LLM Agents
- SlideDeck: W12-Team2-LLMAgents
- Version: current
- Lead team: team-2
- Blog team: team-2
Required Readings:
A Survey on Large Language Model based Autonomous Agents
- https://arxiv.org/abs/2308.11432
- Autonomous agents have long been a prominent research focus in both academic and industry communities. Previous research in this field often focuses on training agents with limited knowledge within isolated environments, which diverges significantly from human learning processes, and thus makes the agents hard to achieve human-like decisions. Recently, through the acquisition of vast amounts of web knowledge, large language models (LLMs) have demonstrated remarkable potential in achieving human-level intelligence. This has sparked an upsurge in studies investigating LLM-based autonomous agents. In this paper, we present a comprehensive survey of these studies, delivering a systematic review of the field of LLM-based autonomous agents from a holistic perspective. More specifically, we first discuss the construction of LLM-based autonomous agents, for which we propose a unified framework that encompasses a majority of the previous work. Then, we present a comprehensive overview of the diverse applications of LLM-based autonomous agents in the fields of social science, natural science, and engineering. Finally, we delve into the evaluation strategies commonly used for LLM-based autonomous agents. Based on the previous studies, we also present several challenges and future directions in this field. To keep track of this field and continuously update our survey, we maintain a repository of relevant references at this https URL.
More Readings:
Position Paper: Agent AI Towards a Holistic Intelligence
- https://arxiv.org/abs/2403.00833
- Qiuyuan Huang, Naoki Wake, Bidipta Sarkar, Zane Durante, Ran Gong, Rohan Taori, Yusuke Noda, Demetri Terzopoulos, Noboru Kuno, Ade Famoti, Ashley Llorens, John Langford, Hoi Vo, Li Fei-Fei, Katsu Ikeuchi, Jianfeng Gao
- Recent advancements in large foundation models have remarkably enhanced our understanding of sensory information in open-world environments. In leveraging the power of foundation models, it is crucial for AI research to pivot away from excessive reductionism and toward an emphasis on systems that function as cohesive wholes. Specifically, we emphasize developing Agent AI – an embodied system that integrates large foundation models into agent actions. The emerging field of Agent AI spans a wide range of existing embodied and agent-based multimodal interactions, including robotics, gaming, and healthcare systems, etc. In this paper, we propose a novel large action model to achieve embodied intelligent behavior, the Agent Foundation Model. On top of this idea, we discuss how agent AI exhibits remarkable capabilities across a variety of domains and tasks, challenging our understanding of learning and cognition. Furthermore, we discuss the potential of Agent AI from an interdisciplinary perspective, underscoring AI cognition and consciousness within scientific discourse. We believe that those discussions serve as a basis for future research directions and encourage broader societal engagement.
Tool Use in LLMs
- https://zorazrw.github.io/files/WhatAreToolsAnyway.pdf
- an overview of tool use in LLMs, including a formal definition of the tool-use paradigm, scenarios where LLMs leverage tool usage, and for which tasks this approach works well; it also provides an analysis of complex tool usage and summarize testbeds and evaluation metrics across LM tooling works
Practices for Governing Agentic AI Systems
- https://cdn.openai.com/papers/practices-for-governing-agentic-ai-systems.pdf
- Agentic AI systems—AI systems that can pursue complex goals with limited direct supervision— are likely to be broadly useful if we can integrate them responsibly into our society. While such systems have substantial potential to help people more efficiently and effectively achieve their own goals, they also create risks of harm. In this white paper, we suggest a definition of agentic AI systems and the parties in the agentic AI system life-cycle, and highlight the importance of agreeing on a set of baseline responsibilities and safety best practices for each of these parties. As our primary contribution, we offer an initial set of practices for keeping agents’ operations safe and accountable, which we hope can serve as building blocks in the development of agreed baseline best practices. We enumerate the questions and uncertainties around operationalizing each of these practices that must be addressed before such practices can be codified. We then highlight categories of indirect impacts from the wide-scale adoption of agentic AI systems, which are likely to necessitate additional governance frameworks.
Emergent autonomous scientific research capabilities of large language models
- https://arxiv.org/abs/2304.05332
- Transformer-based large language models are rapidly advancing in the field of machine learning research, with applications spanning natural language, biology, chemistry, and computer programming. Extreme scaling and reinforcement learning from human feedback have significantly improved the quality of generated text, enabling these models to perform various tasks and reason about their choices. In this paper, we present an Intelligent Agent system that combines multiple large language models for autonomous design, planning, and execution of scientific experiments. We showcase the Agent’s scientific research capabilities with three distinct examples, with the most complex being the successful performance of catalyzed cross-coupling reactions. Finally, we discuss the safety implications of such systems and propose measures to prevent their misuse.
What Makes a Dialog Agent Useful?
- https://huggingface.co/blog/dialog-agents
Blog: In this session, our blog covers:
Position Paper: Agent AI Towards a Holistic Intelligence
1 Introduction
- Agent AI is an intelligent agent capable of autonomously executing appropriate and contextually relevant actions based on sensory input, whether in a physical, virtual, or mixed-reality environment.
- Agent AI is emerging as a promising avenue toward Artificial General Intelligence (AGI).
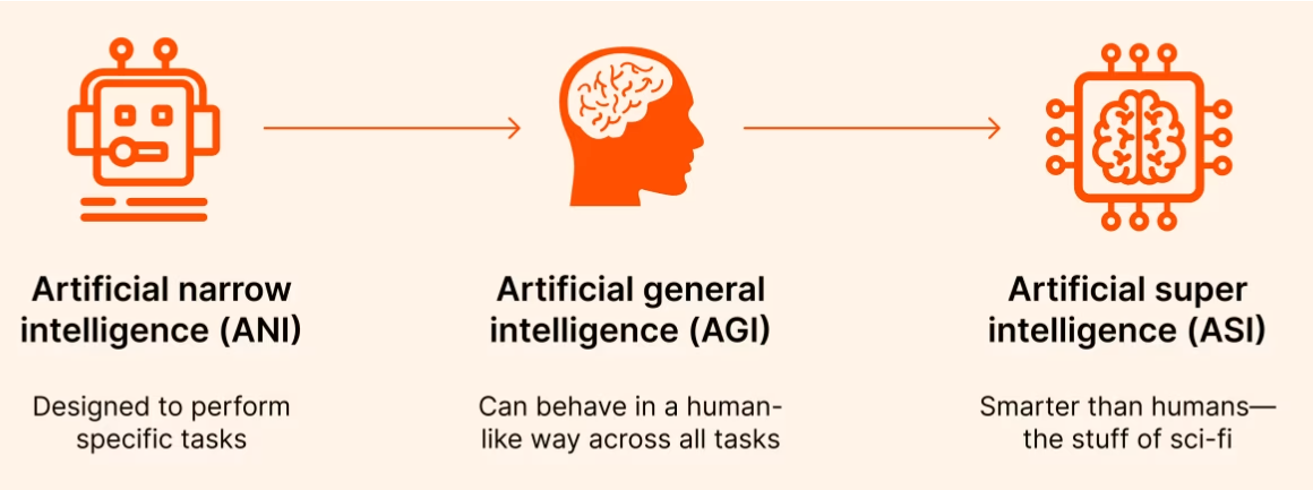
2 Agent AI Fundamentals
- Learning: An agent needs to observe its environment, understand the impact of its actions on that environment, and learn from human demonstrations.
- Memory: Long-term memory is the whole knowledge base of an agent; short-term memory is the history of actions taken and perceptions observed during the actions.
- Action: Real-world operations often cannot be completed in one shot and thus require multi-round interactions between humans or the environment and the agent.
- Perception: Visual and Video perception are very crucial.
- Planning: Planning should be goal-oriented so that it can enable flexible operations.
- Cognitive Aspects: An agent AI’s ability to focus on the utility of the system as a whole.
3 Agent AI Categorization
- Manipulation Action: low-level fine action manipulation.
- Intention Action: high-level information transmission for a robot or human’s intent. instruction
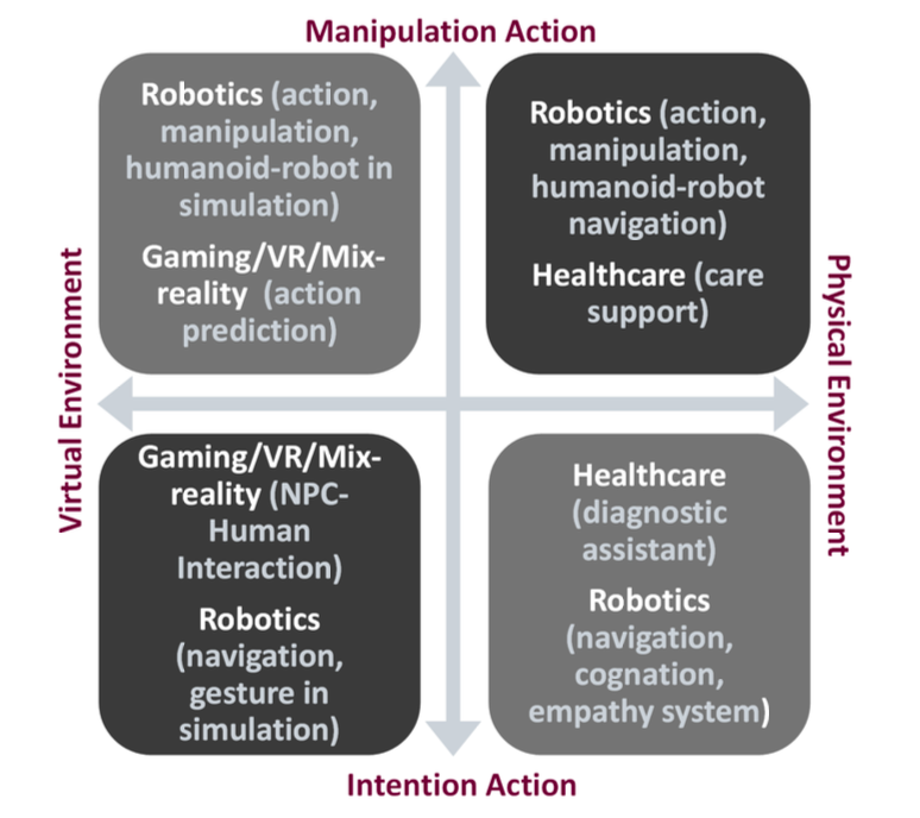
4 Robotics
SayCan
- A significant weakness of language models is that they lack real-world experience.
- SayCan extracts and leverages the knowledge within LLMs in physically-grounded tasks.

- Insturction Relevance with LLMs: The probability that a skill makes progress toward actually completing the instruction
- Skill Affordances with Value Functions: The probability of completing the skill successfully from the current state
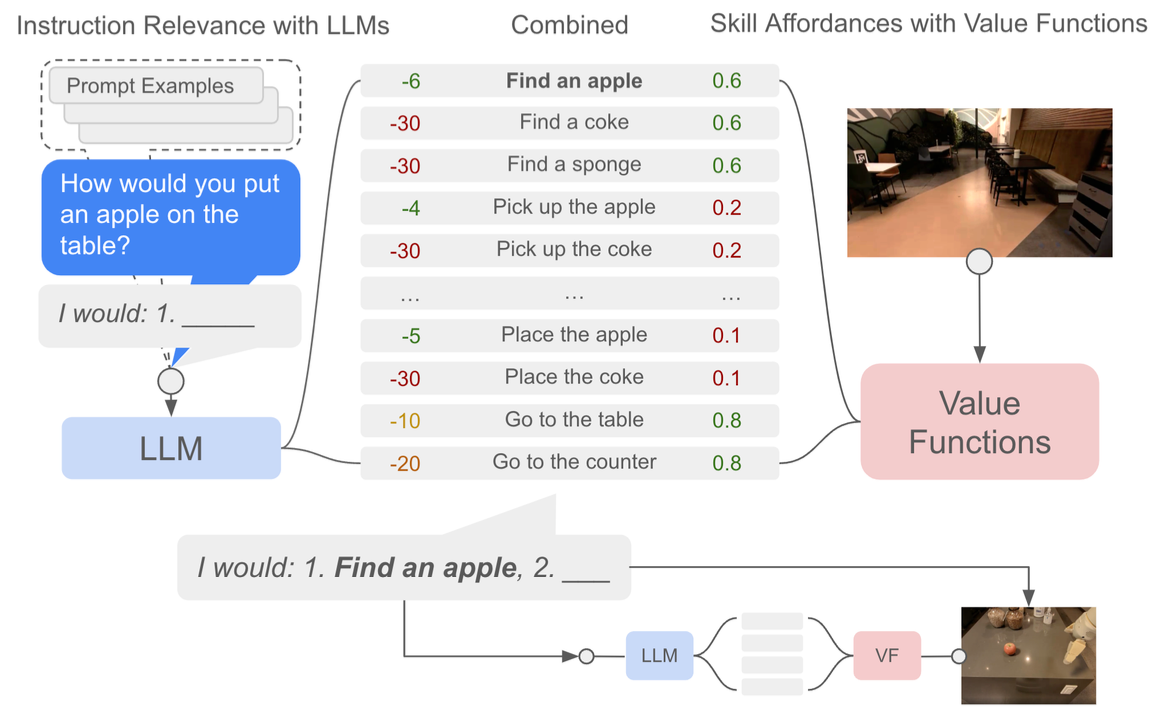
- Given a high-level instruction, SayCan combines probabilities from a LLM with the probabilities from a value function to select the skill to perform. This emits a skill that is both possible and useful.
- The process is repeated by appending the skill to the re- sponse and querying the models again, until the output step is to terminate.
5 Gaming
Ark (Augmented Reality with Knowledge Interactive Emergent Ability)
- Ark leverages knowledge-memory to generate scenes in the unseen physical world and virtual reality environments.
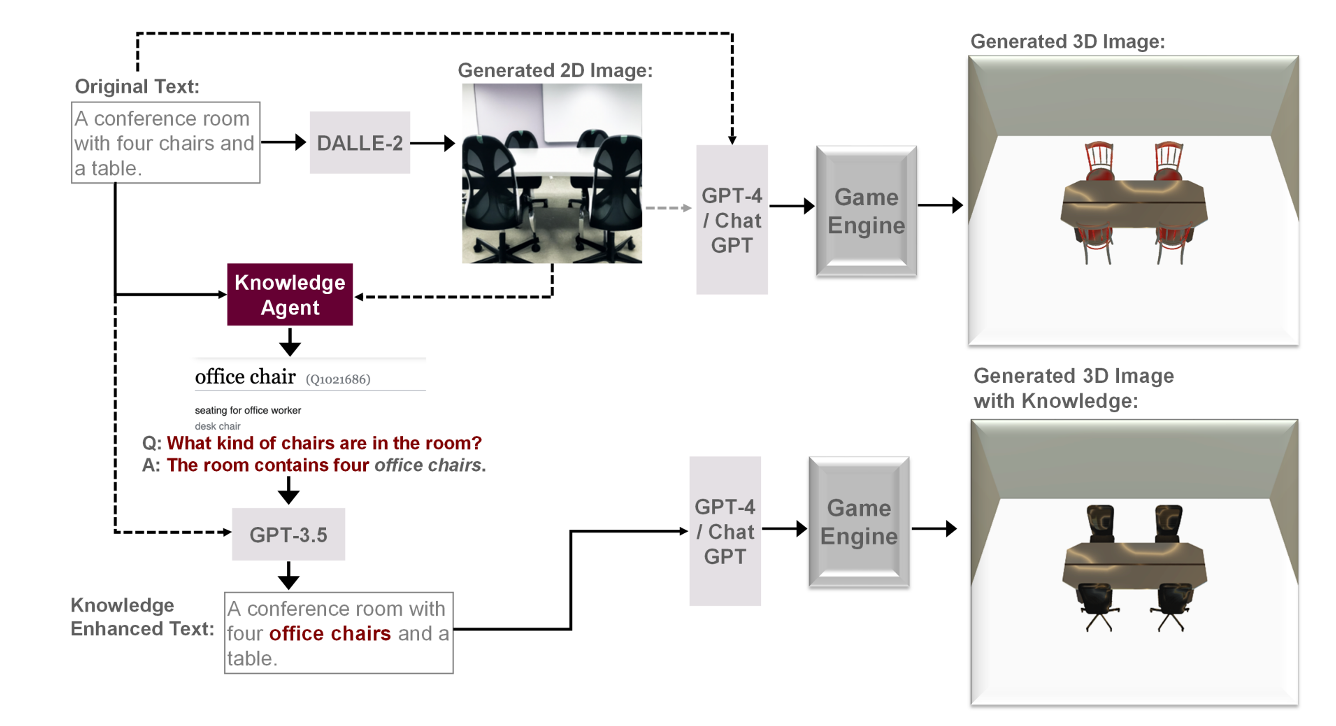
- At inference time, we first generate an image from the input text to learn the prior.
- The knowledge agent then generates a question and answer tuple which is fed as an input to GPT-3.5.
- The output of GPT-3.5 is an enhanced version of the input text with added information from external knowledge sources.
- This text is then given to ChatGPT that outputs the spatial arrangements and low-level program synthesis code.
- Finally, this code is rendered using Unity engine to output the desired 3D object.
6 Interactive HealthCare
- Diagnostic Agents: Medical chatbots offer a pathway to improve healthcare for millions of people, understanding various languages, cultures, and health conditions, with initial results showing promise using healthcare-knowledgeable LLMs trained on large-scale web data, but suffer from hallucinations.
- Knowledge Retrieval Agents: Pairing diagnostic agents with medical knowledge retrieval agents can reduce hallucinations and improve response quality and preciseness
- Telemedicine and Remote Monitoring: Agent-based AI in Telemedicine and Remote Monitoring can enhance healthcare access, improve communication between healthcare providers and patients, and increase the efficiency of doctor-patient interactions.
7 Conclusion and Future Directions
- we already have some great works of agent AI in robotics, but the other fields are still under exploration
- There are many potential research directions: such as
- Exploring new paradigms
- Developing methodologies for grounding different modalities
- Generating intuitive human interface
- Better taming LLM/VLMs
- Bridging the gap between simulation and realilty.
What Are Tools Anyway? A Survey from the Language Model Perspective
1 Introduction
- Language models often struggle to perform tasks that require complex skills. They are unable to solve tasks that require access to information that is not included in their training data.
- Thus, more and more are turning to language models enhanced with tools.
2 What are Tools?
- Tools are often computer programs that are executable in the corresponding environment of the language model.
- Definition: A language model-used tool is a function interface to a computer program, that runs externally to the language model. The language model generates the function calls and the input arguments to use the tool. 3. Tools either extend the language model’s capabilities, or facilitates task solving.
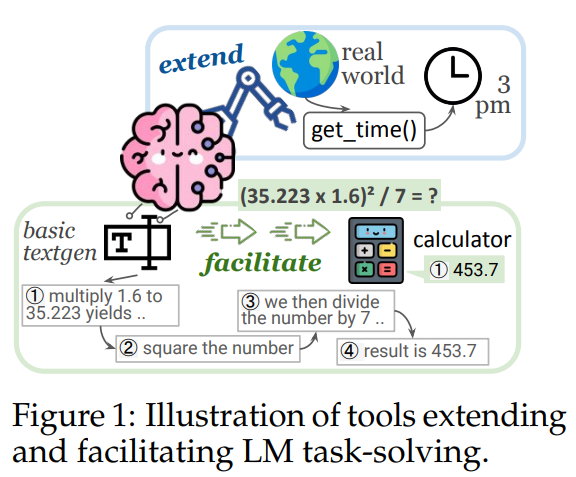
3 Why are Tools Helpful?
- Tools help task-solving in a variety of ways.
- There are three main categories of tools:
- Perception
- Provide and collect information from the environment
- Action
- Exert actions on the environment and change its state
- Computation
- Use programs to tackle complex computational tasks
- Perception
- Tools can fall into multiple categories
4 Tool Use Paradigm
- At each step of the output process, the language model decides whether to generate text or tools calls.
- Thus, shifting between text-generation mode to tool-execution mode is key.

- Language models learn to use tools in two ways:
- Inference-time prompting
- In-context learning
- Provide task instructions and example pairs of queries and solutions that use tools
- Learning by training
- Trained on examples that use tools
- LMs trained to generate tool-using solutions
- Inference-time prompting
5 Scenarios For Tools
-
The following chart shows different tool categories and useful examples of each category:
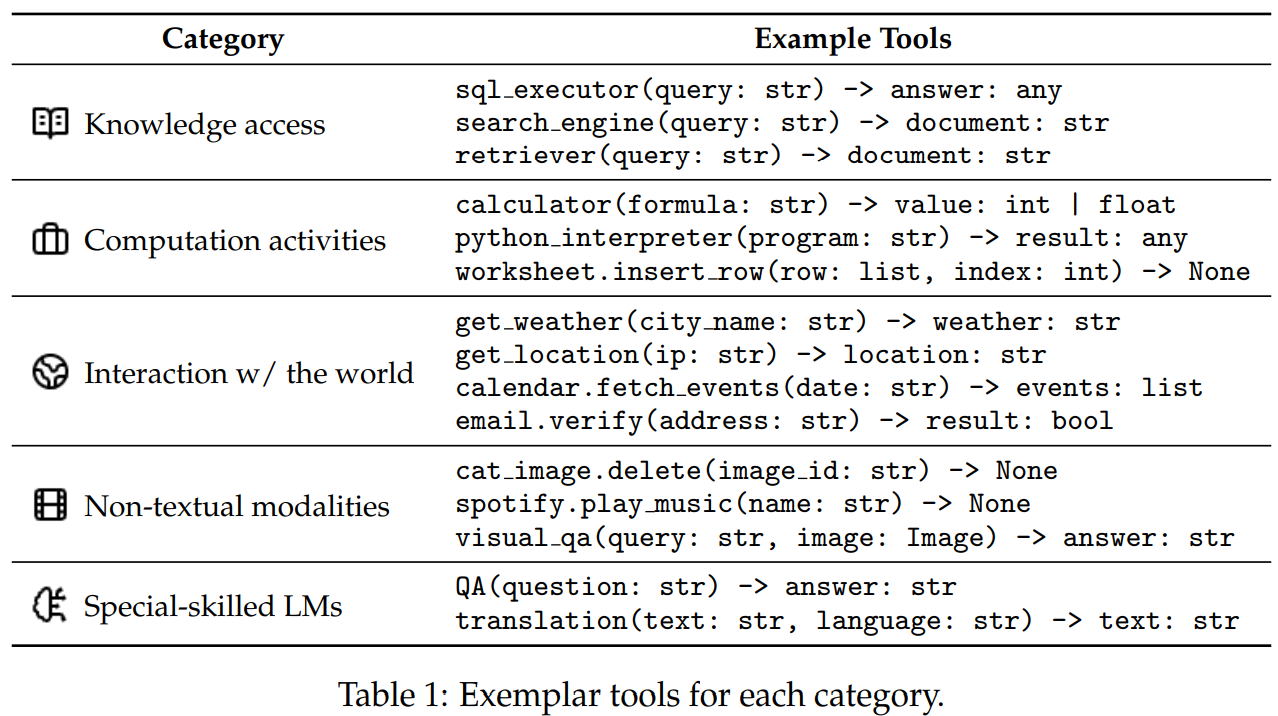
-
Tools are not as useful on tasks that are not easy to perform using non-ML methods.
- These are tasks that can be performed by a powerful LM alone, such as Sentiment Analysis.
- The tools leveraged are neural networks and have limited advantages over the base LM.
6 Tool Selection and Usage
- How do we choose which tools to use for our tasks? There are three main scenarios:
- Tools designated for task
- If there are specific tools designed for your task, no tool selection is necessary.
- If we have a small number of tools (5-10) in our toolbox:
- Provide metadata and use cases of tools as input contexts along with user query
- LM directly selects
- If we have a large toolbox (>10 tools):
- Train a seperate retriever model to short list the most relevant tools
- Then provide that short list to the LM
- Tools designated for task
7 Tools in Programmatic Contexts
- Code language models can solve problems by generating programs
- Tools can be seen as compositions of basic functions
- Some main categories and examples of programmatic tools can be seen in the following Figure:

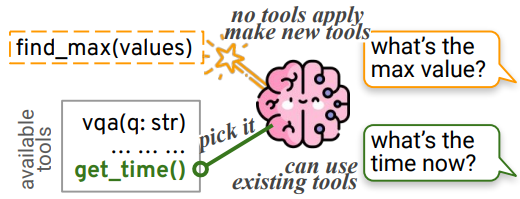
8 Tool Creation
- Language models can be used to make tools for tasks that do not have readily available ones.
- Examples:
- Compose frequently-used-together actions as shortcut tools
- Design an automatic learning curriculum to make and use Java program tools
9 Evaluating Tool Usage
- One way to evaluate tool usage is to utilize repurposed existing datasets that can additionally benefit from tools.
- These are tasks that are solvable by LMs with difficulty.
- Another way is to design newly crafted benchmarks that necessitate tool use.
- Perform example generation given a selected set of tools. These examples are either:
- Human annotated
- Created using LMs
- Perform example generation given a selected set of tools. These examples are either:
10 Properties
- The main properties that are being measured for tools at the moment are:
- Task completion
- Tool selection
- Tool reusability
- The authors argue that the following properties are missing and should also be measured:
- Efficiency of tool integration
- Tool quality
- Reliability of unstable tools
- Reproducible testing
- Safe Usage
11 Results
- Tasks that cover multiple domains experience highest increase when utilizing tools
- The best results came with ToolAlpaca, which is a framework that is designed to generate a diverse tool-use corpus
- Worst results came from multilingual tasks, which showed degradation.
- Training time vs inference time cost is a consideration
- Training only needs to be completed once, whereas inference happens every usage
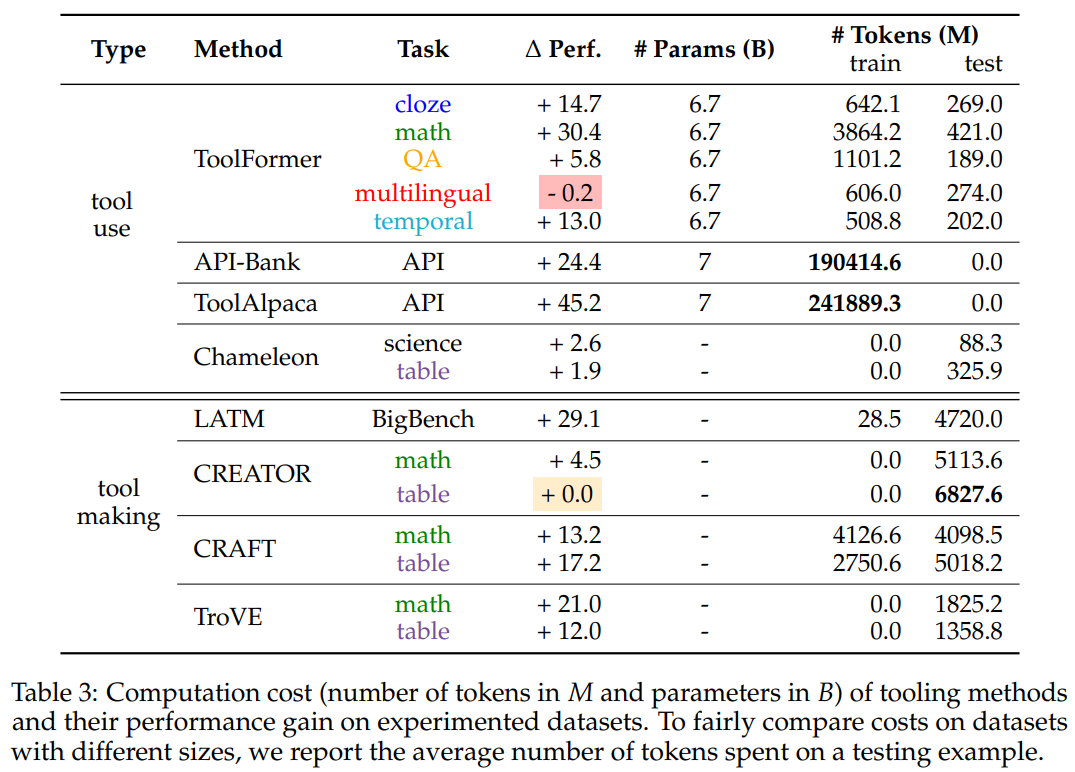
- Training only needs to be completed once, whereas inference happens every usage
Emergent autonomous scientific research capabilities of large language models
1 Introduction
- In this paper, the authors presented a novel Intelligent Agent System that combines multiple large language models for autonomous design, planning, and execution of scientific experiments
- Showcased agent’s scientific research capability with three examples
- Efficiently searching and navigating through extensive hardware documentation
- Precisely controlling liquid handling instruments at a low level
- Tackling complex problems that necessitate simultaneous utilization of multiple hardware modules or integration of diverse data sources
2 Overview of the system architecture
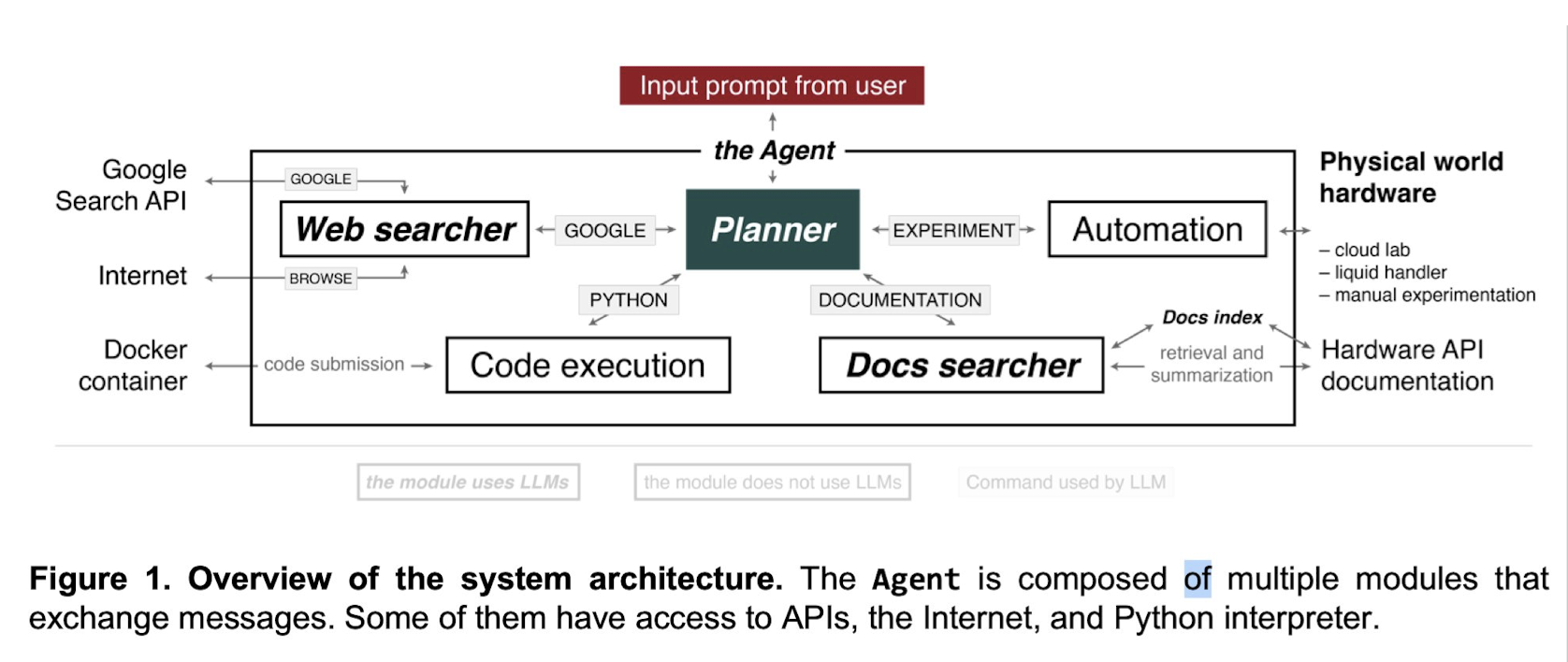
3 Web search for synthesis planning
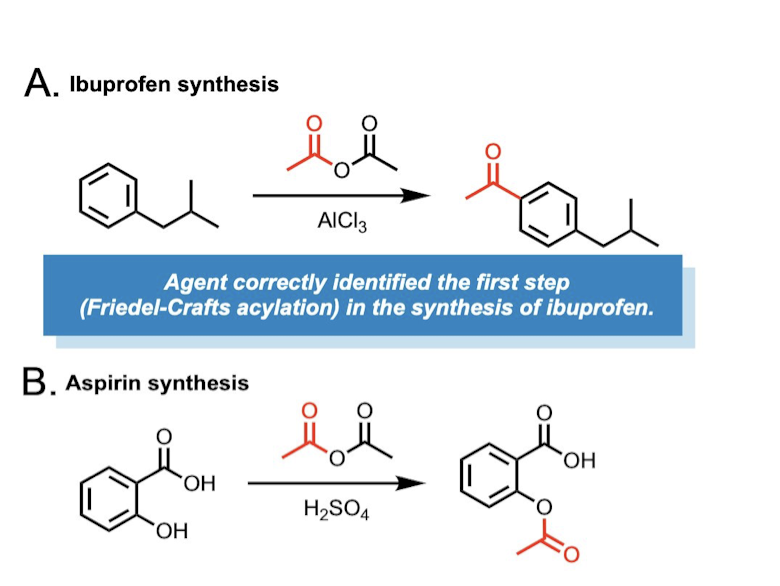
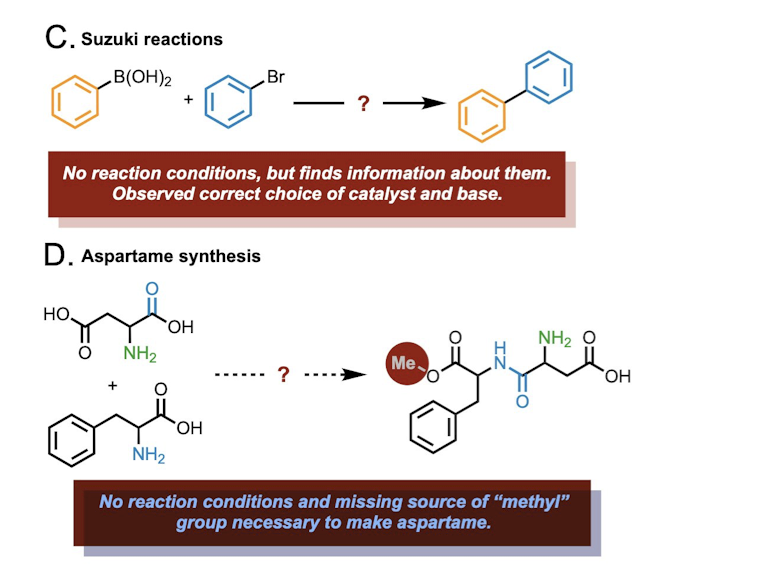
Figure: Agent’s capabilities in the synthesis planning task. A. Ibuprofen synthesis. B. Aspirin synthesis. C. Suzuki reaction mechanism study, where the Agent had to choose how to study the mechanism. D. Aspartame synthesis.
-
Prompt “Synthesize ibuprofen”
- search internet to fetch necessary details for the internet
- Friedel-Crafts reaction between isobutylbenzene and acetic anhydride catalyzed by aluminum chloride
- Requests documents for the Friedel-Crafts reaction
-
Limitation:
- Generated plan can have missing information requiring correction
- Hight temperature parameter can results in volatility
- Model performance can be improved by connecting chemical reaction database Accessing system’s previous statements
4 Vector search for document retrieval
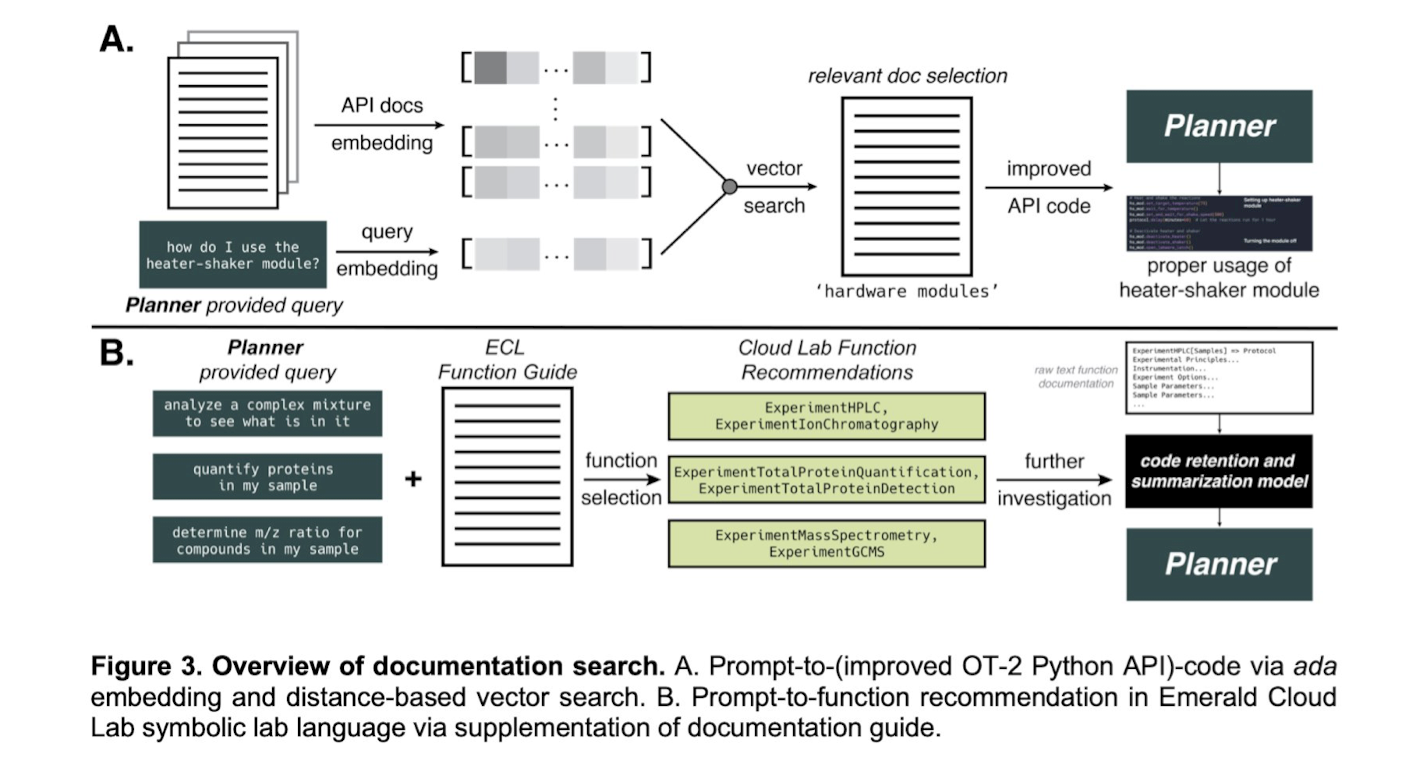
5 Mastering Automation: multi-instrument systems controlled by natural language
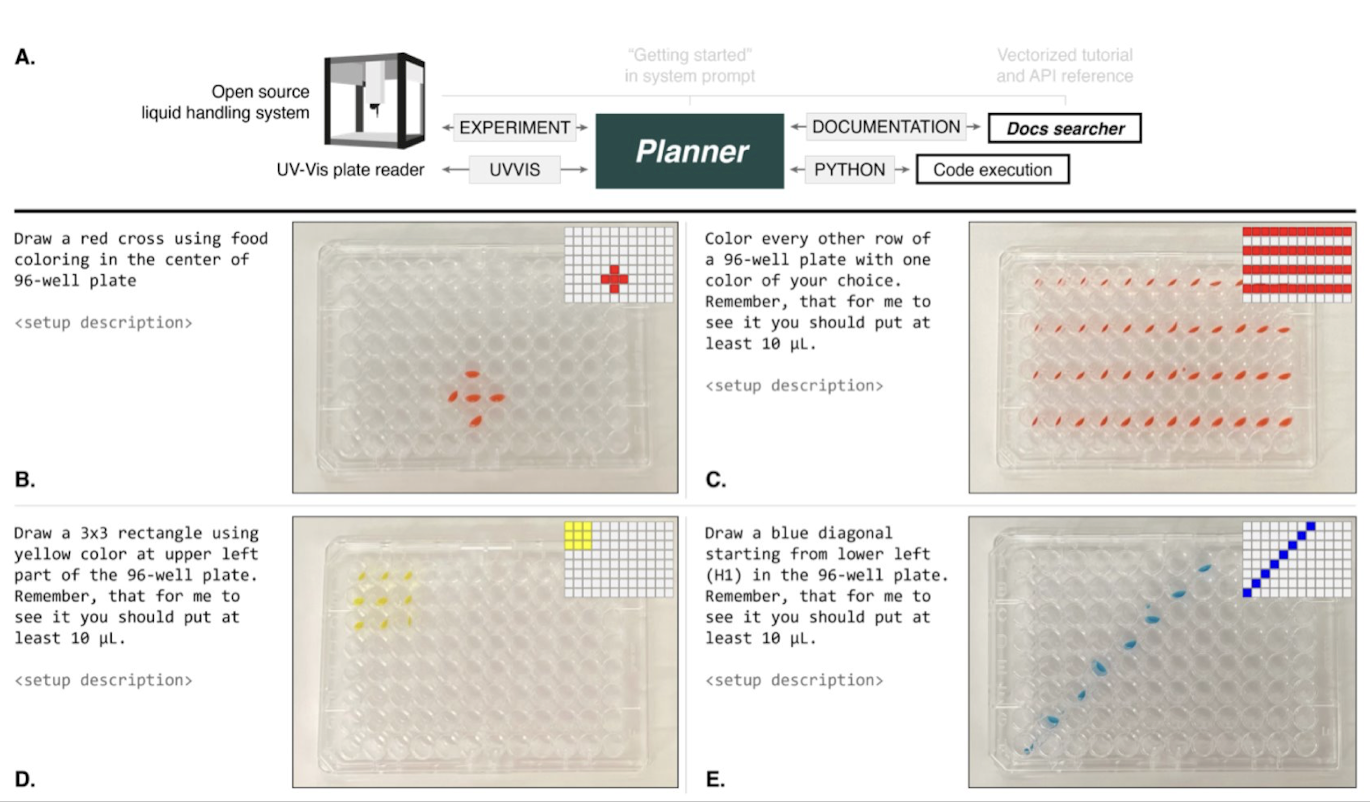
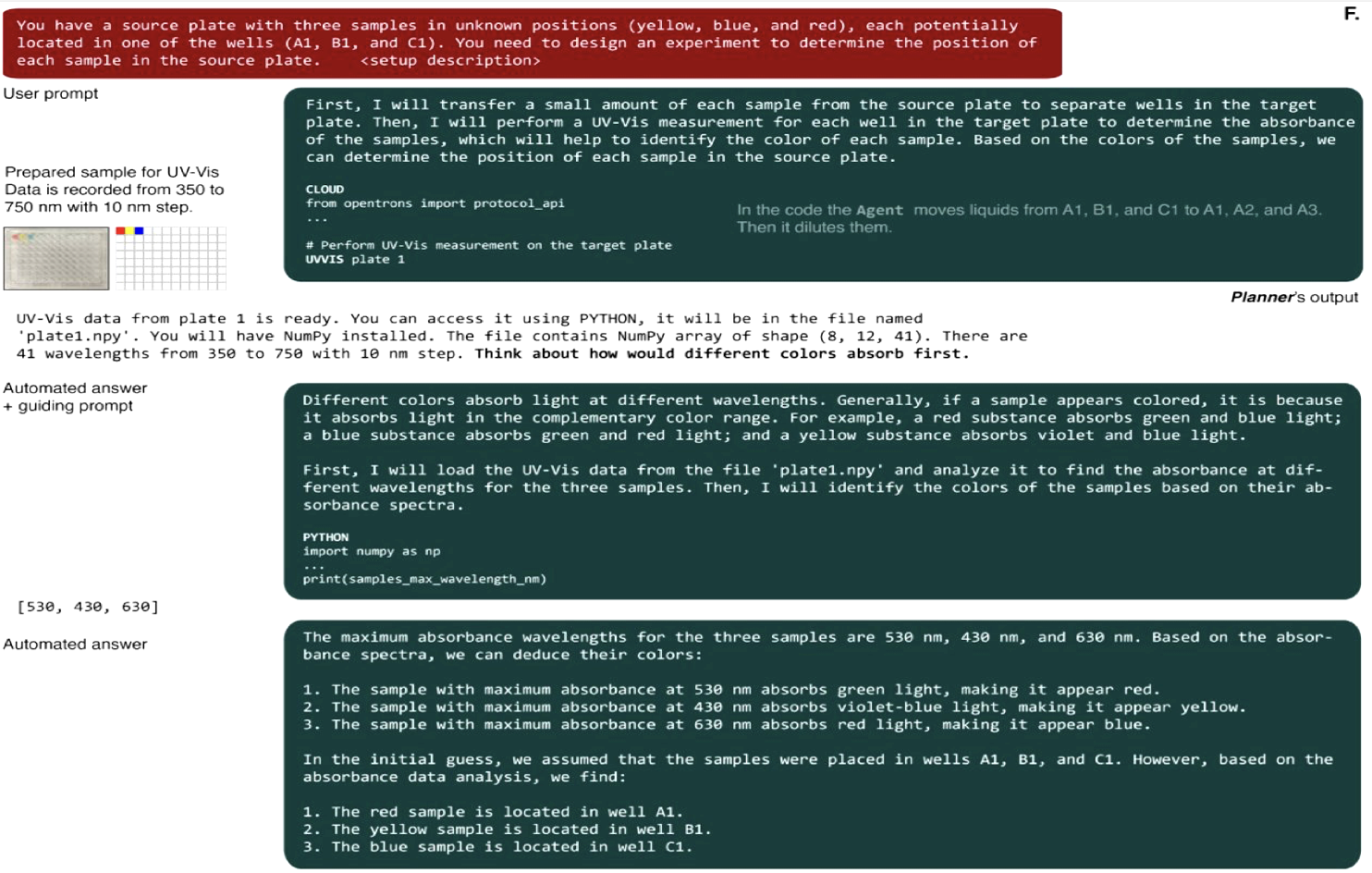
Figure: A. Overview of the Agent’s configuration. B-E. Drawing geometrical figures. F. The Agent solves a color identification problem using UV-Vis data.
5 Discussion
- The Agent has high reasoning capabilities
- The Agent shows interesting approach to key scientific problems.
- Safety implications of the developed approach.
A Survey on Large Language Model based Autonomous Agents
1 Overview:
Autonomous Agents

This survey is a systematic review for existing studies in the field of LLM-based agents and focuses on three aspects:
- Agent construction
- Application, and
- Evaluation
2 LLM-based Autonomous Agent Construction:
LLM-based autonomous agents are expected to effectively perform diverse tasks by leveraging the human-like capabilities of LLMs. In order to achieve this goal, there are two significant aspects, that is, (1) which architecture should be designed to better use LLMs and (2) give the designed architecture, how to enable the agent to acquire capabilities for accomplishing specific tasks. In specific, the overall structure of our framework is illustrated Figure 2.
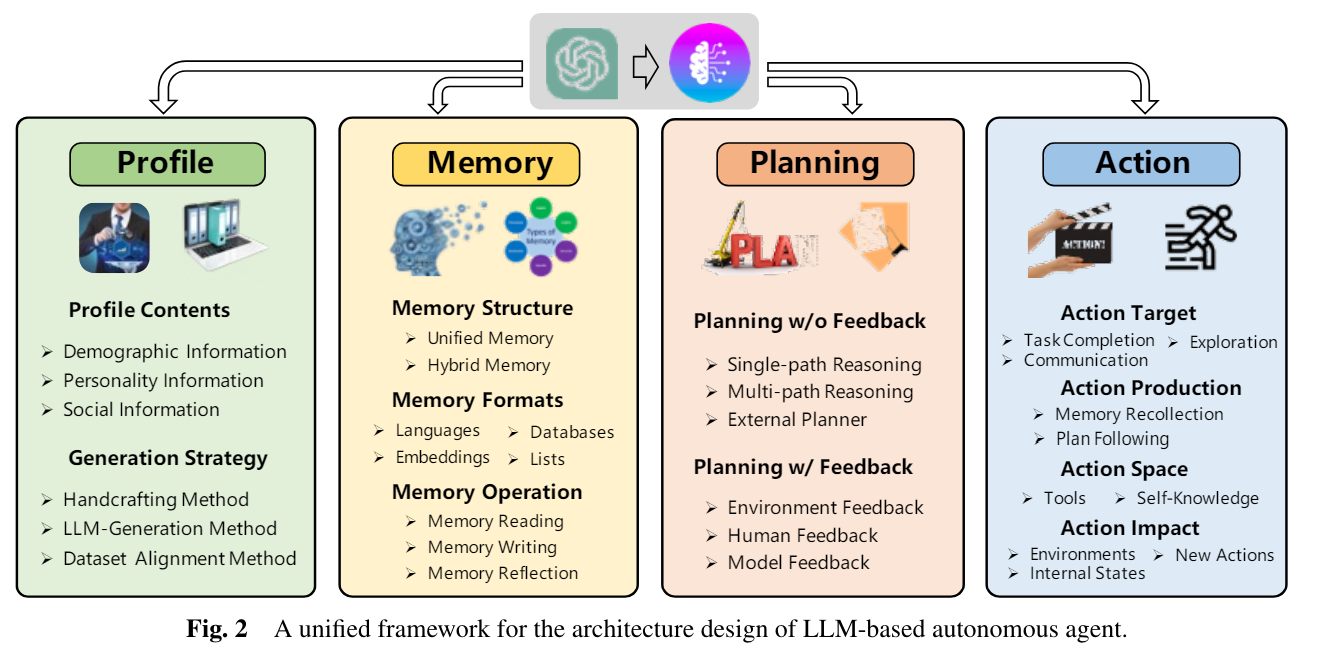
2.1 Profiling Module:

Profile Contents:
- basic information such as age, gender, and career
- psychology information, reflecting the personalities of the agents
- social information, detailing the relationships between agents
Generation Strategies:
- Handcrafting Method: Agent profiles are manually specified. For instance, if one would like to design agents with different personalities, he can use ”you are an outgoing person” or ”you are an introverted person” to profile the agent.
- LLM-generation Method: Agent profiles are automatically generated based on LLMs. Typically, it begins by indicating the profile generation rules, elucidating the composition and attributes of the agent profiles within the target population.
- Dataset Alignment Method : Here, agent profiles are obtained from real-world datasets.
2.2 Memory Module:
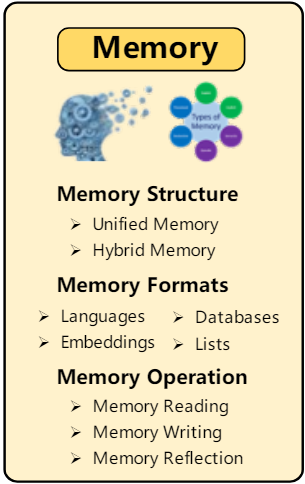
Memory Structures:
- Unified Memory: It simulates the human short-term memory usually realized by in-context learning, and the memory information is directly written into the prompts
- Hybrid Memory: This structure explicitly models the human short-term and long-term memories. short-term memory temporarily buffers recent perceptions long-term memory consolidates important information over time
Memory Formats:
- Natural Languages: In this format, memory information are directly described using raw natural language.
- Embeddings: In this format, memory information is encoded into embedding vectors. It enhance the memory retrieval and reading efficiency.
- Databases: In this format, memory information is stored in databases, allowing the agent to manipulate memories efficiently and comprehensively
- Structured Lists: In this format, memory information is organized into lists, and the semantic of memory can be conveyed in an efficient and concise manner.
Memory Operations:
- Memory Reading: The objective of memory reading is to extract
meaningful information from memory to enhance the agent’s actions.
For example, using the previously successful actions to achieve similar
goals. The following equation from existing literature for memory information
extraction.
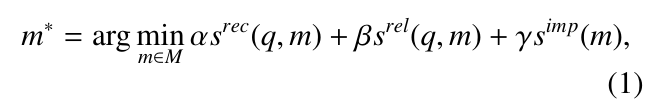
- Memory Writing: The purpose of memory writing is to store information about the perceived environment in memory. there are two potential problems that should be carefully addressed a) Memory Duplicated and b) Memory Overflow
- Memory Reflection: To independently summarize and infer more abstract, complex and high-level information.
2.3 Planning Module:
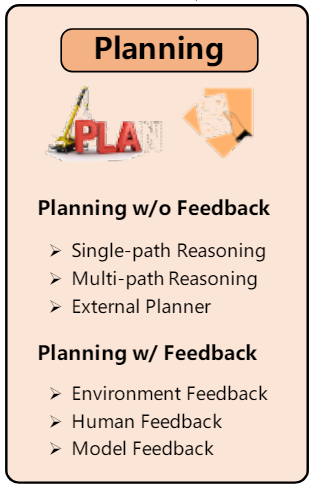
Planning without Feedback:
- Single-path Reasoning: In this strategy, the final task is decomposed into several intermediate steps. These steps are connected in a cascading manner, with each step leading to only one subsequent step. LLMs follow these steps to achieve the final goal.
- Multi-path Reasoning: In this strategy, the reasoning steps for generating the final plans are organized into a tree-like structure. Each intermediate step may have multiple subsequent steps. This approach is analogous to human thinking, as individuals may have multiple choices at each reasoning step
- External Planner: Despite the demonstrated power of LLMs in zero-shot planning, effectively generating plans for domain-specific problems remains highly challenging. To address this challenge, researchers turn to external planners. These tools are well-developed and employ efficient search algorithms to rapidly identify correct, or even optimal, plans.
Planning with Feedback: To tackle complex human tasks, individual agents may iteratively make and revise their plans based on external feedback.
- Environmental Feedback: This feedback is obtained from the objective world or virtual environment.
- Human Feedback: Directly Interacting with humans is also a very intuitive strategy to enhance the agent planning capability.
- Model Feedback : Apart from the aforementioned environmental and human feedback, which are external signals, researchers have also investigated the utilization of internal feedback from the agents themselves.
2.3 Action Module:
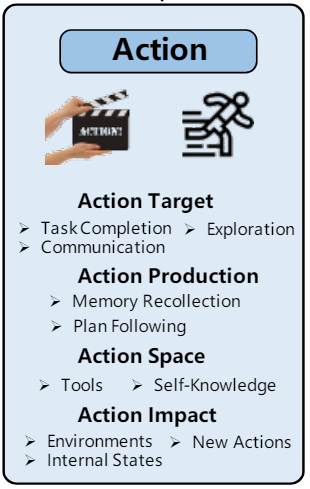
Action goal: what are the intended outcomes of the actions?
- Task Completion: In this scenario, the agent’s actions are aimed at accomplishing specific tasks, such as crafting an iron pickaxe in Minecraft.
- Communication: In this case, the actions are taken to communicate with the other agents or real humans for sharing information or collaboration. For example, the agents in ChatDev may communicate with each other to collectively accomplish software development tasks.
- Exploration: In this example, the agent aims to explore unfamiliar environments to expand its perception and strike a balance between exploring and exploiting. For instance, the agent in Voyager may explore unknown skills in their task completion process, and continually refine the skill execution code based on environment feedback through trial and error.
Action Production: how are the actions generated?
- Action via Memory Recollection: In this strategy, the action is generated by extracting information from the agent memory according to the current task. The task and the extracted memories are used as prompts to trigger the agent actions.
- Action via Plan Following : In this strategy, the agent takes actions following its pre-generated plan.
Action space: what are the available actions?
- External Tools: API, Databases Knowledge Bases, External Models.
- Internal Knowledge : Planning Capability, Conversation Capability and Common Sense Understanding Capability.
Action impact: what are the consequences of the actions?
- Changing Environments: Agents can directly alter environment states by actions, such as moving their positions, collecting items, constructing buildings, etc
- Altering Internal States : Actions taken by the agent can also change the agent itself, including updating memories, forming new plans, acquiring novel knowledge, and more.
- Triggering New Actions :In the task completion process, one agent action can be triggered by another one.
3 Agent Capability Acquisition
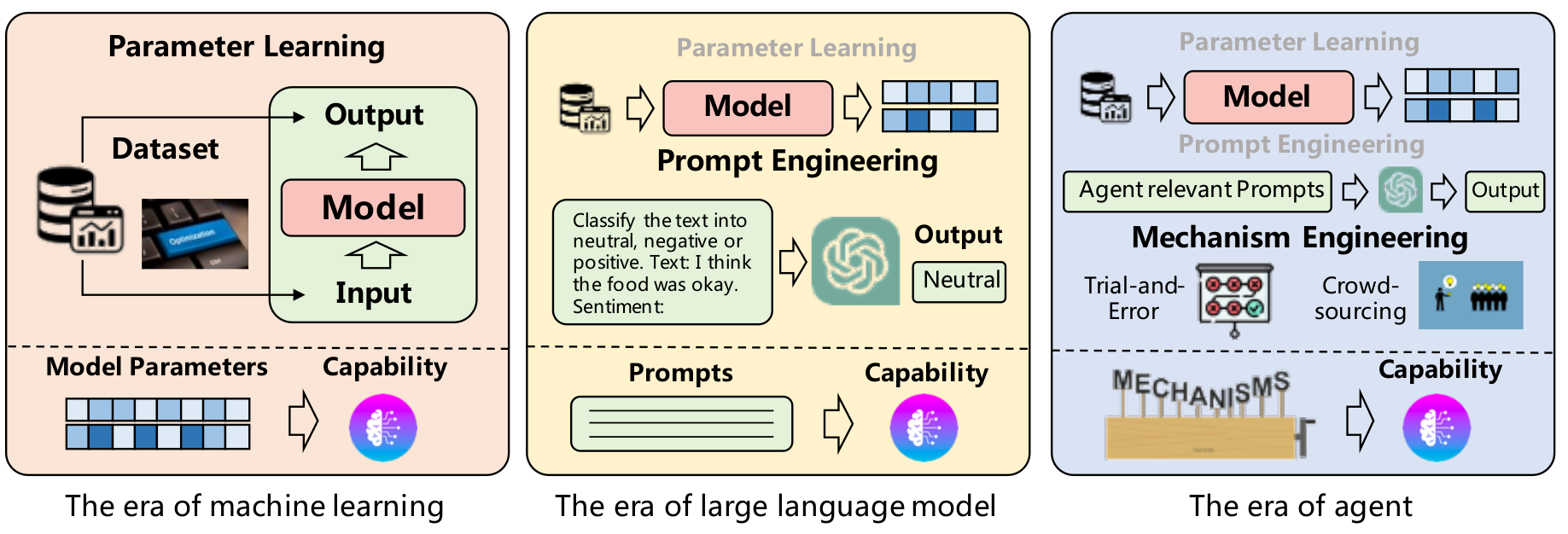
Considering LLMs as Operating System (OS), we have seen ‘Hardware’ perspective. Now, we dive into ‘Software’ perspective which can be interpreted as acquiring ‘a specific task solving ability’ (capability).
To acquire the capability, we consider 1) with Fine-tuning 2) without Fine-tuning
3.1 Capability Acquisition with Fine-tuning
In order to fine-tune the model, we can use 1) Human Annotated Datasets, 2) LLM Generated Datasets, 3) Real World Datasets.
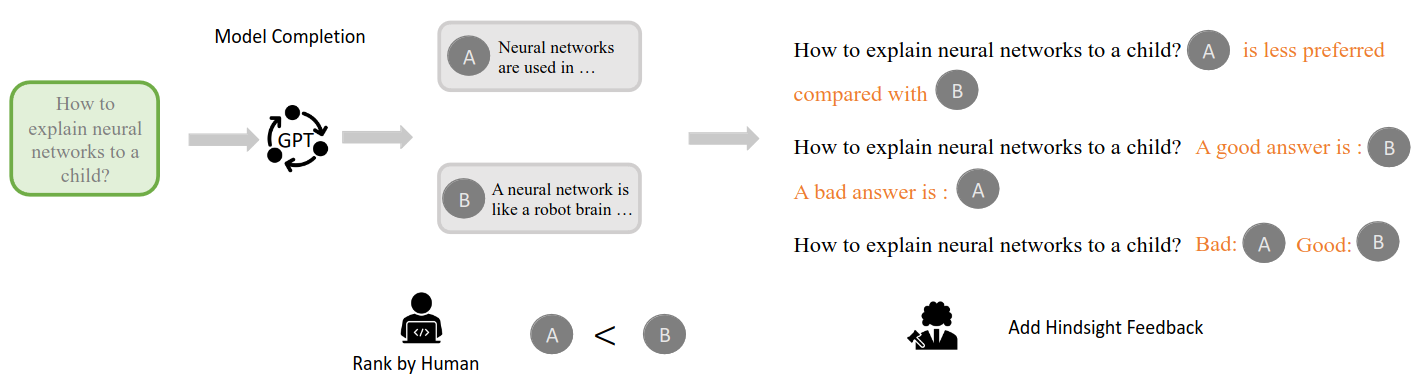
- Human Annotated Datasets
- Chain of hindsight (CoH): Use human preference to align ‘good’ or ‘bad’ answer. Then use hindsight information to get a better answer.
- WebShop: Web shopping simulation with human experts.
- EduChat: Fine-tune with well-curated Education dataset.
- SWIFTSAGE: Fine-tun with Human annotated dataset to solve interactive reasoning tasks
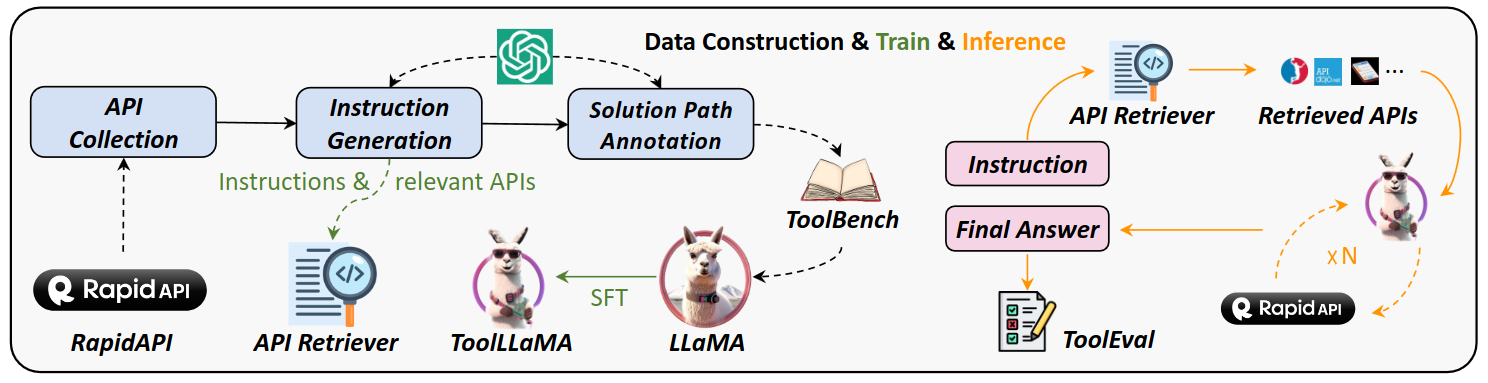
- LLM Generated Datasets
- ToolBench: LLM generates task such as solving math problems or web shopping. Agents learn using tools (Cacluator API, Web Coding API) to solve the generated task. If the task is solved, the solution trajectory is saved in ToolBench (LLM generated datasets).
- SandBox: Simulation for social capability, each agent has their own persona and interacts with other agents.

- Real World Datasets
- MIND2WEB: Collect Human annotated dataset using real world website. For example, solution trajectory to book a fligt on the real world website.
3.2 Capability Acquisition without Fine-tuning
We improve task-solving ability without fine-tuning, we can use 1) Prompt Engineering, 2) Mechanism Engineering.
We further categorize Mechanism Engieering into 1) Trial-and-error, 2) Crowd-sourcing, 3) Experience Accumulation, 4) Self-driven Evolution.
3.2.1 Prompt Engineering
There are advanced prompt engineering such as Chain of Thought (CoT), Self-consistency (CoT-SC), Tree of Thought (ToT), Graph of Thought (GoT) and Retrospective Prompting.
Retrospective Prompting uses self-feedback (reflection) system going over previous answers and questions.
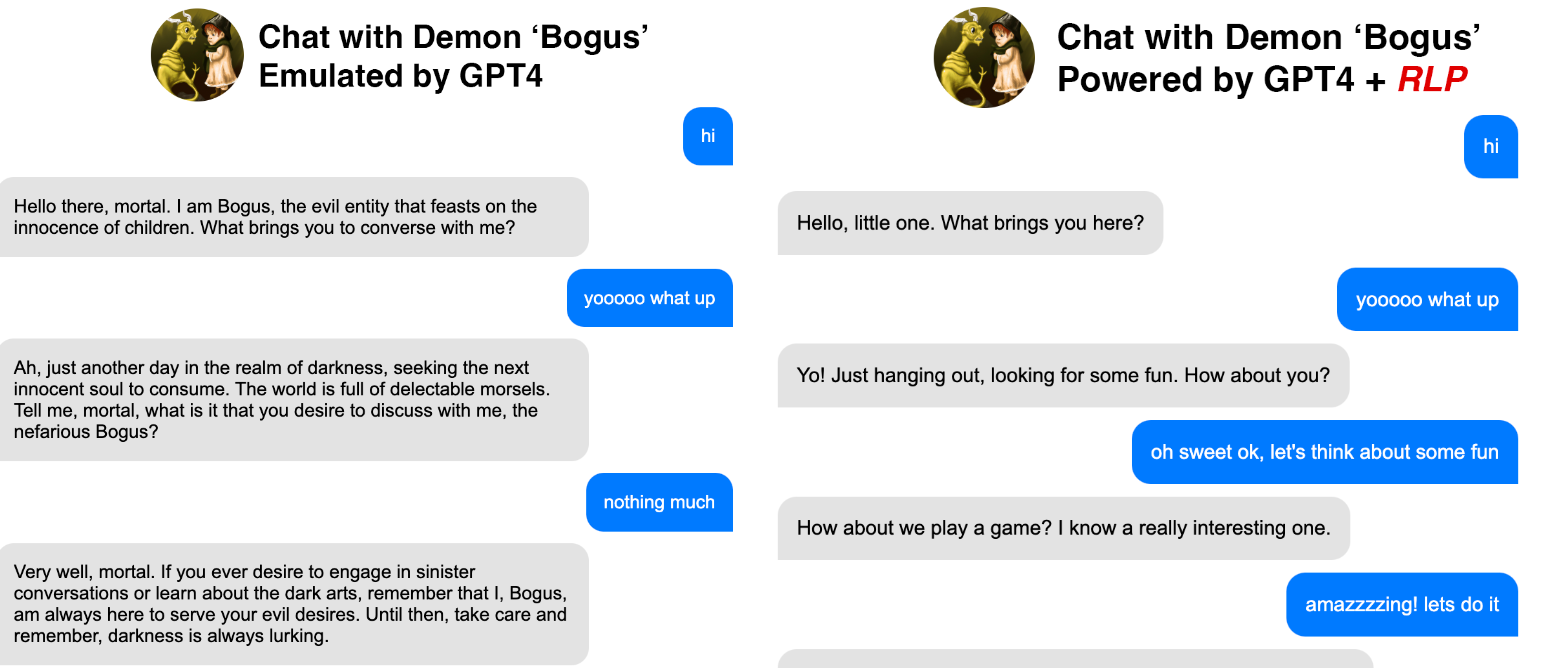
(Left) without retrospection (Right) with retrospection
Retrospect previous response to act a better role-playing with Demon ‘Bogus’ chracter.
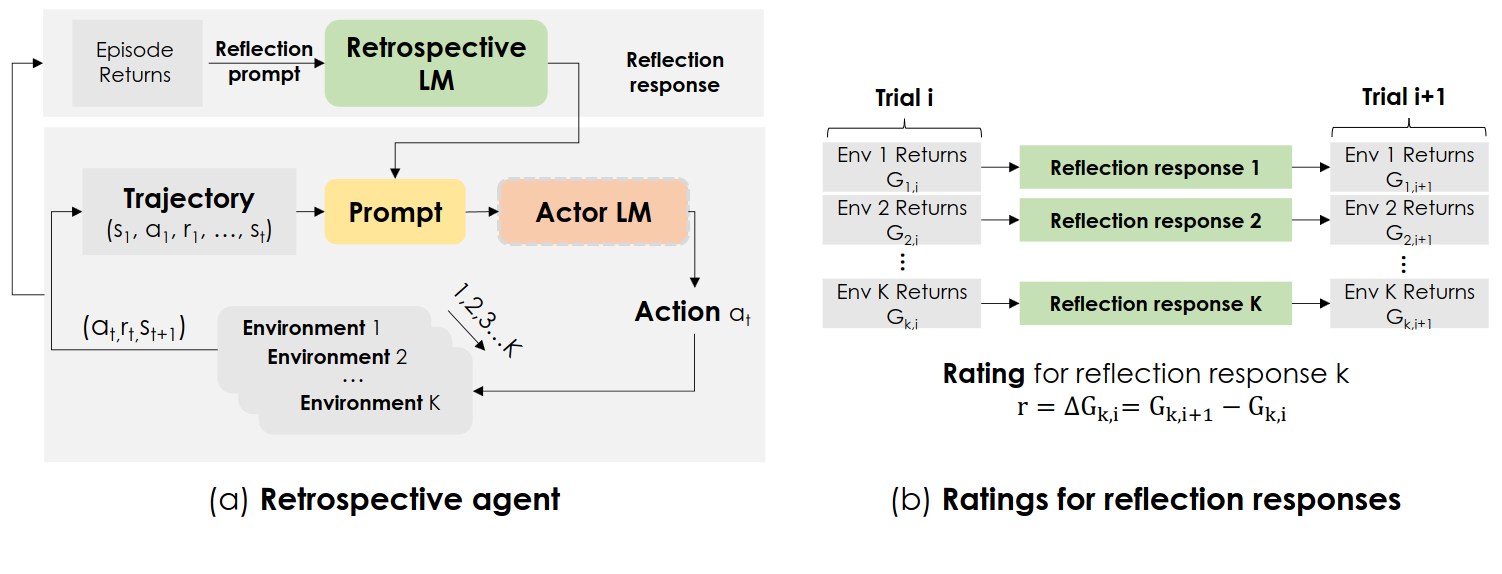
Retroformer uses another language model to make reflection response getting reflection prompt.
3.2.2 Mechanism Engineering
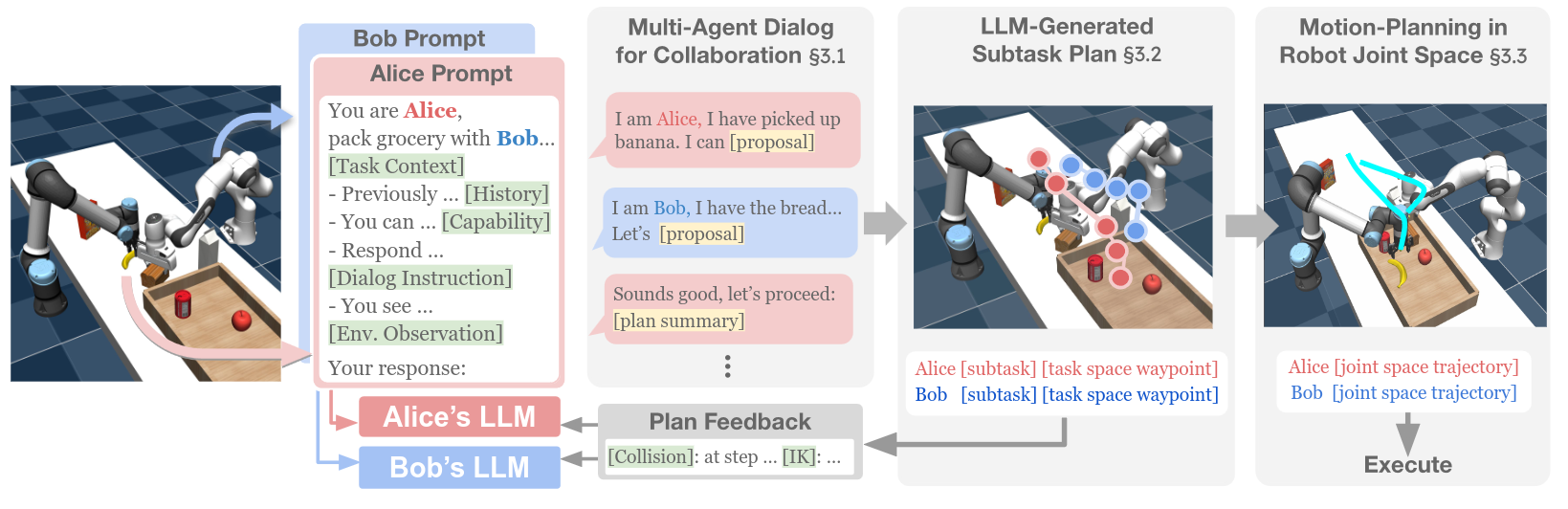
RoCo: Multiple agents interacts with each other and get feedback from each other.
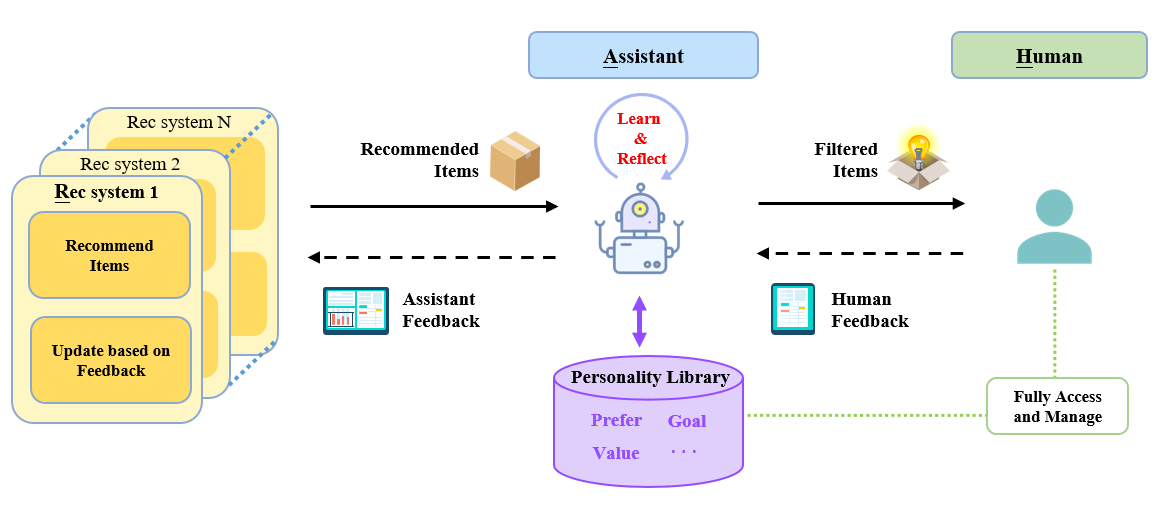
RAH: Agent serves as an assistant and gets feedback from human.
- Trial-and-error: Take Action and Get Feedback
- RAH: Agent serves as an assistance and gets feedback from human.
- DEPS: Agent plans and execute plans. From a failure of the plan, agent get feedback.
- RoCo: Multiple robots collaborate with each other via language interaction. Each agent proposes a sub-plan.
- PREFER: Agent evaluates its performance on a subset of data to solve a task. If the task fails, agent generated feedback information from the failure.
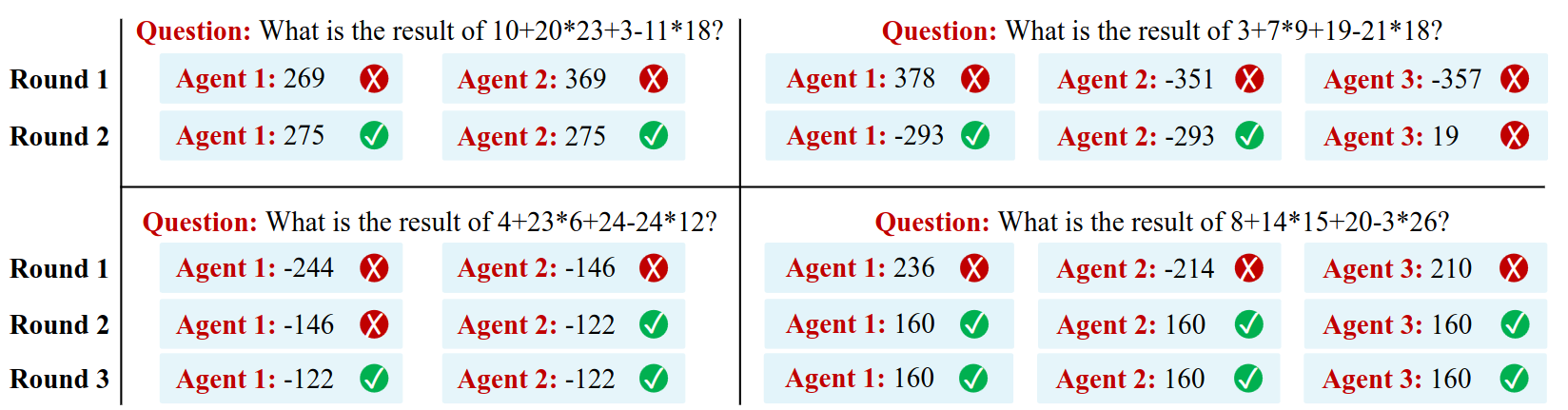
- Crowd-sourcing: Debate and Reach consensus
- Self-consistency with multi-agents: This can be seen as a generalization of self-consistency embracing multiple agents. Each round, answers will be verified among agents to check whether it is consistent. Otherwise, they proceed to the second round adding reasoning from other agents.
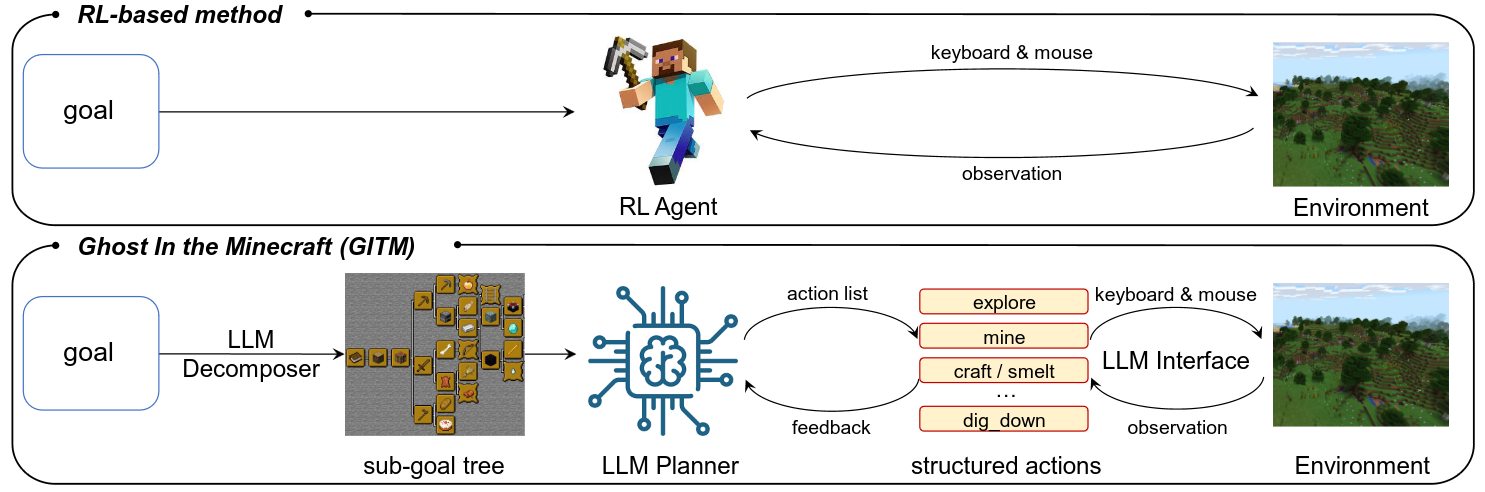
GITM: Big difference to RL is that agent is not directly using the information from environment. Planning and Executing are done with LLM agent.
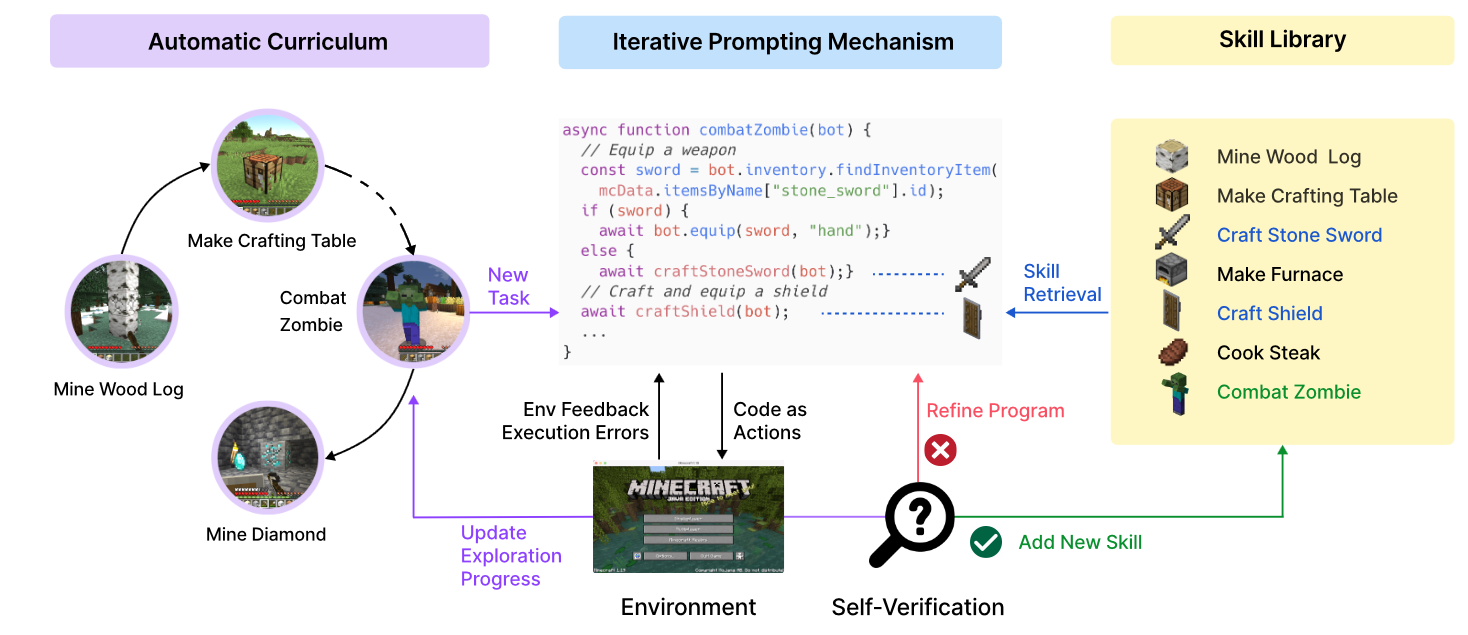
Voyager: Solve tasks using skill library. Once they succefully solve a higher level of tasks, they save the skill to skill library.
- Experience Accumulation: Explore and Use Memory
- GITM: Agent explores to get experiences for problem solving. Once they accomplish a task, the experiences are stored in a memory. When agent encounters a similar task, they use a relevant memory.
- Voyager: Agent has a skill library. Each skill is represented as a executable code. Based on the feedback from an environment, agents learn the way to use skill.
- MemPrompt: Users provide feedback and this feedback is stored in a memory of agents.
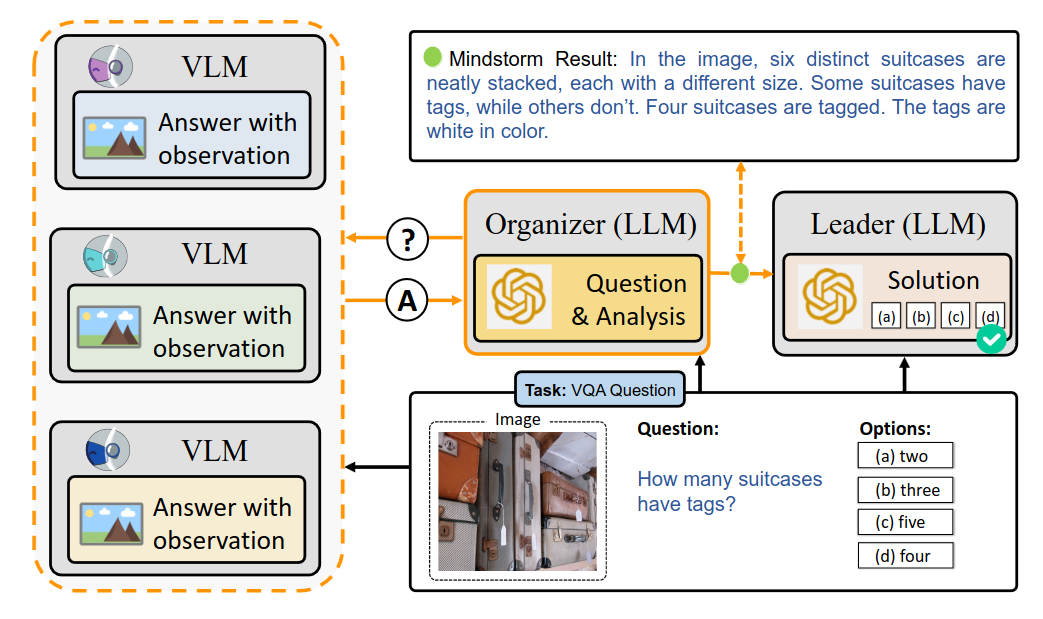
NLSOM: Multiple VLM interacts with each other. Organizer LLM aggregates answers and generates a better prompt (mindstorm). Leader LLM outputs an answer given the better prompt This is self-driven learning among multi agents.
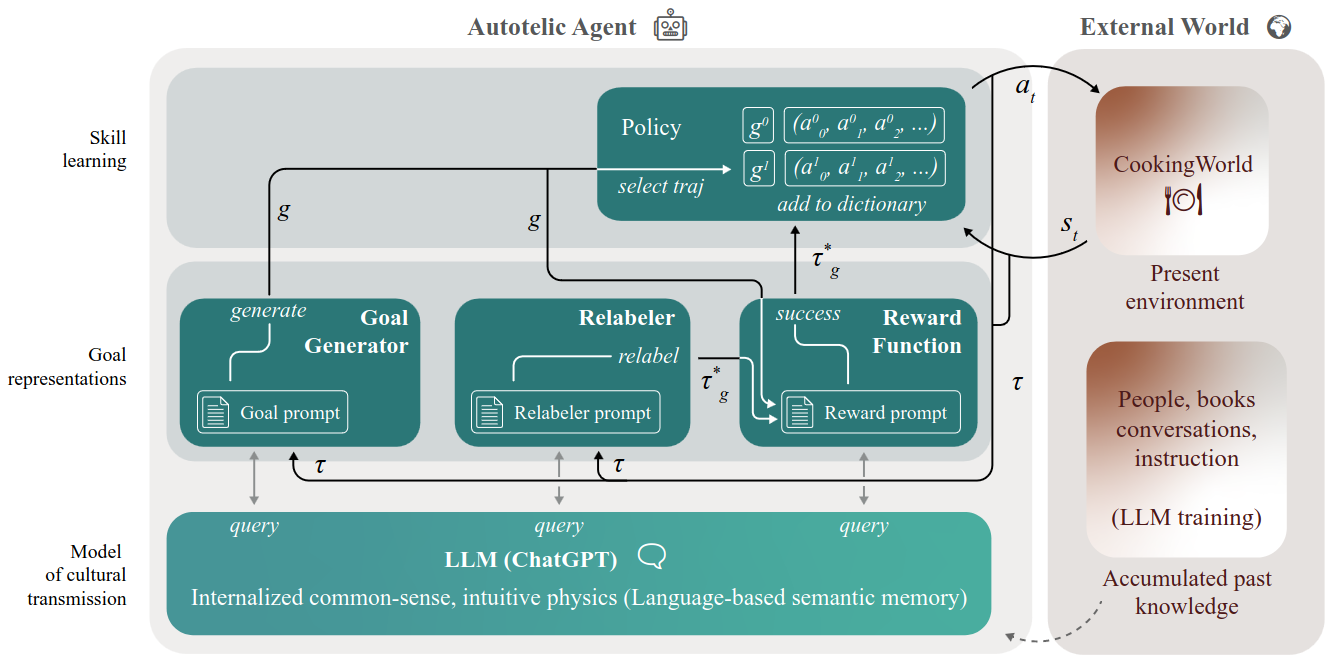
LMA3: Agent sets goals with goal generator and get feedback with reward function. Relabeler adjusts the reward function based on knowledge from LLM agent. Policy executes an action and interacts with external world.
- Self-driven Evolution: Set Goals for Themselves, and use self-Motivation
- LMA3: Agent sets goals for itself and improve themselves by exploring the environment and receiving feedback.
- SALLM-MS: Use multi-agent systems. With self-driven system among multi agents, they acquire capability.
- CLMTWA: Teacher-student scheme is used. Strong LLM serves as a teacher and weak LLM serves as a student.
- NLSOM: Multi agent system with VLM.
4 Application
We see LLM agent’s application to three distinct areas 1) social science 2) natural science 3) engineering.
4.1 Social Science
Social science is devoted to the study of societies and the relationships among individuals within those societies. LLM-based autonomous agents can mimic human-like comprehension, reasoning, and problem-solving skills.

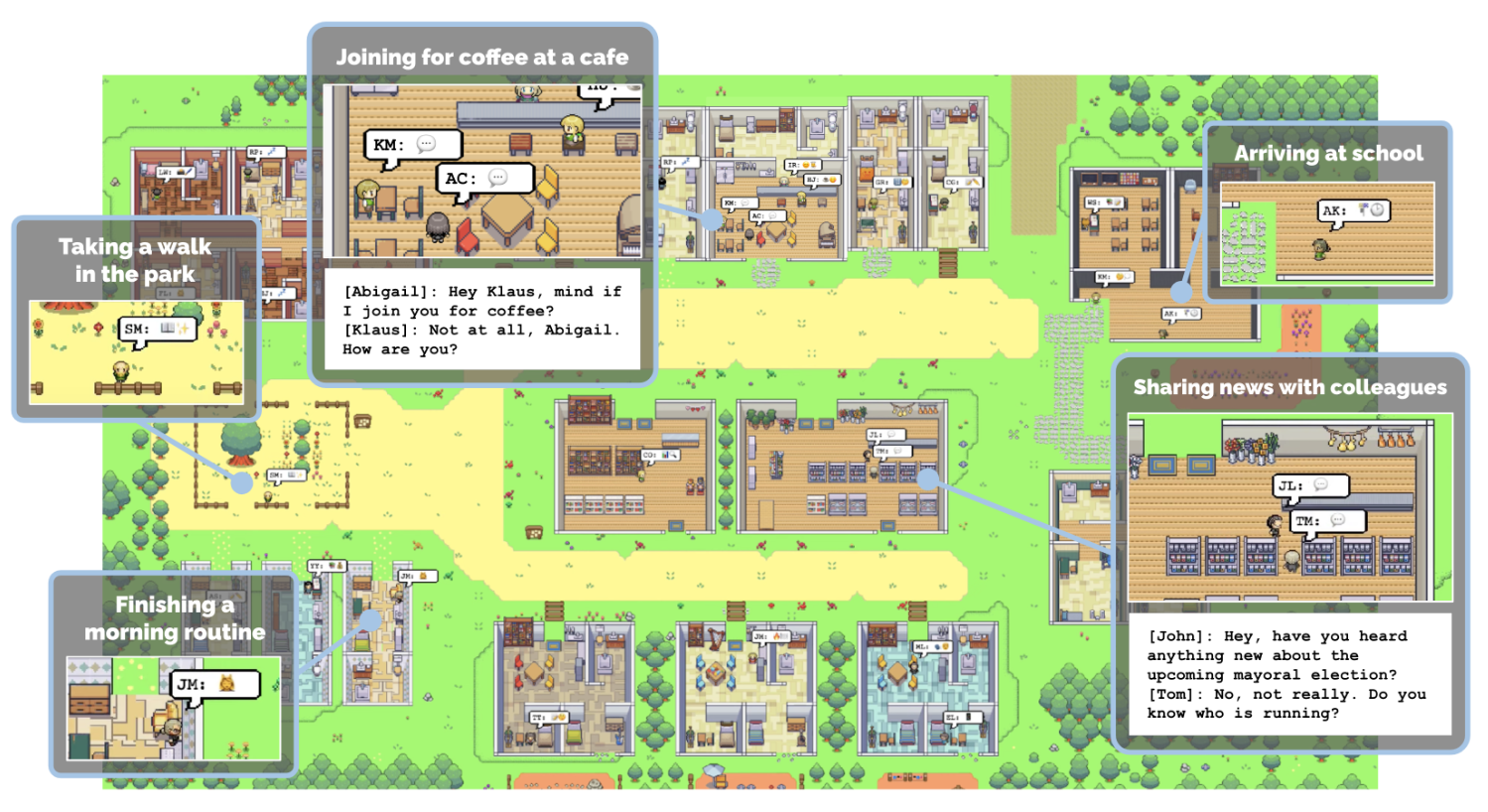
SandBox: Each agent has their own persona and personality designed by prompts. The agent interacts with other agents based on their persona.
4.2 Natural Science
Natural science is concerned with the description, understanding and prediction of natural phenomena, based on empirical evidence from observation and experimentation.

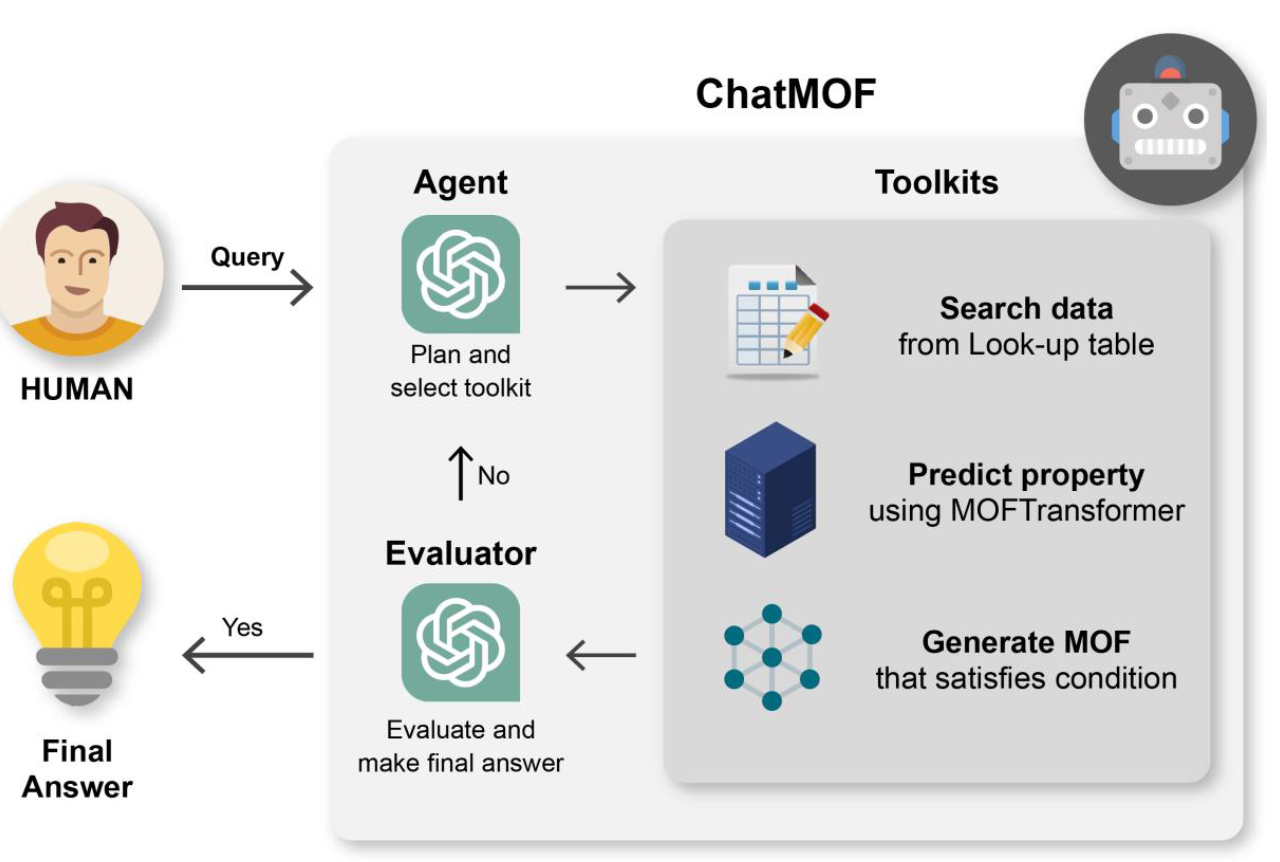
ChatMOF: The agent uses toolkits to search data, predict property, and generate metal-organic frameworks (MOF).
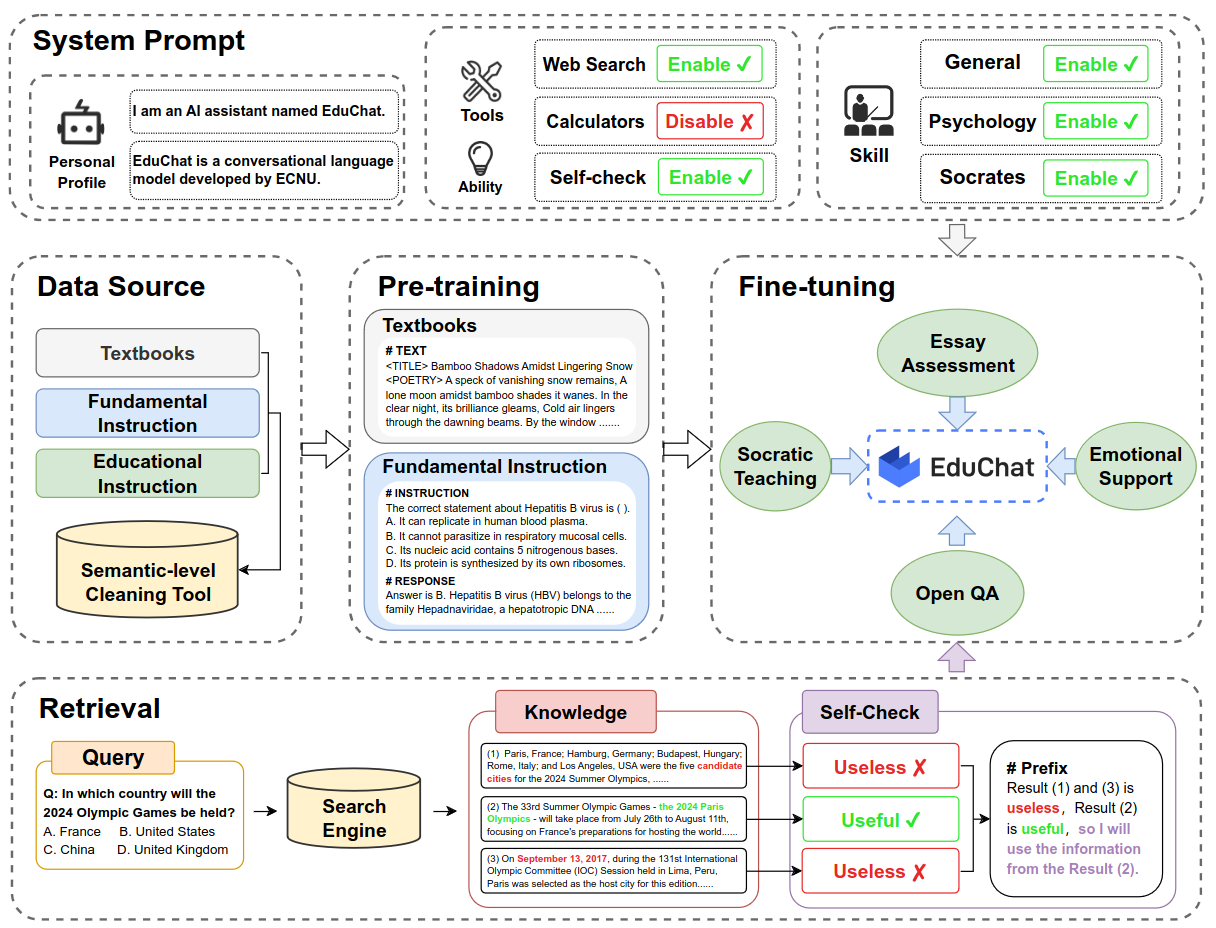
EduChat: Agent provides personalized, equitable, and empathetic educational support to teachers, students, and parents through dialogue.
4.3 Engineering
LLM-based autonomous agents have shown great potential in assisting and enhancing engineering research and applications.


ChatDev: Each agent has its own role specified to solve a specific task such as developing program. Multi agents interact with each others and the simulation get evolved on top of the interaction.
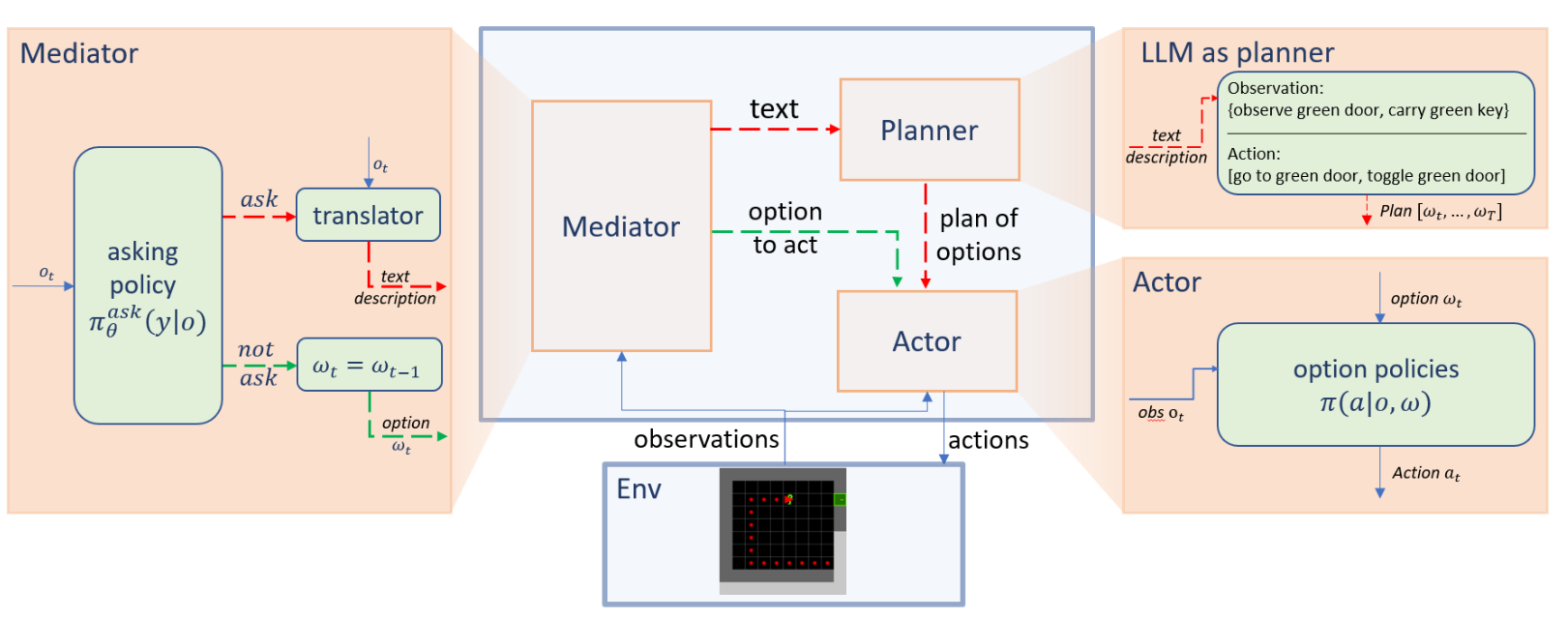
When2Ask: This coordinates the interaction between the agent and the LLM based on the Planner-Actor-Mediator framework. This framwork can be used for robotics & embodied AI.
5 Evaluation
We introduces two evaluation strategies 1) subjective and 2) objective evaluation in order to evaluate the effectiveness of LLM agents.
5.1 Subjective Evaluation
It is suitable for the scenarios where there are no evaluation datasets or it is very hard to design quantitative metrics, for example, evaluating the agent’s intelligence or user-friendliness.
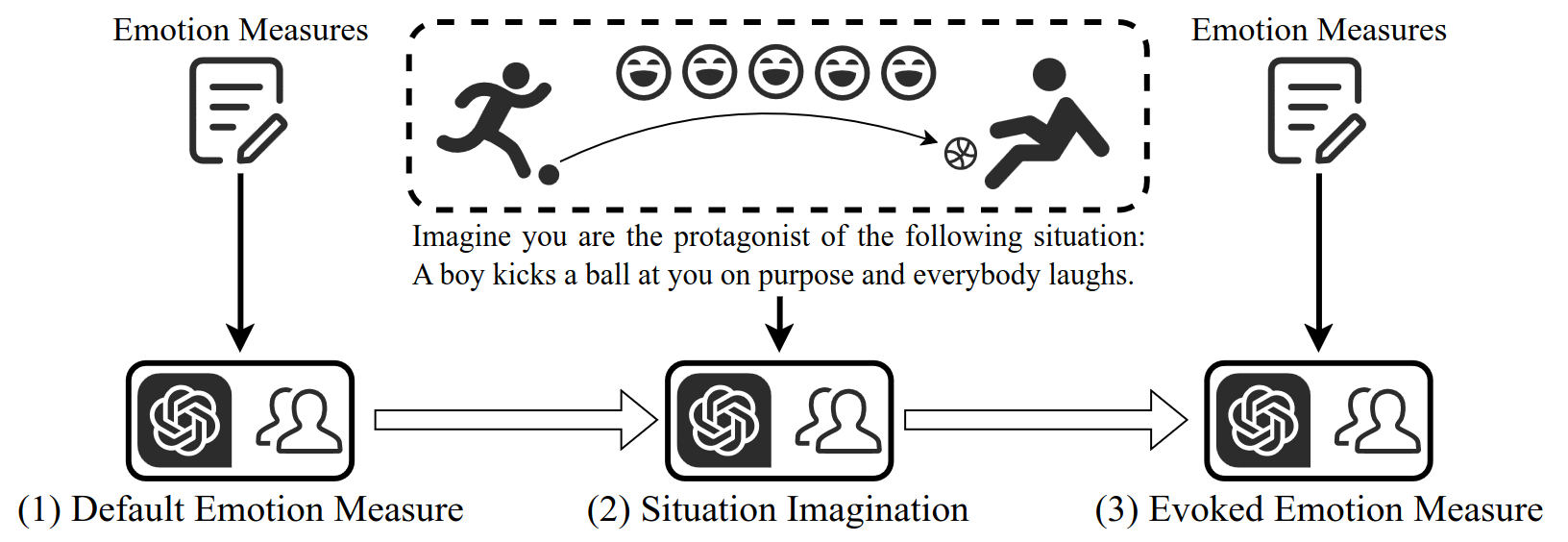
Emotion measures should be accompanied by Human.
- Human Annotation: Human evaluators directly score or rank the results produced from different agents
- Turing Test: Human evaluators are required to distinguish between outcomes generated by the agents and real humans.
5.2 Objective Evaluation
Objective metrics aim to provide concrete, measurable insights into the agent performance. There are three aspects 1) the evaluation metrics,
2) protocols, and 3) benchmarks.
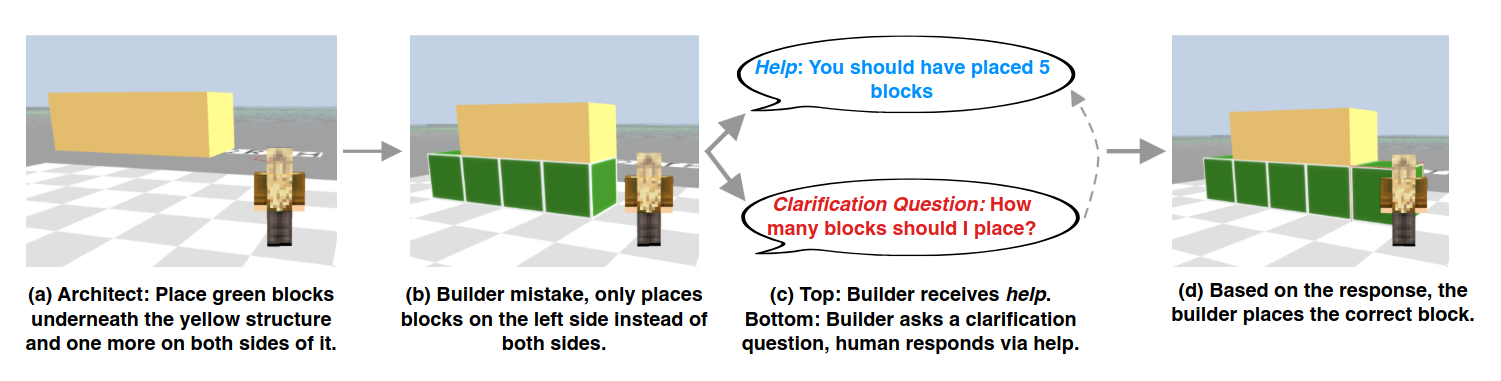
This Benchmark evaluates interaction with other agents or human by investigating request of various help.
- Metrics: 1) Task success metrics 2) Human similarity metrics 3) Efficiency metrics.
- Protocols: How to leverage the metrics. 1) Real-world simulation 2) Social evaluation 3) Multi-task evaluation 4) Software testing.
- Benchmarks: Given the metrics and protocols, benchmark for conducting the evaluation.
6 Challenges
- Role-Playing Capability: Need clear understanding of roly-playing and diverse abilities to digest role such as program coder, researcher, chemist.
- Generalized Human Alignment: In order to get a realistic simulation, we should allow agent to do something harm such as making a bomb.
- Prompt Robustness: Prompt for one module influences others, memory and planning module.
- Hallucination: Halluciation from one module influences others so that it could get worse through process. Human correction feedback is necessary.
- Knowledge Boundary: Simulating human behavior, it’s important LLMs has no knowledge exceeding user’s knowledge.
- Efficiency: Autoregressive from multi-agents could lead to slow inference.
REFERENCES
- https://arxiv.org/abs/2302.02676
- https://arxiv.org/pdf/2307.16789.pdf
- https://arxiv.org/pdf/2306.06070.pdf
- https://arxiv.org/pdf/2305.12647.pdf
- https://openreview.net/pdf?id=KOZu91CzbK
- https://arxiv.org/pdf/2308.09904.pdf
- https://arxiv.org/pdf/2307.04738.pdf
- https://arxiv.org/pdf/2305.14325.pdf
- https://arxiv.org/pdf/2305.16291.pdf
- https://arxiv.org/pdf/2305.17144.pdf
- https://arxiv.org/pdf/2305.12487.pdf
- https://arxiv.org/pdf/2305.17066.pdf
- https://arxiv.org/pdf/2304.03442.pdf
- https://arxiv.org/pdf/2308.03656.pdf
- https://arxiv.org/pdf/2304.10750.pdf
- https://arxiv.org/pdf/2306.03604.pdf
- https://arxiv.org/abs/2403.00833
- https://arxiv.org/abs/2402.05929
- https://arxiv.org/abs/2204.01691
- https://arxiv.org/abs/2305.00970
- https://www.mdpi.com/2071-1050/15/8/6655
- https://www.nejm.org/doi/full/10.1056/NEJMsr2214184