FM copyright infrigement
- SlideDeck: W5-FM-copyright-infrigement
- Version: current
- Lead team: team-6
- Blog team: team-5
In this session, our readings cover:
Required Readings:
Foundation Models and Fair Use
- Peter Henderson, Xuechen Li, Dan Jurafsky, Tatsunori Hashimoto, Mark A. Lemley, Percy Liang
- URL
- Existing foundation models are trained on copyrighted material. Deploying these models can pose both legal and ethical risks when data creators fail to receive appropriate attribution or compensation. In the United States and several other countries, copyrighted content may be used to build foundation models without incurring liability due to the fair use doctrine. However, there is a caveat: If the model produces output that is similar to copyrighted data, particularly in scenarios that affect the market of that data, fair use may no longer apply to the output of the model. In this work, we emphasize that fair use is not guaranteed, and additional work may be necessary to keep model development and deployment squarely in the realm of fair use. First, we survey the potential risks of developing and deploying foundation models based on copyrighted content. We review relevant U.S. case law, drawing parallels to existing and potential applications for generating text, source code, and visual art. Experiments confirm that popular foundation models can generate content considerably similar to copyrighted material. Second, we discuss technical mitigations that can help foundation models stay in line with fair use. We argue that more research is needed to align mitigation strategies with the current state of the law. Lastly, we suggest that the law and technical mitigations should co-evolve. For example, coupled with other policy mechanisms, the law could more explicitly consider safe harbors when strong technical tools are used to mitigate infringement harms. This co-evolution may help strike a balance between intellectual property and innovation, which speaks to the original goal of fair use. But we emphasize that the strategies we describe here are not a panacea and more work is needed to develop policies that address the potential harms of foundation models.
Extracting Training Data from Diffusion Models
- Nicholas Carlini, Jamie Hayes, Milad Nasr, Matthew Jagielski, Vikash Sehwag, Florian Tramèr, Borja Balle, Daphne Ippolito, Eric Wallace
- Image diffusion models such as DALL-E 2, Imagen, and Stable Diffusion have attracted significant attention due to their ability to generate high-quality synthetic images. In this work, we show that diffusion models memorize individual images from their training data and emit them at generation time. With a generate-and-filter pipeline, we extract over a thousand training examples from state-of-the-art models, ranging from photographs of individual people to trademarked company logos. We also train hundreds of diffusion models in various settings to analyze how different modeling and data decisions affect privacy. Overall, our results show that diffusion models are much less private than prior generative models such as GANs, and that mitigating these vulnerabilities may require new advances in privacy-preserving training.
A Comprehensive Survey of AI-Generated Content (AIGC): A History of Generative AI from GAN to ChatGPT
- https://arxiv.org/abs/2303.04226
- Recently, ChatGPT, along with DALL-E-2 and Codex,has been gaining significant attention from society. As a result, many individuals have become interested in related resources and are seeking to uncover the background and secrets behind its impressive performance. In fact, ChatGPT and other Generative AI (GAI) techniques belong to the category of Artificial Intelligence Generated Content (AIGC), which involves the creation of digital content, such as images, music, and natural language, through AI models. The goal of AIGC is to make the content creation process more efficient and accessible, allowing for the production of high-quality content at a faster pace. AIGC is achieved by extracting and understanding intent information from instructions provided by human, and generating the content according to its knowledge and the intent information. In recent years, large-scale models have become increasingly important in AIGC as they provide better intent extraction and thus, improved generation results. With the growth of data and the size of the models, the distribution that the model can learn becomes more comprehensive and closer to reality, leading to more realistic and high-quality content generation. This survey provides a comprehensive review on the history of generative models, and basic components, recent advances in AIGC from unimodal interaction and multimodal interaction. From the perspective of unimodality, we introduce the generation tasks and relative models of text and image. From the perspective of multimodality, we introduce the cross-application between the modalities mentioned above. Finally, we discuss the existing open problems and future challenges in AIGC.
More Readings:
Audio Deepfake Detection: A Survey
- https://arxiv.org/abs/2308.14970
- Audio deepfake detection is an emerging active topic. A growing number of literatures have aimed to study deepfake detection algorithms and achieved effective performance, the problem of which is far from being solved. Although there are some review literatures, there has been no comprehensive survey that provides researchers with a systematic overview of these developments with a unified evaluation. Accordingly, in this survey paper, we first highlight the key differences across various types of deepfake audio, then outline and analyse competitions, datasets, features, classifications, and evaluation of state-of-the-art approaches. For each aspect, the basic techniques, advanced developments and major challenges are discussed. In addition, we perform a unified comparison of representative features and classifiers on ASVspoof 2021, ADD 2023 and In-the-Wild datasets for audio deepfake detection, respectively. The survey shows that future research should address the lack of large scale datasets in the wild, poor generalization of existing detection methods to unknown fake attacks, as well as interpretability of detection results.
Copyright Plug-in Market for The Text-to-Image Copyright Protection
- https://openreview.net/forum?id=pSf8rrn49H
- The images generated by text-to-image models could be accused of the copyright infringement, which has aroused heated debate among AI developers, content creators, legislation department and judicature department. Especially, the state-of-the-art text-to-image models are capable of generating extremely high-quality works while at the same time lack the ability to attribute credits to the original creators, which brings anxiety to the artists’ community. In this paper, we propose a conceptual framework – copyright Plug-in Market – to address the tension between the users, the content creators and the generative models. We introduce three operations in the \copyright Plug-in Market: addition, extraction and combination to facilitate proper credit attribution in the text-to-image procedure and enable the digital copyright protection. For the addition operation, we train a \copyright plug-in for a specific copyrighted concept and add it to the generative model and then we are able to generate new images with the copyrighted concept, which abstract existing solutions of portable LoRAs. We further introduce the extraction operation to enable content creators to claim copyrighted concept from infringing generative models and the combination operation to enable users to combine different \copyright plug-ins to generate images with multiple copyrighted concepts. We believe these basic operations give good incentives to each participant in the market, and enable enough flexibility to thrive the market. Technically, we innovate an inverse LoRA’’ approach to instantiate the extraction operation and propose a data-ignorant layer-wise distillation’’ approach to combine the multiple extractions or additions easily. To showcase the diverse capabilities of copyright plug-ins, we conducted experiments in two domains: style transfer and cartoon IP recreation. The results demonstrate that copyright plug-ins can effectively accomplish copyright extraction and combination, providing a valuable copyright protection solution for the era of generative AIs.
Membership Inference Attacks against Language Models via Neighbourhood Comparison
https://aclanthology.org/2023.findings-acl.719/
Deepfake Taylor Swift event:
- https://www.cbsnews.com/news/taylor-swift-artificial-intellignence-ai-4chan/
Blog:
In this session, our blog covers papers related to foundation models copyright infringement, founding over five-fold topics.
- Foundation Models and Fair Use
- Copyright Plug-in Market for The Text-to-Image Copyright Protection
- Extracting Training Data from Diffusion Models
Paper A. Foundation Models and Fair Use
A.1 Objectives and Motivations
- Existing foundation models are trained on copyrighted material
- Deploying these models can pose both legal and ethical risks
- If the model produces output that is similar to copyrighted data, fair use may no longer apply to the output of the model
The authors emphasize that fair use is not guaranteed, and additional work may be necessary to keep model development and deployment squarely in the realm of fair use.
- Survey the potential risks of developing and deploying foundation models based on copyrighted content.
- Experiments confirm that popular foundation models can generate content considerably similar to copyrighted material
- Discuss technical mitigations that can help foundation models stay in line with fair use
- more research is needed to align mitigation strategies with the current state of the law
- Suggest that the law and technical mitigations should co-evolve
A.2 Fair Use
Foundation models are machine learning models trained on broad data (typically scraped from the internet) generally using self-supervision at scale (Bommasani et al., 2021).
Foundation models are expanded into more products, deployments will only scale to more and more users.

Fair Use Defense
- Data creator
- Creates content that might be used for GenAI training.
- Whose copyright may be violated?
- May sue Tech Company who deploys GenAI
- Tech Company When Tech Companies that deploy GenAI are sued for copyright violation, they can use the Fair Use Defense to not get charged.
Four “Arguments” Tech Company Can Use for Defense If the use of unlicensed copyrighted materials, then such use is legal:
- satisfy transformativeness
- (Nature of the work) Is factual vs creative
- the amount of the portion used is small
- has little effect on the market of the copyrighted materials
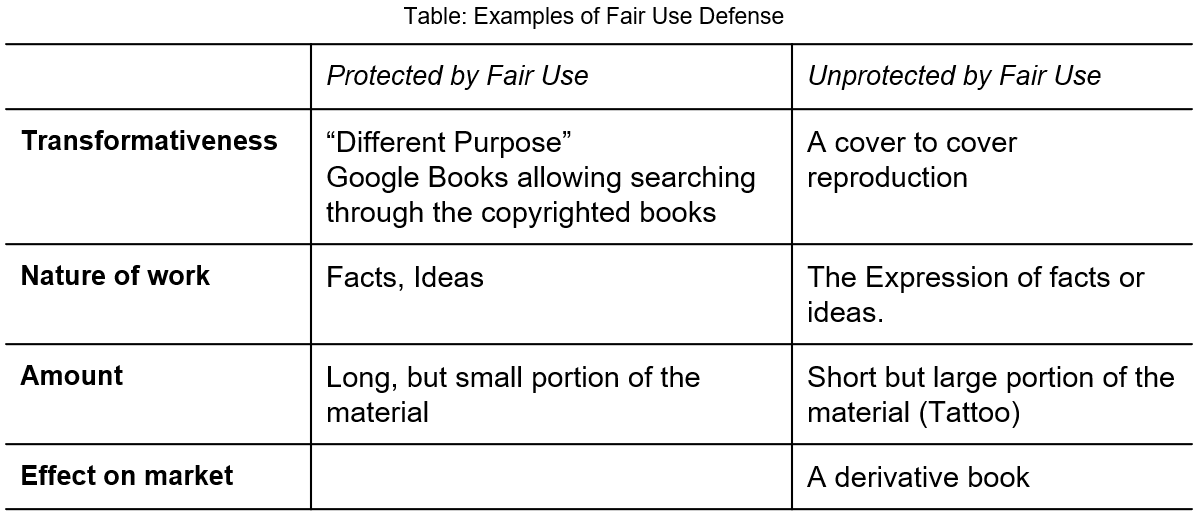
Natural Language Text - Examples of Fair Use Defense
Examined relevant cases that might help shape what is considered fair use for these models, some of which can be seen in Figure 1.
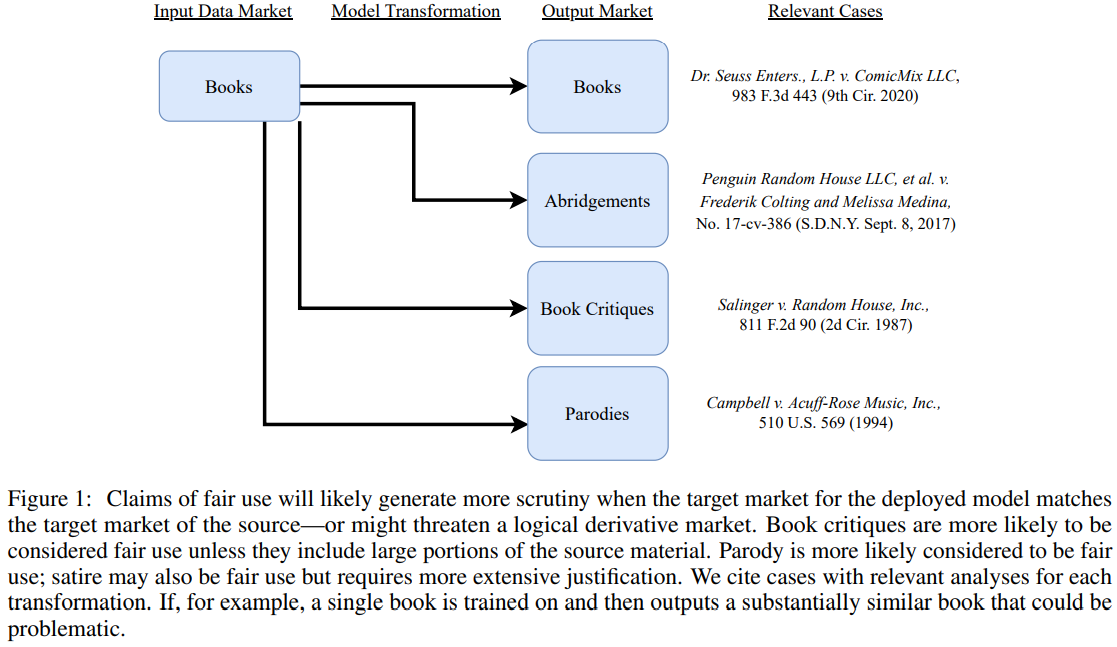
- how a generative foundation model trained on books might be used to produce different types of outputs and what cases might illustrate similar situations.
- these cases help us outline the level of the transformation necessary to stay within the current confines of fair use doctrine
Text generation: One of the most prevalent, and earliest, use-cases of foundation models, like GPT.
Applications: Copy-editing, text-based games, and general-purpose chatbots.
Training data sources: internet, books, court documents.
Fair Use Considerations:
- The role of transformation in determining fair use.
- Examination of relevant cases paralleling foundation model outputs.
Verbatim Copying and Hypotheticals:
- Google Books case: Limited content provision as fair use.
- Hypothetical scenario: Virtual assistant reading books aloud.
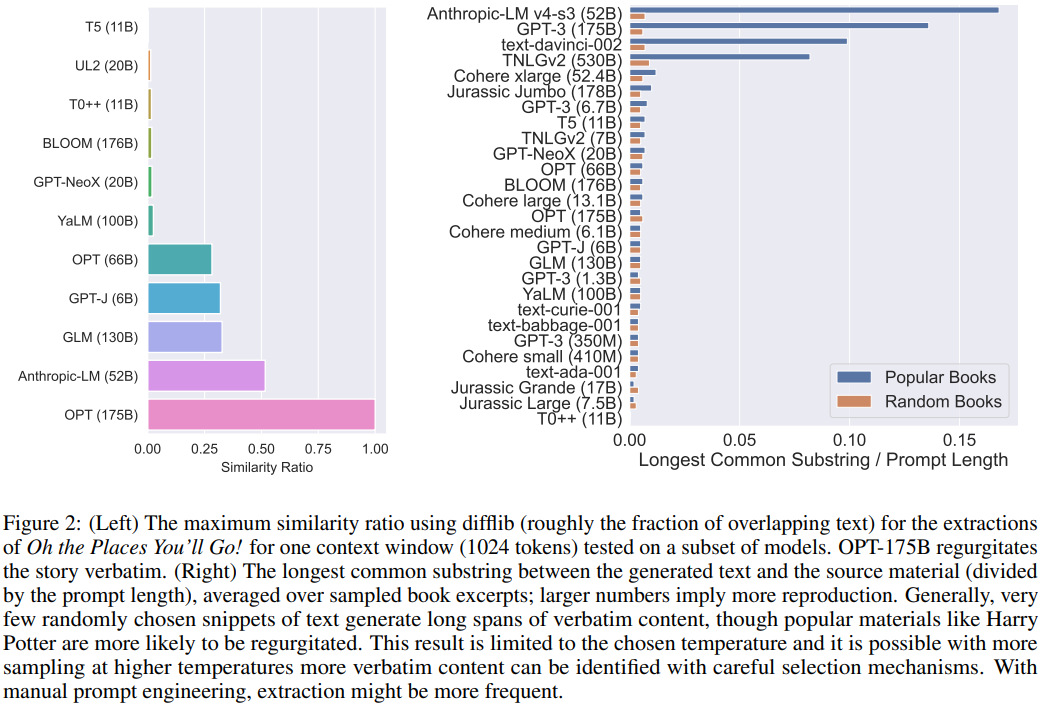
- Under such a low-temperature regime, many models generate repetitive low-quality content and extraction rates are low, generally only generating small amounts of verbatim text, as seen in Figure 2.
- Nonetheless, certain types of content yield greater extraction even with little manual prompt engineering
Implications for Foundation Models:
- The thin line between transformative use and copyright infringement.
- The importance of model output transformation for fair use defense.
Challenges in Determining Fair Use:
- Difficulty in applying fair use to verbatim and minimally transformed outputs.
- The significance of the amount and substantiality of the used portion.
Strategies for Compliance:
- Enhancing model outputs for greater transformation.
- Legal and technical strategies to align with fair use doctrine.
Code - Examples of Fair Use Defense
Natural language text and code generation models have similar training processes, in fair use assessments, they have each different case law with slightly varied assessments.
Literal vs. Non-literal Infringement:
- Literal infringement (verbatim copying) unlikely to be fair use, especially for significant portions of the code.
- Introduction of tests for non-literal infringement: Abstraction-Filtration-Comparison and SSO tests, focusing on copyrightable, expressive aspects of code (e.g., inter-modular relationships).
Challenges in Non-literal Copyright:
- Judges acknowledge unclear boundaries for non-literal program structure copyright protection.
- Difficulty in proving nonliteral infringement due to protection limitations on non-expressive, functional elements of programs.
Criteria for Fair Use in Code:
- Small amounts of copied code, significant transformation, or different overall products may indicate fair use.
- The importance of transforming generated content to reduce infringement risk.
Copyright Protection Limitations:
- Functional aspects of code have limited copyright protection compared to creative works.
- Encouragement for transformation in generated software to minimize legal risks.
Additional Concerns in Code Generation:
- Potential right of publicity issues with verbatim output of usernames.
- DMCA §1202 and right of publicity considerations for transformative works.
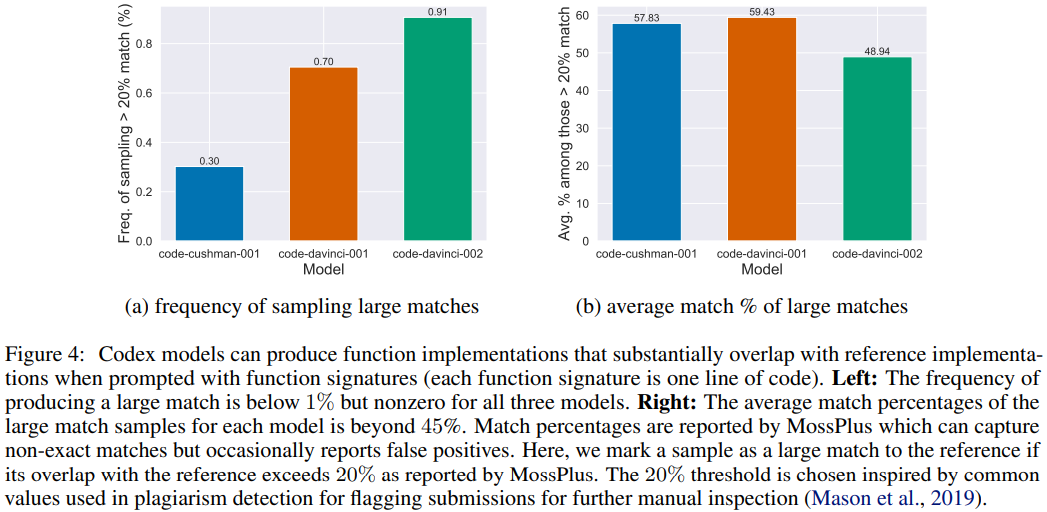
Figure 4 shows that models can generate function implementations that substantially overlap with reference implementations
Generated Images - Examples of Fair Use Defense
The third commonly produced category of generative AI is image generation.
Complexities of fair use with images. -> Hypothetical 2.5: Generate Me Video-Game Assets.
While fair use might offer some defense, the direct appropriation of artists’ work with only slight alterations poses a significant legal risk for the company, indicating that their use might not qualify as fair use.

The third commonly produced category of generative AI is image generation.
Style Transfer
More abstract scenarios, where art is generated in different styles. Three components to consider:
- The rights of the original image that is being transformed into a different style.
- The rights of the artist whose style is being mimicked.
- Other intellectual property considerations with images: the right to publicity and trademark infringement.
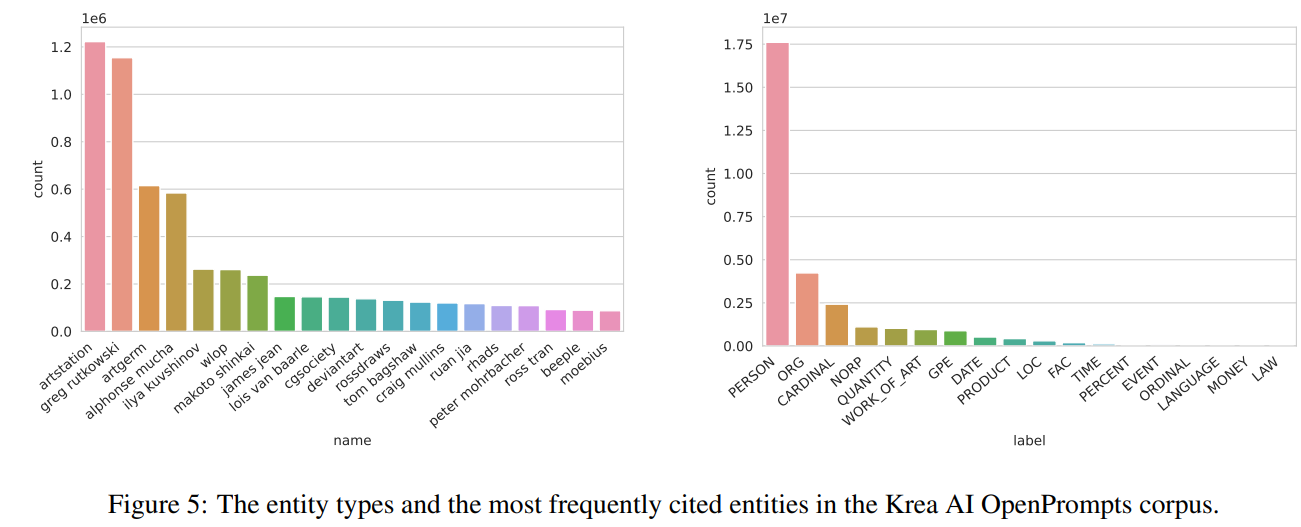
- As seen in Figure 5, we find that the most common named entity type used in prompts are people’s names, including the names of artists like Greg Rutokowski, who is referenced 1.2M times.
- This suggests that users in this community often try to generate images in particular artist styles, which is more likely to be fair use as long as the content itself is sufficiently transformative
A.3 Technical Mitigation
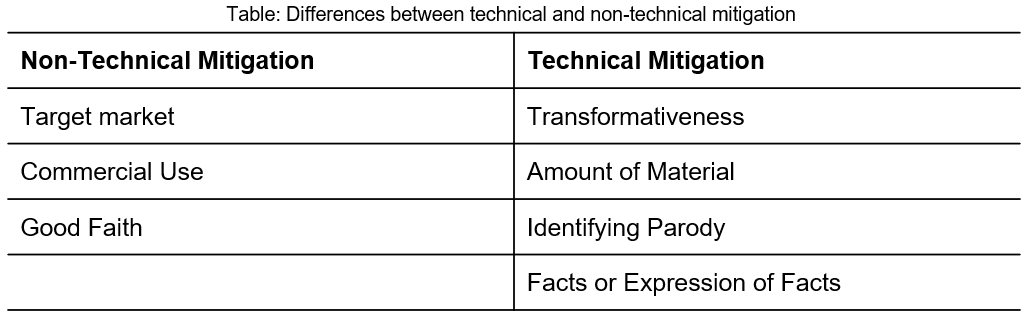
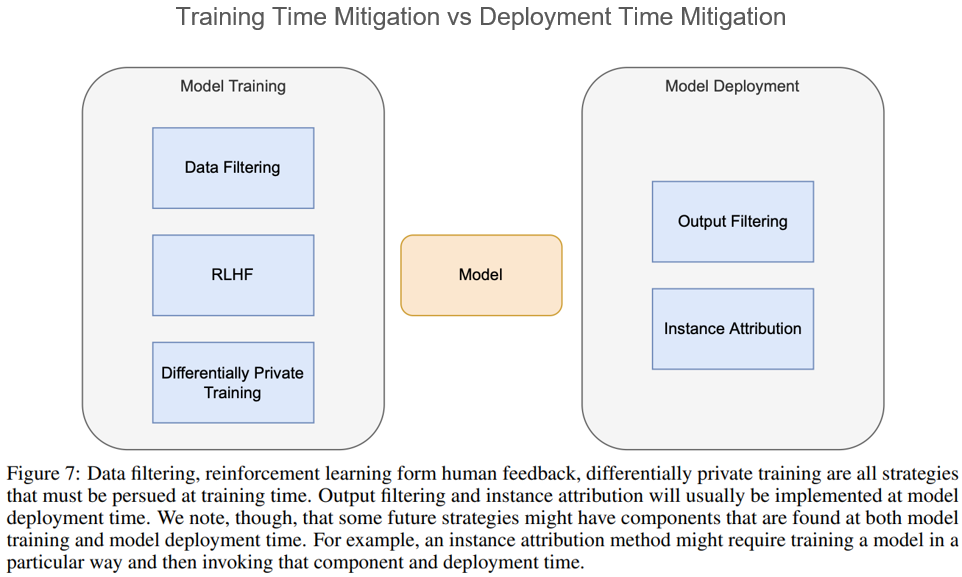
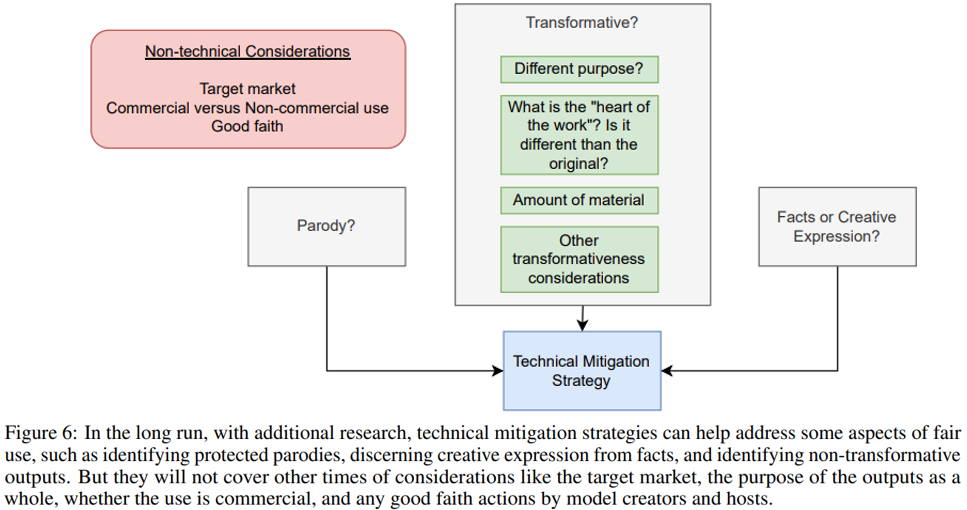
A.3.1 Data Filtering
Two Types of Data Filtering
- Not train on dataset.
- E.g. AlphaCode only trained on unlicensed Github source code
- Restrict to robot.txt for webcrawled data
- Deduplication to reduce memorization
- Problematic: Given different images of an NBA player, a tattoo may still be memorized.
A.3.2 Output Filtering
Apply a filter to detect output similar to training data, e.g. Github Copilot
Disadvantages of Current Output Filters
- Additional inference costs
- Easily bypassed by minor style-transfer
Future direction: An output filter that detects high-level semantic similarity?
A.3.3 Instance Attribution
Instance attribution refers to methods that assign attribution scores to training examples to understand the contribution of individual examples (or groups of examples) to (test-time) model predictions (Koh & Liang, 2017; Ghorbani & Zou, 2019; Jia et al., 2019; Pezeshkpour et al., 2021; Ilyas et al., 2022) One application of instance attribution is in determining the source of a generated output.
Instance attribution can also address the credit assignment problem by providing a clear attribution page that lists all works that contributed to the output, along with licensing information, to comply with Creative Commons license attribution guidelines
While promising, current techniques in instance attribution tend to suffer from difficulties in scaling due to high computational cost (e.g., leave-k-out retraining can be costly) (Feldman & Zhang, 2020; Zhang et al., 2021) or being inaccurate or erroneous when applied to complex but realistic model classes (Basu et al., 2020; Ghorbani et al., 2019; Søgaard et al., 2021).
Disadvantage:
- High Computation costs (leave one out retraining or inverting Hessian) Alternatives:
- Retrieval Augmented Methods
It naturally selects the instance before inferencing
A.3.4 Differentially Private Training
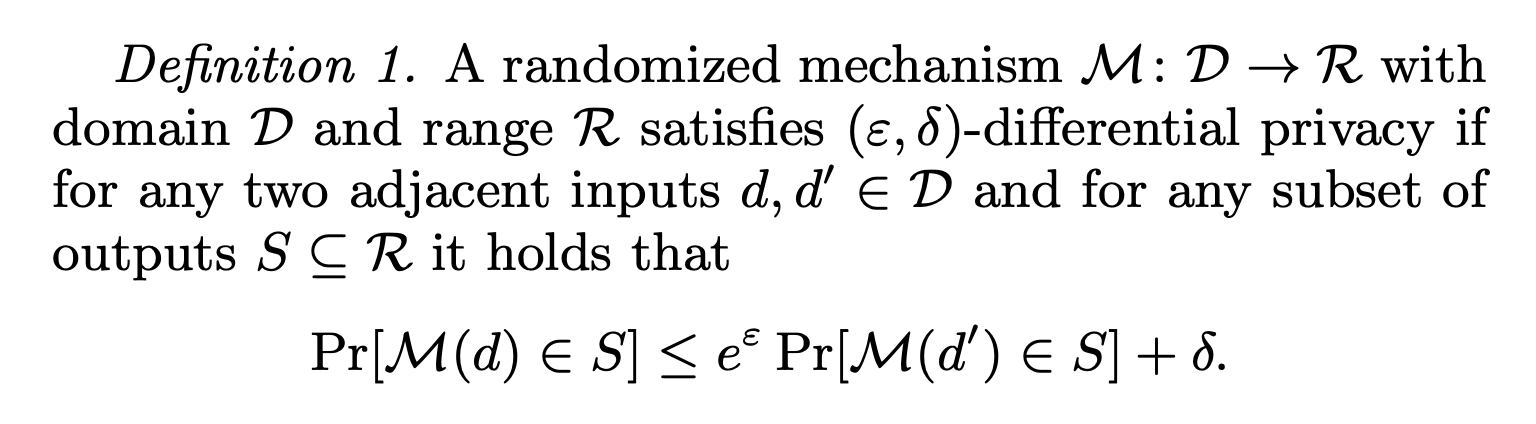
For example:
In DP-SGD, noise is added to the gradient, and the output of such randomized mechanisms would be parameters and proved to have DP guarantee. Benefits in Fair Use: DP-trained models are naturally less likely to memorize a single instance.
Challenges in Fair Use:
- High computation costs
- Trade off between privacy and accuracy
- Similar examples to the single example removed

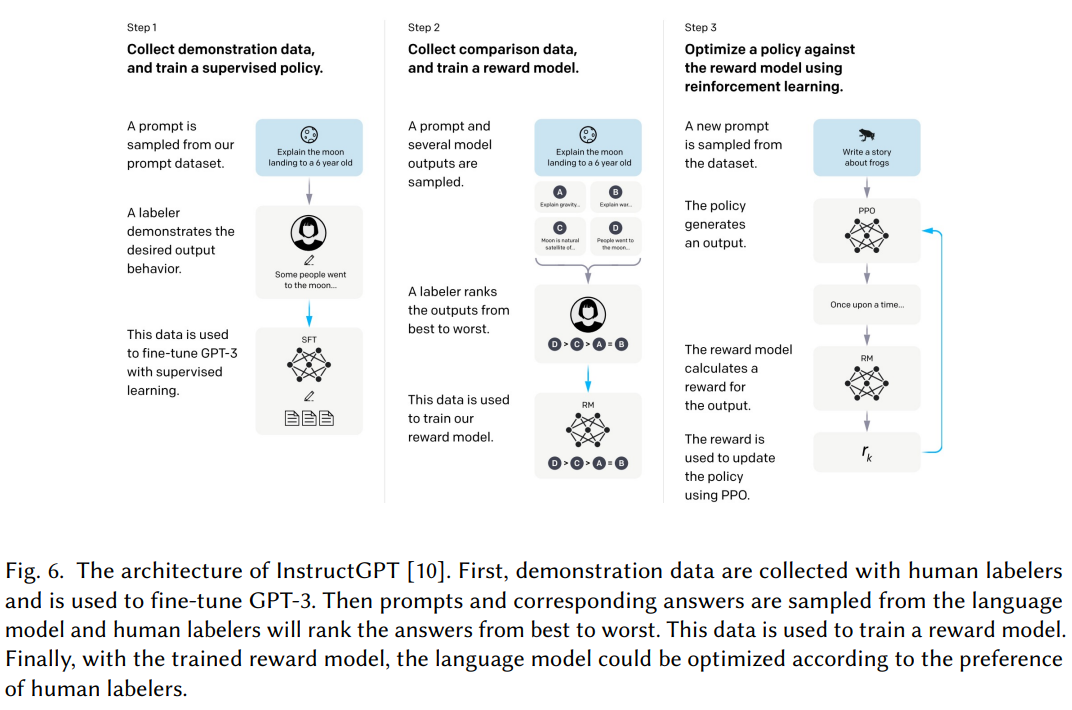
A.3.5 Learning from human feedback
Learning from human feedback (Ouyang et al., 2022) trains models to generate outputs that are aligned with human preferences and values.
For Human Annotations,
- Provide the closest copyrighted content to the LLM output
- Ask to flag outputs that are not transformative enough.
These approaches—and similar ones aimed at promoting helpfulness (Wei et al., 2021; Sanh et al., 2021)—should also consider the copyright risk.
To address this issue, human annotation frameworks in these approaches can take into account the copyright implications of rating systems and instruction following, particularly when incorporating human feedback at scale.
A.4 Forward Looking Agenda
The risk of copyright violation and litigation, even with fair use protection, is a real concern.
To mitigate these risks, the authors recommend that foundation model practitioners consider implementing the mitigation strategies outlined here and pursuing other novel research in this area.
Preventing extreme outcomes in the evolution of fair use law by advancing mitigation strategies: Advancing research in this area (with methods such as improved similarity metrics) may help in preventing extreme outcomes in legal settings.
We should not over-zealously filter: evolutions of fair use doctrine or further policymaking should consider the distributive effects of preventing access to certain types of data for model creation.
Policymakers could consider how and if DMCA (or similar) safe harbors should apply to foundation models: With the uncertainty of DMCA protections, the law may need to adapt to this reality, and it could do so, for instance, by clarifying the role of safe harbors for models that implement sufficiently strong mitigation strategies Pursuing other remedies beyond technical mitigation: Importantly, even if technical mitigation strategies managed to keep foundation models within the confines of fair use, these models may still create harm in many other ways— including disrupting creative industries, exploiting labor, and more
Paper B. PLUG-IN MARKET FOR THE TEXT-TO-IMAGE COPYRIGHT PROTECTION
B.1 Motivation and Impact
whether the copyright laws prohibit using copyrighted data to train machine learning models
- Debate between AI developers, content creators, legislation & judicature department
-
It’s ok to use for “fair use”, but can we say training procedure is “fair use”
- LLM keeps improving the quality of generated images (Diffusion Model)
- But it cannot attribute credits to the original data in the training set
- Adding anxiety to the artist community
- Replicate characters from major IP ( Disney’s Mickey Mouse, /2024sp-GenAI-Risk-Benefits/)
A little bit of Background

B.2 Plug-ing Market
- Motivated by the copyright law: reward creators for their work
- Crediting and sharing revenue with the creator
- Decode generated image into similar example, so that can credit its original creditors
- Propose a conceptual framework named @Plug-in Market
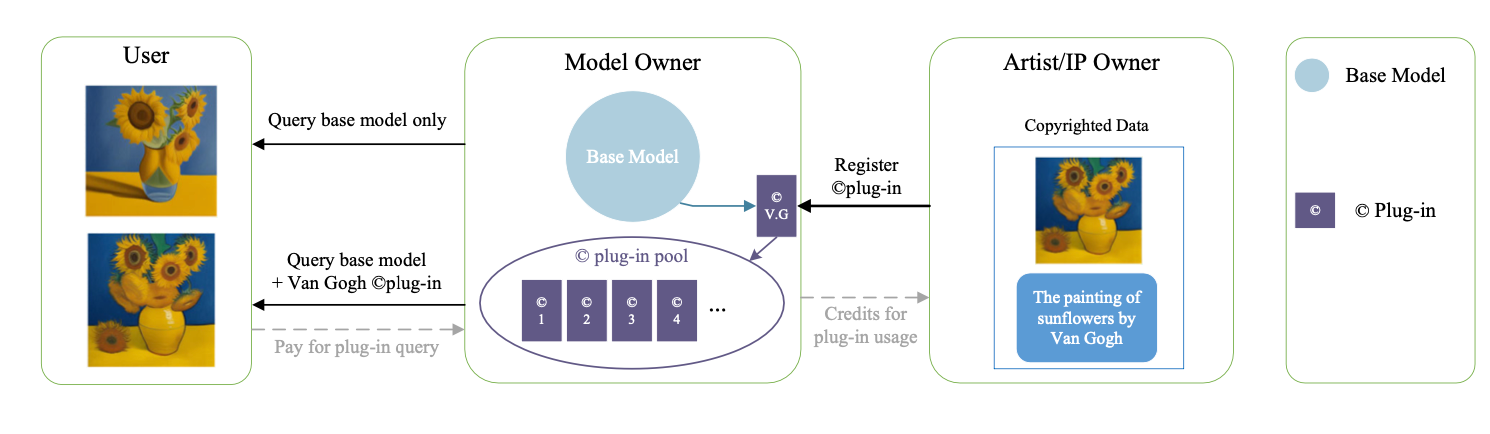
- Model owner (OpenAI) acts as a platform
- Artist/IP owner: register copyright data as a “Plug-in”
- Query base model: not affiliate with the creator
- Query base model with “Plug-in”: credit to the creator, the user pays for query
Within this structure, all involved parties reap advantages. Copyright holders receive fair compensation for their creative efforts, and end users pay for the utilization of copyrighted plug-ins, safeguarding themselves from copyright infringement accusations in their own creations. Meanwhile, the owner of the base model earns profits through plug-in registration and usage.
Furthermore, the market can transparently monitor the usage of copyrighted works, ensuring a fair and straightforward reward system. A thriving market aligns providers with demanders, ultimately benefiting overall societal welfare.
Plug-in Market Operations
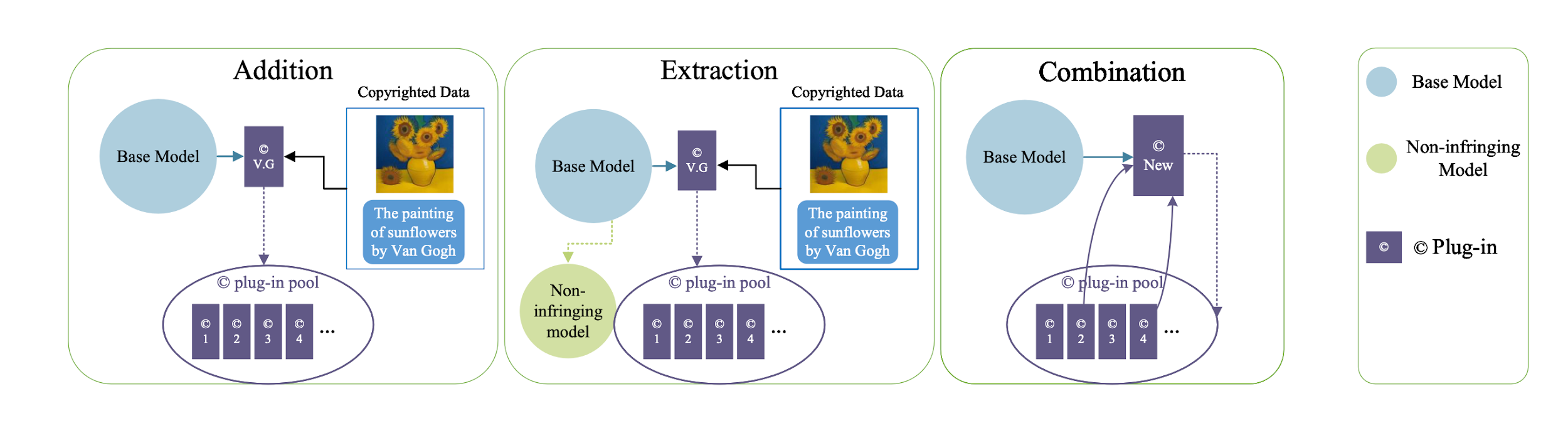
- Addition: creator can easily add work as plugin
- Extraction: model owner can remove works that are infringed from base model
- Combination
- Creator can combine their work together
- User can use different creators’ work to create new images
Addition
- Can be implemented straightforwardly under LoRA
- LoRA can server as a plug-in for SDM and learn them with copyright work
- Track the usage and fairly attribute the reward
Extraction
- Traditional Solution
- Retrain model from scratch only use non-infringing data
- High cost, complex data clearing, hard to implement
- Instead, “ Inverse LoRA”
- Unlearn the target concept
- Tunes the inversed LoRA to memorize surrounding concepts
- Inverse LoRA to obtain the non-infringing model
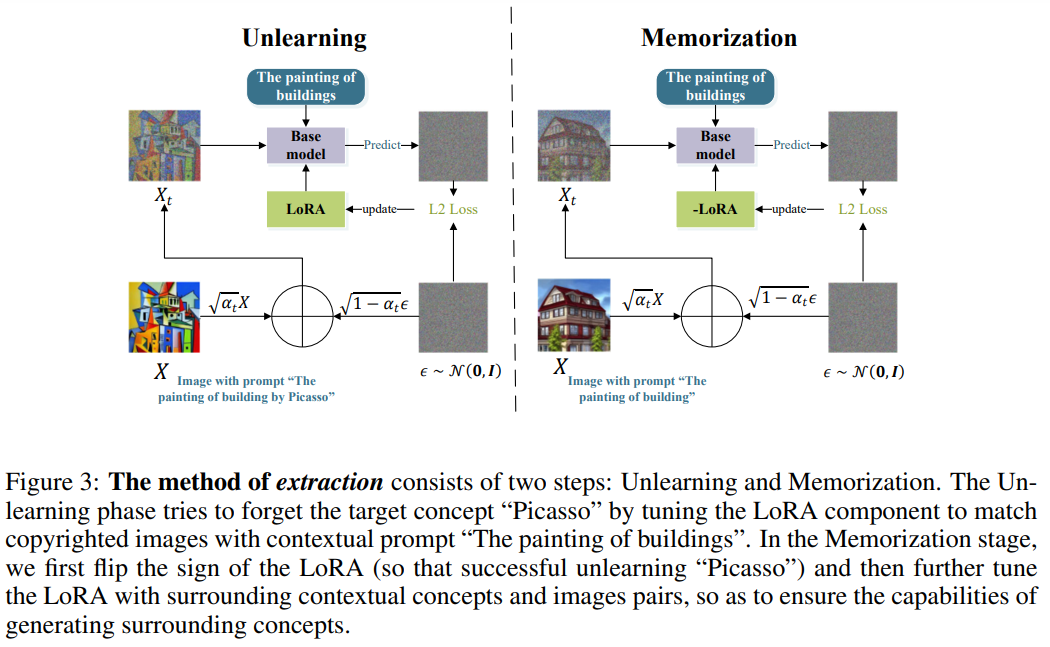
Unlearning: tune LoRA to match a copyrighted image with “The painting of the building” Memorization: guide the generation far away from the target concept “ Picasso”
Combination
- Simply adding two plug-ins will yield unpredictable outcomes (“Snoopy” and “Mikey”)
- EasyMerge: a data-free layer-wise distillation method
- Data-free: only requiring plug-ins and corresponding text prompts
- With layer-wise distillation: accomplish the combination in a few iterations
B.3 Experiment
As the addition operation has been well demonstrated by the public, the authors focus on evaluating extraction and combination operations
- Style transfer: Extraction and Combination
- Cartoon IP recreation: Extraction and Combination
![]()
In Table 1, the authors presented objective measures to assess the performance of the extraction operation in comparison to baseline methods. Our method demonstrates a notable improvement, with the KID metric increasing from 42 to 187 on target style compared to Concepts-Ablation (Kumari et al., 2023), which indicates better removal of the target style

Figure 5 shows three IP characters extraction: Mickey, R2D2, and Snoopy. It performs well on all of them, extracting the given IP without disturbing the generation of other IPs. Table 2 quantifies the extraction effect in IP recreation. We can increase the KID of the target IP by approximately 2.6 times while keeping the KID of the surrounding IP approximately unchanged.
In Figure 6, the authors illustrated the combination and addition of various IPs in a single image, as exemplified in Figure 6. Subsequent to the combination step, the non-infringing model’s capability to generate either Mickey Mouse or Darth Vader-themed images is removed.
![]()
Limitations
- Search
- How to manage plug-ins with its growth?
- How user can find the right plug-in effectively?
- Backward compatibility
- When the base model is upgraded, the pool of plug-ins needs to be retrained, which adds huge cost.
- Performance
- Non-infringing model may degrade if conducting too many extraction operations, and the influence is not thoroughly evaluated.
Summary
People are getting worried that advanced AI models might produce content that violates copyright, especially as these models create high-quality images without giving credit to the original data they were trained on. To address this issue, a solution called “©Plug-in Market” is proposed. This solution involves integrating copyrighted data into the LoRA plug-ins of the base model. This allows users to easily track how the data is used and ensures fair attribution of rewards, aligning with the principles of copyright law. The framework faces a challenge in efficiently handling numerous plug-ins, making it easy for users to find the right ones. Upgrading the base model incurs significant retraining costs for the plug-ins, requiring consideration for backward compatibility. The paper notes a limitation: excessive extraction operations may degrade the performance of the non-infringing model, and this influence is not thoroughly assessed.
Paper C. Extracting Training Data from Diffusion Models
C.1 Motivation
- Whether do generative models memorize and regenerate training example
- Yes, state-of-the-art diffusion models do memorize training samples!

- How and why do memorization occur?
- Understanding privacy risks
- Understanding generalization
C.2 Background
- Diffusion models
- Denoising Diffusion Probabilistic Models (DDPM)
- Training data privacy attacks
- Membership inference attacks: “Was this example in the training set?”
- Inversion attacks: extract representative examples from a target class
- Attribute inference attacks: reconstruct subsets of attributes of training samples
- Extraction attacks: completely recover training examples
This paper explores 3 attacks on diffusion models.

C.3 Threat Model System Overview
- Adversary capabilities
- Black-box adversary on Stable Diffusion and Imagen
- White-box adversary on 16 diffusion models trained on CIFAR-10
- Adversary goals
- Data extraction (Inversion attacks): successfully extract identical image
- Data reconstruction (Attribute inference attacks): given partial knowledge to recover full image
- Membership inference (Membership inference attacks): given image x, infer whether x is in the training set
Data Extraction Attack: Extracting training data from state-of-the-art diffusion model: Stable Diffusion and Imagen

Data Extraction from Stable Diffusion (Black-box attacks)
- Preprocessing: Identifying duplicates in the training data to reduce computational cost
- Embedding: Embed each images to 512 dimension vector using CLIP
- Near-duplication: Search for any training samples that are nearly duplicated with a pixel-level L2 distance below some threshold
- Attack: For each of these near-duplicate images, they use corresponding prompts as input to extraction attack
- Extraction
- Generating images using selected prompts
- 500 images for each prompt with different seeds
- Performing membership inference to get images that appear to be memorized

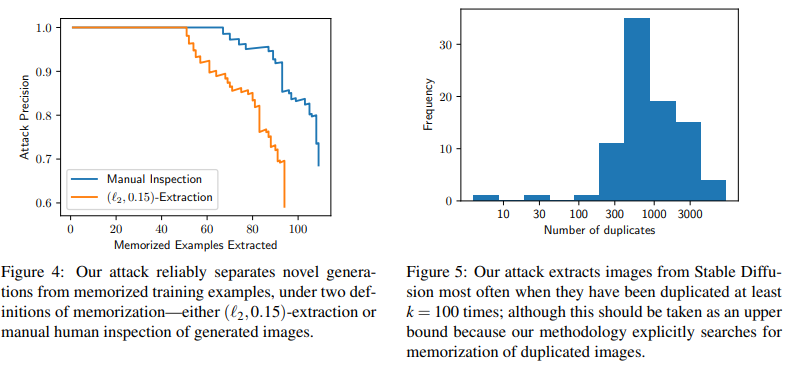
Extraction Result for Stable Diffusion
- Compare with training images using definition 1, 94 images are successfully extracted under the threshold 0.15 for l2 distance
- Still 13 images are memorized after human annotation
For 175 million generated images, they will sort them by the mean distance between images in the clique
C.4 Investigation Memorization
Experiment Setup
- CIFAR-10 dataset
- 16 diffusion models
- Privacy attacks:
- Membership inference attacks (class-conditional models)
- Data reconstruction attacks (inpainting models)
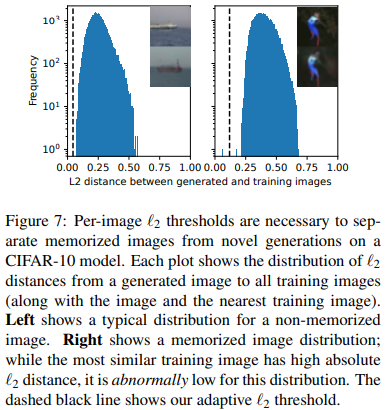
Figure 7 illustrates this by computing the 2 distance between two different generated images and every image in the CIFAR-10 training dataset. The left figure shows a failed extraction attempt; despite the fact that the nearest training image has a 2 distance of just 0.06, this distance is on par with the distance to many other training images (i.e., all images that contain a blue sky). In contrast, the right plot shows a successful extraction attack.
Membership Inference Attack

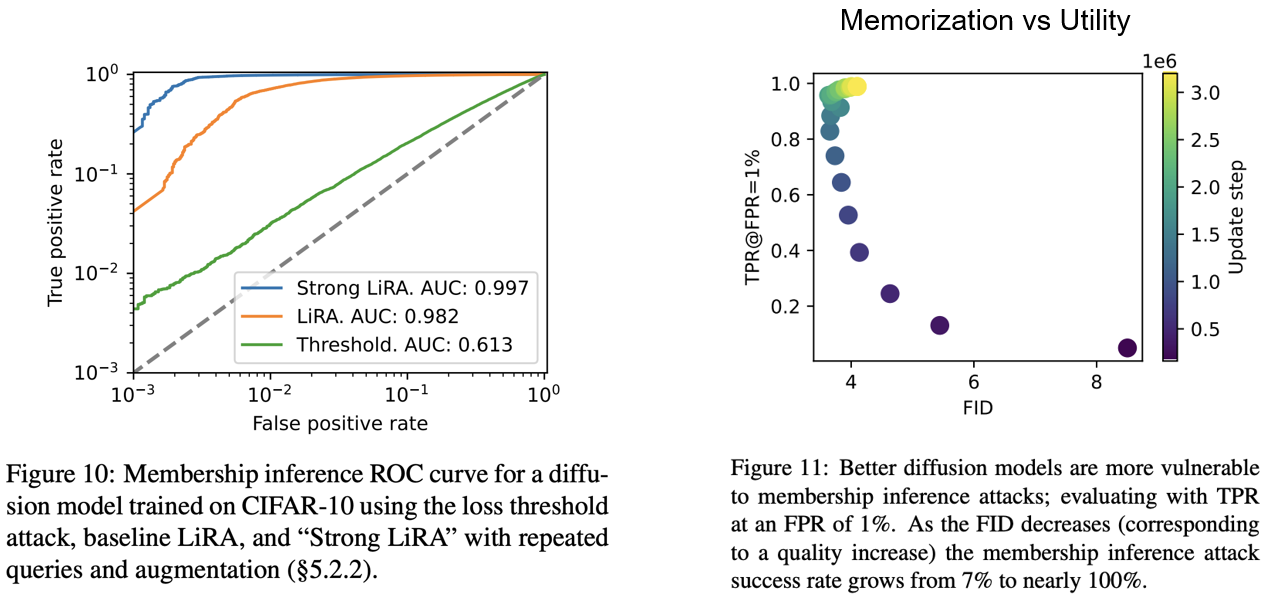
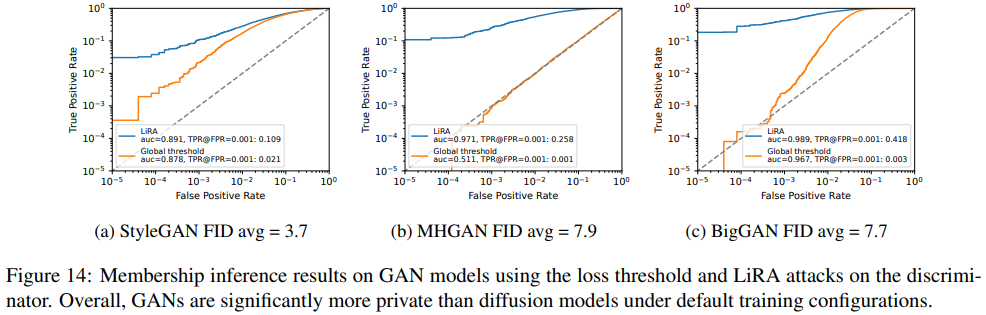
Figure 10 shows the effect of combining both these strategies. Together they are remarkably successful, and at a false positive rate of 0.1% they increase the true positive rate by over a factor of six from 7% to 44%. In Figure 11 the authors computed the attack success rate as a function of FID, and we find that as the quality of the diffusion model increases so too does the privacy leakage. These results are concerning because they suggest that stronger diffusion models of the future may be even less private.
Qualitative Results

Inpainting Attacks
- Recover masked region of an image
- Take top-10 scoring reconstruction results for each image

The above figure shows qualitative examples of this attack. The highest-scoring reconstruction looks visually similar to the target image when the target is in training and does not resemble the target when it is not in training
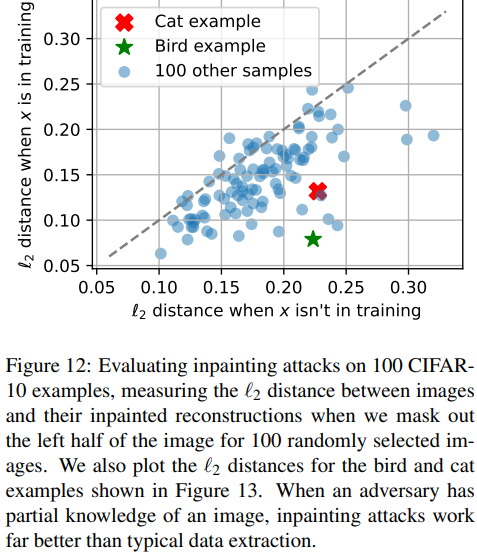
Figure 12 compares the average distance between the sample and the ten highest scoring inpainted samples. This allows us to show our inpainting attacks have succeed: the reconstruction loss is substantially better in terms of `2 distance when the image is in the training set than when not.
C.5 Diffusion Models vs GANs
Unlike diffusion models that are explicitly trained to memorize and reconstruct their training datasets, GANs are not. Instead, GANs consist of two competing neural networks: a generator and a discriminator.
Data Extraction Attacks
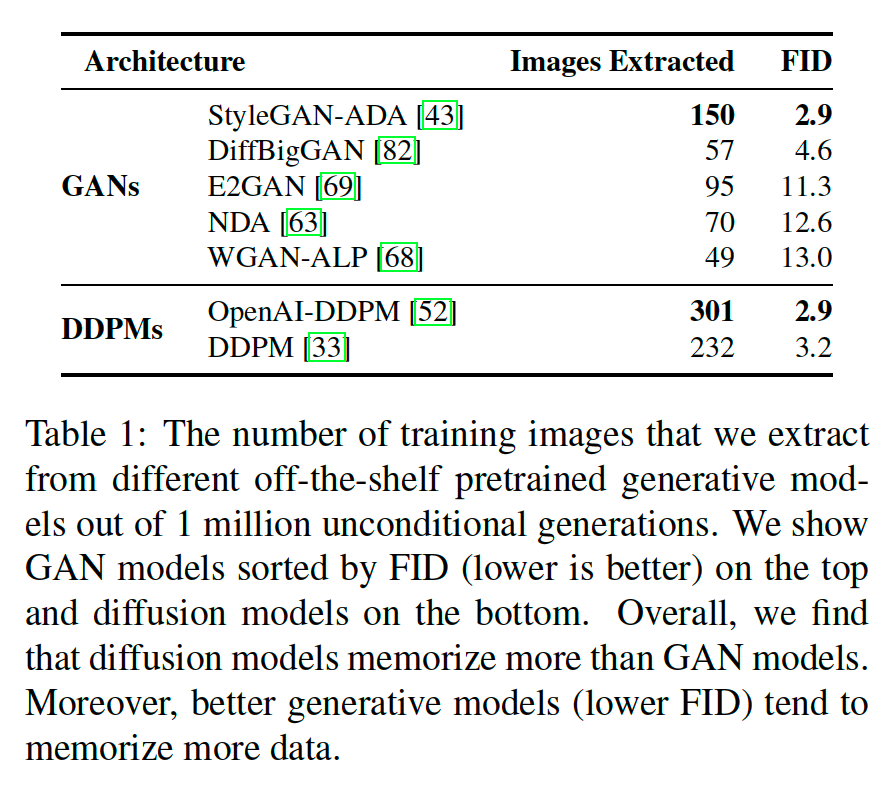
Table 1 shows the number of extracted images for each model and their corresponding FID. Overall, the authors find that diffusion models memorize more data than GANs, even when the GANs reach similar performance, e.g., the best DDPM model memorizes 2× more than StyleGAN-ADA but reaches the same FID.
Using the GANs we trained ourselves, the authors showed examples of the near-copy generations in Figure 15 for the three GANs. Overall, the results further reinforce the conclusion that diffusion models are less private than GAN models
Membership Inference Attacks
Overall, diffusion models have higher membership inference leakage, e.g., diffusion models had 50% TPR at an FPR of 0.1% as compared to < 30% TPR for GANs. This suggests that diffusion models are less private than GANs for membership inference attacks under default training settings, even when the GAN attack is strengthened due to having access to the discriminator.
Defenses and Recommendations
- Deduplicating training data
- Differentially-Private Training
- Differentially-private stochastic gradient descent (DP-SGD)
####Summary
- State-of-the-art diffusion models memorize training images
- Define memorization in diffusion models
- Stronger diffusion models are less private than weaker diffusion models
- Propose attack techniques to help estimate the privacy risks of trained models
Paper D. A Comprehensive Survey of AI-Generated Content (AIGC):A History of Generative AI from GAN to ChatGPT
- A Comprehensive Survey of AI-Generated Content (AIGC): A History of Generative AI from GAN to ChatGPT
ChatGPT and other Generative AI (GAI) techniques belong to the category of Artificial Intelligence Generated Content (AIGC), which involves the creation of digital content.
The goal of AIGC is to make the content creation process more efficient and accessible, allowing for the production of high-quality content at a faster pace.
This survey provides a comprehensive review of the history of generative models, and basic components, and recent advances in AIGC from unimodal interaction and multimodal interaction.
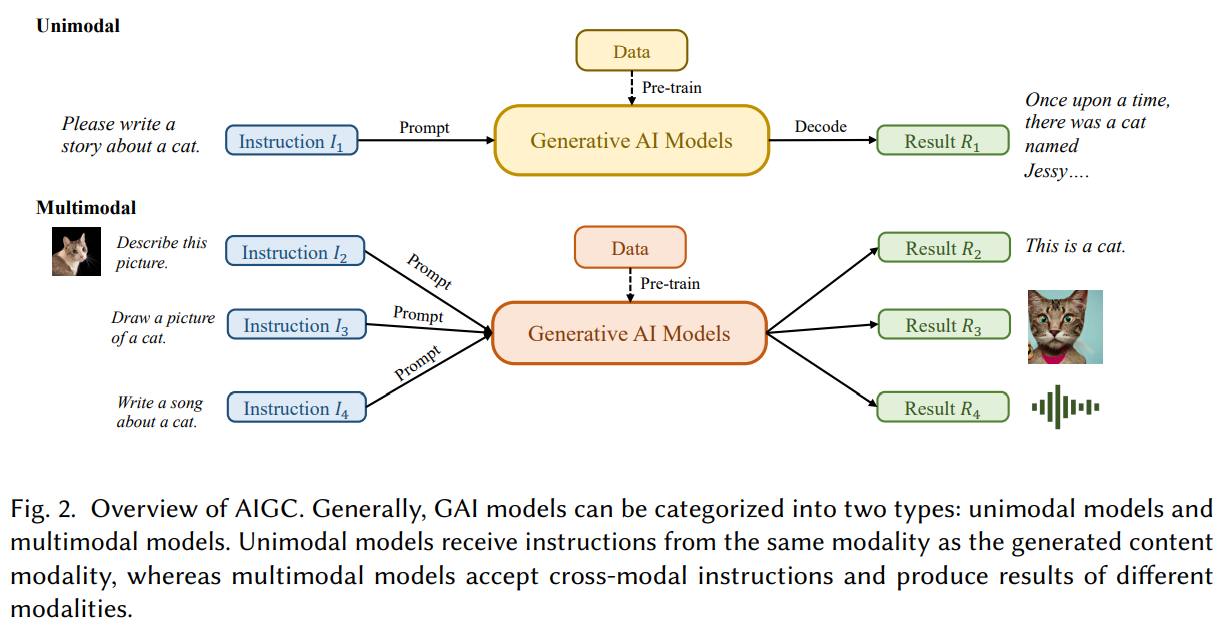
Figure 2 offers a thorough summary of advanced GAI algorithms, both in terms of unimodal generation and multimodal generation.
Three primary contributions are as follows –
- Provide a formal definition and a thorough survey for AIGC and the AI-enhanced generation process.
- Review the history, and foundation techniques of AIGC and conduct a comprehensive analysis of recent advances in GAI tasks and models from the perspective of unimodal generation and multimodal generation.
- Discuss the main challenges facing AIGC and future research trends confronting AIGC.
Emergence from the technical approach
The transformer architecture, introduced in 2017, has revolutionized AI by becoming the backbone of major generative models in NLP and CV. Innovations like the Vision Transformer and SwinTransformer have furthered this by adding visual components.
D.1 Foundation pre-trained model
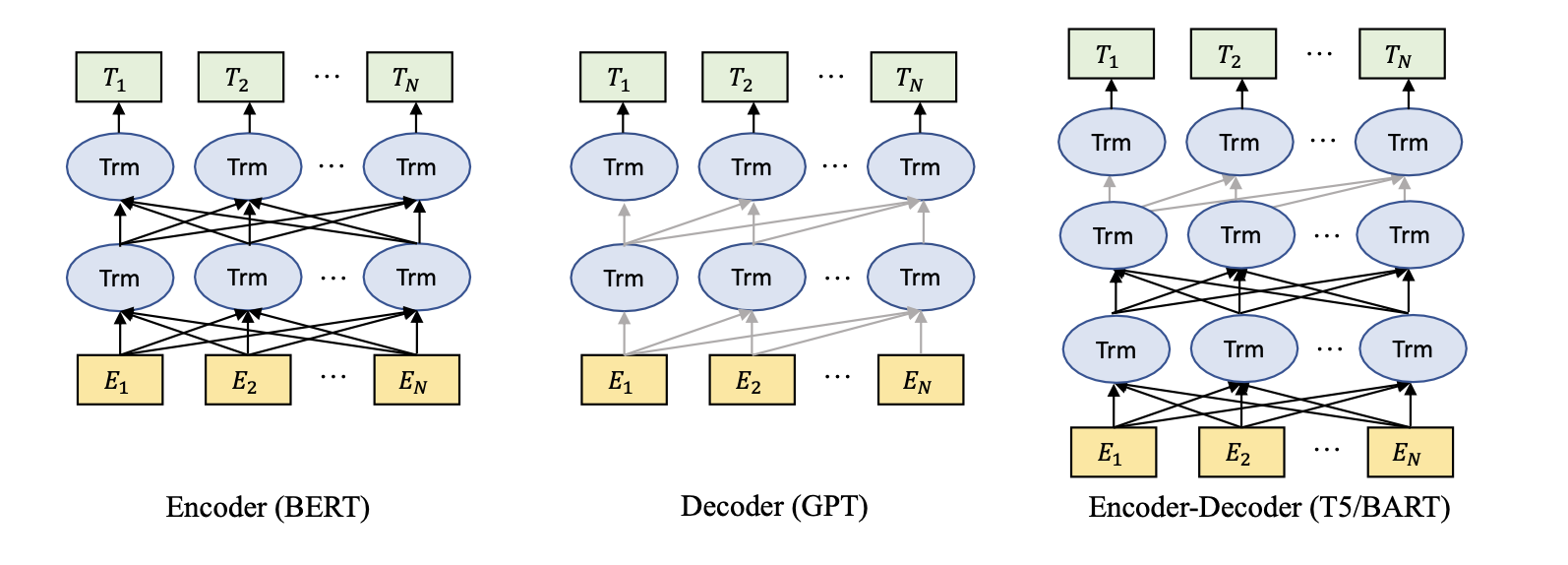
The use of pre-trained language models has emerged as the prevailing technique in the domain of NLP. Generally, current state-of-the-art pre-trained language models could be categorized as masked language models (encoders), autoregressive language models (decoders) and encoder-decoder language models, as shown in Figure 4.
Reinforcement Learning from Human Feedback: To better align AIGC output with human preferences. Three distinct categories, including, pre-training, reward learning, and fine-tuning with reinforcement learning.
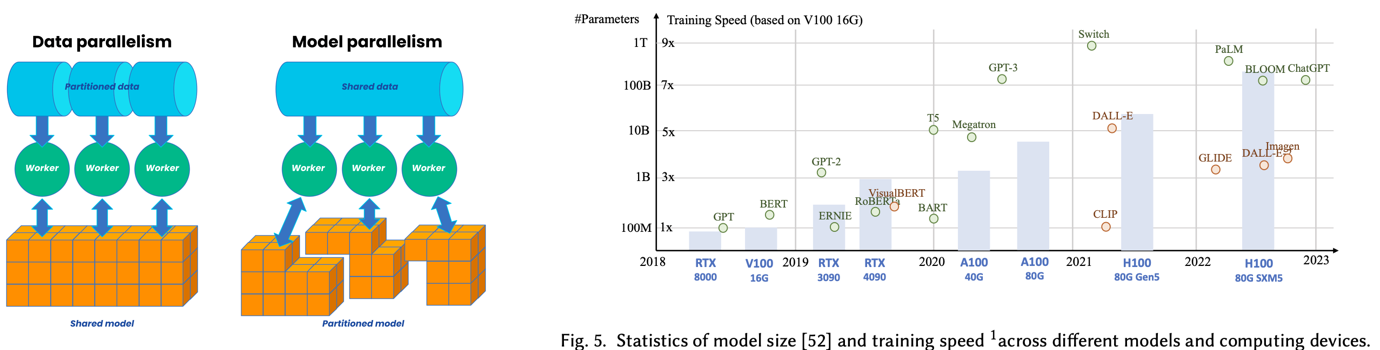
D.2 Computing and Hardware
Distributed Training
The training workload is split among multiple processors or machines, allowing the model to be trained much faster.
Cloud Computing
Service providers let researchers access to powerful computing resources to boost their model training. eg. AWS (Amazon) & Azure (Microsoft)
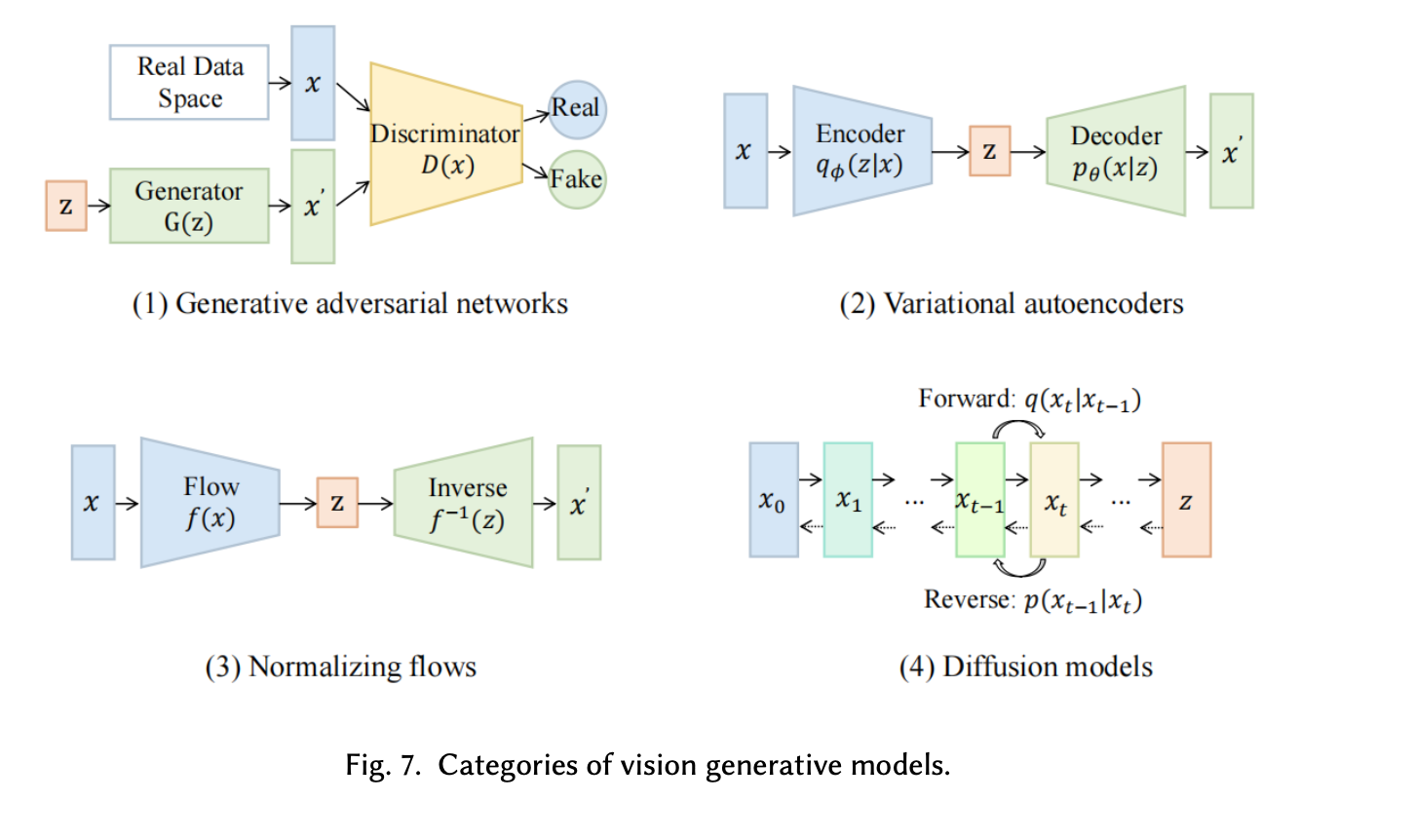
D.3 Generative AI
Unimodal Model
Generative Language Models.
-
Decoder Models (Autoregressive Models): Predicting the probability of a masked token given context information, Eg. GPT3, OPT
-
Encoder Models (Masked Language Models) Model the probability of the next token given previous tokens, Eg. BERT RoBERTa
-
Encoder-Decoder Models Combines transformer-based encoders and decoders together for pre-training, Eg. T5, BART
D.4 Vision Generative Models
GAN: Generative Adversarial Networks (GANs) consist of two parts, a generator and a discriminator. The generator attempts to learn the distribution of real examples in order to generate new data, while the discriminator determines whether the input is from the real data space or not.
LAPGAN (Laplacian Pyramid GAN):
- Utilizes a cascade of convolutional networks.
- Generates high-quality images through a coarse-to-fine approach.
- Enhances detail at each level of the image pyramid.
DCGAN (Deep Convolutional GAN):
- Employs architectural constraints for more stable training.
- Simplifies and stabilizes the structure of convolutional networks.
- Pioneered features like strided convolutions and batch normalization in GANs.
BigGAN:
- Known for high-resolution and diverse image synthesis.
- Implements large-scale models and improved training dynamics.
- Uses class-conditional generation to produce highly detailed images.
VAE: Following variational bayes inference [97], Variational Autoencoders (VAE) are generative models that attempt to reflect data to a probabilistic distribution and learn reconstruction that is close to its original input.
Normalizing Flows: A Normalizing Flow is a distribution transformation from simple to complex by a sequence of invertible and differentiable mappings.
- Coupling and autoregressive flows
- Multi-scale flows
- Convolutional and Residual Flows.
- ConvFlow
- RevNets
- iRevNets
Diffusion Models: The Generative Diffusion Model (GDM) is a cutting-edge class of generative models based on probability, which demonstrates state-of-the-art results in the field of computer vision. It works by progressively corrupting data with multiple-level noise perturbations and then learning to reverse this process for sample generation.
D.5 Multimodal Models
Under the hood of Encoder-Decoder family architectures. The encoder is responsible for learning a contextualized representation of the input data. Decoder is used to generate raw modalities that reflect cross-modal interactions, structure, and coherence in the representation.
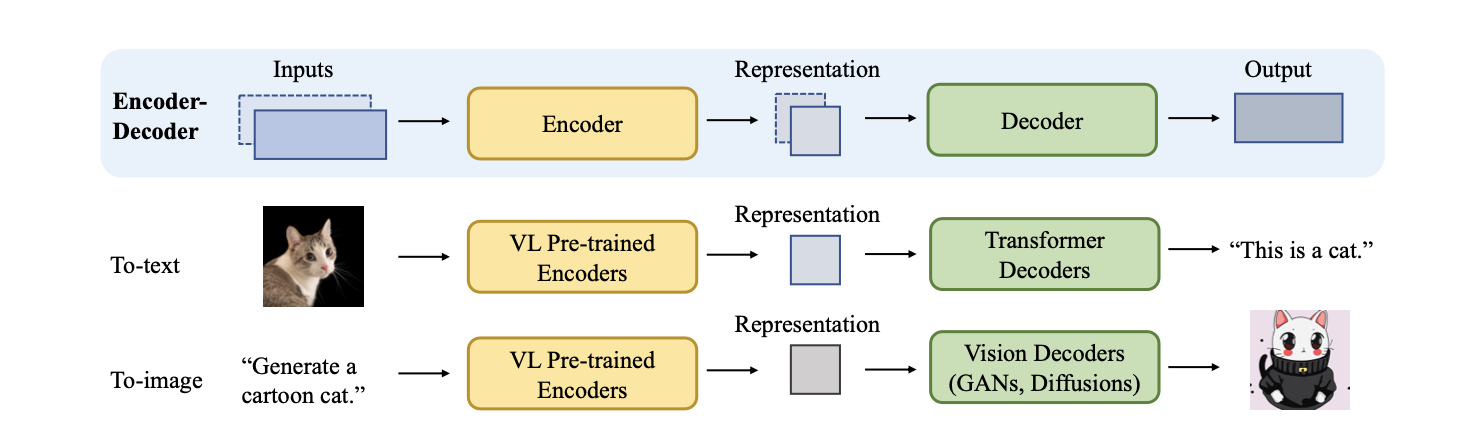
Vision Language Encoders
- Concatenated encoders: concatenating the embeddings from single encoders
Cross-aligned encoders: learning contextualized representations is to look at pairwise interactions between modalities.
![]()
Vision Language Decoders
- To text decoders: Jointly- trained decoders, frozen decoders.
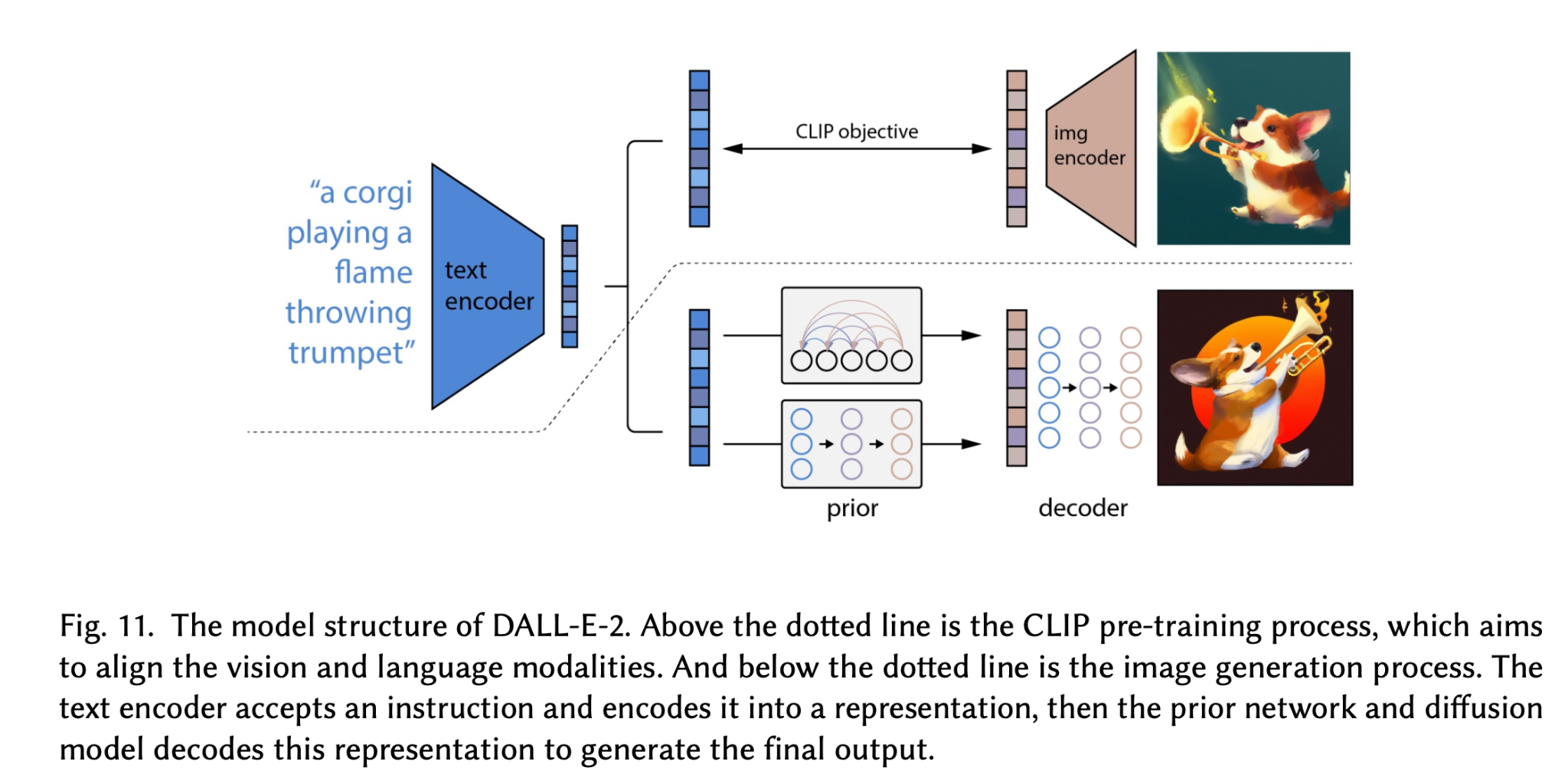
- To image decoders:
- GAN-based,
- Diffusion-based:GLIDE, Imagen
- VAE-based: DALL-E
Other Modalities Generation
- Text-audio
- Text-graph
- Text-code
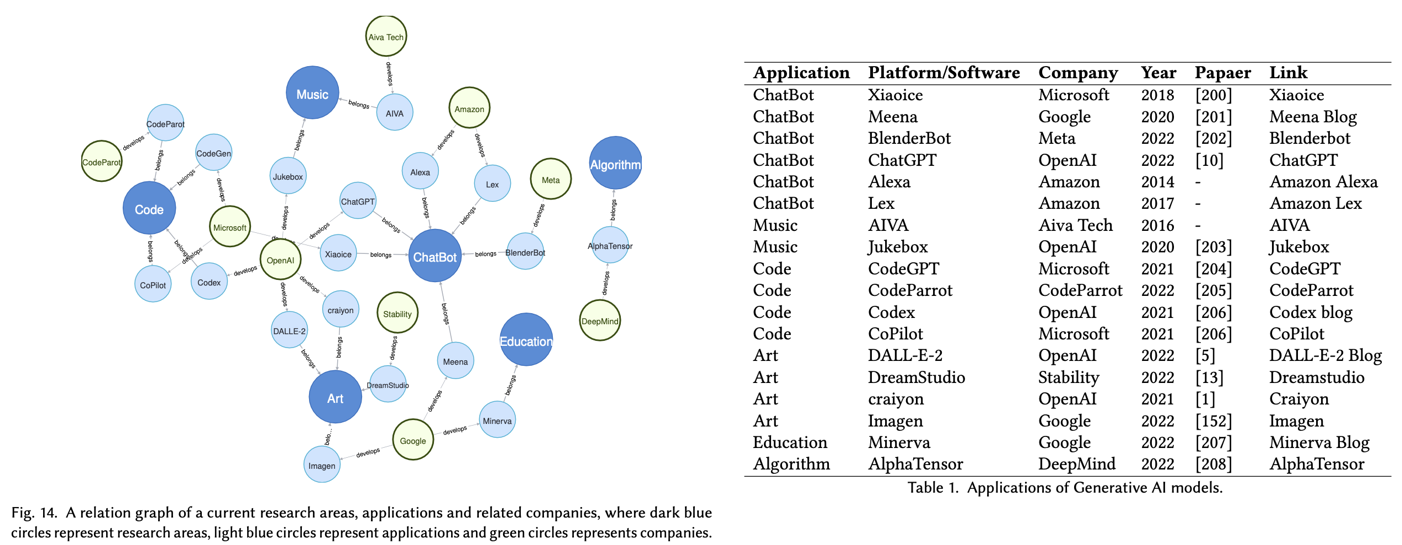
D.6 Applications
D.7 Efficiency
- Inference efficiency: This is concerned with the practical considerations of deploying a model for inference, i.e., computing the model’s outputs for a given input. Inference efficiency is mostly related to the model’s size, speed, and resource consumption (e.g., disk and RAM usage) during inference.
- Training efficiency: This covers factors that affect the speed and resource requirements of training a model, such as training time, memory footprint, and scalability across multiple
D.8 Future Directions
- High-stakes Applications
- Specialization and Generalization
- Continual Learning and Retraining
- Reasoning
- Scaling up
- Social issue
References
- https://arxiv.org/abs/2303.15715
- https://arxiv.org/abs/2301.13188
- https://arxiv.org/abs/2303.04226
- https://openreview.net/forum?id=pSf8rrn49H
- https://arxiv.org/abs/2305.18462