Open Source LLM - Mistral Data preparation
- SlideDeck: W4-OpenSourceLLM
- Version: current
- Lead team: team-6
- Blog team: team-6
In this session, our readings cover:
Required Readings:
Mistral 7B
- https://mistral.ai/news/announcing-mistral-7b/
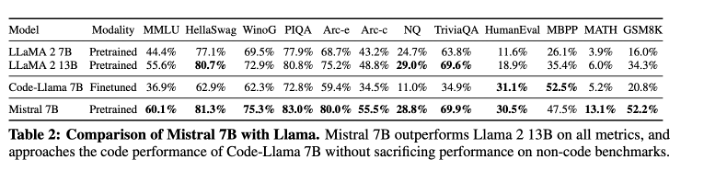
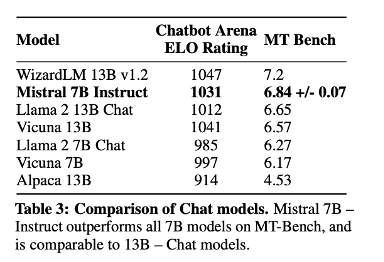
- We introduce Mistral 7B v0.1, a 7-billion-parameter language model engineered for superior performance and efficiency. Mistral 7B outperforms Llama 2 13B across all evaluated benchmarks, and Llama 1 34B in reasoning, mathematics, and code generation. Our model leverages grouped-query attention (GQA) for faster inference, coupled with sliding window attention (SWA) to effectively handle sequences of arbitrary length with a reduced inference cost. We also provide a model fine-tuned to follow instructions, Mistral 7B – Instruct, that surpasses the Llama 2 13B – Chat model both on human and automated benchmarks. Our models are released under the Apache 2.0 license.
More Readings:
OLMo: Accelerating the Science of Language Models
- https://arxiv.org/abs/2402.00838
Language models (LMs) have become ubiquitous in both NLP research and in commercial product offerings. As their commercial importance has surged, the most powerful models have become closed off, gated behind proprietary interfaces, with important details of their training data, architectures, and development undisclosed. Given the importance of these details in scientifically studying these models, including their biases and potential risks, we believe it is essential for the research community to have access to powerful, truly open LMs. To this end, this technical report details the first release of OLMo, a state-of-the-art, truly Open Language Model and its framework to build and study the science of language modeling. Unlike most prior efforts that have only released model weights and inference code, we release OLMo and the whole framework, including training data and training and evaluation code. We hope this release will empower and strengthen the open research community and inspire a new wave of innovation.
Mixtral of Experts
- https://arxiv.org/abs/2401.04088
- We introduce Mixtral 8x7B, a Sparse Mixture of Experts (SMoE) language model. Mixtral has the same architecture as Mistral 7B, with the difference that each layer is composed of 8 feedforward blocks (i.e. experts). For every token, at each layer, a router network selects two experts to process the current state and combine their outputs. Even though each token only sees two experts, the selected experts can be different at each timestep. As a result, each token has access to 47B parameters, but only uses 13B active parameters during inference. Mixtral was trained with a context size of 32k tokens and it outperforms or matches Llama 2 70B and GPT-3.5 across all evaluated benchmarks. In particular, Mixtral vastly outperforms Llama 2 70B on mathematics, code generation, and multilingual benchmarks. We also provide a model fine-tuned to follow instructions, Mixtral 8x7B - Instruct, that surpasses GPT-3.5 Turbo, Claude-2.1, Gemini Pro, and Llama 2 70B - chat model on human benchmarks. Both the base and instruct models are released under the Apache 2.0 license.
- Llama 2: Open Foundation and Fine-Tuned Chat Models
- In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed-source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
- https://arxiv.org/abs/2101.00027
- Recent work has demonstrated that increased training dataset diversity improves general cross-domain knowledge and downstream generalization capability for large-scale language models. With this in mind, we present \textit{the Pile}: an 825 GiB English text corpus targeted at training large-scale language models. The Pile is constructed from 22 diverse high-quality subsets – both existing and newly constructed – many of which derive from academic or professional sources. Our evaluation of the untuned performance of GPT-2 and GPT-3 on the Pile shows that these models struggle on many of its components, such as academic writing. Conversely, models trained on the Pile improve significantly over both Raw CC and CC-100 on all components of the Pile, while improving performance on downstream evaluations. Through an in-depth exploratory analysis, we document potentially concerning aspects of the data for prospective users. We make publicly available the code used in its construction.
Blog: Section 1: The Pile
In this section, we are going to introduce a paper: The pile, an open source dataset for diverse text for language modeling.
Motivation
Their work is driven by several key considerations. As the size of Large Language Models (LLMs) continues to expand rapidly, so does the need for vast amounts of data to effectively train these models. However, major players in the tech industry, such as Google and OpenAI, tend to keep their models and data closely guarded due to their commercial interests. Inspired by the principles of open-source software, they advocate for a similar ethos in the realm of LLMs. Open-sourcing data offers numerous advantages, including enhanced accessibility, opportunities for community collaboration, and the establishment of robust benchmarking and evaluation standards.

In line with this philosophy, various open-source datasets already exist on the internet, including The Common Crawl, RefinedWeb, Starcoder Data, and C4. However, in this section, they introduce a new and unique addition: The Pile. Their primary objective with The Pile is to enhance data diversity, thereby enriching the dataset’s capabilities for modeling and training.
The Pile Components
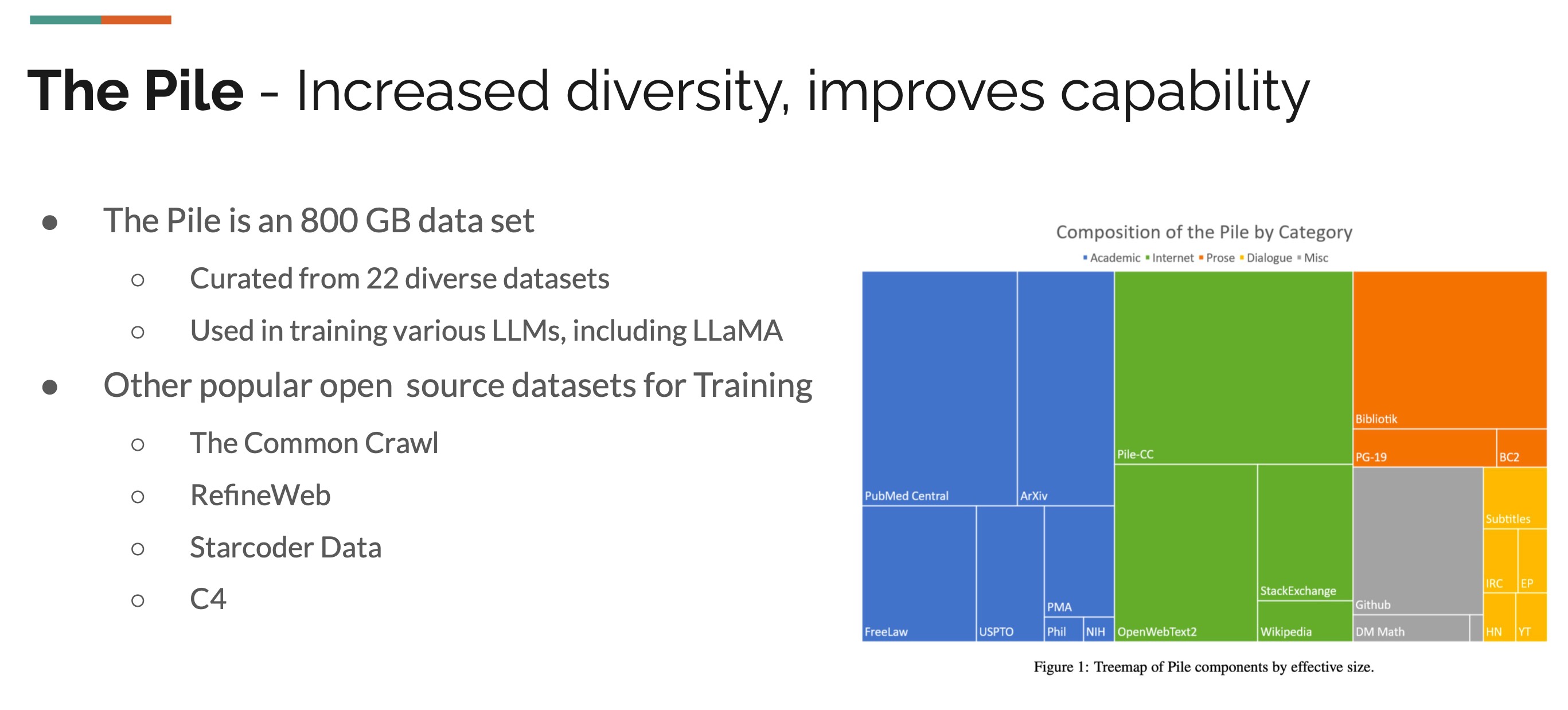
The Pile comprises an 800GB dataset curated from 22 diverse datasets, covering a wide range of domains such as Academic, Internet, Prose, Dialogue, and Miscellaneous. The composition of The Pile by category is illustrated in Figure 1, with a more detailed breakdown provided in Figure 2. This comprehensive coverage ensures that The Pile encompasses a broad spectrum of datasets.
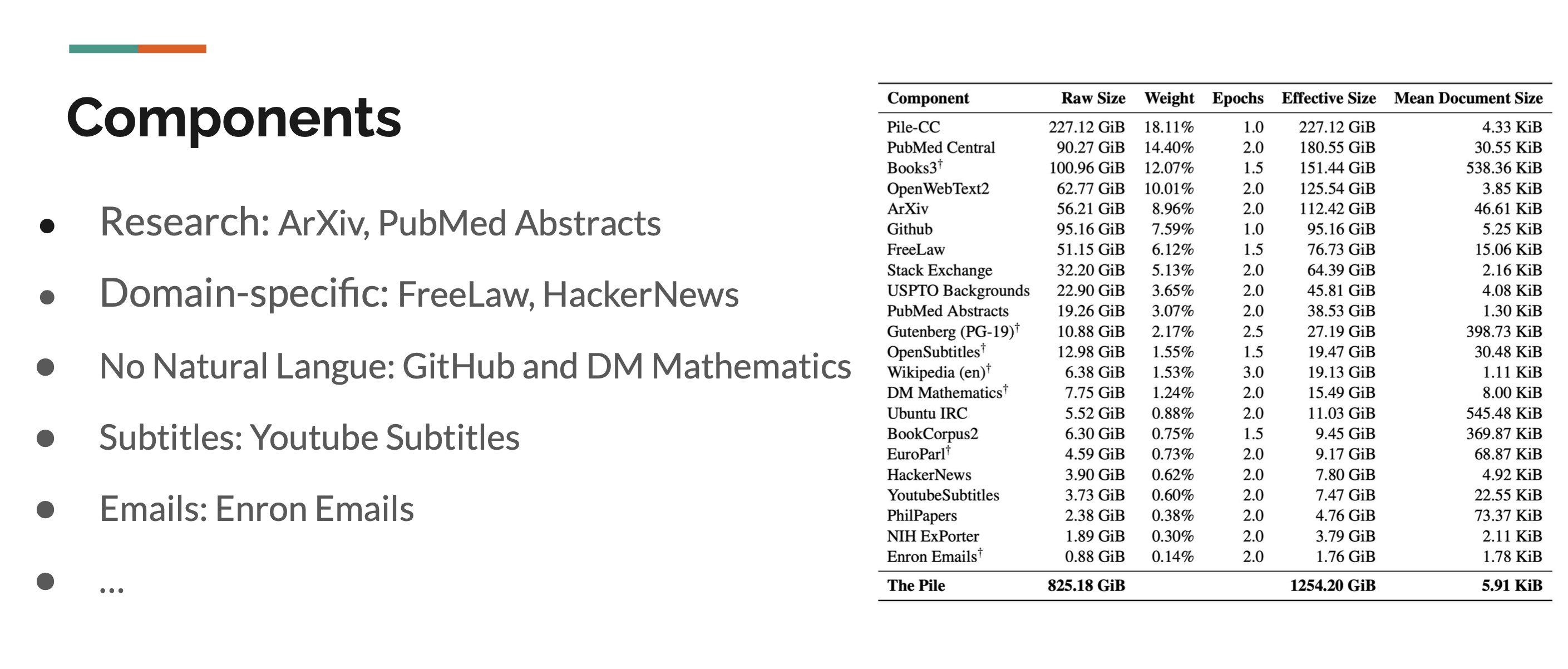

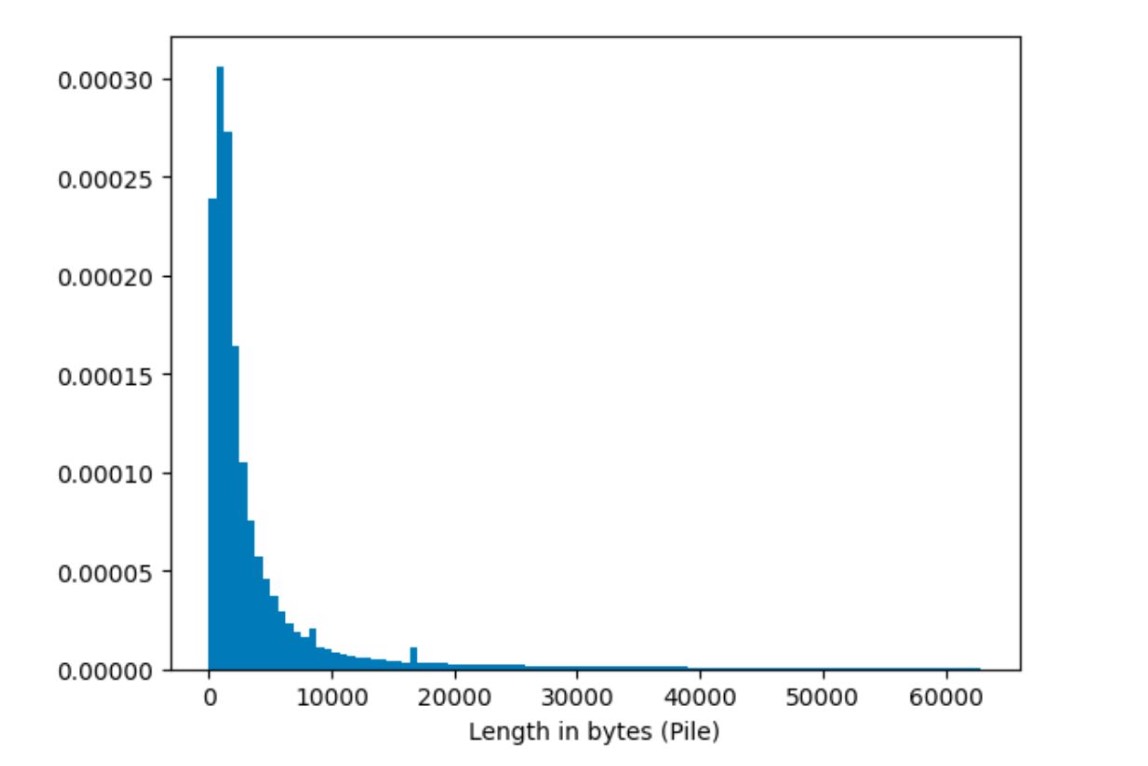
Furthermore, let’s examine the structural statistics of the data. Firstly, the majority of documents in The Pile remain short, typically less than 10k bytes. However, there is also a long tail, indicating a small number of documents with lengths extending up to 60k bytes. Secondly, from a linguistic perspective, 97.4% of The Pile’s dataset is in English. While The Pile aims to be multilingual-friendly, future expansion efforts will be necessary to achieve this goal.
Benchmark Models with The Pile
In this study, Bits per UTF-8 encoded byte (BPB) is utilized to evaluate perplexity, which measures the efficacy of AI in predicting the subsequent word. GPT2/3 models are employed to assess The Pile. Remarkably, as illustrated in the Figure, performance improves progressively with the expansion of model parameters, even when GPT2/3 models are not trained on The Pile. This finding, observed as early as 2020, underscores the significance of the study’s results at the time of its publication.

Benchmark on different Componet
To further confirm how diversity improves the dataset’s capability, we need to evaluate how the diverse dataset enhances performance on individual components. Unfortunately, due to resource limitations, the authors could not train GPT-3 from scratch on The Pile dataset. Instead, they opted for a proxy approach using the formula below:
The parameter ∆set represents the difference in performance of the GPT-3 model when evaluated on The Pile dataset (Lset) and its performance when evaluated on the OWT2 dataset (Lowt2).
- Where:
- LGPT3 is the performance metric of the GPT-3 model on The Pile dataset.
- LGPT3_set is the performance metric of the GPT-3 model on the OWT2 dataset.
- GPT2Pile_owt2 represents the performance difference between the GPT-2 model trained on The Pile dataset and the GPT-2 model trained on the OWT2 dataset.
- GPT2Pile represents the performance of the GPT-2 model trained on The Pile dataset.
- Lset is the intrinsic difficulty of understanding and generating text within The Pile dataset.
- Lowt2 is the intrinsic difficulty of understanding and generating text within the OWT2 dataset
The term ∆set allows researchers to assess how much harder The Pile dataset is for GPT-3 compared to OWT2, while also considering the relative difficulty of tasks and the potential performance improvement achievable by training models specifically on The Pile dataset.
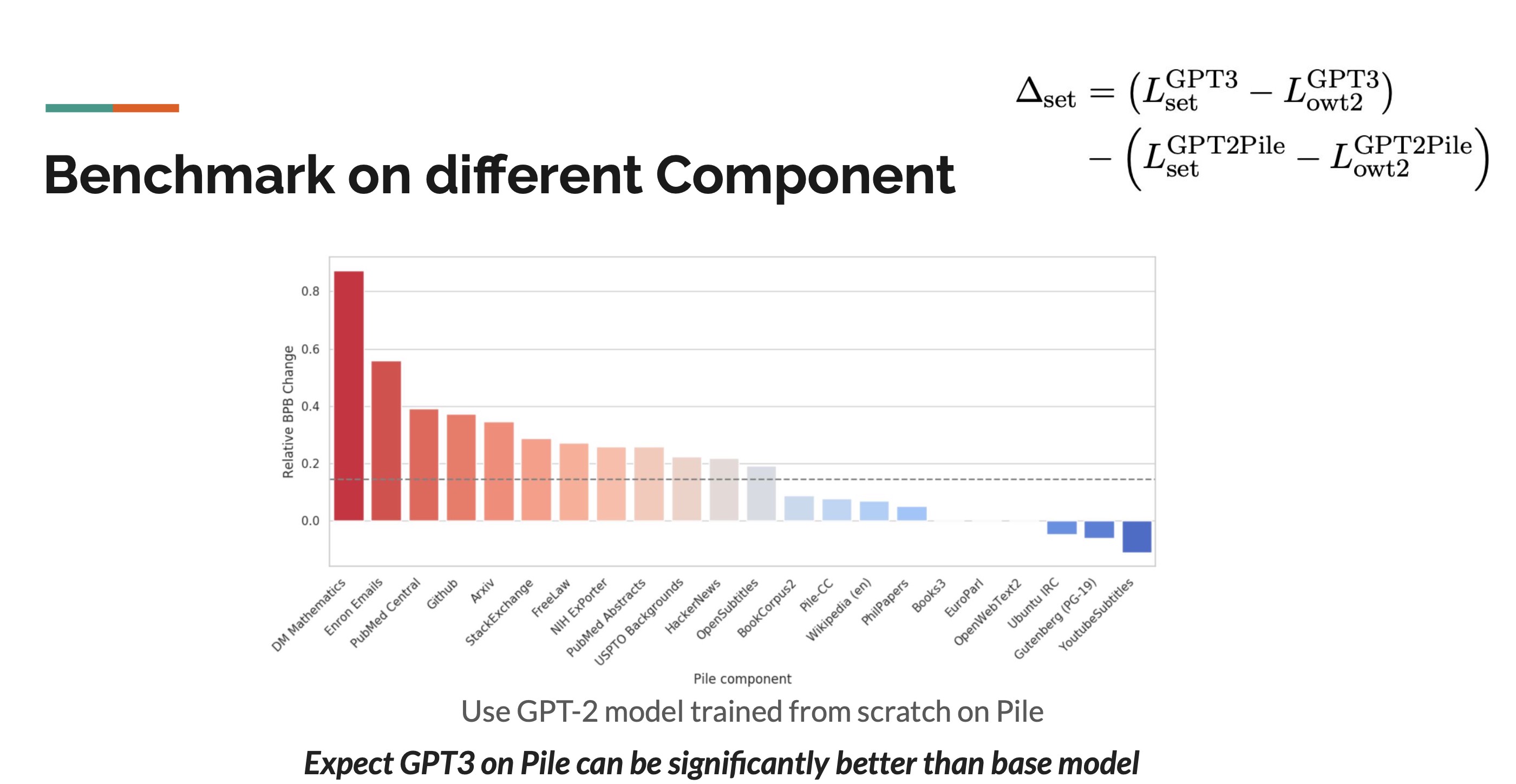
Observing the dotted line in the figure, which represents the average performance improvement, we notice significant enhancements in certain fields, such as DM Mathematics, Enron Emails, and others. This suggests that if GPT-3 were trained from scratch on The Pile dataset, its performance could potentially surpass the baseline model. Through these insights, we gain valuable understanding of the potential benefits of training language models on diverse datasets like The Pile.
Evaluation
To evaluate how the diversity from The Pile improves model training effectiveness, GPT-2 was trained on three different datasets, and the Bits per UTF-8 encoded byte (BPB) metric was employed for evaluation across the datasets. Refer to the table below for details.
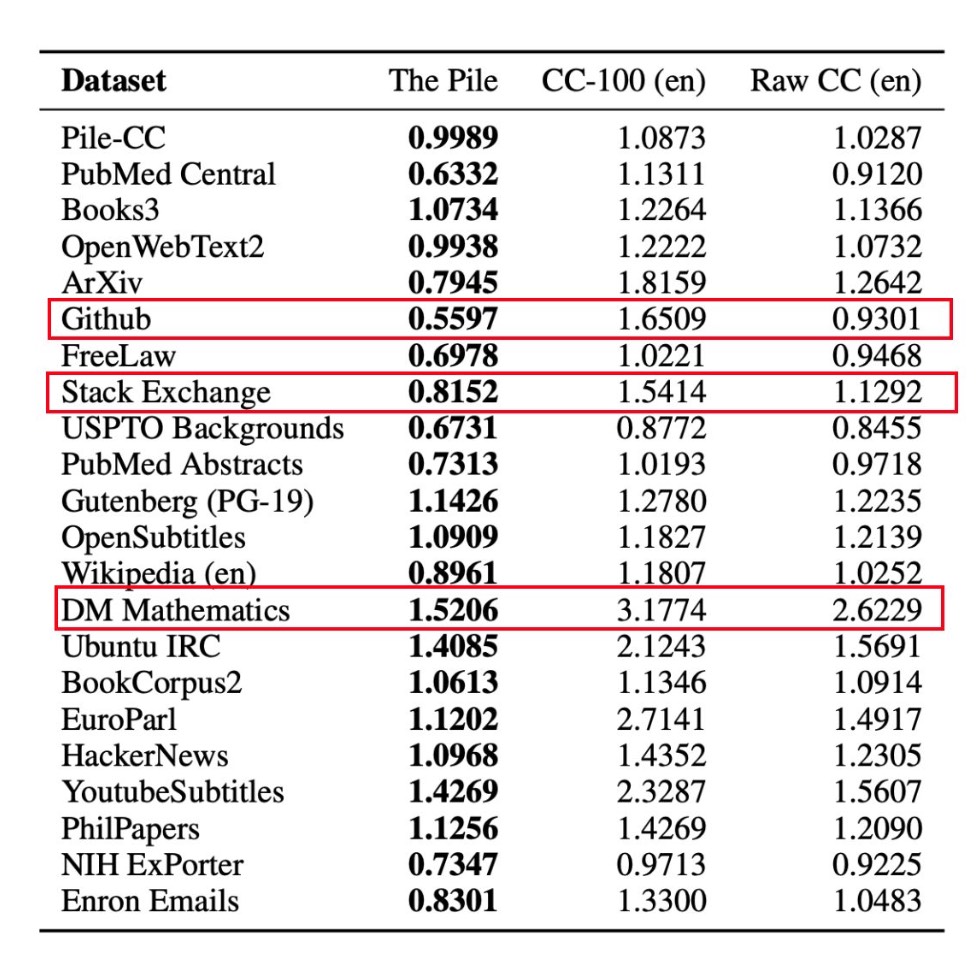
From our observations, The Pile outperforms every dataset, with CC-100 showing minimal improvements compared to our baseline dataset, Raw CC. Notably, certain fields, such as Github, Stack Exchange, and DM Mathematics, exhibit significant improvements. This underscores the effectiveness of training datasets with diverse content in enhancing model training quality.
More about the Pile
Another goal of this work is to address ethical and bias concerns in AI research, while also promoting and standardizing the practice of engaging with AI ethics. The paper’s analysis delves into various perspectives, including topic distribution, inappropriate content, sensitive content (gender, religion, race), and data authority. Readers interested in these aspects can explore the paper to find topics of interest.
Conclusion
In conclusion, this work introduces a new open-source dataset that has been widely adopted in the research community since its release. The study demonstrates the dataset’s capability enhancement by incorporating diverse categories of data through the evaluation process. Moreover, the work endeavors to address ethical and bias concerns in AI research, reflecting a commitment to responsible AI development.
Section 2 Mistral 7B
Why Mistral 7B
- Outperforms Llama 2 13B on all benchmarks
- Outperforms Llama 1 34B on many benchmarks
- Approaches CodeLlama 7B performance on code, while remaining good at English tasks
Here are essential components in Mistral 7B ( Mistral / Mixtral Explained: Sliding Window Attention, Sparse Mixture of Experts, Rolling Buffer)
Group-query attention**
Advantage:Accelerates the inference speed.Reduces the memory requirement during decoding, allowing for higher batch sizes hence higher throughput
Sliding Window Attention
Using Stacked layers to attend information beyond the window size, where one hidden state can access up to h times k tokens.
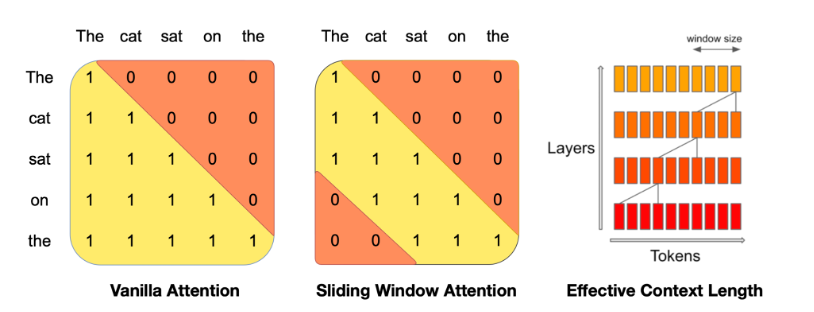
Rolling Buffer Cache

- Rolling Buffer Cache: A mechanism to limit the memory usage of the attention mechanism by using a cache with a fixed size.
- Fixed Cache Size: The cache is set to a fixed size of W, storing only the most recent W key-value pairs.
- Overwriting Mechanism: When the timestep i exceeds W, older values are overwritten using the mod operation
Pre-fill and chunking
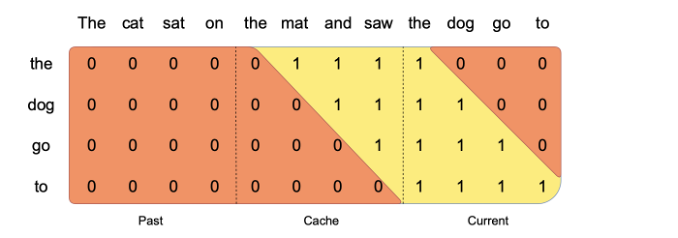
- Prompt Pre-filling: The known parts of a prompt can be pre-processed to fill the (key, value) cache, which helps in quicker generation of subsequent tokens.
- Large Prompt Handling: For prompts too large to process at once, they can be divided into smaller segments, or “chunks”.
- Chunking Strategy: The size of these chunks can be determined by a selected window size, which is optimal for the model’s processing capabilities.
Result:
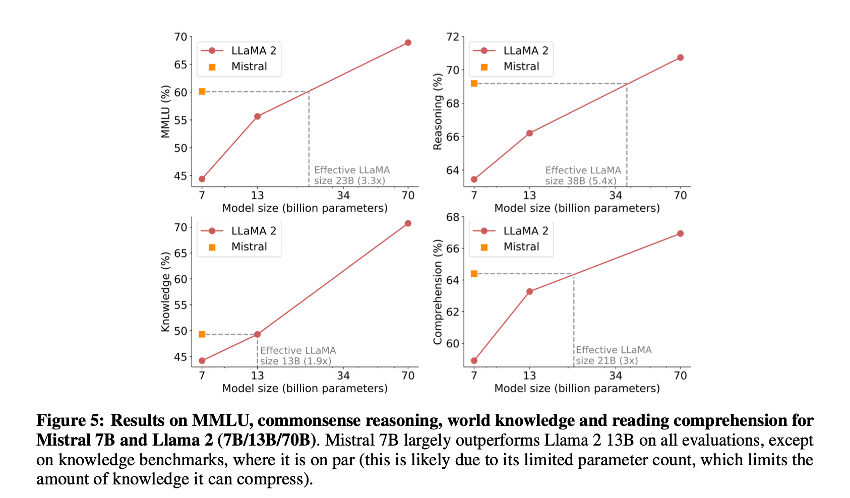
Here is Mistral 7B performance on different tasks (comparing to other open source LLM)
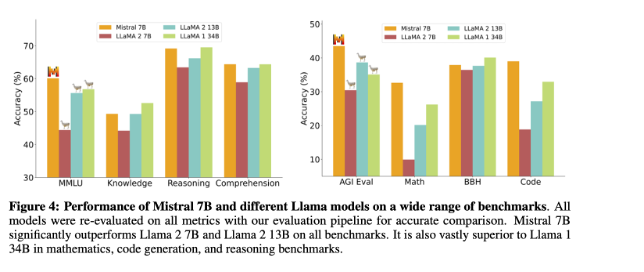
Mistral 7B performs equivalently to Llama2 that would be more than 3x its size. This is as much saved in memory and gained in throughput.
Finetuning Mistral 7B for Chat- Mistral 7B- Instruct
Guardrials

Section 3: Mixtral of Experts
1. Motivation
- The scale of a model is one of the most important metric for better model quality.
- How to scale up the model size under limited compute budget?
2. Contribution
The main contribution of this paper is:
- They proposed Mixtral 8x7B which have competitive performance with respect to accuracy and size and efficiency.
- They fine-tuned Mixtral 8x7B - Instruct and released it under Apache 2.0 licence which means their open-sourced model can be used for academic and commercial usage.
2.1 Mixtral 8x7B
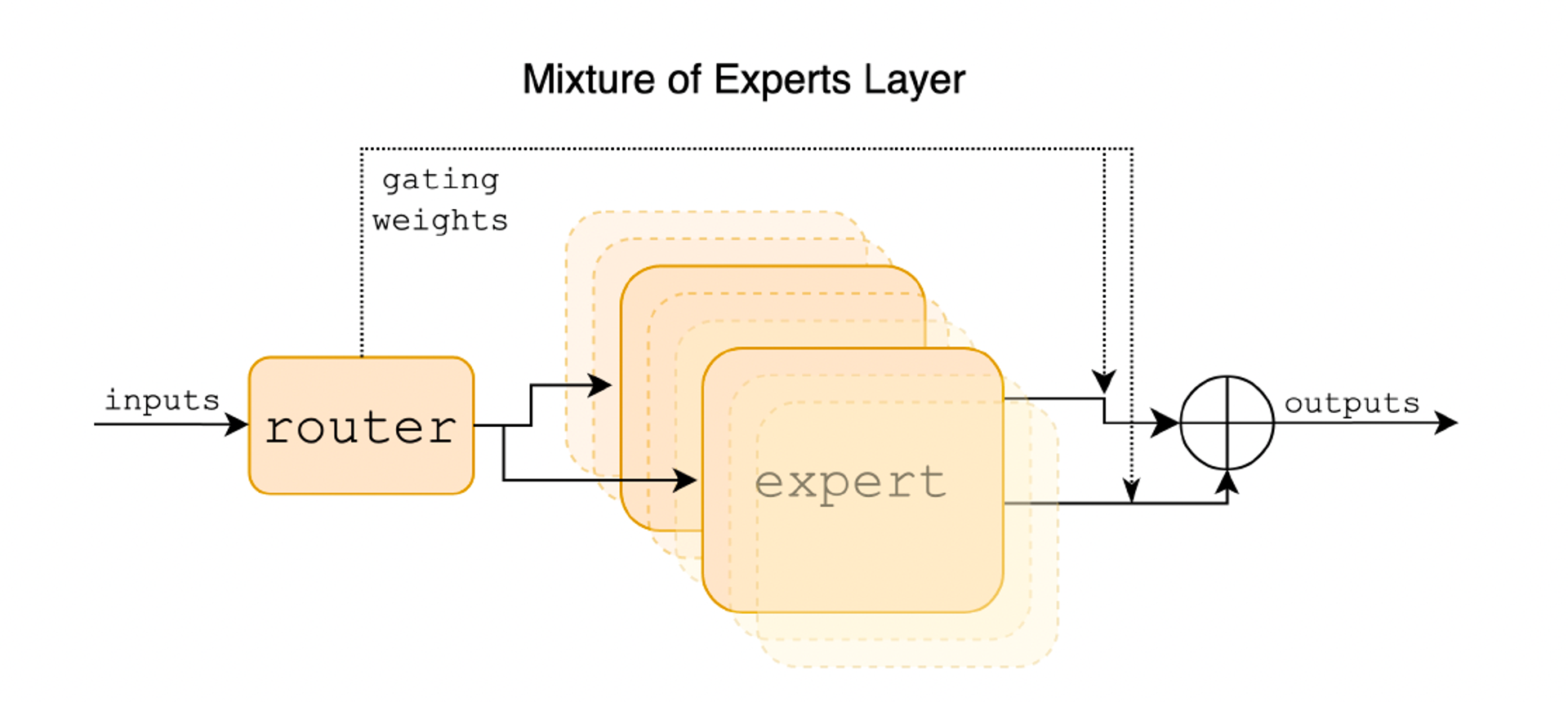
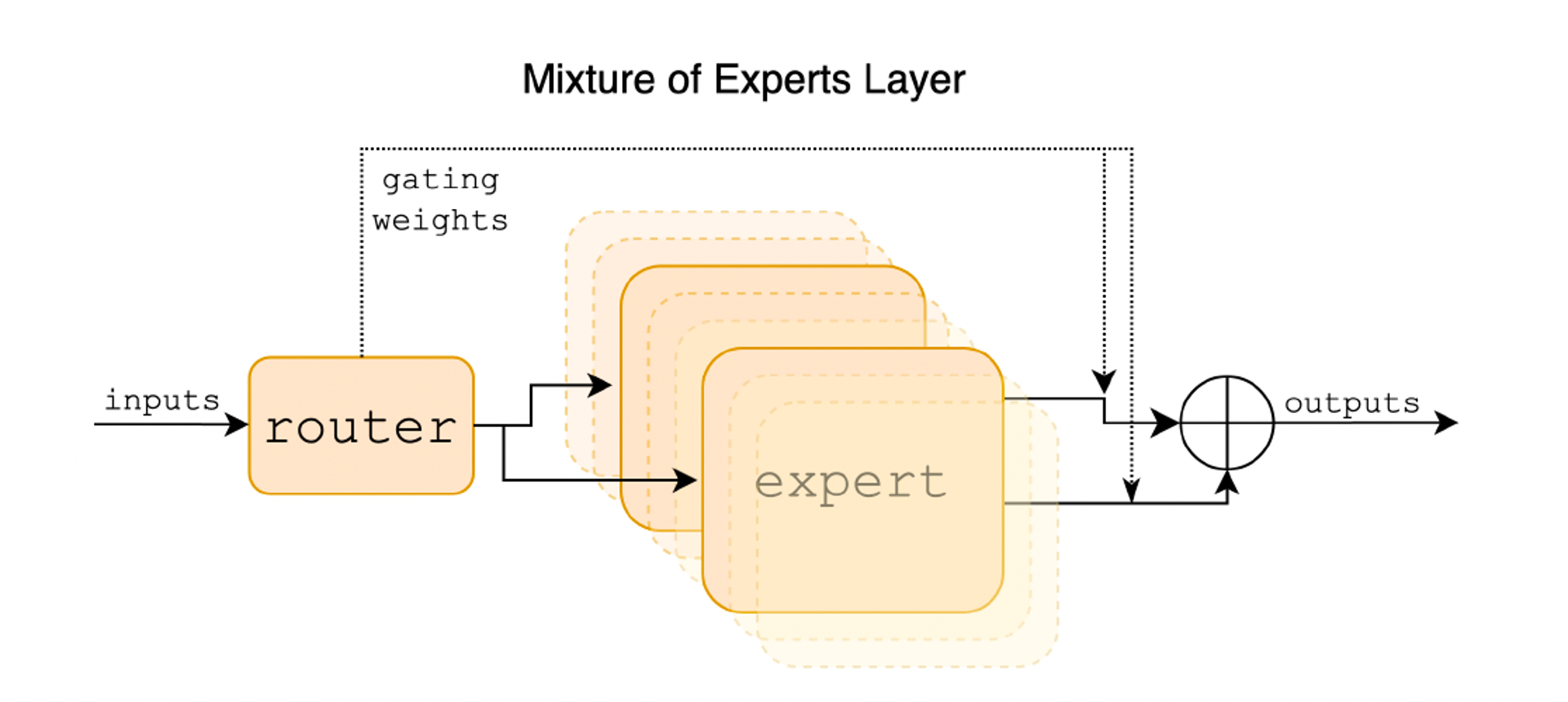
Basically, Mixtral is made up of two components shown as the figure below:
- Sparse Mixture of Expert (MoE) Layer
- Composed of a certain number of “experts”
- Each expert is a neural network
- Router (Gated Network)
- Decided which tokens are sent to which expert
2.2 Mixtral 8x7B - Instruct
- Trained with supervised fine-tuning and direct preference optimization
- Released under Apache 2.0 licence
3. History of MoE
-
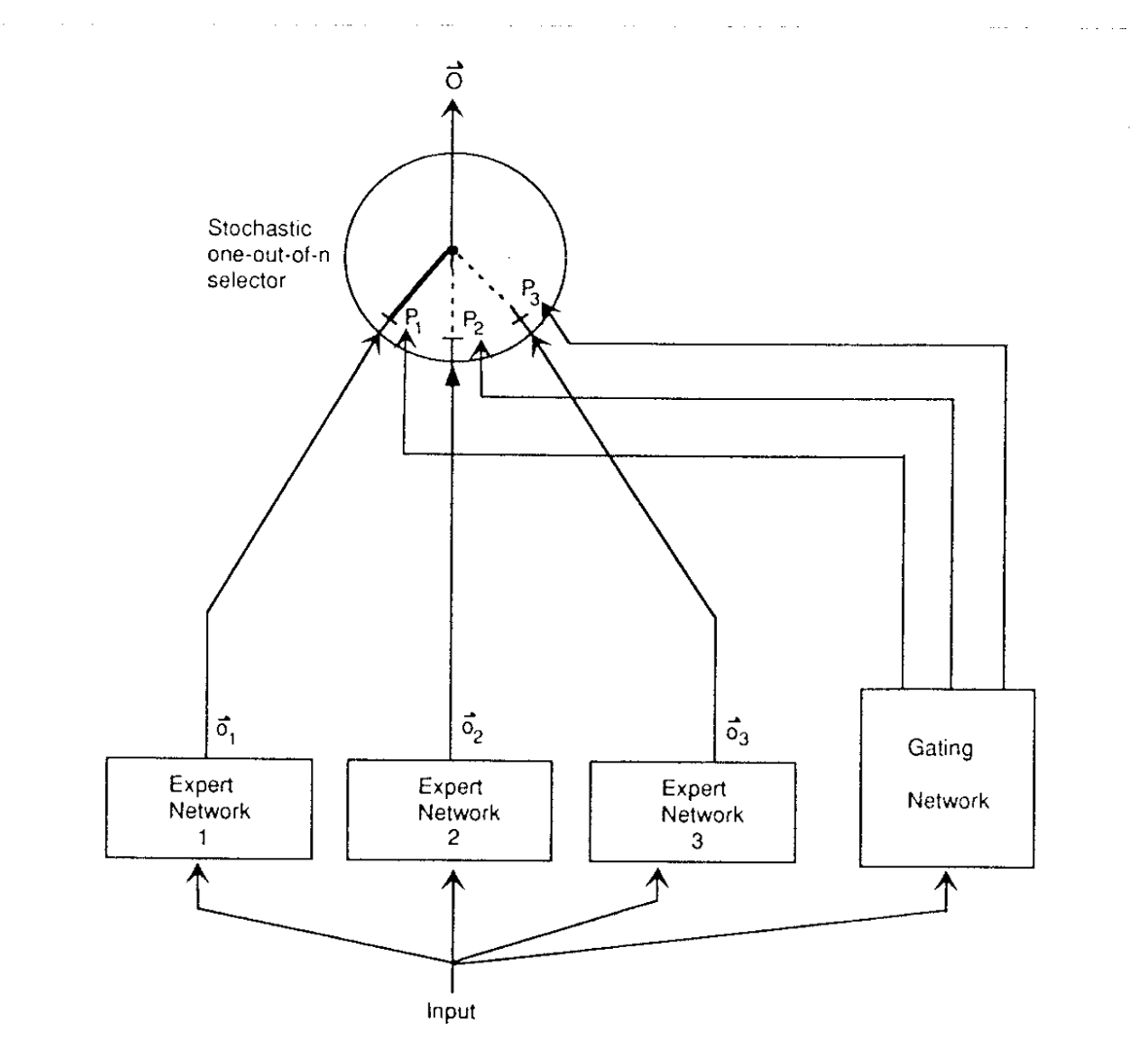
Adaptive Mixture of Local Experts (1991)
The roots of MoEs come from the 1991 paper Adaptive Mixture of Local Experts. The idea, akin to ensemble methods, was to have a supervised procedure for a system composed of separate networks, each handling a different subset of the training cases. Each separate network, or expert, specializes in a different region of the input space. A gating network determines the weights for each expert. During training, both the expert and the gating are trained.
-
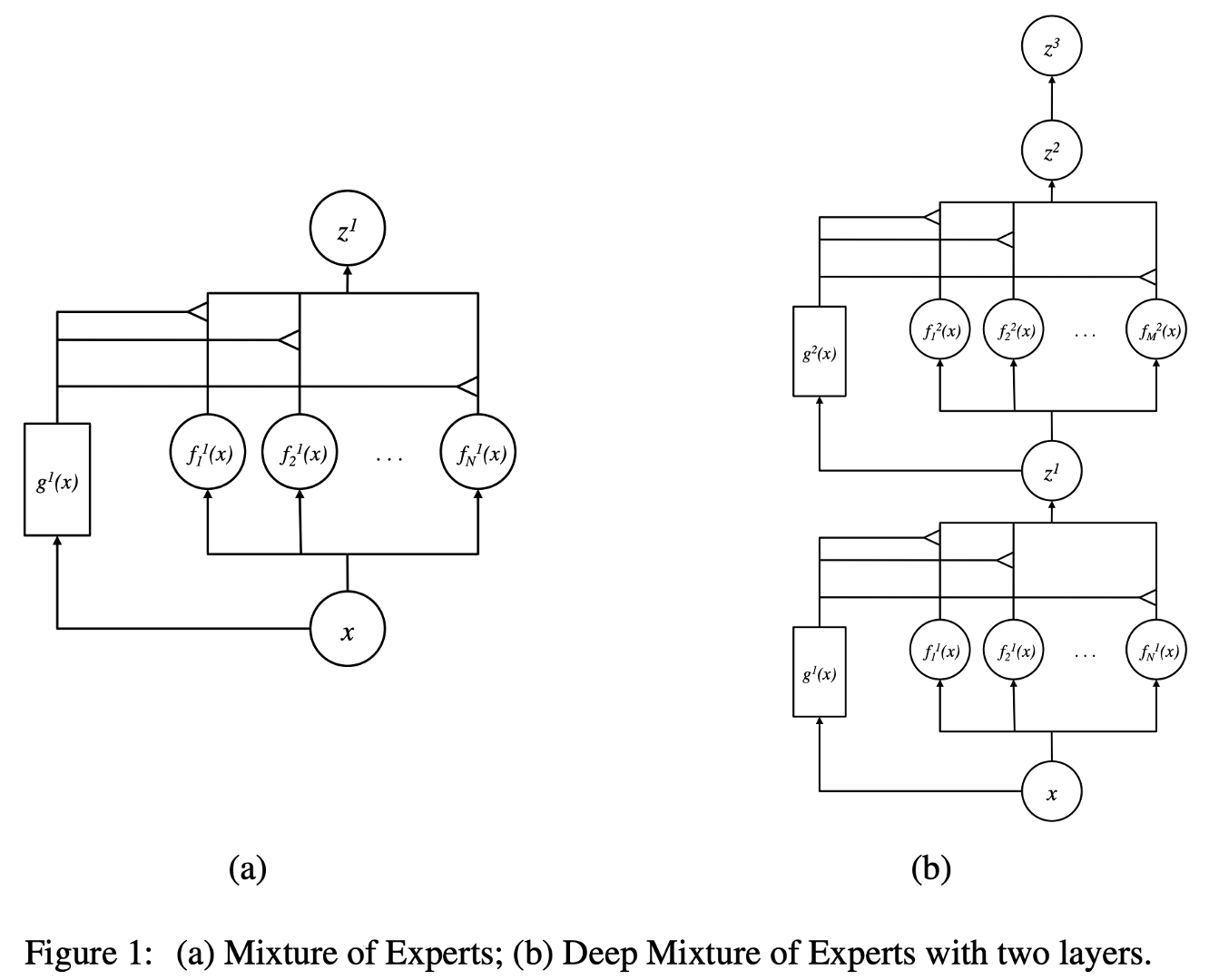
Learning Factored Representations in a Deep Mixture of Experts (2013)
In the traditional MoE setup, the whole system comprises a gating network and multiple experts. MoEs as the whole model have been explored in SVMs, Gaussian Processes, and other methods. The work by Eigen, Ranzato, and Ilya explored MoEs as components of deeper networks. This allows having MoEs as layers in a multilayer network, making it possible for the model to be both large and efficient simultaneously.
-
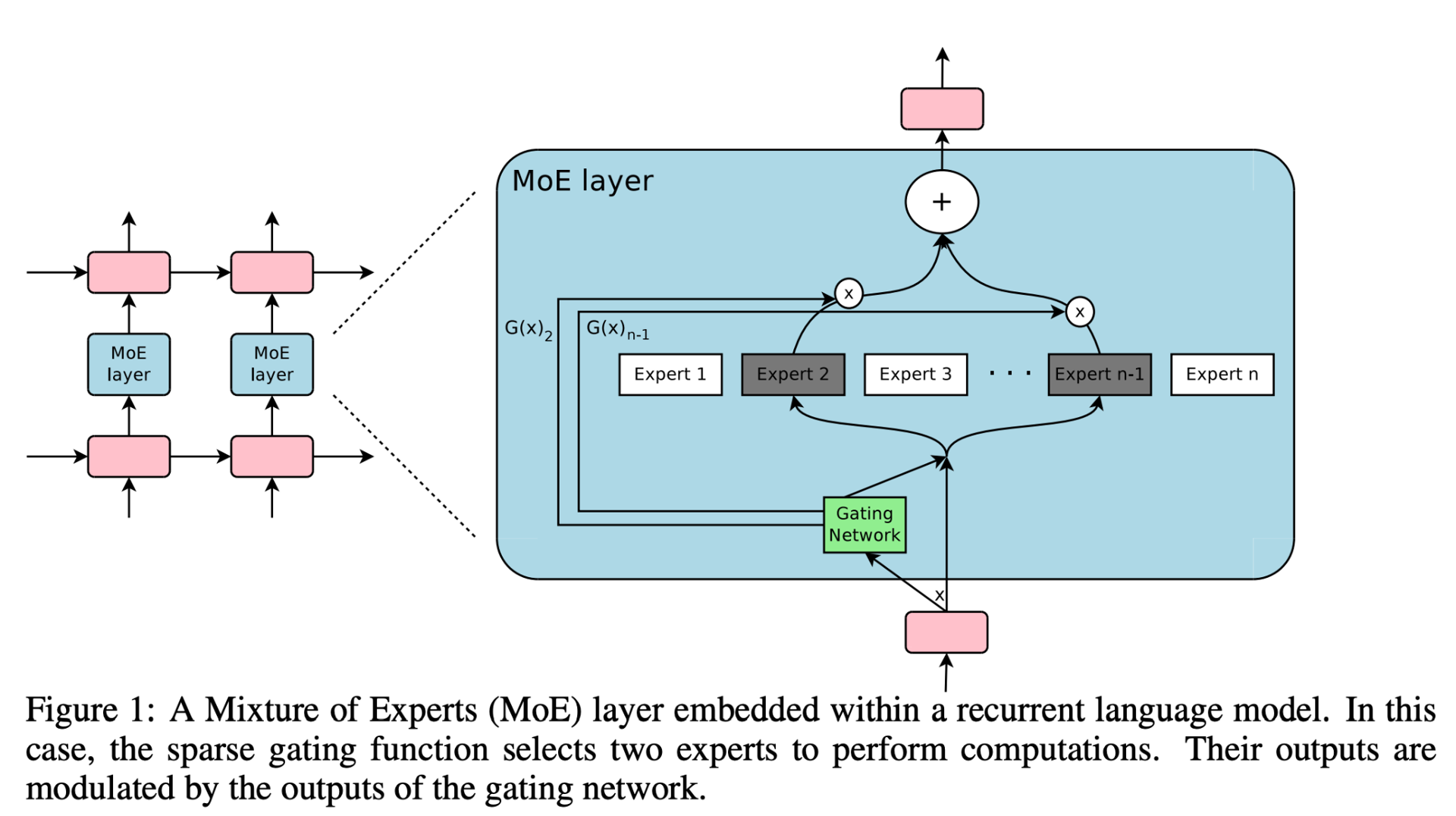
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer (2017)
This work explored a mixture of experts in the context of NLP, scaled this idea of MoE to a 137B LSTM (the de-facto NLP architecture back then, created by Schmidhuber) by introducing sparsity, allowing to keep very fast inference even at high scale.
-
GLaM: Efficient Scaling of Language Models with Mixture-of-Experts (2021)
GLaM later proposed and developed a family of language models named GLaM (Generalist Language Model), which uses a sparsely activated mixture-of-experts architecture to scale the model capacity while also incurring substantially less training cost compared to dense variants. In their work, they integrade MoE layer into transformer architecture as shown in the figure.
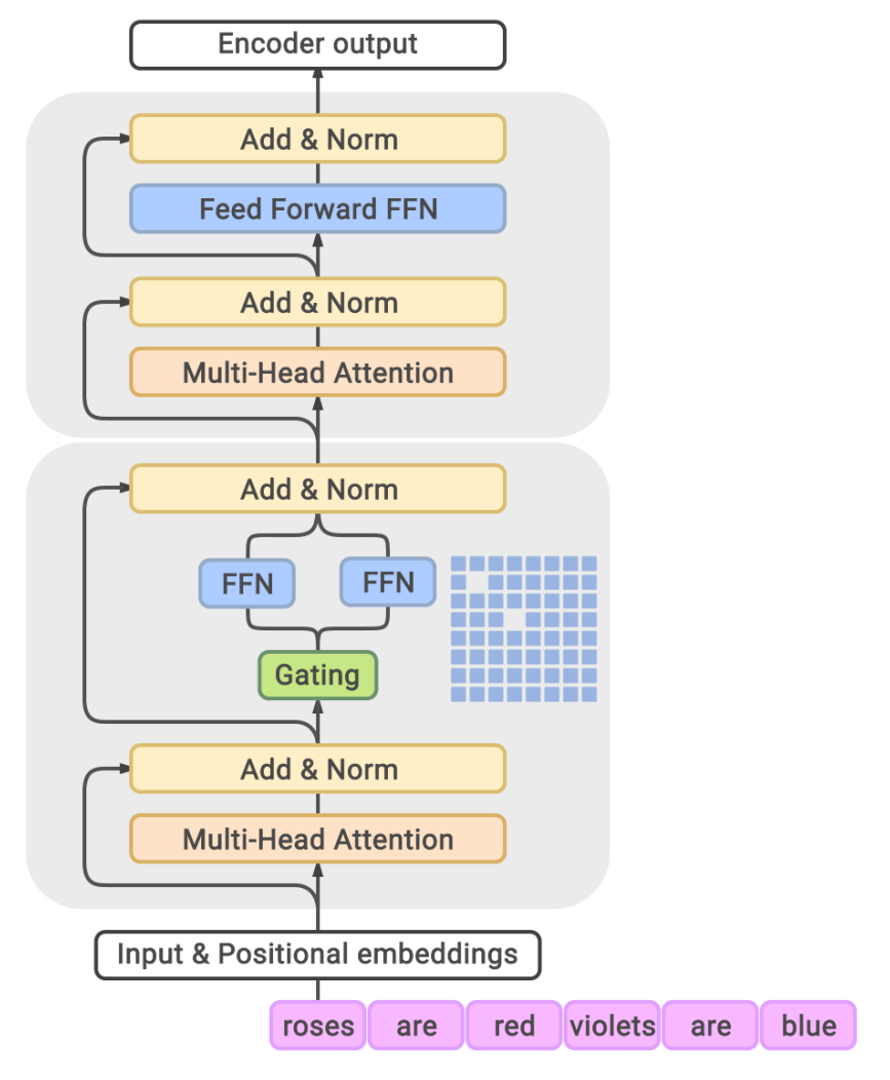
-
Switch Transformer (2022)
Switch Transformer improved the design of MoE layer in Transformer architecture which is now the most popular Transformer-based MoE architecture recently in most large language models.
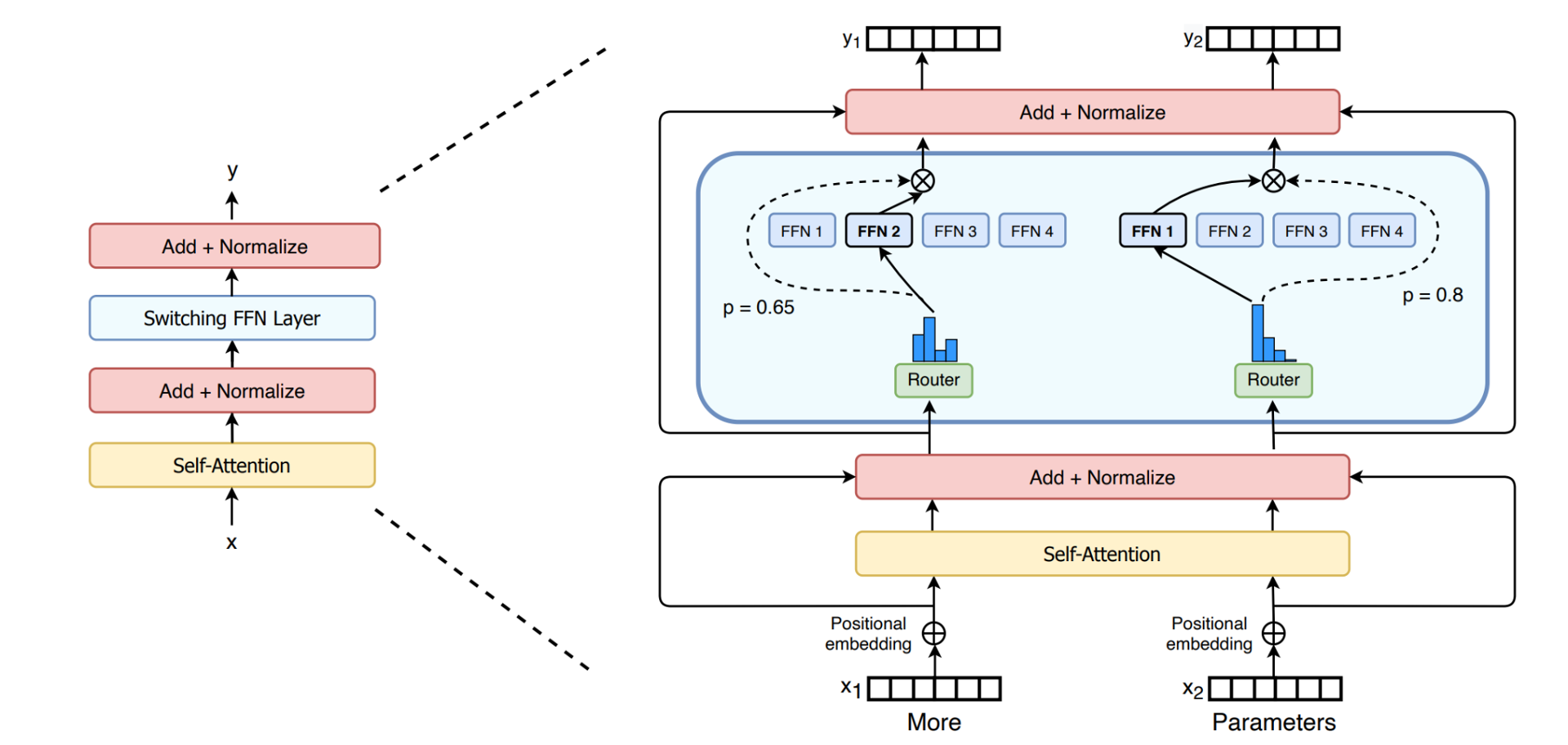
4. Mixtral 8x7B
Mixtral is based on a transformer architecture and uses the same modifications as described in Mistral 7B.
4.1 Model Architecture
The overall parameter architecture of Mixtral is similar to that of Mistral.
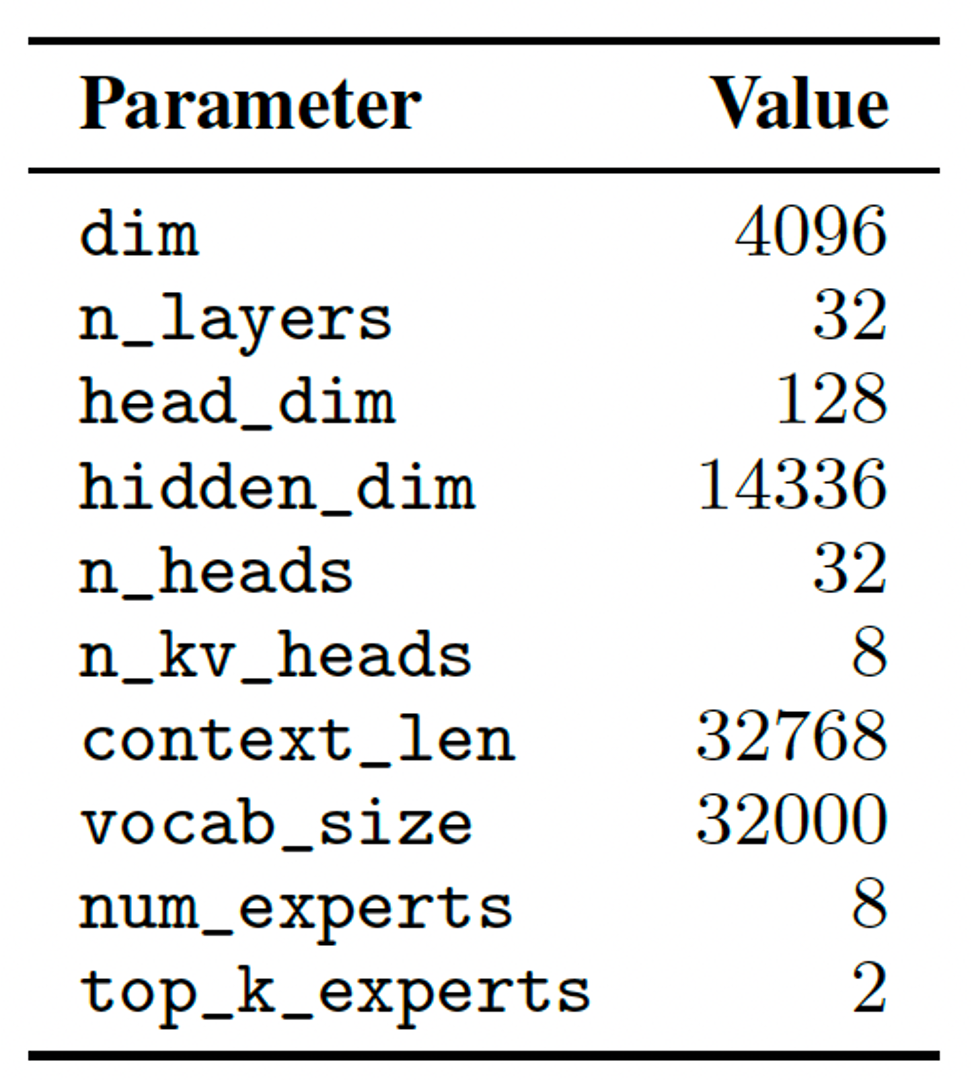
4.2 MoE Layer
Formulation of each MoE Layer
The output of each layer can be formulated as:
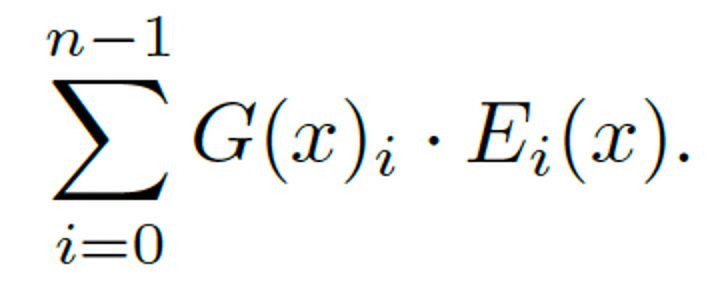
Actully only a few experts will be activated, like in the example below, only 2 experts are activated and get involved in the inference.
Sparsity
To only activate a few experts, the gating vector G(x) should be sparse, it is achieved through taking the softmax over the Top-K logits of a linear layer, which can be formulated as:
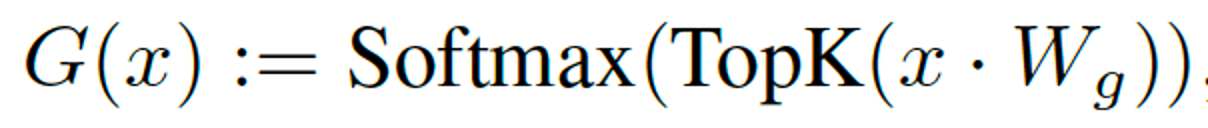
The formulation of topK(l) is:

Mixtral
In a Mixtral, the MoE layer is applied independently per token and replaces the feed-forward (FFN) sub-block of the transformer block. They use the same SwiGLU architecture as the expert function Ei(x) and set K = 2. This means each token is routed to two SwiGLU sub-blocks with different sets of weights. Taking this all together, the output y for an input token x is computed as:
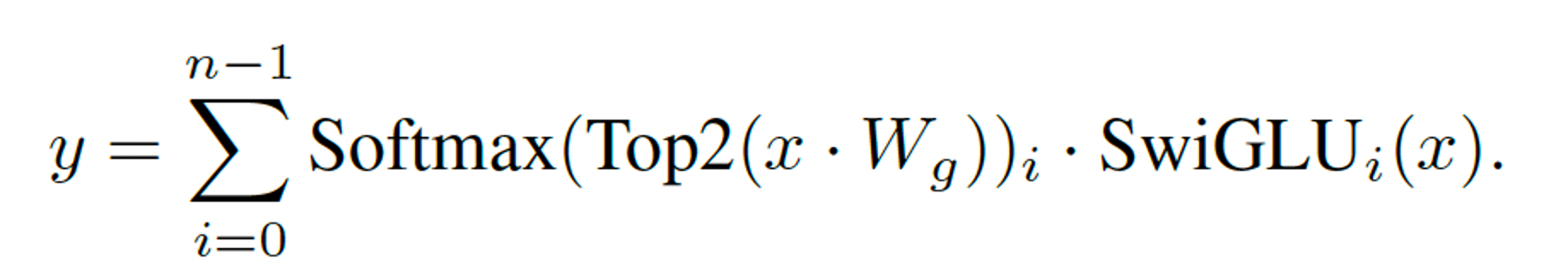
5. Experiments
5.1 Setup
Mixtral is mainly compared with Llama2 because they are both open-sourced LLMs. They are compared on 6 tasks.
- Commonsense Reasoning
- World Knowledge
- Reading Comprehension (0-shot)
- Math
- Code
- Popular aggregated results
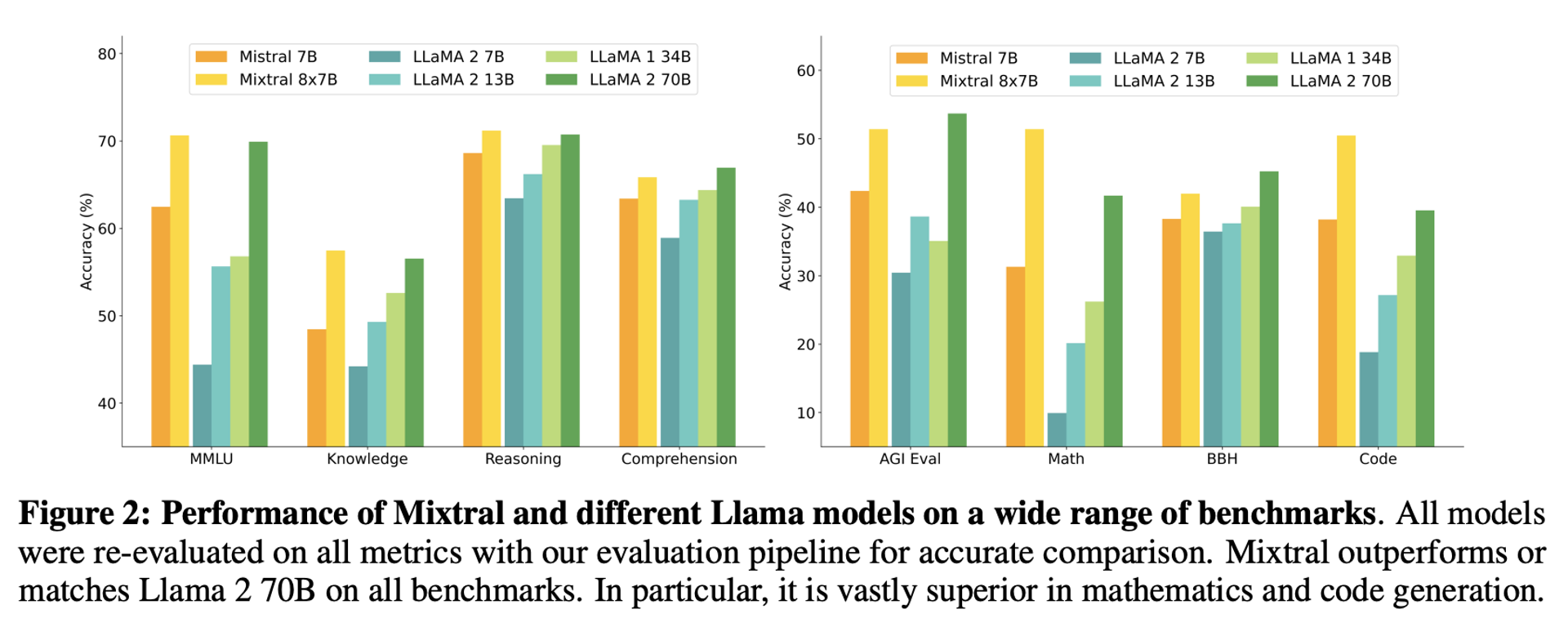
5.2 Accuracy Comparison
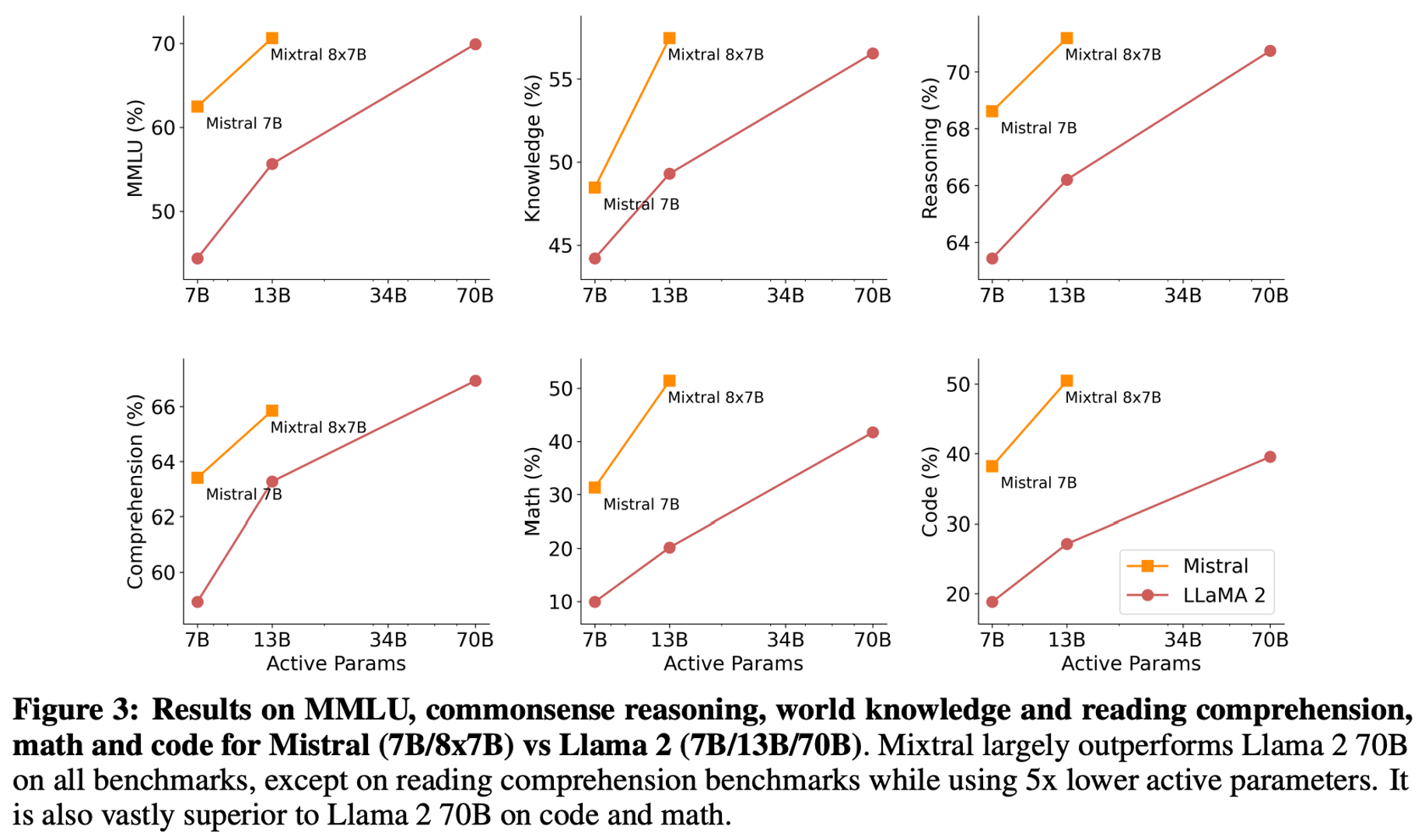
Figure below compares the performance of Mixtral with the Llama models in different categories. Mixtral surpasses Llama 2 70B across most metrics. In particular, Mixtral displays a superior performance in code and mathematics benchmarks.
5.3 Size and Efficiency Comparison
As a sparse Mixtureof-Experts model, Mixtral only uses 13B active parameters for each token. With 5x lower active parameters, Mixtral is able to outperform Llama 2 70B across most categories.
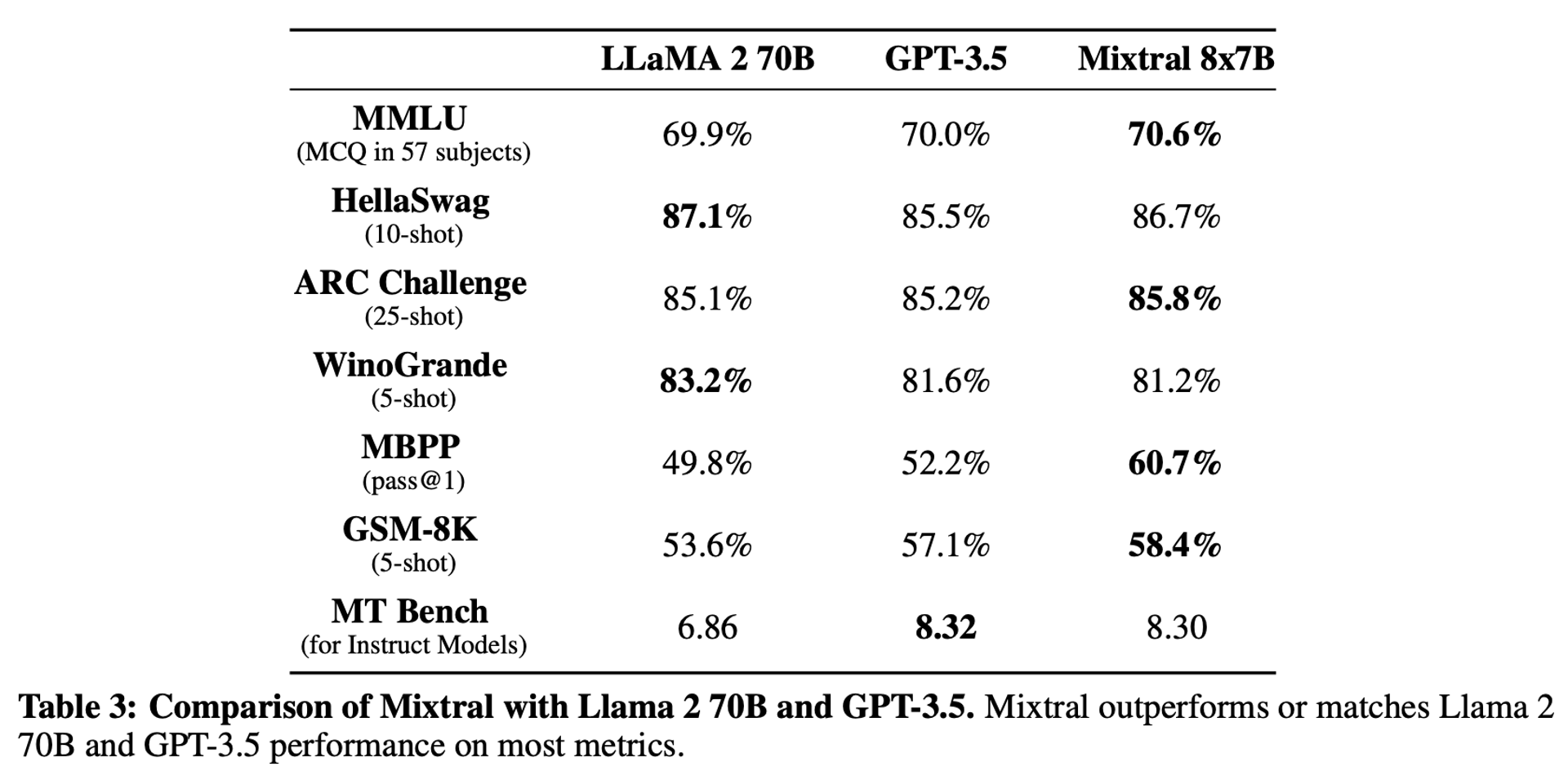
5.4 Comparison with Llama2 70B and GPT-3.5
They also report the performance of Mixtral 8x7B compared to Llama 2 70B and GPT-3.5. We observe that Mixtral performs similarly or above the two other models. On MMLU, Mixtral obtains a better performance, despite its significantly smaller capacity (47B tokens compared to 70B).
5.5 Multilingual Benmarks
The extra capacity allows Mixtral to perform well on multilingual benchmarks while maintaining a high accuracy in English. In particular, Mixtral significantly outperforms Llama 2 70B in French, German, Spanish, and Italian as shown below.

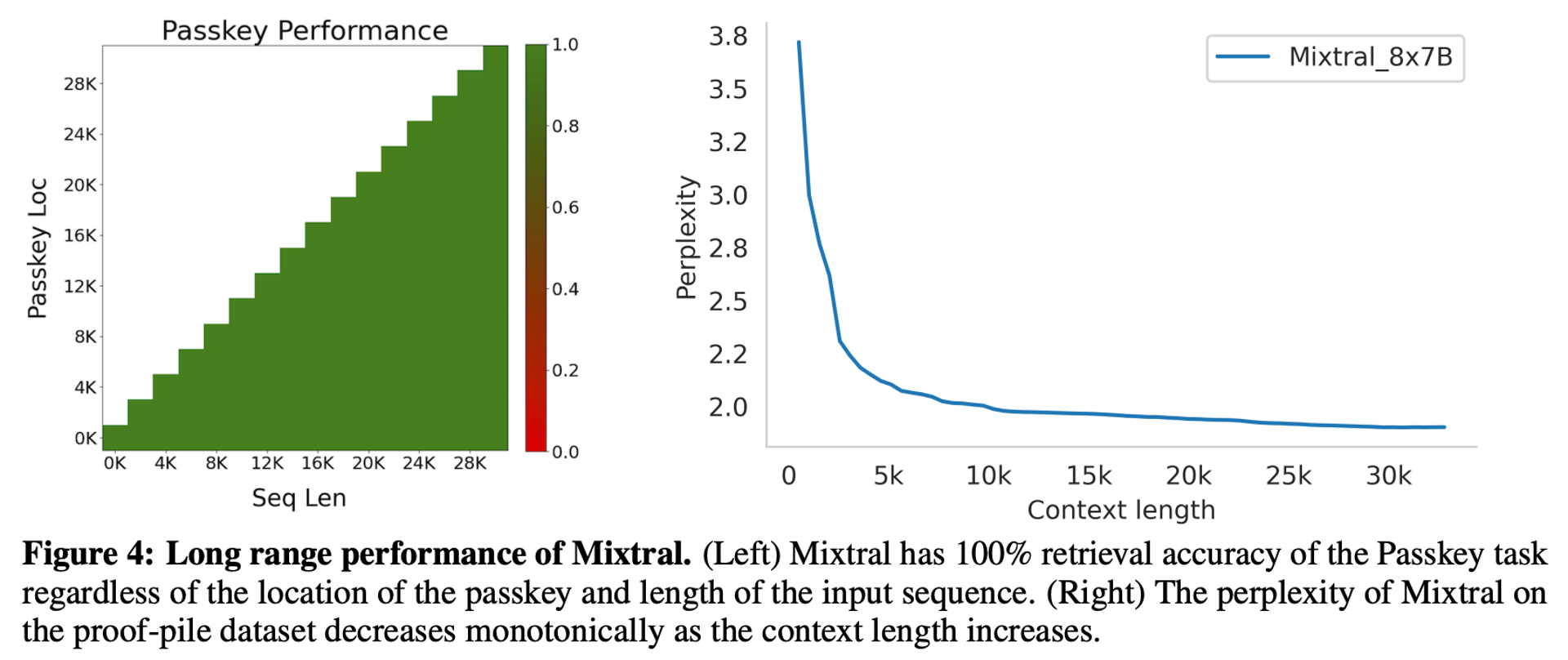
5.6 Long Range Performance
They test its long range performance on Passkey retrieval taks. This task is mainly to measure the ability of the model to retrieve a passkey inserted randomly in a long prompt.
Left figure below shows that Mixtral achieves a 100% retrieval accuracy regardless of the context length or the position of passkey in the sequence.
Right figure below shows that the perplexity of Mixtral on a subset of the proof-pile dataset decreases monotonically as the size of the context increases.
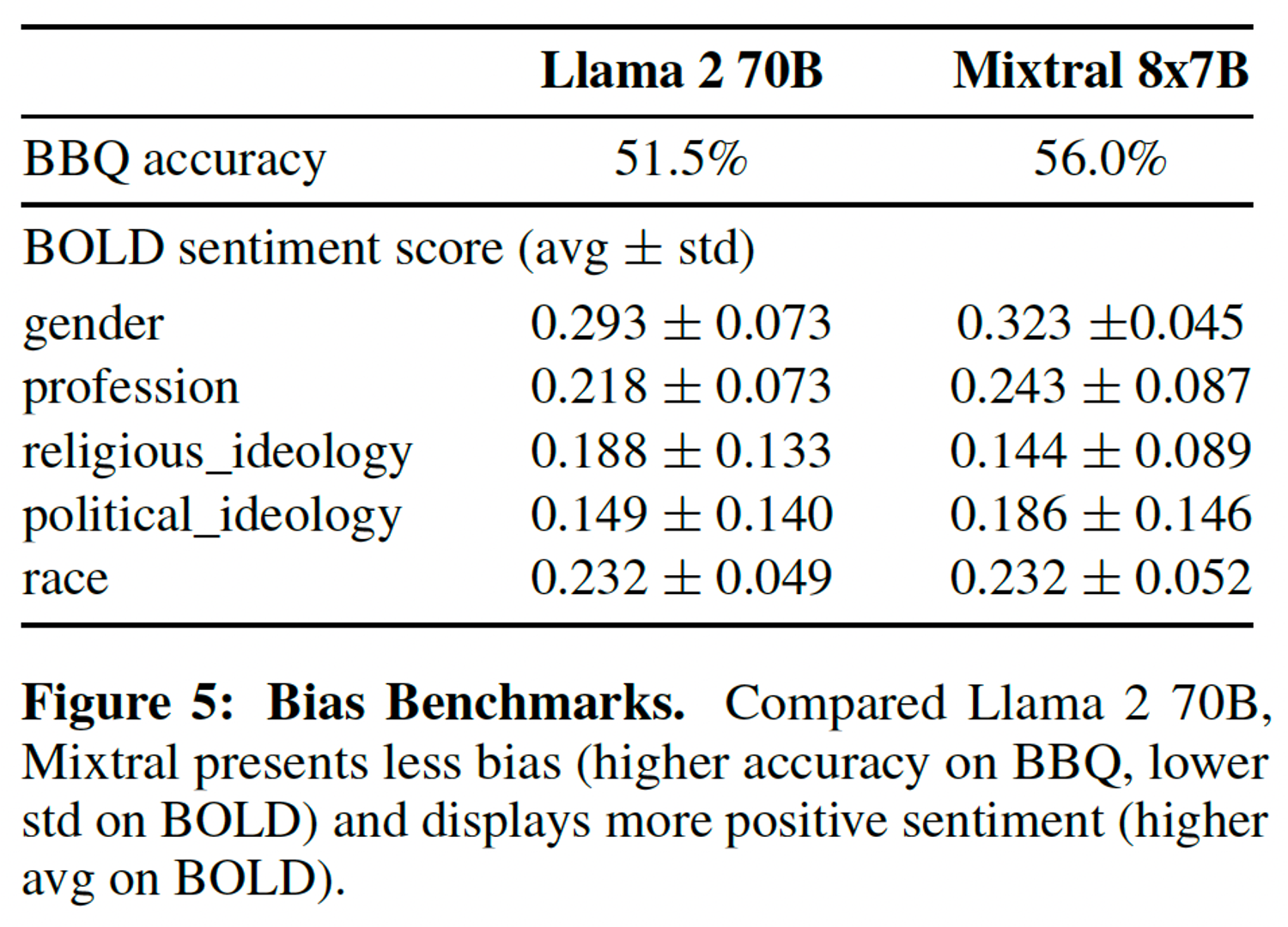
5.6 Bias Benchmarks
To identify possible flaws to be corrected by fine-tuning / preference modeling, they aslo measure the base model performance on Bias Benchmark for QA (BBQ) and Bias in Open-Ended Language Generation Dataset (BOLD).
- Bias Benchmark for QA (BBQ)
- Age, Disability, Status, Gender, Identity, Nationally, Physical appearance, Race/Ethicity, Religion, Socio-economic Status, Sexual Orientation
- Bias in Open-Ended Language Generation Dataset (BOLD)
- Large-scale dataset consists of 23679 English text generation prompts
5.8 Instruction Fine-tuning
Fine-tuning techniques they used:
- Supervised fine-tuning (SFT)
- Direct Preference Optimization (DPO) Mixtral – Instruct reaches a score of 8.30 on MT-Bench.
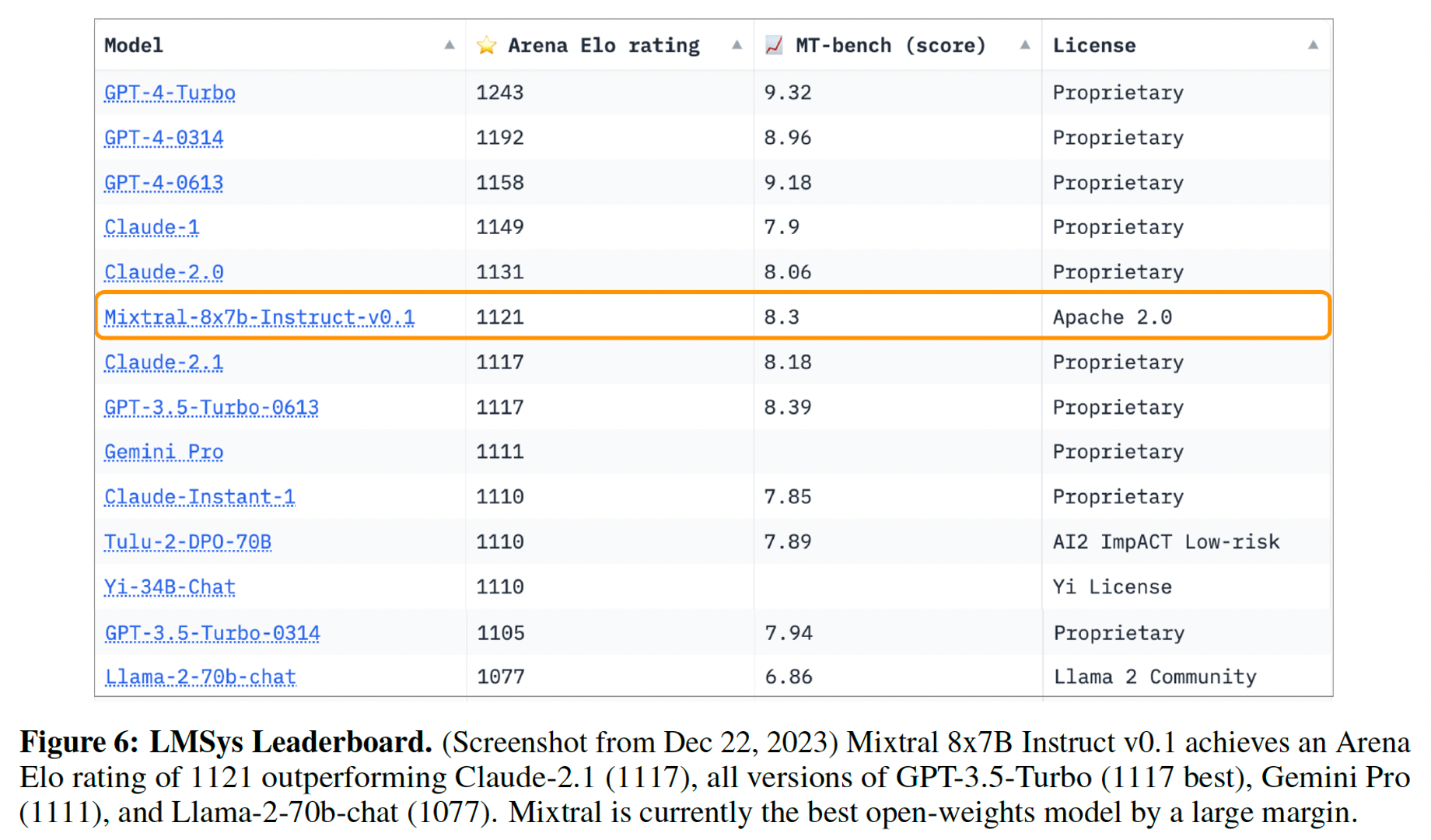
5.9 Routing Analysis
This experiment aims at exploring whether experts are specialized to specific domain.
Setup
- Pile validation dataset
- Layer 0, Layer 15 and Layer 31
Result
According to the output of selected layer, they do not observe obvious patterns in the assignment of experts based on the topic. For instance, at all layers, the distribution of expert assignment is very similar for ArXiv papers (written in Latex), for biology (PubMed Abstracts), and for Philosophy (PhilPapers) documents.
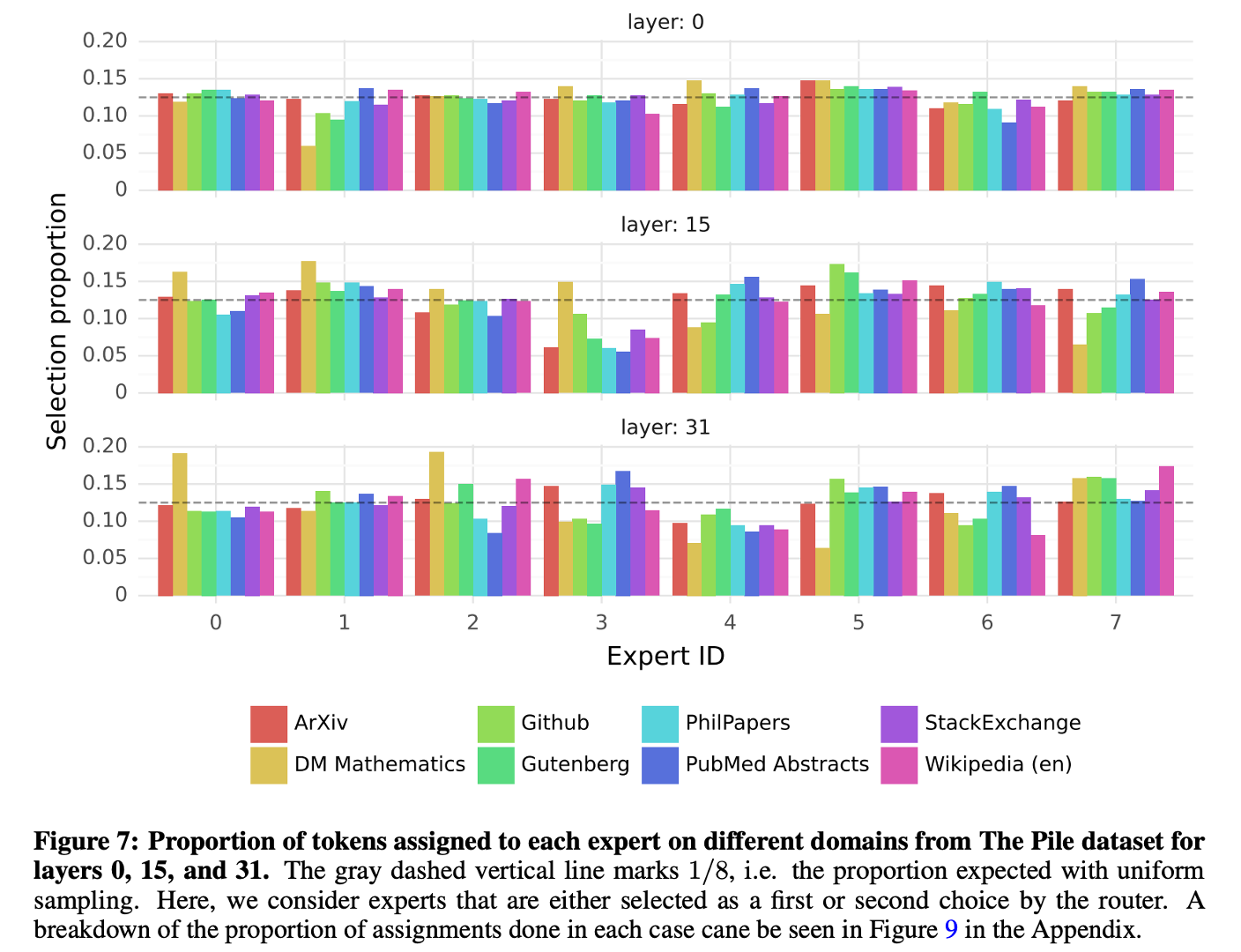
Picture below are examples of text from different domains, where each token is highlighted with a background color corresponding to its selected expert.
- Words such as self in Python and Question in English often get routed through the same expert even though they involve multiple tokens.
- In code, the indentation tokens are always assigned to the same experts, particularly at the first and last layers where the hidden states are more correlated to the input and output of the model.

Section 5: Llama 2: Open Foundation and Fine-Tuned Chat Models
From the following figure, we can see the development of large language models. Llama 2 model is released on 07/2023 and it is open-sourced.
The training process of Llama 2 model includes the Pre-training Methodology and Fine-tuning Methodology.
(1) Pre-training Methodology
To create the new family of Llama 2 models, the authors used an optimized auto-regressive transformer, but made several changes to improve performance. Specifically, they performed more robust data cleaning, updated data mixes, trained on 40% more total tokens, doubled the context length, and used grouped-query attention (GQA) to improve inference scalability for larger models.
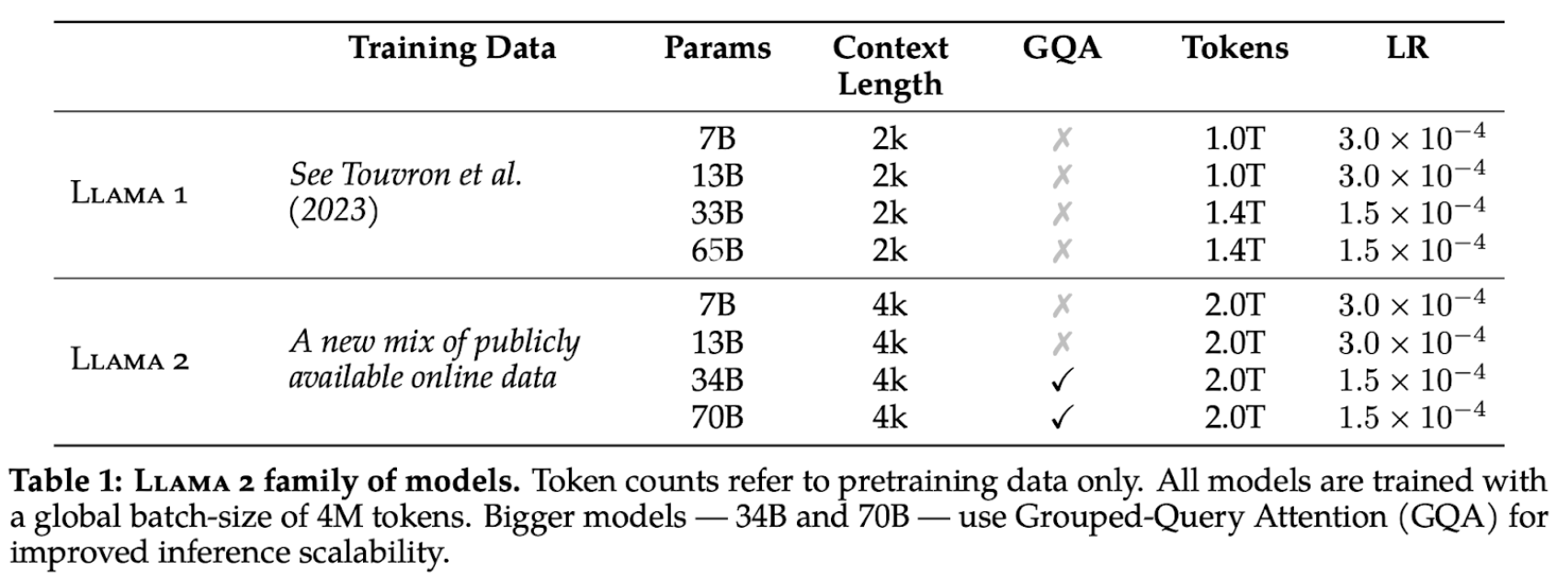
For the training details, Llama 2 adopt most of the pretraining setting and model architecture from Llama 1: - use the standard transformer architecture - apply pre-normalization using RMSNorm - use the SwiGLU activation function - use rotary positional embeddings (RoPE)
The primary architectural differences between this two models are Llama 2 model increased context length and used grouped-query attention (GQA).
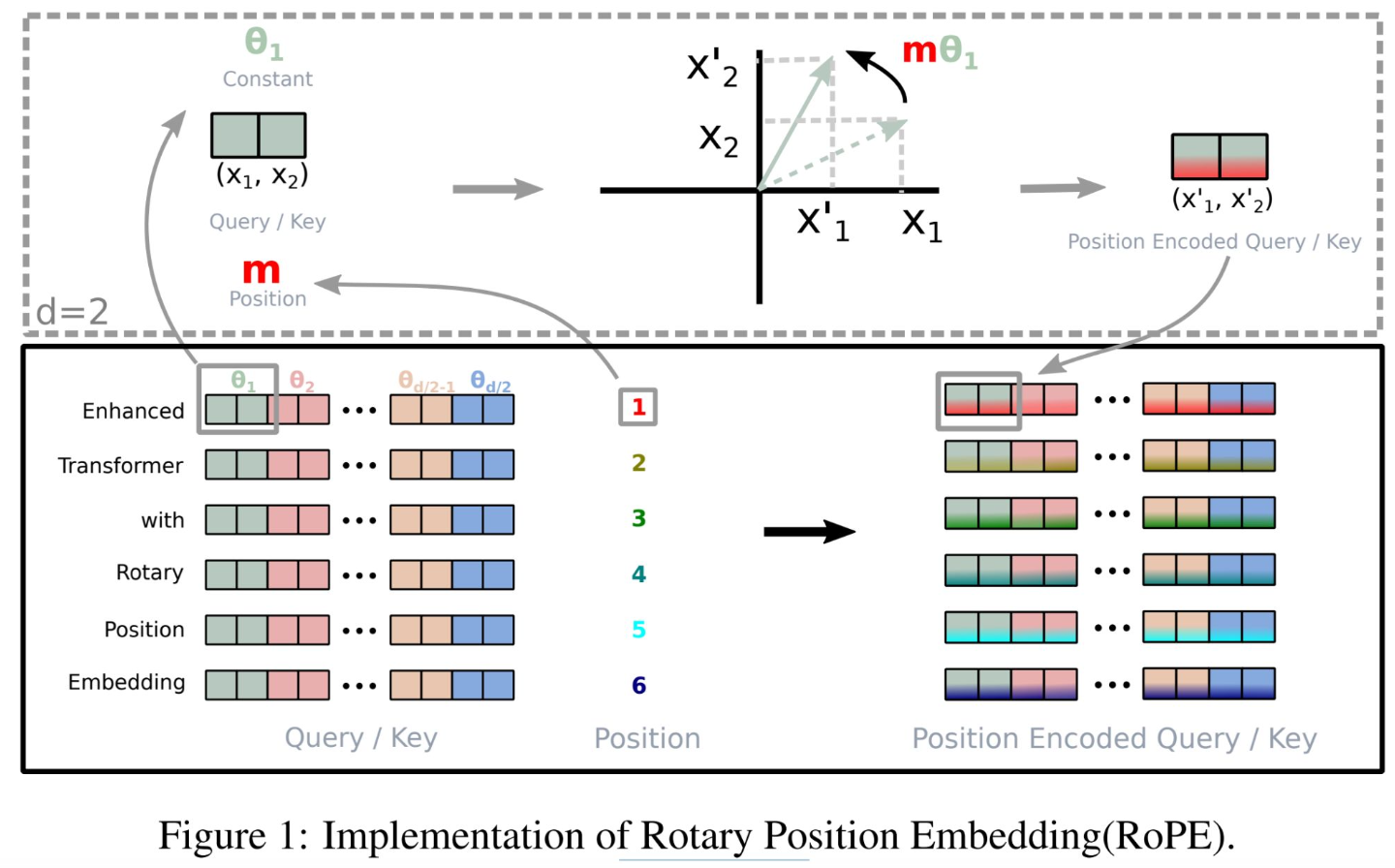
There are some problems in prior methods: (1) Absolute positional encoding is simple, but may not generalize well in longer sequences. (2) Relative positional bias (T5) is not efficient. In order to solve these problems, the authors apply rotation to word vectors to encode rotation, and maintain both absolute and relative positional embeddings in an input sentence. So they do not need to train custom parameters.
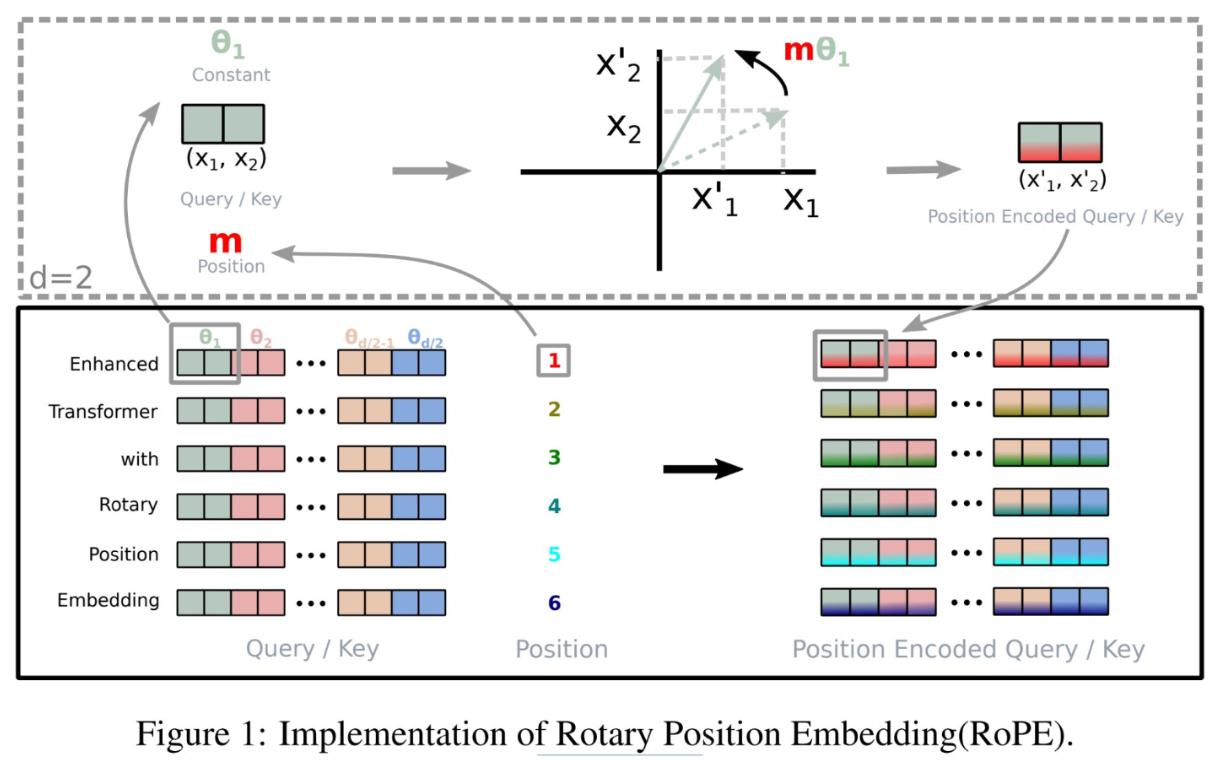
This figure illustrates the implementation of Rotary Position Embedding, or RoPE, which is an enhancement to the traditional position encoding used in transformer models. Unlike standard encoding that applies a fixed pattern to each element, RoPE dynamically encodes the position information by rotating the query and key vectors in the attention mechanism. In the top-left, you see a 2D representation of a query or key vector, marked as (X1, X2). RoPE applies a rotation matrix based on the position m — which rotates the vector to a new position, as shown by (X’1, X’2). This rotation embeds the positional information directly into the query/key, making it position-aware. Below, you see multiple layers of a transformer model with RoPE applied. The different colored blocks represent different dimensions of the query or key vectors. The numbers 1 through 6 indicate different positions in the sequence. The rotation matrix is unique for each position, thus rotating each dimension differently, as indicated by the various θ values. By integrating the position into the computation of attention, RoPE allows for more precise and context-aware interpretations of sequences, which is especially beneficial for tasks where the order and position of elements are crucial.
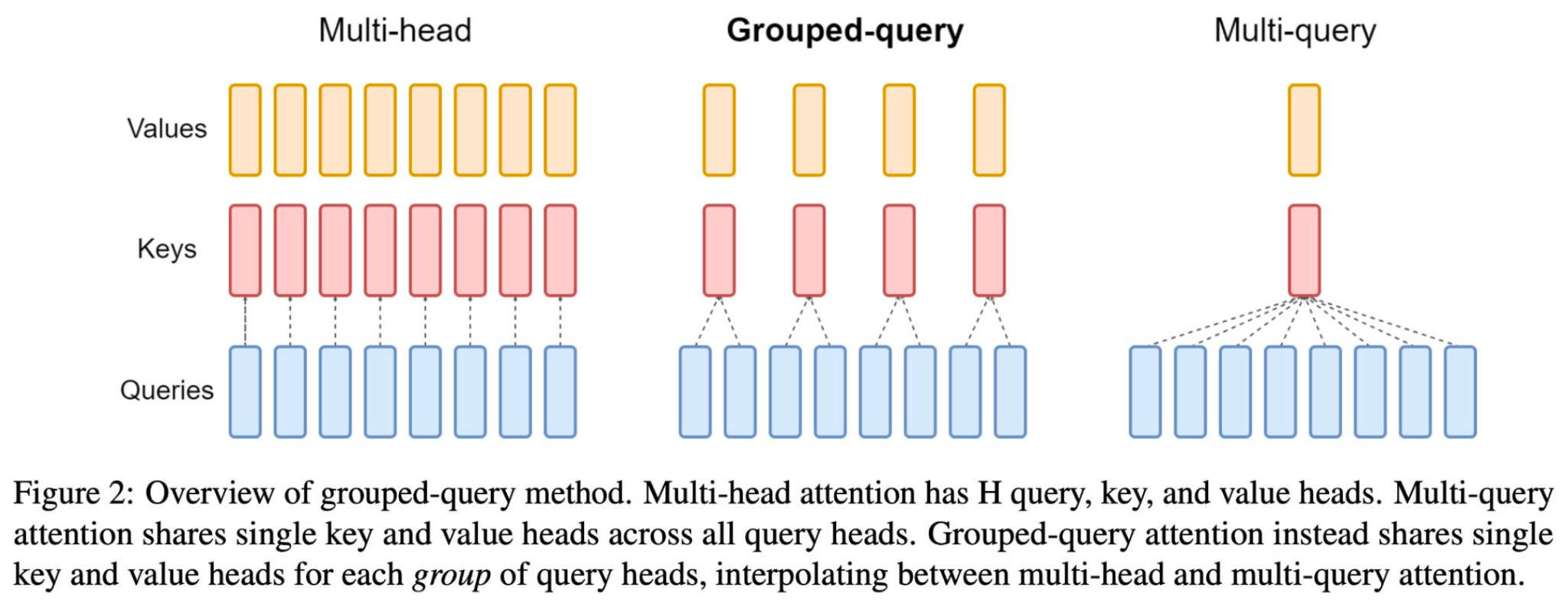
For different visions of Llama 2 models, 34B and 70B models used GQA for improved inference scalability.
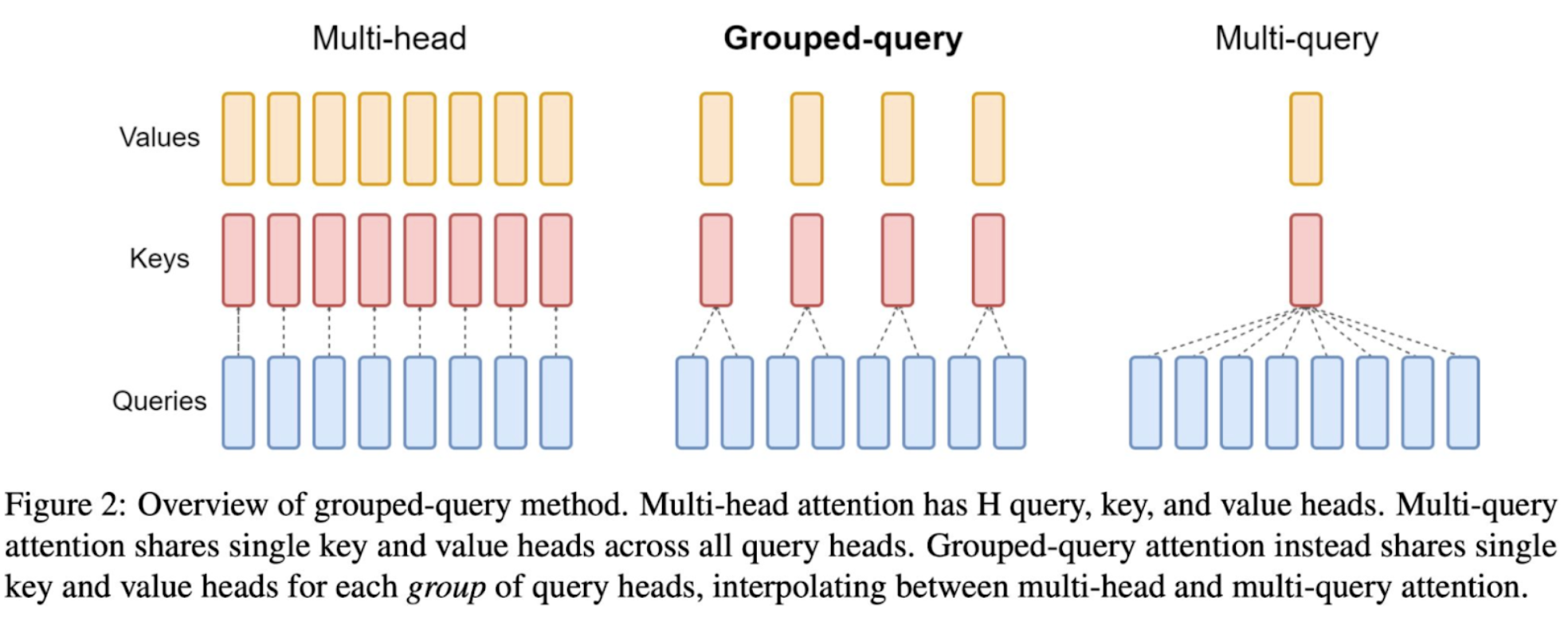
In the above figure, we’re comparing three attention mechanisms used in neural networks: Multi-head, Grouped-query, and Multi-query attention. Multi-head attention uses multiple sets of keys, queries, and values to capture different features from the input data. Grouped-query attention simplifies this by having groups of queries share the same key and value, reducing computational load while still maintaining some multi-head benefits. Multi-query attention further simplifies by using a single key and value for all queries, which is efficient but less expressive.
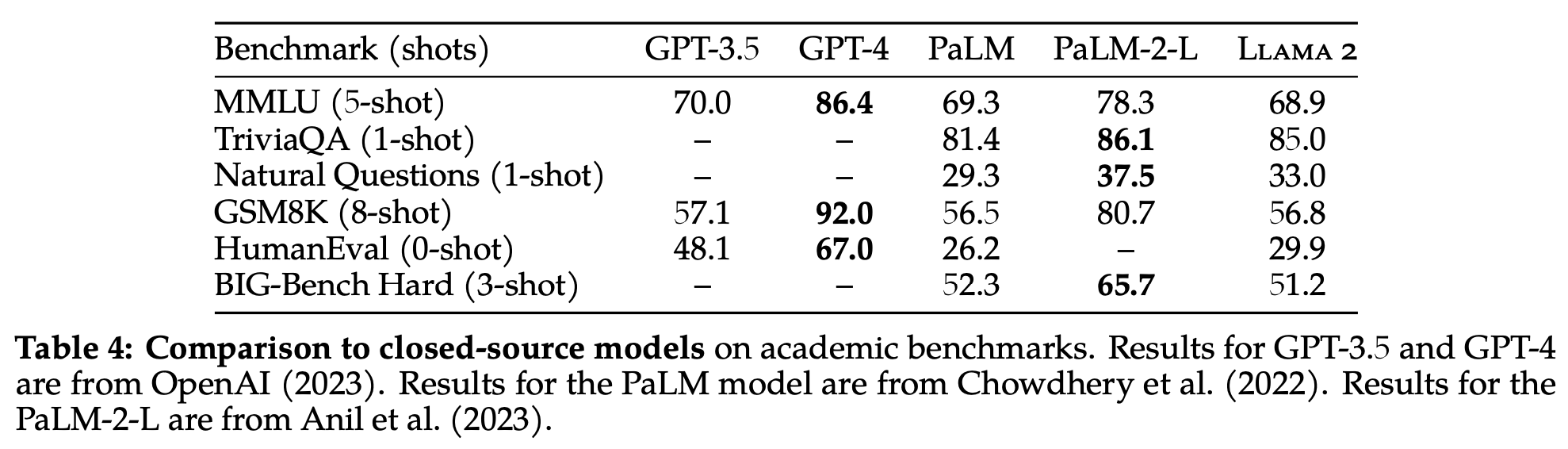
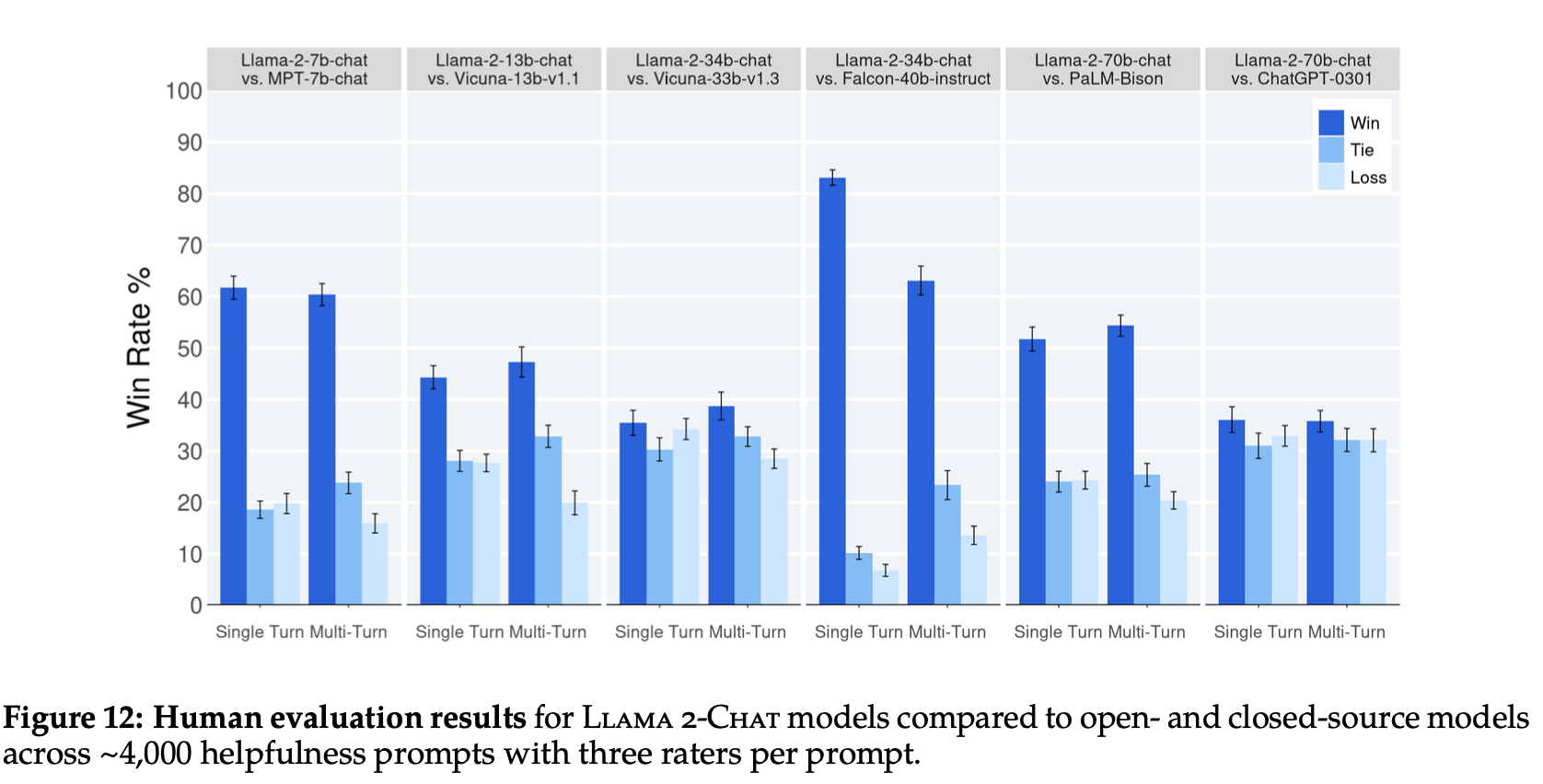
After pretraining, results are not as good as other proprietary, closed-source models. (GPT-4 and PaLM-2-L.) But the Llama-2 model is still very competitive (only a pre-trained model).
(2) Fine-tuning Methodology
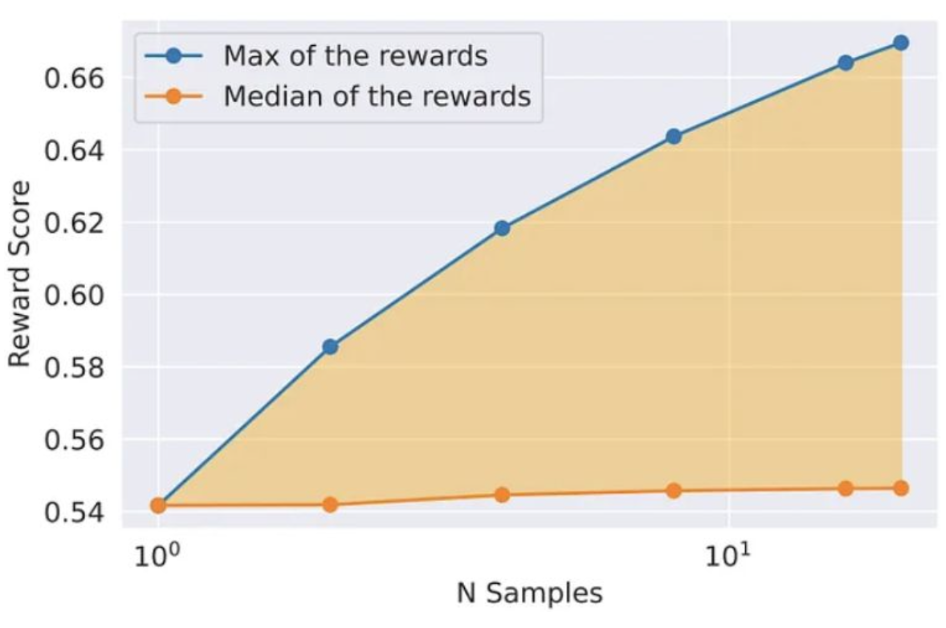
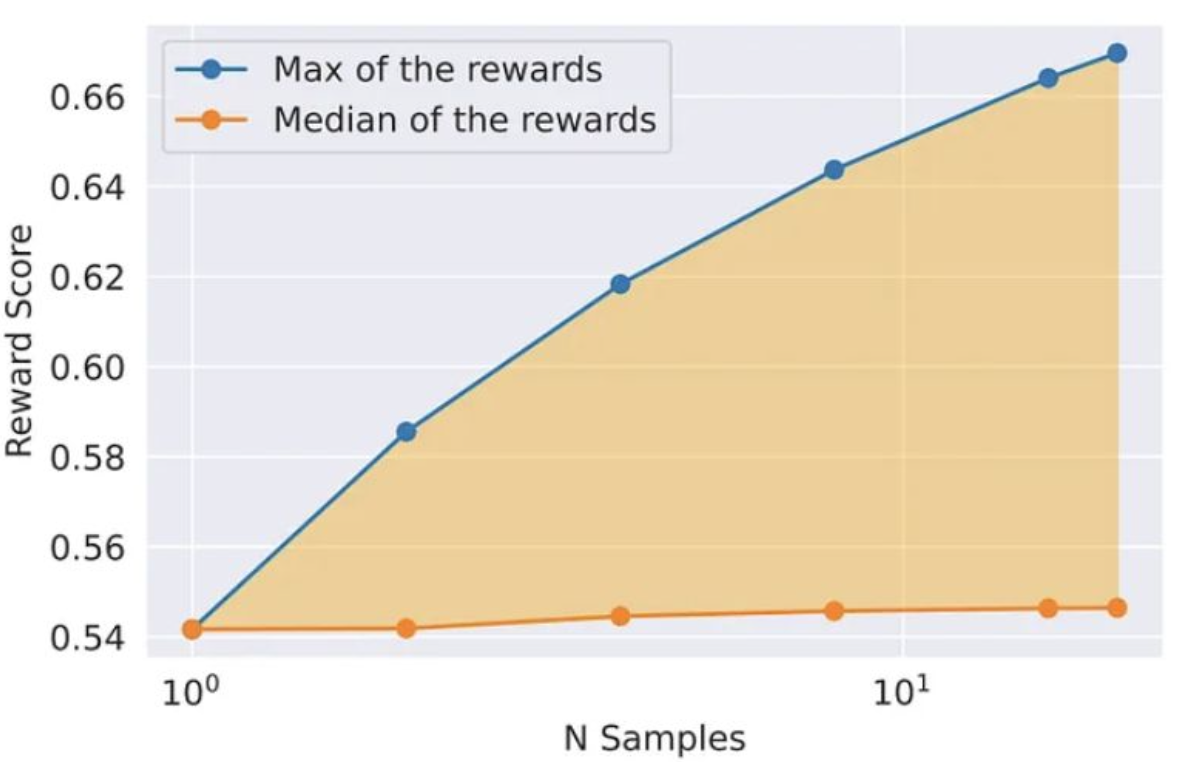
Fine-tuning Methodology includes Iterative Fine-Tuning. Sample K outputs from the model, select best candidate based on reward model. And it can be combined with PPO. Generating multiple samples in this manner can drastically increase the maximum reward of sample. It explores output space randomly, and performs SFT or PPO using samples with highest reward.
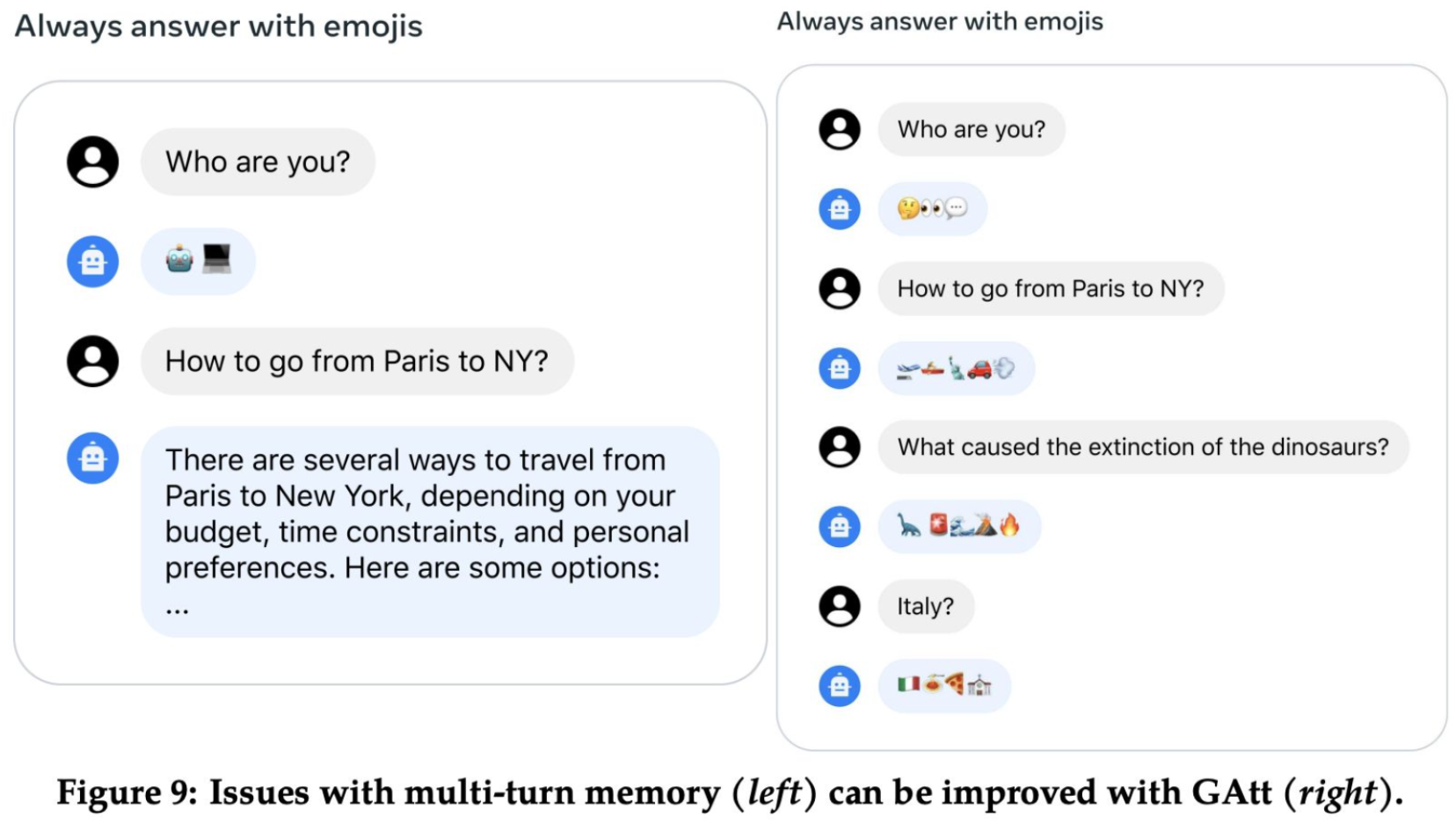
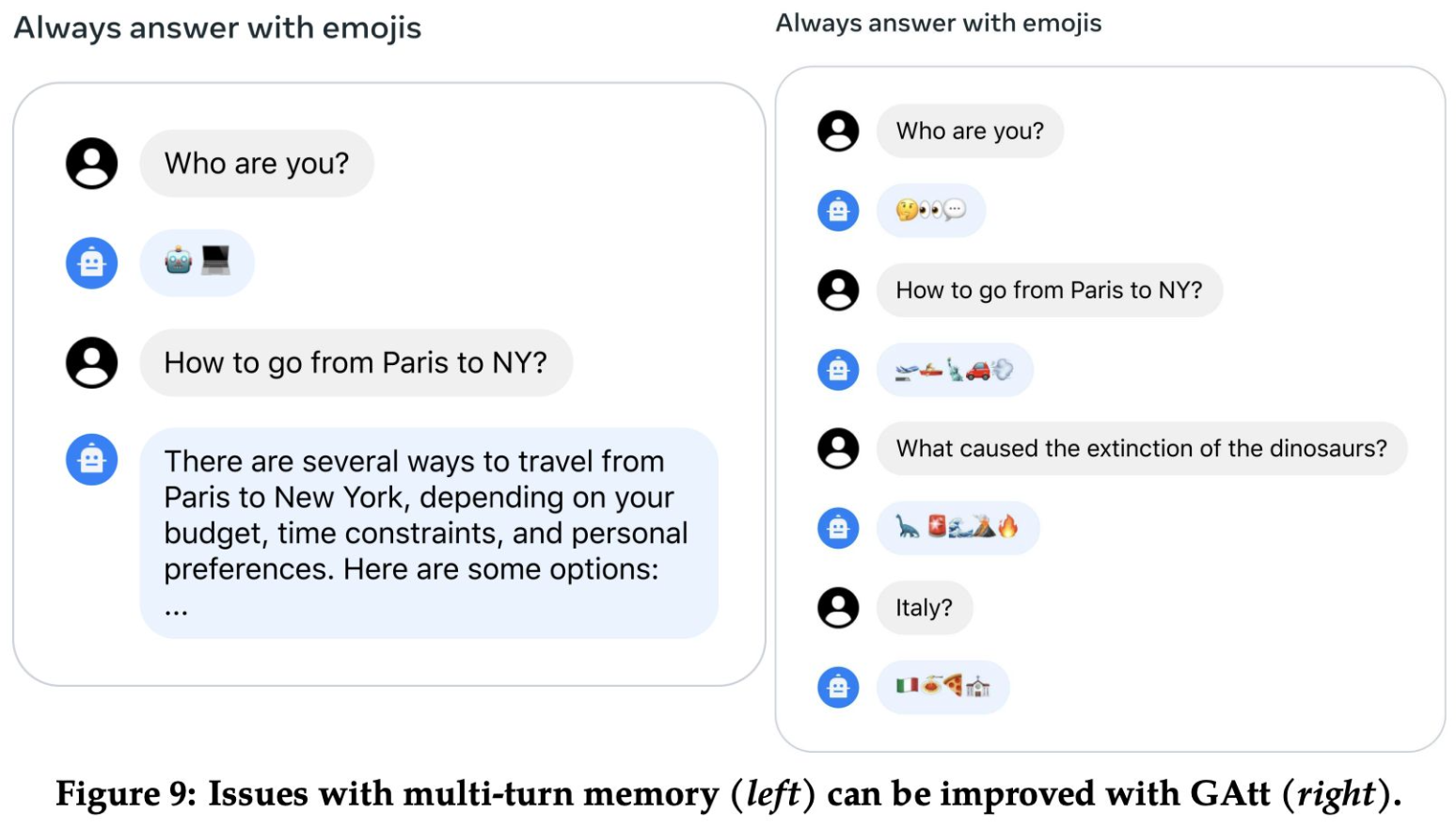
Fine-tuning Methodology also includes a novel concept called Ghost Attention, or GAtt for short. look at this comparison in the following figure. On the left, we have a typical scenario where a chatbot is tasked to always answer with emojis. However, it struggles with maintaining the context over multiple turns of conversation. For instance, when asked ‘How to go from Paris to NY?’, it provides a detailed text response, which is not what it’s supposed to do according to the ‘always answer with emojis’ rule. On the right, we introduce Ghost Attention. GAtt is an improved attention mechanism that addresses the pitfalls of multi-turn memory. It helps the model remember the ‘emoji-only’ rule across different interactions. So, when posed with the same question ‘How to go from Paris to NY?’, the GAtt-enhanced chatbot successfully responds with relevant emojis, illustrating travel and the destination. This visual contrast highlights the efficiency of Ghost Attention in maintaining consistency and context in chatbot interactions, a crucial advancement in conversational AI.
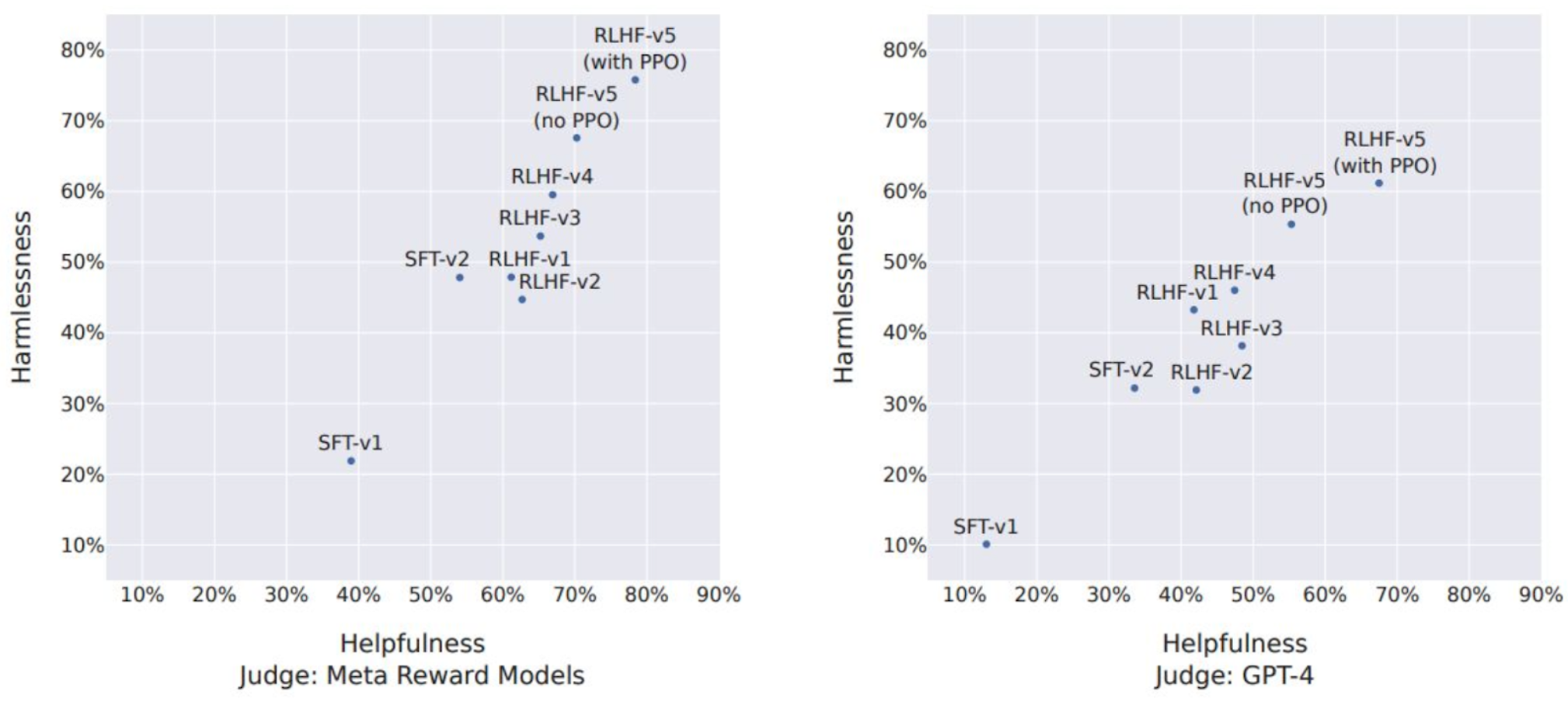
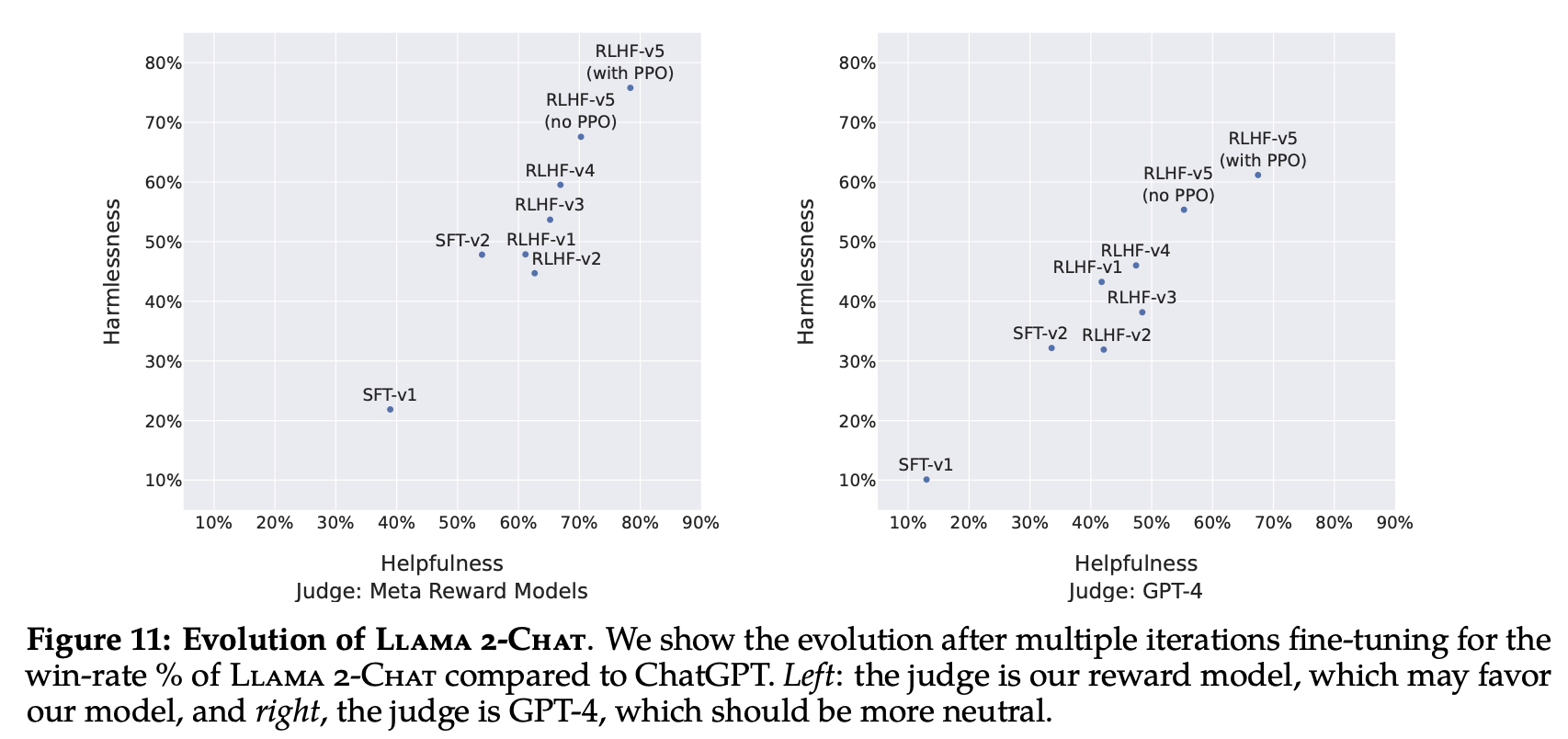
The following figure reports the progress of our different SFT and then RLHF versions for both Safety and Helpfulness axes, measured by our in-house Safety and Helpfulness reward models. On this set of evaluations, the authors outperform ChatGPT on both axes after RLHF-V3 (harmlessness and helpfulness >50%). Despite the aforementioned relevance of using our reward as a point-wise metric, it can arguably be biased in favor of Llama 2-Chat. Therefore, for a fair comparison, they additionally compute the final results using GPT-4 to assess which generation is preferred. The order in which ChatGPT and Llama 2-Chat outputs appeared in GPT-4 prompt are randomly swapped to avoid any bias. As expected, the win-rate in favor of Llama 2-Chat is less pronounced, although obtaining more than a 60% win-rate for our latest Llama 2-Chat.
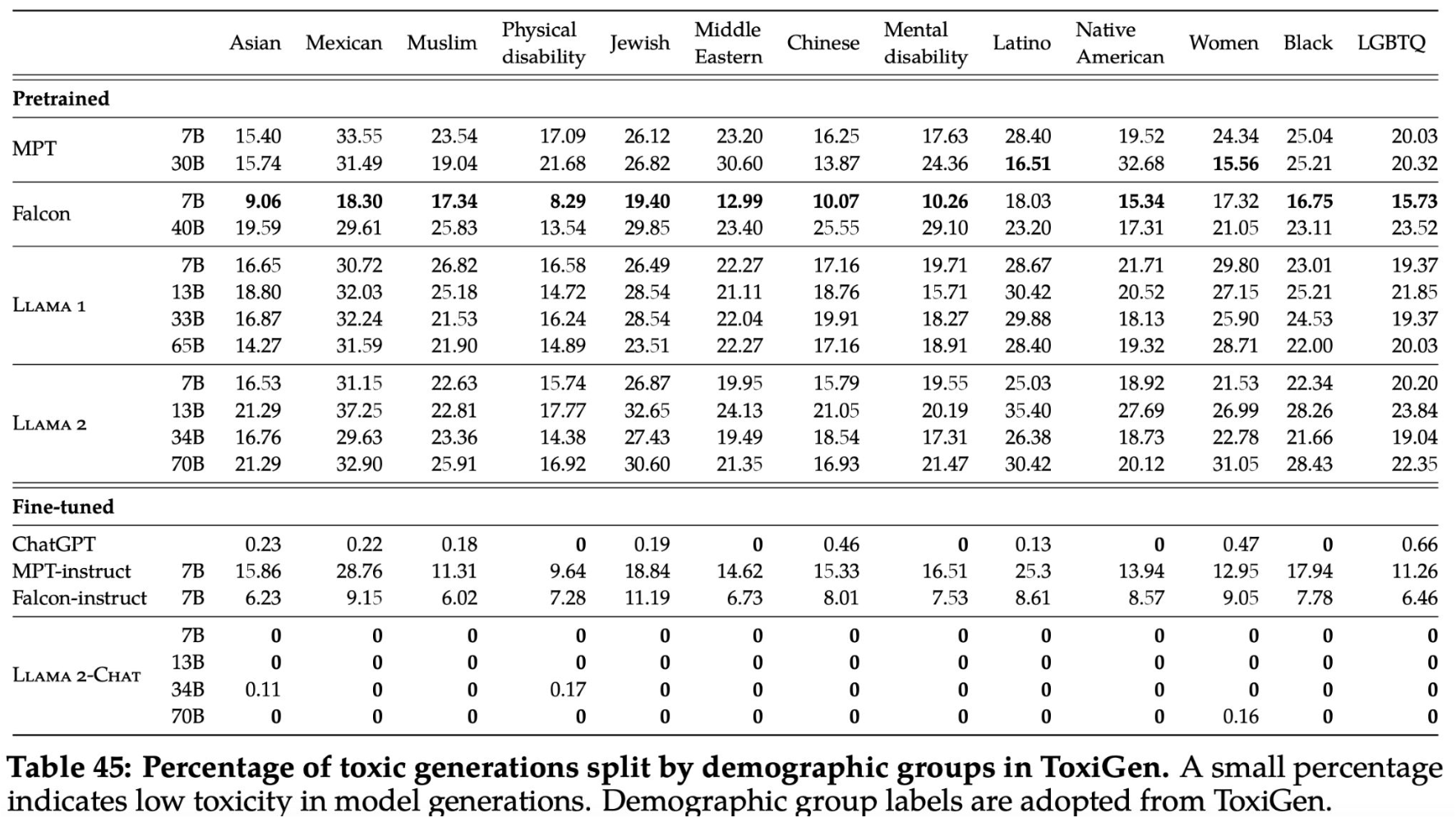
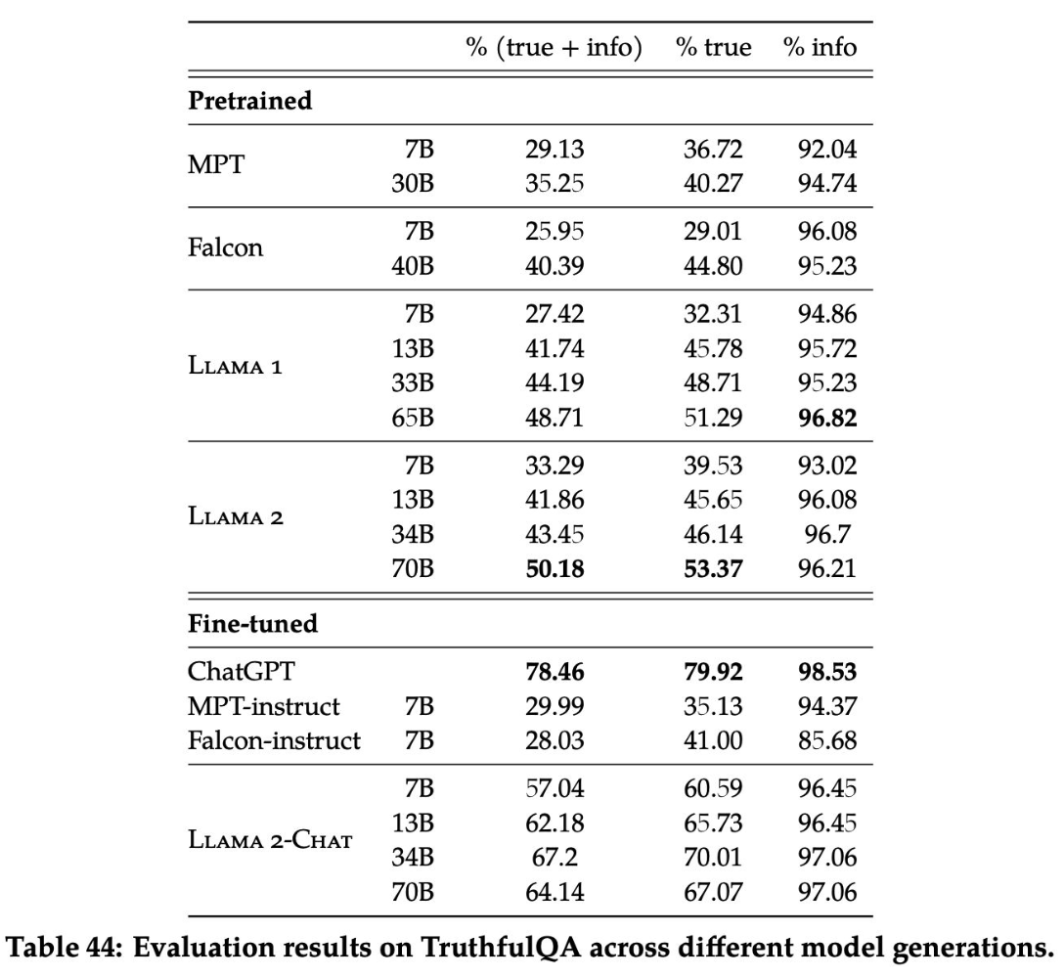
The following table shows evaluation results on TruthfulQA, assessing the accuracy of different language models in generating responses that are both true and informative. For the LLama 2 model, as the model size increases from 7 billion to 70 billion parameters, there is a trend of improvement in producing true and informative responses in the TruthfulQA evaluation. The 70B variant of LLama 2 pre-trained model exhibits over 50% in combined true and informative responses, with a substantial increase in the percentage of purely true responses as well. It also shows that LLama 2-Chat model, achieves even higher accuracy, indicating the effectiveness of fine-tuning in enhancing the model’s ability to generate truthful information.
For the model safety, we can focus on Safety in Fine-Tuning, Safety in RLHF and Safety Evaluation.
During fine-tuning process, it gathers adversarial prompts and safe demonstrations in the SFT training set. It essentially probes for edge cases. Annotator writes both the prompt and the response in adversarial samples.

This image showcases how LLama 2, when fine-tuned for safety, responds to a prompt requesting a roast that includes brutal and offensive content. The model’s response demonstrates a refusal to engage in harmful behavior, highlighting the successful implementation of safety measures in fine-tuning. It emphasizes the importance of maintaining respectful interaction and suggests focusing on positive and constructive feedback instead. This illustrates the model’s ability to handle adversarial samples by promoting positive discourse and rejecting requests for negative output.
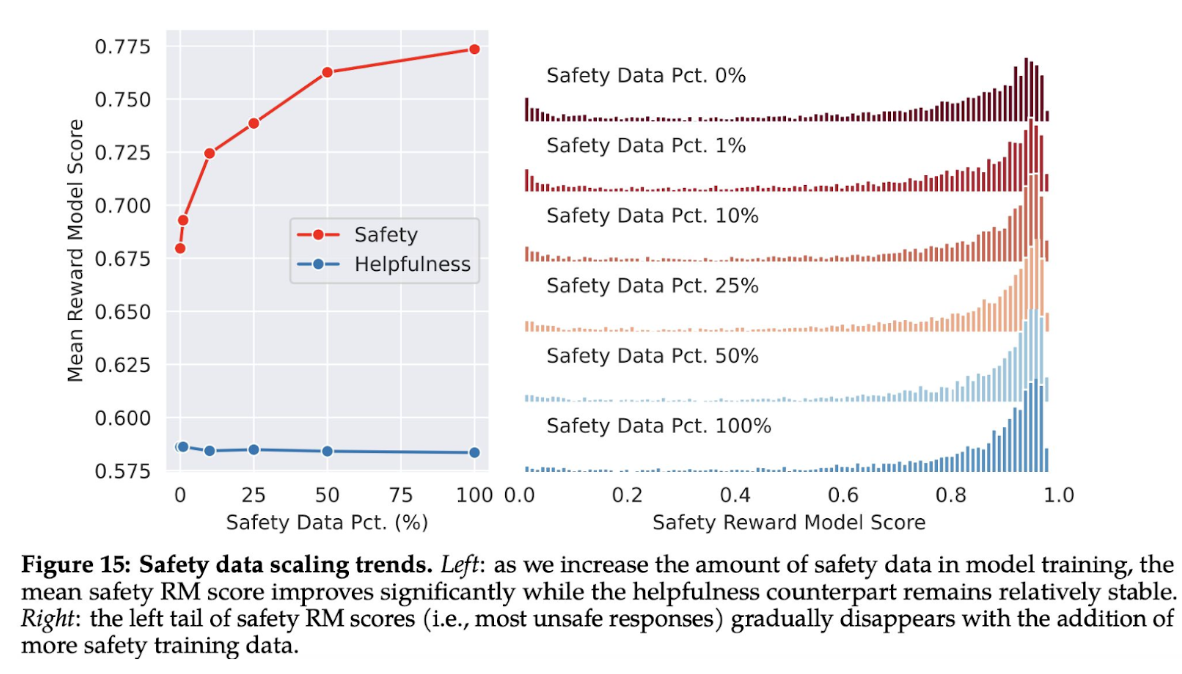
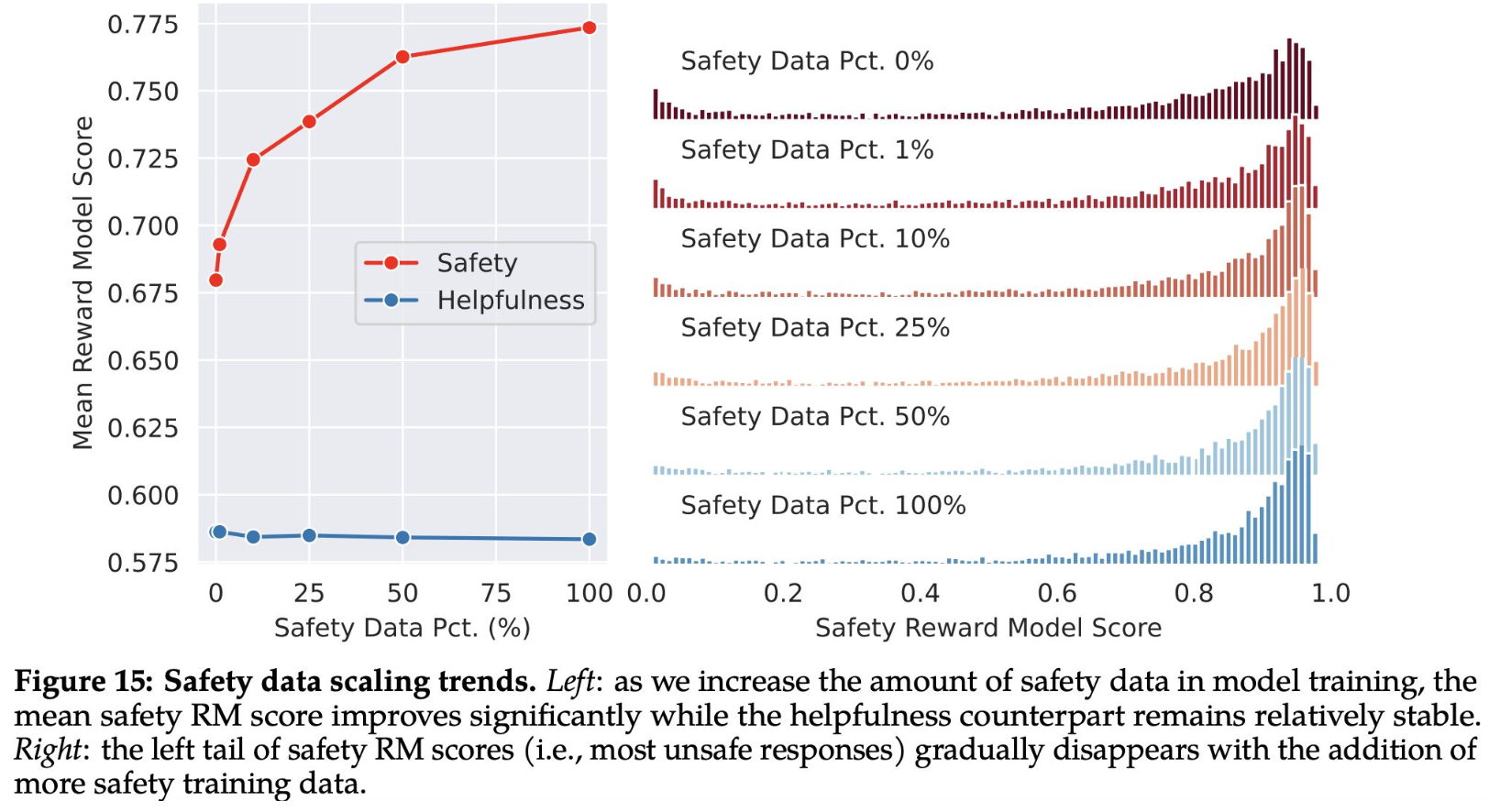
After gathering only a few thousand supervised demonstrations, the authors switched entirely to RLHF to teach the model how to write more nuanced responses. As shown in the following Figure 15, the authors use the mean reward model scores as proxies of model performance on safety and helpfulness. We can observe that when they increase the proportion of safety data, the model’s performance on handling risky and adversarial prompts improves dramatically, and we see a lighter tail in the safety reward model score distribution. Meanwhile, the mean helpfulness score remains constant. They hypothesize that this is because they already have a sufficiently large amount of helpfulness training data. Appendix A.4.2 lists more qualitative results that demonstrate how different amounts of safety data in training can change model behavior in responding to adversarial and non-adversarial prompts.
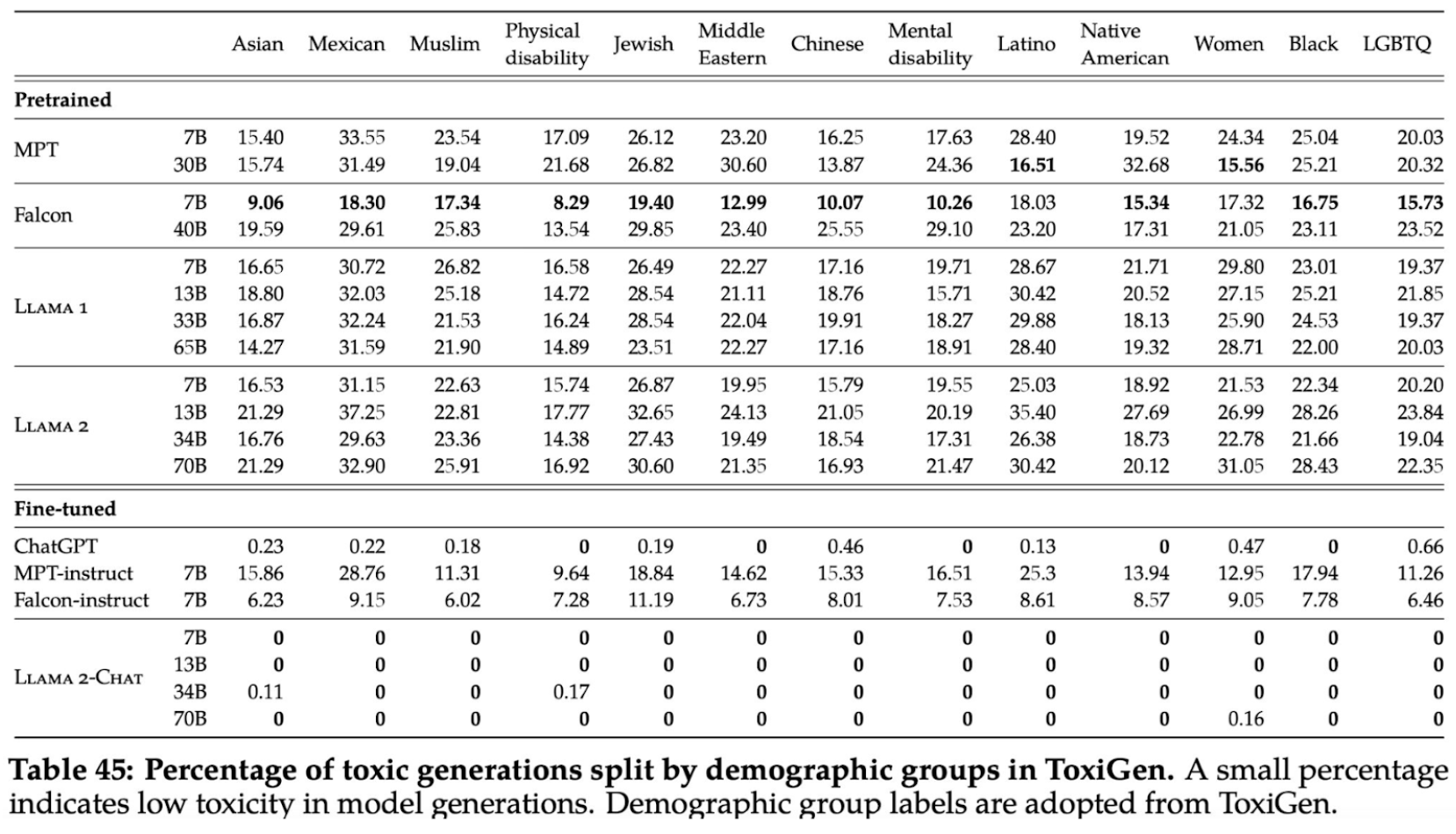
The following image presents results from a safety evaluation for the LLama 2 model, specifically demonstrating the percentages of toxic generations produced by the model across different demographic groups. It shows that pre-trained models generate a higher percentage of toxic outputs, which varies across demographic categories. However, after fine-tuning, the LLama 2-Chat model shows a dramatic reduction in toxicity, with zero or near-zero percentages across all groups. This indicates the effectiveness of fine-tuning in reducing the model’s generation of toxic content and improving its safety regarding different demographics.
Section 6: OLMo: Accelerating the Science of Language Models
Introduction
The success of ChatGPT has demonstrated that large language models have commercial values. The flip side of the commercial success, however, is that its model weights and training procedure becomes proprietary and protected by OpenAI. Therefore, ChatGPT and GPT-4 are also referred as “closed-source models”.
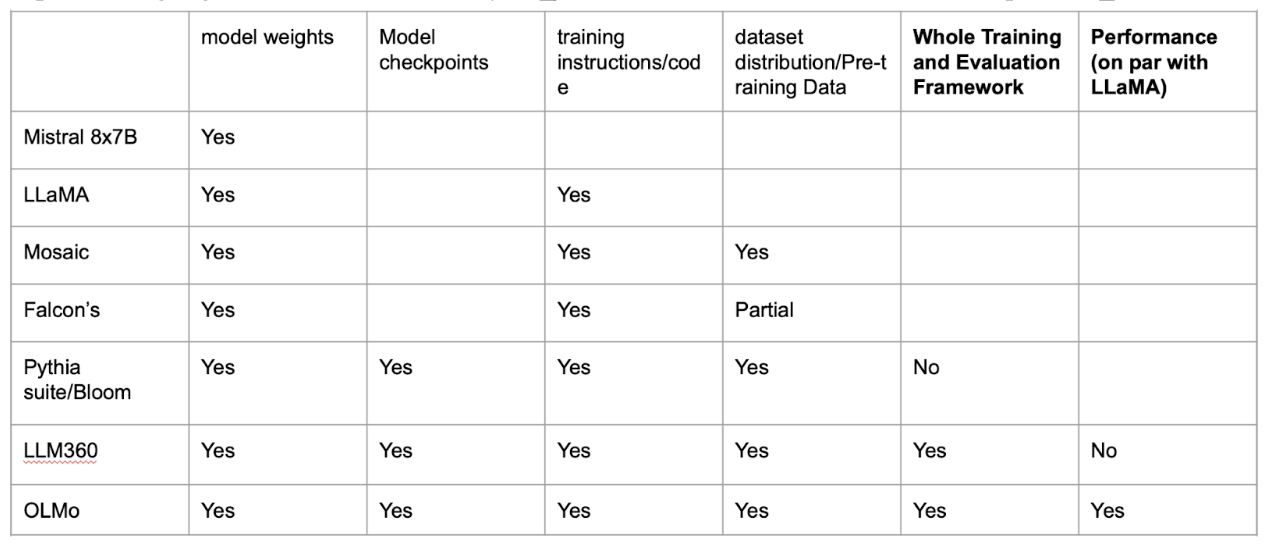
LLaMA is one of the many “open-source models” treated as a foundation by many developers to build AI applications by finetuning its open-sourced model weights. However, for researchers who aim to replicate and improve the foundation large language model or study the science behind it, many aspects of training LLaMA, such as the complete dataset or the model checkpoints, are still not open to the public. Open Language Model (OLMo) addresses this issue by open source the entire training and evaluation framework necessary for training a large language model with performance on par with LLaMA.
As shown in the table below, previous research that open-sourced language models either has some key aspect of the training/evaluation pipeline not disclosed to the public, for example Falcon’s Language Model, or does not have a comparable performance with LLaMA, in the case of LLM360. Open Language Model (OLMo) is the first to open source the whole training/evaluation framework and with the state-of-the-art performance.
Model Architecture
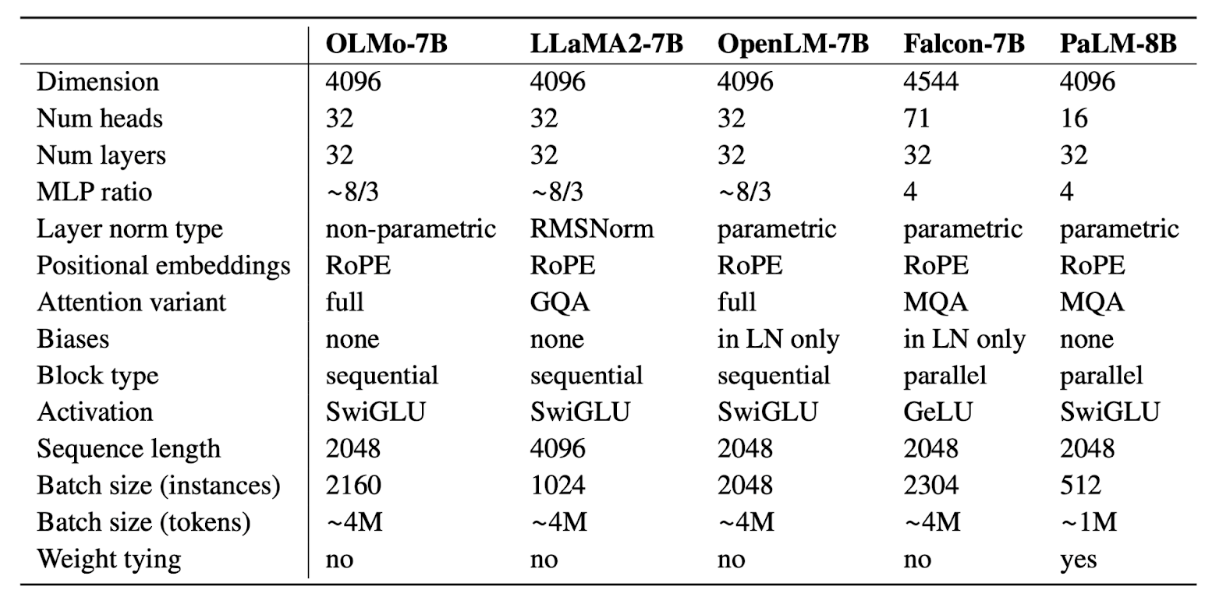
OLMo open sourced three sizes of models: a model with 1 billion parameters, a model with 7 billion parameters, and a model with 65 billion parameters. The 65B model is still under training at the time of writing the paper. The exact architecture is shown in the below table:

A more detailed model architecture for the OLMo-7B model along with the architectures of other 7-8B model are shown in the table below:
Pipeline for Creating the Dataset Dolma
One key aspect that is open sourced by OLMo is the complete dataset for pre-training the large language model. The released dataset is named Dolma and was preprocessed by the following steps:
- language filtering,
- fastText’s language ID model
- Documents with low English score are removed
- quality filtering,
- reimplemented and applied heuristics used in C4 and Gopher
- content filtering,
- Identify content for removal using a fastText classifier trained on Jigsaw Toxic Comments, which contains labeled toxic comments data.
- regular expressions targeting PII (personal identifiable information )
- deduplication,
- mark pages that share the same URL, text or exact paragraphs.
- multi-source mixing
- Tokenization
- GPTNeoX tokenizer
Distributed Training: Hardware
Researchers for OLMo trained the same model twice on two different supercomputers, named LUMI and MosaicML. Training OLMo in LUMI utilized 1024 AMD MI250X GPUs and training the same model on MosaicML utilized 216 NVIDIA A100 GPUs. More details to the supercomputer setup is listed below:
- LUMI supercomputer
- 256 nodes
- Each node consists of 4x AMD MI250X GPUs
- 128GB of memory
- 800Gbps of interconnect
- MosaicML
- 27 nodes
- each node consists of 8x NVIDIA A100 GPUs
- 40GB of memory
- 800Gbps interconnect
Optimizer
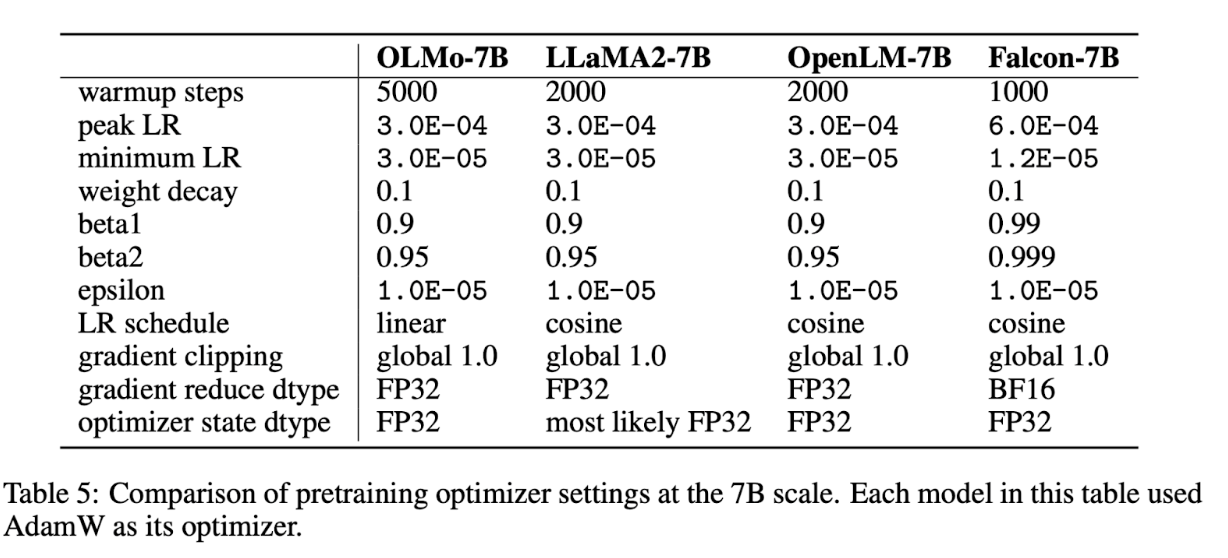
To ensure a better memory efficiency for training OLMo, a ZeRO optimizer strategy via yTorch’s FSDP (Fully Sharded Data Parallel) framework is employed. The specific optimizer setting at the 7B scale is shown in the table below.
Evaluation
As demonstrated in the table and figure below, OLMo achieves performance comparable to other state-of-the-art language models both in terms of common sense reasoning and intrinsic evaluation by Paloma.
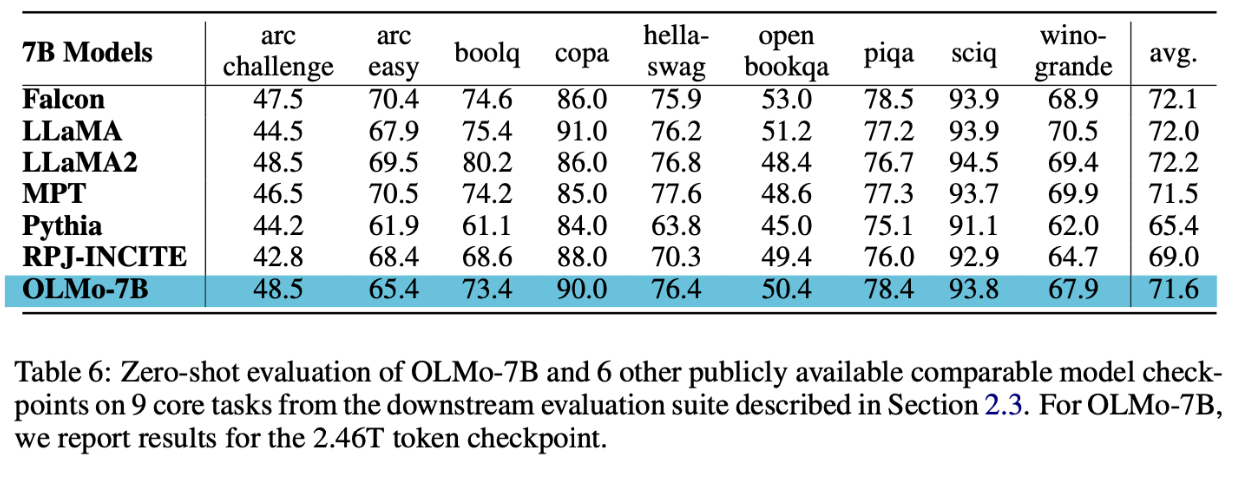
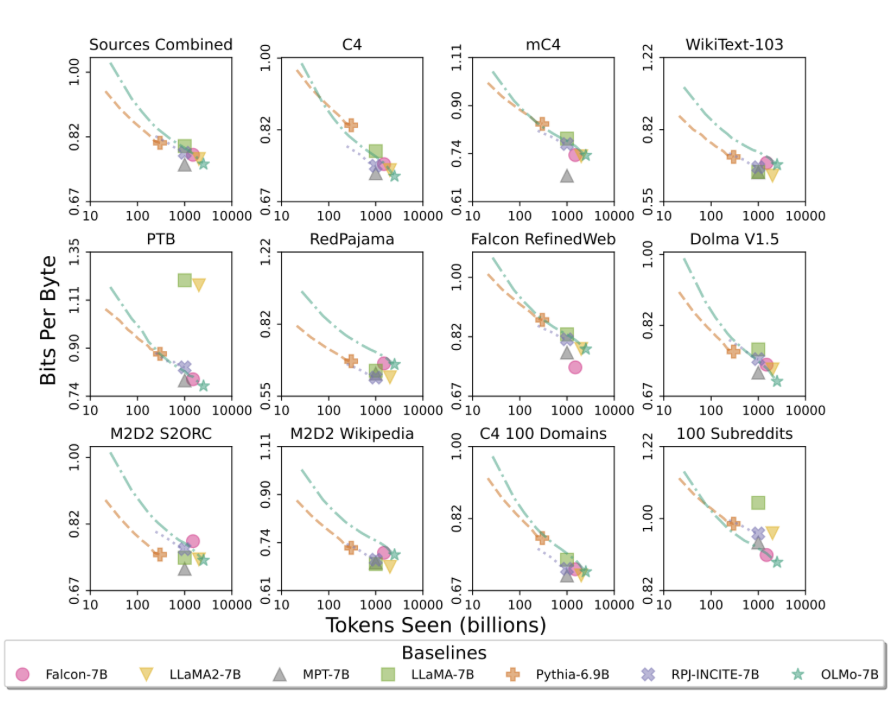
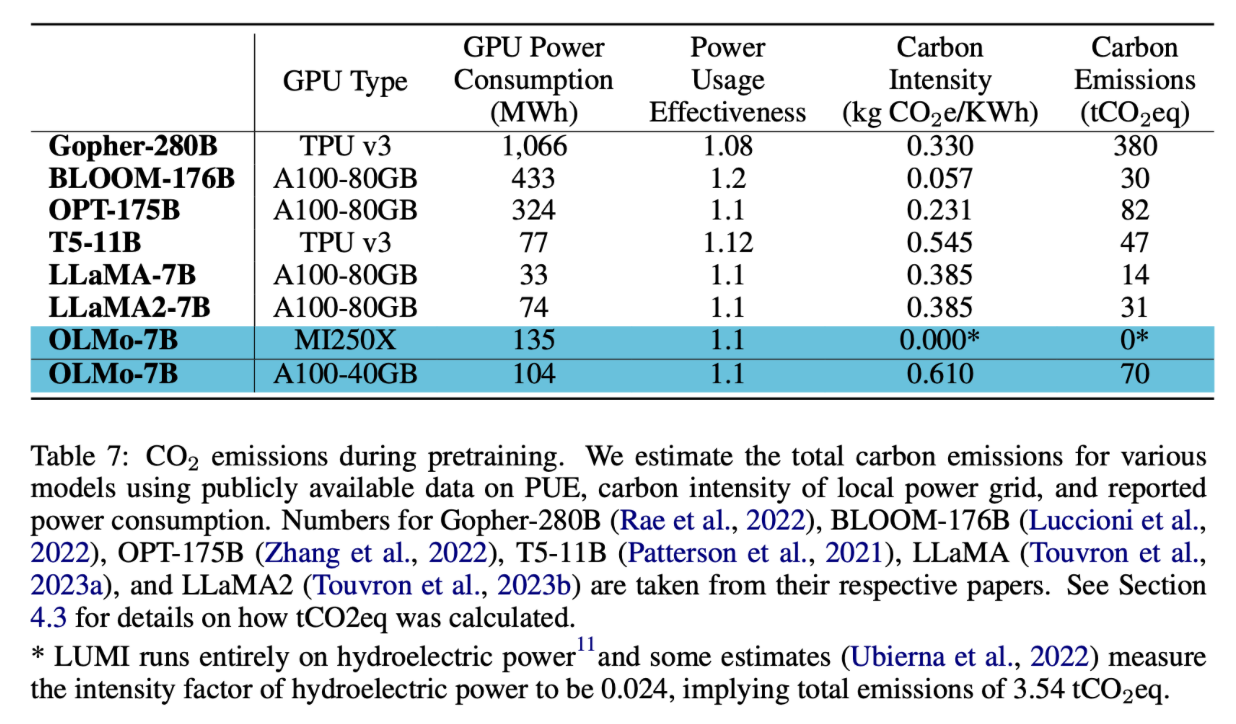
Finally, the paper also shows the carbon emission of training OLMo, with a slightly larger GPU Power consumption compared to training LLaMA2. Since LUMI supercomputer runs on clean energy, the carbon emission is considered 0.
Paper E. Llama 2: Open Foundation and Fine-Tuned Chat Models
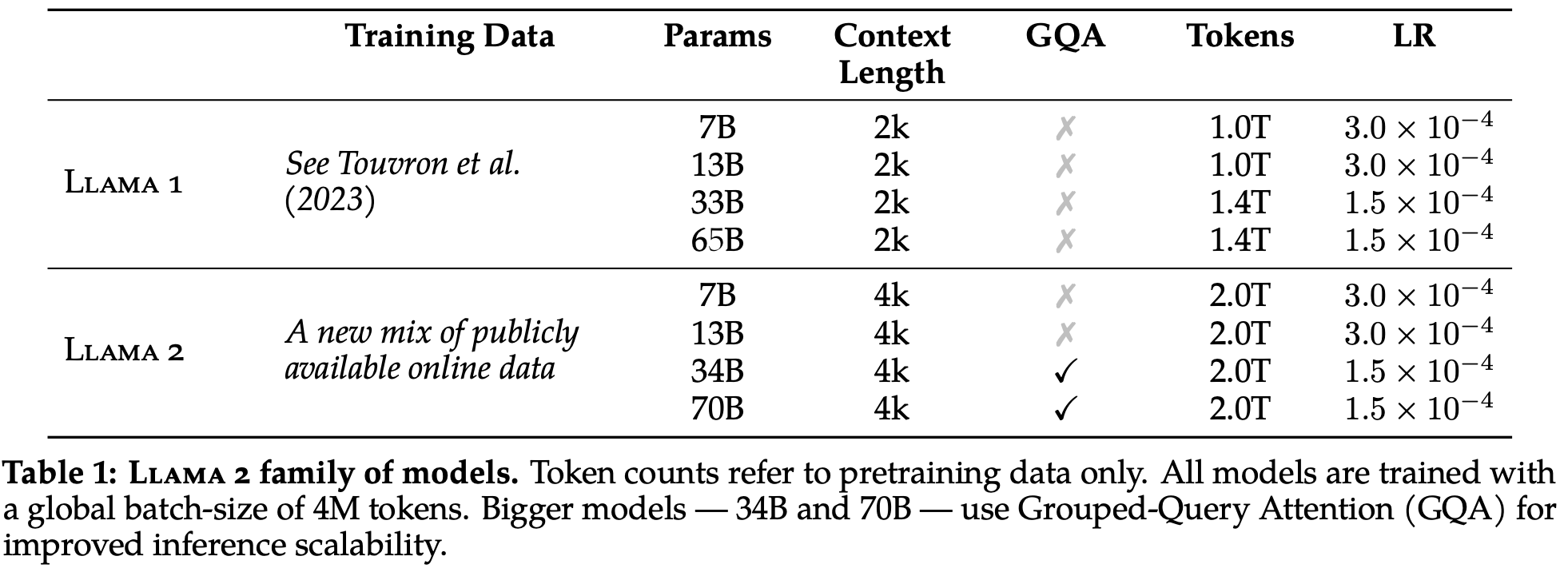
E.1 Pre-training methodology
To create the new family of Llama 2 models, the authors used an optimized auto-regressive transformer but made several changes to improve performance.
Specifically, they performed more robust data cleaning, updated data mixes, trained on 40% more total tokens, doubled the context length, and used grouped-query attention (GQA) to improve inference scalability for larger models.
E.2 Training Details
- Adopt most of the pretraining setting and model architecture from Llama 1:
- use the standard transformer architecture
- apply pre-normalization using RMSNorm
- use the SwiGLU activation function
- use rotary positional embeddings (RoPE)
- Primary architectural differences:
- increased context length
- grouped-query attention (GQA)
E.3 Llama 2: Rotary Positional Embeddings (RoPE)
An enhancement to the traditional position encoding used in transformer models. RoPE dynamically encodes the position information by rotating the query and key vectors in the attention mechanism.
Problems in prior methods:
- Absolute positional encoding is simple, but may not generalize well in longer sequences.
- Relative positional bias (T5) is not efficient. Solution:
- Apply rotation to word vector to encode rotation.
- Maintain both absolute and relative positional embeddings in an input sentence.
- We do not need to train custom parameters.
E.4 Llama 2: Grouped-query Attention (GQA)
- 34B and 70B models used GQA for improved inference scalability.
Pre-trained Results
- After pretraining, results are not as good as other proprietary, closed-source models. (GPT-4 and PaLM-2-L.)
- Llama-2 is still very competitive (only a pre-trained model)
E.4 Fine-tuning methodology
Llama 2: Iterative Fine-Tuning
- Rejection Sampling: Sample K outputs from the model, select the best candidate based on the reward model
- Can be combined with PPO
- Generating multiple samples in this manner can drastically increase the maximum reward of a sample.
Llama 2: Ghost Attention (GAtt)
Llama 2: Fine-Tuning Results
Report the progress of our different SFT and then RLHF versions for both Safety and Helpfulness axes, measured by our in-house Safety and Helpfulness reward models.
E.5 Model Safety
Llama 2: Safety in Fine-Tuning: Adversarial Samples
- Gather adversarial prompts and safe demonstrations in the SFT training set.
- Essentially probes for edge cases.
- Annotator writes both the prompt and the response in adversarial samples.

Llama 2: Safety in RLHF
RLHF safety measures:
- Safety RM uses human preference data to train.
- Reuse the adversarial prompts when training safety RM.
Helpfulness remains intact after safety tuning with RLHF.
Llama 2: Safety Evaluation
The fine-tuned versions of LLama 2-Chat, show virtually zero toxicity across all groups.
- The effectiveness of fine-tuning in mitigating model-generated toxicity.