LLM interpretibility, trust and knowledge conflicts
- SlideDeck: W10-T6-LLMInterpretibility
- Version: current
- Lead team: team-6
- Blog team: team-4
Required Readings:
Rethinking interpretability in the era of large language models
- Chandan Singh, Jeevana Priya Inala, Michel Galley, Rich Caruana, Jianfeng Gao
- 2024/1/30
- Interpretable machine learning has exploded as an area of interest over the last decade, sparked by the rise of increasingly large datasets and deep neural networks. Simultaneously, large language models (LLMs) have demonstrated remarkable capabilities across a wide array of tasks, offering a chance to rethink opportunities in interpretable machine learning. Notably, the capability to explain in natural language allows LLMs to expand the scale and complexity of patterns that can be given to a human. However, these new capabilities raise new challenges, such as hallucinated explanations and immense computational costs. In this position paper, we start by reviewing existing methods to evaluate the emerging field of LLM interpretation (both interpreting LLMs and using LLMs for explanation). We contend that, despite their limitations, LLMs hold the opportunity to redefine interpretability with a more ambitious scope across many applications, including in auditing LLMs themselves. We highlight two emerging research priorities for LLM interpretation: using LLMs to directly analyze new datasets and to generate interactive explanations.
The Claude 3 Model Family: Opus, Sonnet, Haiku
- https://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf
- We introduce Claude 3, a new family of large multimodal models – Claude 3 Opus, our most capable offering, Claude 3 Sonnet, which provides a combination of skills and speed, and Claude 3 Haiku, our fastest and least expensive model. All new models have vision capabilities that enable them to process and analyze image data. The Claude 3 family demonstrates strong performance across benchmark evaluations and sets a new standard on measures of reasoning, math, and coding. Claude 3 Opus achieves state-of-the-art results on evaluations like GPQA [1], MMLU [2], MMMU [3] and many more. Claude 3 Haiku performs as well or better than Claude 2 [4] on most pure-text tasks, while Sonnet and Opus significantly outperform it. Additionally, these models exhibit improved fluency in non-English languages, making them more versatile for a global audience. In this report, we provide an in-depth analysis of our evaluations, focusing on core capabilities, safety, societal impacts, and the catastrophic risk assessments we committed to in our Responsible Scaling Policy [5].
More Readings:
Knowledge Conflicts for LLMs: A Survey
- https://arxiv.org/abs/2403.08319
- This survey provides an in-depth analysis of knowledge conflicts for large language models (LLMs), highlighting the complex challenges they encounter when blending contextual and parametric knowledge. Our focus is on three categories of knowledge conflicts: context-memory, inter-context, and intra-memory conflict. These conflicts can significantly impact the trustworthiness and performance of LLMs, especially in real-world applications where noise and misinformation are common. By categorizing these conflicts, exploring the causes, examining the behaviors of LLMs under such conflicts, and reviewing available solutions, this survey aims to shed light on strategies for improving the robustness
Transformer Debugger
- https://github.com/openai/transformer-debugger
- Transformer Debugger (TDB) is a tool developed by OpenAI’s Superalignment team with the goal of supporting investigations into specific behaviors of small language models. The tool combines automated interpretability techniques with sparse autoencoders. TDB enables rapid exploration before needing to write code, with the ability to intervene in the forward pass and see how it affects a particular behavior. It can be used to answer questions like, “Why does the model output token A instead of token B for this prompt?” or “Why does attention head H attend to token T for this prompt?” It does so by identifying specific components (neurons, attention heads, autoencoder latents) that contribute to the behavior, showing automatically generated explanations of what causes those components to activate most strongly, and tracing connections between components to help discover circuits.
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning
- https://transformer-circuits.pub/2023/monosemantic-features/index.html
- In this paper, we use a weak dictionary learning algorithm called a sparse autoencoder to generate learned features from a trained model that offer a more monosemantic unit of analysis than the model’s neurons themselves. Our approach here builds on a significant amount of prior work, especially in using dictionary learning and related methods on neural network activations , and a more general allied literature on disentanglement. We also note interim reports which independently investigated the sparse autoencoder approach in response to Toy Models, culminating in the recent manuscript of Cunningham et al.
- related post: Decomposing Language Models Into Understandable Components https://www.anthropic.com/news/decomposing-language-models-into-understandable-components
Tracing Model Outputs to the Training Data
- https://www.anthropic.com/news/influence-functions
- As large language models become more powerful and their risks become clearer, there is increasing value to figuring out what makes them tick. In our previous work, we have found that large language models change along many personality and behavioral dimensions as a function of both scale and the amount of fine-tuning. Understanding these changes requires seeing how models work, for instance to determine if a model’s outputs rely on memorization or more sophisticated processing. Understanding the inner workings of language models will have substantial implications for forecasting AI capabilities as well as for approaches to aligning AI systems with human preferences. Mechanistic interpretability takes a bottom-up approach to understanding ML models: understanding in detail the behavior of individual units or small-scale circuits such as induction heads. But we also see value in a top-down approach, starting with a model’s observable behaviors and generalization patterns and digging down to see what neurons and circuits are responsible. An advantage of working top-down is that we can directly study high-level cognitive phenomena of interest which only arise at a large scale, such as reasoning and role-playing. Eventually, the two approaches should meet in the middle.
Language models can explain neurons in language models
- https://openai.com/research/language-models-can-explain-neurons-in-language-models
- Language models have become more capable and more widely deployed, but we do not understand how they work. Recent work has made progress on understanding a small number of circuits and narrow behaviors,[1][2] but to fully understand a language model, we’ll need to analyze millions of neurons. This paper applies automation to the problem of scaling an interpretability technique to all the neurons in a large language model. Our hope is that building on this approach of automating interpretability [3][4][5] will enable us to comprehensively audit the safety of models before deployment.
Blog: Session Blog
Rethinking Interpretability in the Era of Large Language Models
Section based on the paper Rethinking Interpretability in the Era of Large Language Models
- In traditional ML interpretability,
- Building inherently interpretable models,
- such as sparse linear models and decision trees
- Post-hoc interpretability techniques
- Such as Grad-Cam that relies on saliency maps
- Building inherently interpretable models,
- A new opportunity in LLM interpretability:
- Explanation Generation
- “Can you explain your logic?” “ Why didn’t you answer with (A)?”
Interpretability Definition: Extraction of relevant knowledge concerning relationships contained in data or learned by the model The definition applies to both:
- Interpreting an LLM, and
- Using an LLM to generate explanations
Breakdown of LLM interpretability: Uses and Themes
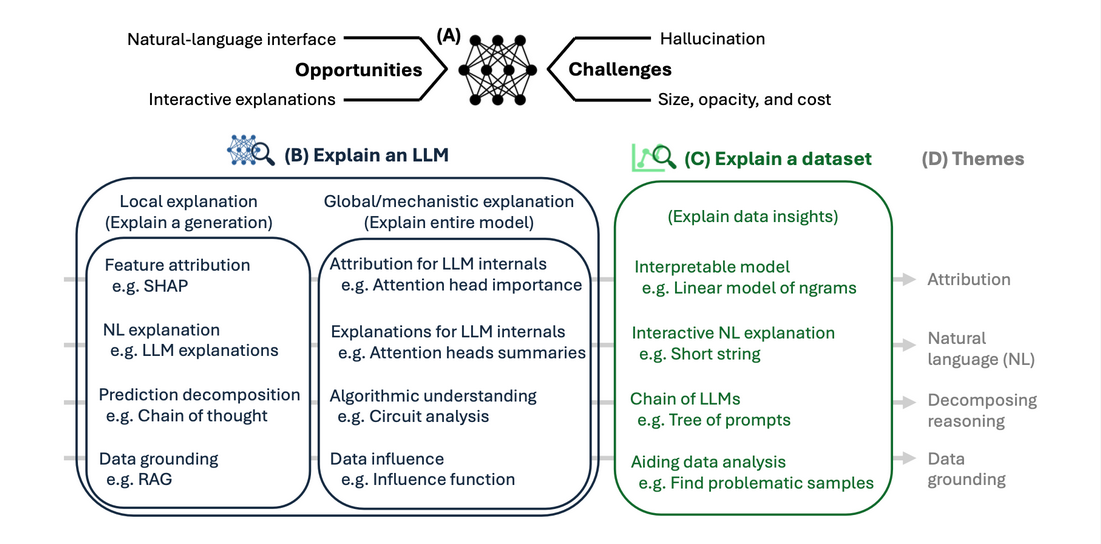
Description example
Local Explanation
Explain a Single Generation by Token-level Attributions
- Providing feature attributions for input tokens
- perturbation-based methods
- gradient-based methods
- linear approximations
- Attention mechanisms for visualizing token contribution to a generation
- LLM can generate post-hoc feature attributions by prompting
Post-hoc feature attributions by prompting LLM

Explain a Single Generation Directly in Natural Language
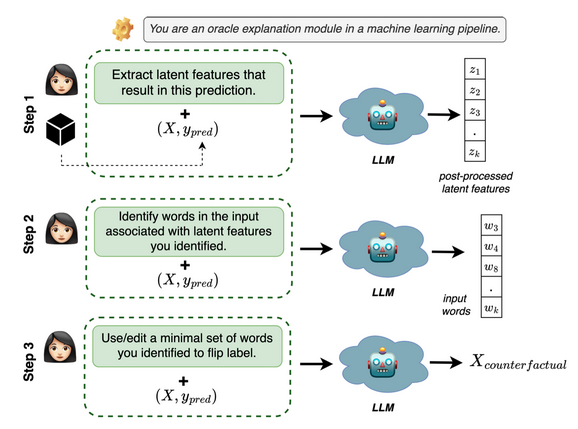
Challenges: Hallucination Mitigation:
- Generate explanation within the answer:
- Chain-of-thought prompting
- Tree-of-thoughts
- Retrieval Augmented Generation
Global Explanation
Probing
Analyze the model’s representation by decoding its embedded information Probing can apply to
- Attention heads
- Embeddings
- Different controllable representations
Probing as it applies to text embeddings:
More Granular Level Representation
- categorizing or decoding concepts from individual neurons
- explaining the function of attention heads in natural language
How groups of neurons combine to perform specific tasks
- finding a circuit for indirect object identification
- entity binding
GPT-4 Probing Example
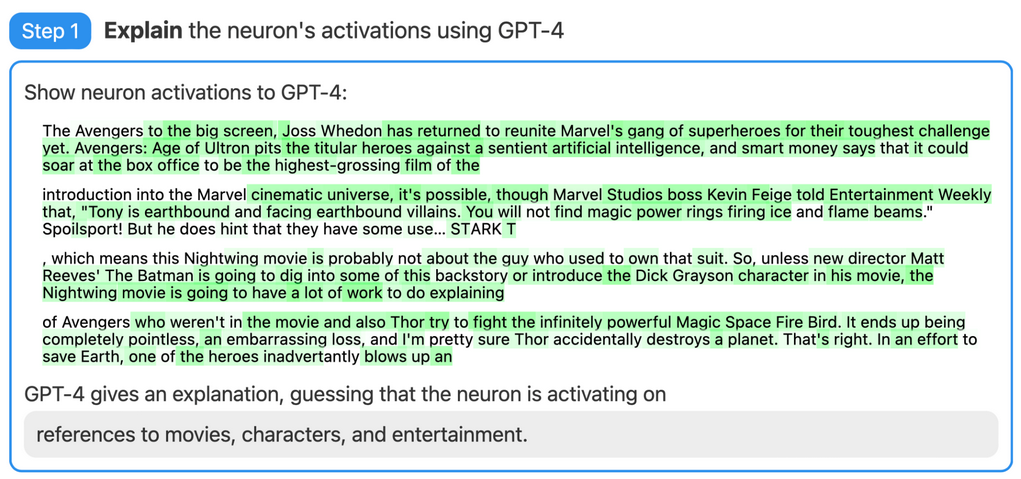



Dataset Explanation
Data set explanation occurs along a spectrum of low-high level techniques:
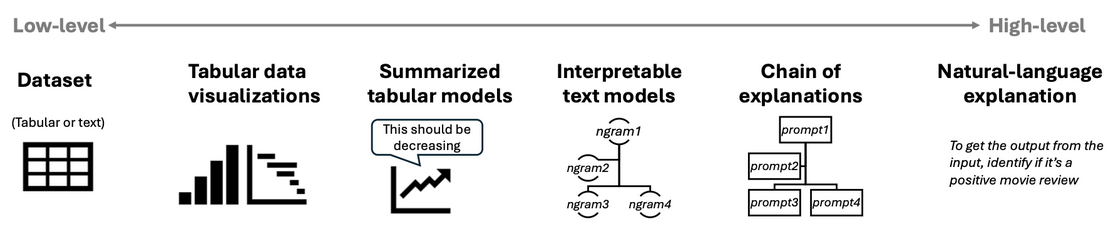
Text Data
Using LLM to build interpretable Linear Models / Decision Trees. Basically just using LLMs to summarize details of less interpretable models.
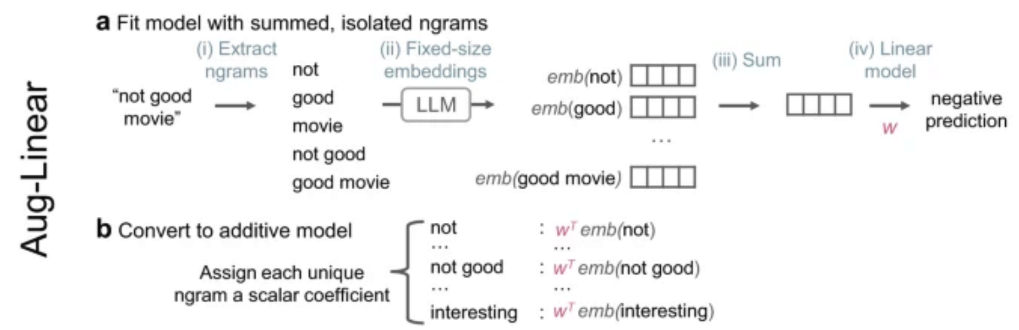 Partially interpretable models via chain of prompts techniques:
Partially interpretable models via chain of prompts techniques:
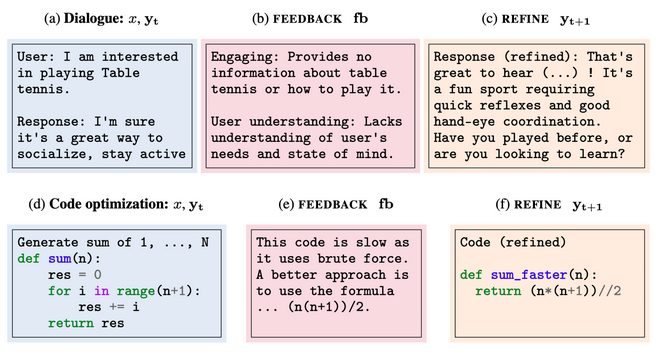
Future Directions
Explanation reliability: prevent hallucinations from leaking in to explanations, ensure that explanations are related to the actual process of the model if asking it to explain itself, implement some kind of verification techniques. Dataset explanation for knowledge discovery: better usages of models to summarize, create and display statistics, and extract knowledge from datasets Interactive explanations: make the process more dynamic and accessible
Claude Model 3 Family: Opus, Sonnet, Haiku
Based on the Claude Product release paper, found here
Introduction
- The Claude 3 family of models encompasses Opus, Sonnet, and Haiku variants, each excelling in reasoning, mathematics, coding, multi-lingual understanding, and vision quality.
- A key enhancement across the family is the inclusion of multimodal input capabilities with text output.
- Claude 3 Opus delivers strong performance in reasoning, mathematics, and coding.
- Claude 3 Sonnet demonstrates increased proficiency in nuanced content creation, analysis, forecasting, accurate summarization, and handling scientific queries.
- Claude 3 Haiku stands out as the fastest and most affordable option in its intelligence category, while also featuring vision capabilities.
Model Setup
- Training Data:
- A proprietary blend of publicly accessible data sourced from the Internet as of August 2023.
- Non-public information obtained from third-party sources.
- Data acquired through data labeling services and paid contractors.
- Internally generated data.
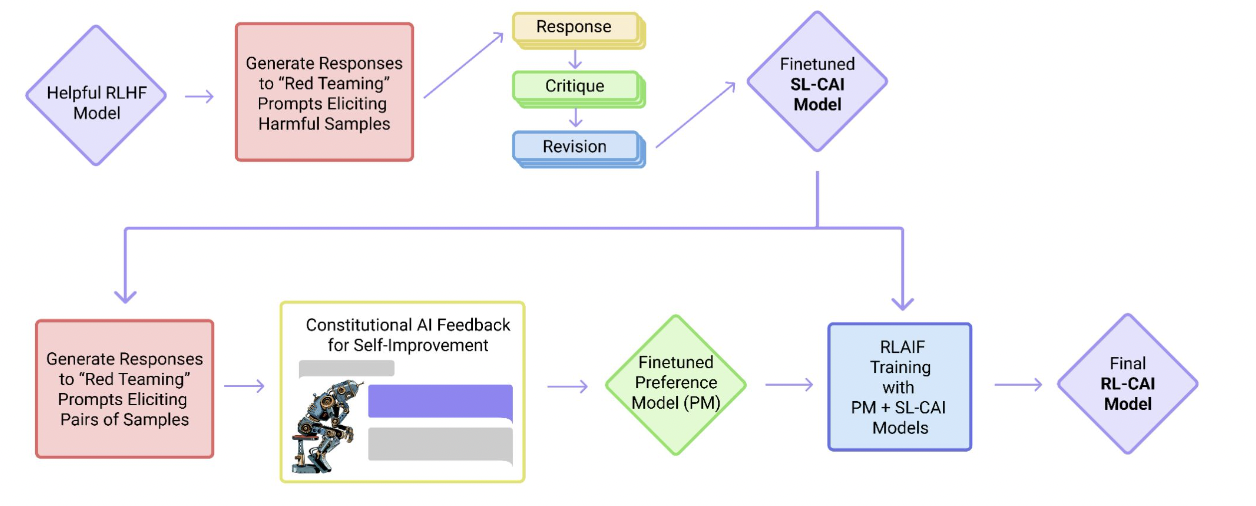
- Training Details:
- Implementation of Constitutional AI to align Claude’s learning process with human values during reinforcement learning.
- Constitutional AI Enhancement:
- Claude’s constitution has been augmented to promote respect for disability rights.
- This addition stems from research on Collective Constitutional AI, aimed at aligning Claude with human values during reinforcement learning.
Security Measures:
- Protected by two-party controls.
- All users require an authorized account for access.
- Continuous 24/7 monitoring of systems.
- Immediate alert response.
- Implementation of endpoint hardening measures.
- Stringent controls on data storage and sharing.
- Thorough personnel vetting procedures.
- Enhancement of physical security measures.
Social Responsibility Focus:
- Implementation of Constitutional AI to ensure alignment with human values.
- Commitment to labor standards and fair treatment of workers.
- Dedication to sustainability practices and minimizing environmental impact.
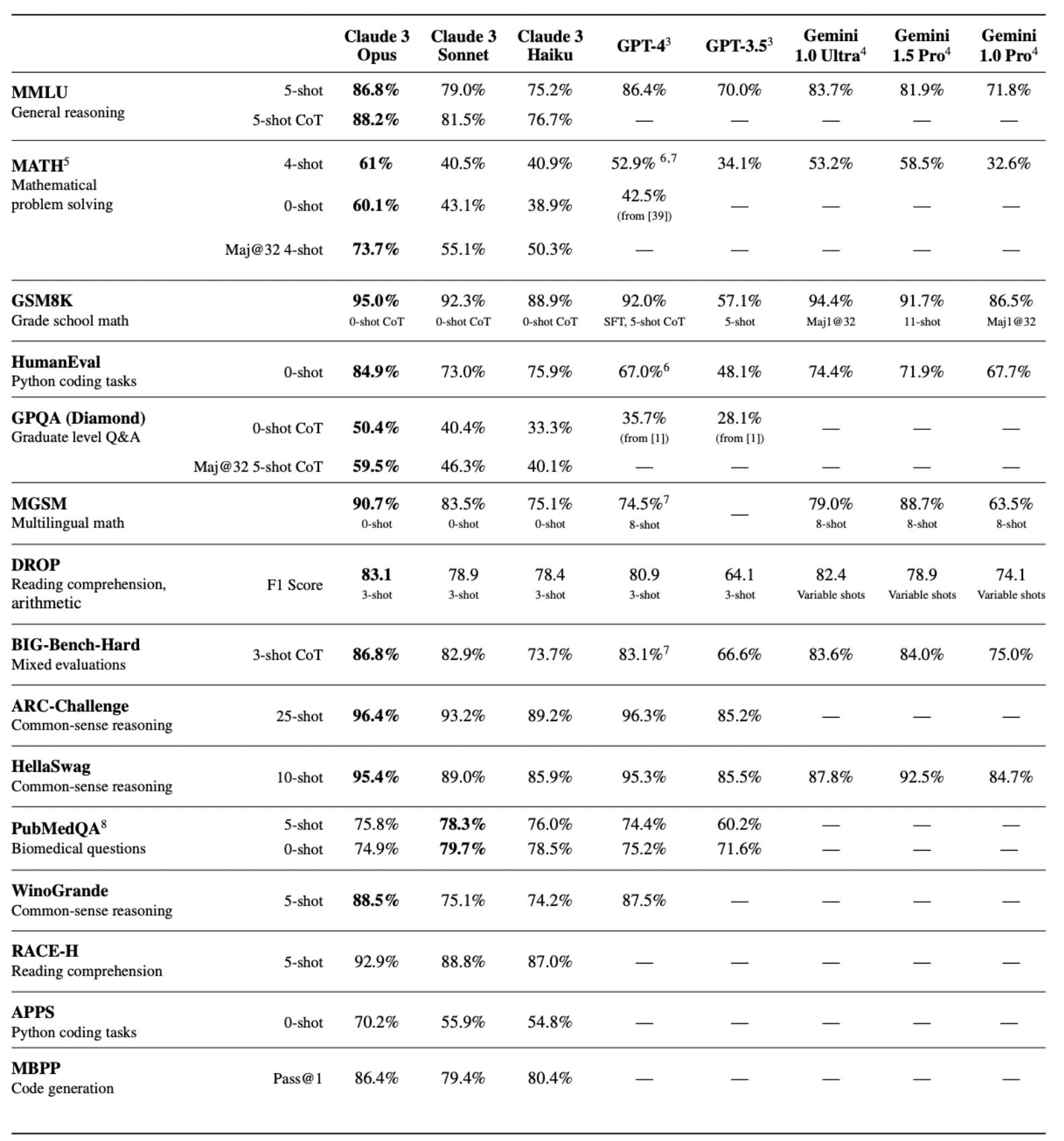
Evaluation Criteria:
- Reasoning: Assessing the model’s ability to logically infer and deduce information.
- Multilingual: Evaluating proficiency in understanding and generating content in multiple languages.
- Long Context: Gauging comprehension and coherence in handling lengthy passages or conversations.
- Honesty: Examining the model’s commitment to truthfulness and accuracy in its responses.
- Multimodal: Assessing capabilities to process and generate content across multiple modalities such as text, images, and audio.
Evaluation
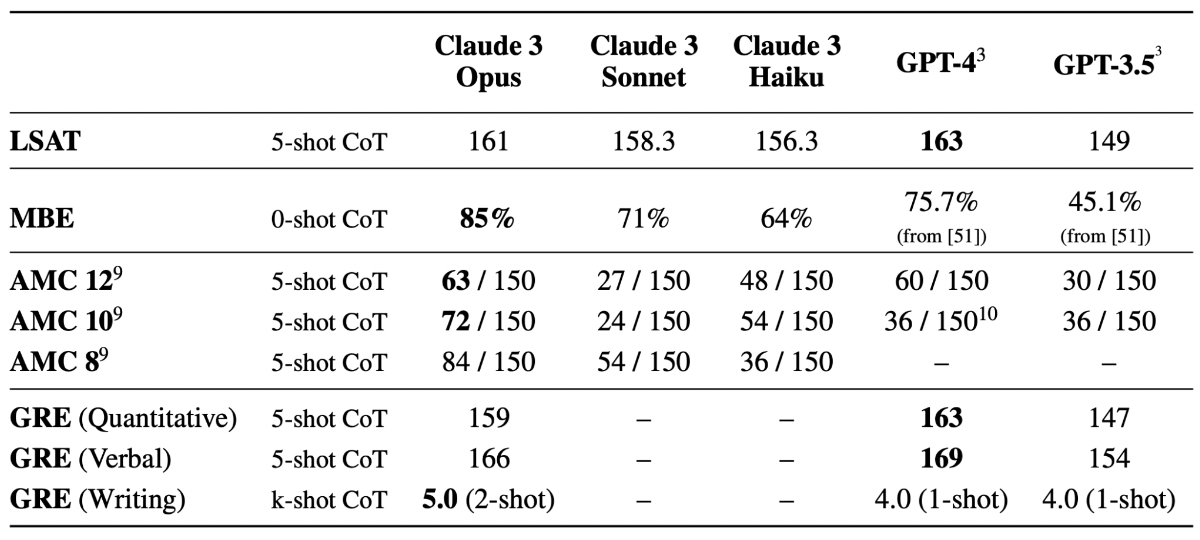
- Law School Admission Test (LSAT): Evaluates critical thinking, analytical reasoning, and reading comprehension skills for admission to law schools.
- Multistate Bar Exam (MBE): Assesses knowledge of common law principles and legal reasoning skills for bar admission.
- American Mathematics Competition (AMC): Tests mathematical problem-solving abilities and reasoning skills among high school students.
-
Graduate Record Exam (GRE): Measures verbal reasoning, quantitative reasoning, analytical writing, and critical thinking skills for graduate school admission.
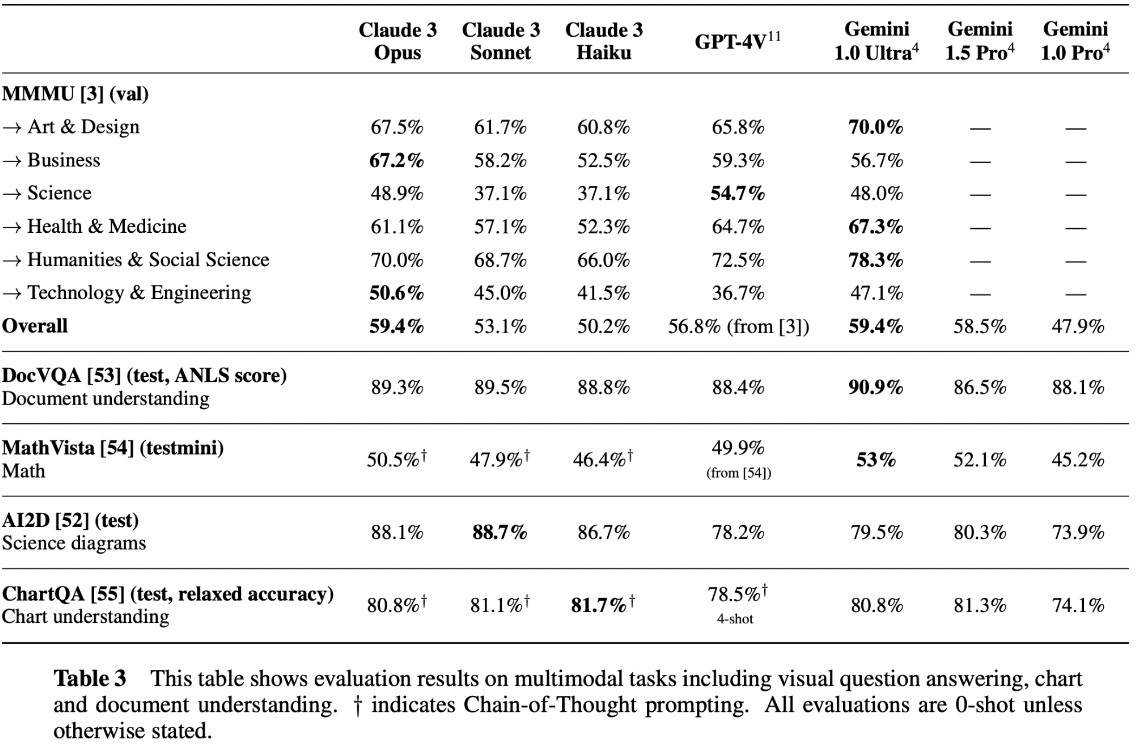
- Visual capabilities
Evaluation - Behavior Design:
- Refusals: Assessment of the chatbot’s ability to appropriately refuse or decline user requests or commands.
- Wildchat Dataset: Examination of toxic user inputs and chatbot responses to ensure appropriate handling of such interactions.
- XSTest Evaluation: Evaluation of the chatbot’s performance using the XSTest evaluation framework, which focuses on various aspects of conversational AI systems, including response quality, engagement, and user satisfaction.
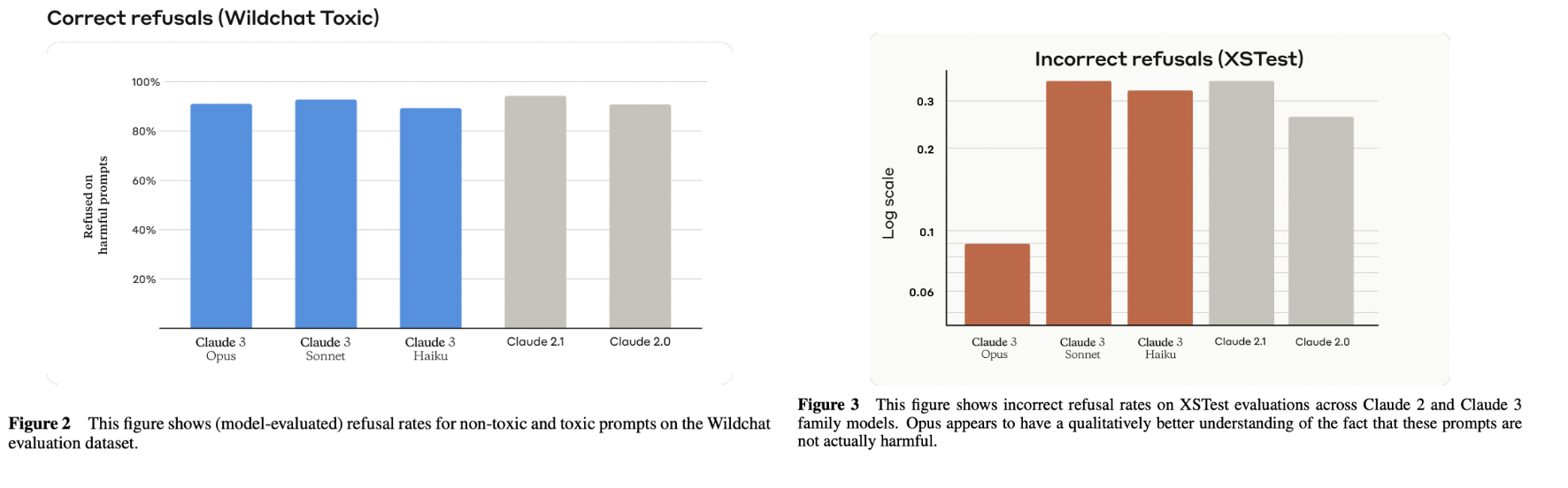
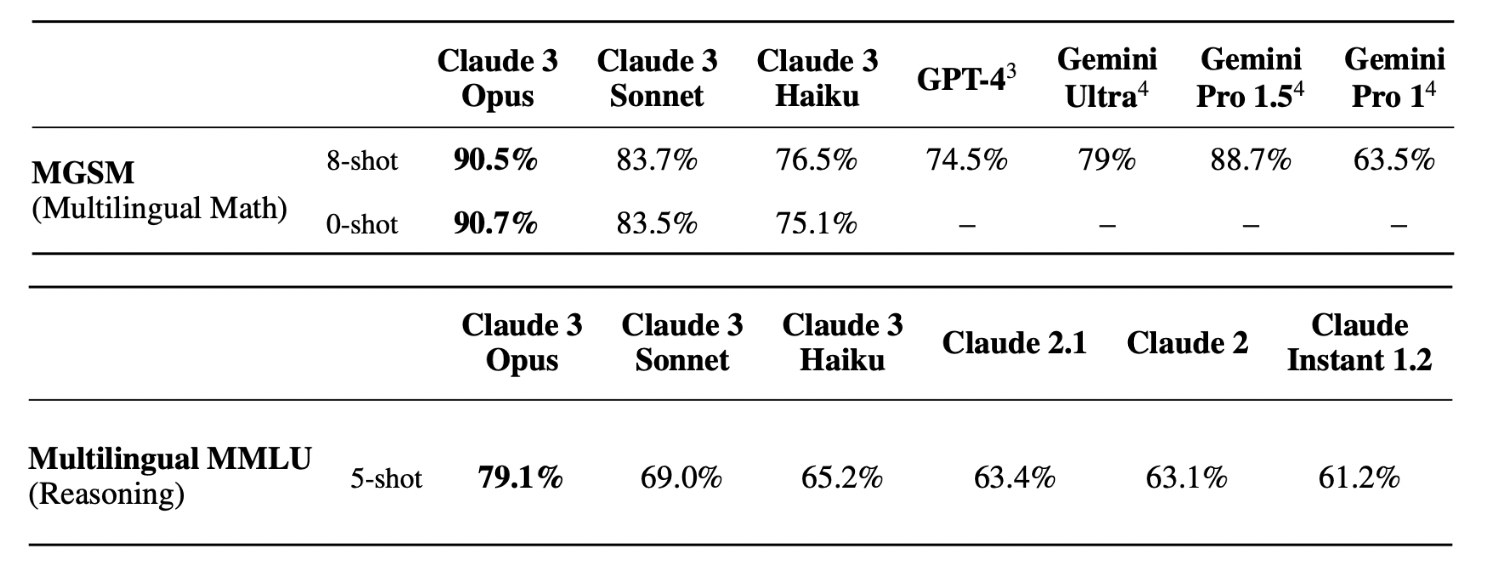
Evaluation - Multilingual:
- Multilingual Reasoning and Knowledge: Assessment of the chatbot’s ability to reason and apply knowledge across multiple languages.
- Multilingual Math: Evaluation of the chatbot’s proficiency in solving mathematical problems and providing explanations in different languages.
- Multilingual MMLU (Mean Length of Utterance): Measurement of the average length of the chatbot’s responses across various languages, serving as an indicator of linguistic complexity and fluency.
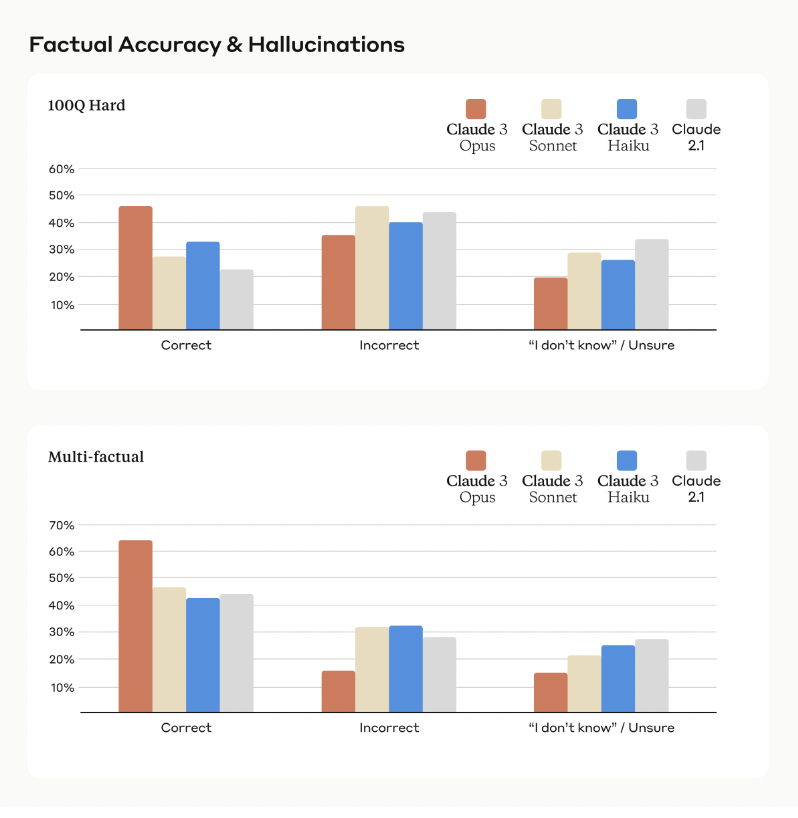
Evaluation - Factual Accuracy:
Assessment of the chatbot’s ability to provide accurate and reliable information across a wide range of topics and domains, ensuring that responses are factually correct and supported by credible sources when applicable.
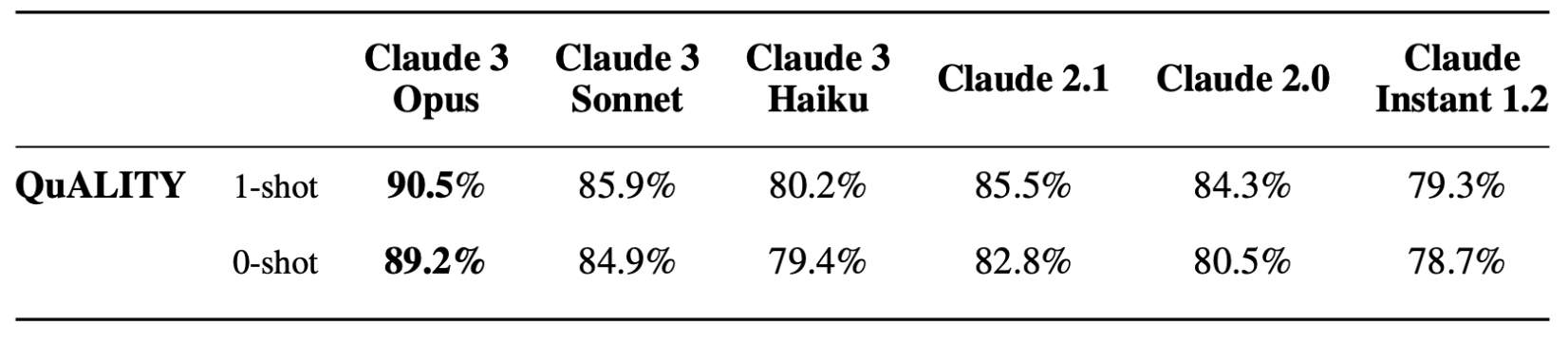
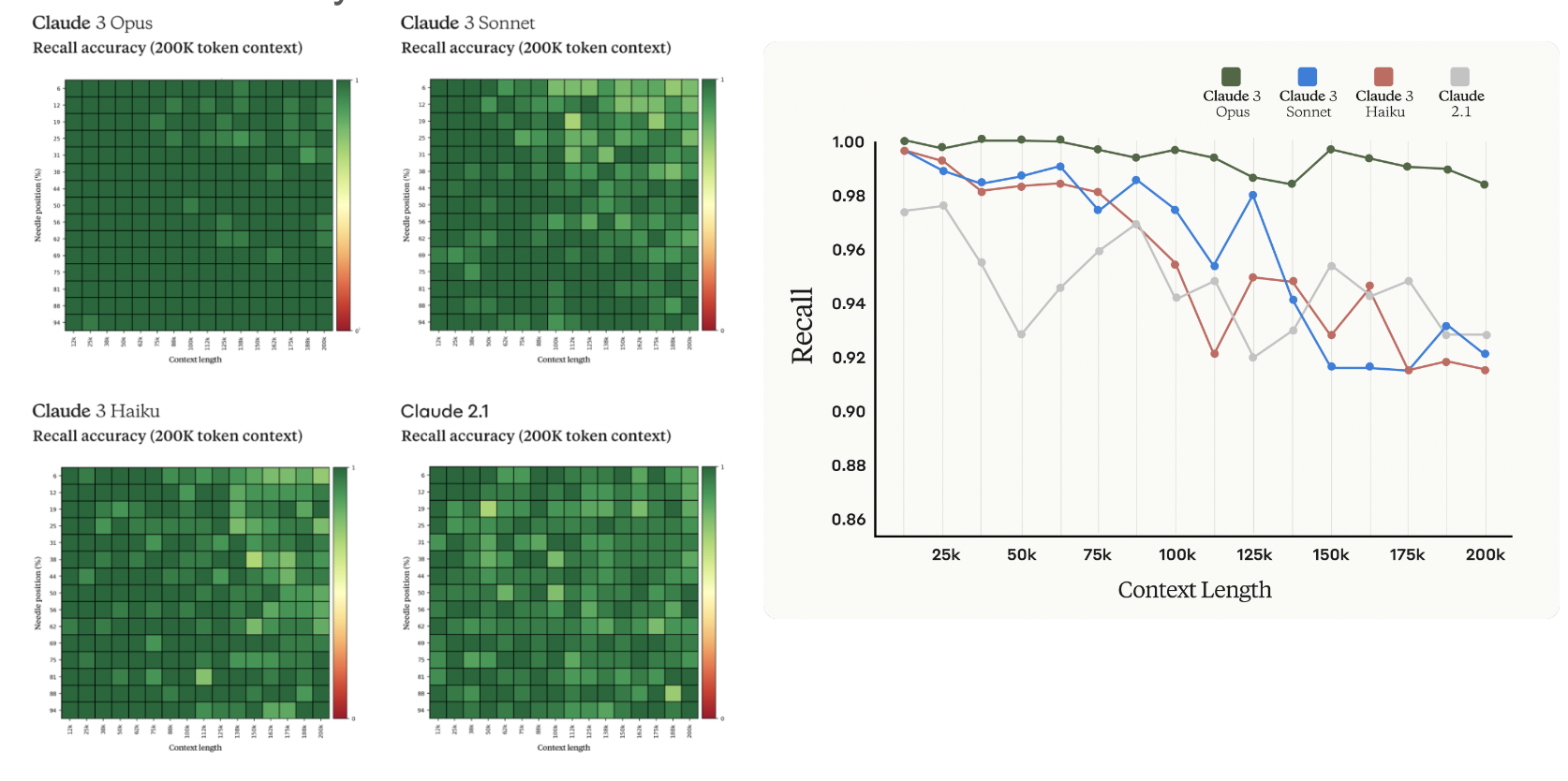
Evaluation - Long Context Performance
Quality benchmark: Multiple-choice question-answering dataset; averaging around 5,000 tokens
Evaluation - Long Context Performance: Needle In A Haystack
- Needle In A Haystack: Test scenario where a target sentence (the “needle”) is inserted into a corpus of documents (the “haystack”). A question is then asked to retrieve the fact contained in the needle. For example:
- Needle: “The best thing to do in San Francisco is to eat a sandwich and sit in Dolores Park on a sunny day.”
- Question: “What is the best thing to do in San Francisco?”
- This evaluation assesses the chatbot’s ability to accurately retrieve relevant information from a longer context or passage.
Knowledge Conflicts for LLMs: A Survey
Based on the paper of the same name, found here
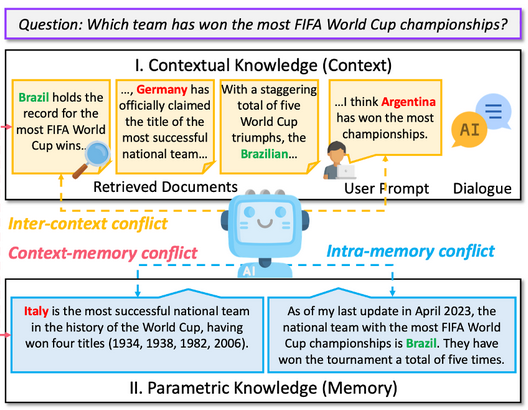
Knowledge Conflicts can be broadly divided into 3 categories:
- Context-memory conflict: stems from a discrepancy between the context and parametric knowledge.
- Inter-context conflict: when external documents provide conflicting information.
- Intra-memory conflict: discrepancies in a language model’s knowledge stem from training data inconsistencies.
Terminology Note:
- context = contextual knowledge = knowledge in retrieved document
- memory = parametric knowledge = knowledge in pretraining data
Overview Diagram:
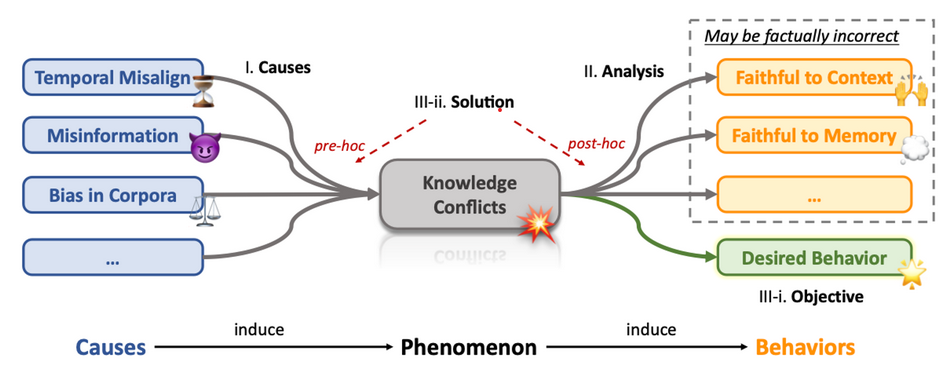
Methodology: Cause of conflict => Analyzing LLM behavior under conflict => Solutions
Context-memory conflict
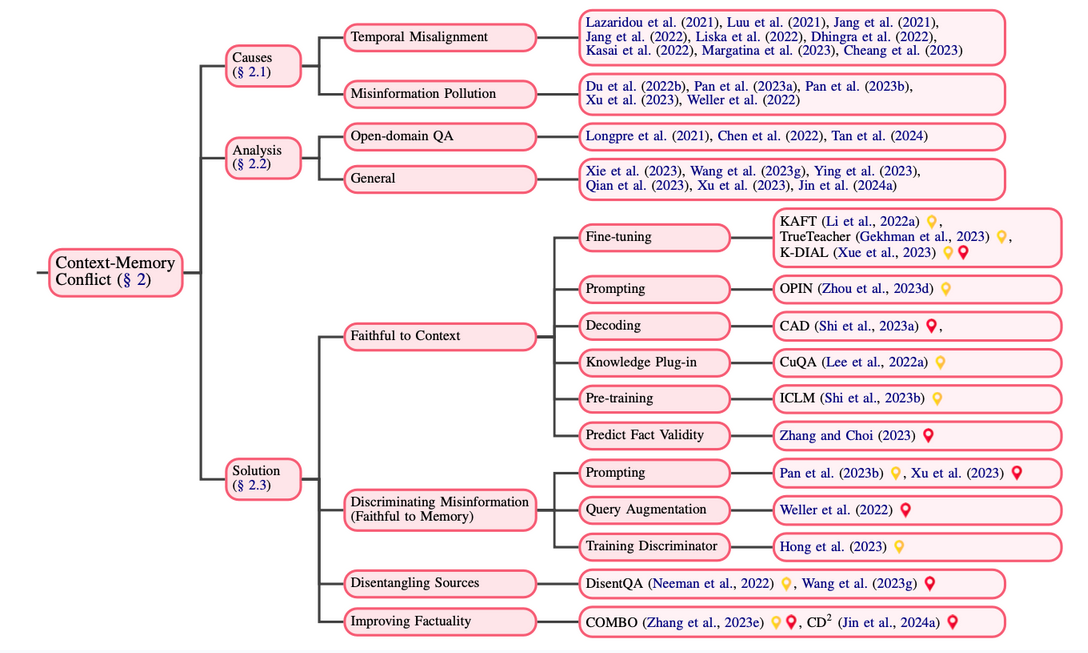
This stems from a discrepancy between the context and parametric knowledge and is the most extensively investigated among the three types of conflicts.
- Causes:
-
Temporal Misalignment: Models trained on past data may not accurately represent current or future realities. (The up-to-date contextual information is considered accurate. Pre-training data information is out-of-date.)
-
Misinformation Pollution: Introducing false or misleading information into a model’s data can spread misinformation if the model doesn’t critically assess these inputs. (The contextual information contains misinformation and is therefore considered incorrect. Web information is polluted. )
-
-
Analysis of Model Behaviors:
-
Open-domain question answering (ODQA) setup: (1) In ODQA research: QA models sometimes depend too much on what they’ve already learned, ignoring conflicting external context. (2) Recent studies: Bigger models like ChatGPT often blend what they know with similar outside information, even if it doesn’t fully match.
-
General setups: LLMs might take in new information that contradicts their knowledge, yet they usually prefer matching information, struggle with conflicts, and favor logic over factual accuracy.
-
- Solutions:
- Faithful to Context:
- Align with contextual knowledge, focusing on context prioritization.
- Discriminating Misinformation (Faithful to Memory):
- Favor learned knowledge over questionable context with skepticism.
- Disentangling Sources:
- Separate context and knowledge to give clear, distinct answers.
- Improving Factuality:
- Strive for a response that combines context and learned knowledge for a truer solution.
Inter-context conflict: when external documents provide conflicting information.
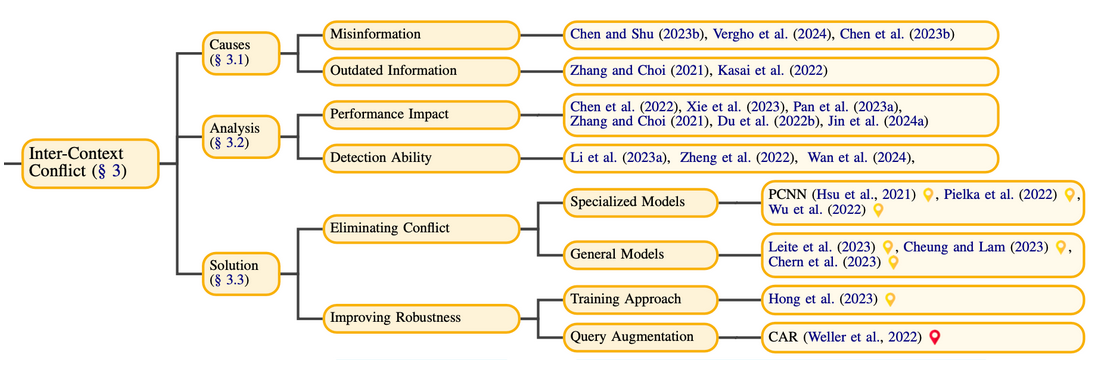
- Causes:
- Misinformation
- RAG poses the risk of including documents containing mis information.
- Outdated Information
- Contain updated and outdated information from the network simultaneously
- Misinformation
- Analysis:
- Performance Impact
Language models are vulnerable to misinformation:
- These models prioritize information that is directly relevant to the query and consistent with their built in parametric knowledge.
- There is a noticeable bias in LLMs towards evidence that matches their inherent parametric memory.
- LLMs tend to focus on information related to more popular entities and answers supported by a larger body of documents within the context.
-
As the number of conflicting pieces of information increases, LLMs face greater difficulties in logical reasoning.
- Detection Ability
- Conversational Contradictions
- Contradictory Documents
- Document Credibility
- Truth vs. Misinformation
- Solution:
- Eliminating Conflict
- General Models for Fact-Checking:
- Improving Robustness
Intra-memory conflict: discrepancies in a language model’s knowledge stem from training data inconsistencies.
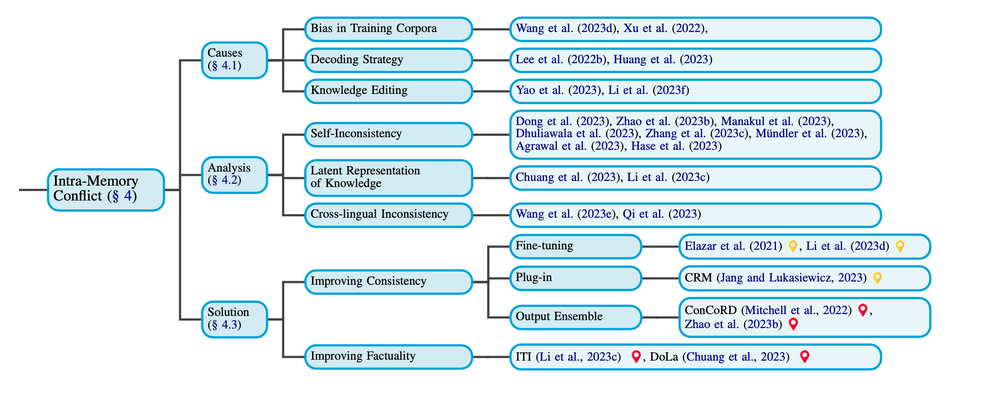
Causes of Intra-Memory (IM) Conflict:
- Bias in Training Corpora
- Pre -trained Corpus from website may leading to misinformation.
- LLM tend to encode superficial associations prevalent within their training data.
- Decoding Strategy
- Most strategies are deterministic and stochastic sampling methods. For the stochastic sampling, the nature of it is “uncertainty”, causing LLMs to produce entirely different content, even when provided with the same context
- Knowledge Editing
- General method will be modifying a small scope of the knowledge encoded in LLMs, resulting in LLMs producing inconsistent responses when dealing with the same piece of knowledge in varying situations.
Self Inconsistency
- Knowledge Consistency Assessment:
- Elazar et al. (2021) developed a method to assess the knowledge consistency of language models, showed poor consistency across these models, with accuracy rates hovering between 50% and 60%.
- Hase et al. (2023) expanded on this by using a more diverse dataset and confirmed that models like RoBERTa-base and BART-base exhibit significant inconsistencies, especially in paraphrase contexts.
- Inconsistency in Question Answering:
- Inconsistencies across multiple open-source LLMs in various contexts.
- LLMs may initially provide an answer to a question but then deny it upon further inquiry. In Close-Book Question Answering tasks, Alpaca-30B was only consistent in 50% of the cases.
Layered Knowledge Representation: Studies show that LLMs store basic information in early layers and semantic information in deeper layers.Later research found factual knowledge is concentrated in specific transformer layers, leading to inconsistencies across layers.
Discrepancy in Knowledge Expression: Li et al. (2023c) revealed an issue where correct knowledge within an LLM parameters may not be accurately expressed during generation. Their experiments showed a 40% gap between knowledge probe accuracy and generation accuracy.
Cross-lingual Inconsistency: LLMs exhibit cross-lingual inconsistencies, with distinct knowledge sets for different languages, leading to discrepancies in information provided across languages.
- Improving Consistency
- Fine-tuning - ie, using a loss with the combination of the consistency loss and standard MLM loss.
- Plug-in - utilizing word-definition pairs from dictionaries to retrain language models and improve their comprehension of symbolic meanings
- Output Ensemble
- Improving Factuality - Focus on improving knowledge across layers. Examples:
- Dola
- ITI
Key Challenges for IM Conflicts:
- Knowledge Conflicts in the Wild - Knowledge conflicts often arise in RALMs (Retrieval-Augmented Language Models) when the models retrieve conflicting information directly from the Web.
- Traditionally, knowledge conflicts have been studied through artificially generated incorrect or misleading information, which may not fully represent real-world scenarios.
- There’s a noted gap in current experimental setups for studying knowledge conflicts, leading to concerns about the applicability of findings from such studies to practical situations.
- Solution at a Finer Resolution
- Evaluation on Downstream Tasks
- Interplay among the Conflicts - From investigating conflicts of a singular type to multi-type
- Explainability - more microscopic examinations to better comprehend how models decide when encounter conflicts
- Multilinguality
- By examining LLMs to address knowledge conflicts in non-English prompts
- Cross-language knowledge conflicts. Solutions could include employing translation systems
- Multimodality - For instance,textual documents might clash with visual data, or the tone of an audio clip might contradict the con tent of an accompanying caption. multimodal knowledge conflicts could focus on crafting advanced LLMs skilled in cross-modal rea- soning and conflict resolution across diverse data types.