LLM evaluating framework
- SlideDeck: W3-LLMEvaluation-Team5
- Version: current
- Lead team: team-5
- Blog team: team-1
In this session, our readings cover:
Required Readings:
Holistic Evaluation of Text-To-Image Models
- https://arxiv.org/abs/2311.04287
- The stunning qualitative improvement of recent text-to-image models has led to their widespread attention and adoption. However, we lack a comprehensive quantitative understanding of their capabilities and risks. To fill this gap, we introduce a new benchmark, Holistic Evaluation of Text-to-Image Models (HEIM). Whereas previous evaluations focus mostly on text-image alignment and image quality, we identify 12 aspects, including text-image alignment, image quality, aesthetics, originality, reasoning, knowledge, bias, toxicity, fairness, robustness, multilinguality, and efficiency. We curate 62 scenarios encompassing these aspects and evaluate 26 state-of-the-art text-to-image models on this benchmark. Our results reveal that no single model excels in all aspects, with different models demonstrating different strengths. We release the generated images and human evaluation results for full transparency at this https URL and the code at this https URL, which is integrated with the HELM codebase.
Holistic Evaluation of Language Models
- https://arxiv.org/abs/2211.09110
More Readings:
Challenges in evaluating AI systems
- https://www.anthropic.com/news/evaluating-ai-systems
Evaluating Large Language Models: A Comprehensive Survey
- https://arxiv.org/abs/2310.19736
- This survey endeavors to offer a panoramic perspective on the evaluation of LLMs. We categorize the evaluation of LLMs into three major groups: knowledge and capability evaluation, alignment evaluation and safety evaluation. In addition to the comprehensive review on the evaluation methodologies and benchmarks on these three aspects, we collate a compendium of evaluations pertaining to LLMs’ performance in specialized domains, and discuss the construction of comprehensive evaluation platforms that cover LLM evaluations on capabilities, alignment, safety, and applicability.
Evaluating Large Language Models Trained on Code
- https://arxiv.org/abs/2107.03374
chatbot-arena-leaderboard
- https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard
Leveraging Large Language Models for NLG Evaluation: A Survey
- https://arxiv.org/abs/2401.07103
Blog: Evaluating Large Language Models
Section 1: Benchmarking in AI
Introducing a self-driving car technology example to illustrate Neural Networks, which rely on training data to learn and improve their accuracy over time.
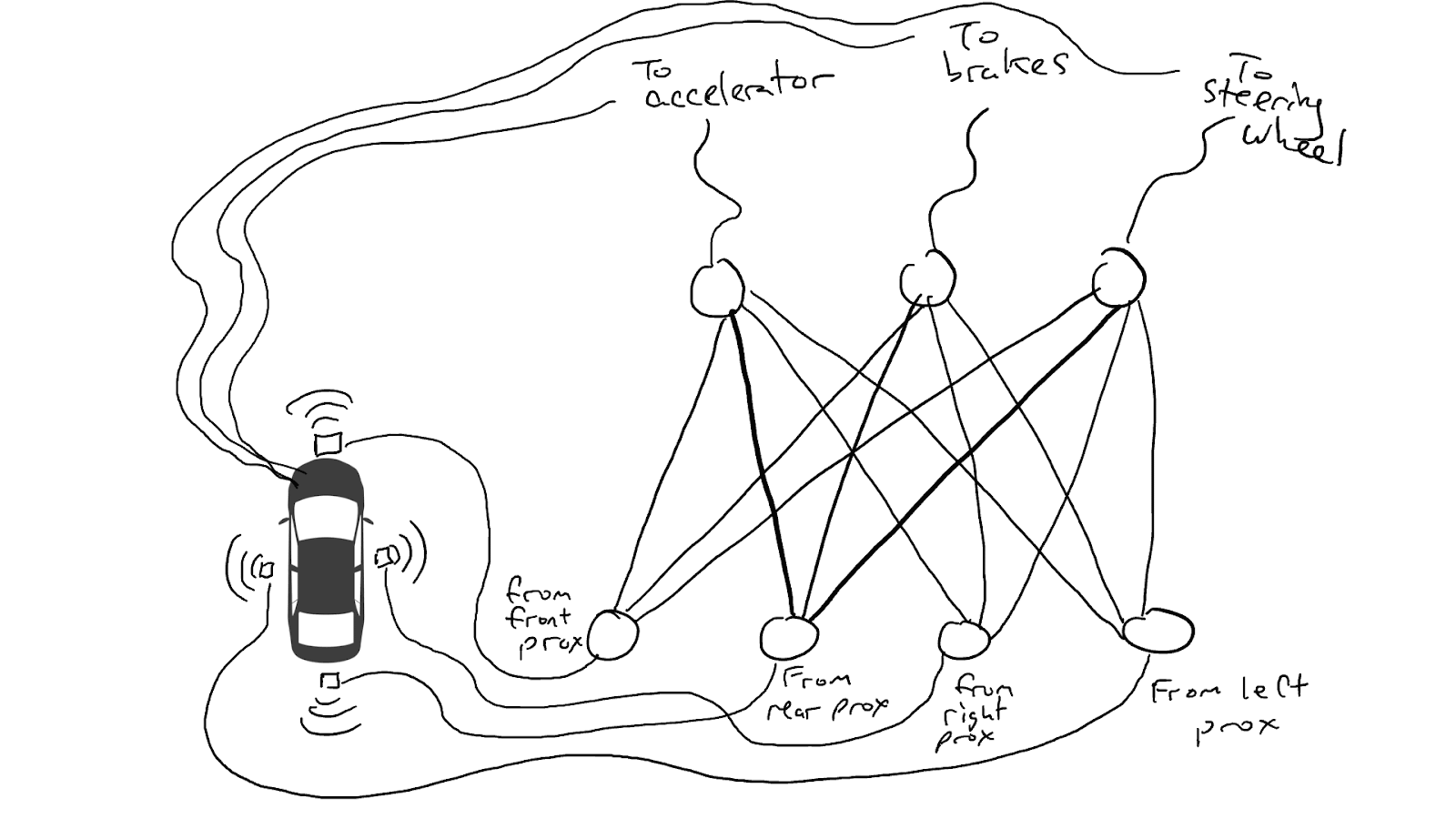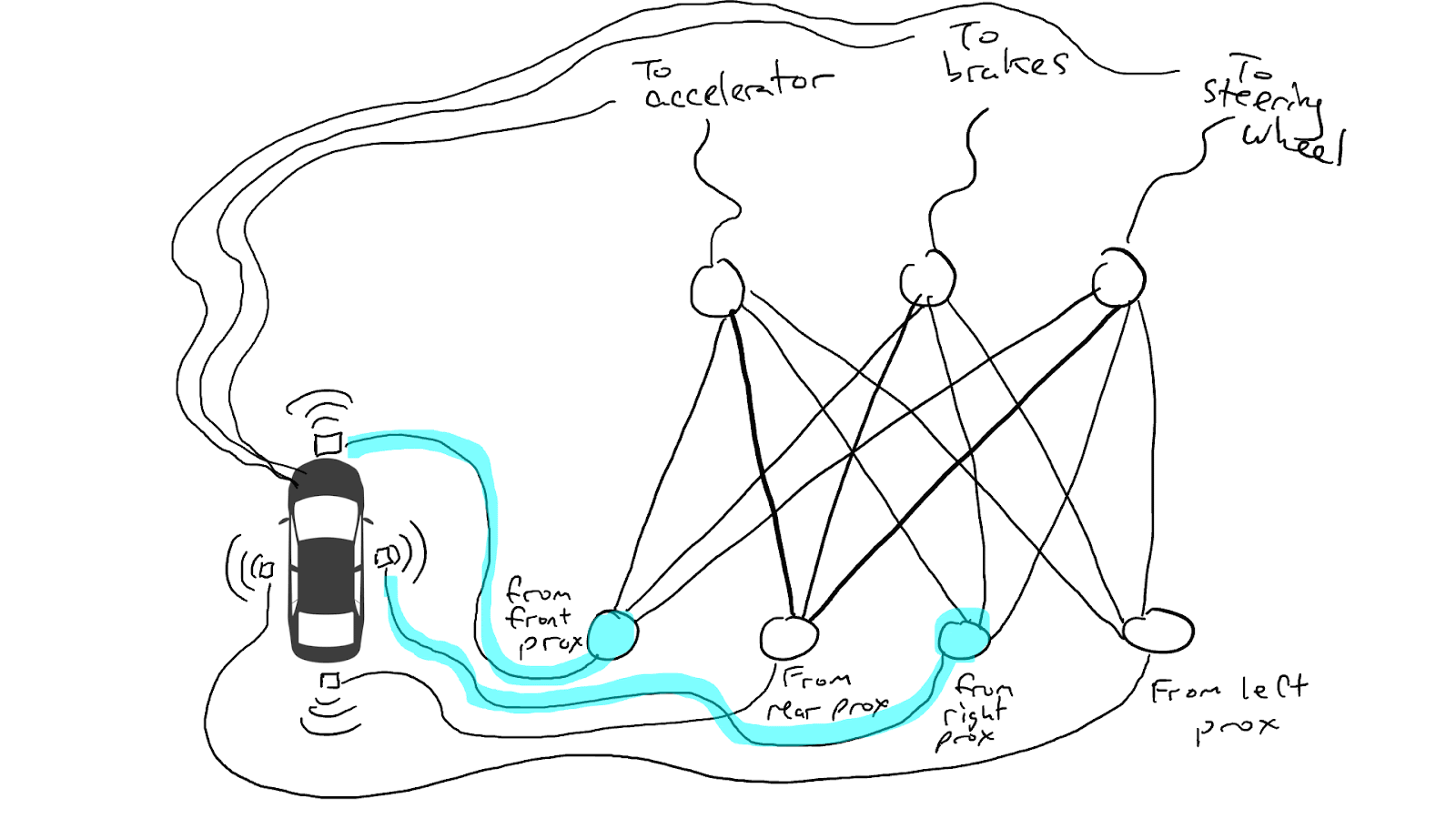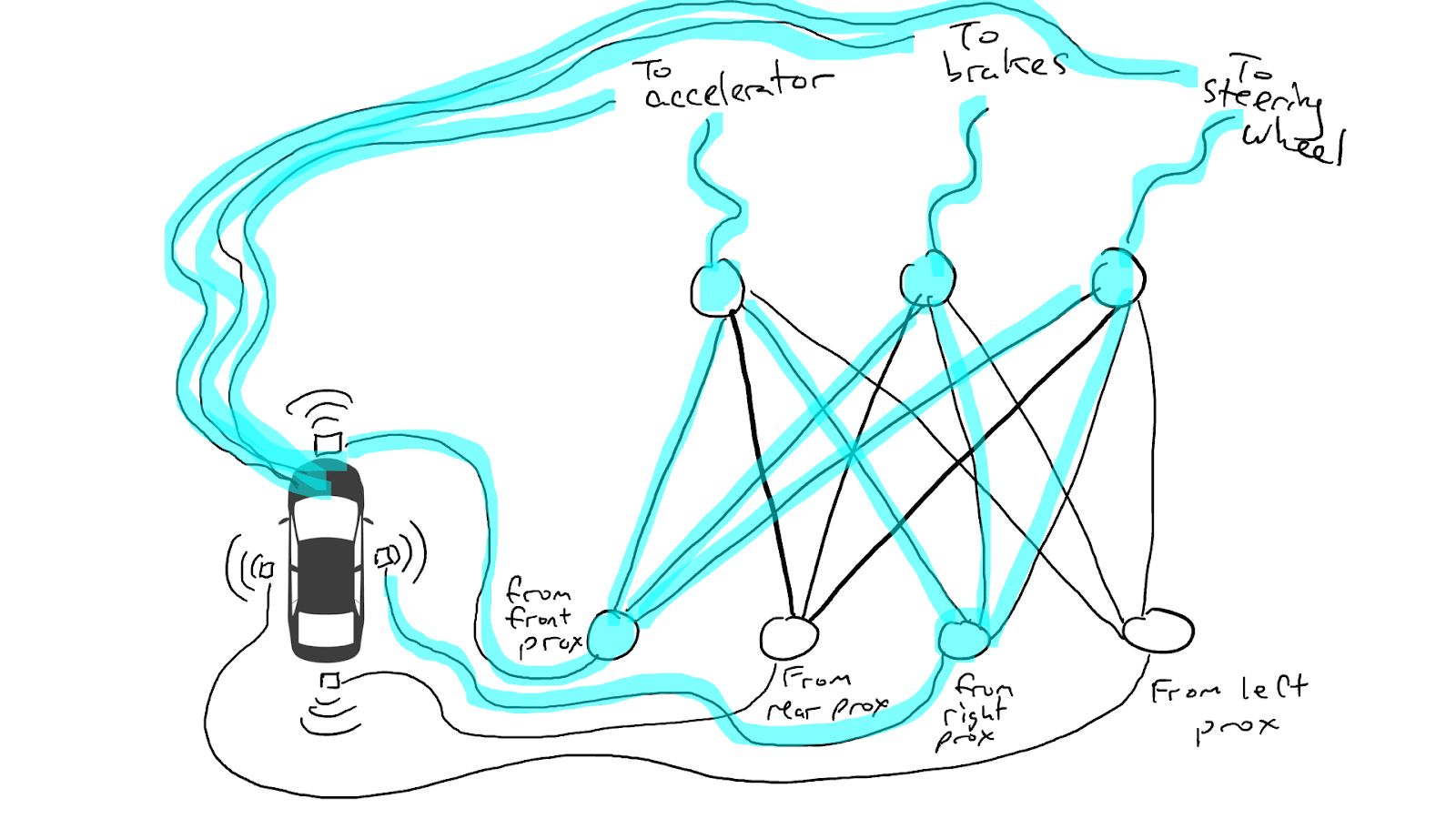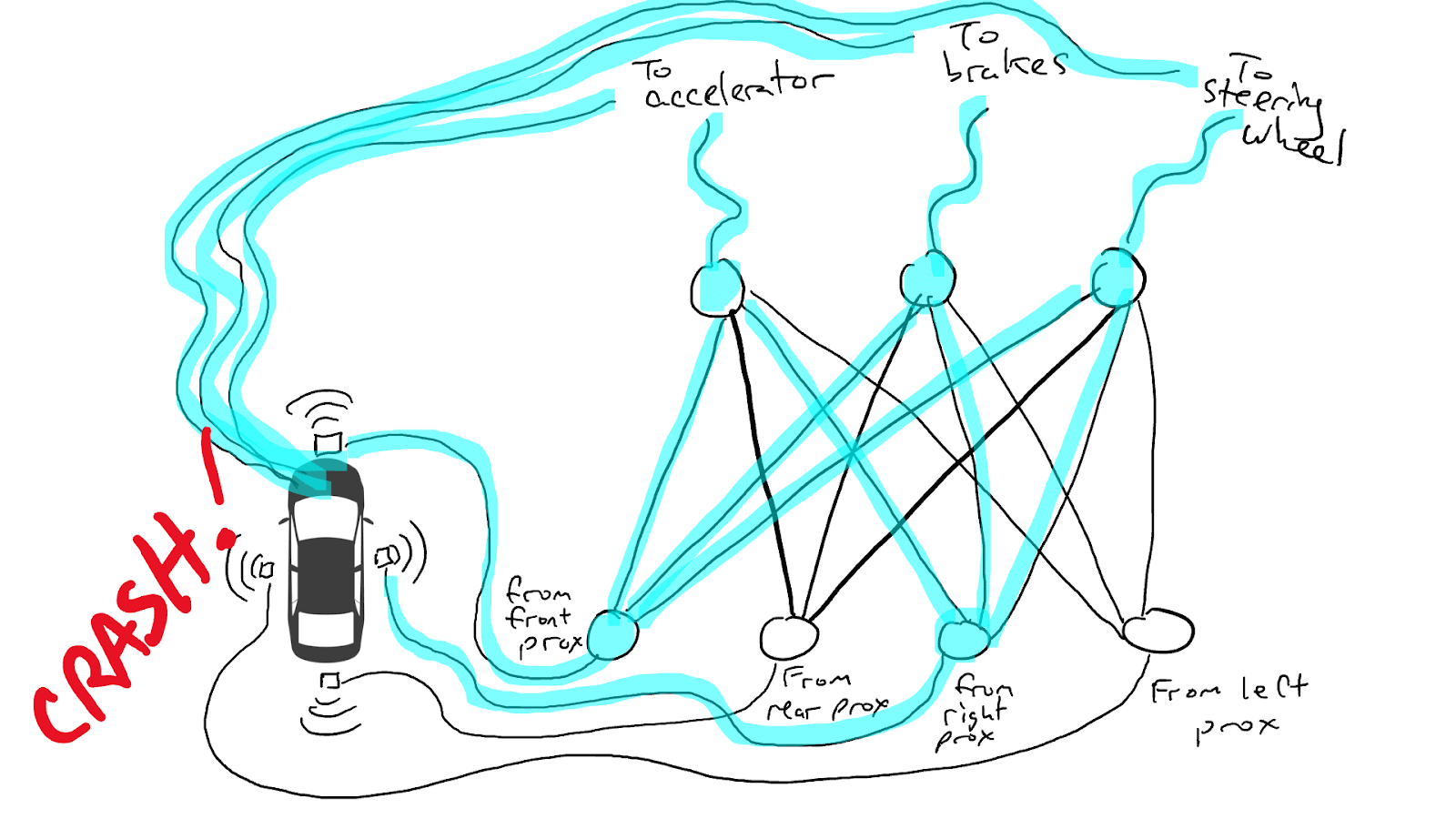
When some of our sensors send energy, that energy flows through to all the actuators and the car accelerates, brakes, and steers all at once.
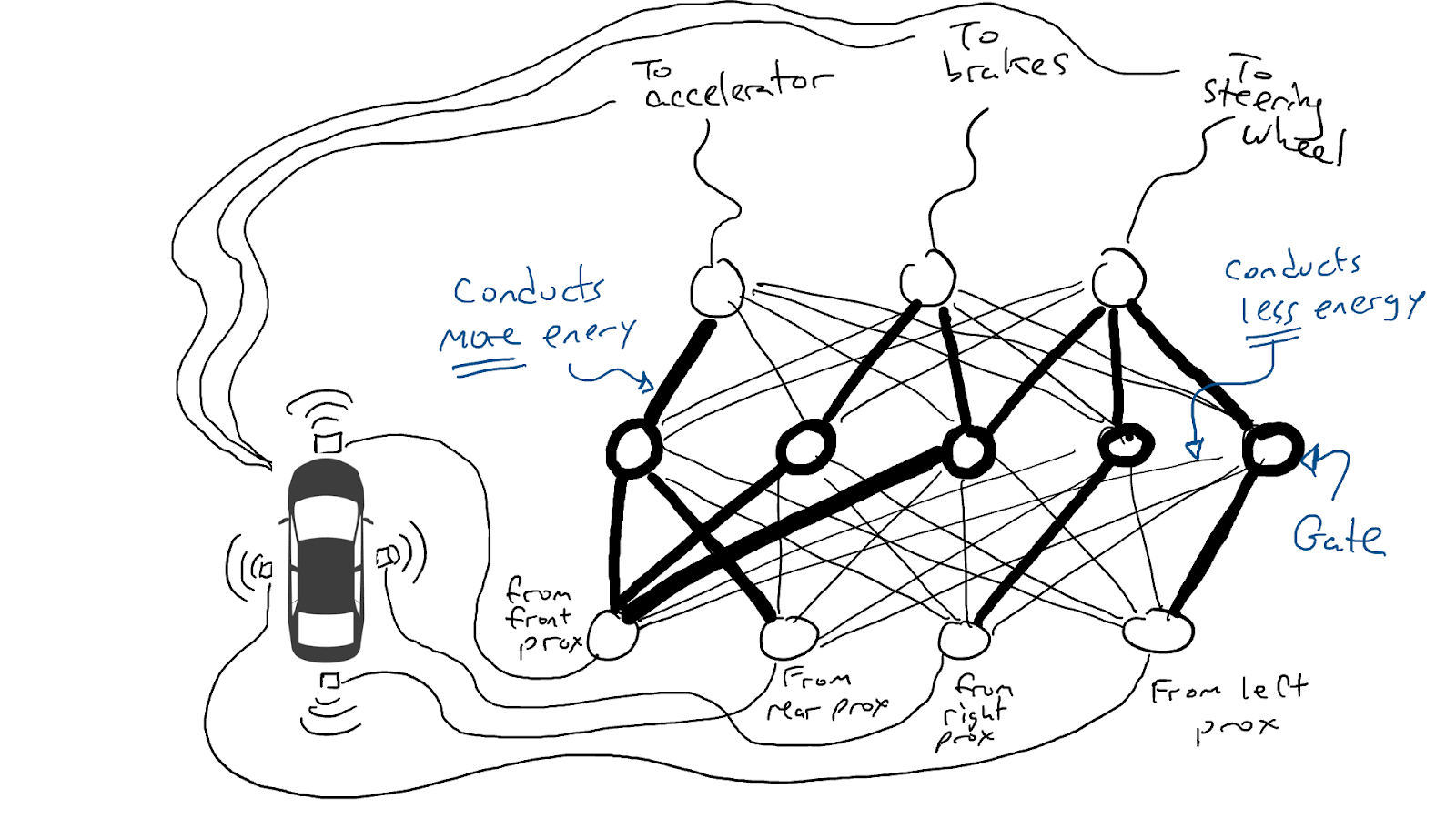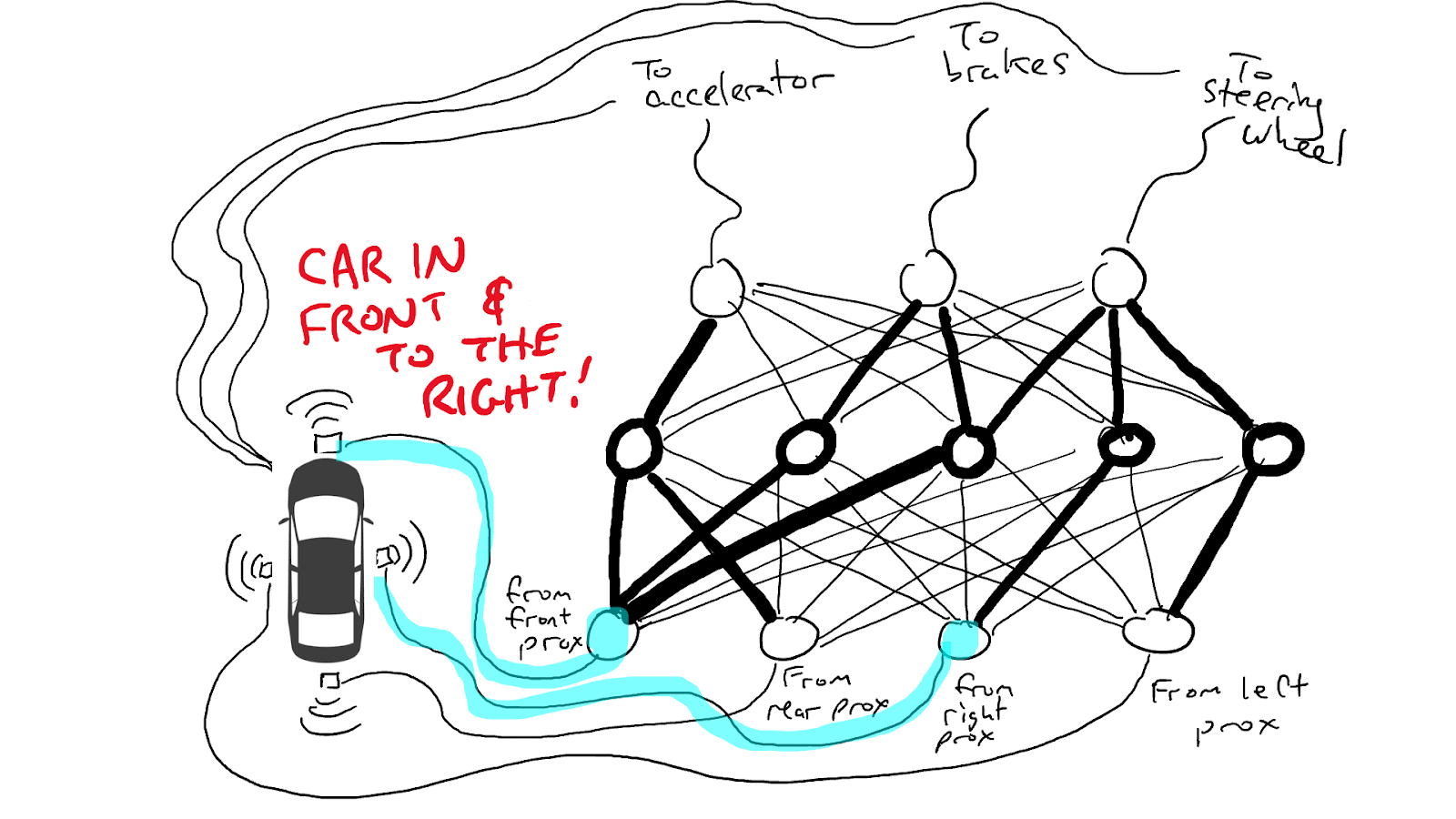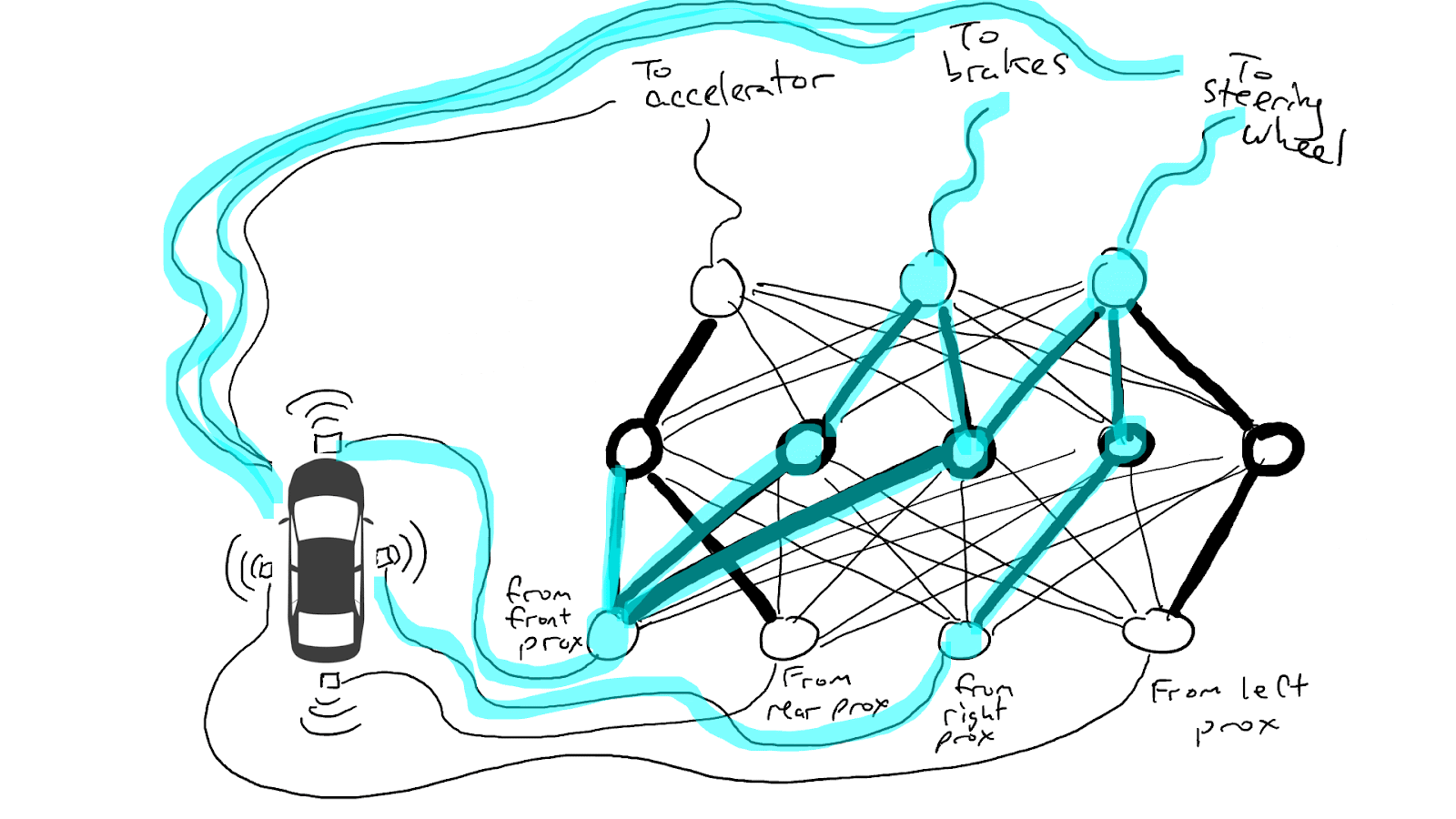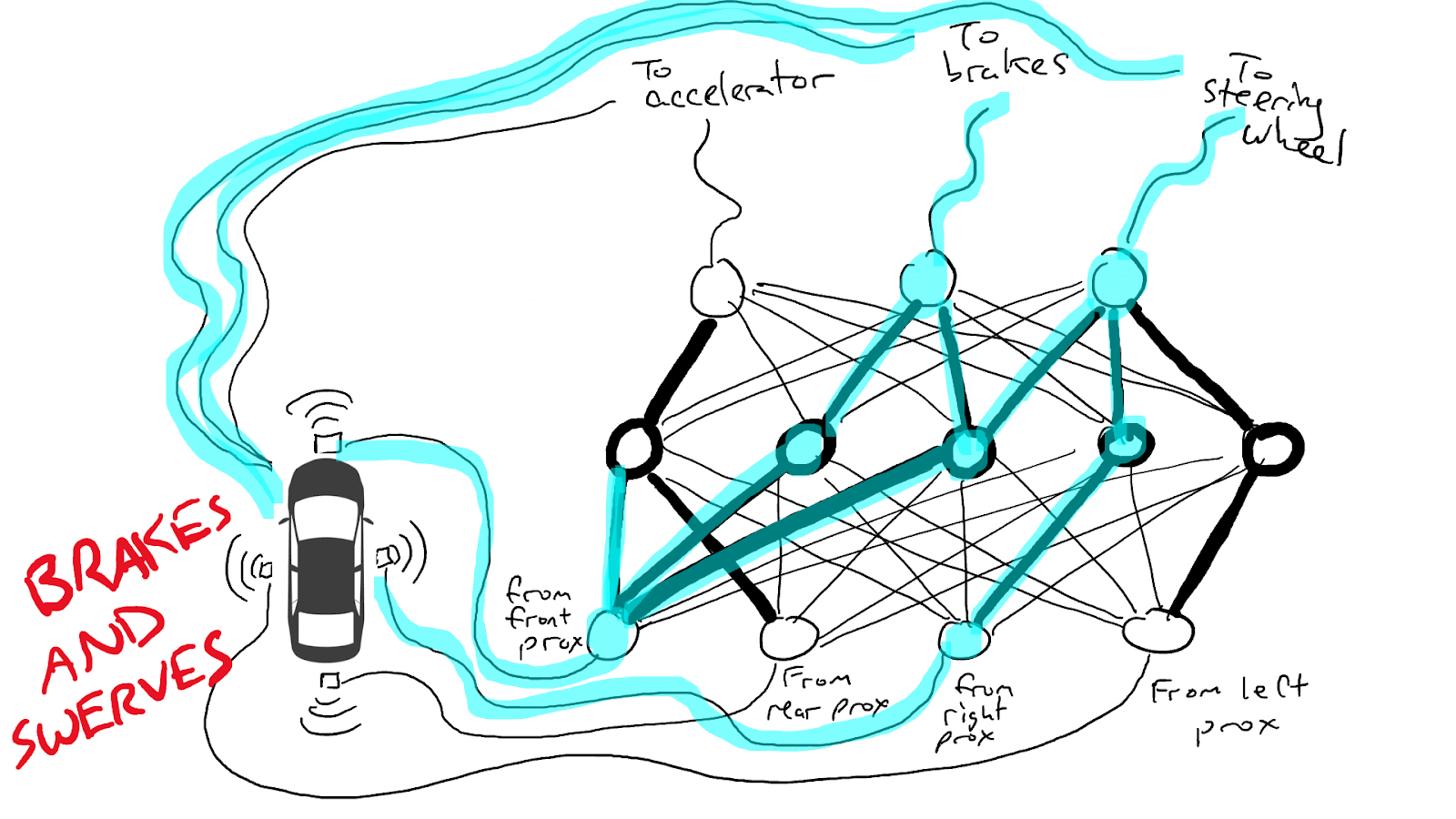
A fully trained neural network.
Darker lines mean parts of the circuit where energy flows more freely. Circles in the middle are gates that might accumulate a lot of energy from below before sending any energy up to the top, or possibly even send energy up when there is little energy below.
(Ref. Medium)
What is Language model?
-
Predicts the next word or sequence of words in a document based on the previous words.
-
Takes text (a prompt) and generates text (a completion).
![[Pasted image 20240210104940.png]]
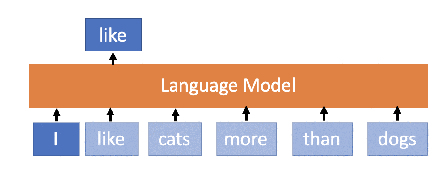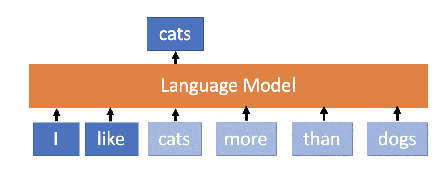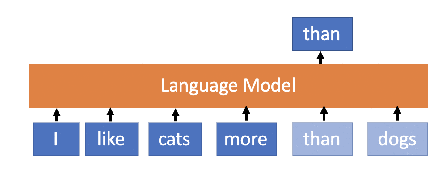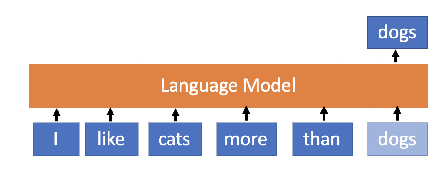
(Ref. Medium)
Applications of Language Models:
-
Sentiment Analysis
-
Language Translation
-
Text Classification
-
Text Generation
-
….
Limitations of Language Models:
-
Lack of world knoledge
-
Inability to handle complex linguistic contexts
-
Weak natural language generation
-
….
What are the capabilities of Large Language Models?
-
Exposed to vastly more text, allowing them to gain broad general knowledge
-
Develop a contextual understanding spanning entire paragraphs or documents
-
Generalize well on new topics and data distributions due to their massive scope
-
….
What is benchmarking in AI?
-
Evaluating the performance of language models or other AI systems
-
Assess their capabilities on various natural language processing tasks

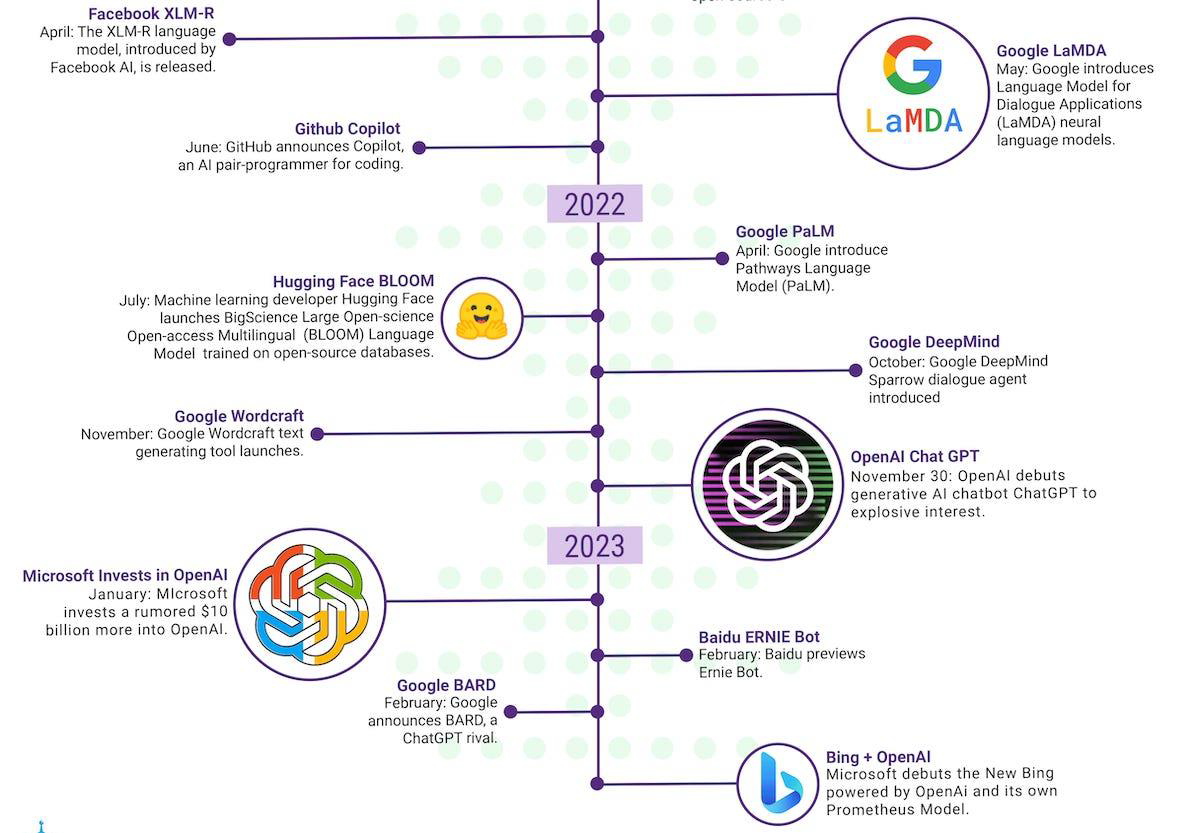
A timeline of LLM history(Ref. Synthedia)
Section 2: Evaluation Framework Design
Benchmarks serve as guiding frameworks for the AI community, embodying values and priorities that direct improvement efforts. Benchmarks are mechanisms for change as well. Benchmarking language models holistically entails assessing them comprehensively across multiple dimensions such as performance, efficiency, robustness, and real-world applicability within a benchmarking framework, ensuring a comprehensive understanding of their capabilities and limitations across various conditions and contexts. Based on these, we’re going to introduce the Holistic Evaluation of Language Models (HELM).

Benchmarking language models holistically involves evaluating their performance across diverse scenarios, considering various criteria, with the relative importance of these factors contingent upon specific scenario. There are three elements for holistic evaluation:
First, HELM adopts a top-down strategy by explicitly defining the evaluation criteria (scenarios and metrics) and making deliberate choices on what subset to evaluate, thereby highlighting areas such as language coverage that may be overlooked.

Second, unlike traditional benchmarks that focus mainly on accuracy and sideline other considerations, HELM adopts a multi-metric approach, emphasizing metrics beyond accuracy and enabling examination of trade-offs between these metrics.

Third, for a meaningful comparison of various language models, it’s essential to standardize the strategy for adapting each model to a given scenario and ensure that all models are evaluated on the same scenarios.
Before our initiative, the assessment of language models was inconsistent. Some of our scenarios lacked any models being evaluated, with only a few scenarios, like BoolQ and HellaSwag, having multiple models assessed. Following the evaluation, models are now systematically assessed across numerous scenarios under similar conditions, promoting greater consistency in evaluation practices.

Evaluation at Scale and Cost:
Language models were evaluated over more than 40 scenarios, covering 6 user-facing tasks (e.g. QA), and conducted 7 targeted evaluations (e.g. reasoning)to delve into particular aspects. The evaluations encompass 7 metrics, including accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency. Additionally, the author conducted benchmark tests on 30 language models (e.g. BLOOM) sourced from 12 different organizations (e.g. OpenAI) using the HELM platform.
This extensive evaluation involved 5,000 runs, appraising each model’s performance across various scenarios, totaling 12 billion tokens and 17 million queries. The financial cost encompassed $38,000 for commercial APIs and approximately 20,000 A100 GPU hours for public models.
Caveats and Considerations about HELM:
1.Different LMs might work in different regimes
- Some models may perform poorly under their evaluation, they may perform well in other contexts
2.Computational resources required to train these models may be very different
- Resource-intensive models generally fare better in our evaluation
3.Hard to ensure models are not contaminated (exposed to test data/distribution)
-
How you adapt the LM (e.g. prompting, probing, fine-tuning) matters
-
Didn’t evaluate all models, and models are constantly being built (e.g. ChatGPT)
Section 3: LLM Evaluation Components
In this section, we will go through different evaluation components of large language models (LLMs).
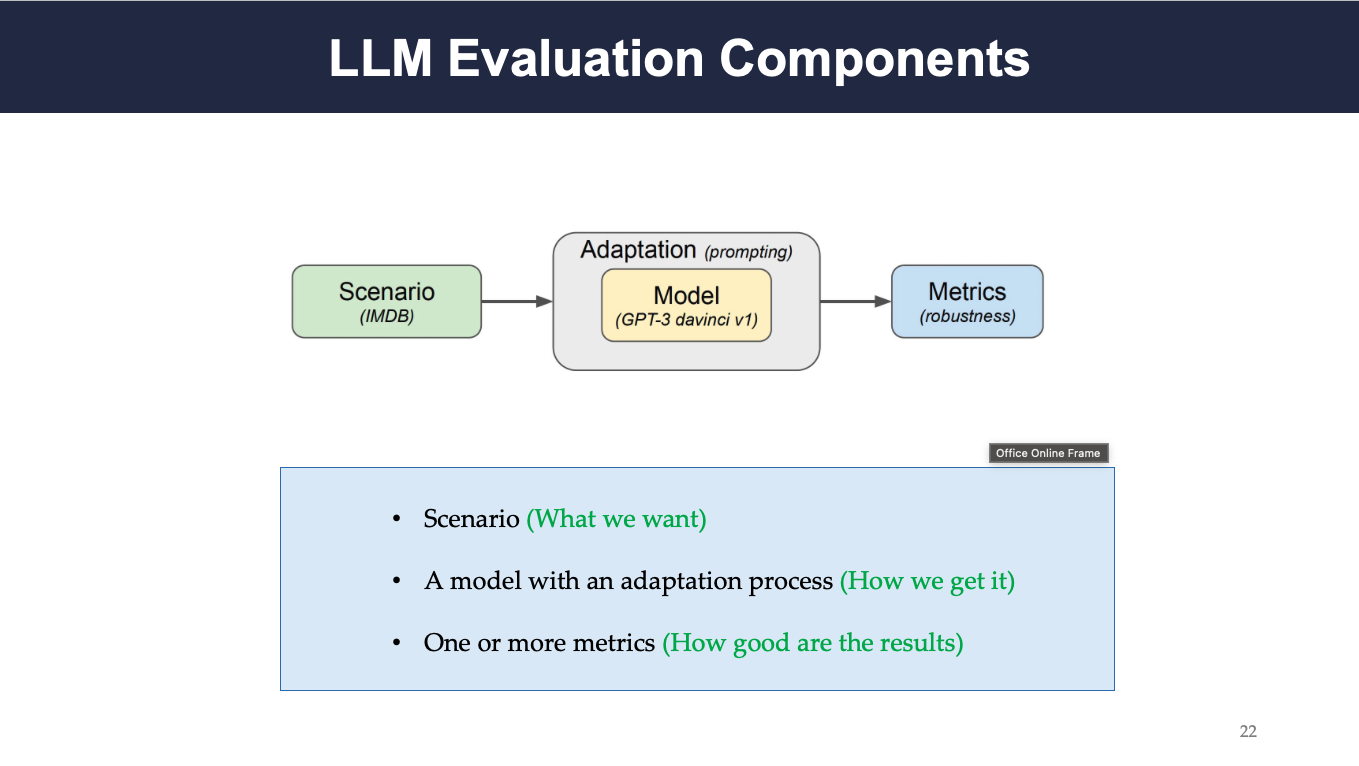
Each evaluation run requires a specific scenario: what we expect from the model, a model with adaptation process: the process of getting the expected outputs, and one or more metrics: to measure how robust the generated results are.
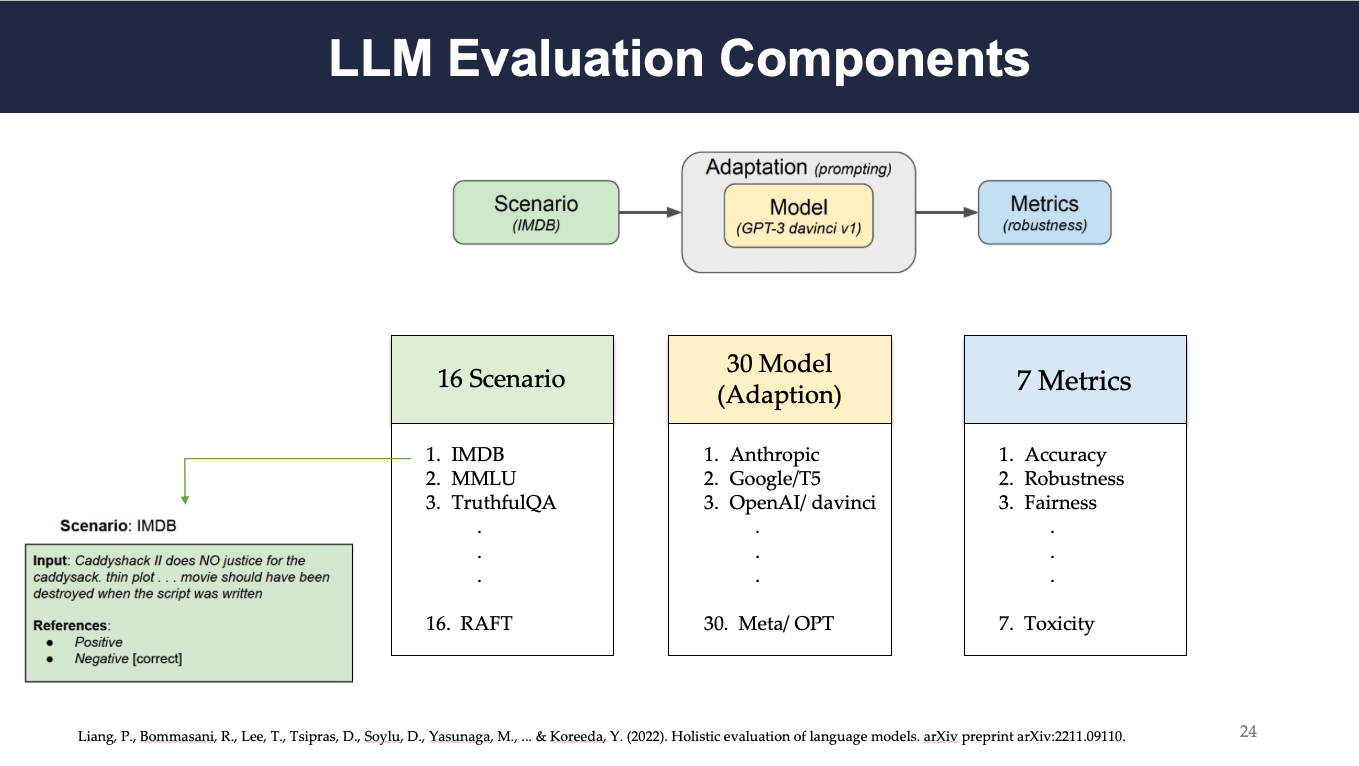
The figure depicts the number of scenarios, models, and metrics considered for this study. A total of 16 different scenarios (i.e., IMDB, MMLU, RAFT, etc.) were instantiated on 30 models through the adaptation process, and later corresponding models were evaluated on 7 metrics (i.e., Accuracy, Fairness, Toxicity, etc.).
Scenario: A scenario encapsulates the desired use case for a language model. It is what we want the models to do. Each training and test set scenario instance consists of an input and a list of references
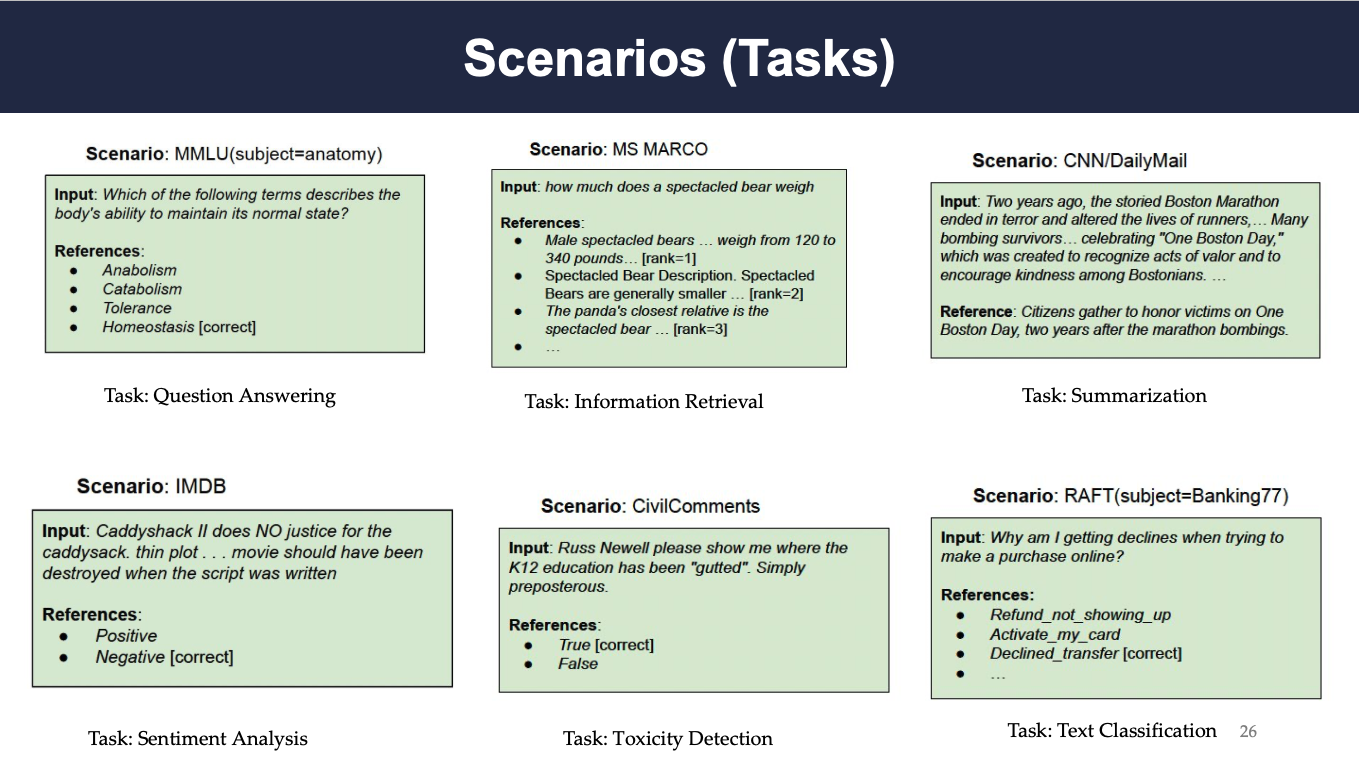
Here are some examples for different scenarios. Various tasks have been designed for each of the scenarios such as, Question Answering, Summarization, Sentiment Analysis, Text Classification, etc. For IMDB scenario example: an input string is provided along with references that contain the correct answer.
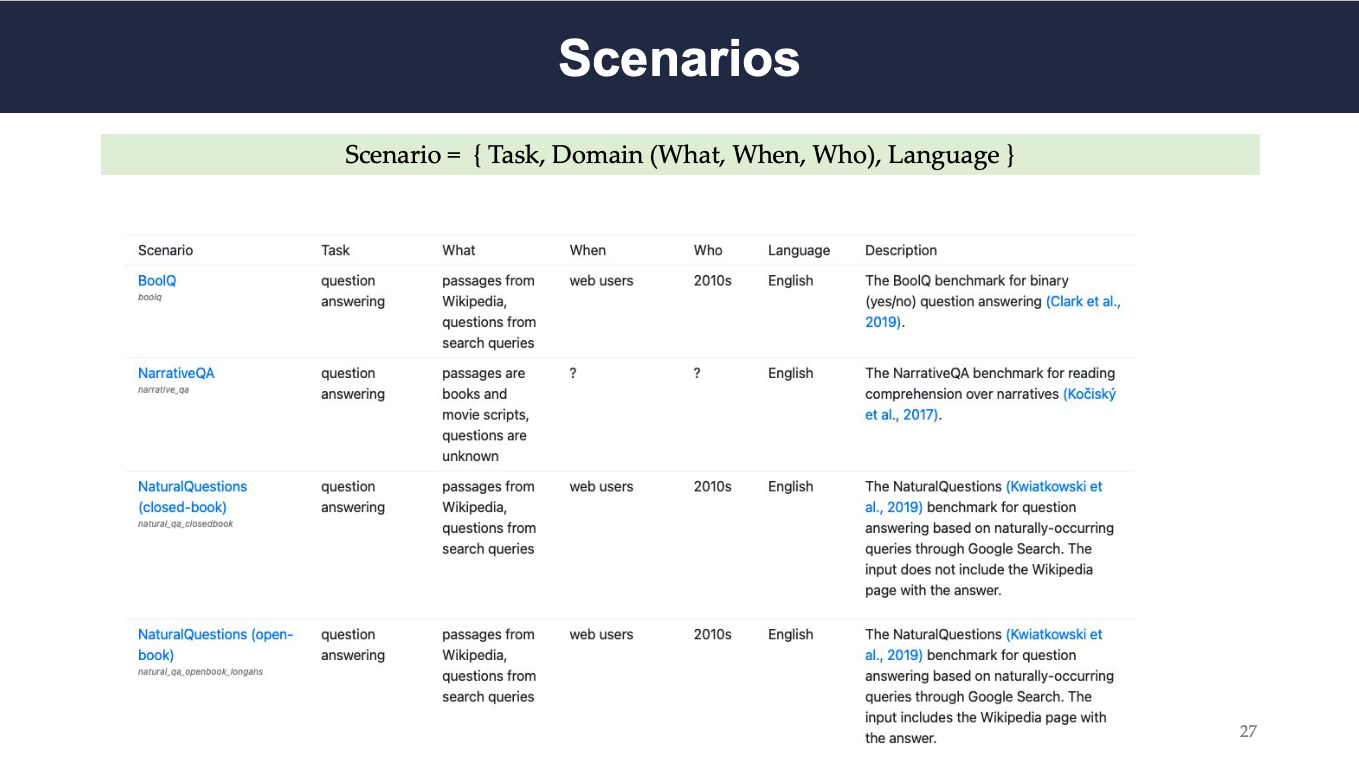
More specifically, a scenario can be considered as a tuple of task, domain and language, where the task defines which type of work should be done, domain specifies the ‘what, when or who’ are associated with the task, and language specifies in which language the model will operate. We can consider the example of BoolQ from the above figure. It is a question answering task, the texts and passages are from Wikipedia, questions are from search queries, the texts and relevant sources were created by web users in 2010, and the operational language is English.
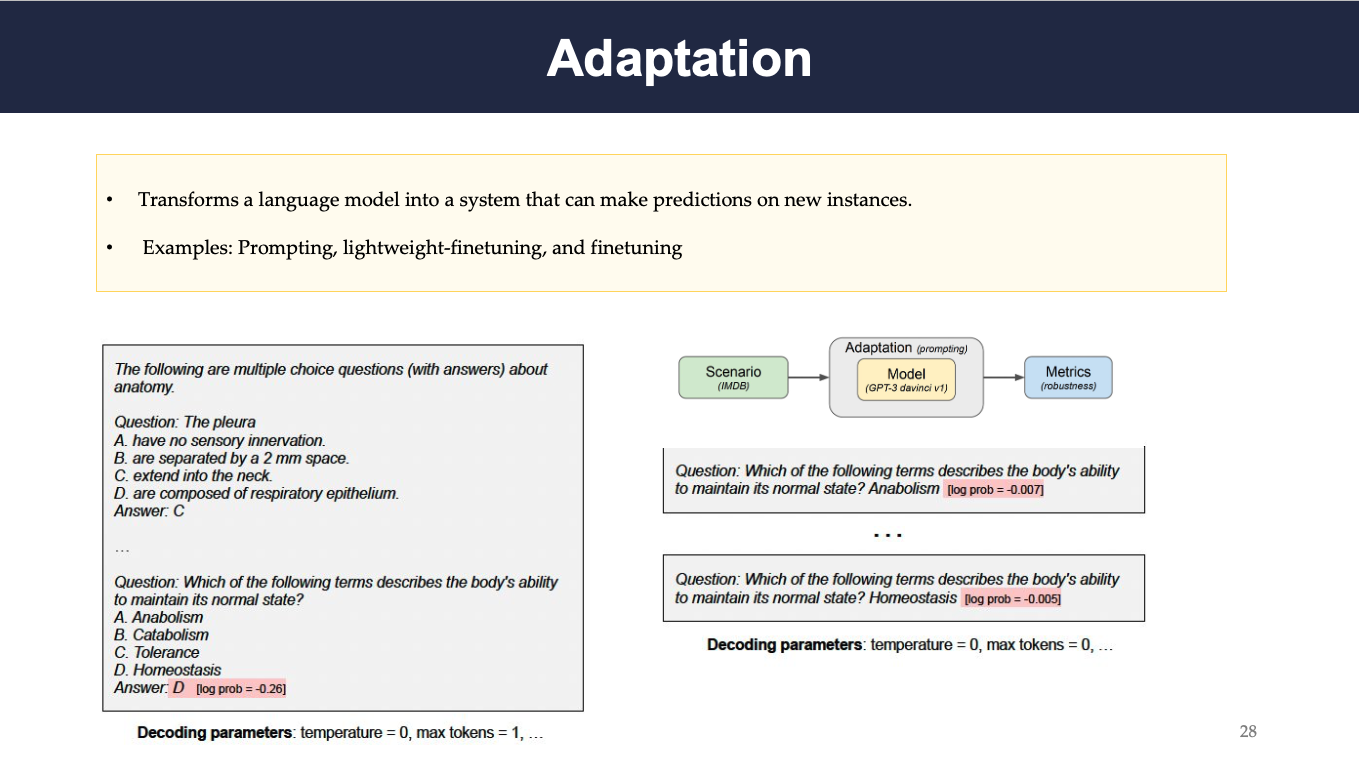
On the other hand, the adaptation process involves transforming a language model into an intermediate system that can make predictions on unseen data. Examples of such adaptation procedures include: prompting, light-weight finetuning, and finetuning. HELM study focuses only on prompting strategy. The above figure demonstrates an example of the adaptation process. A prompt for each evaluation instance was constructed. It may include in-context training instances as well. A decoding parameter is also provided along with the prompt. The model then outputs a completion (marked in red). Two different strategies were adopted for this multiple choice question answering example. The first one is joint strategy (on the right): all answer choices are presented at once, and the other one is separate strategy (on the left): each answer choice is presented separately.

Once a language model is adapted, the resulting system on the evaluation instances of each scenario is executed. This provides the completions with log probabilities. To measure how well the model performs, 7 different metrics are computed over the completion and probabilities. A few notable metrics are: accuracy, fairness, robustness, inference, etc.
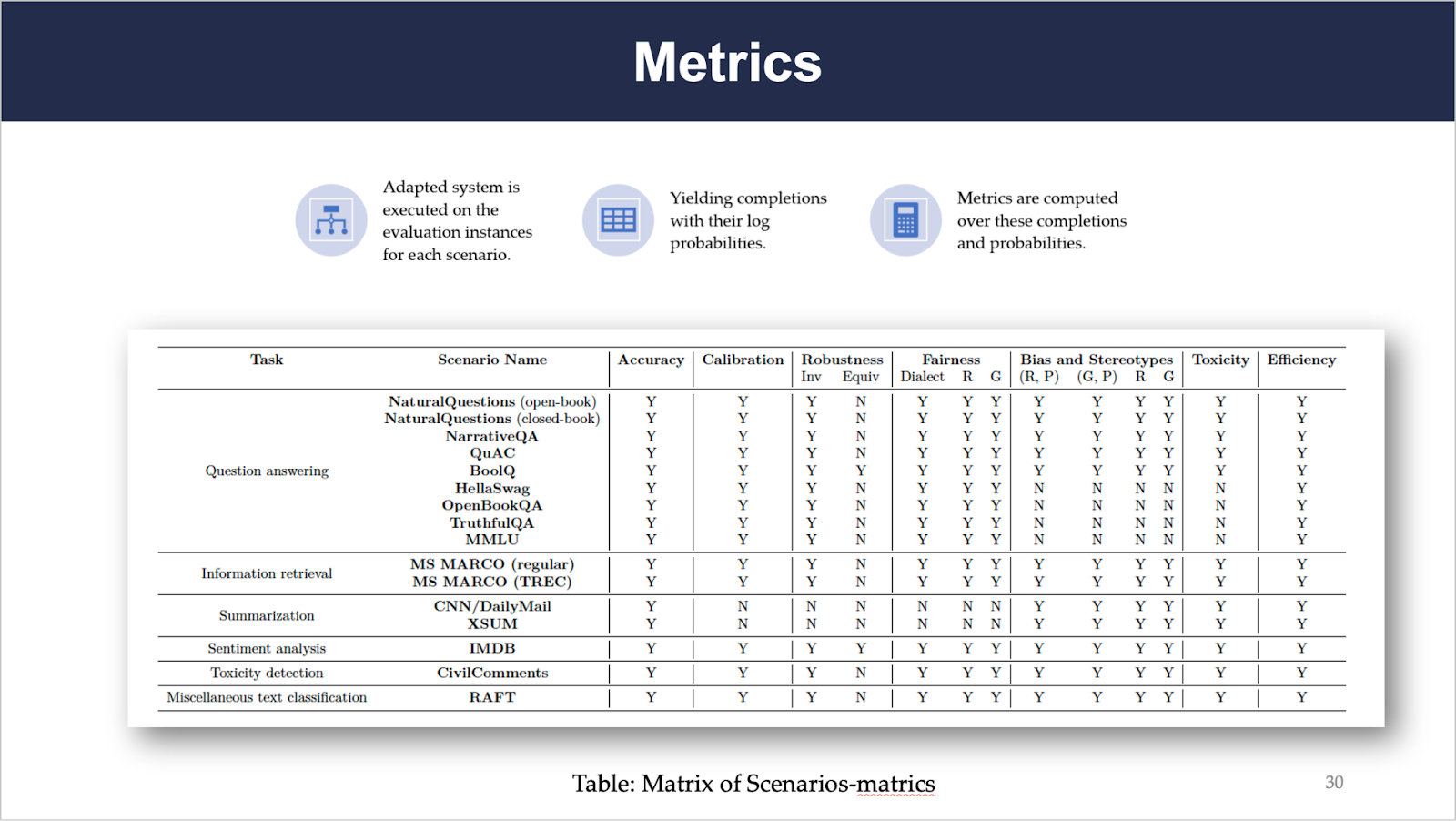
The above table represents the matrix of scenario-metrics. It tabulates the possibility of computing different metrics on each of the 16 scenarios. The study has addressed 98 of 112 (~87.5%) possible (scenario, metrics) pairs. However, the rest of the pairs are not well defined, hence, those are not reported in this study.
Section 4:
Here we introduce the results and discussion of various LLM evaluation tasks.
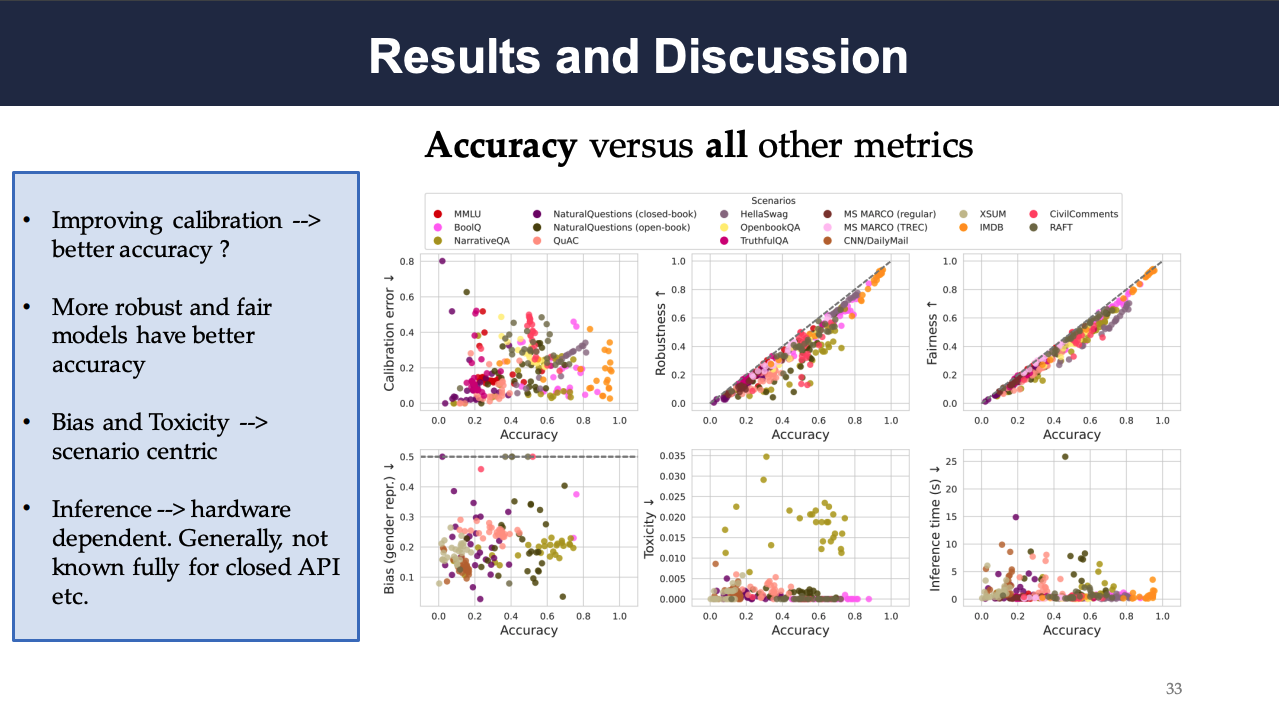
- The relationship between accuracy and calibration depends on the scenario and adaptation procedure. As an example, for HellaSwag, improving accuracy worsens calibration, whereas for OpenBookQA, improving accuracy improves calibration.
- Across all scenarios, strong correlations between accuracy, robustness, and fairness can be observed, where robustness and fairness metrics consider worst-case accuracy over a set of perturbations. While there is a strong correlation between accuracy and fairness, trade-offs can be observed where the most accurate model is not the most robust or most fair.
- The biases and toxicity in model generations are largely constant across models and low overall on average for the core scenarios.
- There is no strong trade-off between accuracy and efficiency (which depends on both the model architecture and the hardware) across all 30 models.
The following result shows how different models would fare in a head-to-head comparison for each metric across all the core scenarios. We can see that 1. text-davinci-002 performs best on our accuracy, robustness, and fairness metrics, 2. Anthropic-LM v4-s3 (52B) is in the top 3 for all 3 metrics (despite being more than 10× smaller in model scale compared to TNLG v2 (530B), which is the second most accurate and fair), 3. Most models have a bias score at around 0.5.![[Pasted image 20240210103855 .png]]
Here are the results of Chatbot Arena on Jan. 29, 2023, which shows that the close source LLMs (e.g., GPT-4, Bard, Claude-1) still outperform the open source ones on this evaluation task.![[Pasted image 20240210103919 .png]]
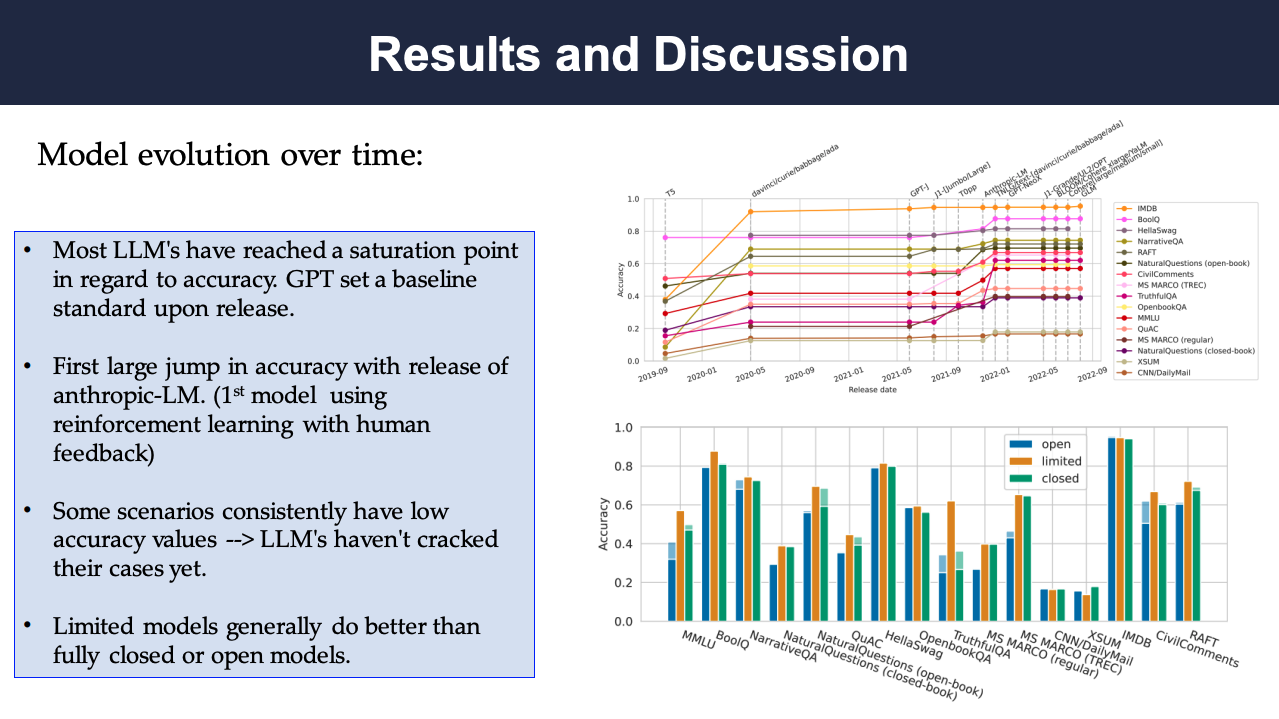
It is interesting to see what the pattern of cumulative accuracy is over time. The first figure in the results below shows the relationship between time (x-axis) and the accuracy of the most accurate model released up to that point (y-axis) across 16 core scenarios. That is, the graph tracks the progress in the state-of-the-art (SOTA) accuracy over time for each scenario. The other figure shows the changes of accuracy as a function of model access. The relationship between access (open vs. limited vs. closed) and model accuracy for each of the 16 core scenarios. Shaded bars indicate the performance of the best model for that scenario, whereas the solid bars indicate the performance of the overall most accurate model across all core scenarios based on Figure 26.
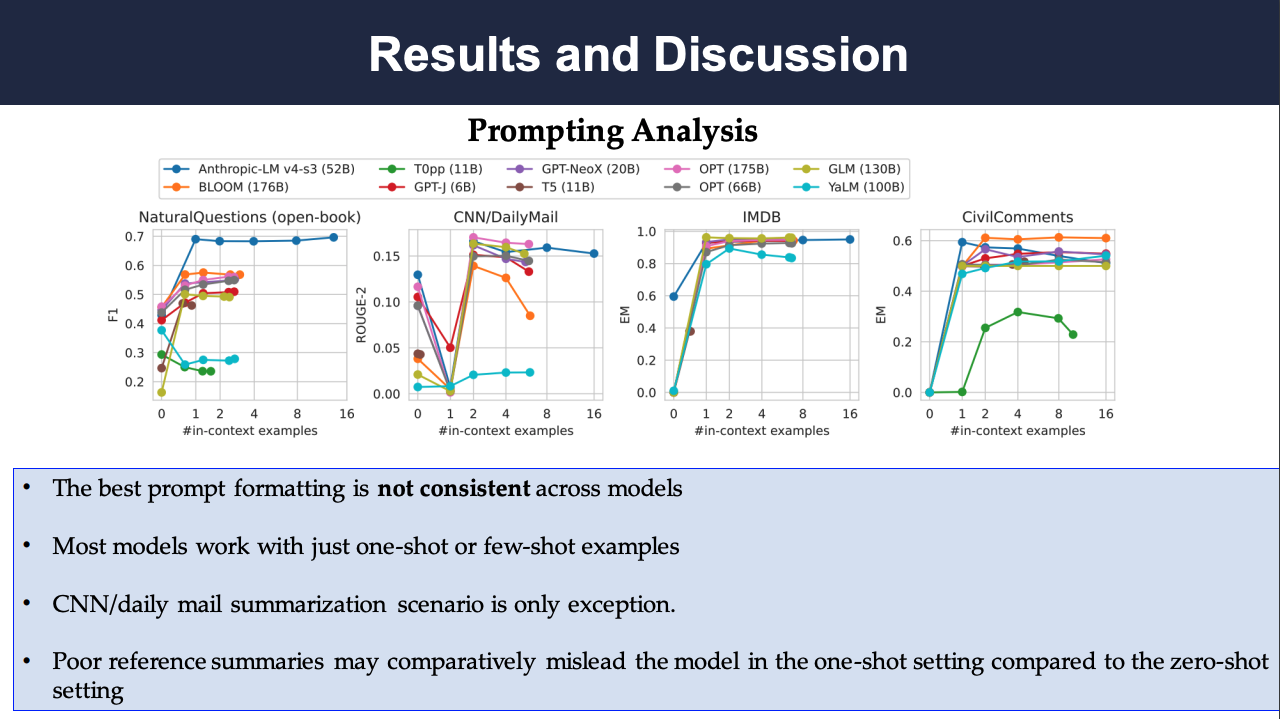
The following figure plots model performance as a fraction of the average number of in-context examples provided (which may be fewer than the maximum stated above if they do not fit inside the context window). For each model, the maximum number of in-context examples is set to [0, 1, 2, 4, 8, 16] and the models will fit as many in-context examples as possible within the context window.
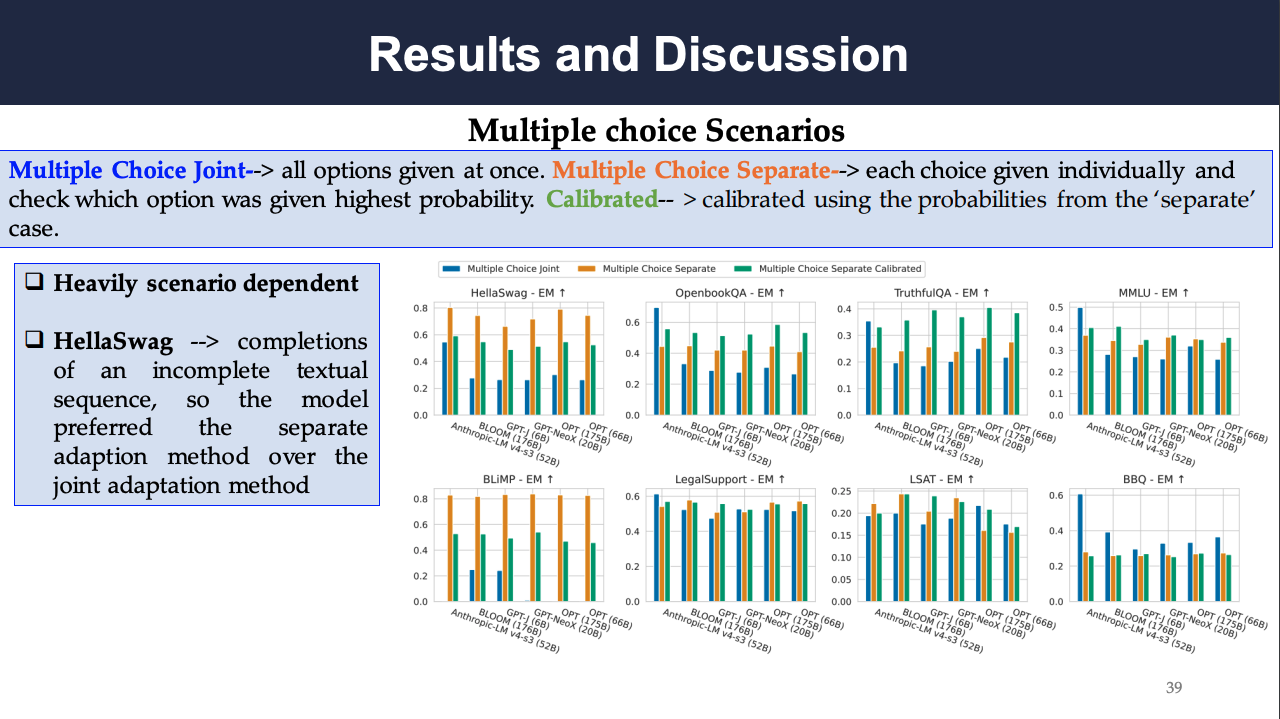
The results for multiple choice scenarios as a function of this choice is visualized below. It can be observed that even for the same scenario, the adaptation method that maximizes accuracy can differ (and produce qualitatively different results) across models. The method that maximizes accuracy is largely determined by the scenario, whereas it is generally consistent across models for a given scenario.
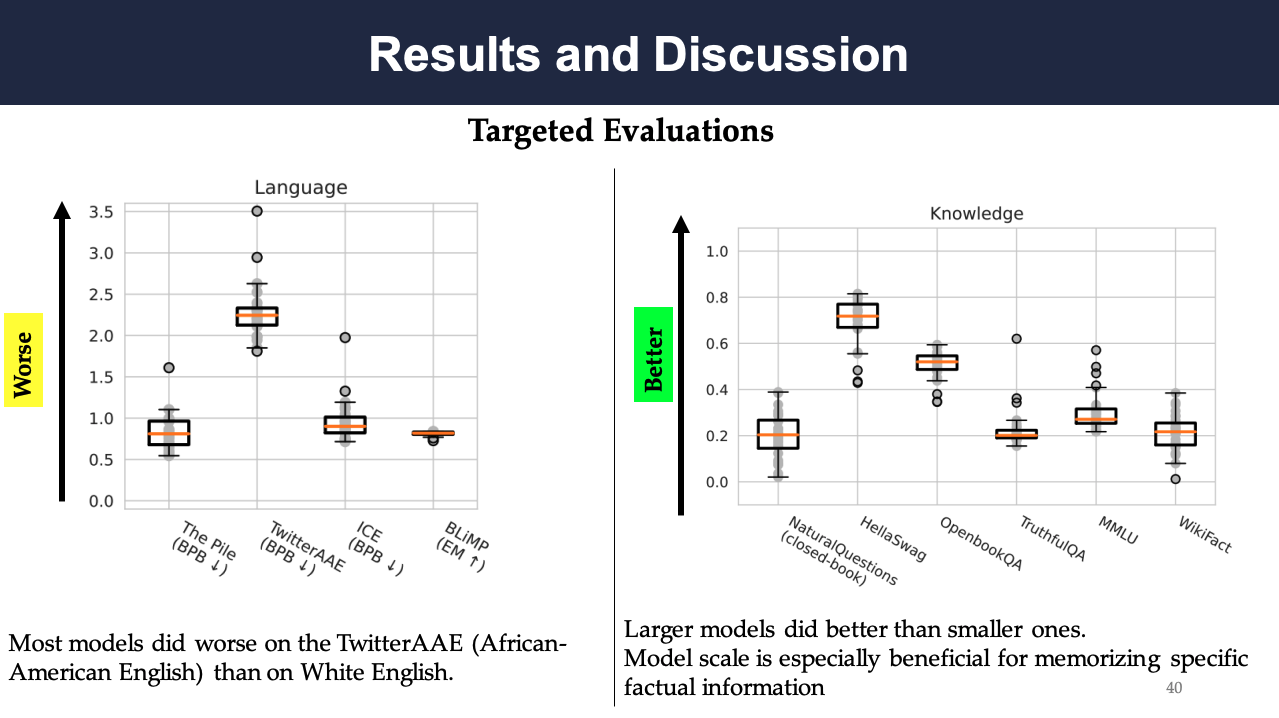
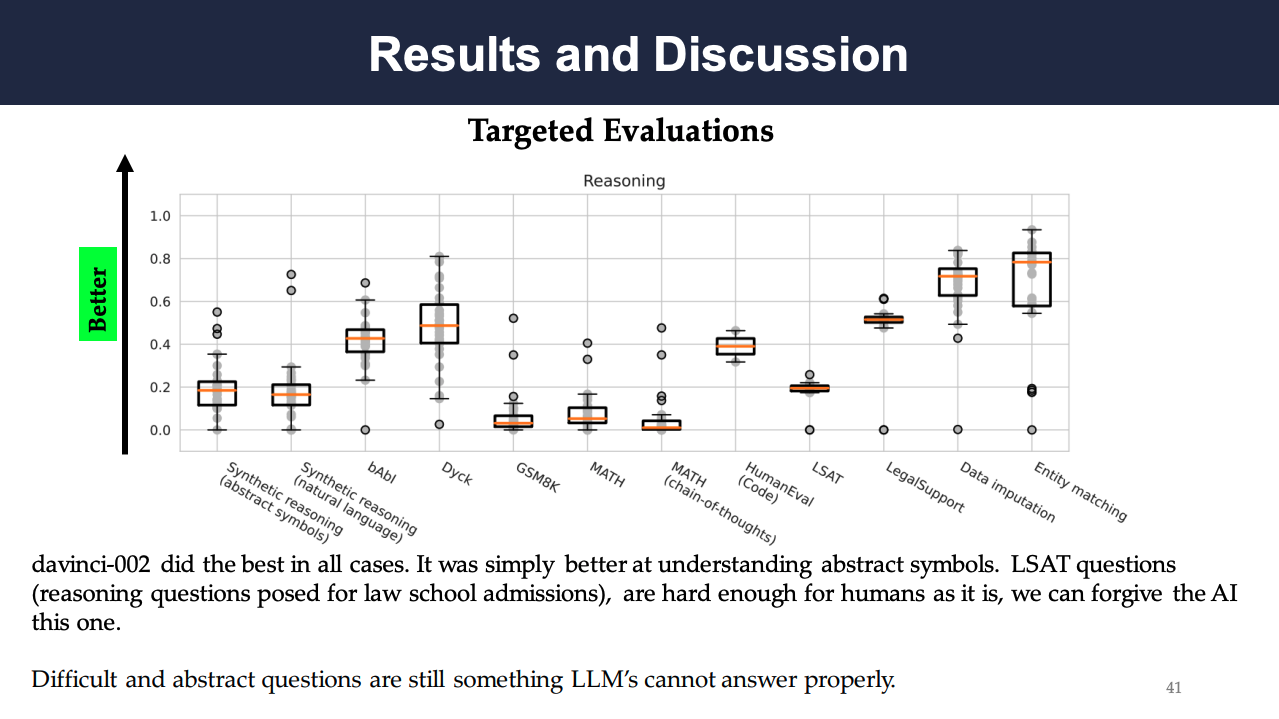
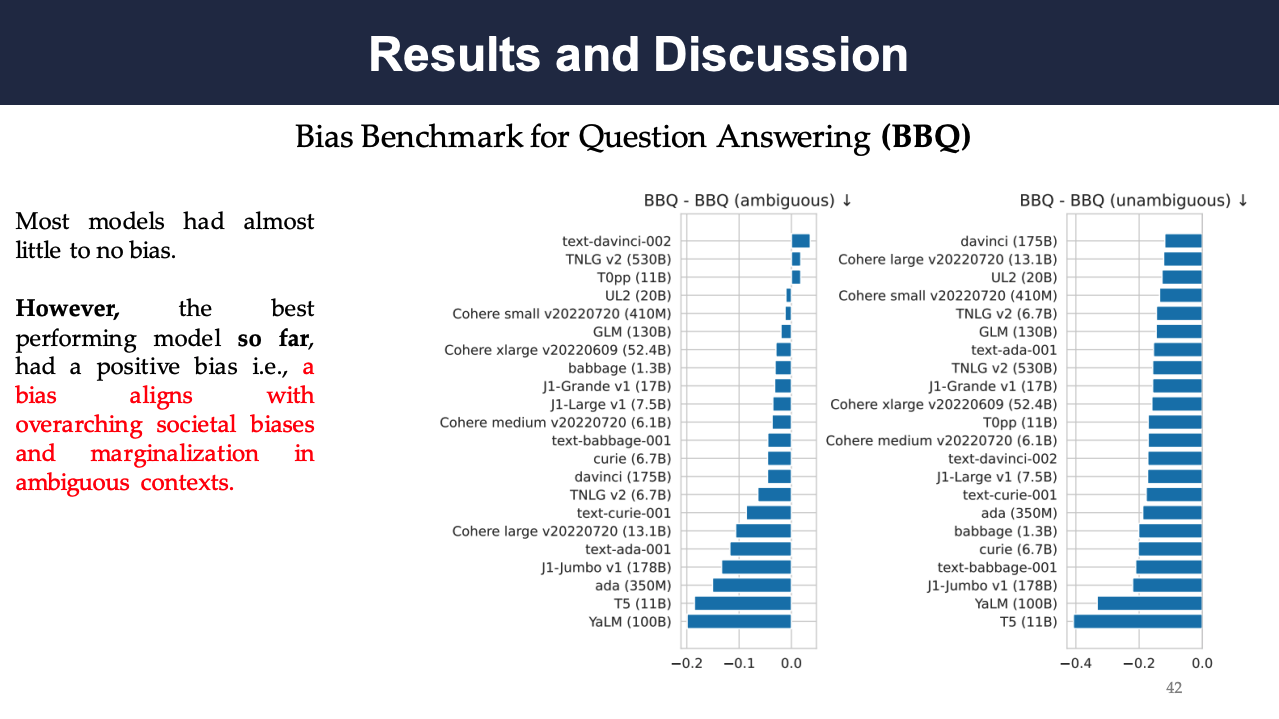
The following results show the targeted evaluation of language, knowledge, reasoning, and social bias, respectively. The language evaluation reports the model accuracy on the four scenarios for evaluating linguistic understanding, and the knowledge evaluation shows the model accuracy on the six scenarios (5 question answering, WikiFact) for evaluating knowledge acquisition. Across all five knowledge-intensive QA scenarios, text-davinci-002 shows to perform the best. The evaluation of reasoning presents the accuracy on 12 scenarios (5 question answering, WikiFact) for evaluating reasoning capabilities. It can be seen that models are most accurate for the structured-data tasks such as entity matching and data imputation, which are primarily based on pattern matching and classification. In contrast, models are relatively inaccurate for tasks that involve abstraction, transitive inference, algebraic and logical reasoning, with natural-language tasks such as LSAT and GSM8K yielding low accuracies. The social bias evaluation mainly depends on the model performance on BBQ, where the accuracy shows a very strong clear correlation with social bias in ambiguous contexts
The last part of our result presentation displays the results of the human evaluation for disinformation. It can be found that for the reiteration scenario, all models received average quality scores above 3, indicating that they generated text that tended to support the given thesis statements.

Section 5: Evaluation of text-to-Image Model
Qualitative improvement over the text-to-image model research has caught a lot of attention recently. A few noteworthy studies on such areas are: DALL-E , Stable Diffusion , Midjourney , Redshift Diffusion , GigaGAN, etc. The appealing outputs of such generative image models have found their applications across many domains i.e., art, design, story-telling, medical imaging etc. However, their associated risks as well as capabilities are not thoroughly assessed. The study Holistic Evaluation of Text-to-Image Models (HEIM) aimed at addressing this critical aspect by introducing a holistic benchmark.

A simple demonstration of why we need such a benchmark is depicted in the figure above. The DALL-E 3 was instructed through a prompt: “Student giving presentation on text-to-image models in front of other students”. The generated images mostly contained people with a specific gender and skin tone.
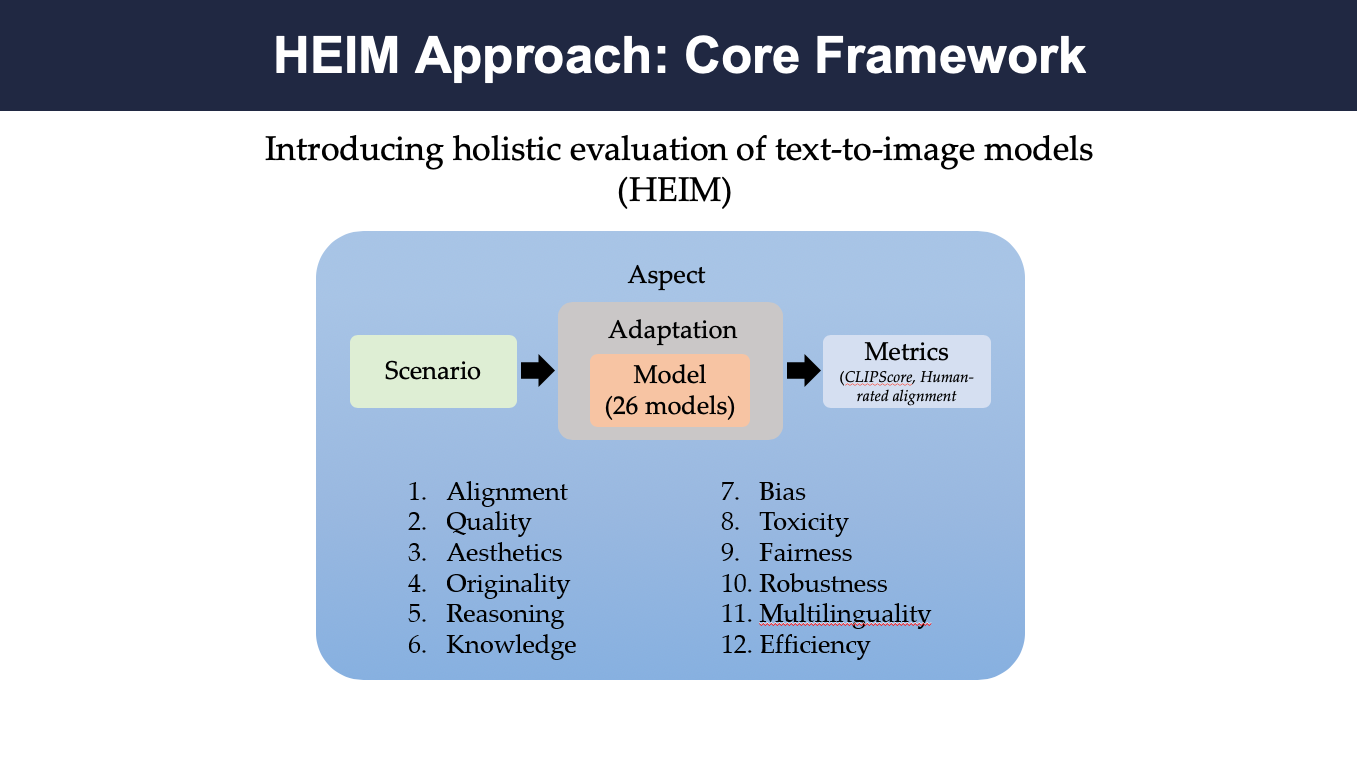
In the above figure, the core evaluation framework of HEIM has been depicted. It is decomposed into 4 key components: an aspect (an evaluative dimension), a scenario (a specific use case), a model with an adaptation process (how the model is run, i.e. prompting), and one or more metrics (capturing how good the results are) [1]. The study covered 12 different aspects, namely, alignment, quality, aesthetics, bias, toxicity, fairness, reasoning, originality, etc. Around 26 different models have been leveraged via the adaptation process. Various metrics have been utilized such as, CLIPScore, Human-rated Alignment, etc.

The above figure shows an overview of the HEIM approach. It includes 12 crucial aspects of image generation (the leftmost column) with 62 prompting scenarios. It also shows the automated metrics (in black font) and human-based evaluation (blue font). In contrast to the existing research which only contains automated metrics on a limited scope, the HEIM study introduced a set of unique metrics such as, aesthetics, originality, etc.
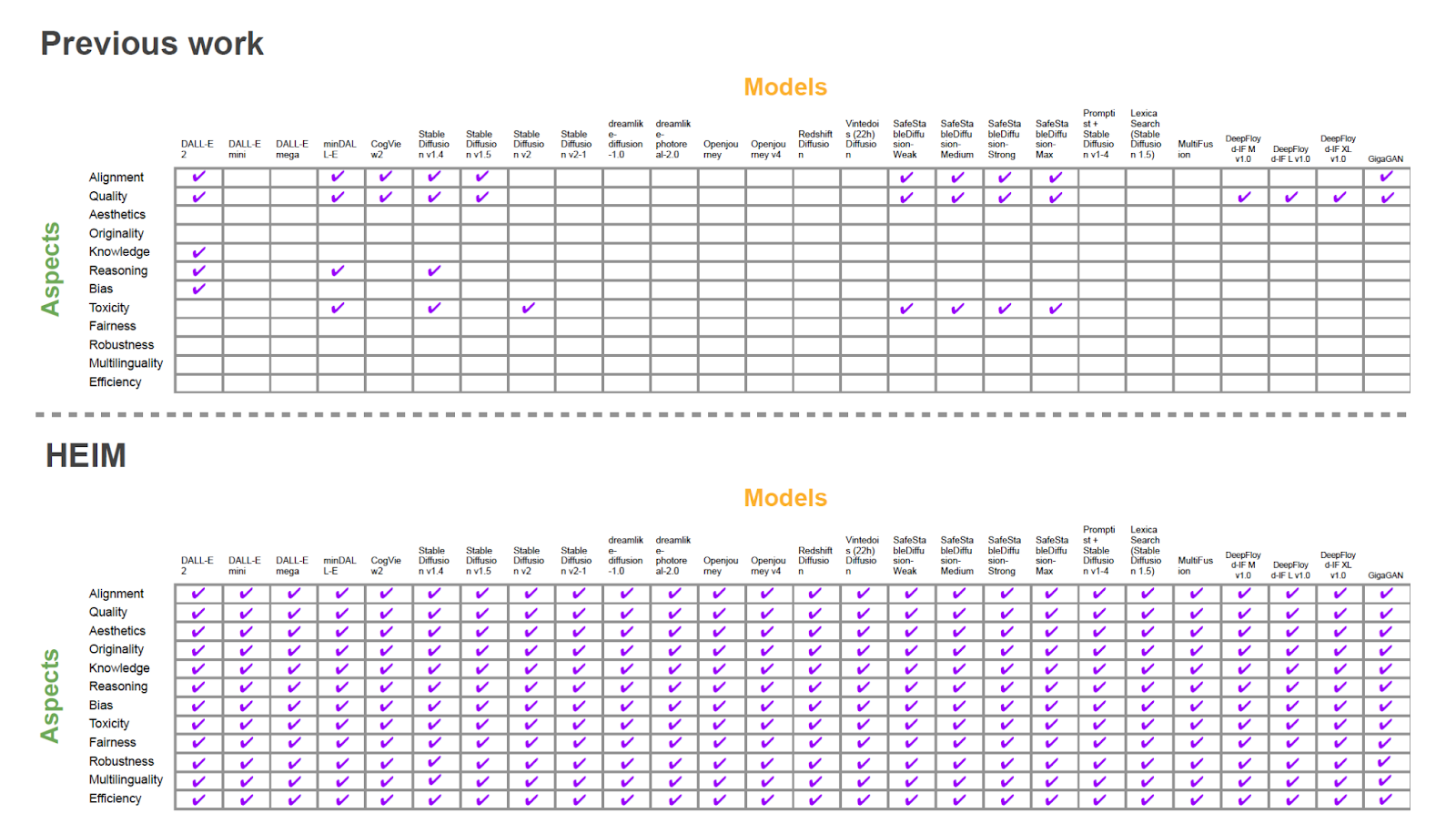
A standardized evaluation is reported where the evaluation approach of previous studies is on the top and the evaluation approach of the current study is on the bottom. It can be observed that the evaluation of image generation models was not comprehensive. Out of 12 core aspects, only 6 aspects were studied previously. For example: DALL-E 2 study evaluated their framework in terms of alignment, quality, knowledge, reasoning and bias, while DALL-E mini or mega were not evaluated on any aspect at all. The HEIM study has taken all possible aspects into consideration while evaluating the respective frameworks.

Here, a few sample outputs from different text-to-image models with various prompts are visualized. The proposed benchmark highlights both the strengths and weaknesses of each model. We can see that most of the models failed to operate in other languages (Multilinguality column). Also, most models responded to toxic contents and generated corresponding outputs. Some models showed gender and skin tone bias.
The holistic evaluation (HEIM) approach has reported a few key findings:
-
Versatile performer across human metrics: DALL-E 2
-
No single model performed the best in all aspects
-
DALL-E 2 → General text-image alignment
-
Openjourney → Aesthetics
-
Dreamlike Photoreal 2.0 → Photorealism
-
minDALL-E and Safe Stable Diffusion → Bias and toxicity mitigation
-
-
Weak correlation was found between human-rated metrics and automated metrics
-
Most models performed poorly in terms of reasoning and multilinguality aspects Particularly, struggled on aspects like originality, bias, and toxicity
Section 6 Evaluation of Generative Text Leveraging LLM
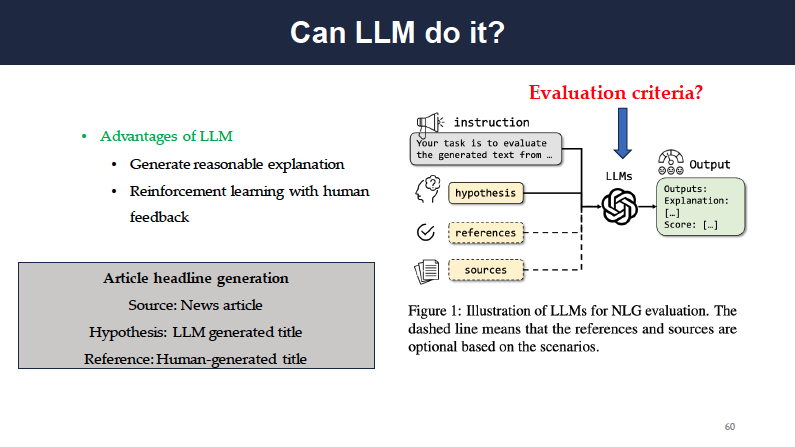
Generative LLMs are powerful for a variety of tasks that fall under the umbrella of Natural Language Generation (NLG). Generally, LLMs are strong at creating reasonable generations and aligning with human feedback through Reinforcement Learning with Human Feedback (RLHF). An example of a practical use case of LLMs performing well on NLG is article headline generation. Given a news article, LLMs can generate a good headline for the article.
We say that the LLMs are good at article headline generation, however, we never answered how. After all, an LLM-generated headline is only a hypothesis, not ground truth. This section of the blog will summarize Evaluation of generative text leveraging LLM: A Survey authored by Li et al., 2024 to illustrate how generative LLMs are evaluated.
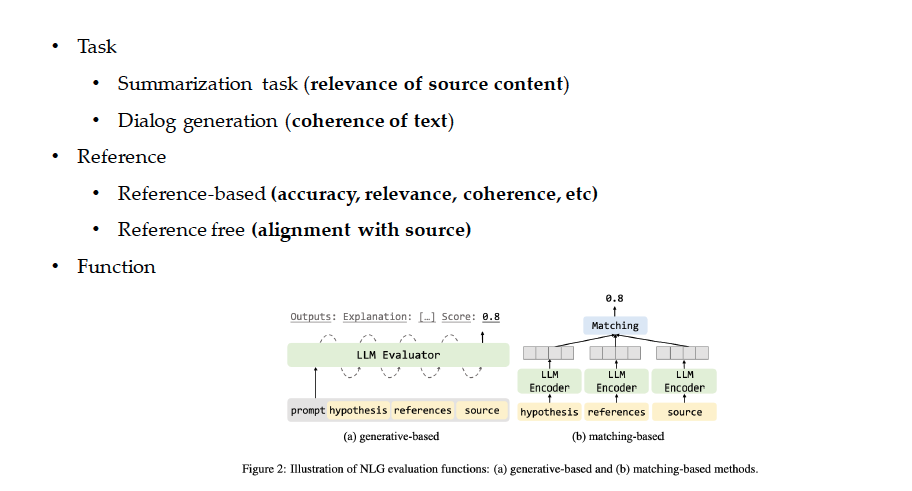
The authors consider 3 aspects of a problem to evaluate LLM performance:
-
Task: What is the LLM supposed to do? For example, Is it summarization, so we measure the relevance to the source content, or is it dialog generation, so we consider the coherence of the text outputted?
-
Reference: Are we referencing the output to anything for evaluation? A reference-based approach will measure, for example, accuracy or relevance, of output with some other information. A reference-free approach will measure the alignment of generation with the source text.
-
Function: Will we evaluate using a generative or matching-based function?

For evaluating an LLM given a task, reference, and function, the appropriate scoring function must also be chosen. Score-based scoring gives a scalar that represents the quality of an output. Probability-based scoring gives a probability of generated text given some prompt, reference, or source. Likert-style scoring classifies the quality of generated text into multiple levels with Likert scales. Pairwise scoring compares the quality of pairs of generated text. Ensemble scoring uses multiple LLM evaluators with different prompts to produce a score. Finally, there are a variety of advanced techniques that use, for example, in-context learning or fine-grained criteria, to produce a score. The authors provide a comprehensive taxonomy for generative evaluation, where these different types of scores are found.

Many LLM NGL problems are evaluated by using LLM evaluators. It is important to have a meta-evaluation of the LLM evaluators to identify their strengths, limitations, and areas of future growth. Li et al. systematically do a meta-evaluation of LLM evaluators meant for machine translation, text summarization, dialogue generation, image captioning, data-to-text, story generation, and general generation. ![[Pasted image 20240210104507 .png]]
For the community to have a more comprehensive understanding of LLM evaluations, there is an opportunity to experiment to explore bias and robustness in evaluations as well as to take a deeper look into domain-specific and unified evaluations
Overall Li et al., 2024 make the following contributions:
-
The authors provide a comprehensive taxonomy of NLG evaluation for LLMs.
-
The authors give a critical analysis of LLM-based NLG evaluation approaches.
-
The authors systematically summarize the meta-evaluations of LLM evaluators.
-
The authors identified unsolved issues in LLM evaluation.
References:
- “LMSys Chatbot Arena Leaderboard - a Hugging Face Space by Lmsys.” LMSys Chatbot Arena Leaderboard - a Hugging Face Space by Lmsys, huggingface.co/spaces/lmsys/chatbot-arena-leaderboard. Accessed 8 Feb. 2024.
- Chen, Mark, et al. “Evaluating large language models trained on code.” arXiv preprint arXiv:2107.03374 (2021).
- Ganguli, Deep, et al. Challenges in Evaluating AI Systems. 2023, https://www.anthropic.com/index/evaluating-ai-systems.
- Guo, Zishan, et al. “Evaluating large language models: A comprehensive survey.” arXiv preprint arXiv:2310.19736 (2023).
- Lee, Tony, et al. “Holistic evaluation of text-to-image models.” arXiv preprint arXiv:2311.04287 (2023).
- Li, Zhen, et al. “Leveraging Large Language Models for NLG Evaluation: A Survey.” arXiv preprint arXiv:2401.07103 (2024).
- Riedl, Mark. “A Very Gentle Introduction to Large Language Models without the Hype.” Medium, Medium, 25 May 2023, mark-riedl.medium.com/a-very-gentle-introduction-to-large-language-models-without-the-hype-5f67941fa59e. [Original source: https://studycrumb.com/alphabetizer]