FM privacy leakage issues
- SlideDeck: W6-FM-privacy-leakage
- Version: current
- Lead team: team-4
- Blog team: team-1
In this session, our readings cover:
Required Readings:
Are Large Pre-Trained Language Models Leaking Your Personal Information?
- https://arxiv.org/abs/2205.12628
- Jie Huang, Hanyin Shao, Kevin Chen-Chuan Chang Are Large Pre-Trained Language Models Leaking Your Personal Information? In this paper, we analyze whether Pre-Trained Language Models (PLMs) are prone to leaking personal information. Specifically, we query PLMs for email addresses with contexts of the email address or prompts containing the owner’s name. We find that PLMs do leak personal information due to memorization. However, since the models are weak at association, the risk of specific personal information being extracted by attackers is low. We hope this work could help the community to better understand the privacy risk of PLMs and bring new insights to make PLMs safe.
Privacy Risks of General-Purpose Language Models
- https://ieeexplore.ieee.org/abstract/document/9152761
- We find the text embeddings from general-purpose language models would capture much sensitive information from the plain text. Once being accessed by the adversary, the embeddings can be reverse-engineered to disclose sensitive information of the victims for further harassment. Although such a privacy risk can impose a real threat to the future leverage of these promising NLP tools, there are neither published attacks nor systematic evaluations by far for the mainstream industry-level language models. To bridge this gap, we present the first systematic study on the privacy risks of 8 state-of-the-art language models with 4 diverse case studies. By constructing 2 novel attack classes, our study demonstrates the aforementioned privacy risks do exist and can impose practical threats to the application of general-purpose language models on sensitive data covering identity, genome, healthcare and location. For example, we show the adversary with nearly no prior knowledge can achieve about 75% accuracy when inferring the precise disease site from Bert embeddings of patients’ medical descriptions. As possible countermeasures, we propose 4 different defenses (via rounding, different…
More Readings:
Privacy in Large Language Models: Attacks, Defenses and Future Directions
- https://arxiv.org/abs/2310.10383
- The advancement of large language models (LLMs) has significantly enhanced the ability to effectively tackle various downstream NLP tasks and unify these tasks into generative pipelines. On the one hand, powerful language models, trained on massive textual data, have brought unparalleled accessibility and usability for both models and users. On the other hand, unrestricted access to these models can also introduce potential malicious and unintentional privacy risks. Despite ongoing efforts to address the safety and privacy concerns associated with LLMs, the problem remains unresolved. In this paper, we provide a comprehensive analysis of the current privacy attacks targeting LLMs and categorize them according to the adversary’s assumed capabilities to shed light on the potential vulnerabilities present in LLMs. Then, we present a detailed overview of prominent defense strategies that have been developed to counter these privacy attacks. Beyond existing works, we identify upcoming privacy concerns as LLMs evolve. Lastly, we point out several potential avenues for future exploration.
ProPILE: Probing Privacy Leakage in Large Language Models
- https://arxiv.org/abs/2307.01881
- Siwon Kim, Sangdoo Yun, Hwaran Lee, Martin Gubri, Sungroh Yoon, Seong Joon Oh The rapid advancement and widespread use of large language models (LLMs) have raised significant concerns regarding the potential leakage of personally identifiable information (PII). These models are often trained on vast quantities of web-collected data, which may inadvertently include sensitive personal data. This paper presents ProPILE, a novel probing tool designed to empower data subjects, or the owners of the PII, with awareness of potential PII leakage in LLM-based services. ProPILE lets data subjects formulate prompts based on their own PII to evaluate the level of privacy intrusion in LLMs. We demonstrate its application on the OPT-1.3B model trained on the publicly available Pile dataset. We show how hypothetical data subjects may assess the likelihood of their PII being included in the Pile dataset being revealed. ProPILE can also be leveraged by LLM service providers to effectively evaluate their own levels of PII leakage with more powerful prompts specifically tuned for their in-house models. This tool represents a pioneering step towards empowering the data subjects for their awareness and control over their own data on the web.
Blog: FM Privacy Leakage Issues
Section 1 Background and Introduction
Privacy in AI is an emerging field that has seen a rapid increase in relevance as AI technologies have been implemented across more and more industries. Privacy-preserving measures are still relatively new, but improving and adopting them is the key to effectively harnessing the power of Artificial Intelligence.
1. Artificial Intelligence-Generated Content Background and Safety
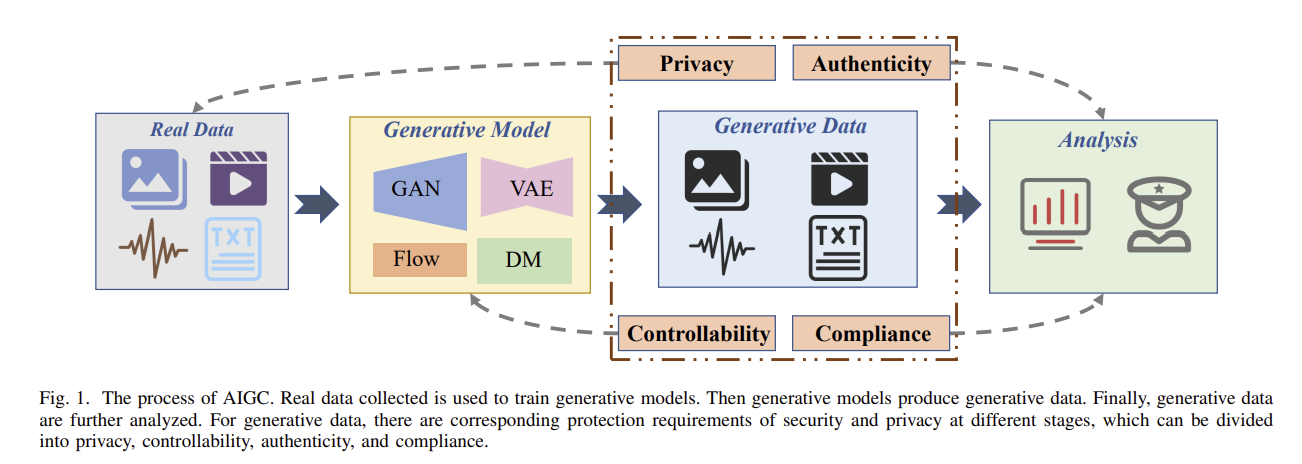
Wang, T., Zhang, Y., Qi, S., Zhao, R., Xia, Z., & Weng, J. (2023). Security and privacy on generative data in AIGC: A survey. arXiv preprint arXiv:2309.09435.
The process of AIGC:
-
Real Data for Training: High-quality training data is essential for AIGC models, sourced from repositories like public databases and social media, then filtered to remove irrelevant data. Preprocessing, augmentation, and privacy measures enhance data quality and security.
-
Generative Model in Training: Generative models such as GANs and VAEs are trained on centralized servers to mimic real data distributions, with model choice based on task needs and available resources. Fine-tuning allows adjustment for new tasks without full retraining.
-
Generative Data: AIGC generates data based on input conditions, surpassing humans in speed and quality for tasks and conversations.
-
Analysis for Generative Data: Analysis of generative data ensures accuracy, consistency, and integrity, with adjustments made to improve quality and minimize risks like discrimination or misinformation through prompt detection and resolution.
2. Subclassifications of Security and Privacy on Generative Data
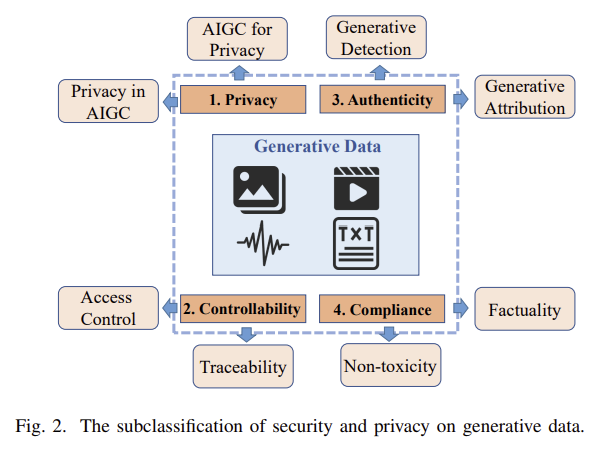
- Privacy
Privacy refers to ensuring that individual sensitive information is protected.
Privacy in AIGC: Generative models may mimic sensitive content, which makes it possible to replicate sensitive training data.
AIGC for privacy: Generative data contains virtual content, replacing the need to use sensitive data for training.

- Controllability
Controllability refers to ensuring effective management and control access of information to restrict unauthorized access.
Access control: Generative data needs to be controlled to prevent negative impacts from adversaries.
Traceability: Generative data needs to support the tracking of the generation process for monitoring any behavior involving security.

- Authenticity
Authenticity refers to maintaining the integrity and truthfulness of data.
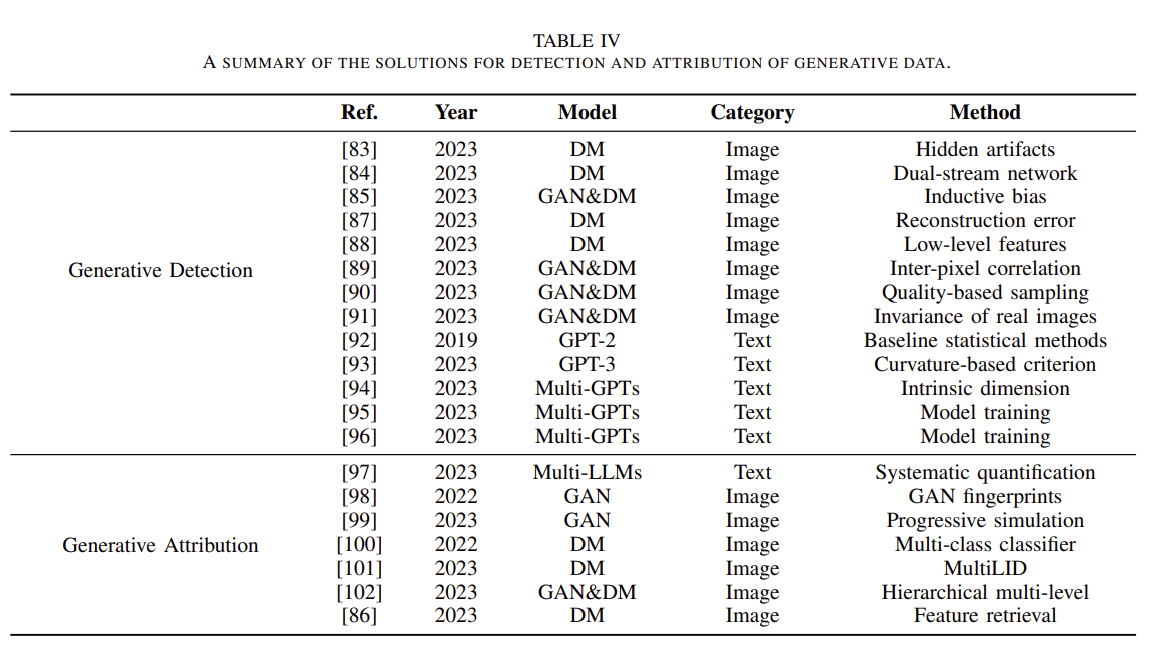
Generative detection: The ability to detect the difference between generated data and real data.
Generative attribution: Data should be further attributed to generative models to ensure credibility and enable accountability.
- Compliance
Compliance refers to adhering to relevant laws, regulations, and industry standards.
Non-toxicity: generative data is prohibited from containing toxic content.
Factuality: Generative data is strictly factual and should not be illogical or inaccurate.
3. Areas of Concern
While leaking user information is never ideal, some areas are of more concern than others:
-
Medical Information: Family history, underlying conditions, past operations, etc. This information would normally be considered private, but medical AI technologies might risk leaking it to outside parties, such as insurance companies or scammers.
-
Financial Information: Income, taxes, investments, etc, this kind of information is not normally publicly advertised, but might see exposure from individuals or businesses looking to use AI to streamline tasks like tax filings or accounting.
-
Personal Activities: Some people want to stay out of the public eye for one reason or another, and AI technologies used by travel agencies, airlines, etc might expose their locations and plans.
4. Defenses: Differential Privacy
Differential privacy safeguards databases and real-time data by perturbing data with noise to ensure observer indistinguishability. This perturbation balances data accuracy and privacy, crucial in sensitive domains like healthcare. Achieving this balance is challenging, particularly in Cyber-Physical Systems (CPSs) where accuracy is paramount. Differential privacy’s efficacy lies in navigating this delicate balance between data accuracy and privacy preservation.
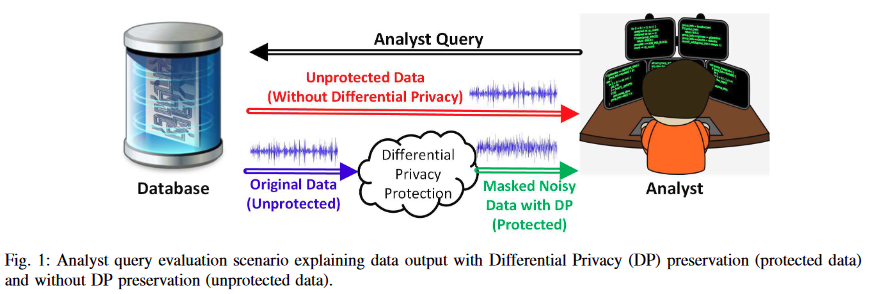
Hassan, M. U., Rehmani, M. H., & Chen, J. (2019). Differential privacy techniques for cyber physical systems: a survey. IEEE Communications Surveys & Tutorials, 22(1), 746-789.
5. Defenses: Distributed Models
By distributing the databases used for a model, risks are much lower for any given attack and many attacks may be outright thwarted. However, analysis on reported data from distributed nodes can still leak information. To combat this, combining with DP allows a federated system that is very private.
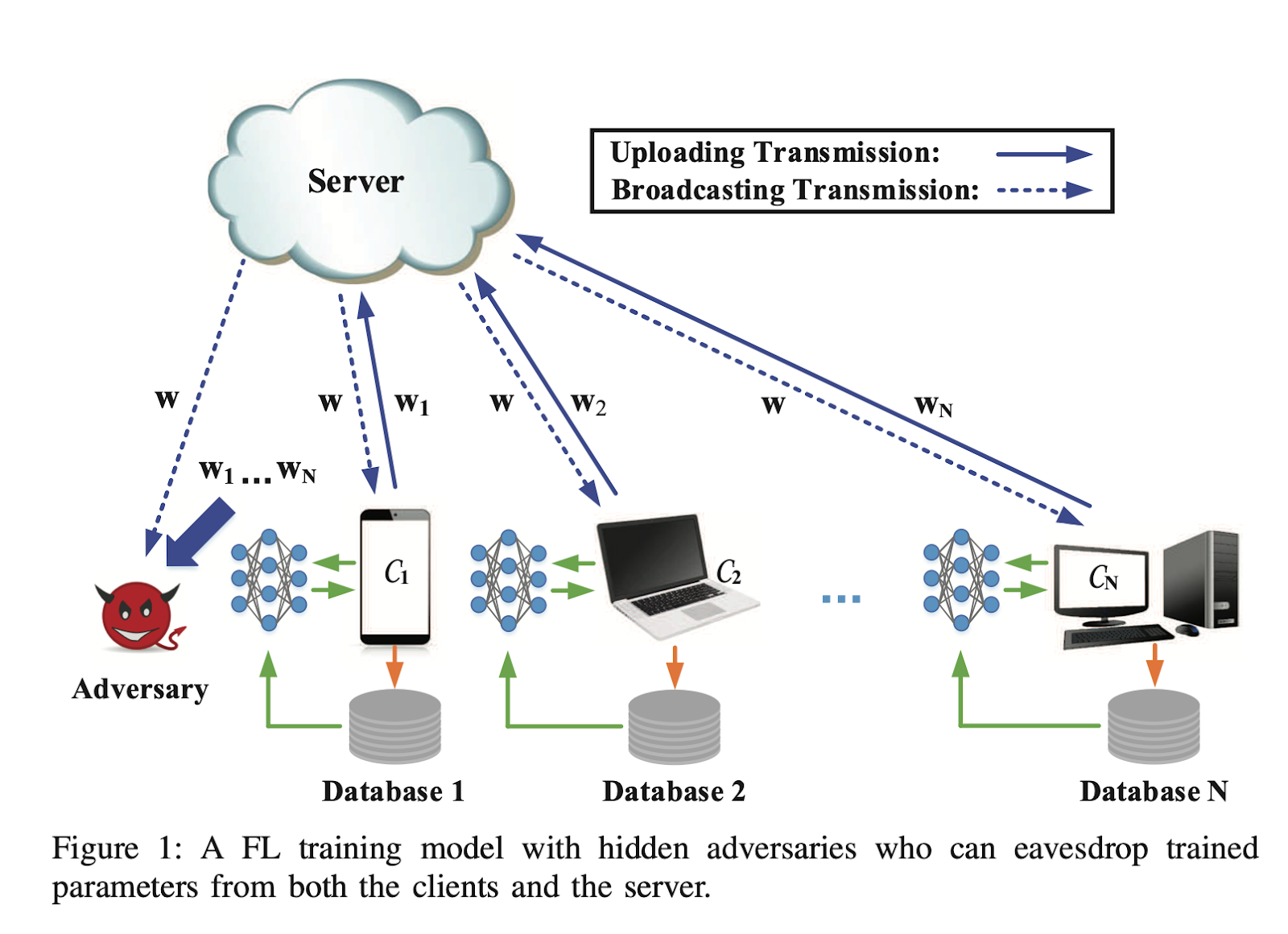
Wei, K., Li, J., Ding, M., Ma, C., Yang, H. H., Farokhi, F., … & Poor, H. V. (2020). Federated learning with differential privacy: Algorithms and performance analysis. IEEE Transactions on Information Forensics and Security, 15, 3454-3469.
Section 2 Privacy Risks of General-Purpose Language Models
Despite the utility and performance of general-purpose language models (LMs), they don’t come without privacy risks. The authors of “Privacy Risks of General-Purpose Language Models” (Pan et al., 2020) outline the privacy risks found in earlier general-purpose LMs.
General purpose large language models are becoming increasingly popular and are used for a variety of end purposes due to their flexibility. Despite this, “general-purpose language models tend to capture much sensitive information in the sentence embeddings”. Much of this sensitive information is financial or medical data. In generative AI in the image domain, attacks exist for reconstructing similar source images. These same attacks exist in natural language processing (NLP).
As mentioned previously, model inversion attacks exist for image generators. For example, Fredrickson et al published the following that demonstrates this attack:
-
“Model inversion attacks that exploit confidence information and basic countermeasures”
-
“Privacy in pharmacogenetics: An end-to-end case study of personalized warfarin dosing”
There are also membership inference attacks. For example, “Membership inference attacks against machine learning models” (Shokri et al. 2017).
There also exists general ML privacy risks where no specific private data is exposed, rather big data is used to predict unknown private info.
There are several motivations for this study:
-
LLMs like Bert and ChatGPT mentioned previously are being pushed as general purpose tools.
-
Many companies do not understand the comparative risks of data leakage for LLMs vs other types of models.
- Particular risks for sensitive information such as medical or financial info.
This paper shows how even relatively simple attacks pose a threat in order to better inform the public about the risks of using LLMs with sensitive information.
The attack the authors use has 3 underlying assumptions:
-
The adversary has access to a set of embeddings of plain text, which may contain the sensitive information the adversary is interested in
-
For simplicity only, we assume the adversary knows which type of pre-trained language models the embeddings come from.
-
The adversary has access to the pre-trained language model as an oracle, which takes a sentence as input and outputs the corresponding embedding
- The format of the plain text is fixed and the adversary knows the generating rules of the plain text.
This image outlines the basics of their attack.
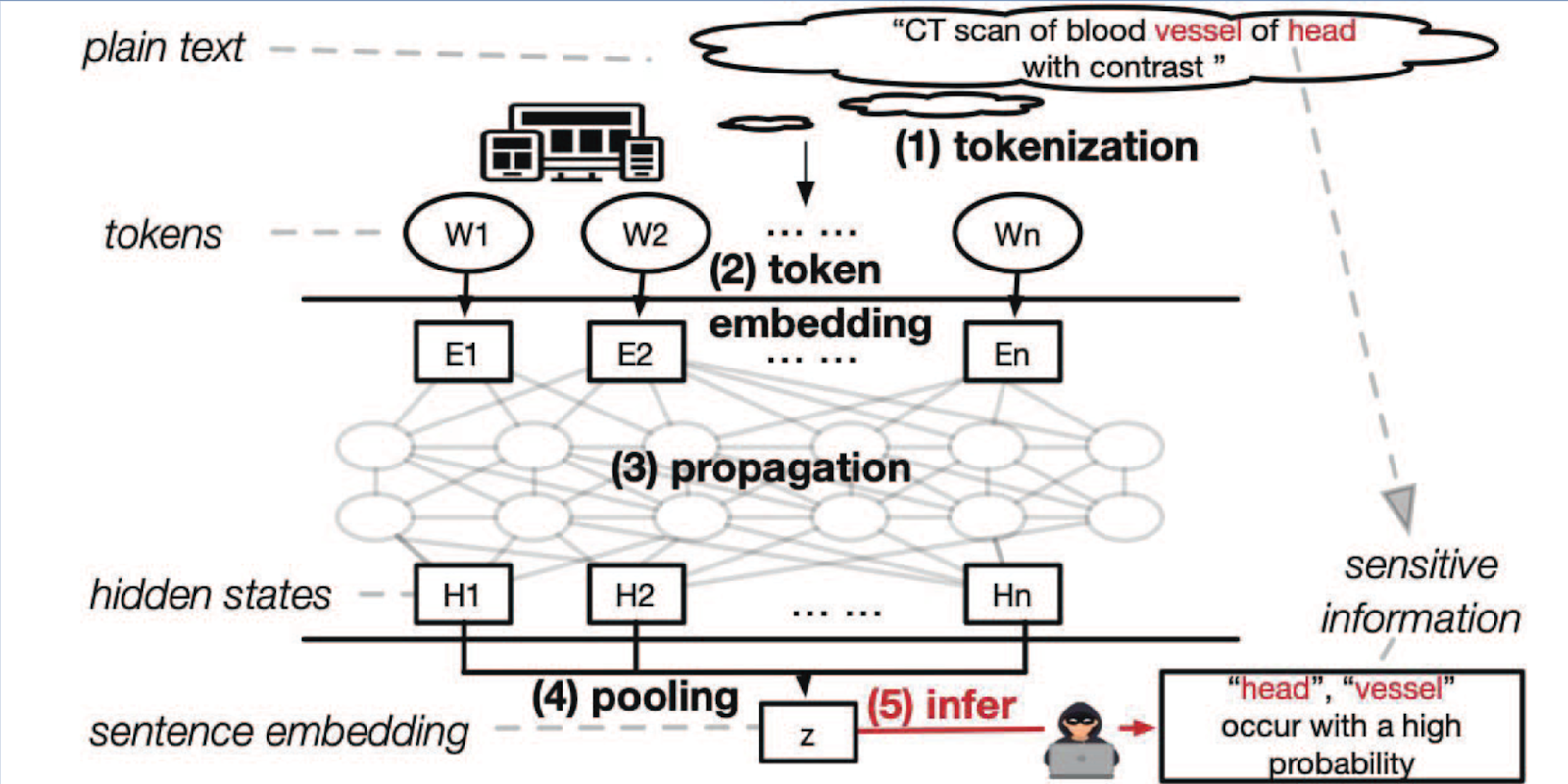
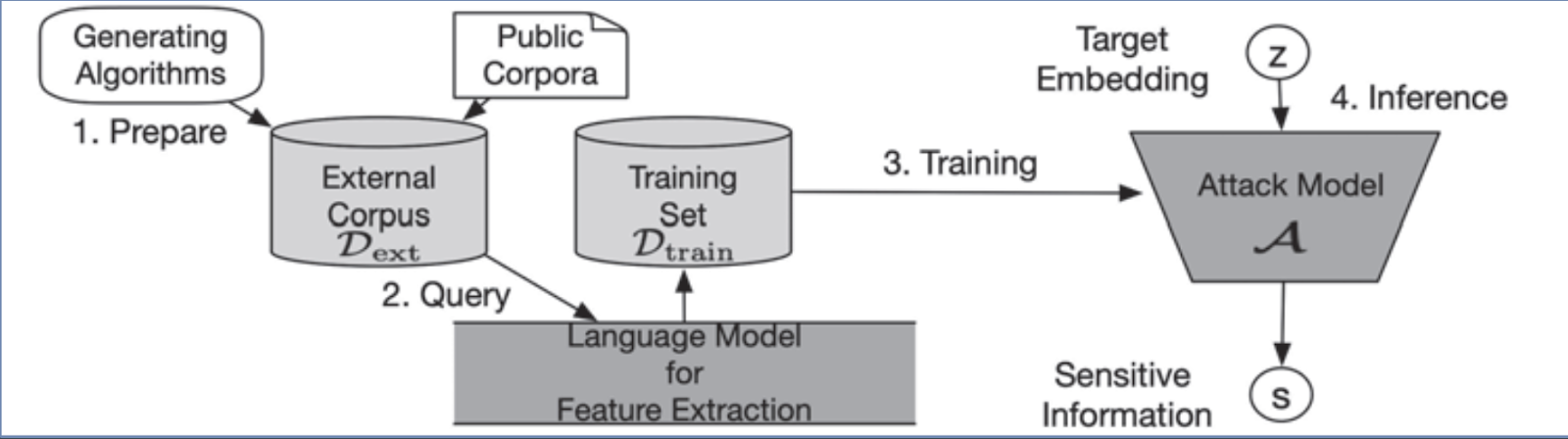
To carry out the attack, 4 steps are taken:
-
Create non-sensitive training data approximation (external corpus).
-
Query model for embeddings using an external corpus.
-
Using embeddings and labels to train attack model.
-
Use an attack model to infer sensitive training data.
The authors use this attack methodology to create two case studies that recognize patterns:
-
Citizen ID - commonly used, but possibly sensitive
-
May exist in training data or sensitive data that an organization is using LLMs to process.
-
Examples include US Social Security numbers, which are considered semi-private.
-
-
Genome Sequence - Bert used for splice site predictions
- However, DNA can contain indicators for medical conditions, demographic info, etc.

The authors demonstrate high accuracy in recovering the private information of citizens. This is done by generating 1000 citizen IDs that contain private information using a defined schema. These IDs are used to query the target model to get embeddings for the victims. This method successfully identifies the specific month and day of the victim’s birthday with more than 80% accuracy on the first attempt and determines the complete birth date with over 62% accuracy within the top five attempts.
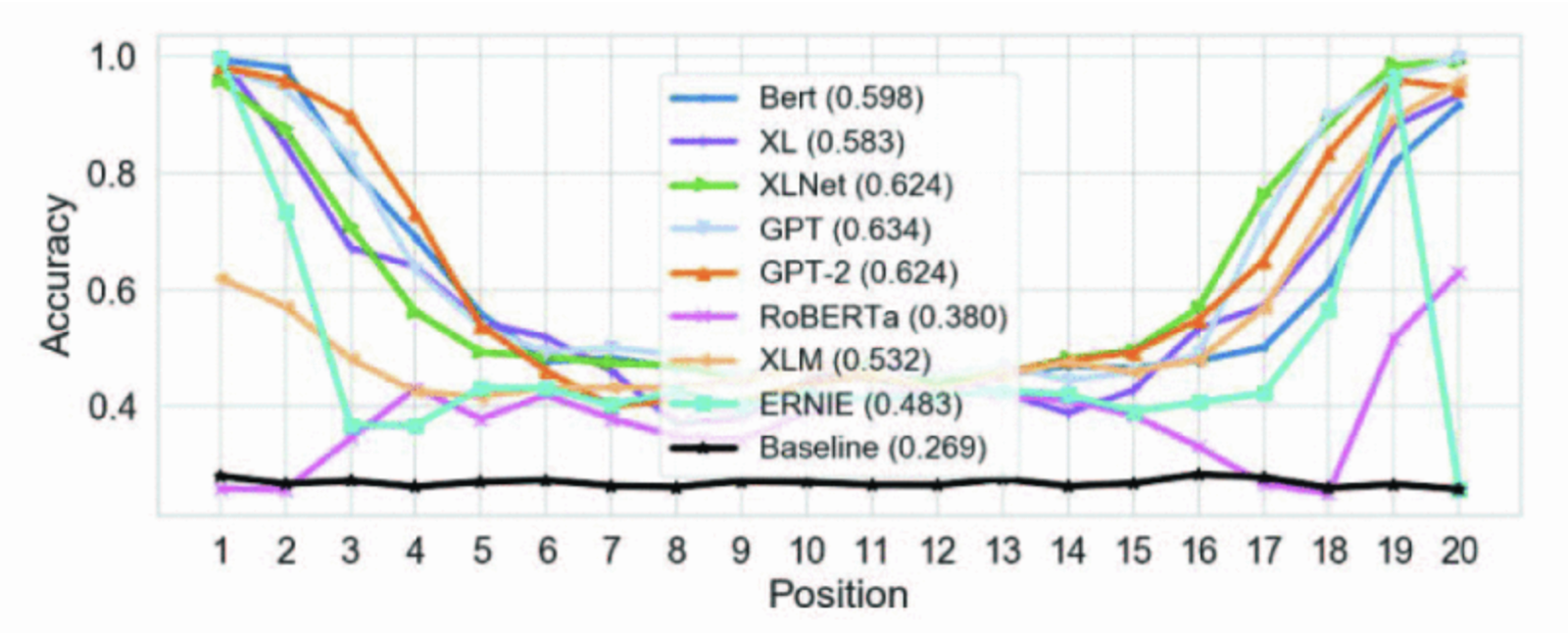
For the second case study, the authors demonstrate being able to accurately recover genomes on various nucleotide positions.
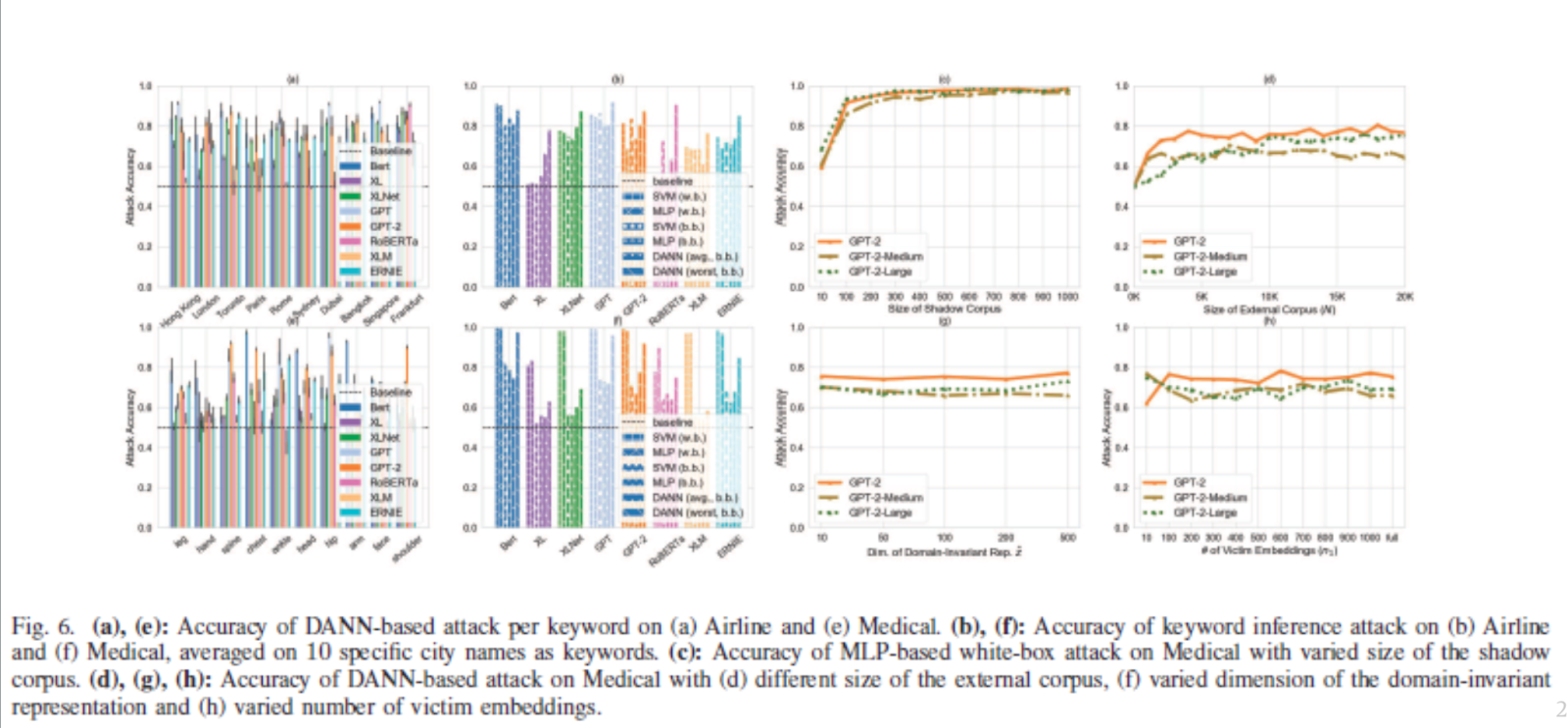
The authors also conduct two case studies involving keyword inference. The first involves airline reviews providing info on travel plans and the second involves medical descriptions providing sensitive health information. From these, the authors conclude the following:
-
There is a division based on white vs black-box models (attacking is harder for black-box models, but still possible).
-
Overall, highly effective in both cases but notably less so in black box scenarios (75% accuracy vs 99% accuracy, though on the airline dataset, the black-box models still achieve roughly 90% accuracy).
-
Google’s XL and Facebook’s RoBERTa are more robust against white-box attacks compared to their peers.
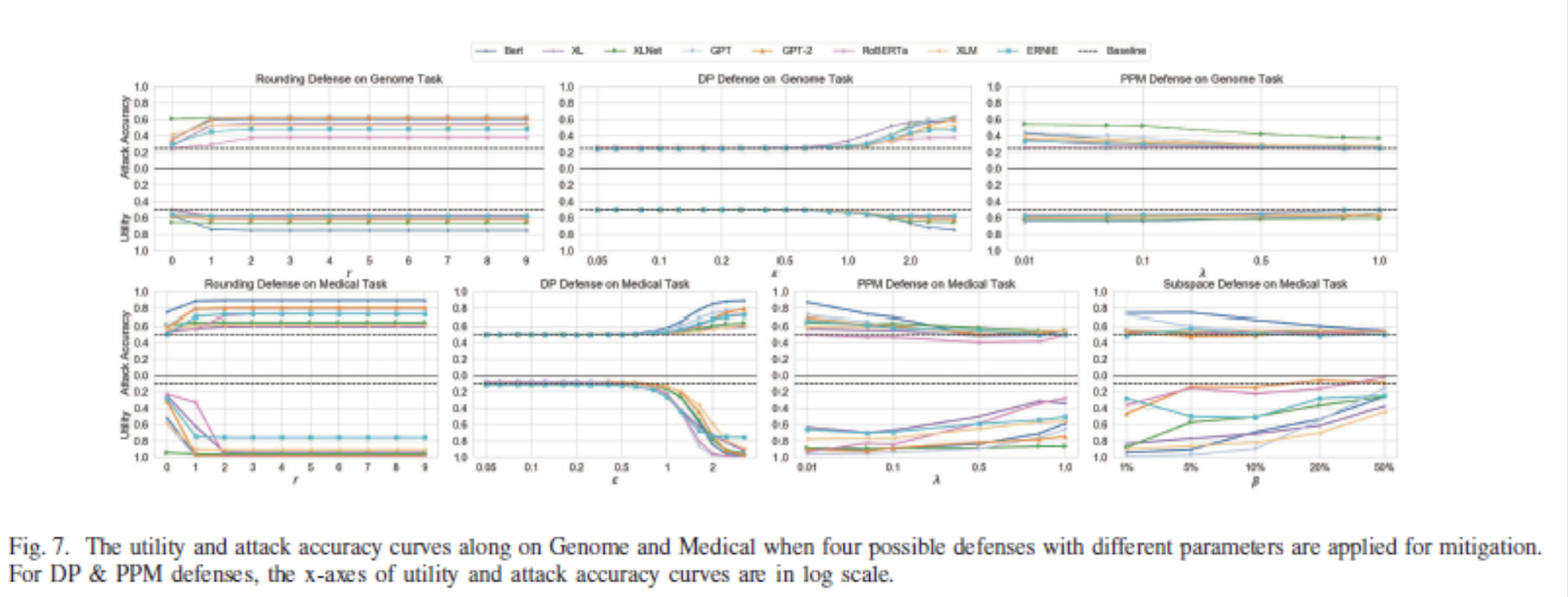
From this study, the authors find 4 main defense strategies that can be used:
-
Rounding
-
Laplace DP
-
Privacy-Preserving Mapping
-
Subspace Projection
In conclusion, the following points made from this study:
-
There are serious risks of leaking private data from training/backend inputs for LLMs.
-
Attacks against even black-box systems are relatively effective without further defensive measures.
-
Existing defenses against keyword inference and pattern-matching attacks on NLP models are possibly sufficient.
- However, awareness and widespread adoption are majorly lacking.
Section 3 Are Large Pre-Trained Language Models Leaking Your Personal Information?

This paper (Huang et al, 2022), explores how pre-trained large language models (PLMs) are prone to leak user information, particularly email addresses, due to PLMs’ capacity to memorize and associate data.


The authors conduct a 2 part attack task. The first part, given an email address context, examines whether the model can recover the email address. The second part queries PLMs for an associated email address, given an owner’s name. For this, the Enron corpus of email dresses and names is used.

This study attempts to measure memorization and associations of PLMs. To measure memorization, the prefix of a sequence is inputted to the PLM. To measure association, four prompts (as shown in the figure above) are used to extract the target email address.
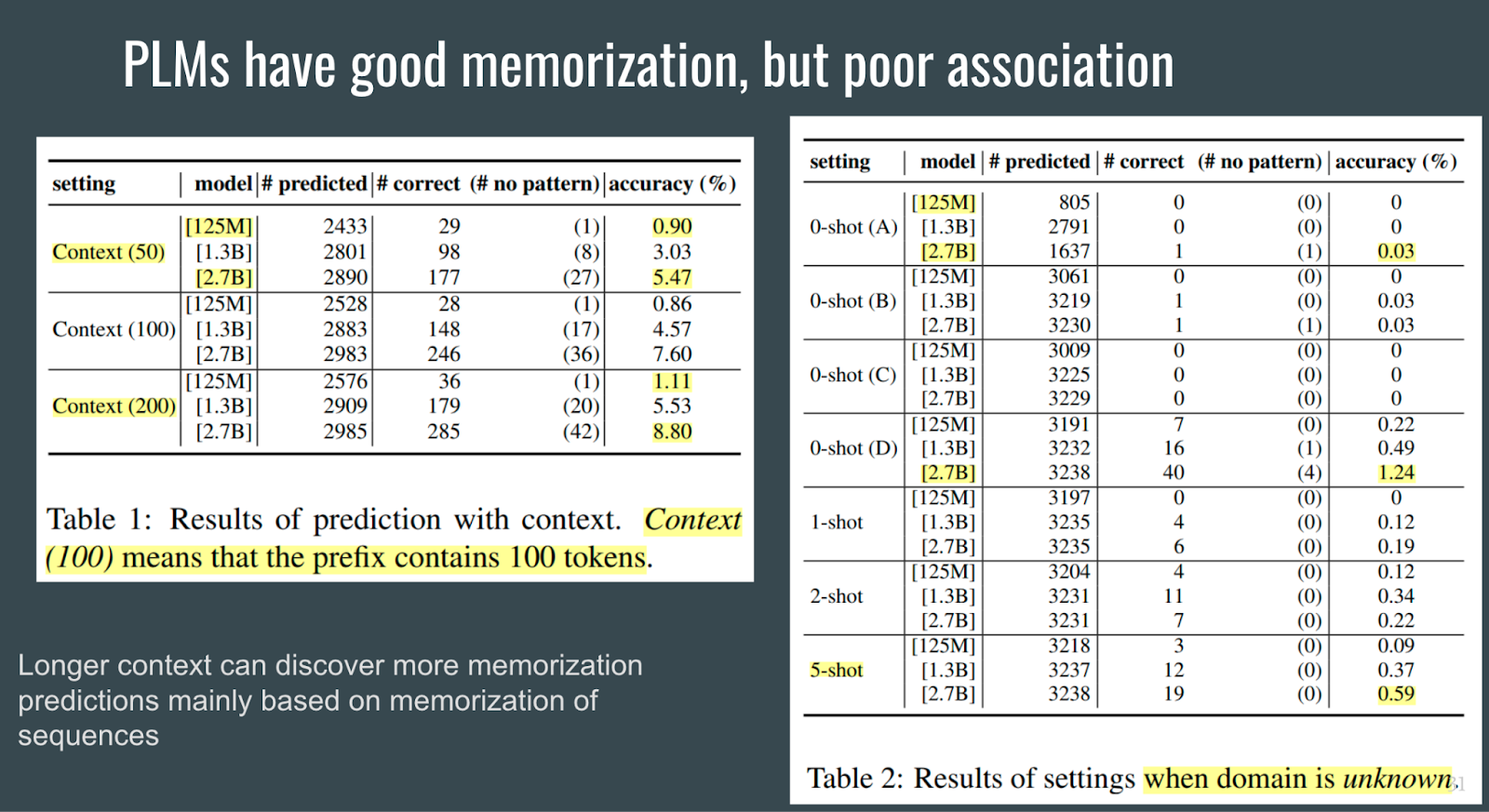
From measuring memorization and association, the authors conclude that PLMs can memorize information well, but cannot associate well.
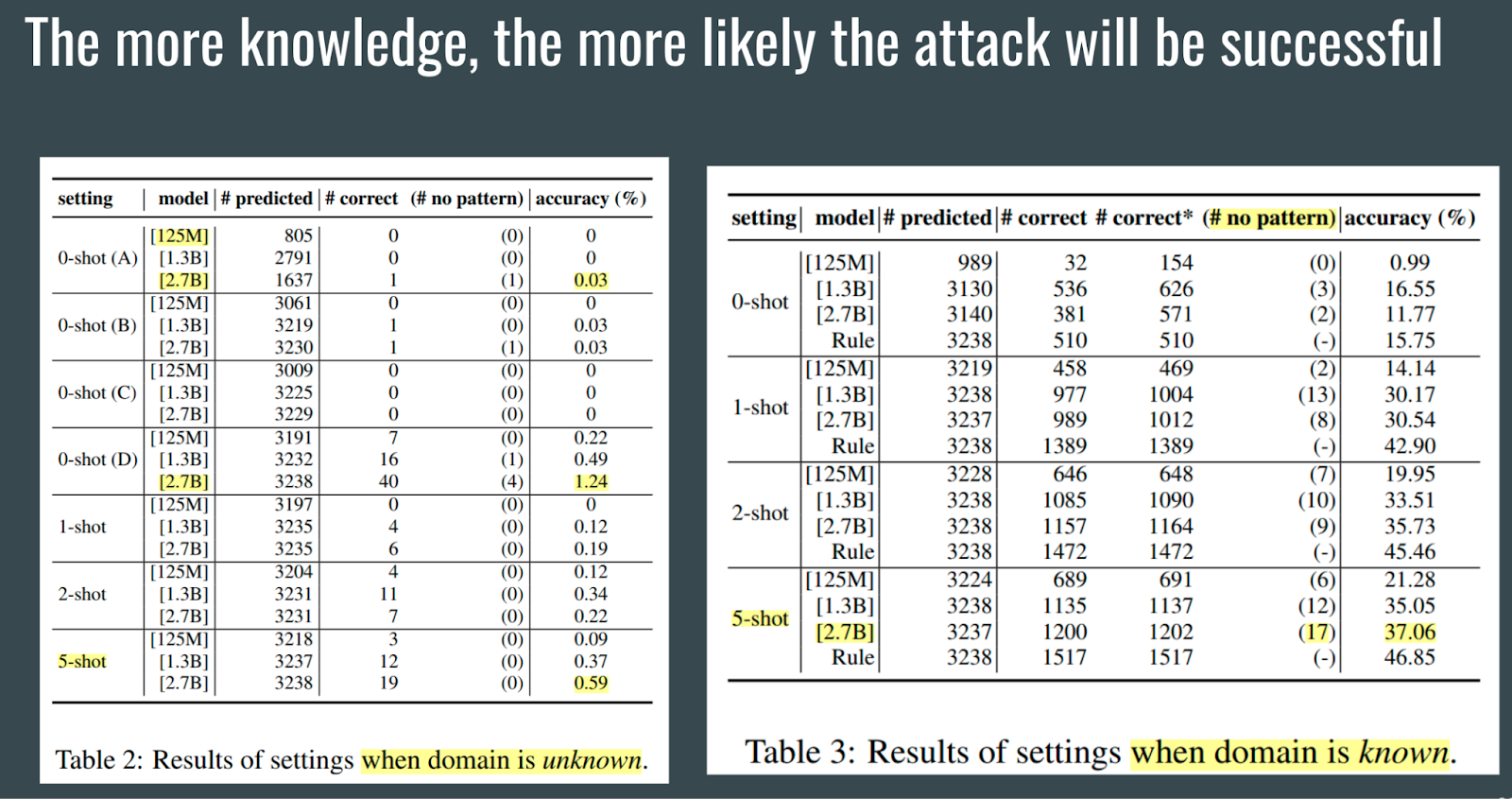
The author’s experiments also show that the more knowledge the PLM gets, the likelihood of the attack being successful increases. The same trend is observed when the PLM is larger.
Despite PLMs being vulnerable to leaking private data, they are still relatively safe when training data is public and private:
-
If the training data is private:
-
Attackers have no access to acquire the contexts.
-
If the training data is public:
-
PLMs cannot improve the accessibility of the target email address since attackers still need to find (e.g., via search) the context of the target email address from the corpus first to use it for prediction.
Additionally, if the attacker already finds the context, they can simply get the email address after the context without the help of PLMs.
To mitigate PLM vulnerabilities the authors recommend pre and post-processing:
-
Pre-processing:
-
Blur long patterns.
-
Deduplicate training data.
-
-
Post-processing:
- Use a module to examine whether the output text contains sensitive information.
The authors conclude that PLMs do leak personal information due to memorization, however, since the models are weak at the association, the risk of specific personal information being extracted by attackers is low.
Section 4 Privacy in Large Language Models: Attacks, Defenses, and Future Directions
“Privacy in Large Language Models: Attacks, Defenses, and Future Directions” (Li et al., 2023) analyzes current privacy attacks on LLMs, discusses defense strategies, highlights emerging concerns, and suggests areas for future research.
There are 3 motivations for this work:
-
Training data includes vast internet-extracted text
-
Poor quality & Leaks PII (personally identifiable information)
-
Violates privacy laws
-
-
Integration of diverse applications into LLMs
-
such as ChatGPT + Wolfram Alpha, ChatPDF, New Bing etc
-
Additional domain-specific privacy and security vulnerabilities
-
-
Studying the trade-off between privacy and utility of all mechanisms.
- DP vs current mechanisms
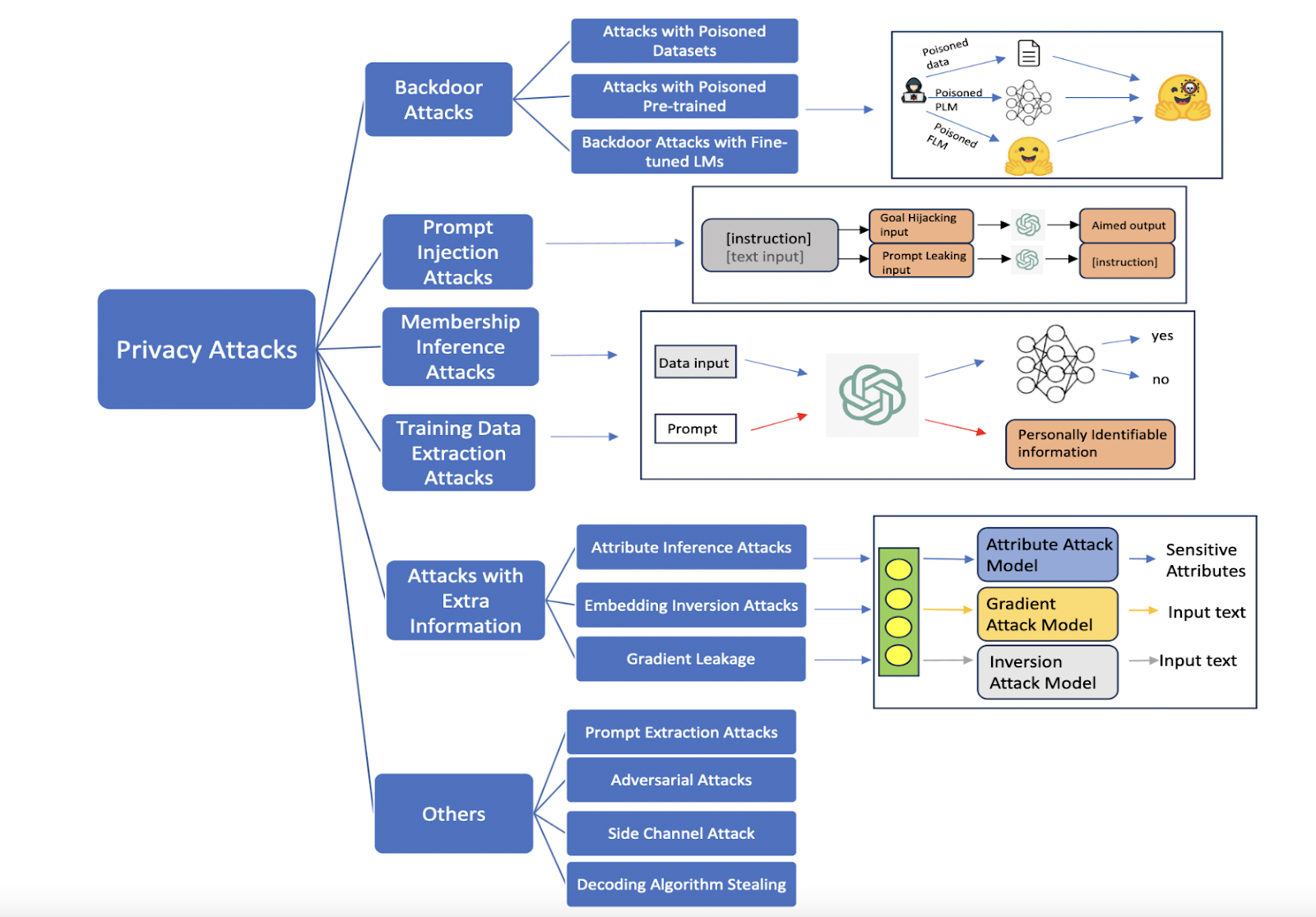
Taxonomy of attacks this paper covers.
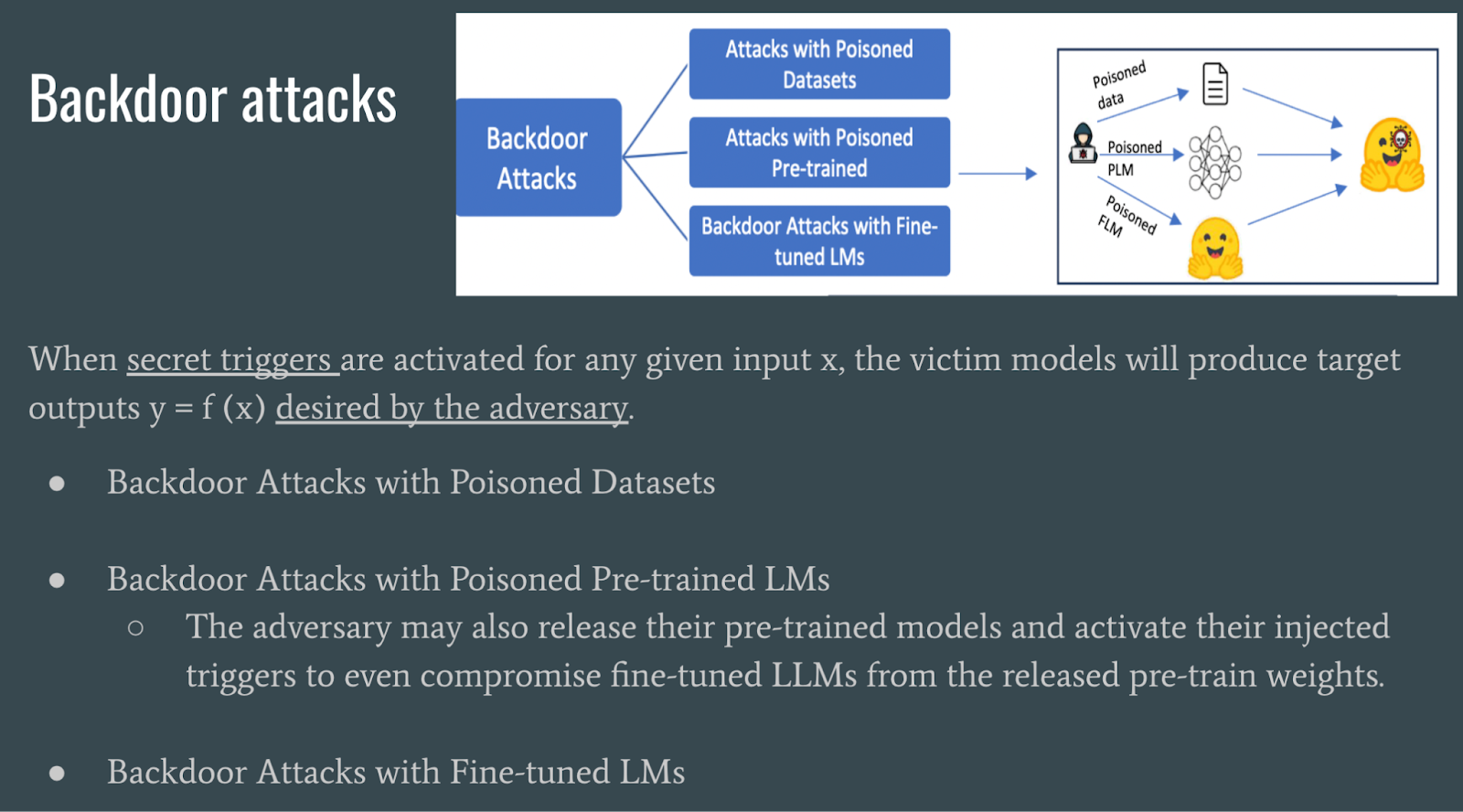
Backdoor attacks involve adversaries activating hidden triggers in models or datasets to manipulate outputs or compromise fine-tuned language models by releasing poisoned pre-trained LLMs.
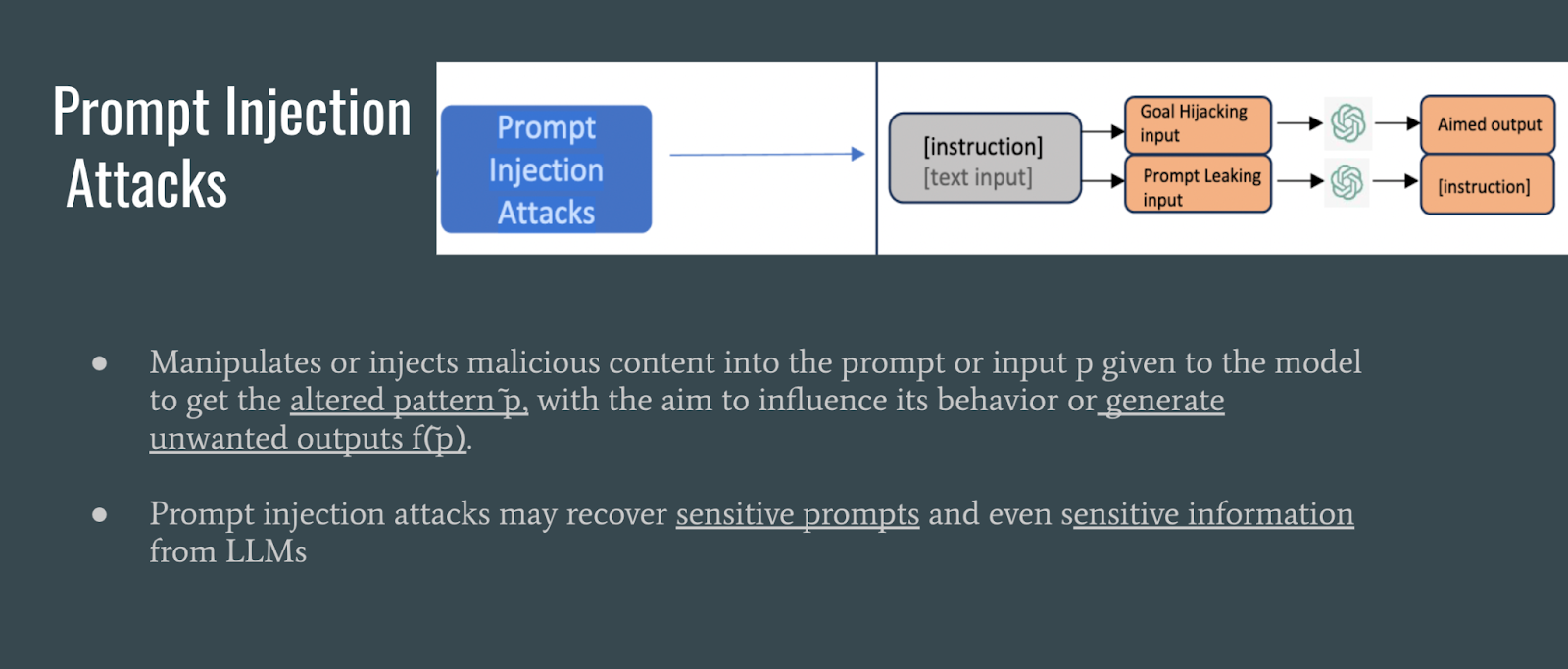
Prompt injection attacks involve injecting or manipulating malicious content into the prompt to influence the model to output an unwanted output.
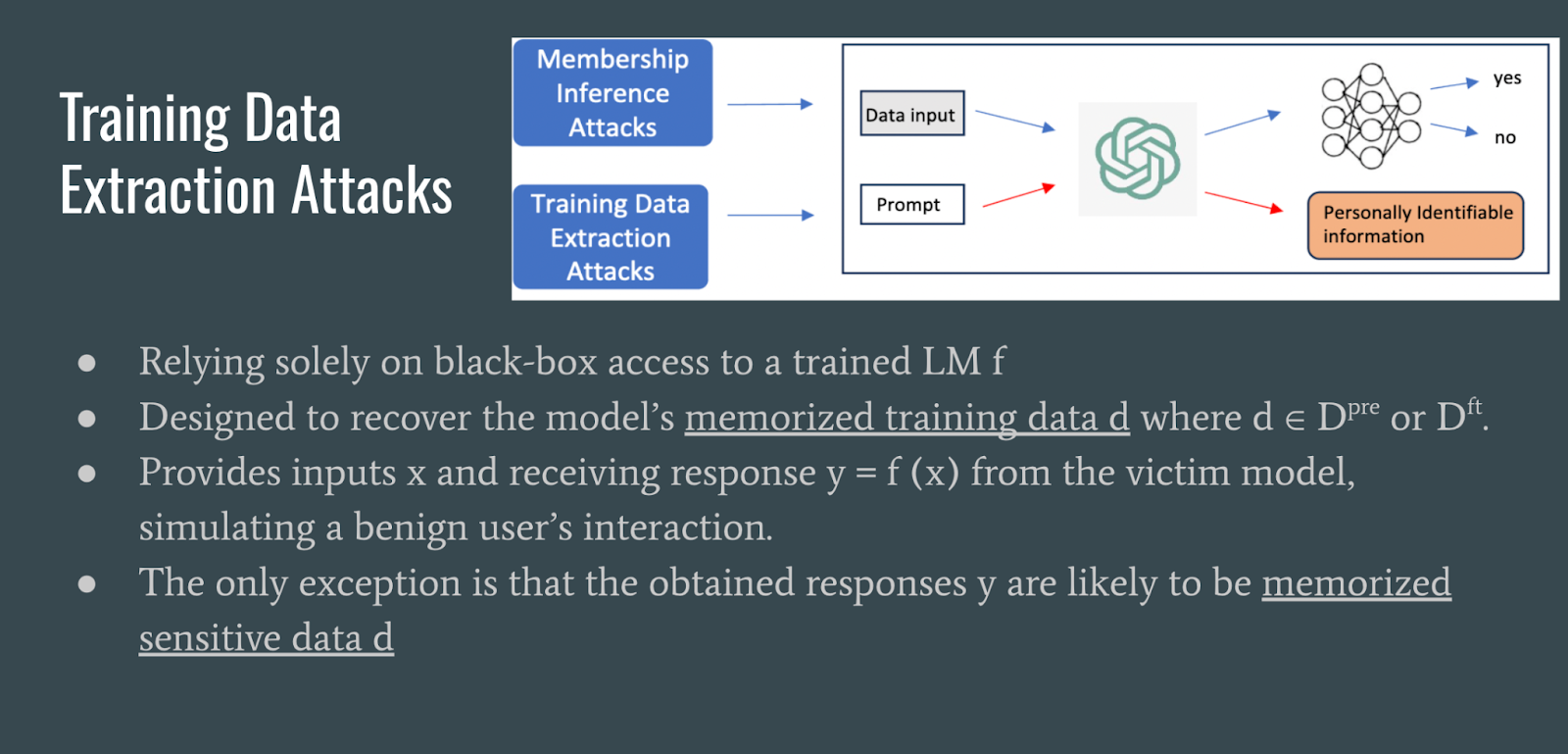
Training data extraction attacks involve prompting the LLM to recover data is likely memorized training data.
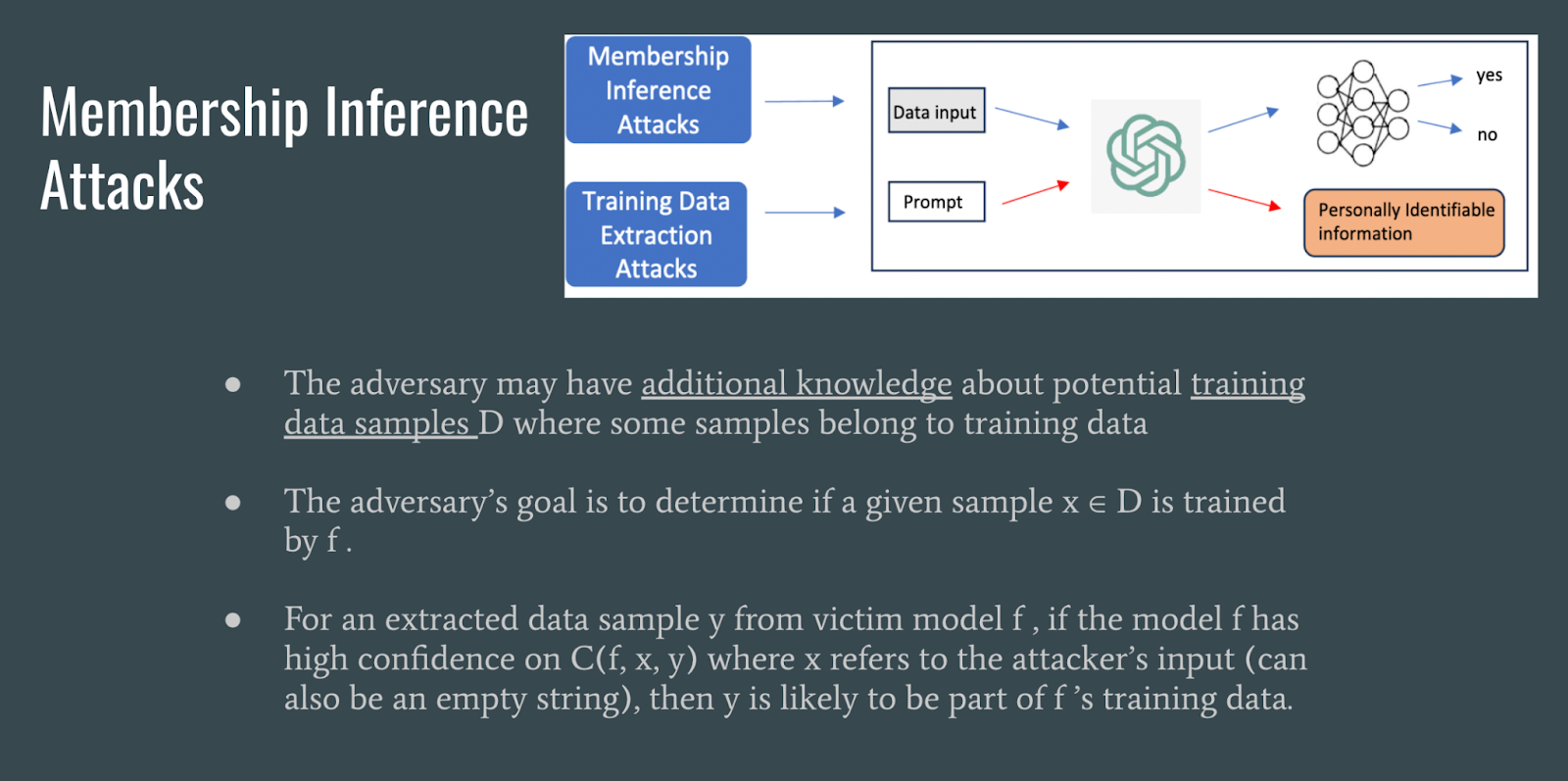
Membership inference attacks are are attacks that attempt to determine a if data was used to train the LLM.
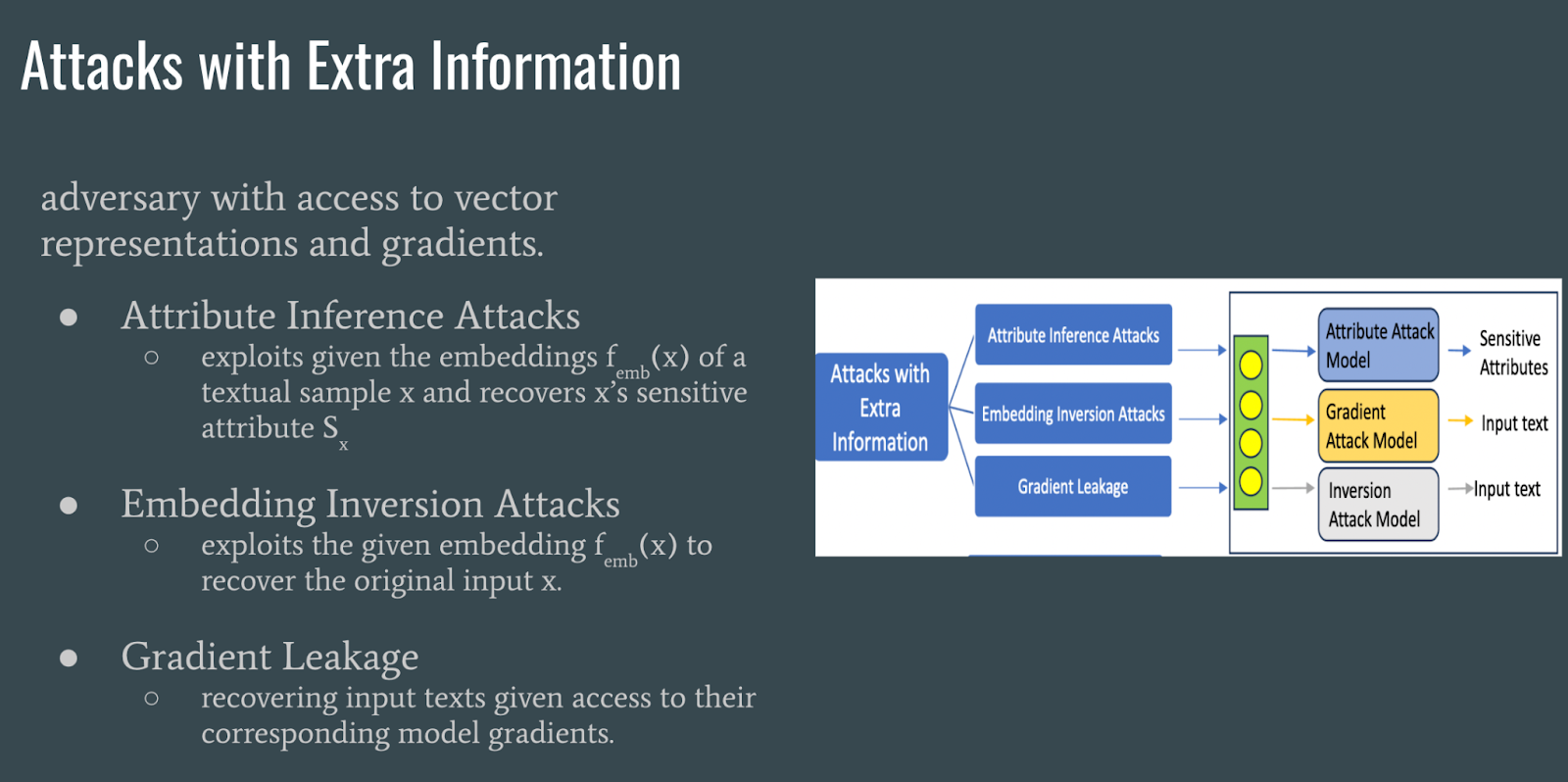
Attacks with extra information use model embeddings to recover an input’s sensitive attributes or to recover the original input of the embedding. Gradient leakage could be used to recover input texts.
Other types of attacks include prompt extraction attacks, adversarial attacks, side channel attacks, and decoding algorithm stealing.
In addition to these attacks the authors also outline some privacy defences.

Federated learning can train LLMs in a collaborative manner without sharing private data.
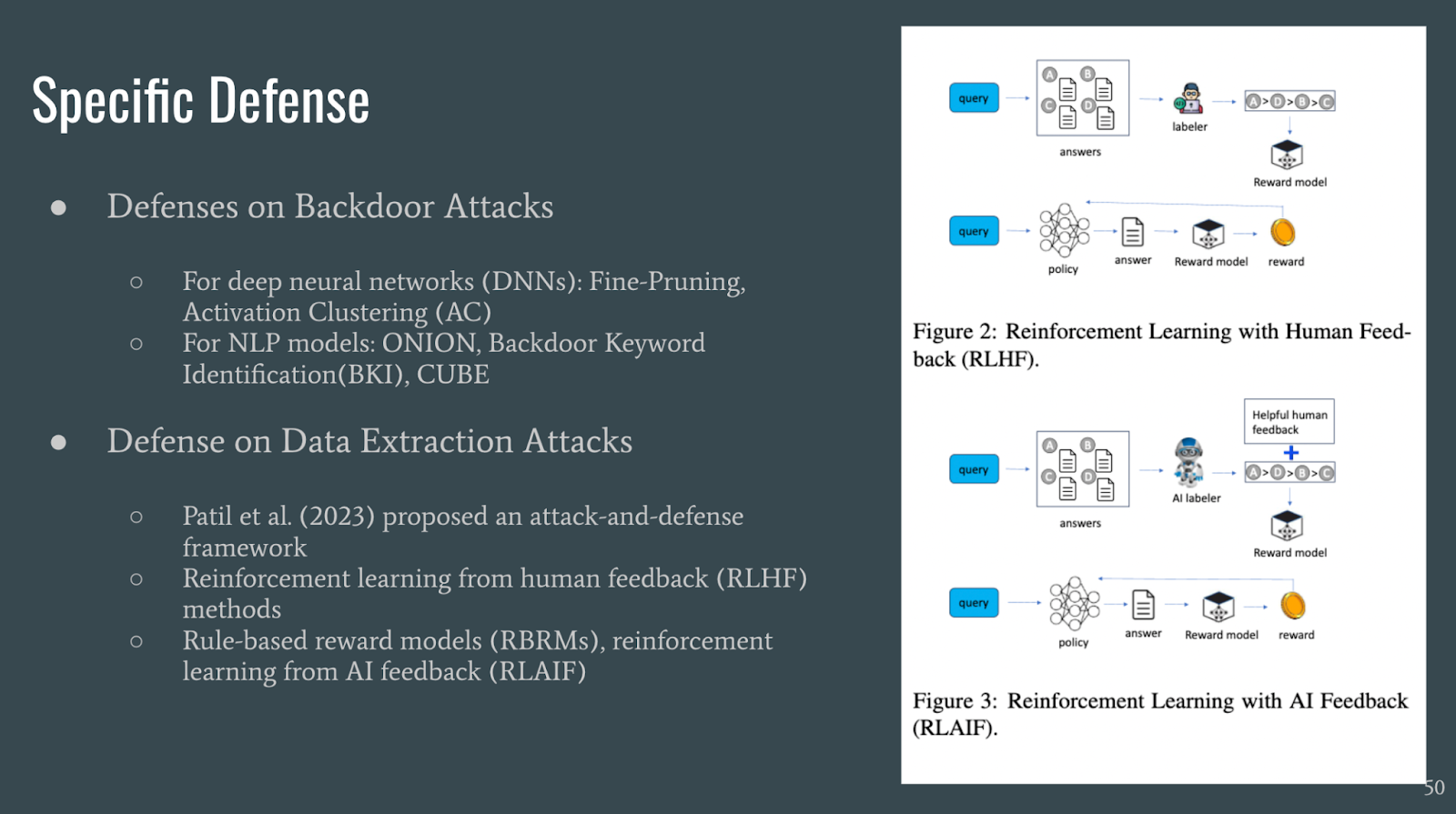
Additionally, defenses can be specific to a type of attack such as backdoor attacks or data extraction attacks.
The authors point out two limitations they observe:
-
Impracticability of Privacy Attacks.
-
Limitations of Differential Privacy Based LLMs
They also recommend the following future works:
-
Ongoing Studies about Prompt Injection Attacks
-
Future Improvements on SMPC (Secure Multi-Party Computation)
-
Privacy Alignment to Human Perception
-
Empirical Privacy Evaluation
In conclusion this survey lists existing privacy attacks and defenses in LMs and LLMs and critiques the limitations of these approaches and suggests future directions for privacy studies in language models.