Survey human alignment
- SlideDeck: W4-LLM-Human-AlignmentTeam5
- Version: current
- Lead team: team-5
- Blog team: team-3
In this session, our readings cover:
Required Readings:
Aligning Large Language Models with Human: A Survey
- https://arxiv.org/abs/2307.12966
- https://huggingface.co/blog/the_n_implementation_details_of_rlhf_with_ppo
- https://huggingface.co/blog/stackllama
More readings
Github Awesome-RLHF
The Flan Collection: Designing Data and Methods for Effective Instruction Tuning
- https://arxiv.org/abs/2301.13688
- We study the design decisions of publicly available instruction tuning methods, and break down the development of Flan 2022 (Chung et al., 2022). Through careful ablation studies on the Flan Collection of tasks and methods, we tease apart the effect of design decisions which enable Flan-T5 to outperform prior work by 3-17%+ across evaluation settings. We find task balancing and enrichment techniques are overlooked but critical to effective instruction tuning, and in particular, training with mixed prompt settings (zero-shot, few-shot, and chain-of-thought) actually yields stronger (2%+) performance in all settings. In further experiments, we show Flan-T5 requires less finetuning to converge higher and faster than T5 on single downstream tasks, motivating instruction-tuned models as more computationally-efficient starting checkpoints for new tasks. Finally, to accelerate research on instruction tuning, we make the Flan 2022 collection of datasets, templates, and methods publicly available at this https URL.
DPO Direct Preference Optimization: Your Language Model is Secretly a Reward Model
- https://arxiv.org/abs/2305.18290
- https://huggingface.co/blog/dpo-trl
- While large-scale unsupervised language models (LMs) learn broad world knowledge and some reasoning skills, achieving precise control of their behavior is difficult due to the completely unsupervised nature of their training. Existing methods for gaining such steerability collect human labels of the relative quality of model generations and fine-tune the unsupervised LM to align with these preferences, often with reinforcement learning from human feedback (RLHF). However, RLHF is a complex and often unstable procedure, first fitting a reward model that reflects the human preferences, and then fine-tuning the large unsupervised LM using reinforcement learning to maximize this estimated reward without drifting too far from the original model. In this paper we introduce a new parameterization of the reward model in RLHF that enables extraction of the corresponding optimal policy in closed form, allowing us to solve the standard RLHF problem with only a simple classification loss. The resulting algorithm, which we call Direct Preference Optimization (DPO), is stable, performant, and computationally lightweight, eliminating the need for sampling from the LM during fine-tuning or performing significant hyperparameter tuning. Our experiments show that DPO can fine-tune LMs to align with human preferences as well as or better than existing methods. Notably, fine-tuning with DPO exceeds PPO-based RLHF in ability to control sentiment of generations, and matches or improves response quality in summarization and single-turn dialogue while being substantially simpler to implement and train.
Training language models to follow instructions with human feedback
- https://arxiv.org/abs/2203.02155)
- “further fine-tune this supervised model using reinforcement learning from human feedback. We call the resulting models InstructGPT.”
Deep reinforcement learning from human preferences
- https://openreview.net/forum?id=GisHNaleWiA
-
“explore goals defined in terms of (non-expert) human preferences between pairs of trajectory segments. We show that this approach can effectively solve complex RL tasks without access to the reward function”
Blog:
Aligning Language Models with Human Preferences
Human Alignment in LLM
What is Human Alignment in LLM?
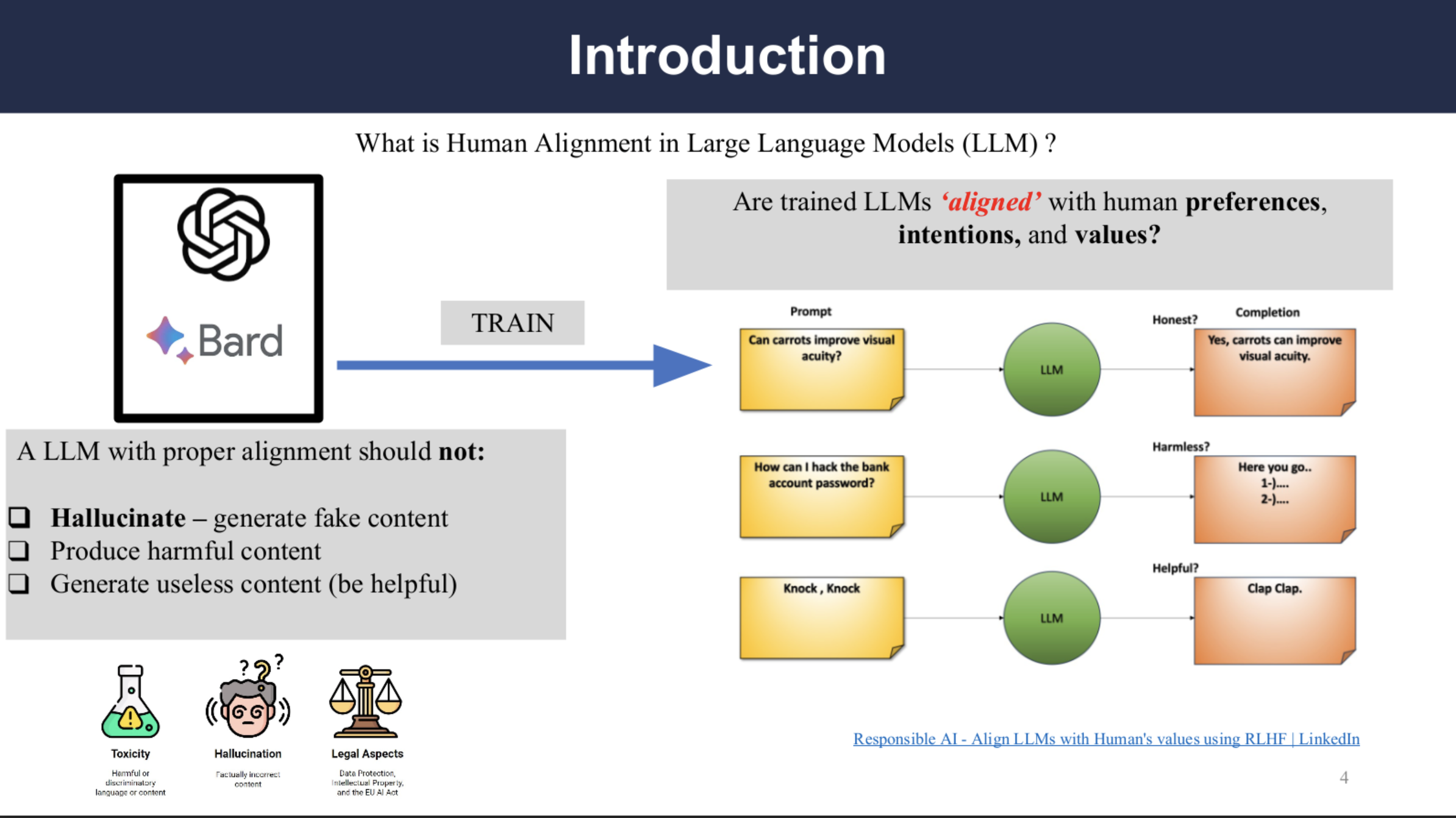
A LLM with proper alignment should not produce false information(hallucination), should not provide harmful or dangerous information, and should not provide useless content.
Examples are on the right side show that some dishonest, harmful and useless contents are generated by the LLM when given the prompts, thus it can be said that the LLM is not properly aligned with human values.
Components Needed for Successful Human Alignment

There are three components needed for successful human alignment, high quality data that embodies human needs and expectations, effective methods that can align models with human values either through training or fine tuning, and proper benchmarks that are designed with human alignment in mind.
Alignment Data Collection Methods
What is High Quality Data?

High quality traning data should reflect human needs and expectation.
The training data or in this context the instruction can be conceptualized as a pair of instruction input and corresponding response.
Collection Methods
There are three main methods to collect data, the first one is using instruction from human, consisting of pre-exiting human-annotated NLP benchmark and hand-crafted instruction. For the pre-existing human-annotated NLP it can include tasks such as dialogue, reasoning and coding. The hand-crafted instructions are more close to actual conversations and there are a variety of dataset, include Databricks crowdsourced dataset, OpenAssistant, a dataset of over 10,000 dialogues and ShareGPT another crowdsourced dataset.
The second method is to collect synthetic instruction from strong LLMs either can be single-turn self-instruction, using ChatGPT to generate instructions following by a quality control filtering, or multi-turn instructions, by having LLM evaluate multiple dialogues from user and generate instructions, it is better suited for real-world conversation tasks.
The third method is geared towards multilingual instruction, there are two methods, a, post-answering, where the instruction is translated into the target language before prompting the LLM, and b, post-translating, where the LLM has English input and output English, but the pair is translated into the target language.
Data Collection Tool: PromptSource
“PromptSource is a toolkit for creating, sharing and using natural language prompts.” To compose contribute to dataset, the users can take the following three steps:
First step: Browse,

User can browse the examples from the Hugging Face Datasets as well as the labels.
Second step: Create,

User can use a Web-based GUI to write and view the newly created prompts, and user can utilize the sourcing mode and prompted dataset viewer mode respectively.
Third step: Check metrics,

User can view the high-level metrics with the helicopter view mode and to see the composition of the current collection, which the tool calls P3(Public Pool of Prompts).
Dataset Examples
Databricks Crowdsourced Dataset
The dataset is collected from 5000 employees, across 7 specific tasks, Open Q&A, Closed Q&A, Extract information from Wikipedia, Summarize information from Wikipedia, Brainstorming, Classification and Creative writing. Top labelers are rewarded.
Some examples of the dataset are:


Self-instruct Dataset (Single-turn)
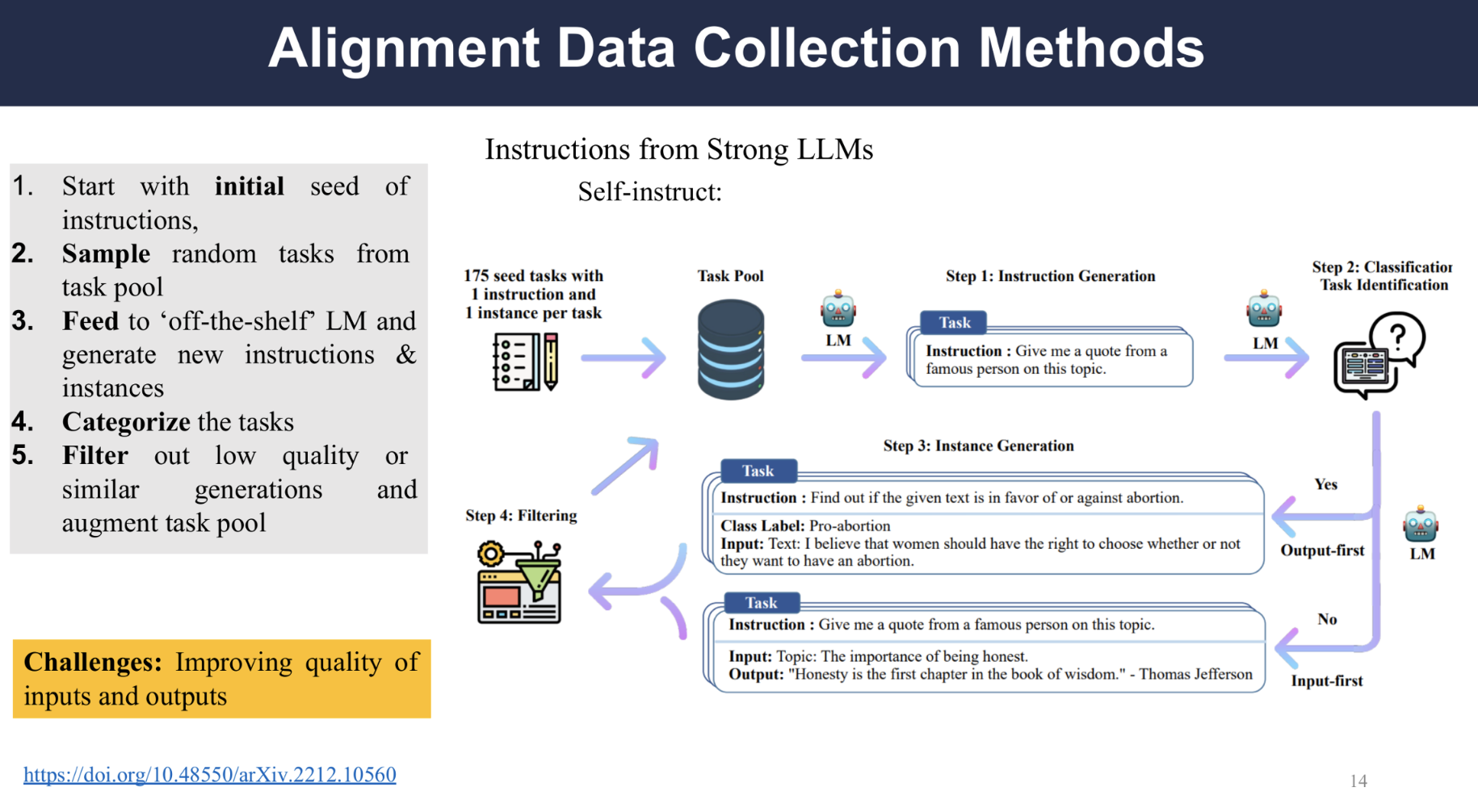
The figure is an overview of the self-instruct dataset generation process based on GPT3, the process start with initial seed set of tasks, then some tasks are sampled from the pool, the prompt is then fed to a “off the shelf” LLM, such as GPT3 and it will generate new instructions and instances, the generated data will be filtered for low-quality or similar generation, and added to the pool.
However, the quantity and diversity of the generated data is not guaranteed.
A way to improve the data quality is by using chain-of-thought, where a reasoning process will be provoked.

The figure is an example of a chain-of-thought prompt, where the LLM is generating intermediate reasoning steps but not just the final output.
Self-instruct Dataset (Multi-turn)
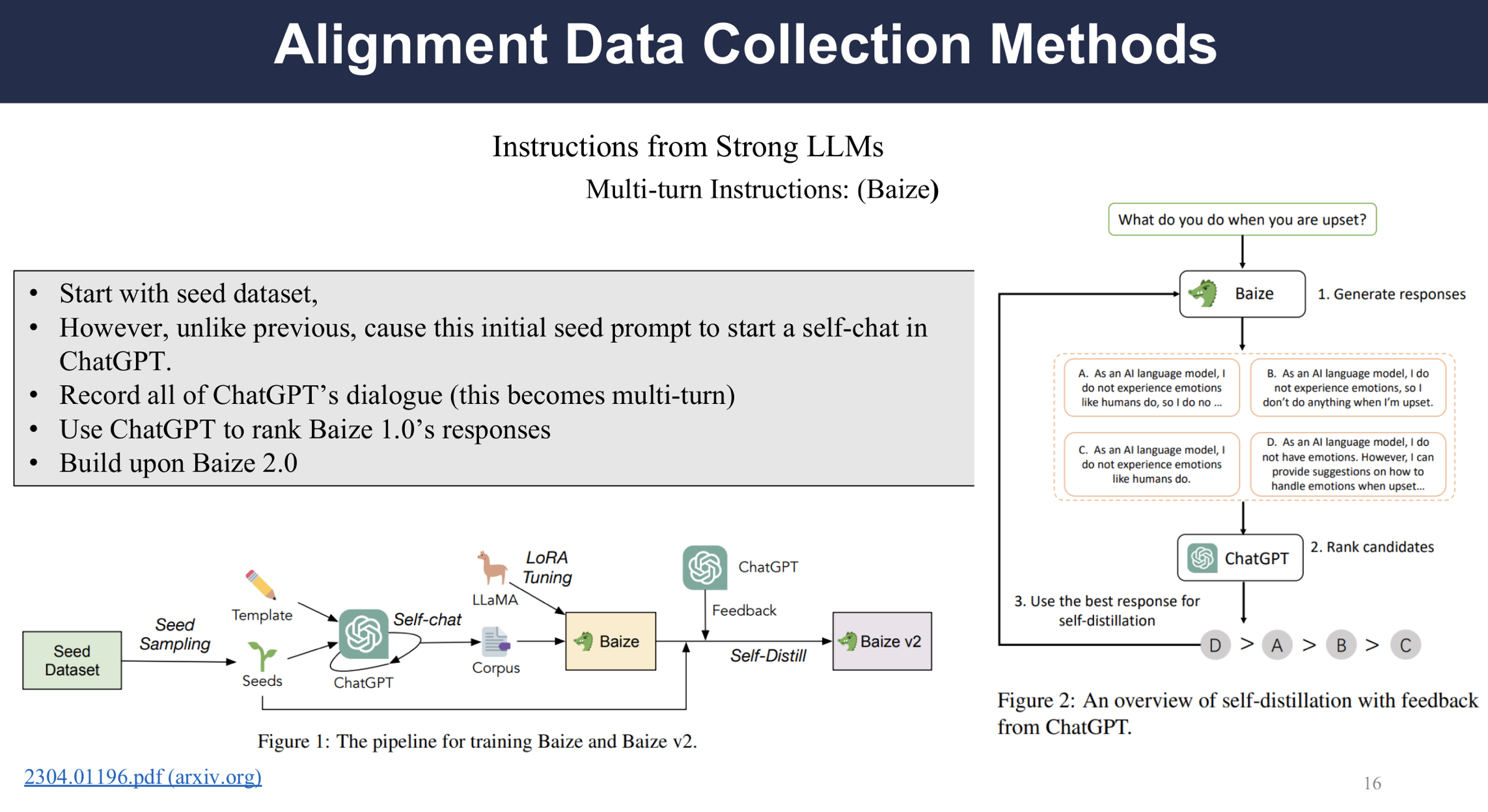
The paper Baize introduces a pipeline which uses ChatGPT to simulate user and agent conversation in the setting of multi-turn dialogues. The pipeline is shown in the bottom and the right figure shows self-distillation with feedback(SDF), a potential alternative to RLHF(Reinforcement Learning with Human Feedback).
The authors use Quora and Stack Overflow as seeds and use ChatGPT to both ask question and generate responses, thus the generated data is multi-turn dialogues.
To train Baize, the authors used SDF, whose output will also be ranked by ChatGPT and fine tuned based on the ranking. SDF is three times faster than RLHF and does not need an additional model to assign the rewards.
Multilingual Instruction Dataset
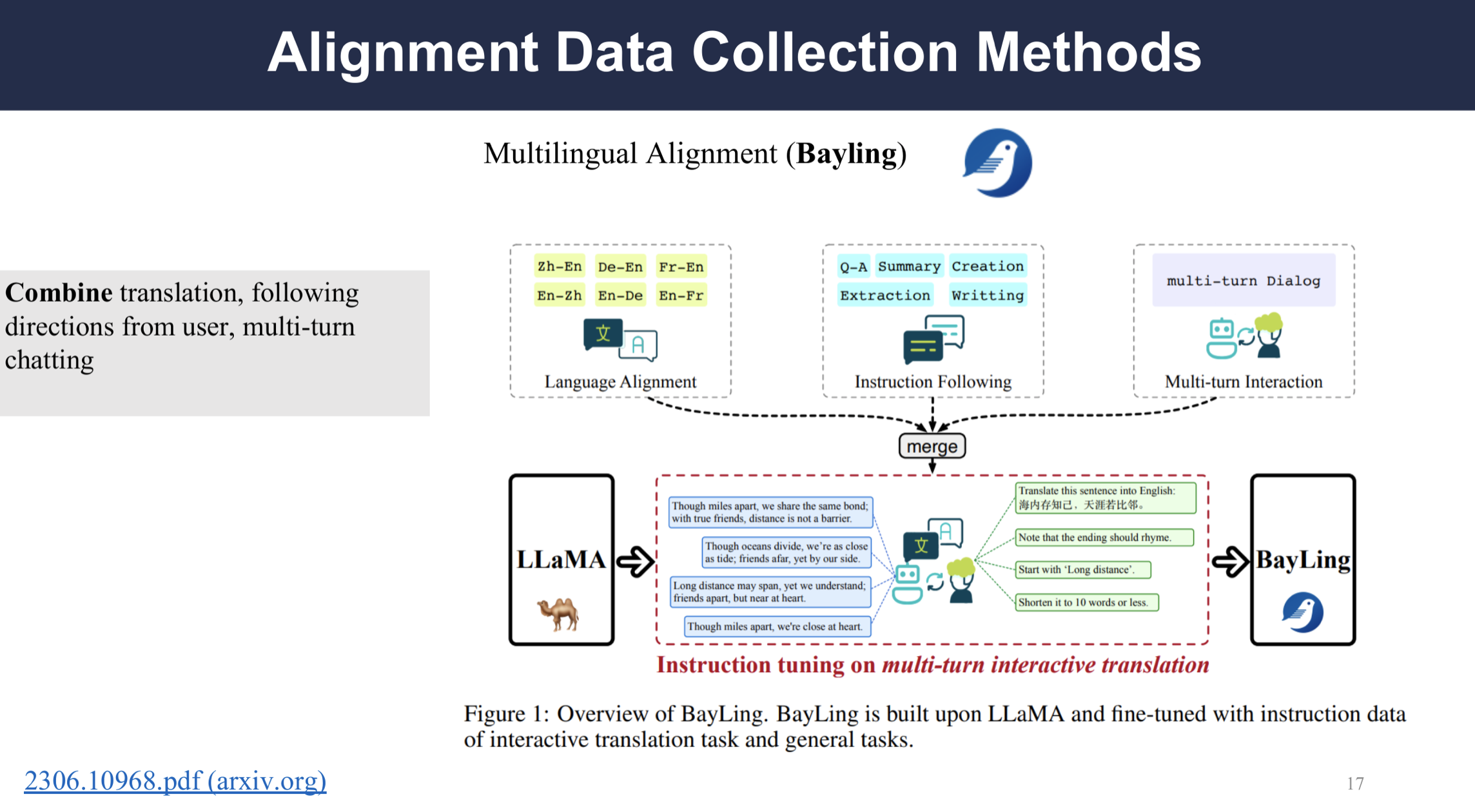
BayLing is an “instruction following LLM” built upon LLaMA and it is designed to be able to construct translation instruction paris for tuning automatically. It can achieve a 89% performance comparing to GPT-3.5-turbo with only 13 billion parameters.

This is an example of how the user can use BayLing to translate a sentence in multiple turns and mold the translation to the user’s preference.
Data Management – Post Data Collection
Now that the data is generated, the questions raise: how much data is the optimal amount? Is it feasible integrate different instructions together? How to control the quality of the data?
The dataset can be integrated
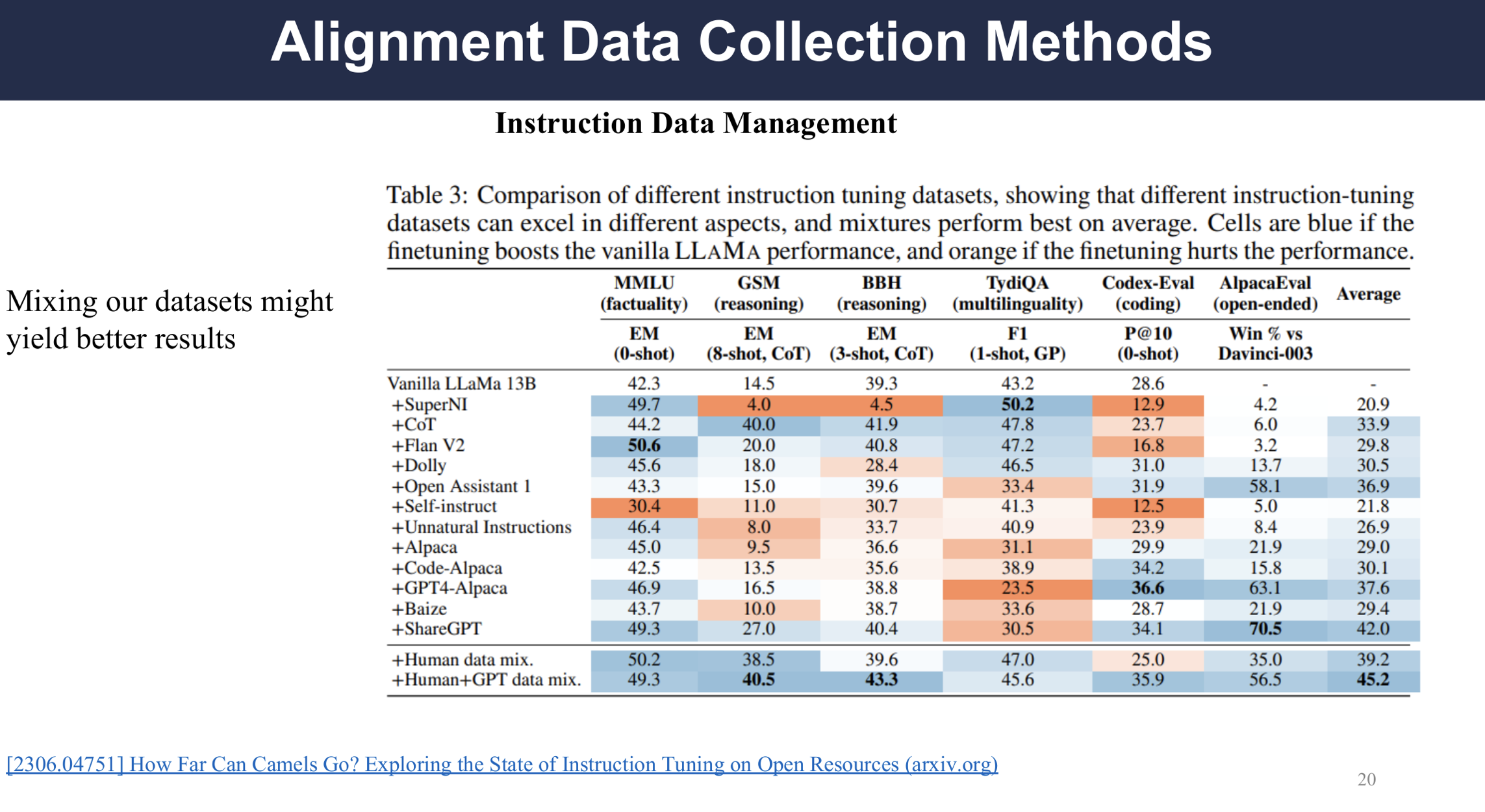
Paper “How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources” gives the answer that the dataset can be integrated, the authors evaluated LLaMa 1B on different dataset and it shows that there is not a universal dataset that is the best tuning dataset but a mixed dataset can improve the overall performance of the LM across different tasks.
The dataset quatity is more important than the quality
The paper “Alpagasus: Training a better Alpaca wit fewer data” answers the question that the dataset quantity is more important than quality and the more isn’t always the better. The authors trained the Alpagasus on 9k high quality data selected on the original 52k dataset and the performance of the model is better than the original model as evaluated by GPT-4
Alignment Training

One training method is to use supervised fine-tuning, where the loss is calculated as the cross-entropy over the ground truth.

To align the model with human, there are three methods, one is online human preference training, where the model is trained in real time continuously, the second is offline human preference training, where the model is trained in a later cycle after the feedback has been collected, and the third is parameter-effective fine-tuning, where the model is fine-tuned mainly through twerking the parameters.
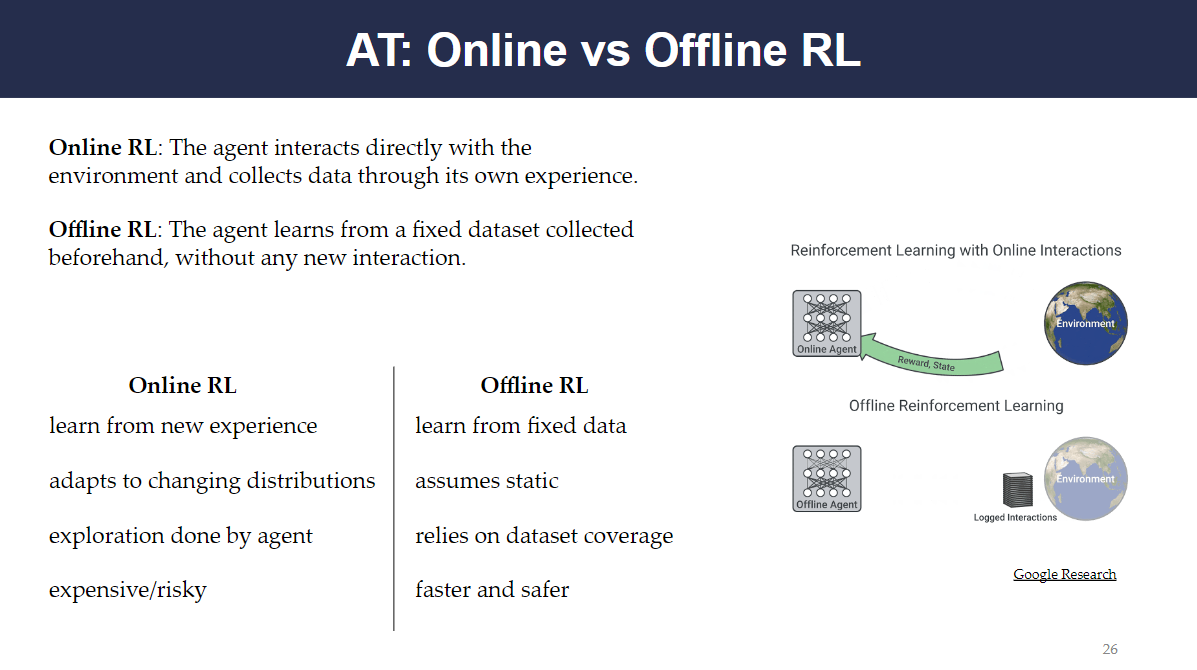 In online reinforcement learning, the agent interacts directly with the environment and collects data through its own experience. This involves exploration by the agent, deciding which actions are expensive/risky, and adapting to changing situations and distributions.
In online reinforcement learning, the agent interacts directly with the environment and collects data through its own experience. This involves exploration by the agent, deciding which actions are expensive/risky, and adapting to changing situations and distributions.
In offline reinforcement learning, the agent learns from a fixed dataset. This is a faster and safer method of training, and it relies on the coverage of the dataset.
 RLHF attempts to learn human preference signals from external reward models.
It involves three steps:
RLHF attempts to learn human preference signals from external reward models.
It involves three steps:
- Collect demonstration data and train a supervised policy
- Collect comparison data and train a reward model
- Optimize a policy against the reward model using the PPO reinforcement learning algorithm
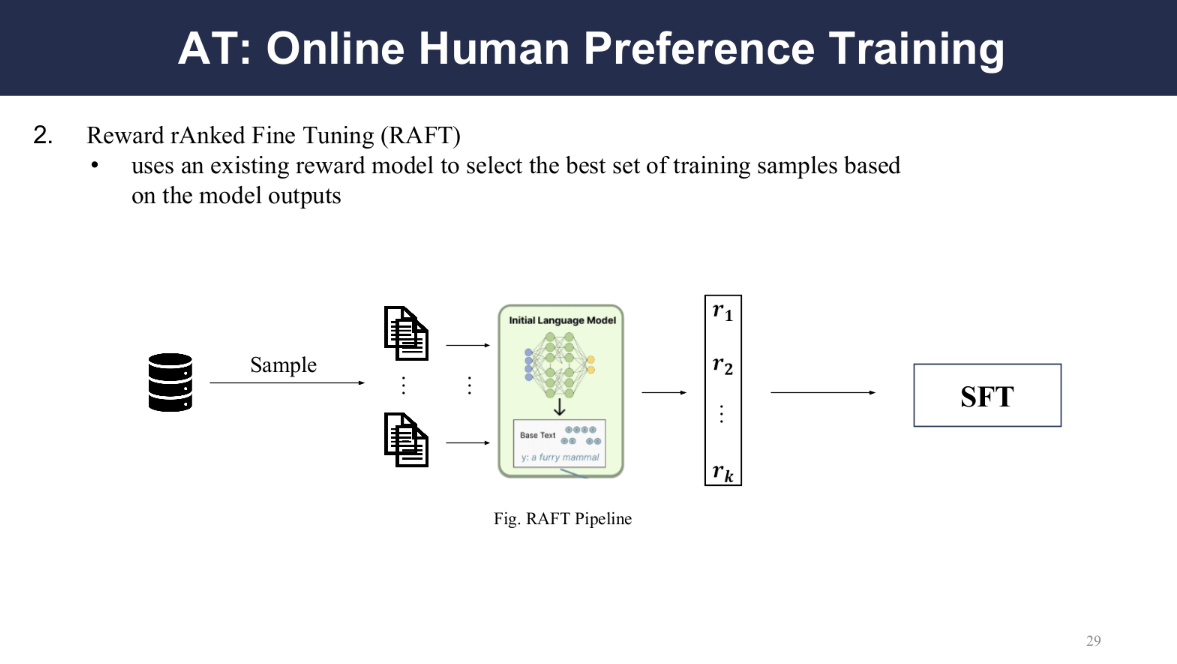 RAFT (Reward rAnked Fine Tuning) is a pipeline method that uses an existing reward model to select the best set of training samples based on the model outputs.
RAFT (Reward rAnked Fine Tuning) is a pipeline method that uses an existing reward model to select the best set of training samples based on the model outputs.
 Many hyper-parameters must be tuned to achieve better stability and performance during the training procedure.
Many hyper-parameters must be tuned to achieve better stability and performance during the training procedure.
 Direct Preference Optimization (DPO) and Preference Ranking Optimization (PRO) are two ranking-based approaches to offline human preference training.
Direct Preference Optimization (DPO) and Preference Ranking Optimization (PRO) are two ranking-based approaches to offline human preference training.
 In addition to DPO and PRO, using an SFT training objective and KL divergence as the regularization term as well as RRHF are two more examples of ranking-based approaches to learning human preferences in an offline fashion.
In addition to DPO and PRO, using an SFT training objective and KL divergence as the regularization term as well as RRHF are two more examples of ranking-based approaches to learning human preferences in an offline fashion.
 In addition to ranking-based approaches, there are also language-based approaches to learning human preferences. In concept behavior cloning, LLMS are trained on high and low quality datasets to distinguish between high and low quality instruction responses. In Chain of Hindsight, human preferences are incorporated as a pair of parallel responses discriminated as low-quality or high-quality using natural language profiles.
In addition to ranking-based approaches, there are also language-based approaches to learning human preferences. In concept behavior cloning, LLMS are trained on high and low quality datasets to distinguish between high and low quality instruction responses. In Chain of Hindsight, human preferences are incorporated as a pair of parallel responses discriminated as low-quality or high-quality using natural language profiles.
 This figure shows a visualization of the Chain of Hindsight (CoH) process. CoH training loss is only applied on model output tokens.
This figure shows a visualization of the Chain of Hindsight (CoH) process. CoH training loss is only applied on model output tokens.
 A benefit of parameter-effective training (PET) is that LLMs could enable models to adhere to provided instructions. A downside is that vast GPU and extensive datasets are required for instruction training.
A benefit of parameter-effective training (PET) is that LLMs could enable models to adhere to provided instructions. A downside is that vast GPU and extensive datasets are required for instruction training.
 For supplementary parameters in PET, trainable tokens can be prepended to each hidden layer’s input, leaving the parameters of the LLM frozen during fine-tuning.
With shadow parameters, one trains the weight representing model variance without modifying the number of total model parameters during inference.
For supplementary parameters in PET, trainable tokens can be prepended to each hidden layer’s input, leaving the parameters of the LLM frozen during fine-tuning.
With shadow parameters, one trains the weight representing model variance without modifying the number of total model parameters during inference.
 Underfitting issue: LLMs with LoRA (see previous slide) perform worse than fully fine-tuned ones, and it is preferable to use larger LLMs than larger training instruction datasets with LoRA.
Underfitting issue: LLMs with LoRA (see previous slide) perform worse than fully fine-tuned ones, and it is preferable to use larger LLMs than larger training instruction datasets with LoRA.
Alignment Evaluation
 We will consider two main components of evaluation for alignment quality: Evaluation Benchmarks (AE1) and Evaluation Paradigm (AE2)
We will consider two main components of evaluation for alignment quality: Evaluation Benchmarks (AE1) and Evaluation Paradigm (AE2)
 Closed-set benchmarks evaluate the skills and knowledge of aligned LLMs. Some general knowledge examples include MMLU and KoLA.
Closed-set benchmarks evaluate the skills and knowledge of aligned LLMs. Some general knowledge examples include MMLU and KoLA.
 For reasoning benchmarks, various benchmarks exist for different categories, including Arithmetic, Common Sense, and Big Bench, which tests for data understanding, word sorting, and causal judgement. Benchmarks also exist for codign abilities of LLMs
For reasoning benchmarks, various benchmarks exist for different categories, including Arithmetic, Common Sense, and Big Bench, which tests for data understanding, word sorting, and causal judgement. Benchmarks also exist for codign abilities of LLMs
 In addition to closed-set benchmarks, open-set benchmarks also exist, which can have more flexible and diverse responses.
In addition to closed-set benchmarks, open-set benchmarks also exist, which can have more flexible and diverse responses.
 Human-based evaluation is an important alignment evaluation paradigm. In this paradigm, human annotators categorize each response into one of four levels. This depends highly on the subjectivity of the annotators, however.
Human-based evaluation is an important alignment evaluation paradigm. In this paradigm, human annotators categorize each response into one of four levels. This depends highly on the subjectivity of the annotators, however.
 Using human-based evaluations can be inefficient and expensive. Some recent studies are trying to incorporate LLMs into output text classification for various NLP tasks.
LLMs can also have evaluation bias, favoring their own responses or candidates that appear earlier.
Using human-based evaluations can be inefficient and expensive. Some recent studies are trying to incorporate LLMs into output text classification for various NLP tasks.
LLMs can also have evaluation bias, favoring their own responses or candidates that appear earlier.
Challenges and Future Directions
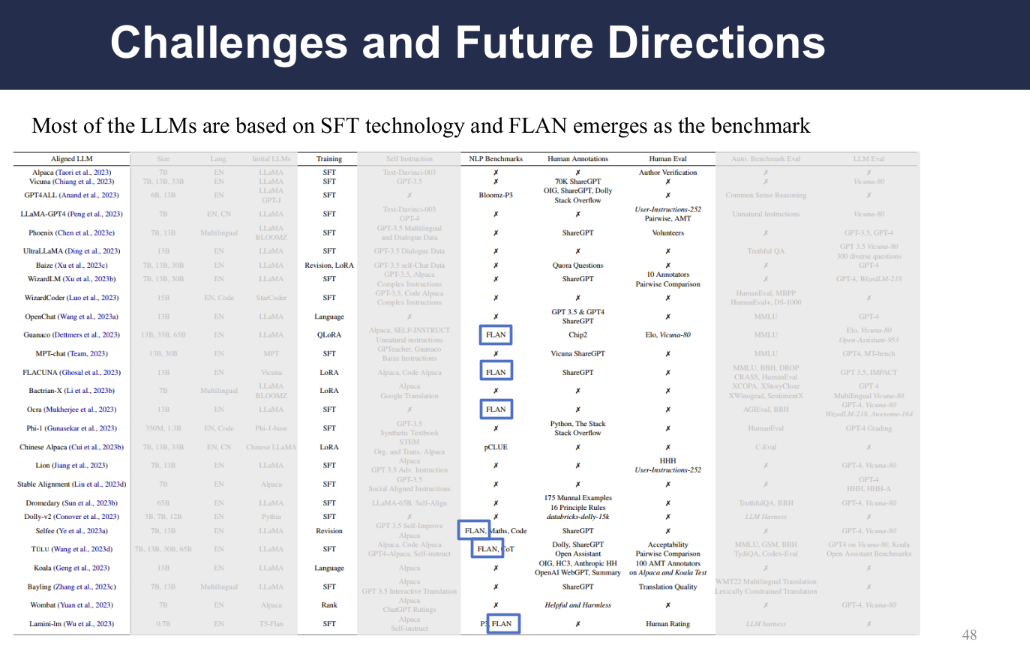 This chart shows that most of the LLMs reviewed are based on LLM technology, with FLAN arising as a common benchmark.
This chart shows that most of the LLMs reviewed are based on LLM technology, with FLAN arising as a common benchmark.
 FLAN is short for Fine-tuned LAnguage Net. It is an instruction tuning approach to fine-tune language models on a collection of datasets described via instructions.
FLAN is short for Fine-tuned LAnguage Net. It is an instruction tuning approach to fine-tune language models on a collection of datasets described via instructions.
 This slide shows various comparisons and attributes of FLAN. Notably, instruction tuning with FLAN is only beneficial for models of a certain size, as seen on the bottom right graph.
This slide shows various comparisons and attributes of FLAN. Notably, instruction tuning with FLAN is only beneficial for models of a certain size, as seen on the bottom right graph.
Fine-Grained Instruction Data Management for LLMs
Proper data management can significantly enhance the reasoning capabilities of language models aligned with human values. The evaluation of models such as FLAN and programming instructions has shown varying results in problem-solving and alignment to human values, with some models demonstrating noticeable improvements and others exhibiting a need for further alignment.
Evaluation tables indicate that LLMs like FLAN and ShareGPT show promising performance across various benchmarks, including MMLU and CRASS for FLAN and a wide range of tasks for ShareGPT, which is evidenced by its high win rates across datasets of different sizes. These benchmarks are crucial as they offer insight into the LLMs’ alignment with human values, such as harmlessness, helpfulness, and honesty.
LLM Alignment Across Languages & The Role of SFT
A significant challenge in LLM alignment arises where the focus has been predominantly on English-based prompts. This raises pertinent questions about the performance of these technologies across different languages, especially those that are resource-poor. Effective strategies for transferring the benefits of LLM alignment across linguistic barriers are yet to be established.
Furthermore, the current landscape of aligned LLMs relies heavily on SFT technologies. However, SFT does not inherently incorporate human preferences into the models, which requires an extensive amount of instructional data and substantial training resources to achieve the desired level of alignment.
Human-in-the-loop LLMs Alignment Data Generation
Human intervention remains crucial in the generation of alignment data for LLMs. Human-in-the-loop methodologies, such as those employed by ShareGPT, have shown to be effective across a spectrum of NLP tasks. This proves that humans still play a pivotal role in ensuring the quality of LLM alignment, particularly through tasks like data annotation, bias detection, and ethical oversight.
Implications of LLMs on Customer Service
The deployment of LLMs in customer service represented through chatbots, has led to tangible improvements, such as a 14% increase in issue resolution per hour and a 9% reduction in handling time, illustrating the practical benefits of LLMs when effectively aligned and implemented.
Objectives of InstructGPT
The InstructGPT model stands out with its aim to follow a wide array of written instructions while avoiding untruthful or harmful outputs. By utilizing human feedback, InstructGPT seeks to fine-tune language models to closely align with human intentions. The model is demonstrated to generate reliable outputs, minimizing toxicity and bias, and shows an impressive ability to generalize beyond the specifics of fine-tuning datasets.
Human Evaluations and Main Findings
Human evaluations reveal that InstructGPT, even with fewer parameters, can outperform larger models like GPT-3 in generating accurate and truthful outputs. The main findings highlight InstructGPT’s superior performance in producing contextually appropriate and informative content, showcasing its potential in achieving high-quality LLM alignment.
InstructGPT Architecture and Training
Training InstructGPT
The InstructGPT architecture builds upon the GPT-3 model, incorporating a three-step training process to ensure outputs align closely with human intentions:
Supervised Fine Tuning (SFT): Labelers create demonstration data to train a supervised policy, fine-tuning GPT-3 to replicate these desired responses to prompts.
Reward Modeling (RM): Comparison data is collected, with labelers ranking multiple model outputs from best to worst. This ranking trains a reward model.
Reinforcement Learning (RL): An optimized policy is developed against the reward model using reinforcement learning techniques, specifically Proximal Policy Optimization (PPO), to refine the final output of the InstructGPT.
Methodology and Dataset
To start the training, labelers wrote initial prompts because regular GPT-3 models lacked a base of instruction-like prompts. Prompts were classified into three categories: plain (arbitrary tasks), few-shot (multiple query/response pairs per instruction), and user-based (waitlist use cases for the OpenAI API).
Datasets and Use-Cases
Three datasets were produced for the fine-tuning process:
SFT Data: 13k prompts
RM Data: 33k prompts
PPO Data: 31k prompts
The three datasets generated from these prompts reflects the diversity of use-cases such as generation, open question answering, brainstorming, chat, rewriting, summarization, and classification. This variety ensures that InstructGPT can handle a broad range of tasks effectively.
Fine-tuning and Optimization
SFT is done on labeler demonstrations over multiple epochs, but it tends to overfit after just one epoch.
RM Optimization: The loss function is defined by cross-entropy loss, where the reward difference is mapped to a value between 0 and 1 using a sigmoid function.
RM output delivers a scalar reward, optimizing the computational efficiency and reducing overfitting.
RL Training: The objective function considers the rewards from the RM model output and includes a KL penalty to prevent substantial deviations from the pre-trained model.
The reward from RM, coupled with Proximal Policy Optimization (PPO) in the RL phase, ensures the model is fine-tuned to customer prompts effectively. KL-penalty in the RL training phase prevents the model’s policy from diverging too far from the original pre-trained model, thus maintaining performance consistency.
Preference Model
GPT-3 when it is provided a few-shot prefix to ‘prompt’ it into an instruction-following mode (GPT-3-prompted)
- PPO always above 0.5
- 1.3B PPO is better than 175B SFT
Meta-result for API distribution
Likert Comparison between FLAN and T0
Results on TruthfulQA dataset
Reliable Answering
Simple Mistakes
Summary & Discussions
- Demonstrate that this alignment technique can align to a specific human reference group for a specific application
- Implication
- Cost effective than training larger model
- More research is needed for generalization
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
RLFH Recap
RLHF typically begins by fine-tuning a pre-trained LM with supervised learning on high-quality data for the downstream task(s) of interest (dialogue, summarization, etc.), to obtain a model πSFT.
Reward Modelling Phase: In the second phase the SFT model is prompted with prompts x to produce pairs of answers (y1, y2) ∼ πSFT (y|x). These are then presented to human labelers who express preferences for one answer, denoted as yw ≻ yl | x where yw and yl denotes the preferred and dispreferred completion amongst (y1, y2) respectively.
we can parametrize a reward model rϕ(x, y) and estimate the parameters via maximum likelihood. Framing the problem as a binary classification we have the negative log-likelihood loss.
During the RL phase, we use the learned reward function to provide feedback to the language model.. The added constraint is important, as it prevents the model from deviating too far from the distribution on which the reward model is accurate, as well as maintaining the generation diversity and preventing mode-collapse to single high-reward answers.
Limitations of RLHF
-
Complex training procedure
-
Computationally expensive
-
Instability of Actor-Critic Algorithms used in RLHF (e.g. PPO)
RLHF vs DPO
-
Leverage an analytical mapping from reward functions to optimal policy.
-
Directly optimize a LLM to adhere to human preferences, without explicit reward modeling or RL.
-
Implicitly optimizes the same objective as existing RLHF algorithms (reward maximization with a KL-divergence constraint) but is simple to implement and straightforward to train.
Implicitly optimizes the same objective as existing RLHF algorithms (reward maximization with a KL-divergence constraint) but is simple to implement and straightforward to train.
How DPO Works?
- Step 1: Data Collection
- For each prompt x, sample y1 and y2 from the reference policy πref(.|x), and label them with human preferences to construct the offline data set of preferences D = {x(i), yw(i), yl}Ni=1
- Step 2: Loss Optimization
- Optimize the langage model πθ to minimize the DPO loss LDPO with respect to the given reference policy πref, dataset D, and the desired β
DPO Loss Function
LDPO(πθ; πref) = −E(x,yw,yl)∼D [log σ(β log * πθ(yw | x)/πref(yw | x) - β log * πθ(yl | x)/πref(yl | x))]
- πθ represents the policy (language model) being trained.
- πref is the reference policy, typically the initial pre-trained model.
- yw and yl are the preferred and less-preferred responses, respectively.
- σ denotes the sigmoid function.
- D represents the dataset of human preferences.
-
This loss function calculates the probability that the model’s preferred response (as per the human preference data) is more likely than the less-preferred response, given the context x.
-
The model is trained to minimize this loss, thereby increasing its ability to generate responses that align with human preferences.
DPO Evaluations
- DPO provides the highest expected reward for all KL values, demonstrating the quality of the optimization.
- Summarization win rates vs. human-written summaries, using GPT-4 as evaluator. DPO exceeds PPO’s best-case performance on summarization, while being more robust to changes in the sampling temperature.
What DPO Offers?
-
Simplicity and Stability
- More straightforward and stable approach by eliminating the need for a separate reward model.
-
Computational Efficiency
- By condensing the training into a single stage, DPO reduces computational demands
-
Enhanced Performance
- Initial experiments demonstrate DPO’s capability to fine-tune language models effectively, often outperforming traditional RLHF methods.
-
Ethical Alignment
- Integrating human preferences, DPO positions itself as a tool for developing AI systems that resonate more with human values and ethics.
Why DPO Loss Function Works?
Bradley-Terry Model
-
A statistical model used to analyze paired comparison data, where the goal is to model the preferences or relative strengths of different items.
-
It predicts the probability that item/individual, i will be preferred over item/individual, j using the formula:
- P (i > j) = Pi / (Pi + Pj)
-
Here, Pi and Pj represent the intrinsic “strengths” or “worth” of items i and j, where higher values of, P indicate a greater likelihood of preference.