Self-exam LLM and reasoning
- SlideDeck: W12-team-2-self-exam-LLM
- Version: current
- Lead team: team-2
- Blog team: team-1
In this session, our readings cover:
Required Readings:
Augmented Language Models: a Survey
- Grégoire Mialon, Roberto Dessì, Maria Lomeli, Christoforos Nalmpantis, Ram Pasunuru, Roberta Raileanu, Baptiste Rozière, Timo Schick, Jane Dwivedi-Yu, Asli Celikyilmaz, Edouard Grave, Yann LeCun, Thomas Scialom
- This survey reviews works in which language models (LMs) are augmented with reasoning skills and the ability to use tools. The former is defined as decomposing a potentially complex task into simpler subtasks while the latter consists in calling external modules such as a code interpreter. LMs can leverage these augmentations separately or in combination via heuristics, or learn to do so from demonstrations. While adhering to a standard missing tokens prediction objective, such augmented LMs can use various, possibly non-parametric external modules to expand their context processing ability, thus departing from the pure language modeling paradigm. We therefore refer to them as Augmented Language Models (ALMs). The missing token objective allows ALMs to learn to reason, use tools, and even act, while still performing standard natural language tasks and even outperforming most regular LMs on several benchmarks. In this work, after reviewing current advance in ALMs, we conclude that this new research direction has the potential to address common limitations of traditional LMs such as interpretability,
Self-Consistency Improves Chain of Thought Reasoning in Language Models
- https://arxiv.org/abs/2203.11171
- Chain-of-thought prompting combined with pre-trained large language models has achieved encouraging results on complex reasoning tasks. In this paper, we propose a new decoding strategy, self-consistency, to replace the naive greedy decoding used in chain-of-thought prompting. It first samples a diverse set of reasoning paths instead of only taking the greedy one, and then selects the most consistent answer by marginalizing out the sampled reasoning paths. Self-consistency leverages the intuition that a complex reasoning problem typically admits multiple different ways of thinking leading to its unique correct answer. Our extensive empirical evaluation shows that self-consistency boosts the performance of chain-of-thought prompting with a striking margin on a range of popular arithmetic and commonsense reasoning benchmarks, including GSM8K (+17.9%), SVAMP (+11.0%), AQuA (+12.2%), StrategyQA (+6.4%) and ARC-challenge (+3.9%).
If LLM Is the Wizard, Then Code Is the Wand: A Survey on How Code Empowers Large Language Models to Serve as Intelligent Agents
- https://arxiv.org/abs/2401.00812
- Ke Yang, Jiateng Liu, John Wu, Chaoqi Yang, Yi R. Fung, Sha Li, Zixuan Huang, Xu Cao, Xingyao Wang, Yiquan Wang, Heng Ji, Chengxiang Zhai
- The prominent large language models (LLMs) of today differ from past language models not only in size, but also in the fact that they are trained on a combination of natural language and formal language (code). As a medium between humans and computers, code translates high-level goals into executable steps, featuring standard syntax, logical consistency, abstraction, and modularity. In this survey, we present an overview of the various benefits of integrating code into LLMs’ training data. Specifically, beyond enhancing LLMs in code generation, we observe that these unique properties of code help (i) unlock the reasoning ability of LLMs, enabling their applications to a range of more complex natural language tasks; (ii) steer LLMs to produce structured and precise intermediate steps, which can then be connected to external execution ends through function calls; and (iii) take advantage of code compilation and execution environment, which also provides diverse feedback for model improvement. In addition, we trace how these profound capabilities of LLMs, brought by code, have led to their emergence as intelligent agents (IAs) in situations where the ability to understand instructions, decompose goals, plan and execute actions, and refine from feedback are crucial to their success on downstream tasks. Finally, we present several key challenges and future directions of empowering LLMs with code.
More Readings:
ReAct: Synergizing Reasoning and Acting in Language Models
- Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, Yuan Cao
- While large language models (LLMs) have demonstrated impressive capabilities across tasks in language understanding and interactive decision making, their abilities for reasoning (e.g. chain-of-thought prompting) and acting (e.g. action plan generation) have primarily been studied as separate topics. In this paper, we explore the use of LLMs to generate both reasoning traces and task-specific actions in an interleaved manner, allowing for greater synergy between the two: reasoning traces help the model induce, track, and update action plans as well as handle exceptions, while actions allow it to interface with external sources, such as knowledge bases or environments, to gather additional information. We apply our approach, named ReAct, to a diverse set of language and decision making tasks and demonstrate its effectiveness over state-of-the-art baselines, as well as improved human interpretability and trustworthiness over methods without reasoning or acting components. Concretely, on question answering (HotpotQA) and fact verification (Fever), ReAct overcomes issues of hallucination and error propagation prevalent in chain-of-thought reasoning by interacting with a simple Wikipedia API, and generates human-like task-solving trajectories that are more interpretable than baselines without reasoning traces. On two interactive decision making benchmarks (ALFWorld and WebShop), ReAct outperforms imitation and reinforcement learning methods by an absolute success rate of 34% and 10% respectively, while being prompted with only one or two in-context examples. Project site with code: this https URL
- Comments: v3 is the ICLR camera ready version with some typos fixed. Project site with code: this https URL
Towards Reasoning in Large Language Models: A Survey
- Jie Huang, Kevin Chen-Chuan Chang
- Reasoning is a fundamental aspect of human intelligence that plays a crucial role in activities such as problem solving, decision making, and critical thinking. In recent years, large language models (LLMs) have made significant progress in natural language processing, and there is observation that these models may exhibit reasoning abilities when they are sufficiently large. However, it is not yet clear to what extent LLMs are capable of reasoning. This paper provides a comprehensive overview of the current state of knowledge on reasoning in LLMs, including techniques for improving and eliciting reasoning in these models, methods and benchmarks for evaluating reasoning abilities, findings and implications of previous research in this field, and suggestions on future directions. Our aim is to provide a detailed and up-to-date review of this topic and stimulate meaningful discussion and future work. Comments: ACL 2023 Findings, 15 pages
Large Language Models Can Self-Improve
- Jiaxin Huang, Shixiang Shane Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu, Jiawei Han / Large Language Models (LLMs) have achieved excellent performances in various tasks. However, fine-tuning an LLM requires extensive supervision. Human, on the other hand, may improve their reasoning abilities by self-thinking without external inputs. In this work, we demonstrate that an LLM is also capable of self-improving with only unlabeled datasets. We use a pre-trained LLM to generate “high-confidence” rationale-augmented answers for unlabeled questions using Chain-of-Thought prompting and self-consistency, and fine-tune the LLM using those self-generated solutions as target outputs. We show that our approach improves the general reasoning ability of a 540B-parameter LLM (74.4%->82.1% on GSM8K, 78.2%->83.0% on DROP, 90.0%->94.4% on OpenBookQA, and 63.4%->67.9% on ANLI-A3) and achieves state-of-the-art-level performance, without any ground truth label. We conduct ablation studies and show that fine-tuning on reasoning is critical for self-improvement.
- https://arxiv.org/abs/2210.11610
Orca 2: Teaching Small Language Models How to Reason /
- https://arxiv.org/abs/2311.11045
- Orca 1 learns from rich signals, such as explanation traces, allowing it to outperform conventional instruction-tuned models on benchmarks like BigBench Hard and AGIEval. In Orca 2, we continue exploring how improved training signals can enhance smaller LMs’ reasoning abilities. Research on training small LMs has often relied on imitation learning to replicate the output of more capable models. We contend that excessive emphasis on imitation may restrict the potential of smaller models. We seek to teach small LMs to employ different solution strategies for different tasks, potentially different from the one used by the larger model. For example, while larger models might provide a direct answer to a complex task, smaller models may not have the same capacity. In Orca 2, we teach the model various reasoning techniques (step-by-step, recall then generate, recall-reason-generate, direct answer, etc.). More crucially, we aim to help the model learn to determine the most effective solution strategy for each task. We evaluate Orca 2 using a comprehensive set of 15 diverse benchmarks (corresponding to approximately 100 tasks and over 36,000 unique prompts). Orca 2 significantly surpasses models of similar size and attains performance levels similar or better to those of models 5-10x larger, as assessed on complex tasks that test advanced reasoning abilities in zero-shot settings. make Orca 2 weights publicly available at this http URL to support research on the development, evaluation, and alignment of smaller LMs
Blog: Self-Exam LLM and Reasoning
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Chain of Thought (CoT)
Chain-of-thought prompting incorporated with pre-trained large language models has achieved promising results on complex reasoning tasks. This paper proposes a new decoding strategy, named self-consistency, to replace the naive greedy decoding used in chain-of-thought prompting. Instead of only taking the greedy path, it first samples a diverse set of reasoning paths and then selects the most consistent answer by marginalizing out the sampled reasoning paths.
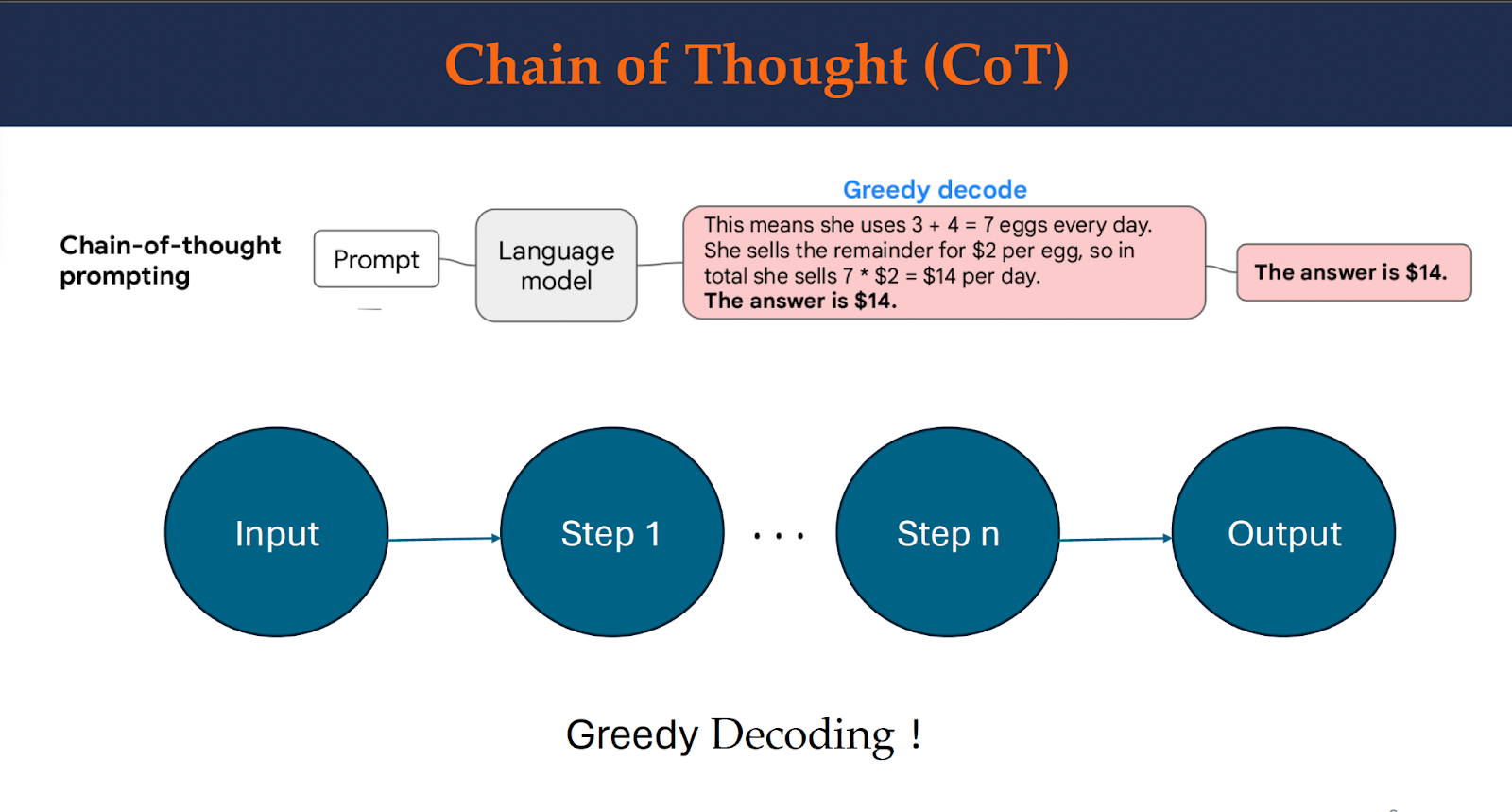
In this image, we demonstrate how greedy decoding works. However, there could be cases where multiple paths exist. In the next image, we will have a look at an example.

We can see that the word “LSTETRE” could form a valid English word with different combinations of characters in multiple stages. While option 1 and 2 can form the valid word “LETTERS” in 2 steps, option 3 forms the same word in 3 steps with different combinations of characters in each stage.
HereH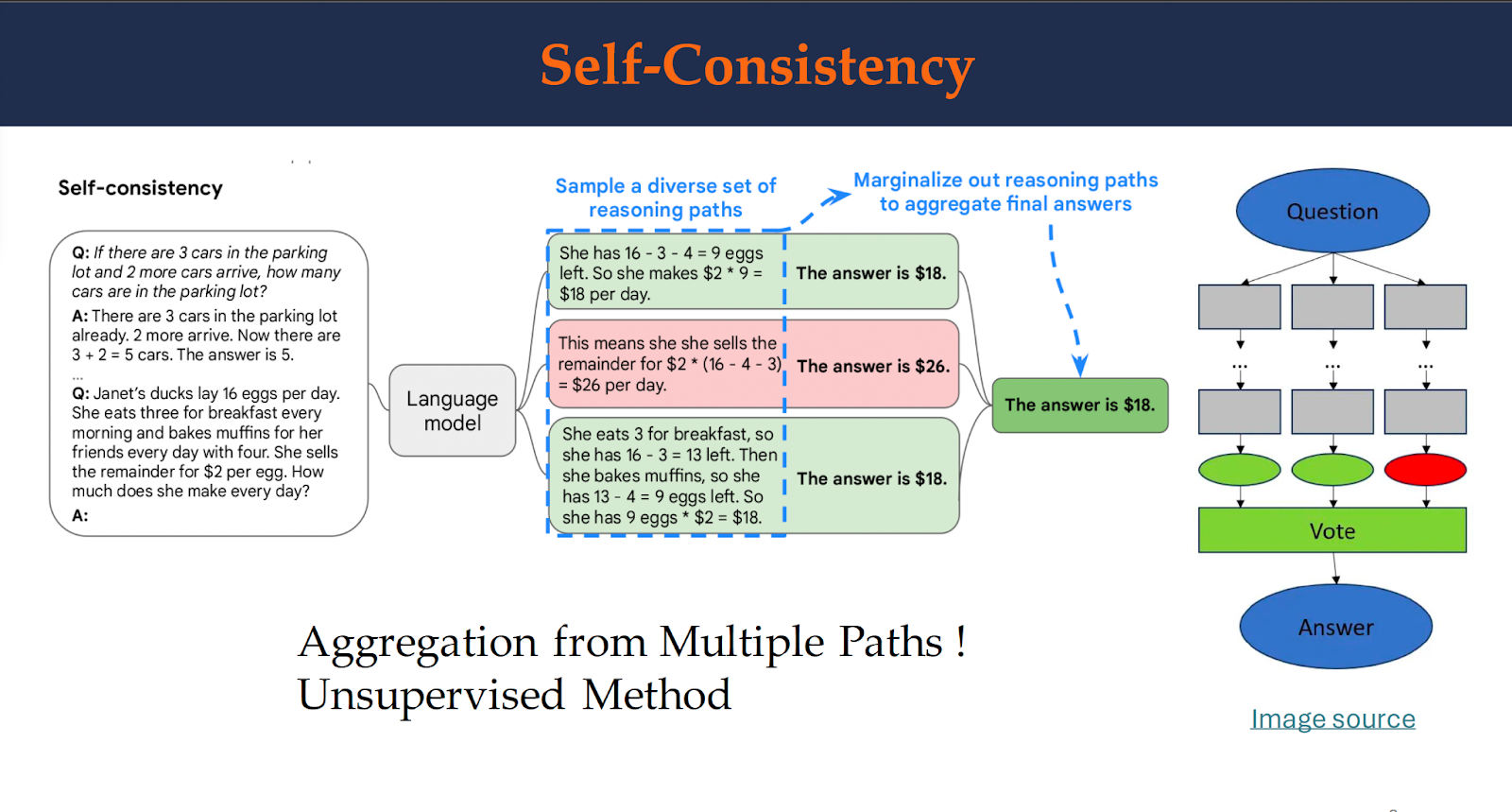
Here is an example of Self-Consistency. The self-consistency method contains three steps: (1) prompt a language model using chain-of-thought (CoT) prompting; (2) replace the “greedy decode” in CoT prompting by sampling from the language model’s decoder to generate a diverse set of reasoning paths; and (3) marginalize out the reasoning paths and aggregate by choosing the most consistent answer in the final answer set.

This figure shows the aggregation strategy. First, a language model is prompted with a set of manually written chain-of-thought examples. Next, a set of candidate outputs are sampled from the language model’s decoder, generating a diverse set of candidate reasoning paths. Self-consistency is compatible with most existing sampling algorithms, including temperature sampling, top-k sampling, and nucleus sampling. Finally, the answers are aggregated by marginalizing out the sampled reasoning paths and choosing the answer that is the most consistent among the generated answers.
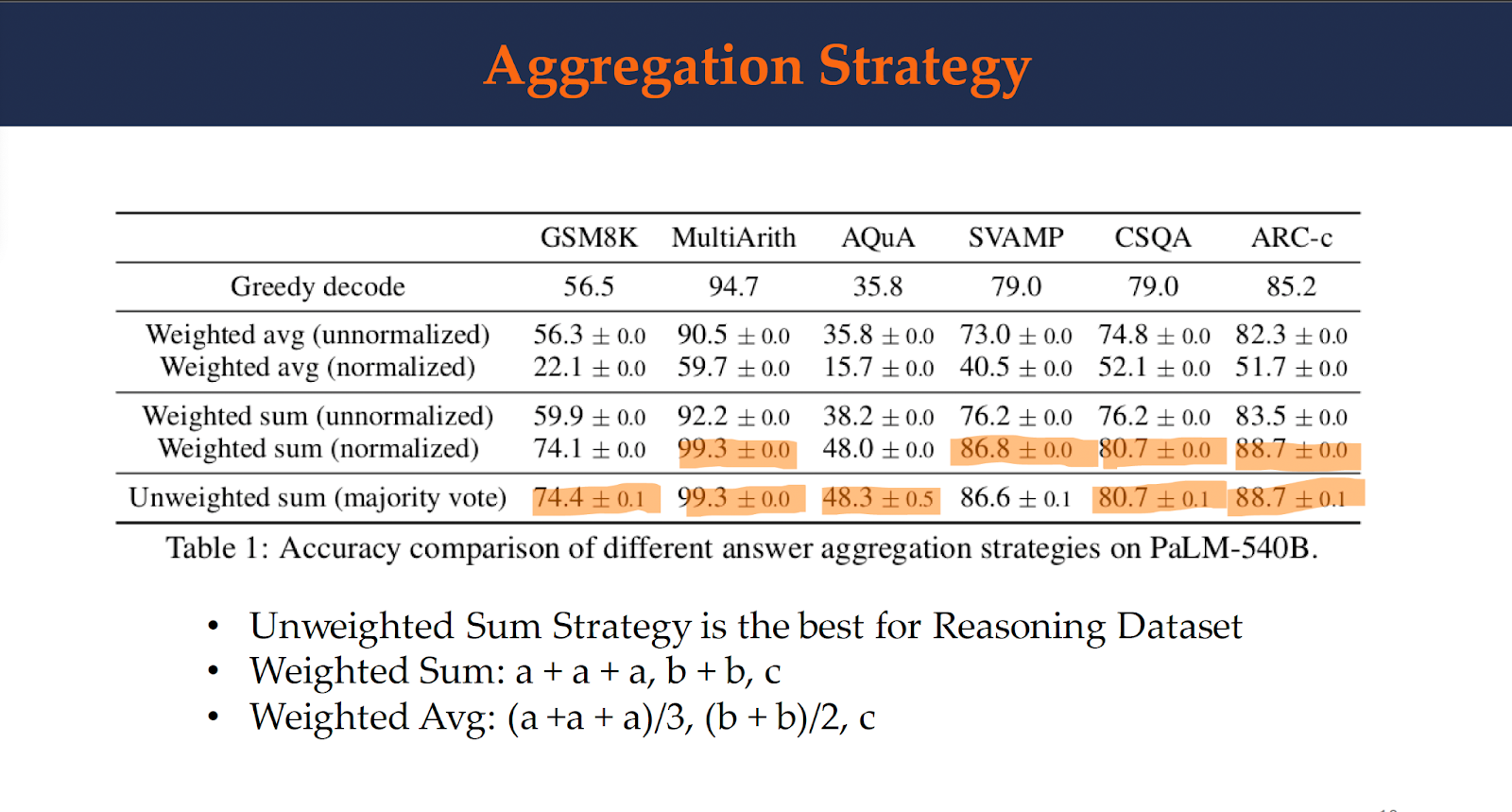
Table 1 shows the test accuracy over a set of reasoning tasks by using different answer aggregation strategies. It can be observed that the unweighted sum strategy is the best method for reasoning dataset. Here is examples where self-consistency improved the performance over the greedy decoding.

Experimental Setup
Tasks and associated datasets. The self-consistency was evaluated on the following reasoning benchmarks.

Language models and prompts. Self-consistency was also evaluated over four transformer-based language models with varying scales:

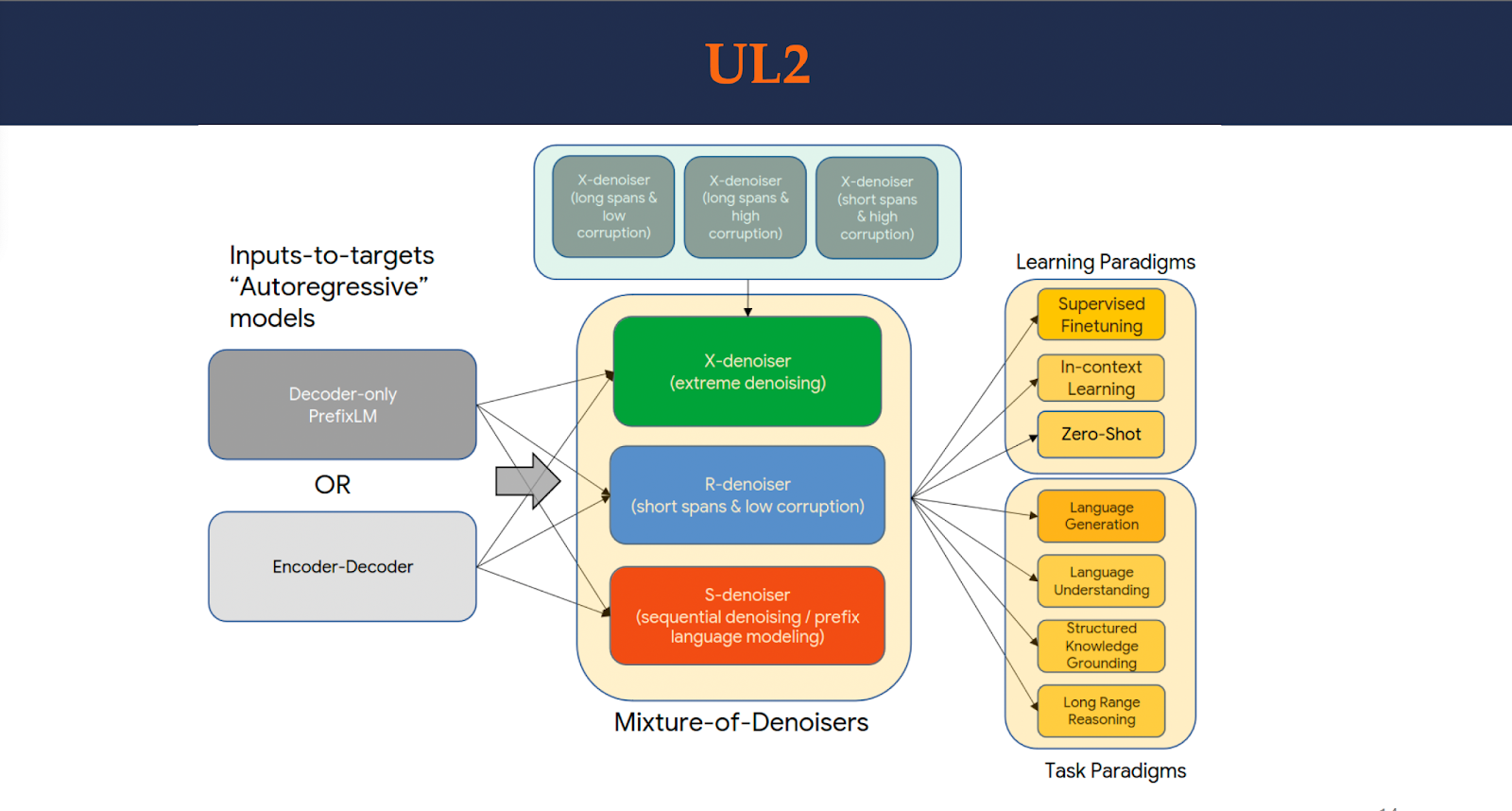
UL2 is an encoder-decoder model trained on a mixture of denoisers with 20- billion parameters. UL2 is completely open-sourced4 and has similar or better performance than GPT-3 on zero-shot SuperGLUE, with only 20B parameters and thus is more compute-friendly.
Main Results
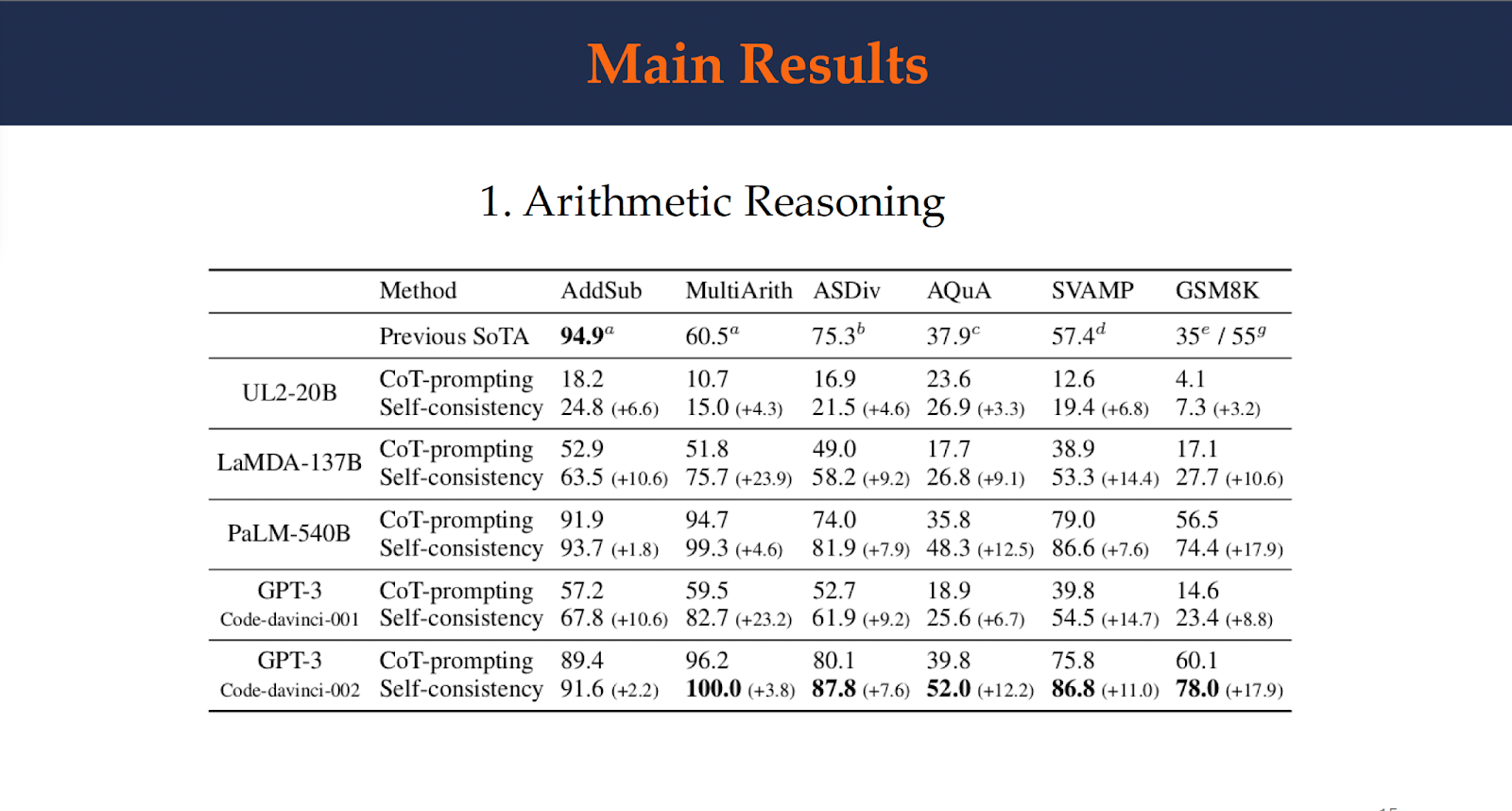
This figure shows the arithmetic reasoning accuracy by self-consistency compared to chain-of-thought prompting. Self-consistency improves the arithmetic reasoning performance over all four language models significantly over chain-of-thought prompting. With self-consistency, a new state-of-the-art results are achieved on almost all tasks.
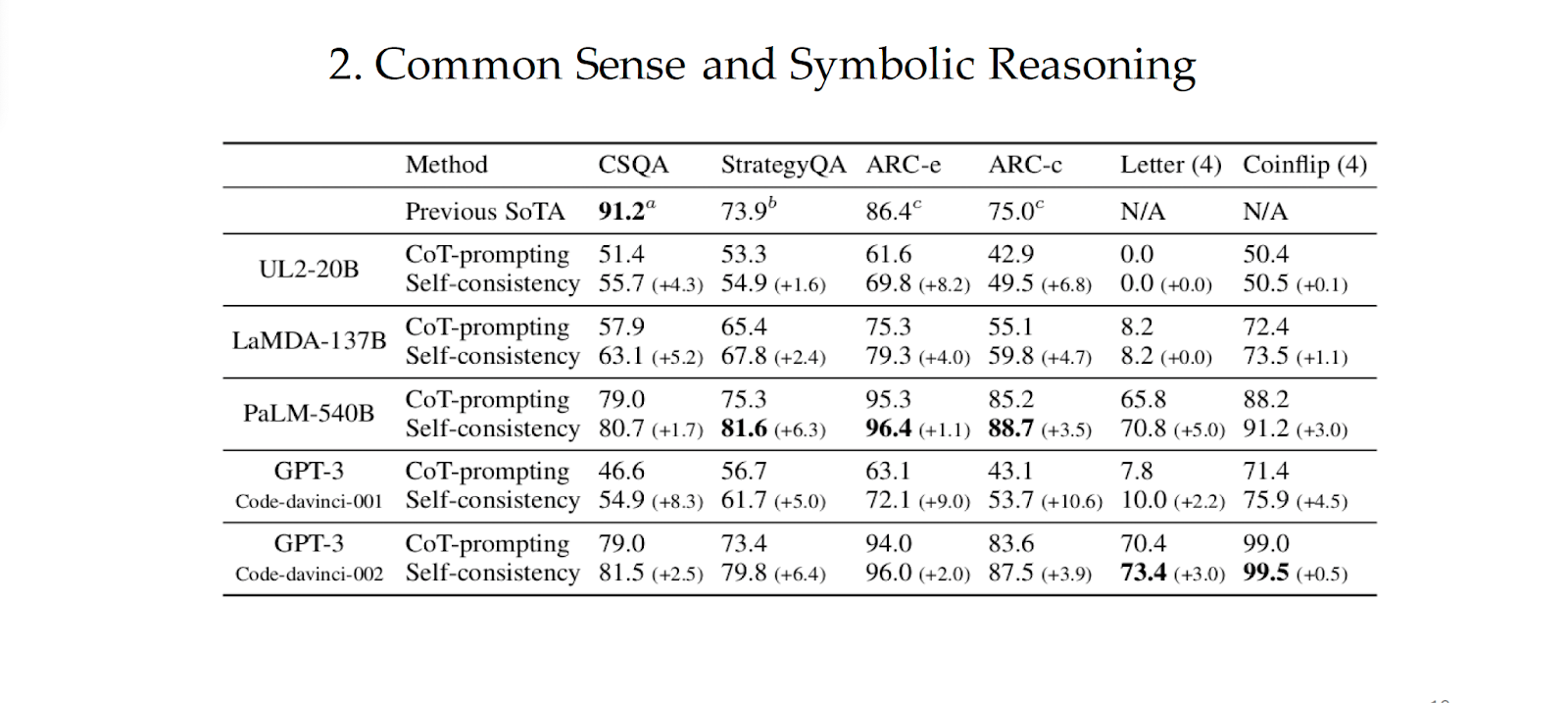
Here is the commonsense and symbolic reasoning accuracy by self-consistency compared to chain-of-thought prompting. Self-consistency yields large gains across all four language models, and obtained SoTA results on 5 out of 6 tasks. For symbolic reasoning, we test the out-of-distribution (OOD) setting where the input prompt contains examples of 2-letters or 2-flips but we test examples of 4-letters and 4-flips. In this challenging OOD setting, the gain of self-consistency is still quite significant compared to CoT-prompting with sufficient model sizes.
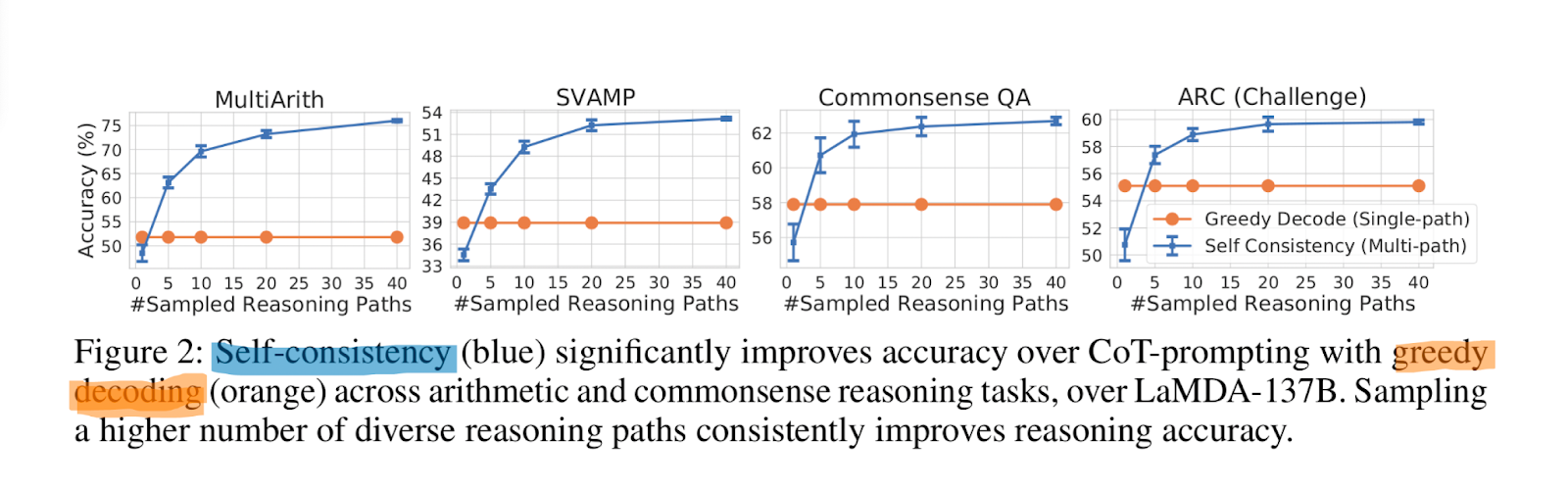
To show the effect of the number of sampled reasoning paths, the authors have plotted the accuracy (mean and standard deviation over 10 runs) with respect to varying numbers of sampled paths (1, 5, 10, 20, 40) in Figure 2. The results show that sampling a higher number (e.g., 40) of reasoning paths leads to a consistently better performance, further emphasizing the importance of introducing diversity in the reasoning paths.
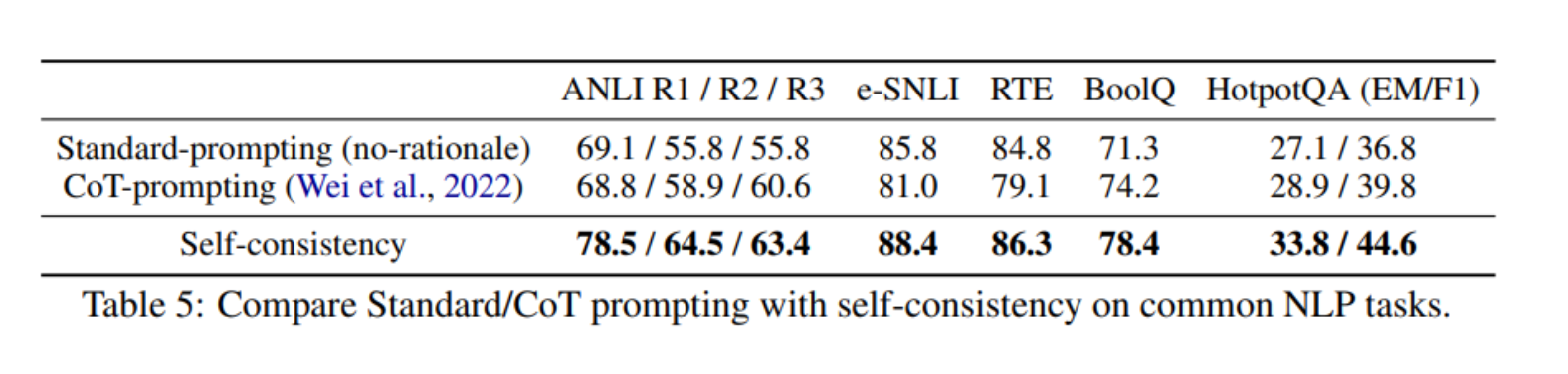
Self-Consistency vs Chain of Thought
Chain-of-thought can hurt performance compared to standard prompting in few-shot in-context learning.

Self-consistency can robustly boost the performance and outperform standard prompting, making it a reliable way to add rationales in few-shot in-context learning for common NLP tasks.
Self-Consistency vs Sample-and-Rank
What is Sample-and-Rank?
-
Approach to improve generation quality
-
Multiple sequences sampled
-
Ranked according to each sequence’s log probability
The authors compared self-consistency with sample-and-rank on GPT-3 code-davinci-001. Sample-and-rank slightly improves accuracy with more samples, but not as much as self-consistency.
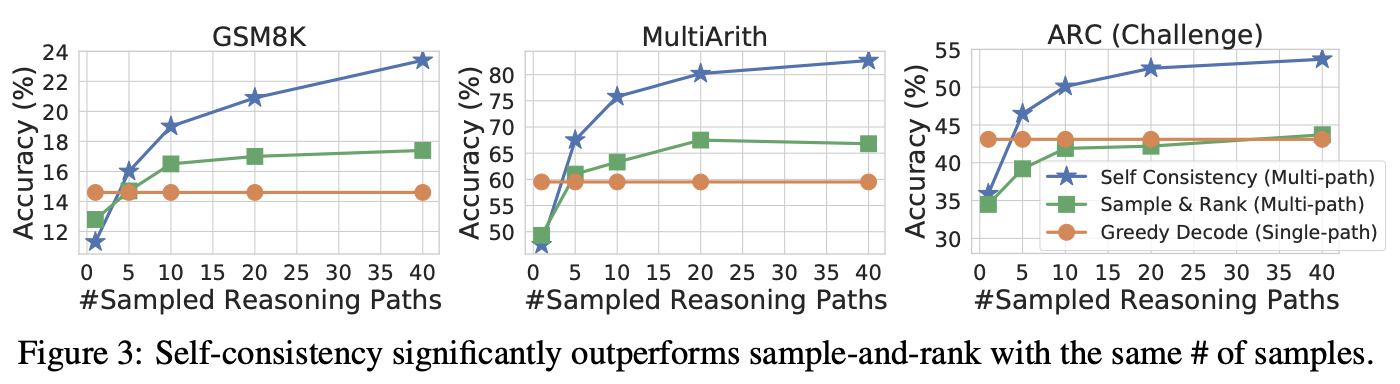
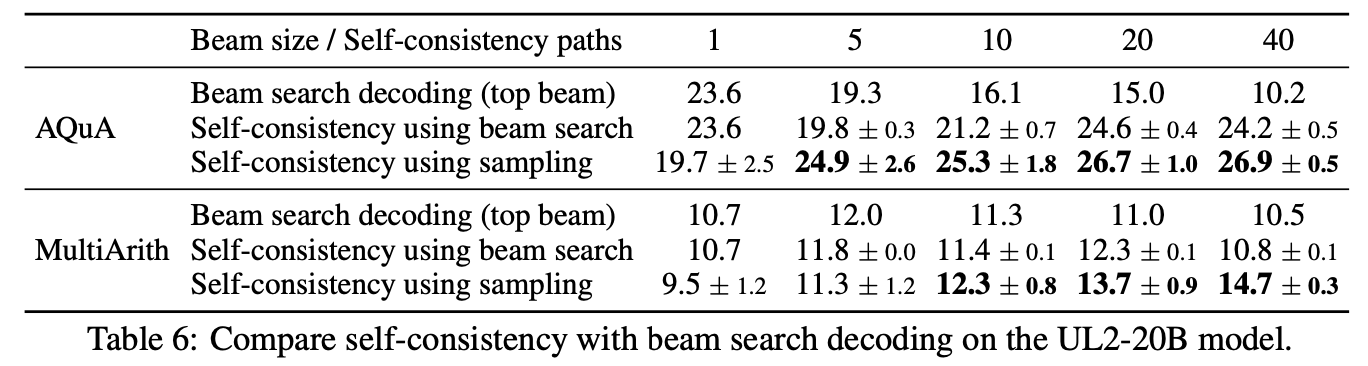
Self-Consistency vs Beam Search
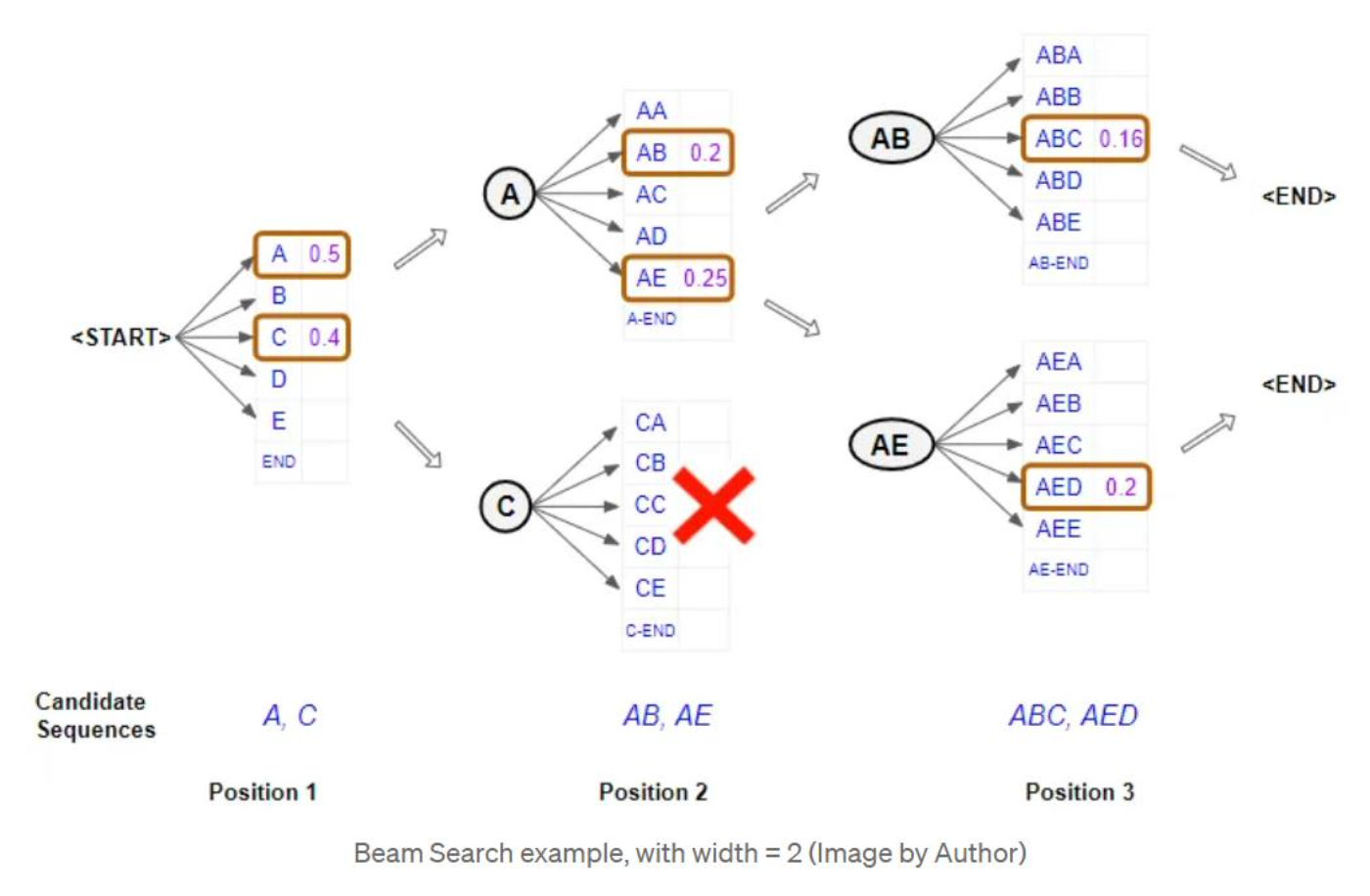
Accuracy reported on same number of beams and reasoning paths
Self-consistency can adopt beam search
- Worse performance than self-consistency
In self-consistency the diversity of the reasoning paths is the key to a better performance
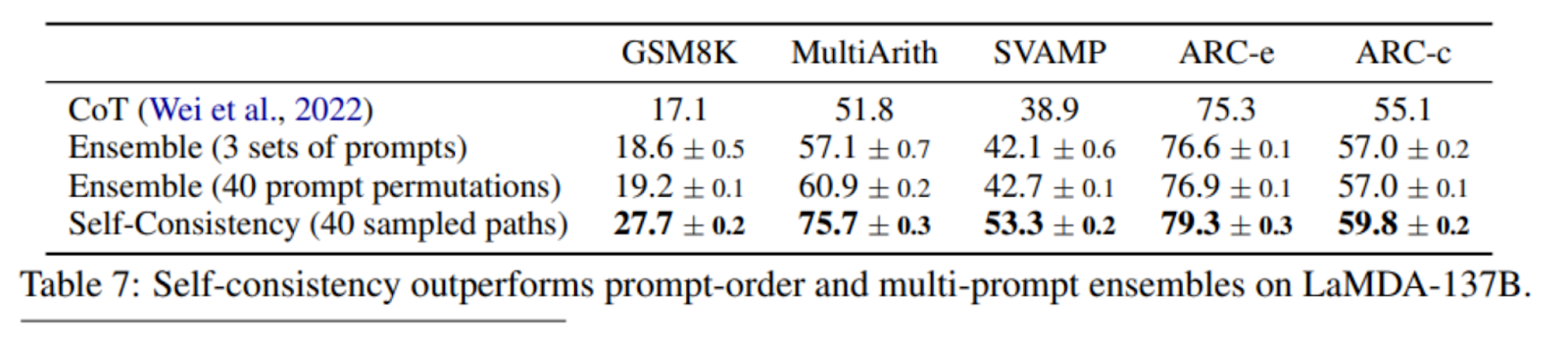
Self-Consistency vs Ensemble-Based Approaches
-
Methods of ensembling
-
Prompt order permutation
-
Multiple sets of prompts
-
Majority vote used
-
-
Self-consistency acts like a “self-ensemble”
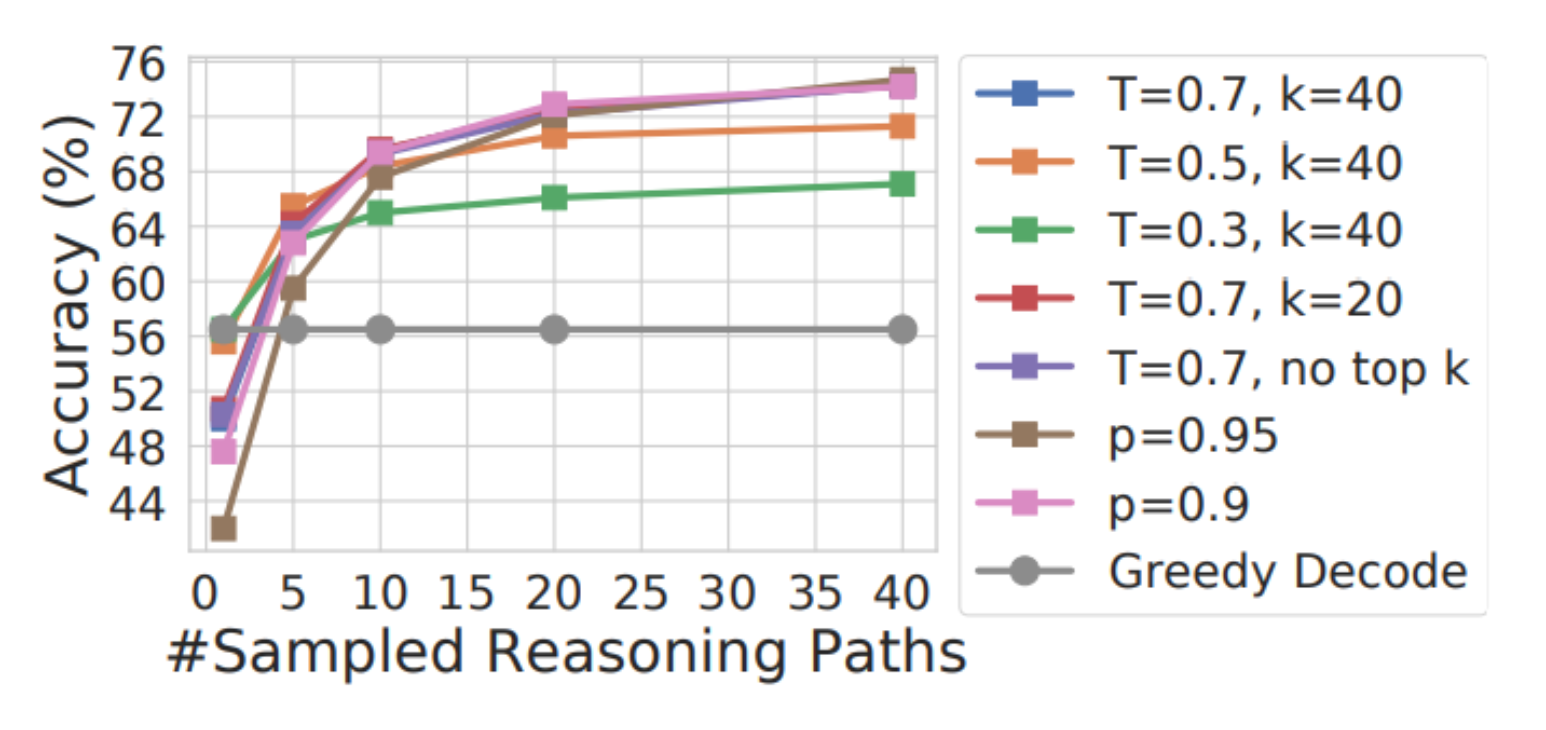
Robustness to Sampling Strategies
Robust to sampling strategies and parameters
-
Temperature
-
k in top-k sampling
-
p in nucleus sampling
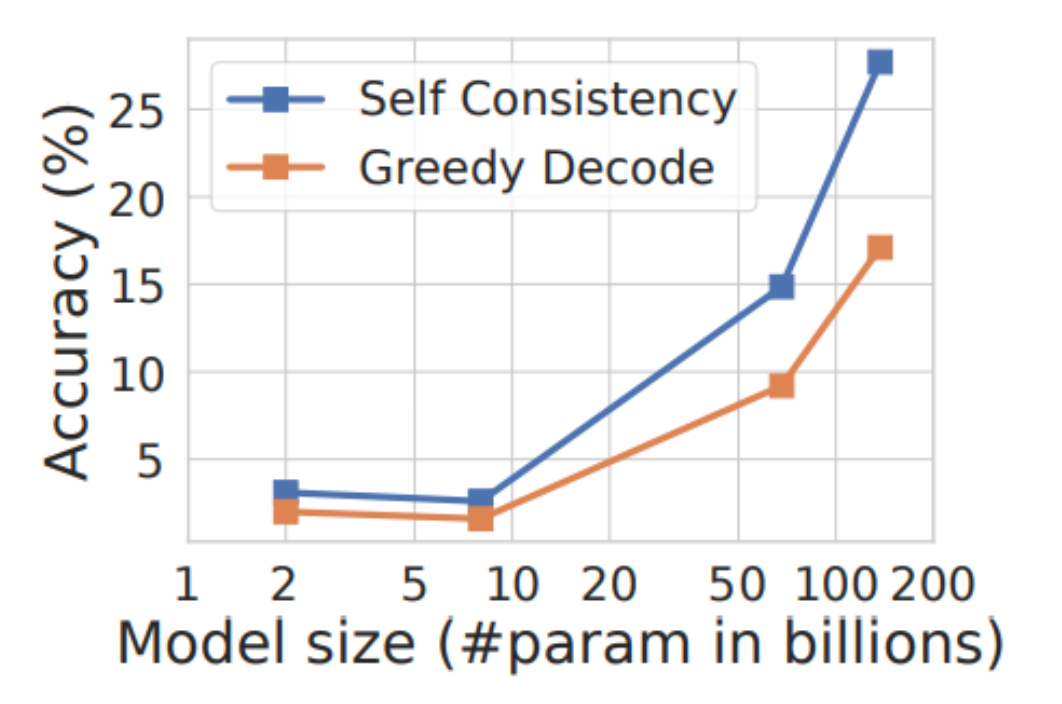
Robustness to Scaling
Self-consistency robustly improves performance across all scales for the LaMDA-137B model series. The gain is relatively lower for smaller models due to certain abilities (e.g., arithmetic) only emerge when the model reaches a sufficient scale.
Prompt Robustness
Improves robustness to imperfect prompts
-
Mistakes can lead to lower greedy accuracy (17.1→ 14.9)
-
Self-consistency can fill in the gaps and improve results

Self-Consistency Robustness
Consistency highly correlated with accuracy
- % of decodes agreeing with final aggregated answer
Self-consistency can be used to provide uncertainty estimate of the model
- Confers some ability for model to “know when it doesn’t know”
Non NL Reasoning Paths
The authors tested the generality of the self-consistency concept to alternative forms of intermediate reasoning like equations (e.g., from “There are 3 cars in the parking lot already. 2 more arrive. Now there are 3 + 2 = 5 cars.” to “3 + 2 = 5”).
Compared to generating natural language reasoning paths, the gain is smaller since the equations are much shorter and less opportunity remains for generating diversity in the decoding process.
Zero-Shot Learning
Self-consistency works for zero-shot CoT as well and improves the results significantly (+26.2%) in Table 8.
Related Work
Language models struggle with Type 2 tasks
-
Arithmetic, logical, commonsense reasoning
-
Previous work focused on specialized approaches
Re-ranking
- Requires training of additional ranker
Self-consistency more widely applicable
Discussion
Self-consistency improves task accuracy
-
Collect multiple reasoning rationales
-
Provide uncertainty estimates
Limitations
- Computational Cost
Use self-consistency to generate better supervised data
- Fine-tuning
Language models sometimes generate nonsensical reasoning paths
- Better ground models’ rationale generations
Augmented Language Models: a Survey
Mialon et. al, in their paper “Augmented Language Models: a Survey” discuss how LLMs are augmented with reasoning and tools to overcome some of the LLMs inherent limitations.
More specifically, LLMs suffer from hallucinations, are optimized to perform on a limited statistical context (next token prediction), and are expensive to retrain and keep up to date due to their size and need for large amounts of data.
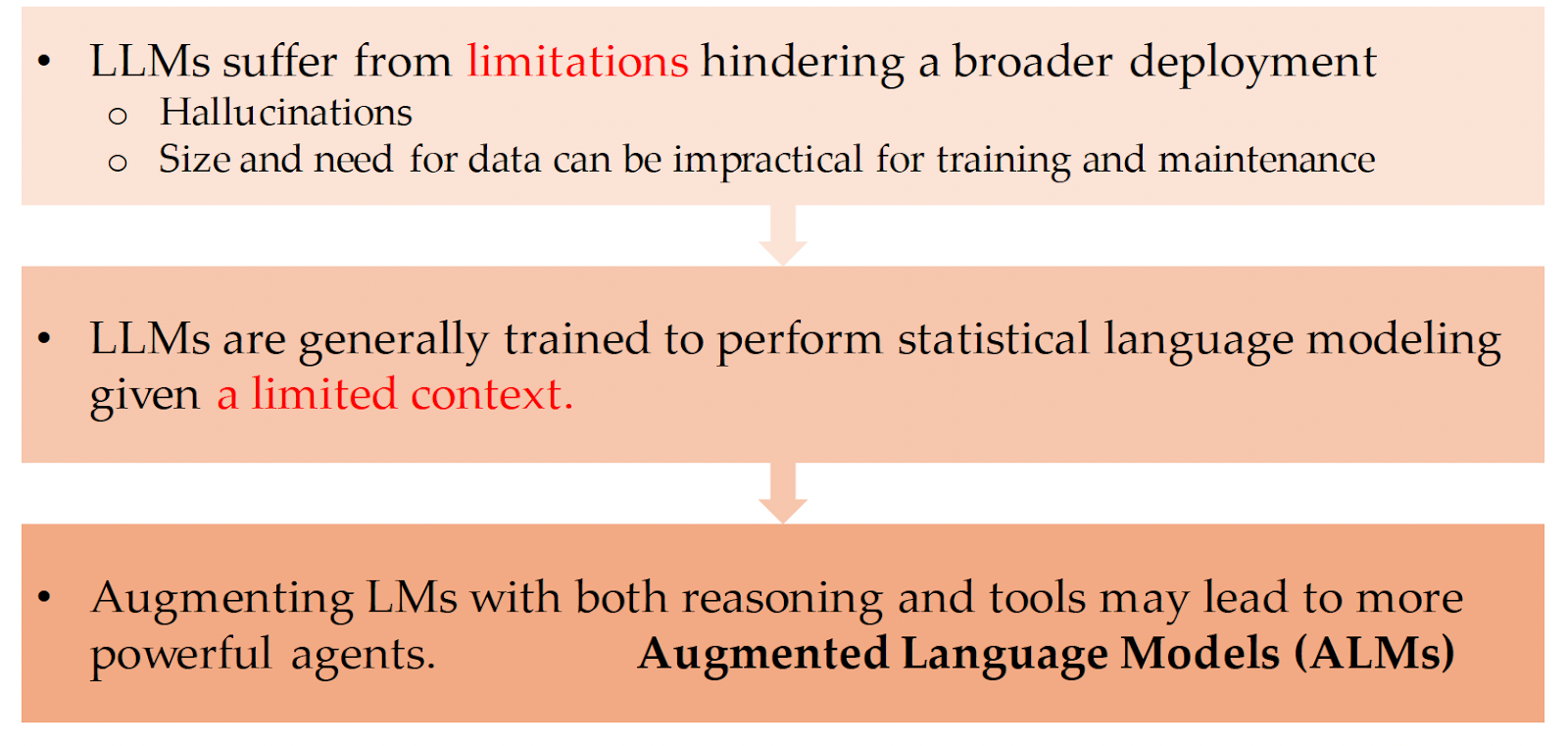
The authors define reasoning and Reasoning, Tools, and Actions as the following: 
Reasoning in LLMs can elicited in a few ways. First, reasoning can be evoked through prompting techniques such as chain-of-thought prompting, self-ask and self-consistency: 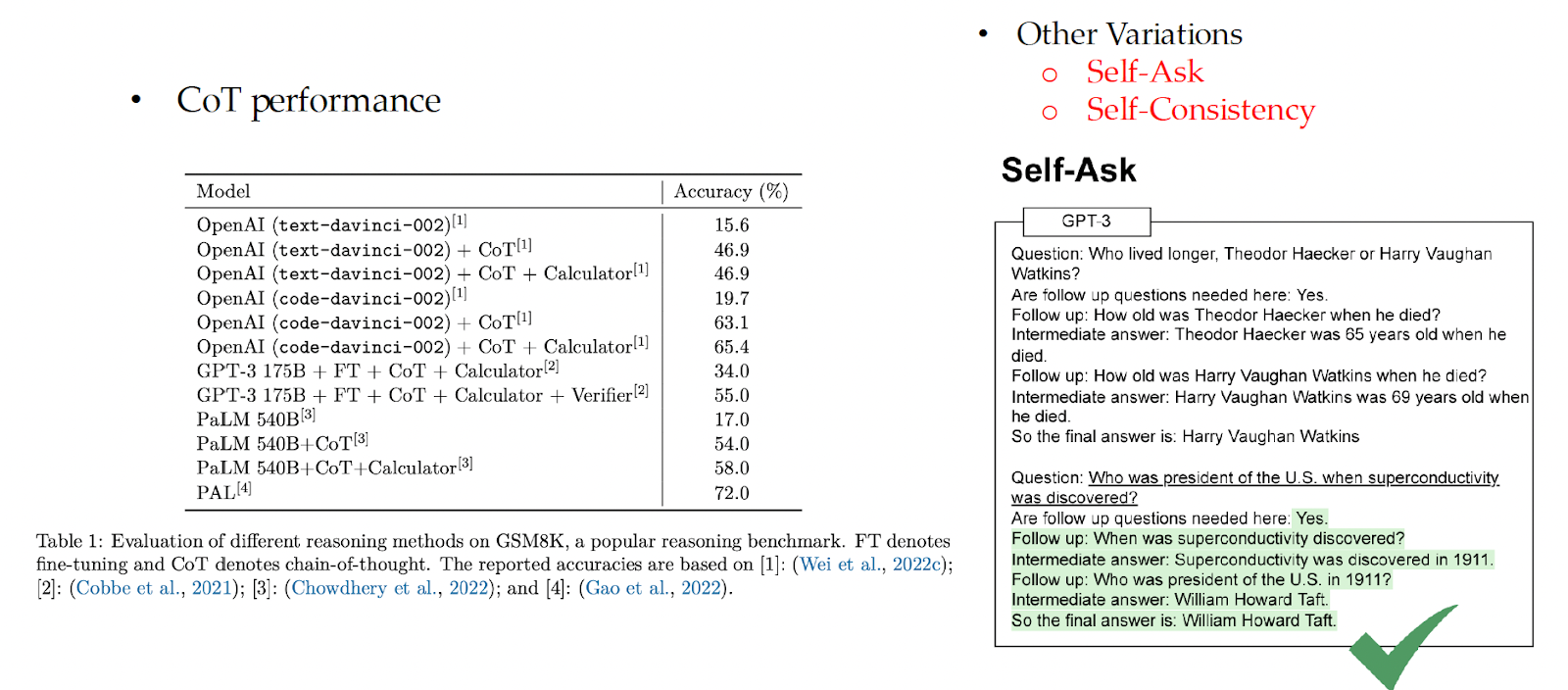
Reasoning can be evoked through recursive prompting, which breaks down the problem at hand into sub-problems. This involves the least-to-most prompting and decomposed prompting techniques. 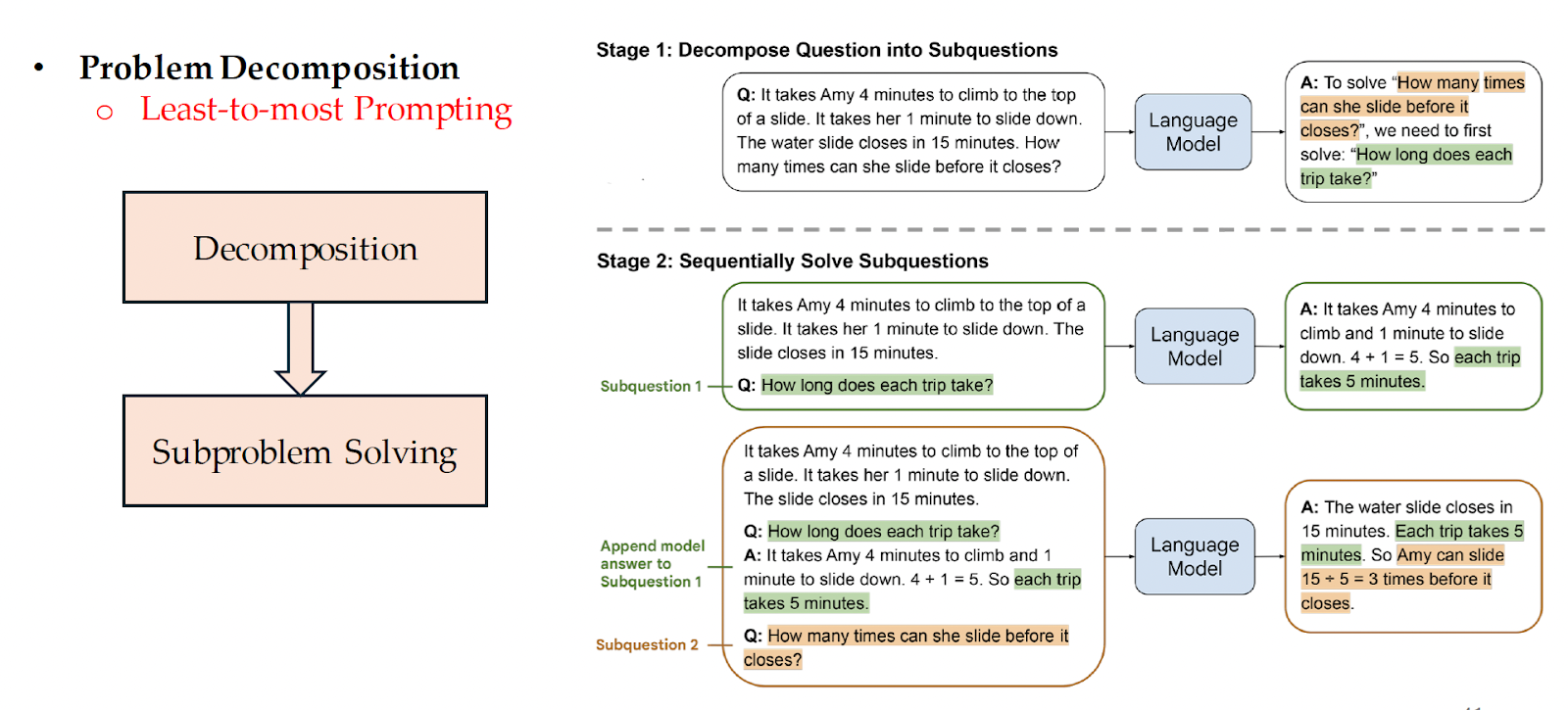 Finally, LLMs can be explicitly taught to reason. For example, LLMs can be trained to perform multi-step computations by asking them to emit intermediate computation steps into a “scratchpad”.
Finally, LLMs can be explicitly taught to reason. For example, LLMs can be trained to perform multi-step computations by asking them to emit intermediate computation steps into a “scratchpad”. These methods can only go so far. Where the models fail at reasoning, tools followed by actions can be used to overcome these limitations. Using tools can follow 4 paradigms:
These methods can only go so far. Where the models fail at reasoning, tools followed by actions can be used to overcome these limitations. Using tools can follow 4 paradigms:
-
Calling another model
-
Information retrieval
-
Computing via symbolic modules and code interpreters
-
Acting on virtual and physical world

An example of calling another model is PEER. This is an LLM trained to produce a plan of action and edit the input text at each step.

Similarly, Visual Language Models (VLMs) are trained on large-scale multimodal web corpora containing interleaved text and images, and they display few-shot learning capabilities of multimodal tasks. The other modalities are augmented to the model during training so that their representations are aligned with the LLM.  LLMs can also be conditioned on information-retrieval. This is called retrieval-augmented LLMs.
LLMs can also be conditioned on information-retrieval. This is called retrieval-augmented LLMs.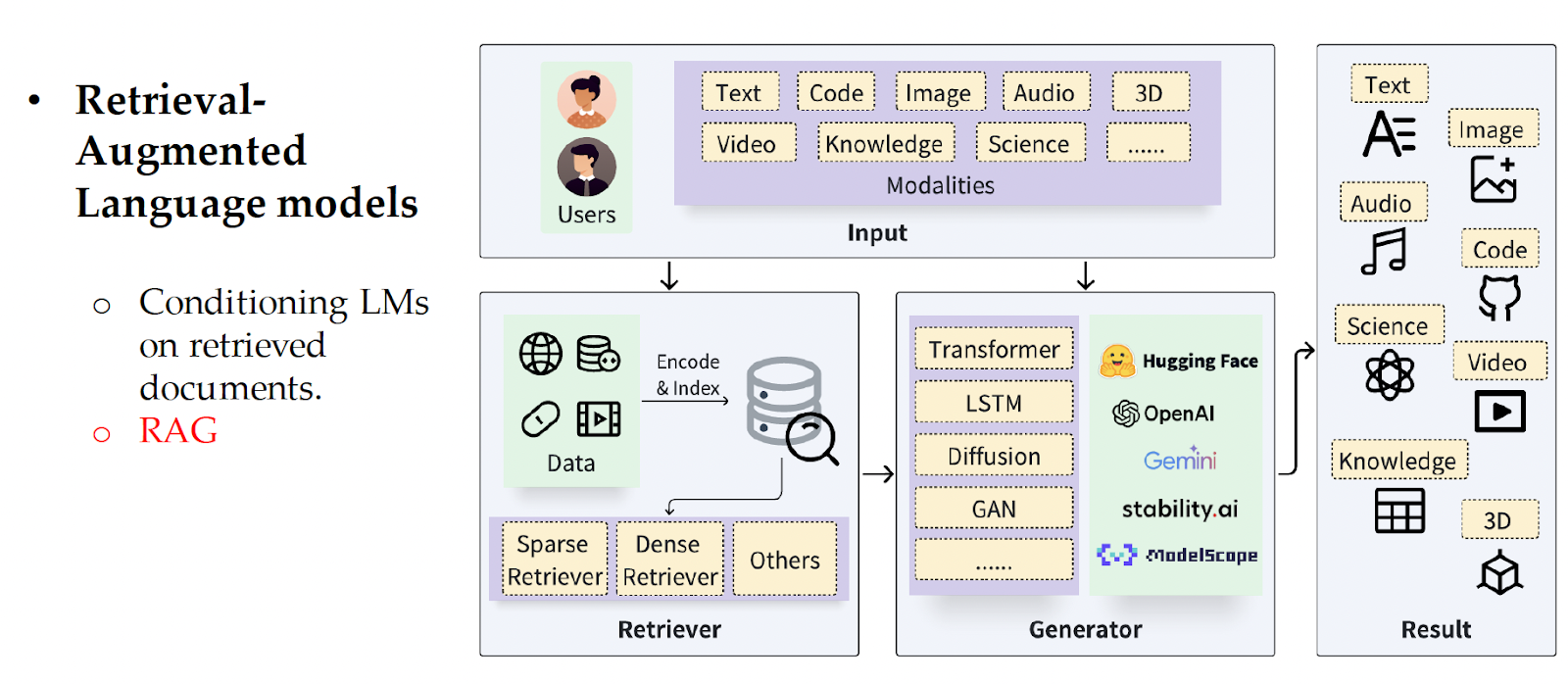
One way LLMs can retrieve information is through querying search engines to enhance what the LLM generates. 
ReAct combine information retrieval with the reasoning ability of LLMs, which performs reasoning and acting in an interleaved manner.

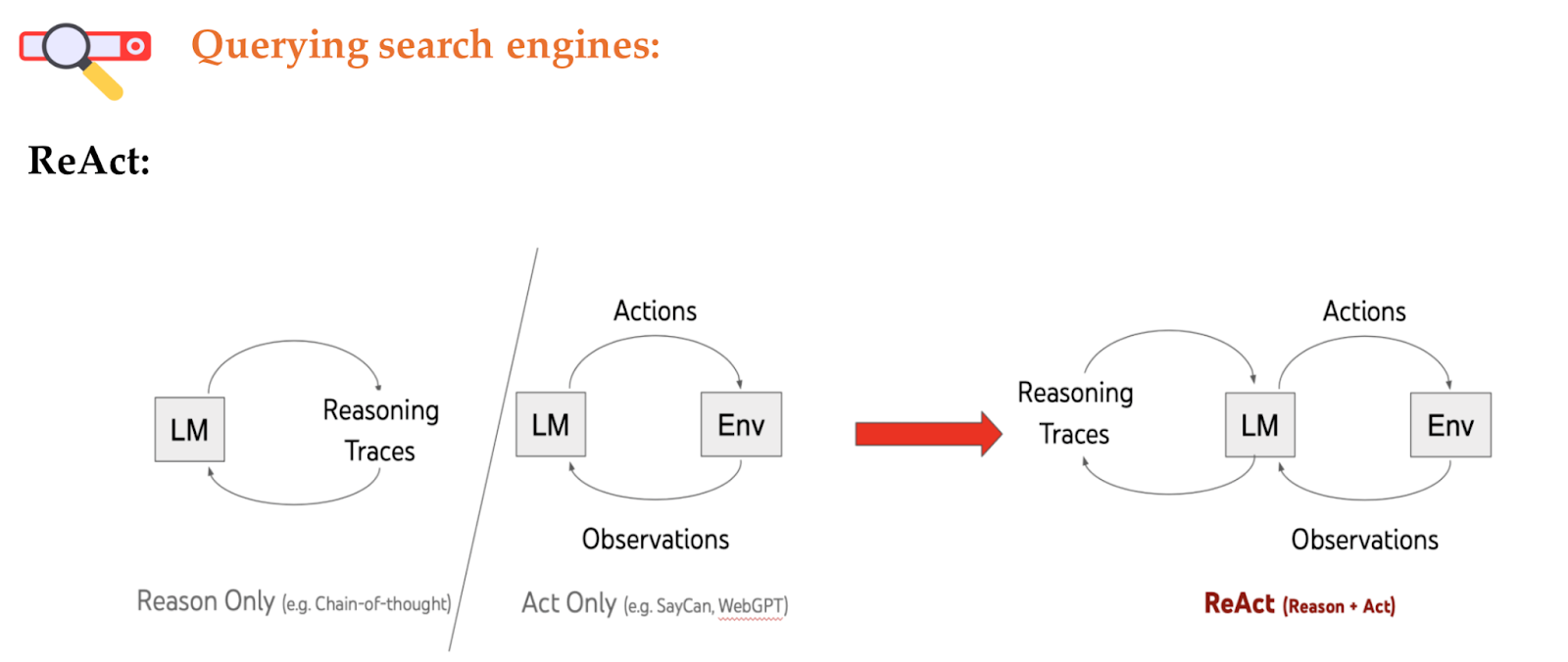
The example below shows how ReAct performs on a question from Hopsopt QA

Beyond the vanilla information retrieval, letting LLMs search and navigate the web directly is another effective way to augment LLMs, which is demonstrated by WebGPT.

Combing LLMs with symbolic modules or code interpreters is another augmentation practice which can equipped the transformer-based deep neural networks with symbolic reasoning ability.

The digram below illustrates how a Program-aided Language models (PAL) help derive the correct answer with intermediate steps and Python code.

To sum up, through innovative integrations of external tools/modules, LMs are overcoming their limitations, showcasing remarkable versatility and improved performance in complex reasoning and computational tasks.
The augmented techniques above use tools to gather external information to improve performance of LLMs on a given task. There are also approaches that allow LLMs to act on the virtual or physical world.
The example below shows how researchers attempt to use LMs to control physical robots, which can be performed by prompting the model to write robot policy code using natural language commands.

While the augmented LMs are a promising direction for future research, it is important to teach them how to reason, use tools, and act.

For prompt pre-training, here are some tips:

For Bootstrapping, here are some tips
If LLM Is the Wizard, Then Code Is the Wand: A Survey on How Code Empowers Large Language Models to Serve as Intelligent Agents
This paper explores the symbiotic relationship between LLMs and code, highlighting how integrating code into LLM training enhances their abilities. By incorporating code, LLMs gain reasoning capabilities, produce structured outputs, and leverage the feedback loop of code compilation and execution environments. This integration not only improves LLM performance in code generation but also extends their utility as intelligent agents, enabling them to understand instructions, decompose goals, plan and execute actions, and refine based on feedback, thus opening up new possibilities for complex natural language tasks.
Code Pretraining and Code Finetuning
Code Pretraining:
-
When the code corpus is sourced from publicly accessible code repositories, such as GitHub, it yields a volume comparable to that of natural language pre-training. We call training with such an abundance of code as code pretraining.
-
This process consists of training code on a pre-trained natural language LLM or or training a LLM from scratch with a blend of natural language and code falls within code pretraining.
Code Finetuning:
- When dataset is smaller compared to the pre-trained natural language corpus, we refer to such training process as code fine-tuning. The objective is to acquainting the model with mathematical proof formulas, SQL etc.
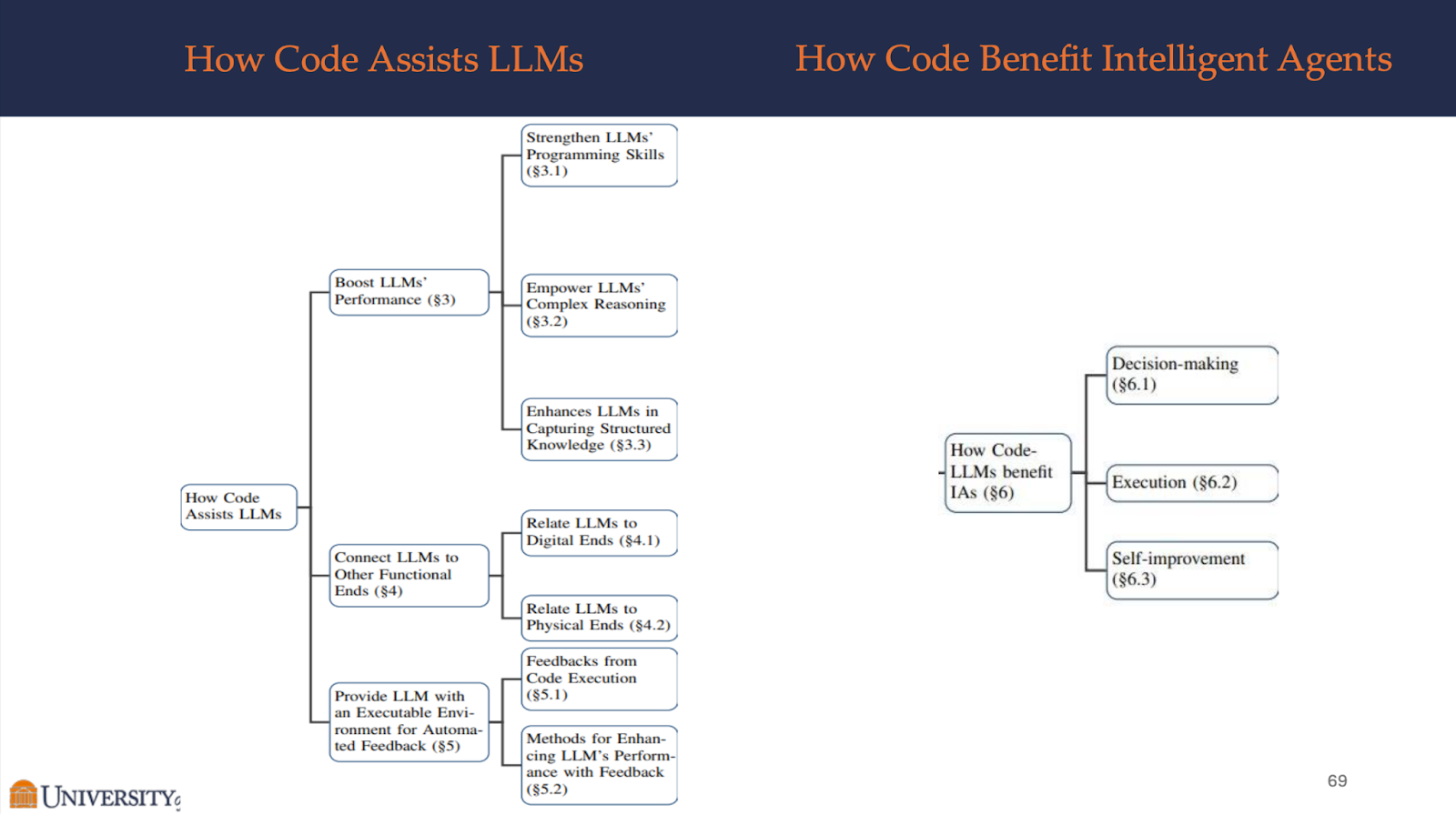
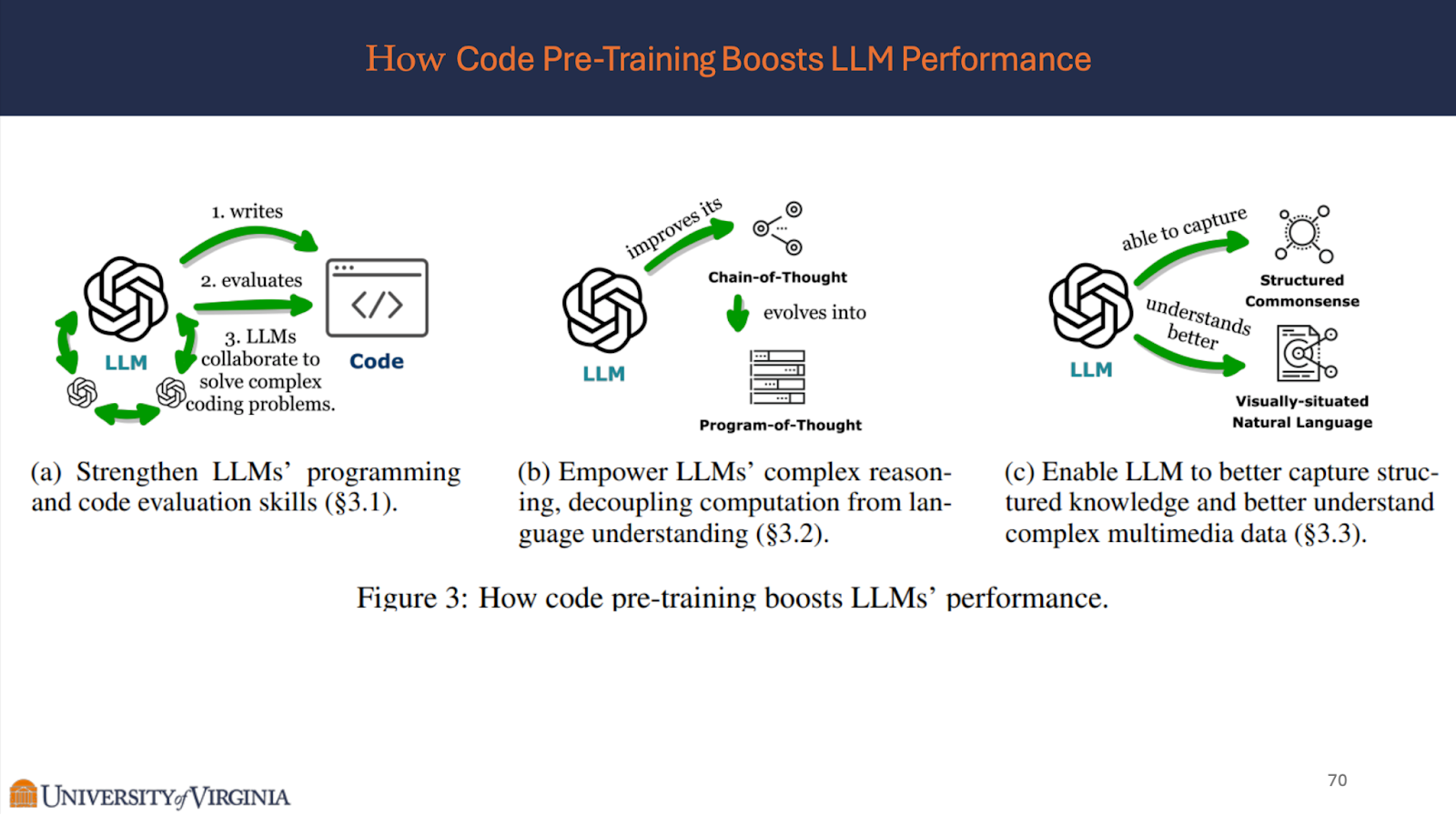
- Strengthen LLMs’ Programming Skills

-
Coder
-
PolyCoder master more than 10 languages
-
CodeX with 12 billion parameters that reads the entire GitHub database and is able to solve 72.31% of challenging Python program
-
Evaluator
-
Code fault localization
-
GPT-3.5 to evaluate the functional correctness and human preferences
-
-
Collaborative Coding:
- Assigning three roles: analyst, coder, and tester to three distinct “GPT-3.5”s, which surpasses GPT-4 in code generation
- Empower LLMs’ Complex Reasoning (Chain-of-thought, Program-of-thought )

-
Chain of Thought
- LLMs pre-trained on code, such as GPT-3’s text-davinci-002 and Codex (Chen et al., 2021), see a dramatic performance improvement arising from CoT , with a remarkable accuracy increase of 15.6% to 46.9% and 19.7% to 63.1% respectively
-
Program of Thought:
-
Enhances performance due to the precision and verifiability inherent in code
-
Executing code and verifying outcomes post translation by LLMs, one can effectively mitigate the effects of incorrect reasoning in CoT
-
- Enable LLMs to Capture Structured Knowledge
-
Commonsense reasoning:
-
Code possesses the graph structure of symbolic representations
-
Leveraging programming language for representing visual structural information and curriculum learning for enhancing the model’s understanding of visual structures
-
-
Markup code:
-
Utilizing markup code such as HTML and CSS to for structured graphical information in graphical user interfaces
-
WebGUM showcased the effectiveness of pre-training model with markup code
-
Connecting LLMs to other Functional Ends
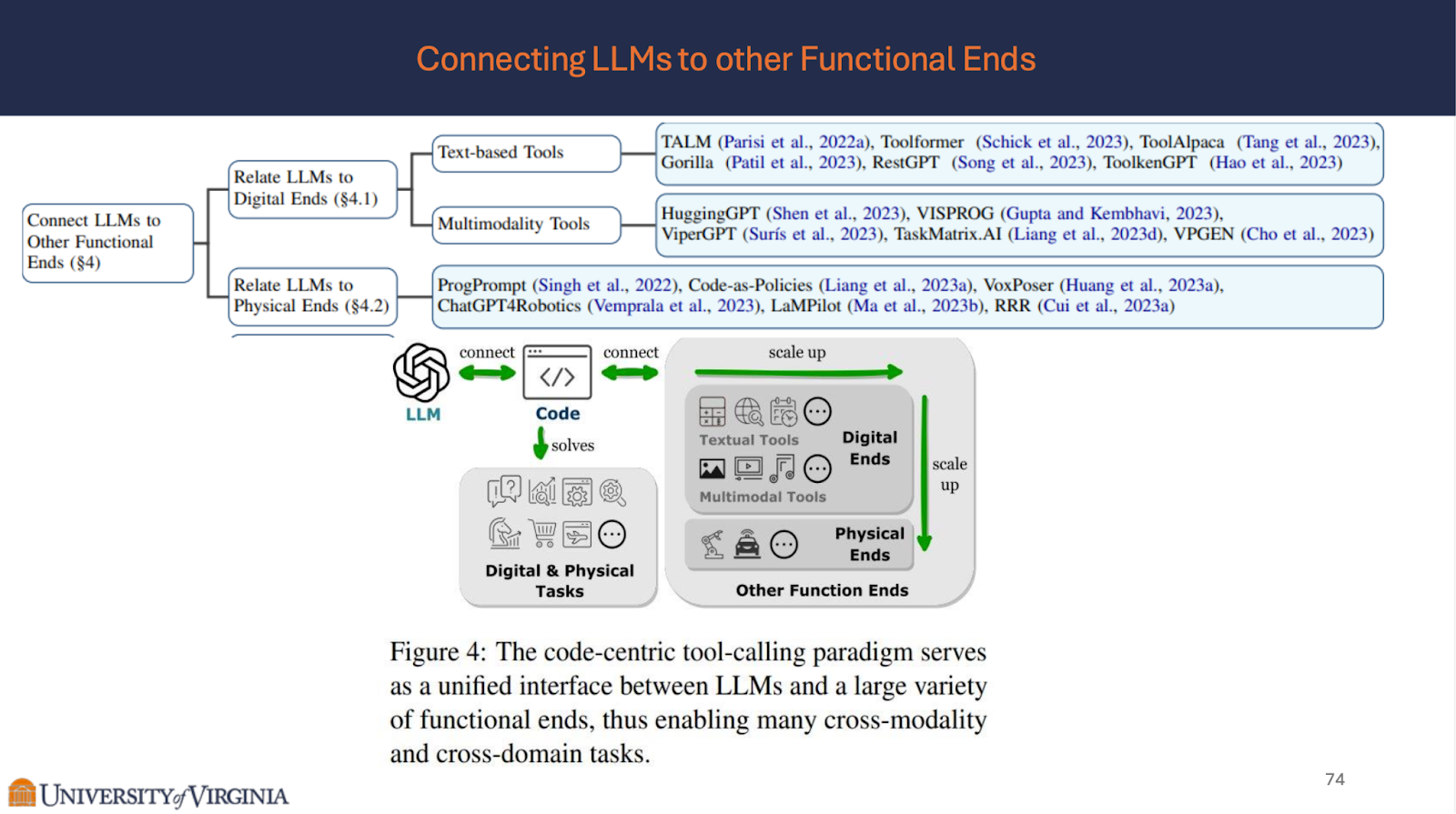
Embedding LLMs into Code Execution Environment
-
LLMs demonstrate performance beyond the parameters of their training due to their ability to intake feedback
-
Embedding LLMs into a code execution environment enables automated feedback
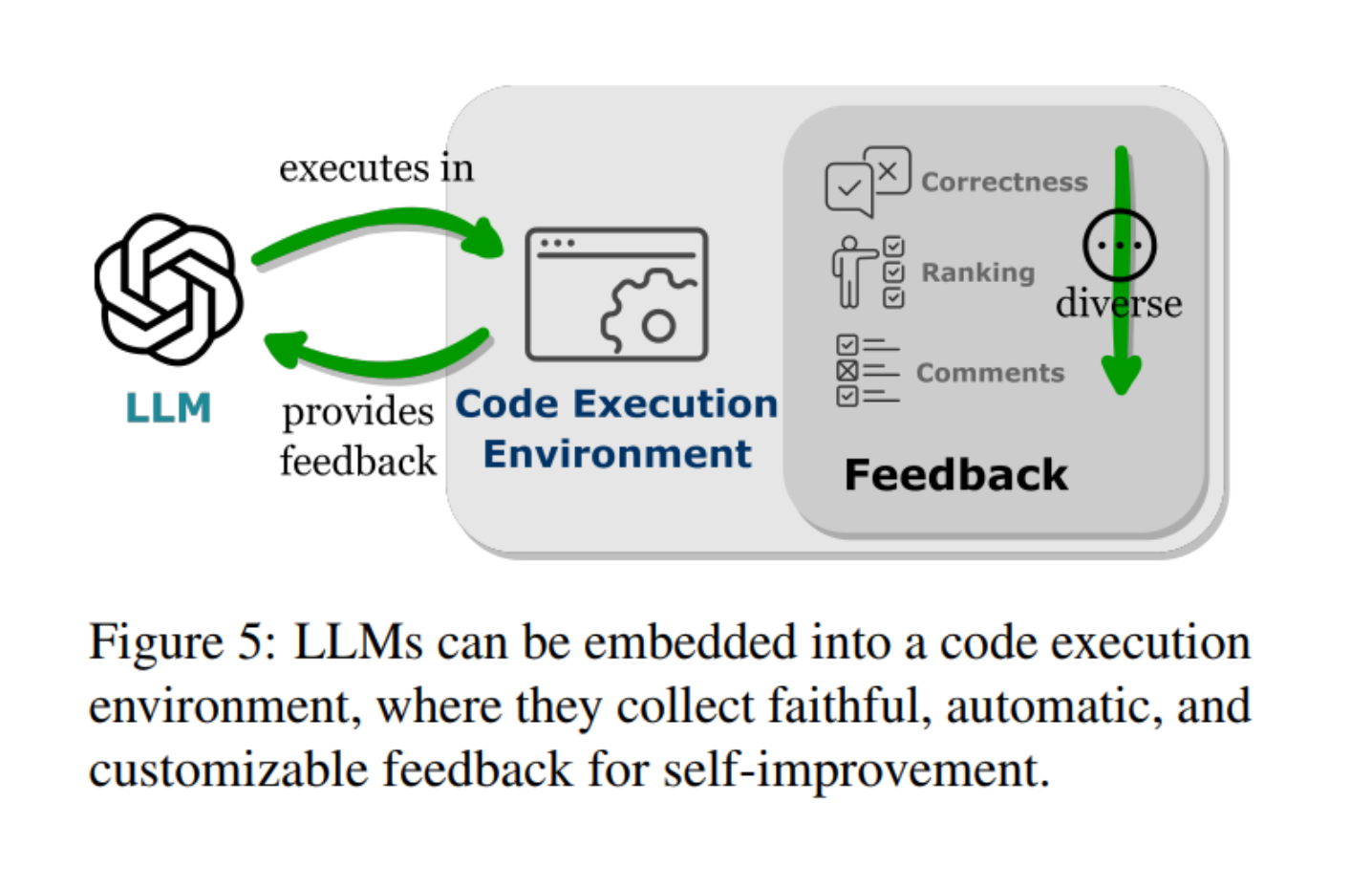
Automated Feedback
-
Program execution outcomes and generating feedback include the
-
Creation of unit tests
-
Application of exact result matching techniques
-
-
From these, feedback can be provided in two primary forms:
-
Simple correctness feedback and (whether a program is correct or not )
-
Textual feedback (explanations about the program or its summarization)
-
-
Execution results can also be translated into reward functions using predefined rules. The rules map execution results into scalar values based on the severity of different error types suitable for reinforcement learning approaches.
-
Additional feedback can be extracted by performing static analysis using software engineering tools
Enhancing LLM’s Performance with Feedback
The feedback derived from code execution and external evaluation modules can enhance LLMs through three major approaches:
-
Selection Based Method (majority voting and re-ranking )
-
Prompting Based Methods and (“self-debugging” with in-context learning)
-
Finetuning Methods (improve the LLMs by updating their parameterized knowledge)
-
Direct Finetuning from feedback
-
Generating Synthetic unit tests to identify and retain only correctly generated examples, which are then composed into correct question-answer pairs
-
RL with fixed reward values for different execution result types based on unit tests
-
Applications
Improvements brought about by code training in LLMs are firmly rooted in their practical operational steps. These steps include:
- Enhancing the IA’s decision-making in terms of
-
Environment perception:
- The perceived information needs to be organized in a highly structured format, ensuring that stimuli occurring at the same moment (e.g., coexisting multimodality stimuli) influence the IA’s perception and decision.
-
Planning:
- Leveraging the synergized planning abilities of code-LLMs, IAs can generate organized reasoning steps using modular and unambiguous code alongside expressive natural language

- Streamlining execution by
-
Actions grounding :
- IA interfaces with external function ends according to the planning, it must invoke action primitives from a pre-defined set of actions
-
Memory Organization :
- IA typically necessitates an memory organization module to manage exposed information, including original planning, task progress, execution history, available tool set, acquired skills, augmented knowledge, and users’ early feedback
- Optimizing performance through feedback automatically derived from the code execution environment
Challenges
- The Causality between Code Pre-training and LLMs’ Reasoning Enhancement
- Gap persists in providing explicit experimental evidence that directly indicates the enhancement of LLMs’ reasoning abilities through the acquisition of specific code properties
- Acquisition of Reasoning Beyond Code:
- Still lack the human-like reasoning abilities
- Challenges of Applying Code-centric Paradigm:
- Connect to different function ends is learning the correct invocation of numerous functions, including selecting the right function end and passing the correct parameters at an appropriate time