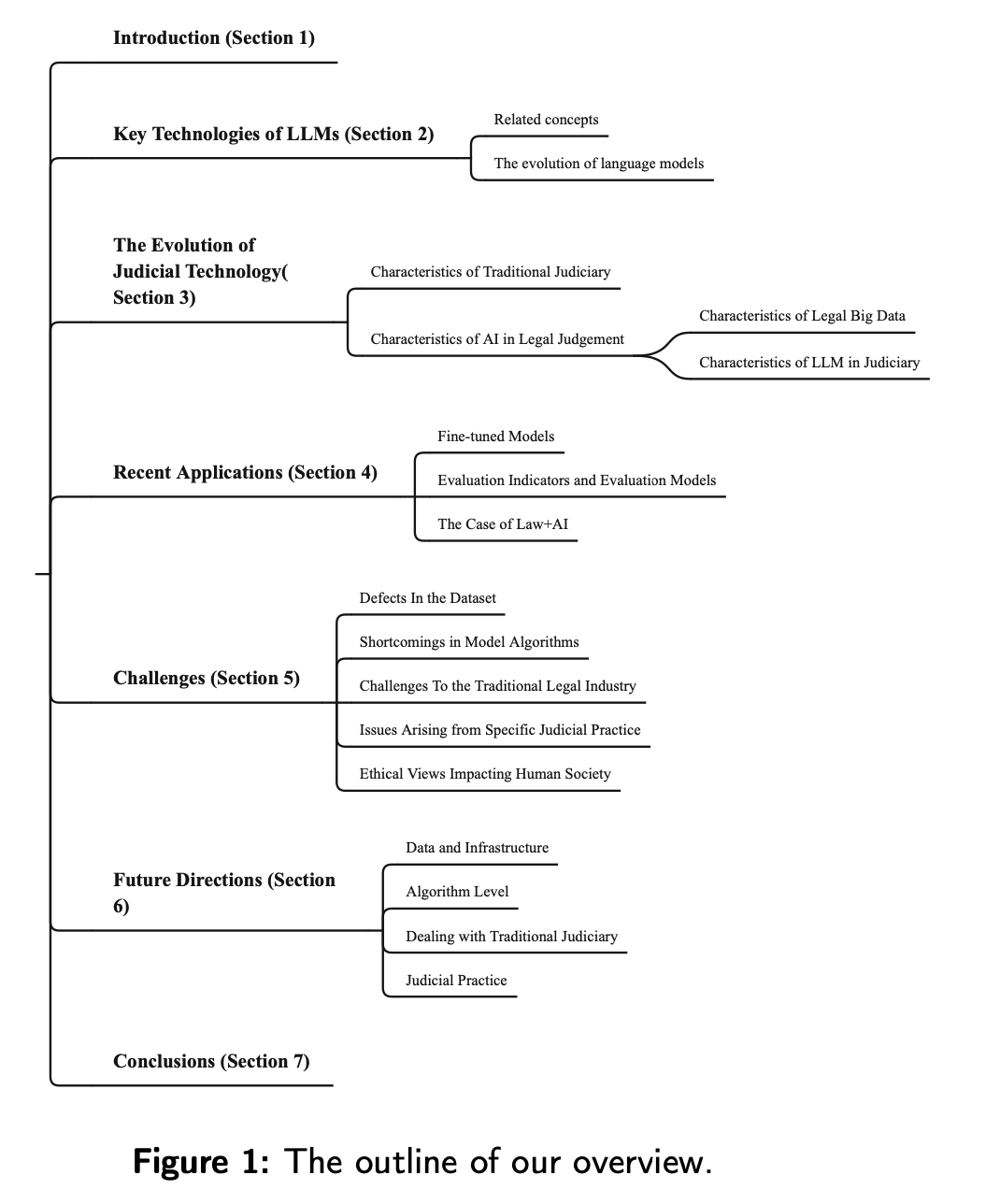
1 Overview
The following figure gives an overview of the survey.
2 Contributions
Main contributions of this survey:
- The first comprehensive review article on legal LLMs
- Demonstrates use of legal LLMs
- Provides the latest research on legal LLMs
- Summarizes the key challenges and future directions of legal LLMs
3 Evolution of Judicial Technology
3.1 Characteristics of Traditional Judicial System
When looking at the traditional judicial system that has been in use since before AI was a thing, we see a number of characteristics:
- Reliance on human decision-making
- Precedent-based
- Flexibility–the law and how it applies to a case depends on context of that particular case
- Time and resource-consuming
3.1 Characteristics of AI in Legal Judgement
In order to effectively use AI in legal judgement, it is imperative to have a large amount of legal big data. However, examining the nature of the legal data that is available shows a number of characteristics that make the task difficult. Some legal big data characteristics:
- Unstructured
- Multilingual and multicultural
- Covers vast scale and complexities
- Timeliness
- Must be regularly updated
- Data multi-sourcing
- Comes from a variety of different sources
- Privacy and security concerns
- May contain sensitive information, which must be removed before use
The following figure shows the main characteristics of LLMs in Judiciary:

Some important use cases include:
- Language Understanding
- LLMs can analyze legal documents and extract information from language
- Content generation
- LLMs can automatically generate legal documents based on information given
- Speech-to-text conversion
- Give legal advice
- LLMs can answer basic questions users may have about the law
- Matching optimal solutions for cases
- AI can extract key features of the case and try to recommend an optimal solution for the case
- Case logic reasoning
- Improve judicial efficiency
4 Recent Applications
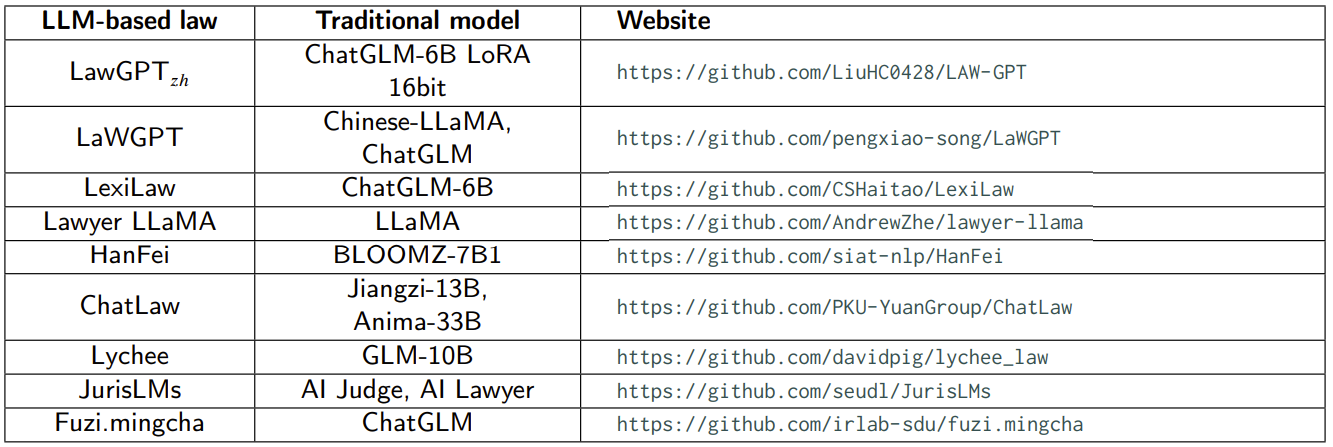
The following are ten popular legal LLMs that are examined by the survey. They are fine-tuned, mainly on question-answer legal data.
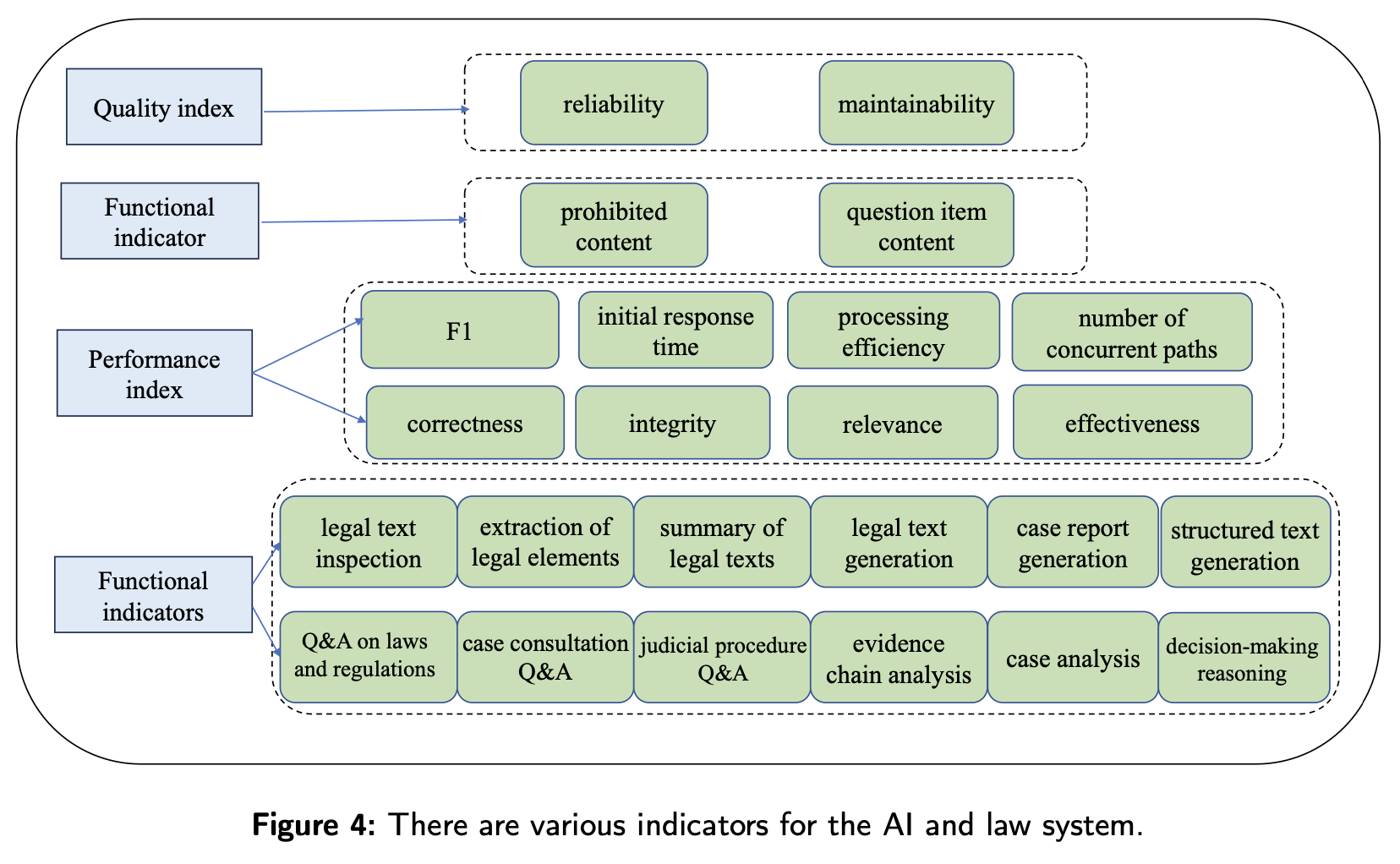
In August 2023, several institutions and universities developed a comprehensive evaluation system for legal AI systems. The evaluation system combines subjective and objective measures. There are four primary indicators:
- Functional Indicators
- Performance Indicators
- Safety Indicators
- Quality Indicators
There are also further subindicators for each category, which can be seen in the following figure:
5 Challenges
5.1 Defects in Datasets
Legal LLMs still face a variety of challenges when it comes to widespread and accurate use. Some important challenges to consider are:
1) Inadequate Data Aquisition
- Insufficient sources of judicial data and documents
- Insufficient sharing of legal data
- Non-standard legal documents
2) Inaccurate Interpretation of Legal Concepts
- Current AI systems have some recognition deficiencies when it comes to legal concepts
3) Dataset Characteristics
- Timeliness
- Legal concepts evolve as time passes, which is not always reflected in law data
- Credibility
- Due to variety of laws and large number of judicial documents, bias and inaccuracies can still exist in datasets
- Scalability
- Current scale of datasets can still be somewhat limited
5.2 Shortcomings in Algorithms
1) Interpretability
- Insufficient interpretability reduces people’s trust in the judicial application of AI
2) Ethics, bias, and fairness
- Algorithms may contain elements of inequality
- Insufficient security in algorithm outsourcing
- Reduced transparency of LLMs in law may lead to judicial unfairness
- Algorithmic Bias
5.3 Challenges of Traditional Legal Industry
5.3.1 Neglecting Judicial Independence
a) In terms of legal enforcement: it includes
- Interpreting Civil Law
- Explaining uncertain concepts, and evaluating disputes
b) In terms of fact-finding: use of discretion, subjective judgment, experiential
Legal LLMs lead to a) Overly relying on AI b) Form preconceived notions
For Example, In assessing the compensation amount in civil litigation, judges can comprehensively consider factors such as the extent of the victim’s financial loss and the defendant’s ability to compensate. In contrast, the algorithms of legal LLMs struggle to measure the extent of loss
Legal LLMs can assist judges. However, it does not possess professional judicial experience and cannot independently make judgments in cases
5.3.2 Impact on Judicial System
Legal LLMs have restrained the subjective initiative of judges and the development of traditional trial systems as reflected in:
1) Court idleness:
- Restrict the subjective initiative of judges
- Diminish the solemnity of the legal process
2) Crisis in the hierarchy of trial: Legal AI systems will impact the judicial process in the hierarchical system.
For example, Any party dissatisfied with any judgment of a lower court can appeal to a higher court which with legal AI system remains same.
5.4 Issues Arising from Specific Judicial Practice
5.4.1 The lack of universality in applications
Legal LLMs often extract feature values from cases and search for similar cases within existing multidimensional datasets to find the “optimal solution” Legal regulations may vary across different countries or regions, leading to inconsistent decision outcomes for the same case under different legal rules, so, the “optimal solution” proposed by the large model may not apply to a particular case.
5.4.2 The lack of subjective thinking, emotions, and experience
Legal LLMs lack autonomous thinking abilities and professional experience, among other things. Judicial decision making process is not merely a logical reasoning process on a single layer but also involves moral, ethical, and practical considerations in the legal system.
5.4.3 Contradiction with the presumption of innocence principle
Various systems are used which predicts probability of crime without those even occurring like COMPAS system for crime prediction and risk assessment, PredPol for iterative calculation of potential crime locations and PRECOBS system in Germany is used for burglary prevention and violence crime prediction.
- Imbalance of prosecution and defense
- Unequal control over data
- Differences in the ability to analyze case data
- Issues of policy attention, investment imbalance, and unequal exploration
- Administrative Performance
 Figure: Futuristic System that apprehends people based on their probability of
committing Crime.
Figure: Futuristic System that apprehends people based on their probability of
committing Crime.
5.5 Ethical Views Impacting Human Society
5.5.1 Disregard for human subjectivity:
Human subjectivity is susceptible to algorithmic bullying.
5.5.2 Misleading user comments:
In testing certain LLMs, such as ChatGPT, AI has displayed behaviors such as inducing users to divorce, making inappropriate comments, and even encouraging users to disclose personal privacy or engage in illegal activities
5.5.3 Ethical value consistency:
There may be situations where AI misleads or harms human interests. Team 2 Domain Centered FMs March 23, 2024
6 Future Directions
6.1 Data and Infrastructure
- Obtaining more comprehensive legal big data
- Defining the boundaries of legal concepts and limiting the scope of application
- Data transparency
- Building a legal knowledge graph
- Optimizing the foundational infrastructure for model training [High-performance computing resources, Storage and data management, Model scaling and deployment etc.]
6.2 Algorithm Level:
- Strategy adjustment and optimized algorithm
- Limiting algorithmic biases and “black box” operations the scope of application
- Promote limited algorithmic transparency
6.3 Dealing with Traditional Judiciary
- Clarifying the positioning of large models
- Defining the thinking capability of LLMs
- Ensuring parties’ access to data
- Expanding and optimizing the consulting function of judicial large models
6.4 Judicial Practice:
- Improve accountability mechanisms to prevent political interference
- Foster the development of interdisciplinary talents
- Collaboration and sharing of experiences
7 Conclusions
This paper synthesized various technologies and ideas regarding the opportunities, challenges, and recommendations for the application of AI in the judicial field. Team 2 Domain Centered FMs March 23, 2024
REFERENCES
https://arxiv.org/abs/2308.10620 https://arxiv.org/abs/2312.03718 https://arxiv.org/abs/2306.15794 https://arxiv.org/abs/2402.06852 https://www.nature.com/articles/s41586-021-03819-2 https://www.nature.com/articles/s41587-023-02115-w https://www.nature.com/articles/s41587-022-01618-2 https://www.nature.com/articles/s41587-024-02127-0 https://www.biorxiv.org/content/10.1101/2024.02.10.579791v2 https://www.biorxiv.org/content/10.1101/2024.02.25.581968v1 https://www.biorxiv.org/content/10.1101/2023.04.30.538439v1 https://www.biorxiv.org/content/10.1101/2023.01.11.523679v1 https://www.biorxiv.org/content/10.1101/2024.02.27.582234v1