Prompt Engineering
- SlideDeck: W11-team-2-prompt-engineering-2
- Version: current
- Lead team: team-2
- Blog team: team-6
In this session, our readings cover:
Required Readings:
Unleashing the potential of prompt engineering in Large Language Models: a comprehensive review
- https://arxiv.org/abs/2310.14735
- Banghao Chen, Zhaofeng Zhang, Nicolas Langrené, Shengxin Zhu / This paper delves into the pivotal role of prompt engineering in unleashing the capabilities of Large Language Models (LLMs). Prompt engineering is the process of structuring input text for LLMs and is a technique integral to optimizing the efficacy of LLMs. This survey elucidates foundational principles of prompt engineering, such as role-prompting, one-shot, and few-shot prompting, as well as more advanced methodologies such as the chain-of-thought and tree-of-thoughts prompting. The paper sheds light on how external assistance in the form of plugins can assist in this task, and reduce machine hallucination by retrieving external knowledge. We subsequently delineate prospective directions in prompt engineering research, emphasizing the need for a deeper understanding of structures and the role of agents in Artificial Intelligence-Generated Content (AIGC) tools. We discuss how to assess the efficacy of prompt methods from different perspectives and using different methods. Finally, we gather information about the application of prompt engineering in such fields as education and programming, showing its transformative potential. This comprehensive survey aims to serve as a friendly guide for anyone venturing through the big world of LLMs and prompt engineering.
More Readings:
Skeleton-of-Thought: Large Language Models Can Do Parallel Decoding
- This work aims at decreasing the end-to-end generation latency of large language models (LLMs). One of the major causes of the high generation latency is the sequential decoding approach adopted by almost all state-of-the-art LLMs. In this work, motivated by the thinking and writing process of humans, we propose Skeleton-of-Thought (SoT), which first guides LLMs to generate the skeleton of the answer, and then conducts parallel API calls or batched decoding to complete the contents of each skeleton point in parallel. Not only does SoT provide considerable speed-ups across 12 LLMs, but it can also potentially improve the answer quality on several question categories. SoT is an initial attempt at data-centric optimization for inference efficiency, and further underscores the potential of pushing LLMs to think more like a human for answer quality.
Topologies of Reasoning: Demystifying Chains, Trees, and Graphs of Thoughts
- The field of natural language processing (NLP) has witnessed significant progress in recent years, with a notable focus on improving large language models’ (LLM) performance through innovative prompting techniques. Among these, prompt engineering coupled with structures has emerged as a promising paradigm, with designs such as Chain-of-Thought, Tree of Thoughts, or Graph of Thoughts, in which the overall LLM reasoning is guided by a structure such as a graph. As illustrated with numerous examples, this paradigm significantly enhances the LLM’s capability to solve numerous tasks, ranging from logical or mathematical reasoning to planning or creative writing. To facilitate the understanding of this growing field and pave the way for future developments, we devise a general blueprint for effective and efficient LLM reasoning schemes. For this, we conduct an in-depth analysis of the prompt execution pipeline, clarifying and clearly defining different concepts. We then build the first taxonomy of structure-enhanced LLM reasoning schemes. We focus on identifying fundamental classes of harnessed structures, and we analyze the representations of these structures, algorithms executed with these structures, and many others. We refer to these structures as reasoning topologies, because their representation becomes to a degree spatial, as they are contained within the LLM context. Our study compares existing prompting schemes using the proposed taxonomy, discussing how certain design choices lead to different patterns in performance and cost. We also outline theoretical underpinnings, relationships between prompting and others parts of the LLM ecosystem such as knowledge bases, and the associated research challenges. Our work will help to advance future prompt engineering techniques.
Blog: Unleashing the potential of prompt engineering in Large Language Models: a comprehensive review
Introduction
Models that are built on Large Language Model (LLM) as the backbone are capable of extracting meaningful information that can assist medical diagnosis or creating engaging contents. These models are also referred to as Artificial Intelligence-Generated Content (AIGC). Once the AIGC model is trained, by changing the way we compose the prompts as input to the model, the quality of the model’s output can change. In this paper, we focus on techniques of engineering the prompts to achieve higher quality model output from the same AIGC model.
Basic of Prompt Engineering
One basic technique to improve the model output is to be clear and precise in writing the prompt, see an example from the below figure. When the prompt is vague, since there are numerous ways a model could respond, the model often ends up with a broad response that are less useful. Being more specific in the prompt can guide it towards the response that we are looking for.
Role-playing is another basic technique that is effective in improving the model output. Prompting the model to role-play as an historian may improve the model’s output when the question is related to a historical event. Prompting the model to role-play as an expert in AI may have a similar positive effect when the question is about LLM.
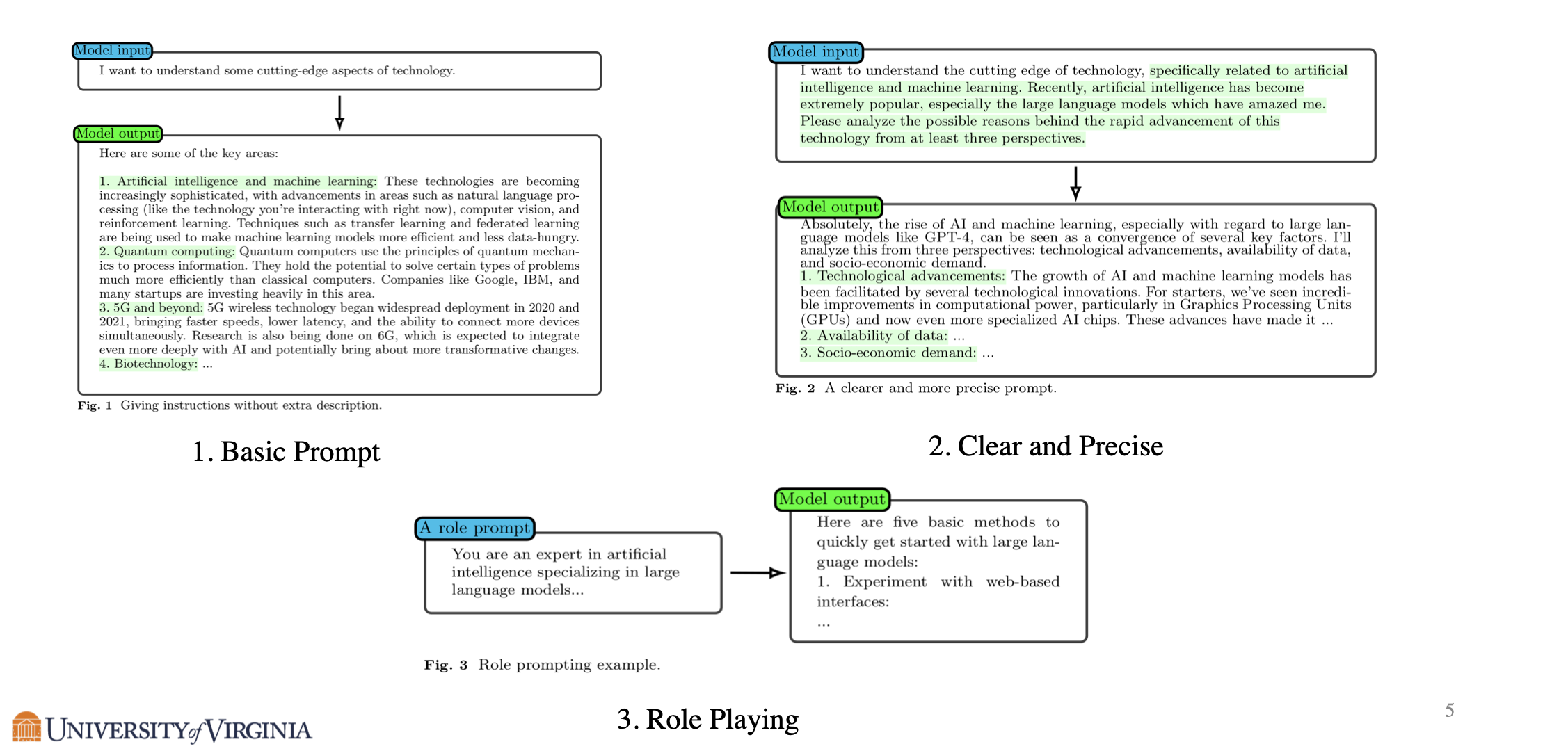
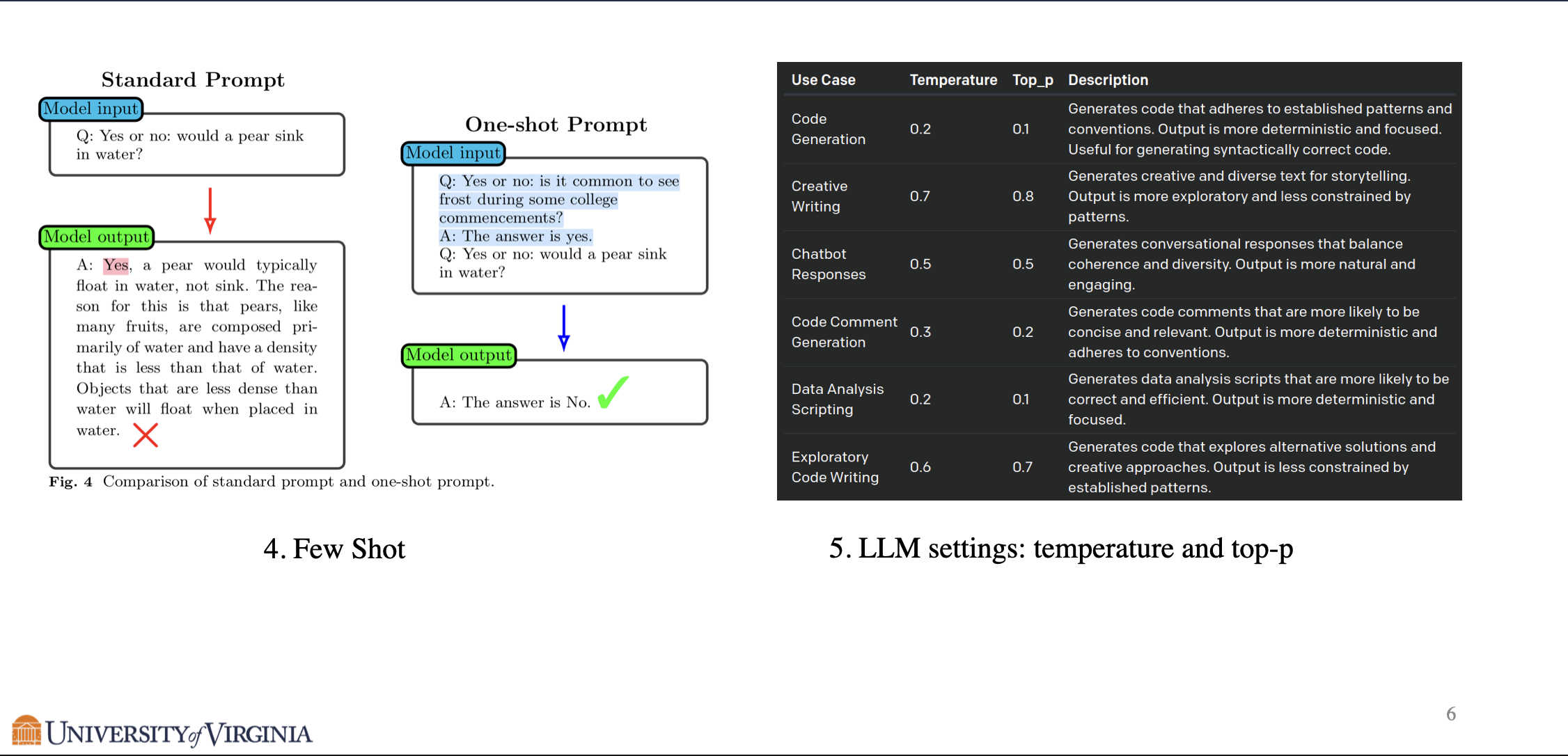
Few Shot prompting is also a common prompt engineering technique, where the model is given a few examples with answers in addition to the original question. This relies on the few shot learning ability that is emergent in large language models, which can be understood as a form of meta learning.
Authors of the paper also note that adjusting the temperature and top-p is essential for prompt engineering. For code generation where standard pattern is valued, a smaller temperature and top-p is preferred, whereas in creative writing, a larger temperature and top-p may help the model produce original responses.
Advanced Prompt Engineering
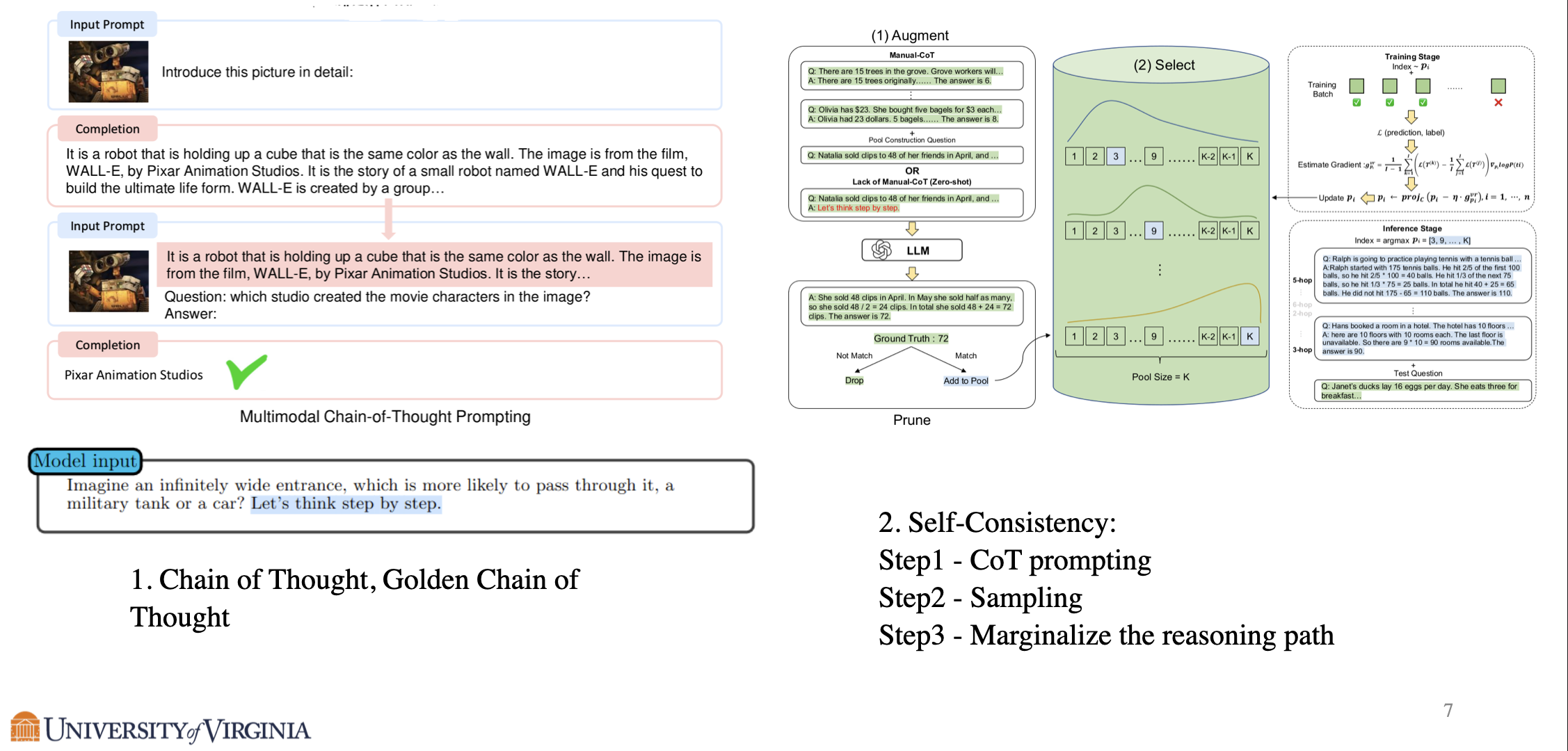
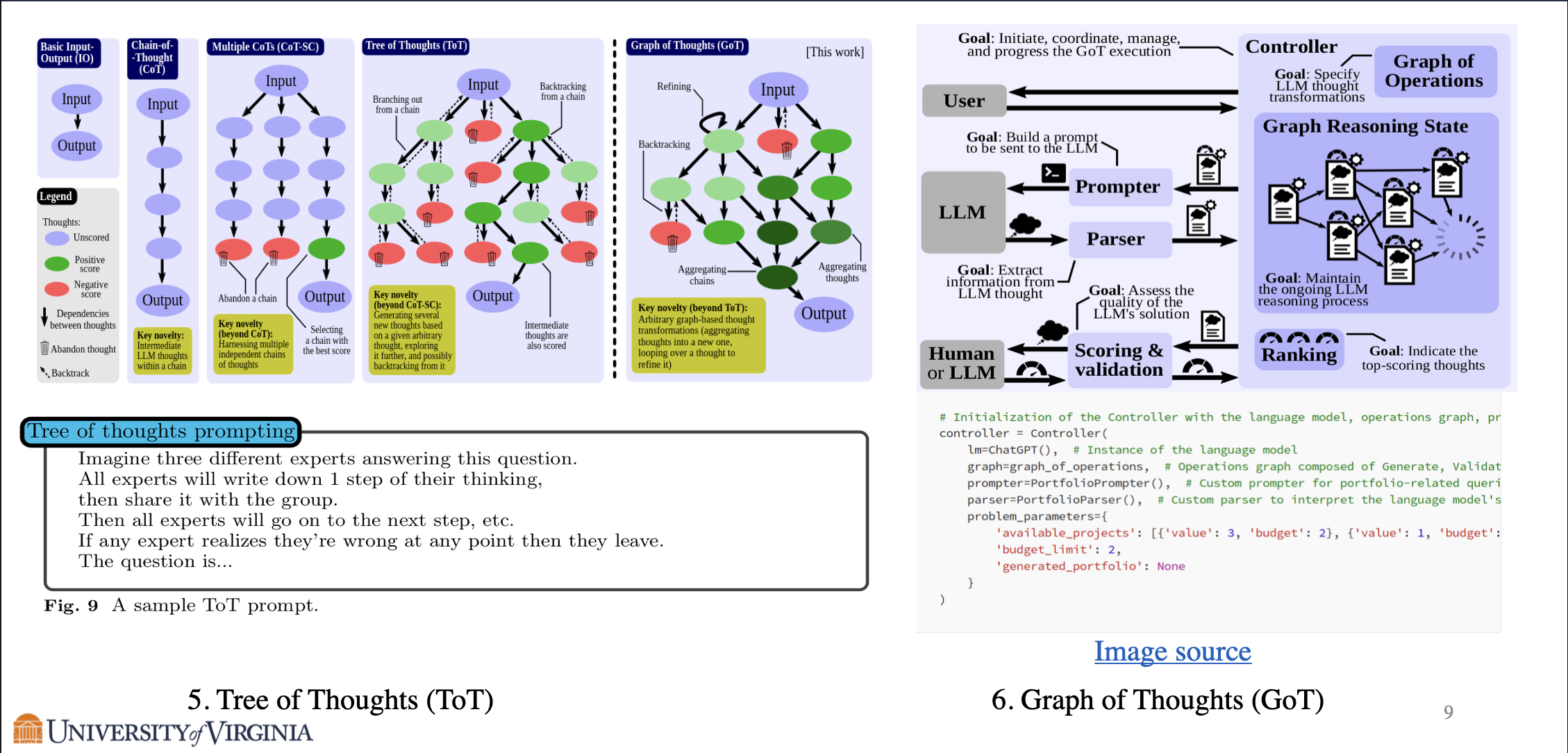
Chain of Thought prompting induces the model to respond with step by step reasoning, which not only improves the quality of the output, but also shows correct intermediate steps for high stake applications such as medical reasoning. Zero-shot chain of thought is a simple yet effective technique, where we only need to include the phrase “Let’s think step by step” to the input. Golden chain of thought is a technique that utilizes few-shot prompting for chain of thought prompting, by providing ground truth chain of thoughts solutions as examples to the input of the model. Golden chain of thoughts can boost the solve rate from 38% to 83% in the case of GPT-4, but the method is limited by the requirement of ground truth chain of thoughts examples.
Self-Consistency is an extension to chain of thought prompting. After chain of thought prompting, by sampling from the language model decoder and choosing the most self-consistent response, Self-Consistency achieves better performance in rigorous reasoning tasks such as doing proofs.
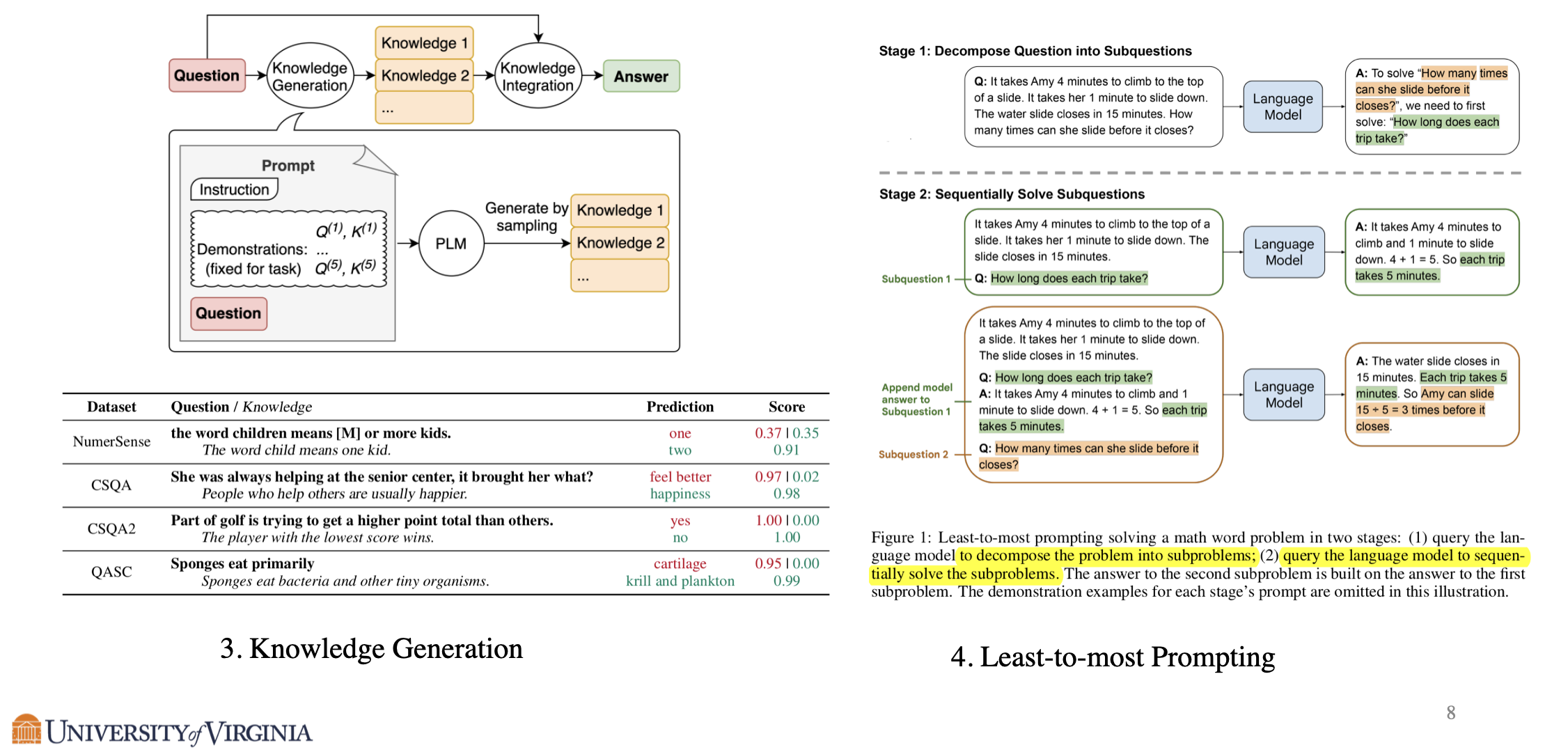
Knowledge Generation breaks down the content generation into two step generations: in the first step generation, the model is only prompted to output pertinent information (knowledge) of the original query, then the knowledge is included as prompt in the second step generation.
Least-to-most prompting also takes a multi-step generation approach similar to knowledge generation. A given problem is decomposed into numerous sub-problems, and the model will output responses for each sub-problem. These responses will be included in the prompt to help the model answer the original problem.
Tree of Thoughts reasoning constructs the steps of reasoning in a tree structure. This is particularly helpful when we need to break down a problem into steps, and further break down of each steps into more steps. Graph of Thoughts is a generalization of tree of thought structure, where each each contains the relation between each node. Graph of thoughts may be helpful for problems requiring intricate multifaceted resolutions.
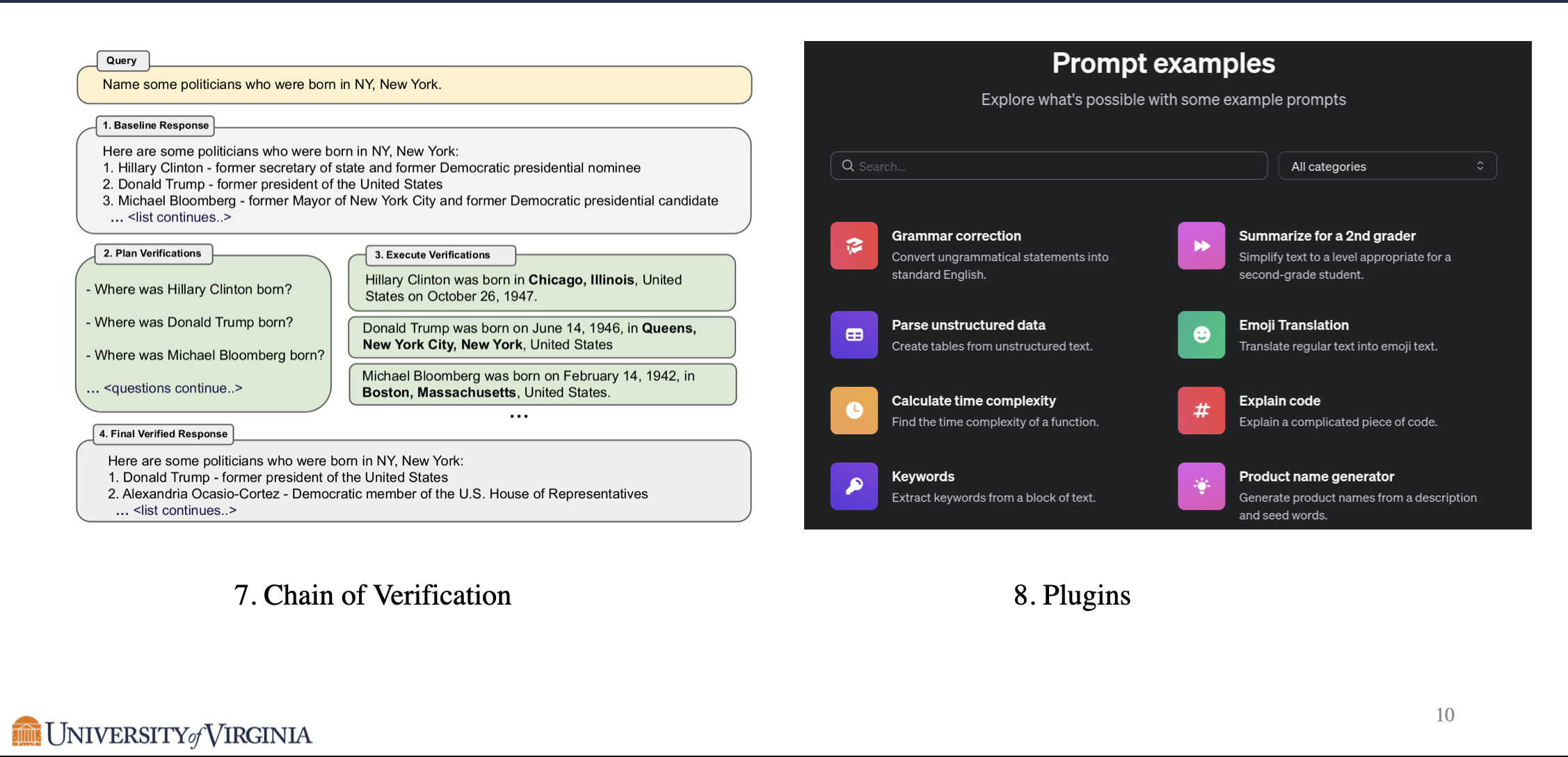
Chain of Verification corrects a response that may contain false information, by prompting the LLM to ask verification questions for the response. LLM may correct the false information by answering the verification questions. These answers will help LLM to generate a more accurate response for the original query.
In addition to the specific techniques mentioned above, there also exist Plug-ins of ChatGPT such as Prompt Enhancer that automatically enhance the prompt for the user.
Accessing the Efficacy of Prompt Methods
Benchmarking the prompt methods requires evaluating the quality of response from LLM, which can be performed by human or by other metrics.
Subjective evaluations requires human evaluators, which has the advantage of evaluating fluency, accuracy, novelty, and relevance, and some of its disadvantages are the inconsistency problem, expensive, and time consuming.
Objective evaluations relies on metrics to evaluate the response. Some examples includes BLEU, which is a biLingual evaluation and BERTScore, which relies on a BERT Model for the metric.
Objective evaluations has pros such as automatic evaluation, cheap, quick and cons particularly about the alignment problem.
Evaluation results from InstructEval shows that in few shot settings, once the examples are specified, providing additional prompt harms the performance, while in zero shot settings, the expert written prompt improves performance.
Application of Prompt Engineering
Prompt engineering can help Assessment in teaching and learning, where tailored prompts can set the pace for the student. Zero-shot prompting can generate elements such as settings, characters and outlines, allowing for content creation and editing. In the domain of computer programming, self-debugging prompting outperforms other text-to-SQL models and minimizes the number of attempts. Prompted engineering also significantly reduces error rate when applied to reasoning tasks. Finally, prompt engineering can also support dataset generation, where LLm can be prompted to generate smaller datasets for training domain specific models.
Long context prompting for Claude 2.1
- https://www.anthropic.com/news/claude-2-1-prompting
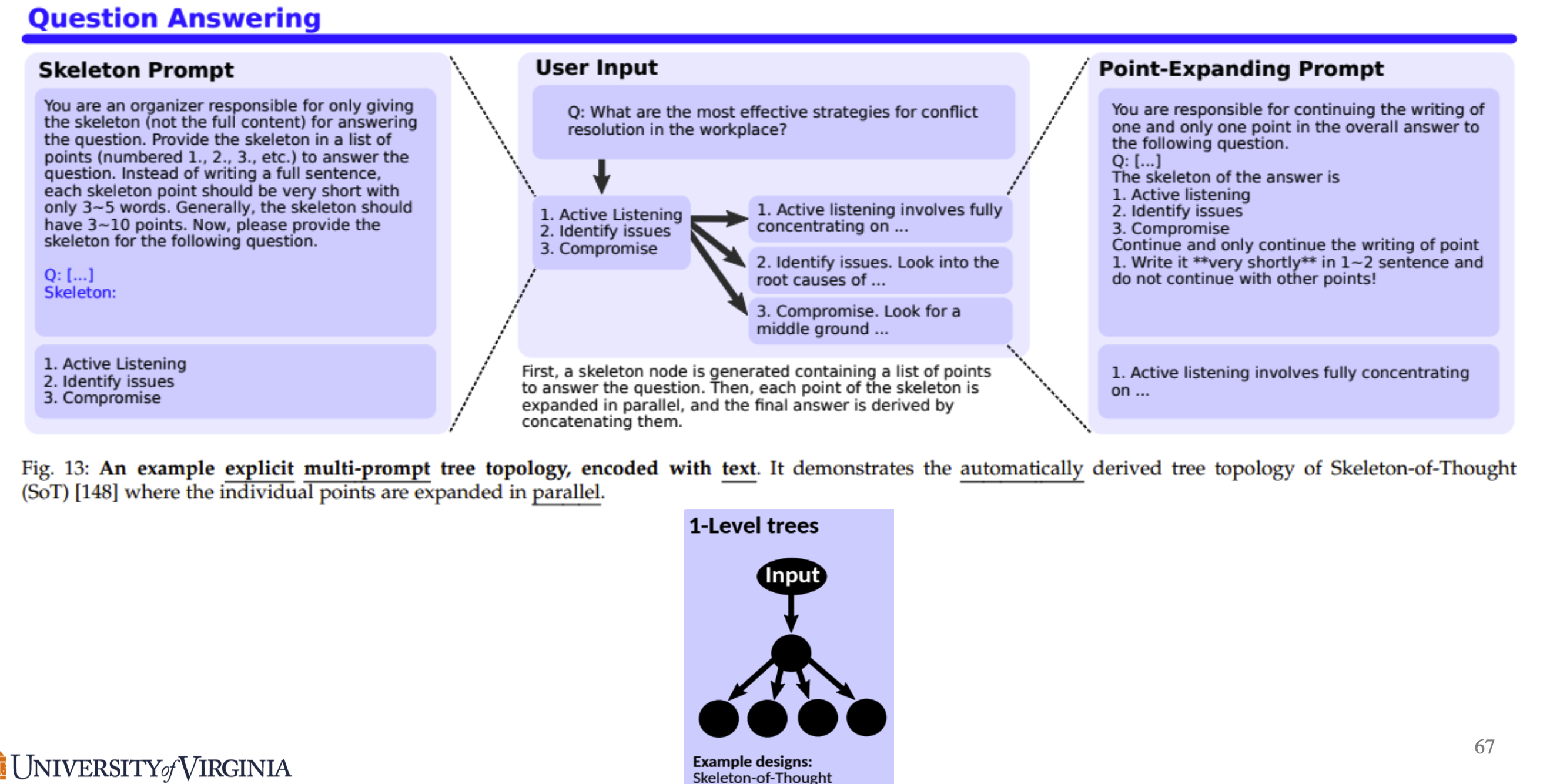
Skeleton Of Thought: Prompting LLMs For Efficient Parallel Generation
Motivation
LLMs have powerful performance, but the inference speed is low due to :
- Large model size
- Expensive attention operation
- The sequential decoding approach
Existing work either compress/redesign the model, serving system, hardware.
This work instead focus on the 3rd axis and propose Skeleton Of Thought for efficient parallel decoding without any changes to LLM models, systems and hardwares.
High-level Overview
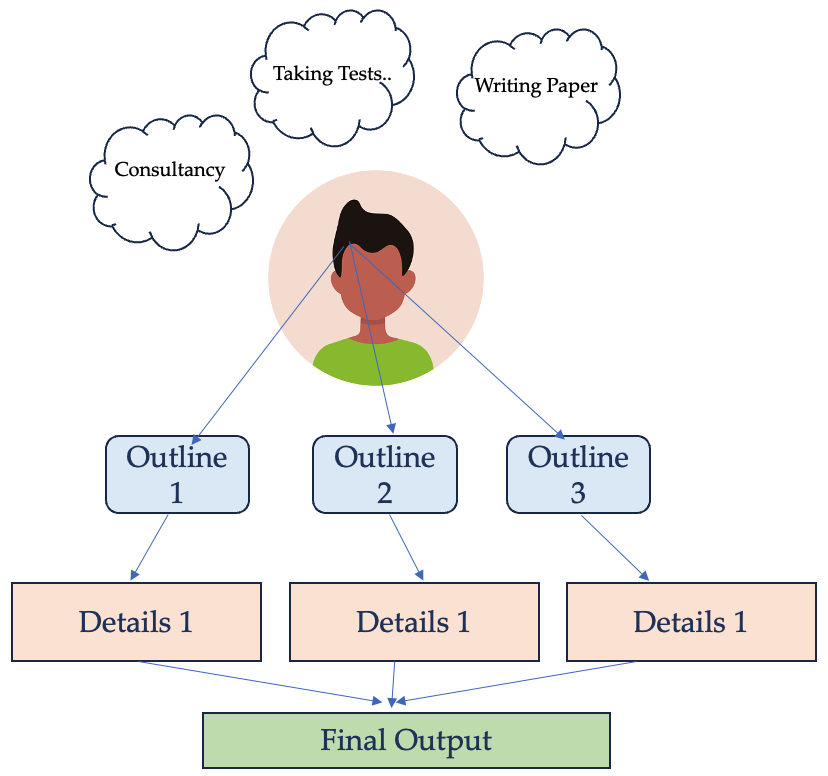
The idea comes from how humans answer questions. Steps of human thoughts can be summarized as below:
- Derive out the skeleton according to protocals and strategies.
- Add evidence and details to explain each point. If we visualize these steps, it looks like:
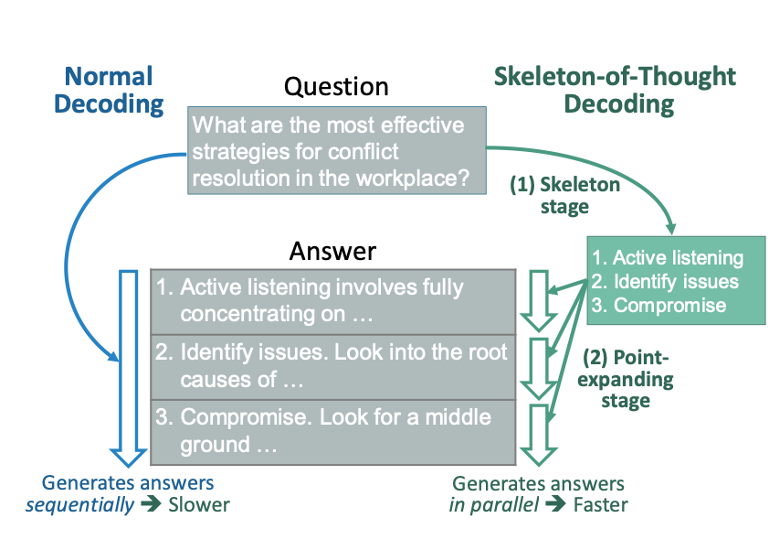
Based on this, this paper proposed Skeleton-of-Thought as shown in Figure below which includes 3 steps:
- Prompt the LLM to give out the skeleton.
- Conduct batched decoding or parallel API calls to expand multiple points in parallel.
- Aggregate the outputs to get final answer.
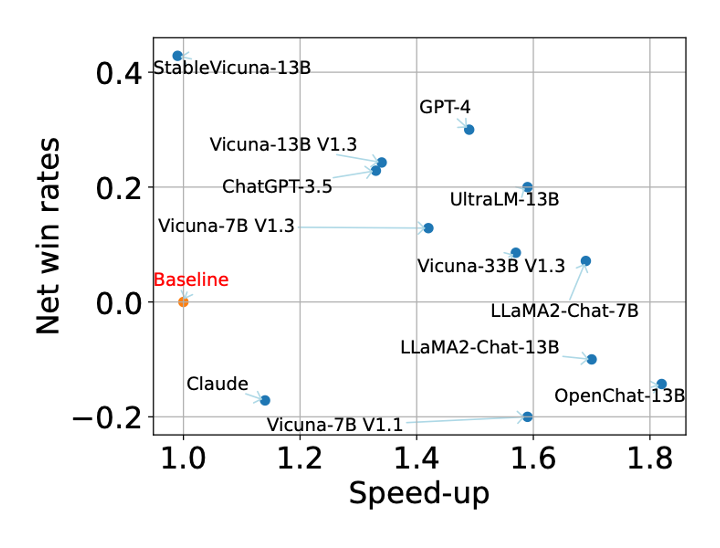
Compared with 12 recently released LLMs, SoT can not only provide considerable speed-ups but also improve the answer quality as shown in figure below.
The y-axis net win rate is the difference between the fraction of questions that SoT-R has better and worse answers than normal generation.
The x-axis speed-up is the ratio between the latency of normal and SoT-R generation.
Method
The method of SoT has two stages: skeleton stage and point-expanding stage.
Skeleton Stage
In skeleton stage, SoT uses a skeleton prompt to guide the LLM to output a concise skeleton of the answer so that we can extract some points from the skeleton response. A prompt example is shown in Figure below.

Point-expanding Stage
Based on the skeleton, SoT uses point-expanding prompt to let LLM expand on each point in parallel. A prompt example is shown in Figure below. After completing all points, SoT concatenate all the point-expanding responses to get the final answer.

Parallelization
The authors use parallel point expanding to achieve speed-up than normal decoding. In specific:
- For proprietary models with only API access, parallelization is achieved by issuing multiple API calls.
- For open-source models that we can run locally, parallelization is achieved by letting LLMs process point-expanding requests as a batch.
Evaluation – Overall Quality
For the evaluation, we can assess it from various perspectives.
-
Evaluation Process:
- Present a question and a pair of answers to an LLM judge.
-
LLM-based evaluation frameworks:
-
FastChat: general metric.
-
LLMZoo: general metric plus 5 detailed metrics - coherence, diversity, immersion, integrity, and relevance.
-
-
Extensions to avoid evaluation bias:
-
Running the evaluation twice with either ordering of the two answers
-
For each run, a score is assigned: 1 – win; 0 – tie; -1 – lose
-
Sum the two scores to get the final score
-
-
Net win rates:
- (#win - #lose)/total number of questions
Evaluation – Evaluation of Answer Quality
-
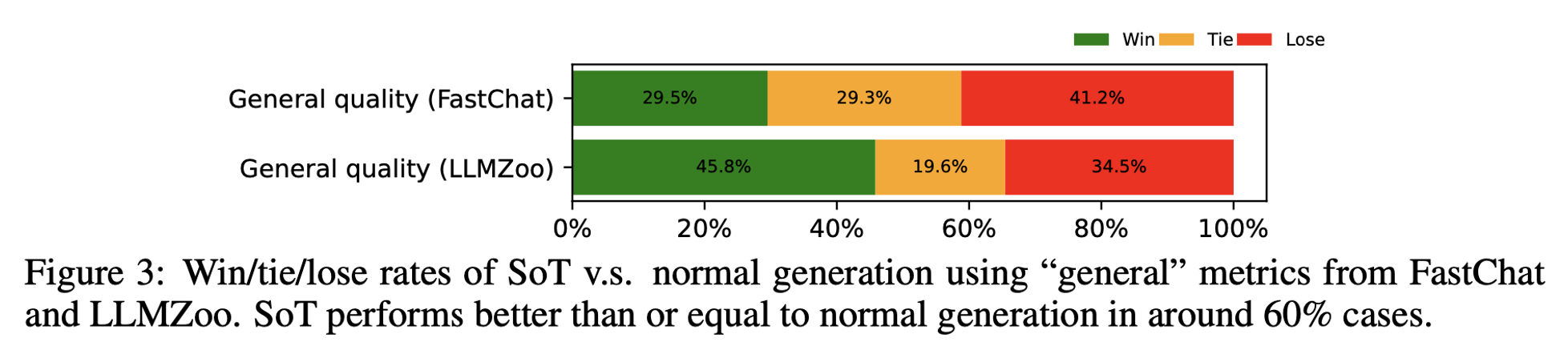
Regarding Overall Quality, based on the figure provided, we can conclude:
-
There is a discrepancy between the two metrics on win rates.
-
SoT is not worse than the baseline in around 60% of the cases.
-
The lose rates are also pretty high.
-
-
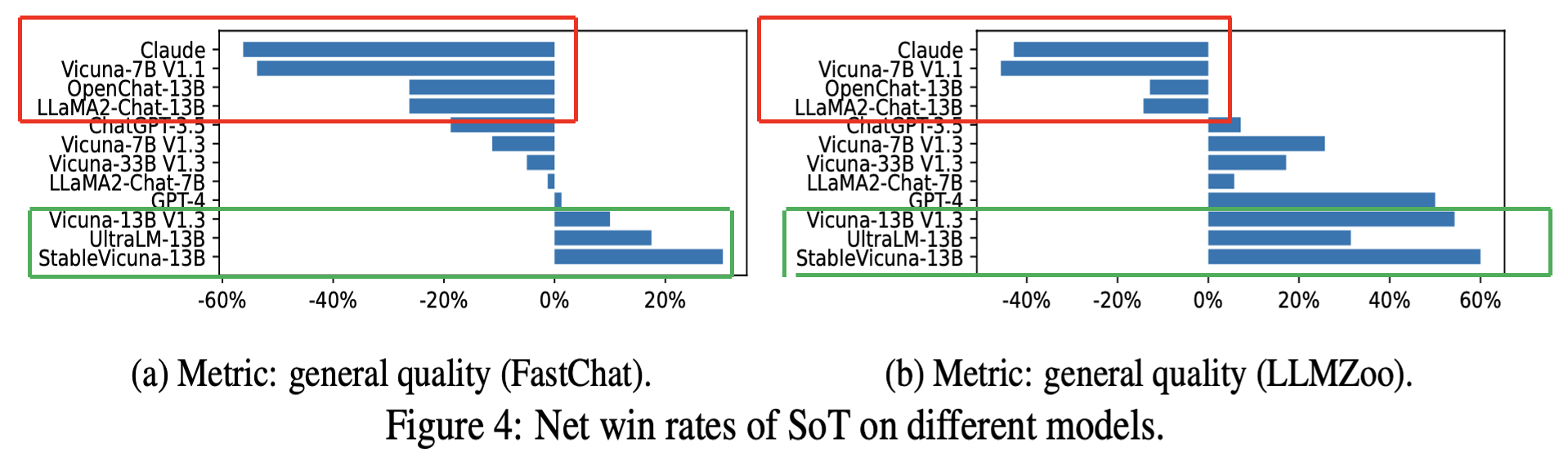
Regarding the quality of each model, the conclusions drawn from the figure indicate:
-
The red rectangular frame in the figure highlights: Both metrics agree that OpenChat-13B, Vicuna-7B V1.1, Claude, LLaMA2-Chat-13B have negative net win rates.
-
The green rectangular frame in the figure highlights: Vicuna-13B V1.3, StableVicuna-13B, and UltraLM-13B have positive net win rates.
-
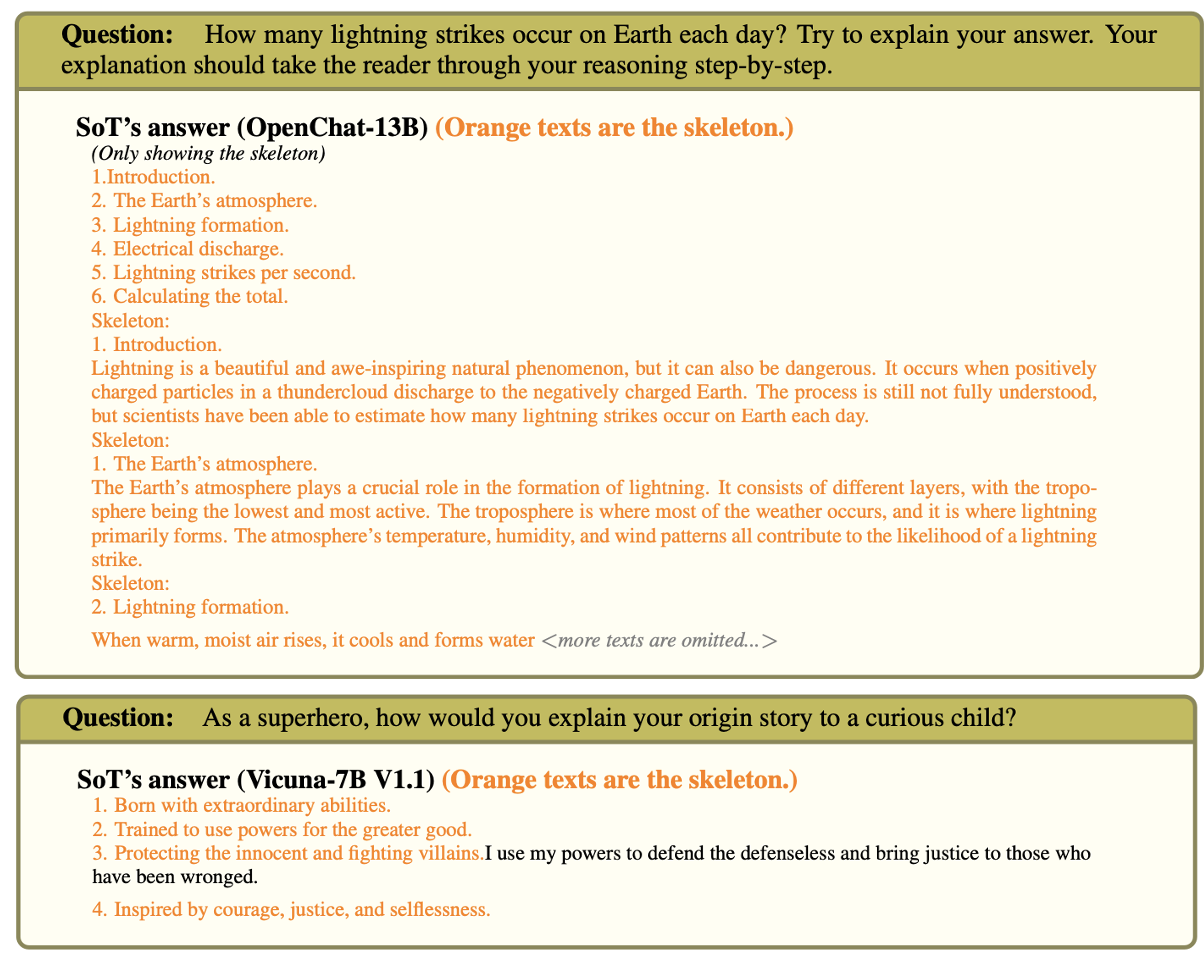
- Based on the figure, the reasons for bad net win rates can be identified as follows:
The question and answer provided by OpenChat-13B in the figure demonstrate that models construct the complete answer during the skeleton stage. And the figure showing the question and answer from Vicuna-7B V1.1 illustrates that models omit details during the point-expanding stage.
In summary, some strong models have very high-quality answers that are hard to beat.
-
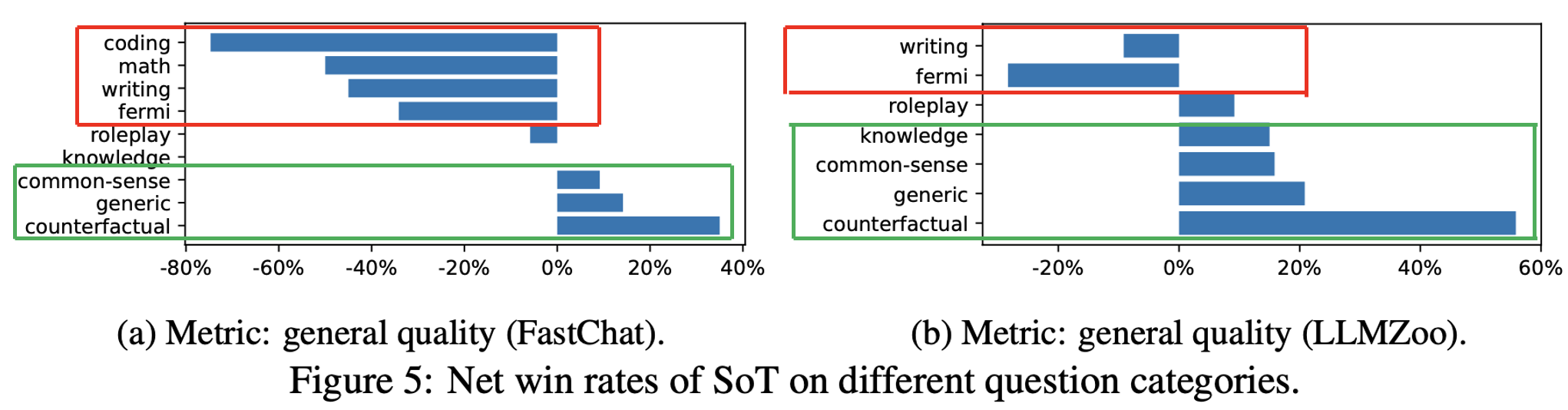
Regarding the quality of each question category, our conclusions from the figure are:
-
The green rectangular frame in the figure highlights: SoT performs relatively well on generic, common-sense, knowledge, and counterfactual questions.
-
The red rectangular frame in the figure highlights: Relatively poorly on writing, fermi, math, and coding.
-
-
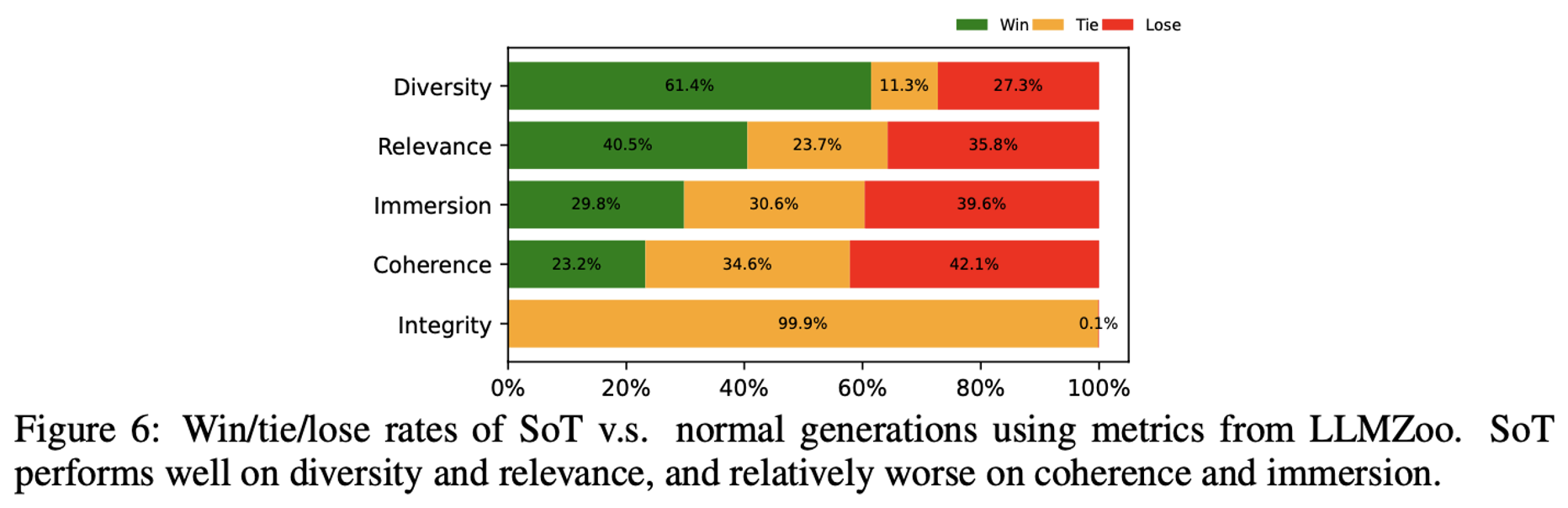
Concerning the Quality of Detailed Metrics, the information from the figure reveals:
- SoT improves the diversity and relevance while hurting the immersion and coherence.
SoT-R – Definition and Framework
-
Prompting Router:
- Ask the LLM if the desired answer is in a list of independent points.

-
Trained Router:
-
Annotate the LIMA training set: a label of 1 or 0.
-
Fine-tune a RoBERTa model using the labeled data.
-
Ask the RoBERTa to classify if the SoT is suitable for the desired answer.
-
SoT-R – Evaluation
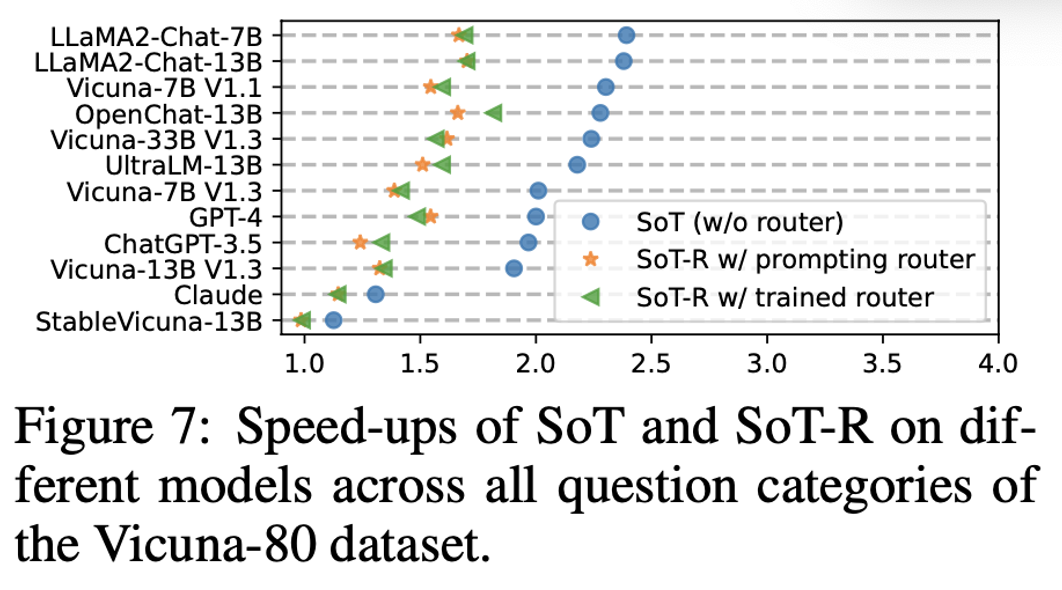
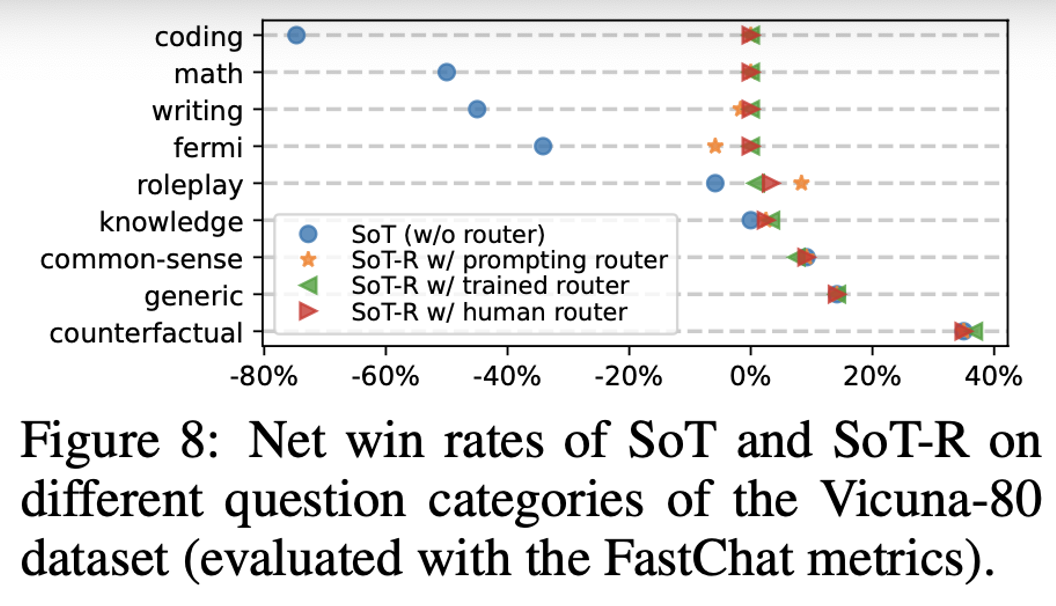
Based on the provided figures, we can understand:
-
SoT-R obtains lower speed-ups than SoT.
-
SoT-R significantly improves the answer quality on questions where SoT is not suitable.
-
The two types of SoT-R perform similarly to a human router.
Conclusion
Having thoroughly reviewed the paper, we’ve gained significant insights into the Skeleton of Thought concept. From this, we can derive several conclusions, each from a unique perspective:
-
Efficient LLM methods at model and system levels:
- SoT is a data-level technique.
-
Prompting methods for LLMs:
- SoT is the first attempt at exploiting the power of prompting to improve efficiency.
-
Answer quality evaluation:
- The answer quality evaluation is far from perfect due to the limited prompt set, the potential bias of GPT-4 judges, and the inherent difficulty of evaluating LLM generations.
-
Efficiency and overhead of SoT in different scenarios:
- higher costs due to the increased number of API calls and tokens.
- computation overhead
-
Eliciting or improving LLMs’ ability:
- Graph-of-Thoughts
Topologies of Reasoning: Demystifying Chains, Trees, and Graphs of Thoughts
Evolving into Chains of Thought
In the exploration of reasoning and cognitive processes, the paper delves into the intricacies of how thoughts are structured, leading to the conceptualization of reasoning topologies. These topologies provide a framework for understanding the organization and flow of thoughts as individuals tackle various tasks.
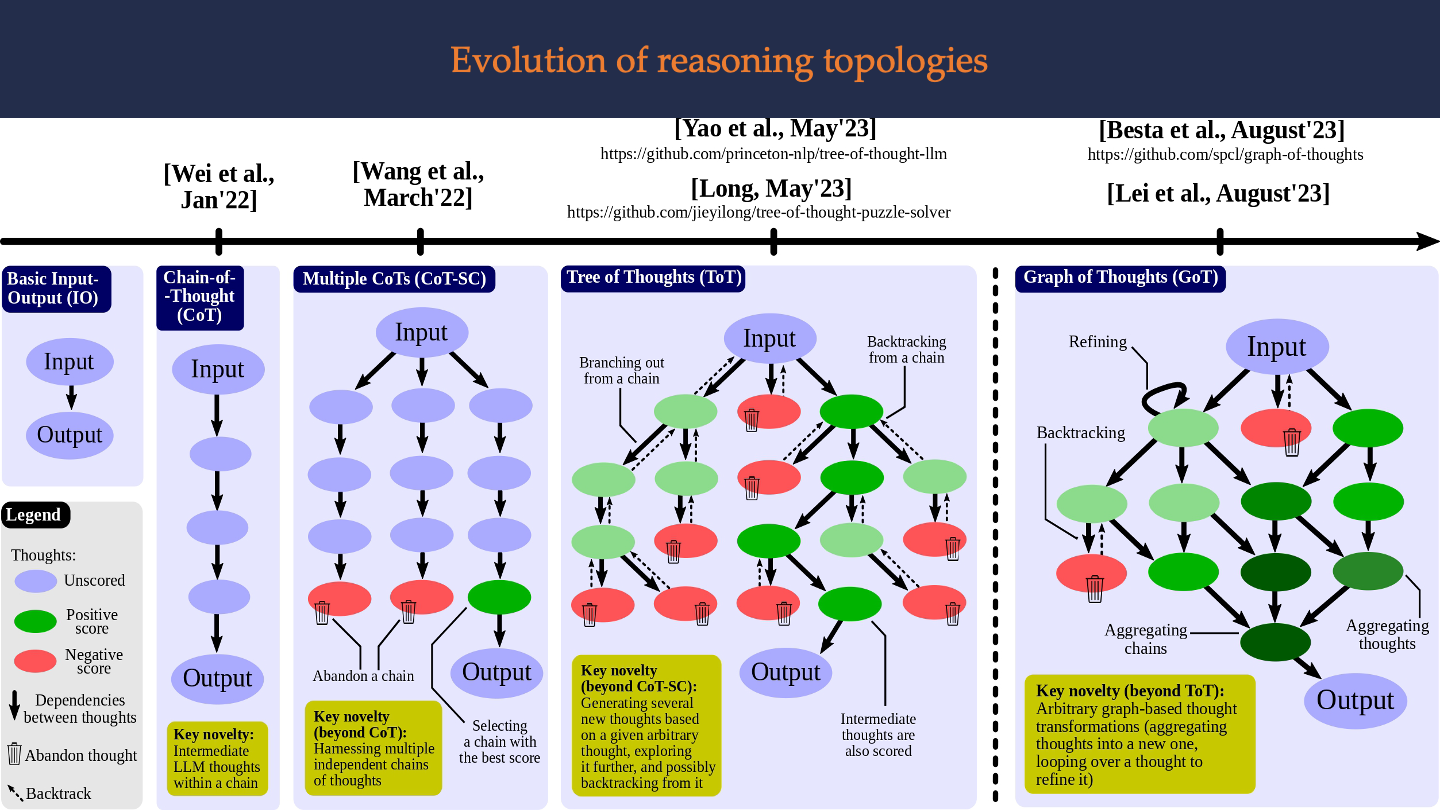
This figure presents an evolution of reasoning topologies in language model (LLM) prompting methodologies, showing an increasing complexity in how LLMs process and generate output based on a given input.
- Input-Output (IO) prompting: This is the most basic method where an LLM provides a final reply immediately after receiving the initial prompt from the user, with no intermediate steps in the reasoning process.
- Chain of Thought (CoT): Introduced by Wei et al., this method improves upon IO by incorporating explicit intermediate steps of reasoning, known as “chains of thought,” which lead to the final output.
- Chain-of-Thought with Self-Consistency (CoT-SC): Improving upon CoT, CoT-SC introduces several independent reasoning chains originating from the same initial input. The model then selects the best outcome from these final thoughts based on a predefined scoring function. The idea is to utilize the randomness within the LLM to generate multiple possible outcomes.
- Tree of Thoughts (ToT): This method further advances CoT by allowing branches at any point within the chain of thoughts. This branching allows for the exploration of different paths and options during the reasoning process. Each node in the tree represents a partial solution, and based on any given node, the thought generator can create a number of new nodes. Scores are then assigned to these new nodes either by an LLM or human evaluation. The method of extending the tree is determined by the search algorithm used, such as Breadth-First Search (BFS) or Depth-First Search (DFS).
- Graph of Thoughts (GoT): GoT enables complex reasoning dependencies between generated thoughts, allowing for any thought to generate multiple child thoughts and also have multiple parent thoughts, forming an aggregation operation. This method incorporates both branching (where thoughts can generate multiple outcomes) and aggregation (where multiple thoughts can contribute to a single new thought).
The progression of these topologies indicates a move from linear, single-step reasoning to complex, multi-step, and multi-path reasoning structures, improving the depth and robustness of the reasoning process within LLMs.
Thoughts and Reasoning Topologies
What is a Thought ?
- In CoT, a thought refers to a statement within a paragraph that contains a part of the reasoning process aimed at solving the input task.
- In ToT, in some tasks, such as Game of 24, a thought means an intermediate or a final solution to the initial question.
- In GoT, a thought contains a solution of the input task (or of its subtask).
Therefore, Paper proposes thought to be “Semantic unit of task resolution, i.e., a step in the process of solving a given task”
What is a Reasoning Topology?
Authors models thoughts as nodes; edges between nodes correspond to dependencies between these thoughts and a topology can be defined as G =(V,E)
Taxonomy of Reasoning Schemes
Topology Class
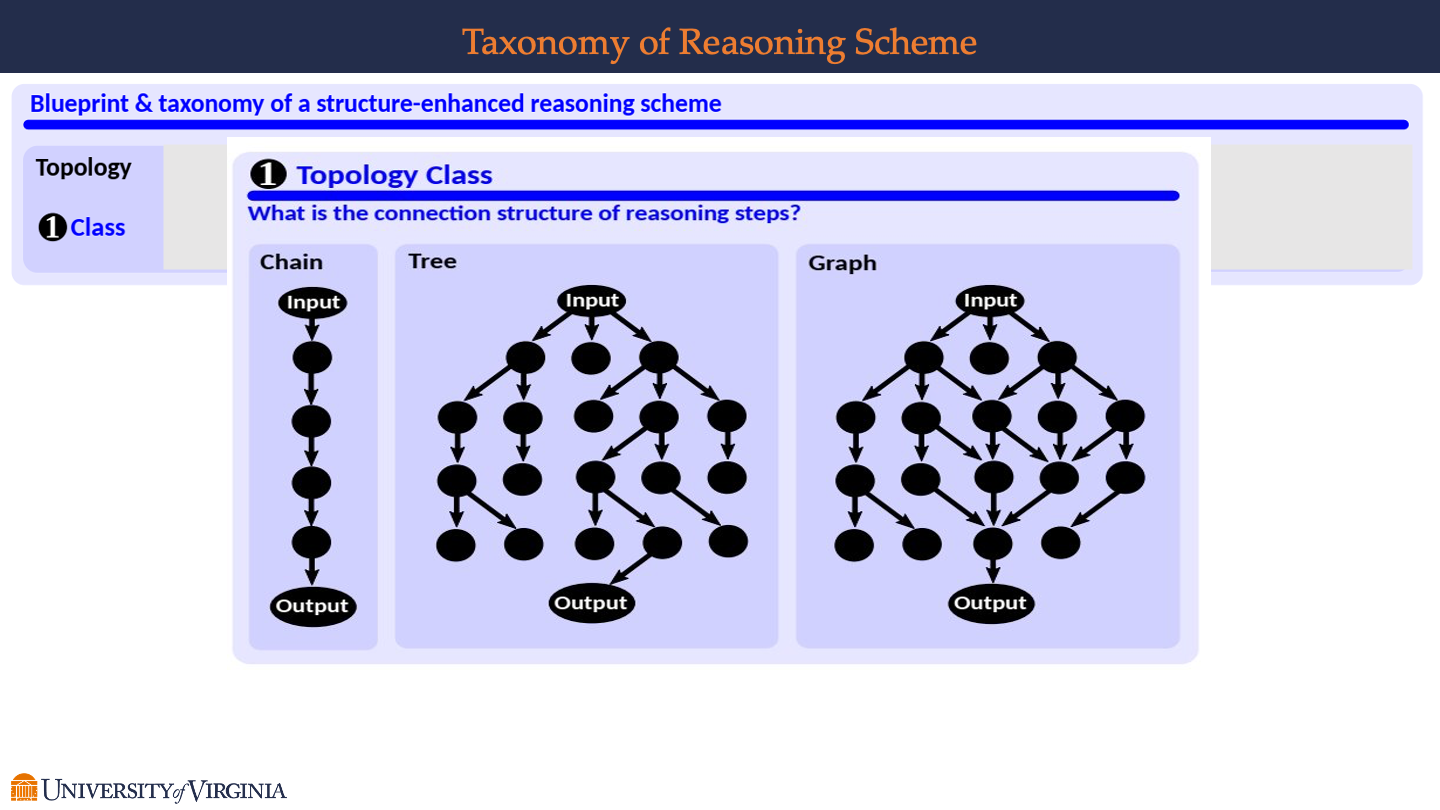
- This section presents three different classes of topological structures used to represent reasoning steps: Chain, Tree, and Graph.
- Chain: Depicted as a linear sequence of nodes connected vertically from an “Input” node at the top to an “Output” node at the bottom, suggesting a step-by-step, sequential reasoning process.
- Tree: Shown as a branching structure that starts with a single “Input” node which then divides into multiple pathways, eventually leading to one “Output” node. This illustrates a decision-making process that considers various paths or options before concluding.
- Graph: Illustrated as a network of interconnected nodes with one “Input” node and one “Output” node. Unlike the chain or tree, the graph shows multiple connections between the nodes, indicating a complex reasoning process with interdependencies and possible loops.
Topology Scope:”Can the topology extend beyond a single prompt?”
-
Single-prompt
-
Describes a structure contained within a single prompt/reply interaction.
-
The visual represents a tree topology where all reasoning nodes are part of one complete exchange, suggesting a condensed reasoning process that occurs in one step.
-
-
Multi-prompt
-
Indicates that one prompt/reply can contain multiple reasoning nodes.
-
The visual here expands the tree topology to show that individual prompts or replies may encompass multiple nodes, which implies a more extensive reasoning process involving several interactions.
-
Topology Representation
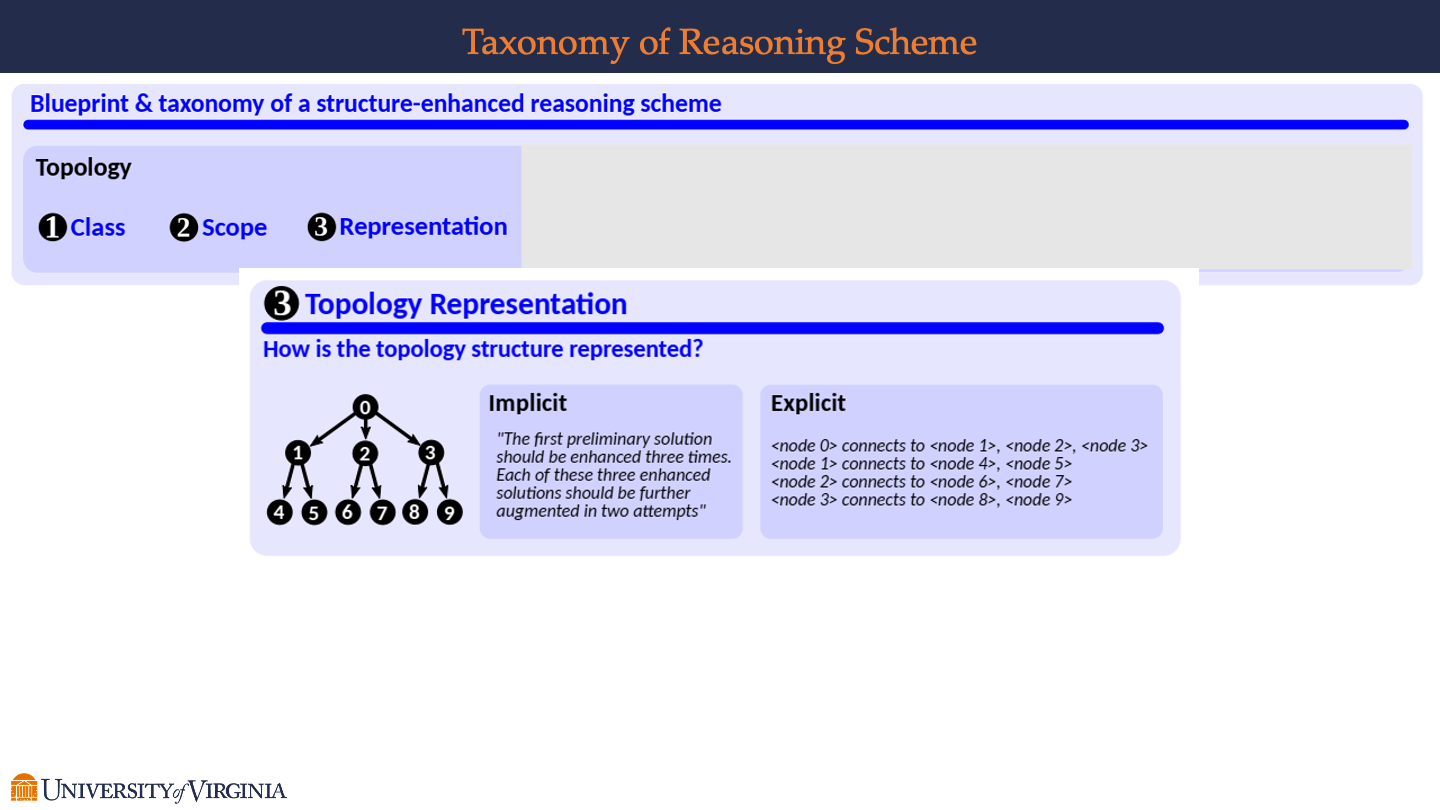
- The question is, “How is the topology structure represented?” indicating a focus on the manner in which the reasoning processes are visually and conceptually depicted.
- Tree Diagram
- A tree diagram is shown with a root node labeled “0” at the top, branching out to nodes “1,” “2,” and “3,” which further branch out to nodes “4” through “9”. This diagram is a representation of the reasoning structure, likely meant to illustrate the hierarchical and branching nature of thought processes.
-
Implicit vs. Explicit Representation
-
On the left, under the heading “Implicit,” there is a statement suggesting a less direct method of describing the reasoning process: “The first preliminary solution should be enhanced three times. Each of these three enhanced solutions should be further augmented in two attempts.”
-
On the right, under the heading “Explicit,” there is a more direct and detailed explanation of the connections between the nodes: “<node 0> connects to <node 1>, <node 2>, <node 3> <node 1> connects to <node 4>, <node 5> <node 2> connects to <node 6>, <node 7> <node 3> connects to <node 8>, <node 9>.”
-
Topology Derivation
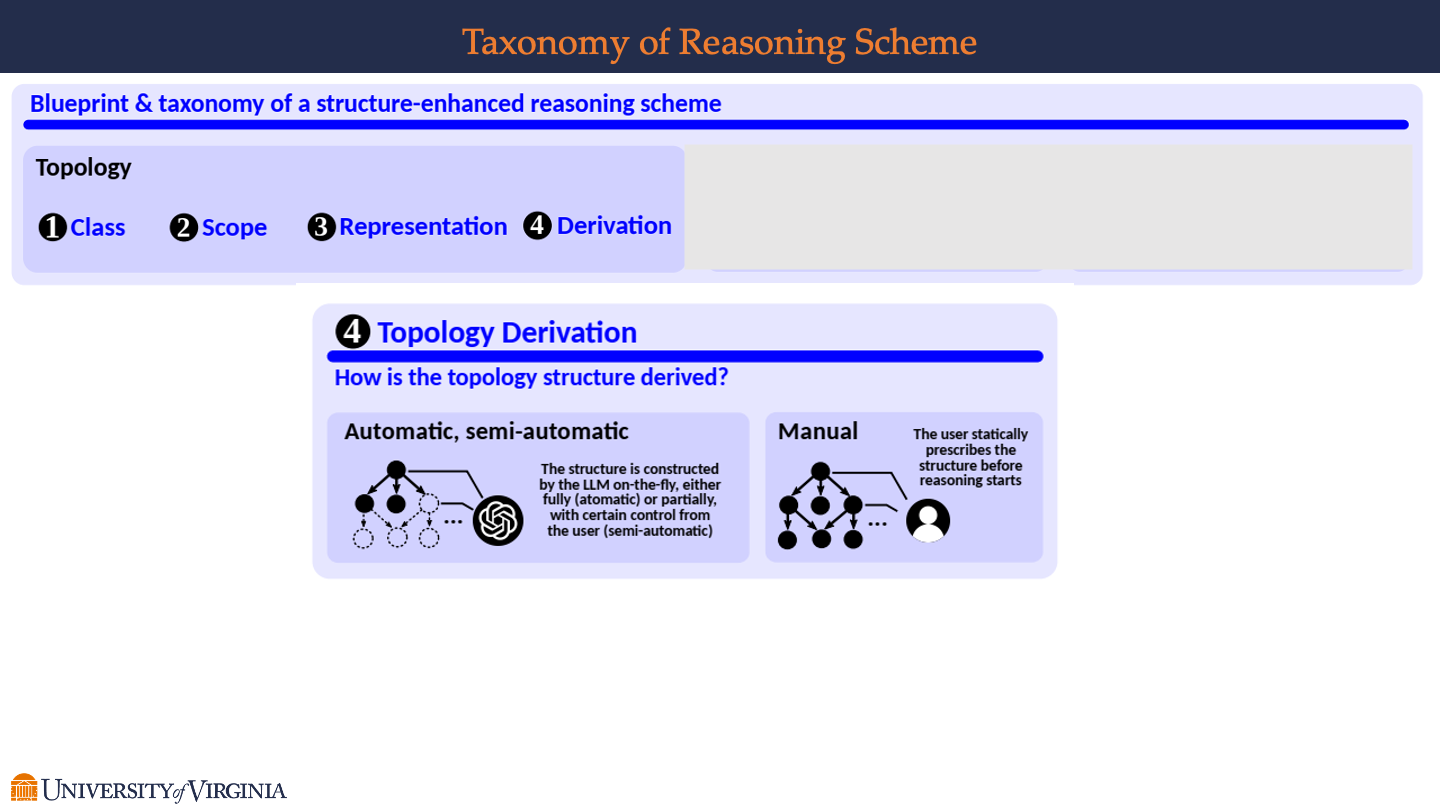
- Automatic, semi-automatic:
- The left side of the slide discusses the automatic and semi-automatic construction of topology structures. It mentions that the structure can be constructed on-the-fly by the Large Language Model (LLM), either fully automatically or with partial control from the user, indicating a semi-automatic approach. The accompanying graphic shows a partial tree with some nodes filled in and others as dotted outlines, suggesting that some parts of the structure are generated by the LLM while others may be influenced or completed by the user.
- Manual:
- On the right side, the slide describes a manual method of topology derivation. Here, the user statically prescribes the structure before reasoning starts, implying that the entire topology is defined in advance by the user without the dynamic involvement of an LLM. The graphic shows a complete tree structure, symbolizing a user-defined topology without any automatic generation.
Topology Schedule and Schedule Representation
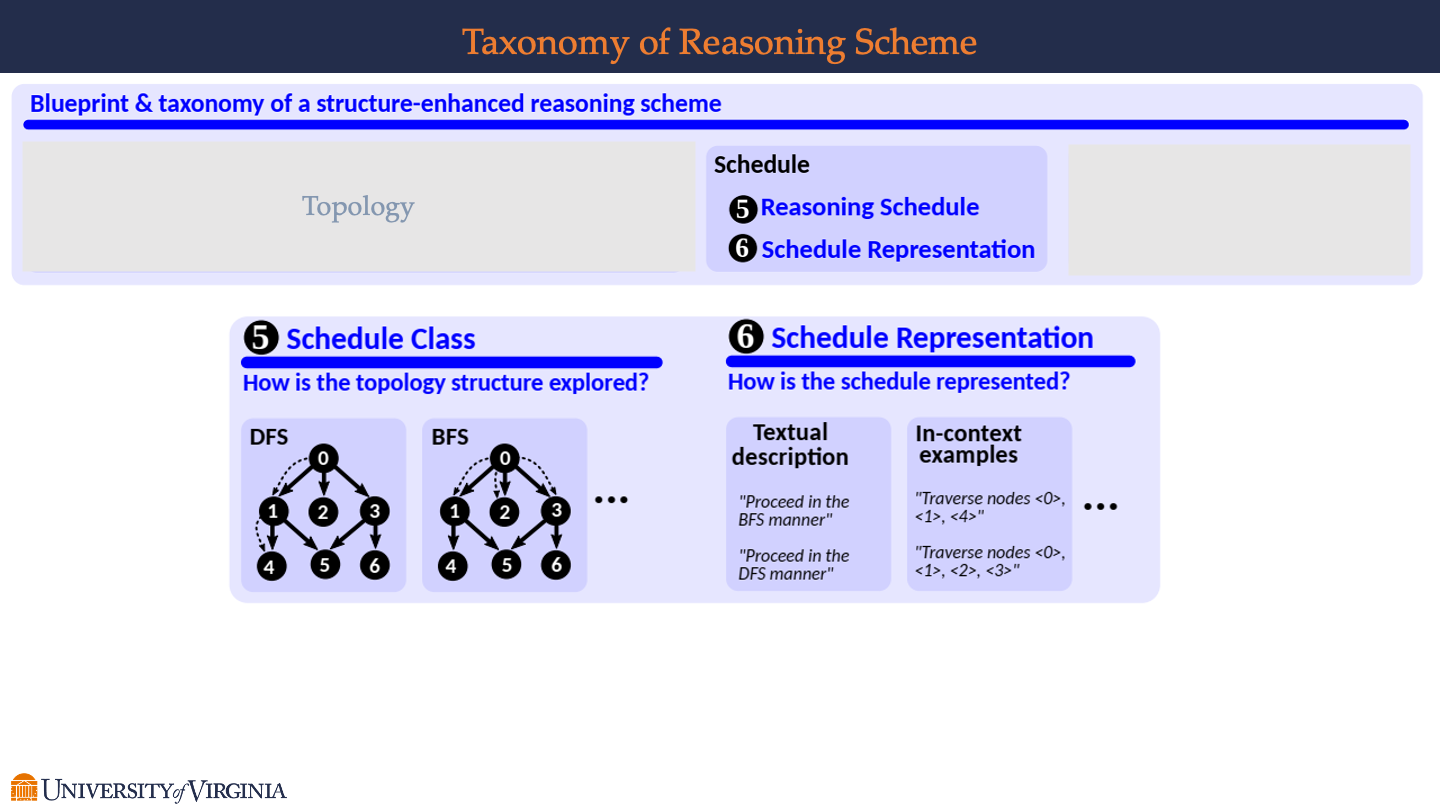
-
Schedule Class
-
The slide poses the question, “How is the topology structure explored?” indicating an interest in the methods used to navigate the reasoning topology.
-
Two common search strategies are presented:
- DFS (Depth-First Search): Illustrated with a partial topology where the search path moves from the root node “0” to the deepest node along a branch before backtracking, as shown by the direction of the arrows.
- BFS (Breadth-First Search): Also shown with a partial topology, but here the search path is horizontal, indicating that the strategy explores all nodes at the current depth before moving to the next level.
-
-
Schedule Representation
-
This section asks, “How is the schedule represented?” highlighting different ways to describe the traversal strategy.
-
Two forms of representation are given
- Textual description: Provides a direct command to proceed in either “BFS manner” or “DFS manner,” offering a high-level instruction on how to navigate the topology.
- In-context examples: Offers specific node traversal sequences such as “Traverse nodes <0>, <1>, <4>” for BFS and “Traverse nodes <0>, <1>, <2>, <3>” for DFS, providing a clear, detailed path to follow within the topology.
-
Generative AI Pipeline
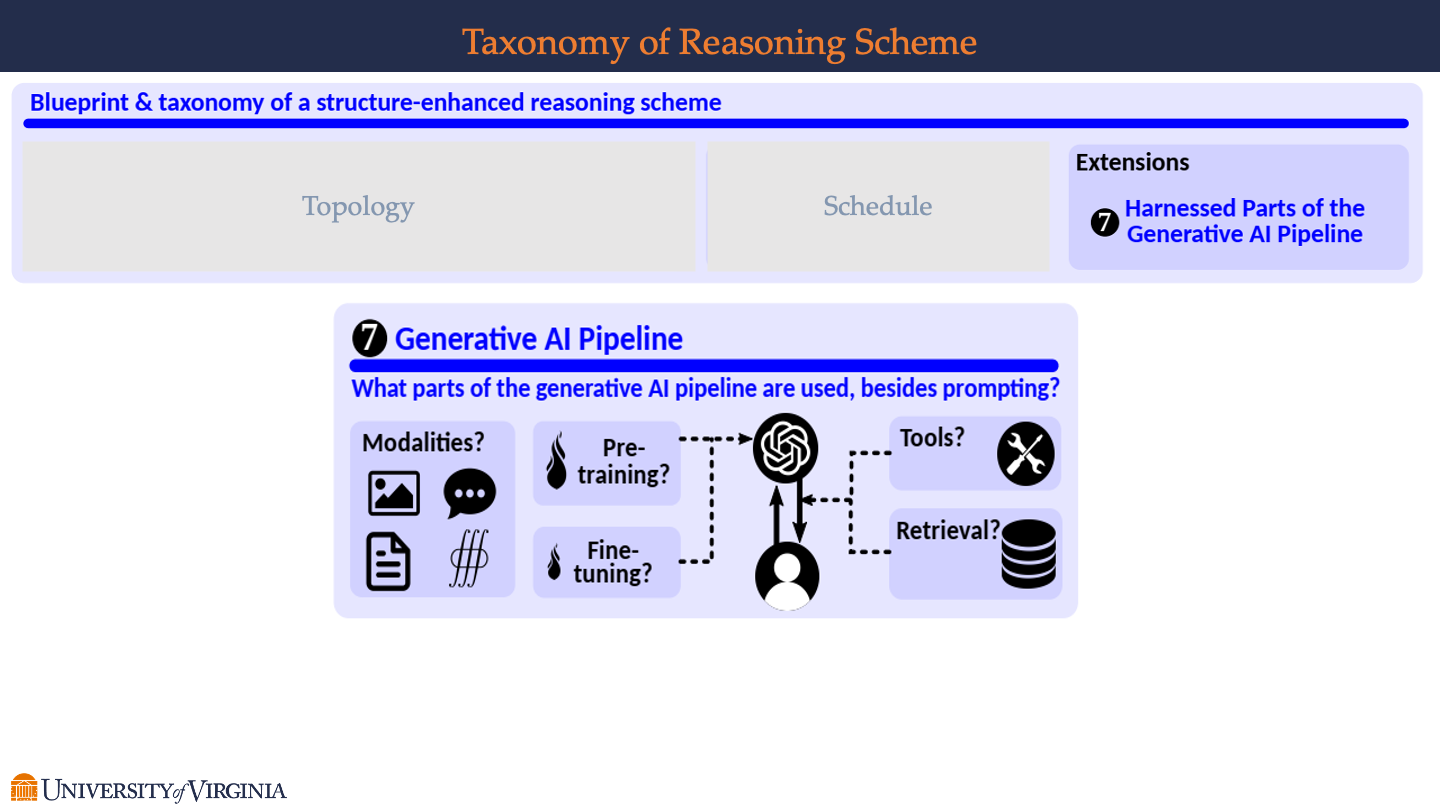
- Modalities?
- This suggest various types of data inputs or outputs used in AI, such as text, speech, image, and music.
- Pre-training?
- Indicated by a lightning bolt symbol, referring to the initial phase of AI training where a model learns from a vast dataset before it’s fine-tuned for specific tasks.
- Fine-tuning?
- Depicted with a wrench, implying the process of adjusting a pre-trained model with a more targeted dataset to improve its performance on specific tasks.
- Tools?
- Represented by a screwdriver and wrench, this likely refers to additional software or algorithms that can be applied in conjunction with the AI for task completion or enhancement.
- Retrieval?
- Shown with a database icon, suggesting the use of retrieval systems to access pre-stored data or knowledge bases that the AI can use to inform its responses or generate content.
LLM Reasoning Schemes Represented With Taxonomy
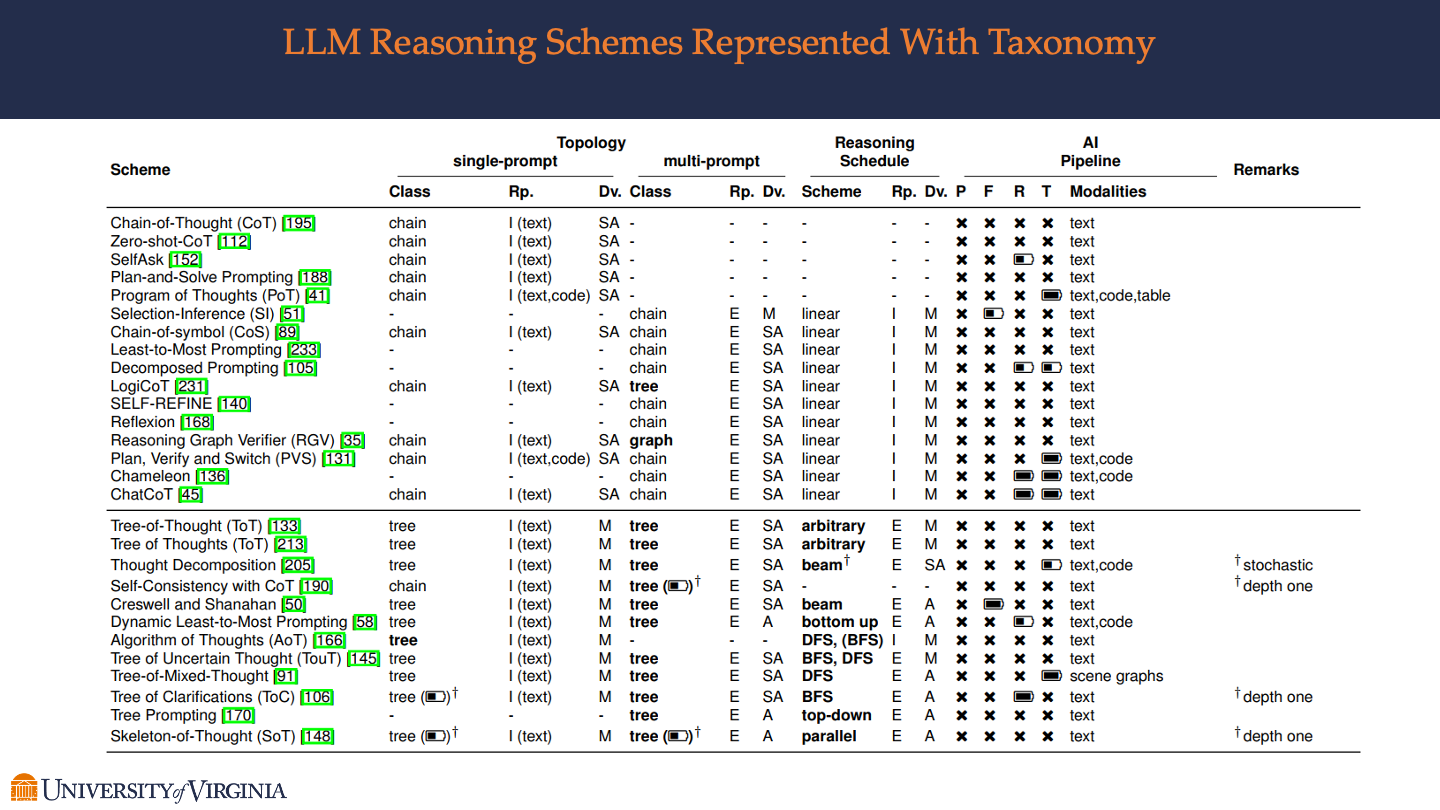
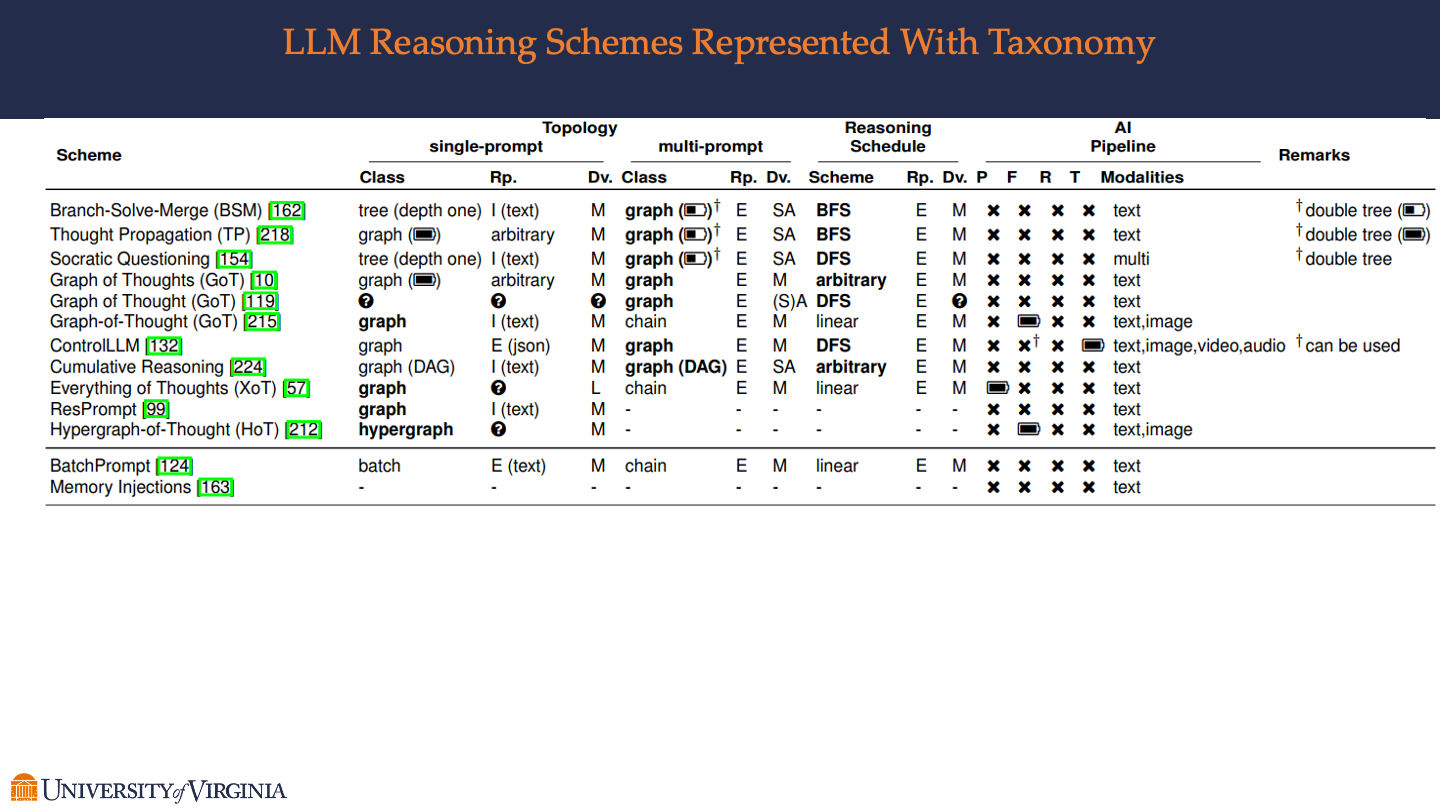
Focusing on the application of reasoning schemes in Large Language Models (LLMs), these pages highlight how the taxonomy of reasoning is implemented in AI systems. It covers specific methodologies within the Chain of Thought (CoT) reasoning, such as multi-step reasoning and zero-shot reasoning instructions, showcasing their impact on enhancing the problem-solving capabilities of LLMs.
Chain of Thought Works

- Multi-Step Reasoning:
- Chain-of-Thought (CoT): This is described as a single-prompt scheme utilizing few-shot examples to guide LLMs.
- Program of Thoughts (PoT): It refers to the use of code to generate a step-by-step functional Python program.
- SelfAsk: This expands each step in the reasoning chain by posing a follow-up question, which is then answered in sequence.
- Math Reasoning:
- On the left, under “User Prompt,” an example question is posed regarding Alexis and her spending on business clothes and shoes, followed by a systematic breakdown of the cost of items and the budget used to deduce how much she paid for the shoes.
- On the right, under “LLM Answer,” a similar math problem is presented concerning Tobias earning money from chores, with the solution worked out step-by-step to determine how many driveways he shoveled.
- Examples:
- The right side features two math reasoning examples to illustrate the Chain of Thought method in action. Each example is carefully broken down into individual reasoning steps, showing how an LLM might approach complex problems by dividing them into smaller, more manageable parts.

- Zero-Shot Reasoning Instructions:
- It describes an approach where LLMs are expected to perform multi-step reasoning without relying on hand-tuned, problem-specific in-context examples.
- Two types of zero-shot reasoning are mentioned:
- Zeroshot-CoT (Chain of Thought): A prompt to the LLM to “Let’s think step by step.”
- Zeroshot-PoT (Program of Thoughts): A prompt to write a Python program step by step, starting with defining the variables.
- Creative Writing Example:
- A user prompt is provided on the right-hand side, which outlines a task for creative writing. The user is instructed to write four short paragraphs, with each paragraph ending with a specific sentence:
- “It isn’t difficult to do a handstand if you just stand on your hands.”
- “It caught him off guard that space smelled of seared steak.”
- “When she didn’t like a guy who was trying to pick her up, she started using sign language.”
- “Each person who knows you has a different perception of who you are.”
- A user prompt is provided on the right-hand side, which outlines a task for creative writing. The user is instructed to write four short paragraphs, with each paragraph ending with a specific sentence:
Overview of Chain of Thought Works

On the left side, a “User Prompt” is provided for the task of writing a coherent passage of four short paragraphs. Each paragraph must end with a pre-specified sentence:
- “It isn’t difficult to do a handstand if you just stand on your hands.”
- “It caught him off guard that space smelled of seared steak.”
- “When she didn’t like a guy who was trying to pick her up, she started using sign language.”
- “Each person who knows you has a different perception of who you are.”
The phrase “Let’s think step by step.” is emphasized, suggesting the application of sequential reasoning to address the creative task.
On the right side, the “LLM Answer” section provides a sample output from an LLM that has followed the chain of thought reasoning approach. The LLM’s responses are crafted to end each paragraph with the specified sentences, displaying a thoughtful progression that connects each statement. Each paragraph develops a context that leads to the predetermined ending, demonstrating the LLM’s ability to generate content that flows logically and coherently.
Planning & Task Decomposition

This figure contains two contrasting examples demonstrating how the Plan-and-Solve approach can be applied:
- Incorrect LLM Approach:
- The first example (top left) shows an attempt by an LLM to solve a math problem related to a dance class enrollment. The model incorrectly calculates the percentages of students enrolled in various dance classes. The process is marked by a red “X,” indicating an incorrect reasoning path where the LLM does not first understand the problem or plan its solution.
- Correct PS Prompting Approach:
- The second example (bottom left) applies the Plan-and-Solve approach correctly. Here, the problem is first understood, a plan is then devised, and finally, the solution is carried out step-by-step. This method is laid out in a series of steps, each addressing a part of the problem:
- Step 1: Calculate the total number of students enrolled in contemporary and jazz dance.
- Step 2: Calculate the number of students enrolled in hip-hop dance.
- Step 3: Calculate the percentage of students who enrolled in hip-hop dance.
- The second example (bottom left) applies the Plan-and-Solve approach correctly. Here, the problem is first understood, a plan is then devised, and finally, the solution is carried out step-by-step. This method is laid out in a series of steps, each addressing a part of the problem:
The example demonstrates a structured problem-solving technique where an initial plan is crucial for guiding the LLM through the reasoning process. It emphasizes the effectiveness of decomposing a task into manageable parts and addressing each part systematically, leading to a correct solution.
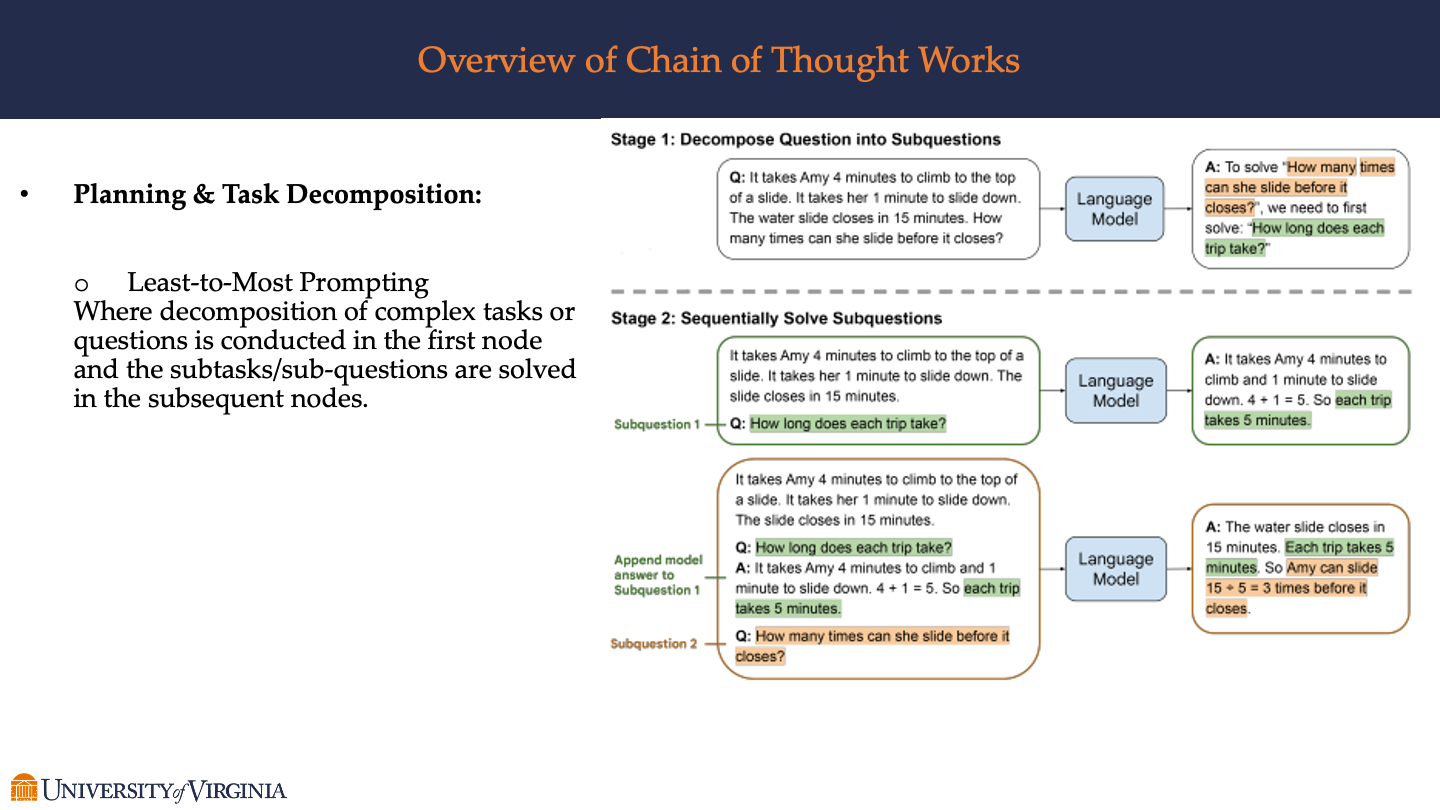
This shows the approach in two stages:
- Stage 1: Decompose Question into Subquestions
- The example given is a math problem involving Amy climbing and sliding down a slide, with an inquiry about how many times she can do this before the slide closes.
- The problem is decomposed into sub-questions, likely to simplify the task and make the solution process more manageable.
- Stage 2: Sequentially Solve Subquestions
- Subquestion 1: “How long does each trip take?”
- The answer to Subquestion 1 is then used to tackle Subquestion 2: “How many times can she slide before it closes?”
- Each sub-question is answered using a language model that appears to provide a step-by-step explanation, building on the information from the previous steps.

This includes a figure (Figure 2) that provides an example of prompts used for both decomposing and reassembling (split and merge) sub-tasks within a task-solving framework. The example shows a sequence of operations starting with a complex task and breaking it down into smaller, sequential operations that eventually lead to the solution. These operations are represented by the prompts given to the language model, indicating a sequence that the model follows to achieve the task. For instance, starting with a name like “Jack Ryan,” the model is prompted to split this into words, identify the first letter of each word, and finally concatenate them with spaces.
This method showcases how complex tasks can be handled systematically by LLMs, allowing for the modular processing of information. The approach can be generalized to various tasks, as indicated by the side examples where the model performs similar operations on different inputs like “Elon Musk Tesla” and “C++,” demonstrating flexibility in the model’s reasoning capability.
Task Preprocessing:
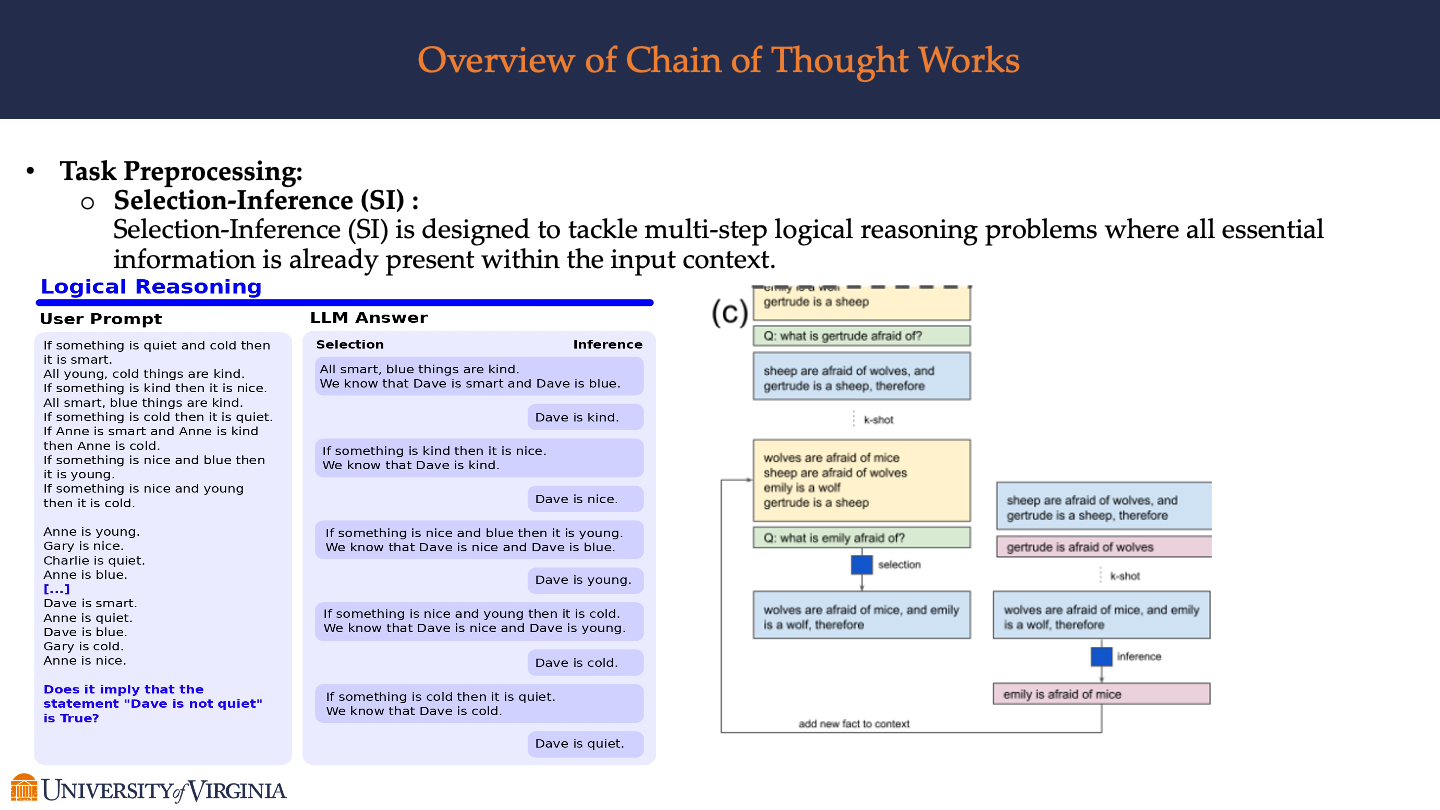
- Selection-Inference (SI) :
- Selection-Inference (SI) is designed to tackle multi-step logical reasoning problems where all essential information is already present within the input context
- Iterative Refinement:
- Verification enables the reasoning frameworks to iteratively refine the generated context and intermediate results.
- Tool Utilization:
- To better integrate multiple execution methods, more effective schemes opt to devise a plan that specifies tools for handling each sub-task, before executing the reasoning chain. Examples include AutoGPT , Toolformer , Chameleon , ChatCot , PVS and others .
Reasoning With Trees
Motivation
- Exploration
- Generate multiple thoughts from a given thought
- Sampling
- Task decomposition
- Voting
- Automatic selection of best outcome of generated outputs
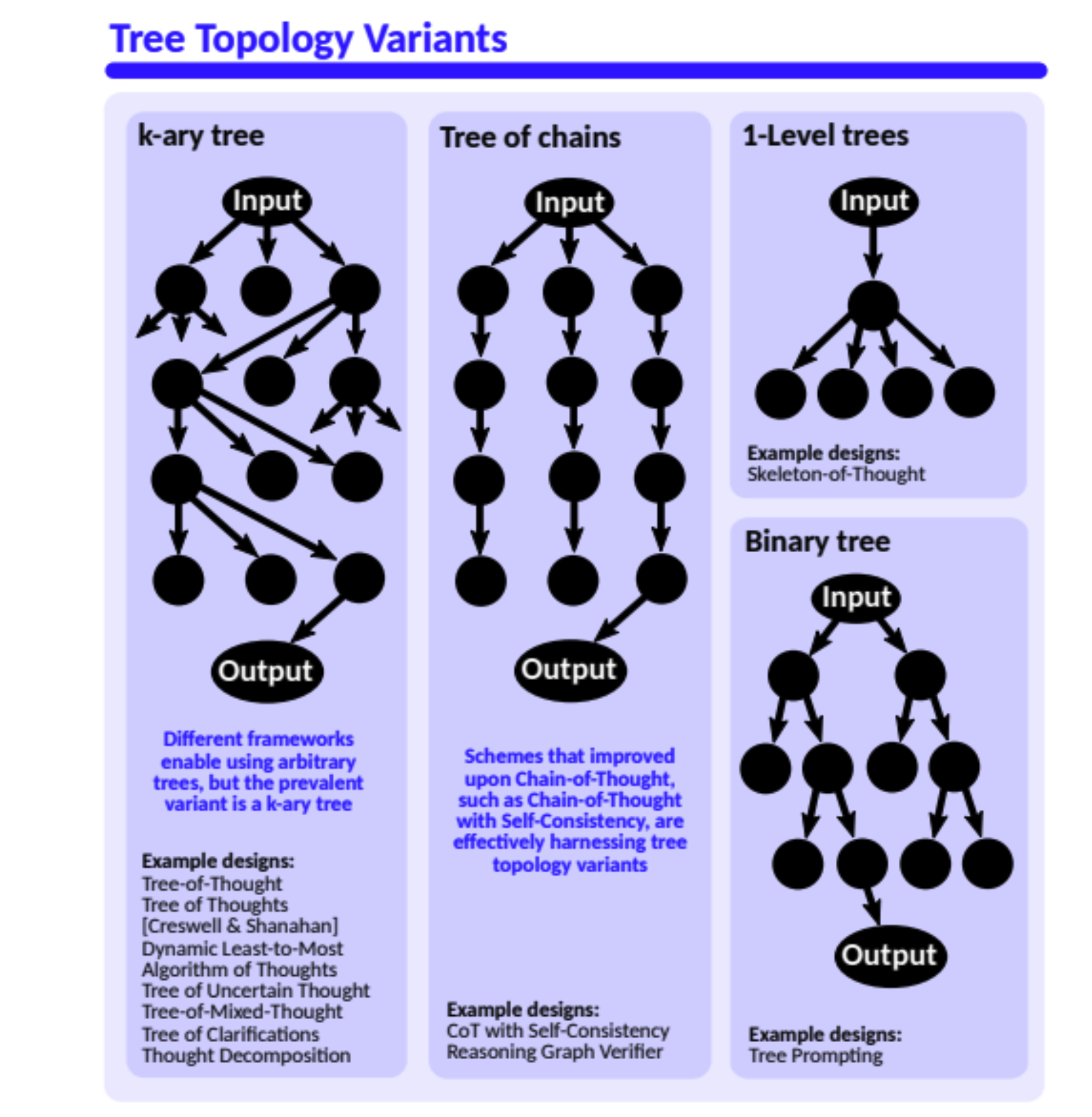
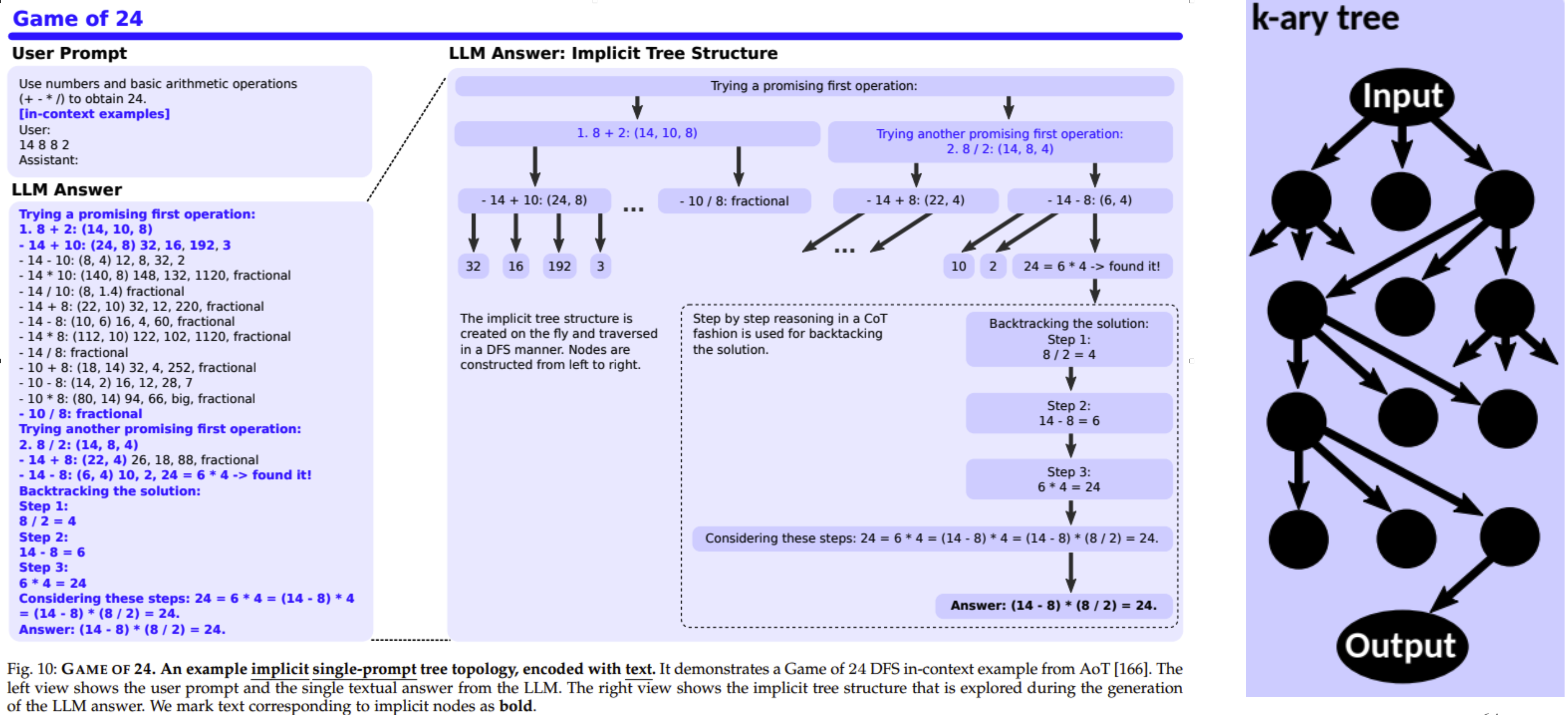
K-ary Trees K-ary trees can represent decision processes where each node is a decision point, and the branches (up to K) represent different options or outcomes from that decision point. This is especially useful in scenarios with multiple choices at each step, allowing a comprehensive visualization of possible decision paths.
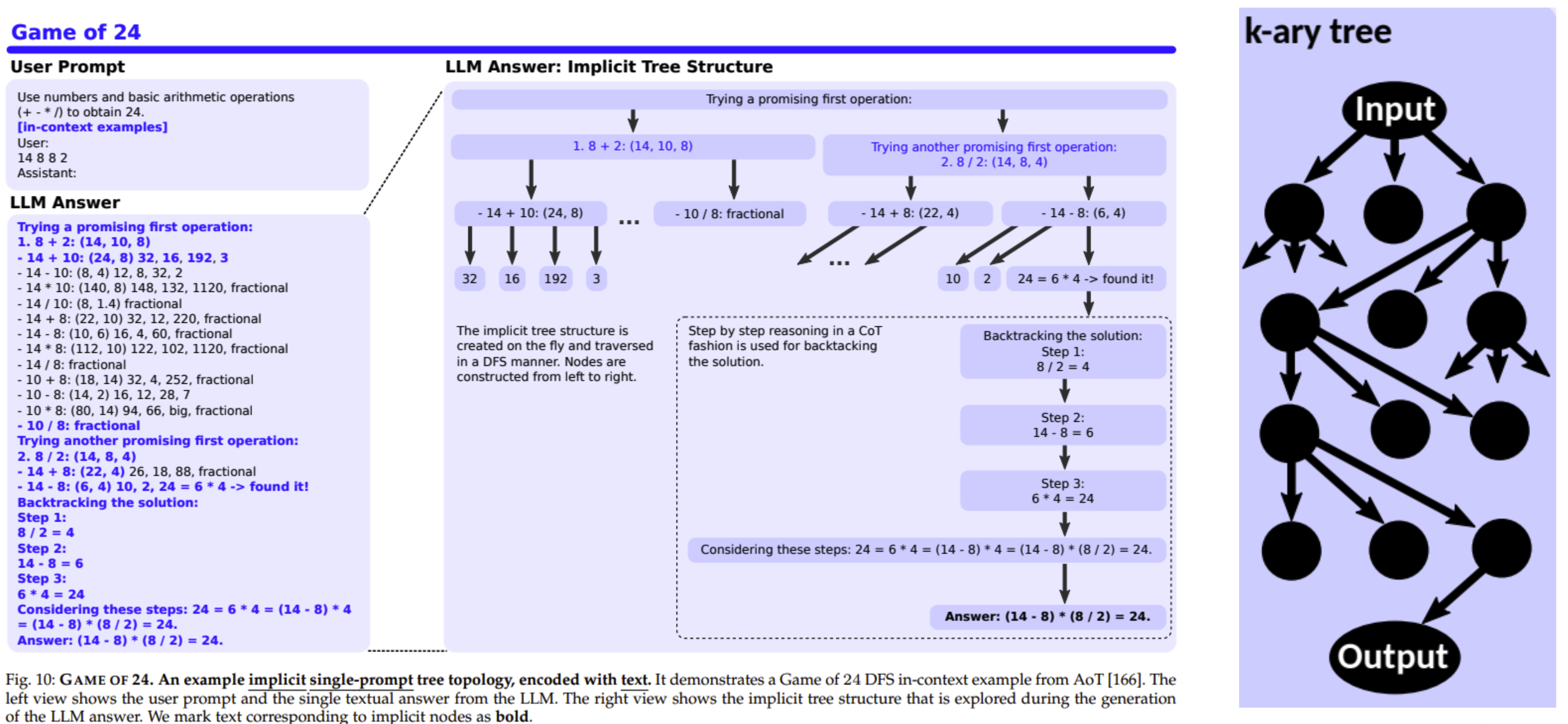
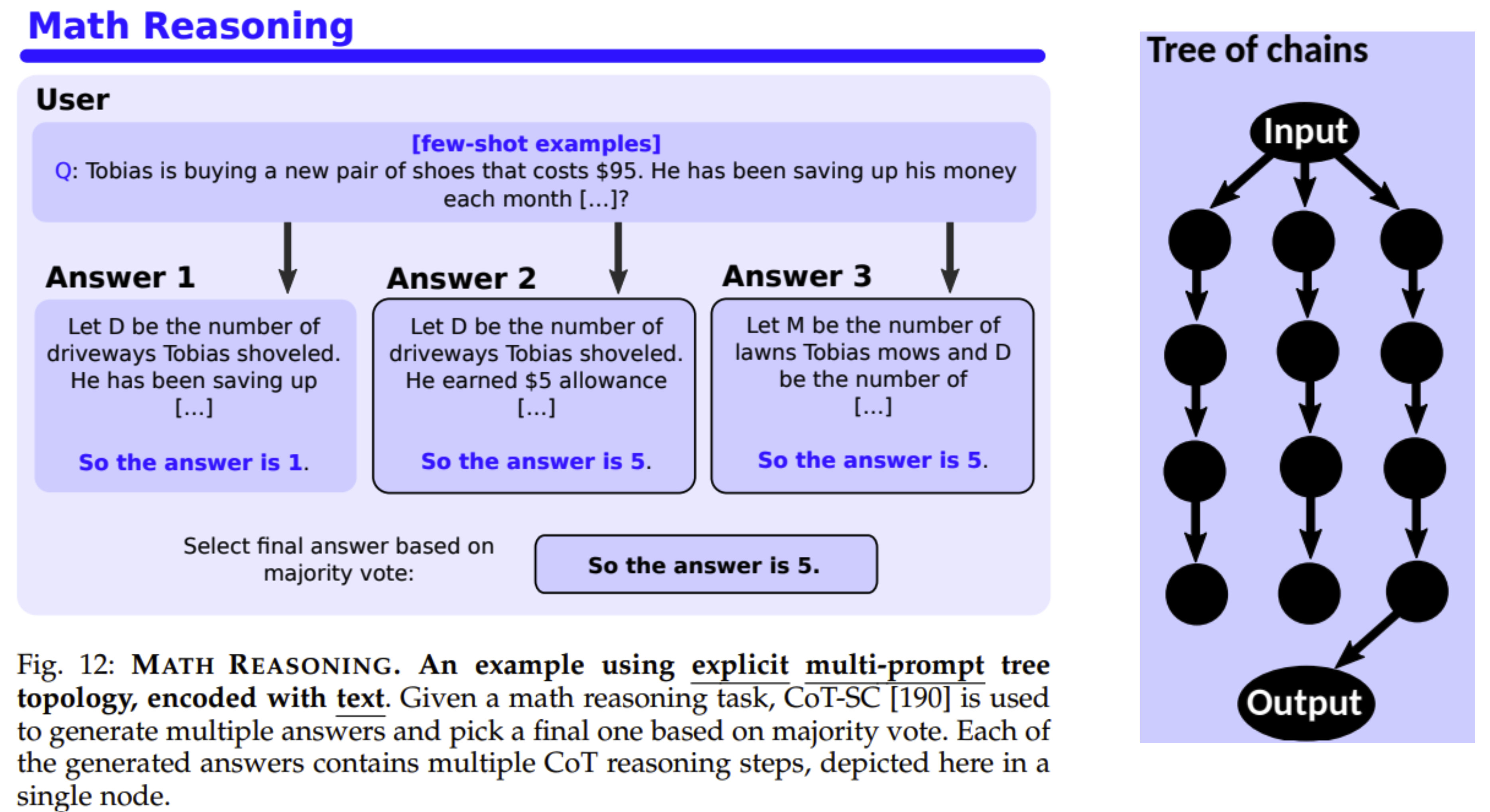
Tree of Chains Tree of Chains enables a clear visualization of various inference paths and their interconnections, aiding in the systematic exploration and analysis of potential outcomes. By breaking down complex inference processes into manageable chains, it facilitates a deeper understanding and aids in the identification of the most logical or optimal conclusion from a set of premises.
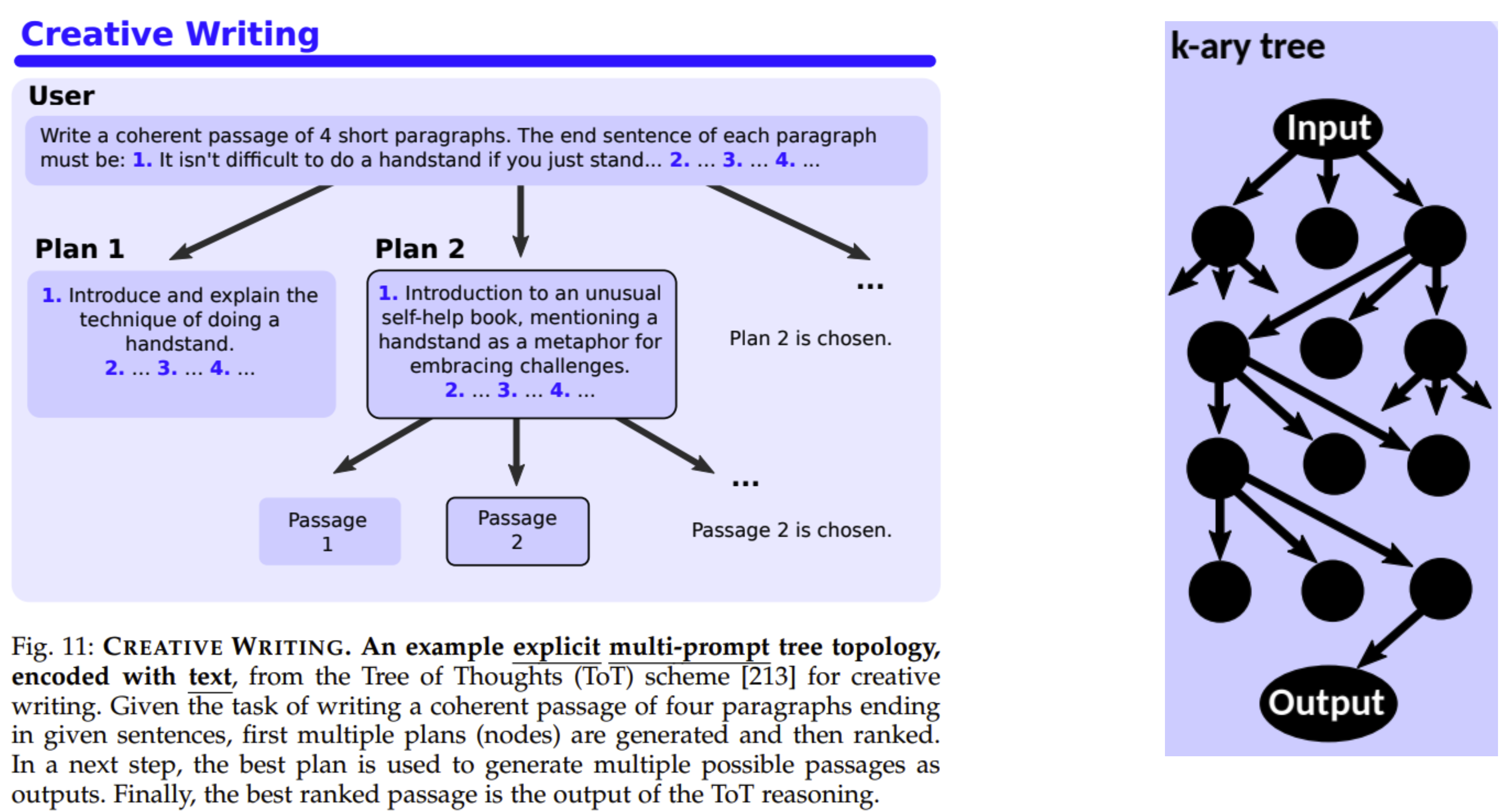
Single Level Tree In the reasoning process, Single-Level Trees help organize and visualize the different dimensions or options of a problem, making the decision-making process more structured and streamlined. Each child node can represent an independent line of thought or decision point, allowing analysts to quickly assess the pros and cons of different options without delving into more complex hierarchical structures.
Tree Performance
- Increasing branching factor
- Higher diversity of outcomes
- Beneficial for accuracy
- Increases computational cost
- Optimal branching factor is hard to find
- Problem dependent
- More complicated problems can benefit more from decomposition into subproblems ### Reasoning with graphs
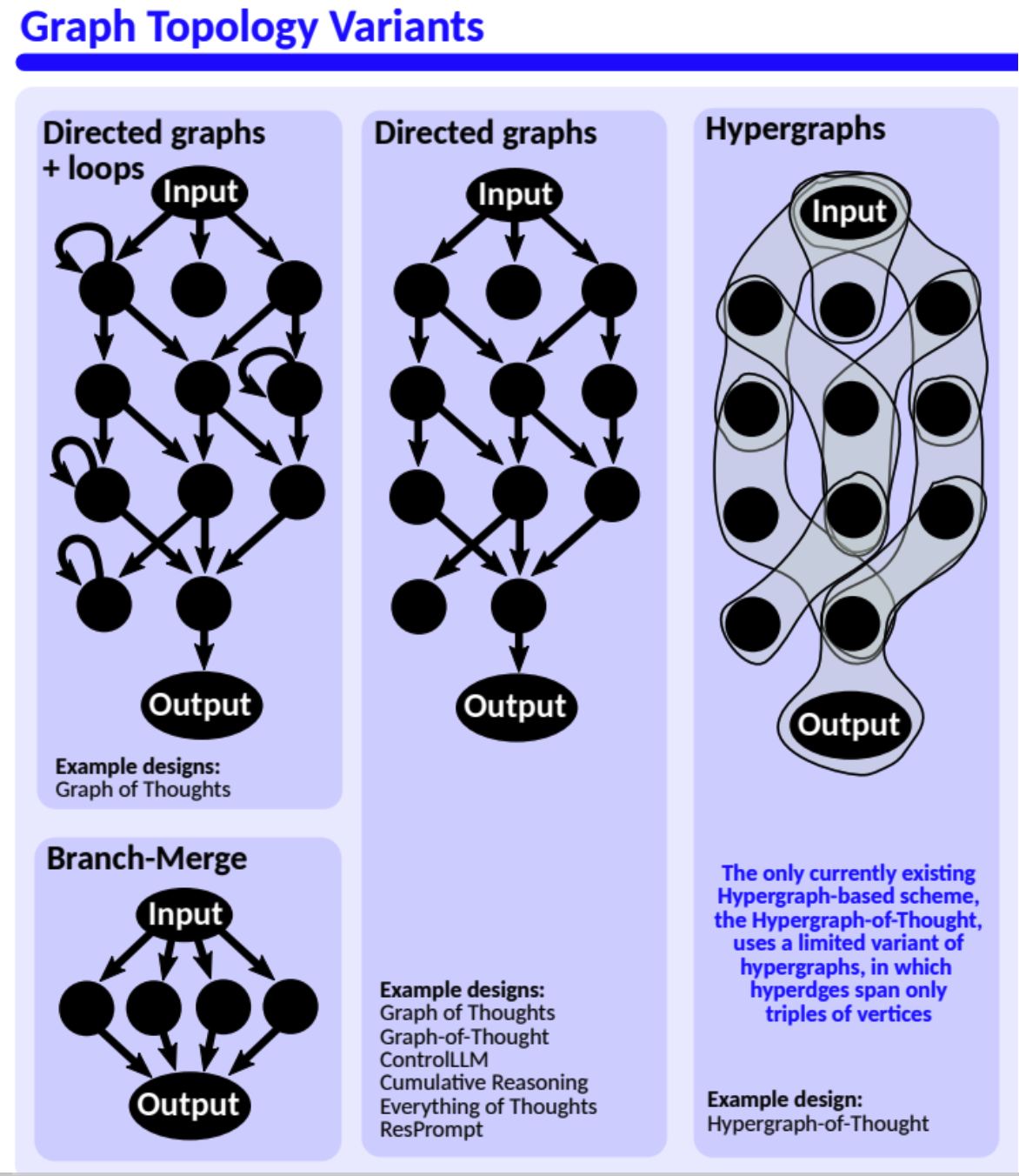
Motivation
- Aggregation
- Being able to combine multiple thoughts into one
- Synergy
- Produce outcome better than individual parts
- Effective composition of outcomes of tasks
- Exploration
- Flexible
- Arbitrary
Examples
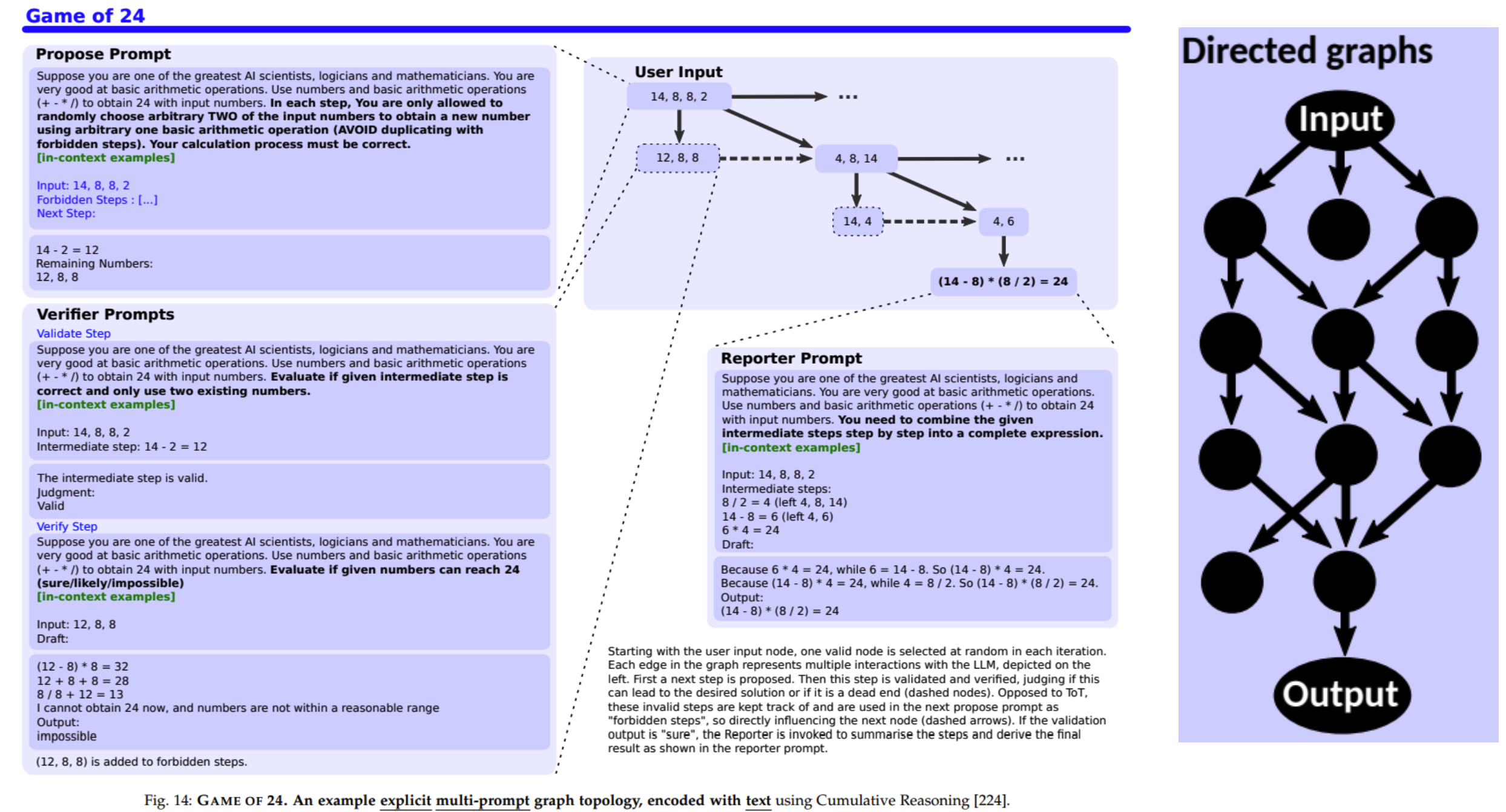



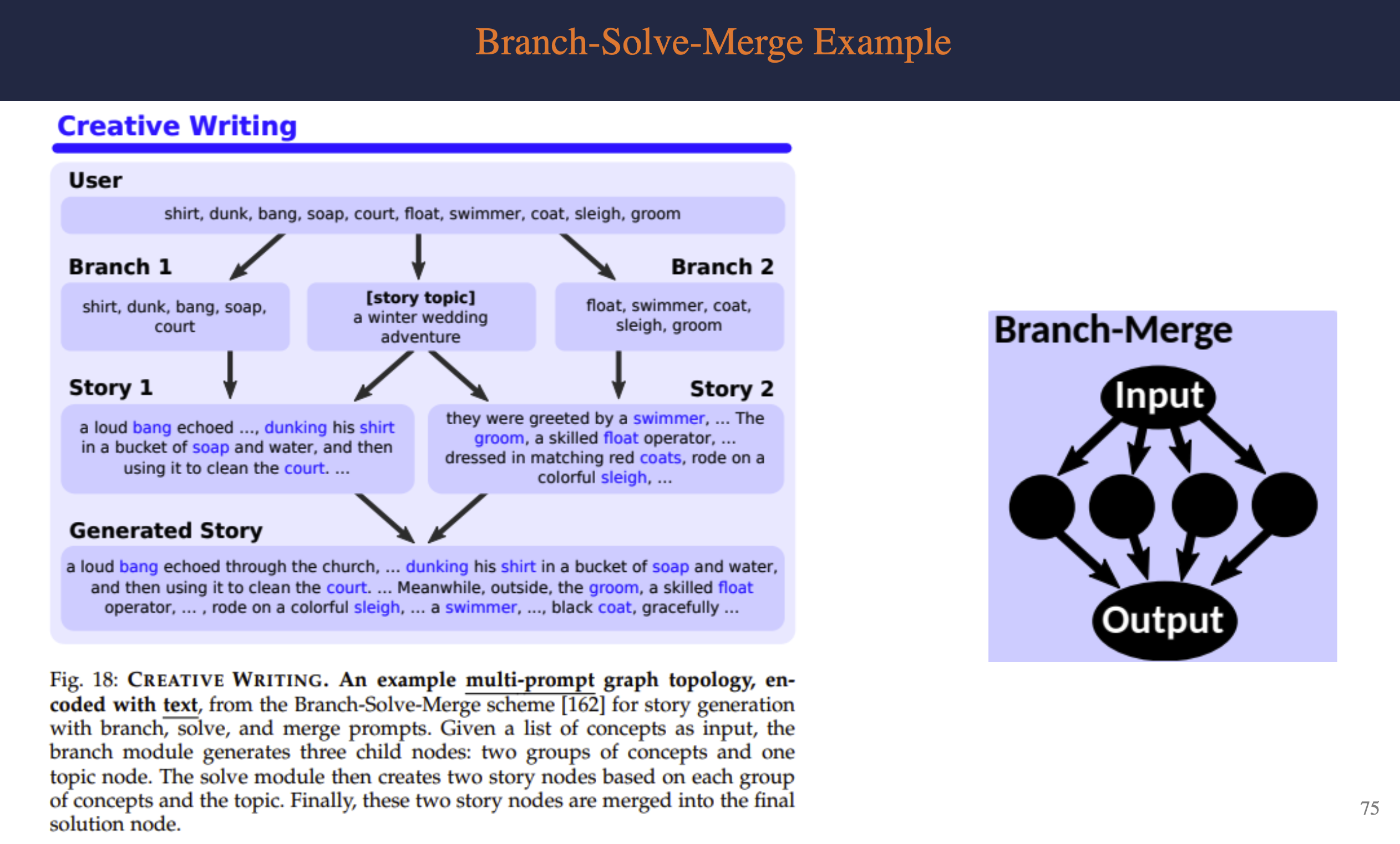
Chains vs. Trees vs. Graphs of THoughts
Chains - Explicit intermediate LLM thoughts - Step-by-step - Usually most cost effective Trees - Possibility of exploring at each step - More effective than chains Graphs - Most complex structure - Enable aggregation of various reasoning steps into one solution - Often see improvements in performance compared to chains and trees