Recent LLM basics
- SlideDeck: W13-RecentLLMbasics
- Version: current
- Lead team: team-1
- Blog team: team-4
In this session, our readings cover:
Require Readings:
Towards Efficient Generative Large Language Model Serving: A Survey from Algorithms to Systems
- https://arxiv.org/abs/2312.15234
- In the rapidly evolving landscape of artificial intelligence (AI), generative large language models (LLMs) stand at the forefront, revolutionizing how we interact with our data. However, the computational intensity and memory consumption of deploying these models present substantial challenges in terms of serving efficiency, particularly in scenarios demanding low latency and high throughput. This survey addresses the imperative need for efficient LLM serving methodologies from a machine learning system (MLSys) research perspective, standing at the crux of advanced AI innovations and practical system optimizations. We provide in-depth analysis, covering a spectrum of solutions, ranging from cutting-edge algorithmic modifications to groundbreaking changes in system designs. The survey aims to provide a comprehensive understanding of the current state and future directions in efficient LLM serving, offering valuable insights for researchers and practitioners in overcoming the barriers of effective LLM deployment, thereby reshaping the future of AI.
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling
- https://arxiv.org/abs/2304.01373
- How do large language models (LLMs) develop and evolve over the course of training? How do these patterns change as models scale? To answer these questions, we introduce \textit{Pythia}, a suite of 16 LLMs all trained on public data seen in the exact same order and ranging in size from 70M to 12B parameters. We provide public access to 154 checkpoints for each one of the 16 models, alongside tools to download and reconstruct their exact training dataloaders for further study. We intend \textit{Pythia} to facilitate research in many areas, and we present several case studies including novel results in memorization, term frequency effects on few-shot performance, and reducing gender bias. We demonstrate that this highly controlled setup can be used to yield novel insights toward LLMs and their training dynamics. Trained models, analysis code, training code, and training data can be found at \url{this https URL}.
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
- https://arxiv.org/abs/2403.09611
- Multimodal LLM Pre-training - provides a comprehensive overview of methods, analysis, and insights into multimodal LLM pre-training; studies different architecture components and finds that carefully mixing image-caption, interleaved image-text, and text-only data is key for state-of-the-art performance; it also proposes a family of multimodal models up to 30B parameters that achieve SOTA in pre-training metrics and include properties such as enhanced in-context learning, multi-image reasoning, enabling few-shot chain-of-thought prompting.
More Readings:
Sparks of Large Audio Models: A Survey and Outlook
- Siddique Latif, Moazzam Shoukat, Fahad Shamshad, Muhammad Usama, Yi Ren, Heriberto Cuayáhuitl, Wenwu Wang, Xulong Zhang, Roberto Togneri, Erik Cambria, Björn W. Schuller
- This survey paper provides a comprehensive overview of the recent advancements and challenges in applying large language models to the field of audio signal processing. Audio processing, with its diverse signal representations and a wide range of sources–from human voices to musical instruments and environmental sounds–poses challenges distinct from those found in traditional Natural Language Processing scenarios. Nevertheless, \textit{Large Audio Models}, epitomized by transformer-based architectures, have shown marked efficacy in this sphere. By leveraging massive amount of data, these models have demonstrated prowess in a variety of audio tasks, spanning from Automatic Speech Recognition and Text-To-Speech to Music Generation, among others. Notably, recently these Foundational Audio Models, like SeamlessM4T, have started showing abilities to act as universal translators, supporting multiple speech tasks for up to 100 languages without any reliance on separate task-specific systems. This paper presents an in-depth analysis of state-of-the-art methodologies regarding \textit{Foundational Large Audio Models}, their performance benchmarks, and their applicability to real-world scenarios. We also highlight current limitations and provide insights into potential future research directions in the realm of \textit{Large Audio Models} with the intent to spark further discussion, thereby fostering innovation in the next generation of audio-processing systems. Furthermore, to cope with the rapid development in this area, we will consistently update the relevant repository with relevant recent articles and their open-source implementations at this https URL.
Blog:
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling
This research work aims to address the following questions.
- How do large language models (LLMs) develop and evolve over the course of training?
- How do these patterns change as models scale?
Contribution
The research aims to explore the development and evolution of large language models (LLMs) over the course of training, with a specific focus on understanding how these patterns change as the models scale. To achieve this, the study introduces Pythia, a suite consisting of 16 LLMs. These models are trained on public data in the exact same order but vary in size, ranging from 70M to 12B parameters. This diverse set of models allows for a comprehensive investigation into the impact of model size on the developmental trajectory of LLMs.
Additionally, the research contributes by providing public access to 154 checkpoints for each of the 16 models. These checkpoints serve as snapshots of the models at different stages of training, enabling researchers to examine their progression over time. Moreover, the study offers tools to download and reconstruct the exact training dataloaders used for training the models. This provision facilitates further study and analysis of the training data, offering insights into the learning process of LLMs.
Overall, the research provides valuable resources and insights for the scientific community interested in understanding the development and behavior of large language models, shedding light on how these models evolve as they scale in size.
Models in the Pythia suite
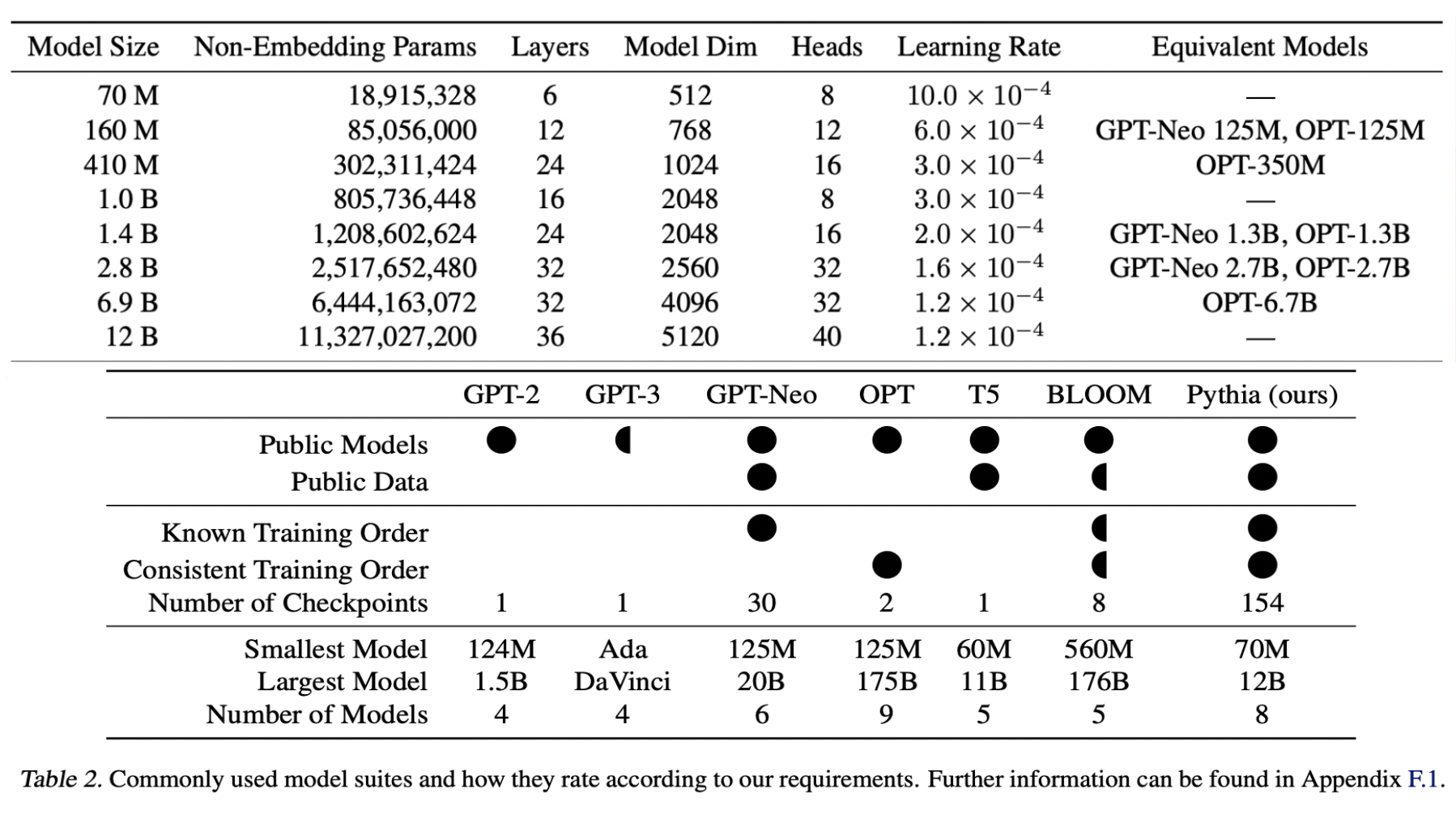
Training data in Pythia
The Pile is a curated collection of English language datasets designed specifically for training large language models. It offers several benefits:
-
Freely and publicly available: The Pile dataset is accessible to anyone without any cost, making it widely accessible for researchers, developers, and enthusiasts.
-
Higher downstream performance: Compared to other popular crawl-based datasets like C4 and OSCAR, The Pile has demonstrated superior downstream performance. This means that language models trained on The Pile tend to perform better on various downstream natural language processing tasks.
-
Wide adoption: The Pile has been widely adopted by state-of-the-art language models, including GPT-J-6B, GPT-NeoX-20B, Jurassic-1, Megatron-Turing NLG 530B, OPT, and WuDao. This indicates its credibility and usefulness in training advanced language models.
The publication “The Pile: An 800GB dataset of diverse text for language modeling” by Gao et al. in 2020 provides further details about the dataset and its characteristics.
The authors trained two copies of the Pythia suite using identical architectures:
- One using the original Pile dataset consisting of 334 billion tokens.
- The other using a modified version of the Pile dataset, which underwent near-deduplication using MinHashLSH with a threshold of 0.87, resulting in a reduced dataset of 207 billion tokens.
This near-deduplication process was carried out based on the advice from Lee et al. (2021), suggesting that language models trained on deduplicated data exhibit improved performance and memorize less of their training data.
Model Architecture in Pythia
-
Fully dense attention layers: In the transformer architecture, attention mechanisms are crucial for capturing long-range dependencies in the input sequences. Fully dense attention layers imply that every token attends to every other token in the sequence, enabling the model to capture complex patterns and relationships.
-
Flash Attention: Flash Attention is a technique used during training to improve device throughput. It likely involves optimizations or modifications to the attention mechanism to make it more computationally efficient, thereby speeding up the training process.
-
Rotary embeddings: Positional embeddings are used in transformer models to provide information about the position of tokens in the input sequence. Rotary embeddings are a type of positional embedding that may offer advantages in certain scenarios, potentially improving the model’s ability to understand sequential data.
-
Parallelized attention, feedforward techniques, and model initialization methods from GPT-J: These are techniques and methodologies introduced by the GPT-J model, which is known for its efficiency and effectiveness in large-scale language modeling tasks. Utilizing these techniques can help improve the performance and training efficiency of the model.
-
Untied embedding/unembedding matrices: Embedding matrices are used to represent tokens in a continuous vector space. Untying the embedding and unembedding matrices means that the model treats each embedding dimension independently, which can aid in interpretability research. This technique allows researchers to better understand how specific dimensions of the embedding space contribute to the model’s predictions.
Model Training in Pythia
-
Training code: The training code is implemented using the open-source library GPTNeoX. This library likely provides tools and utilities specifically designed for training large language models like GPT-3.
-
Optimizer: The optimizer used for training is Adam, a popular optimization algorithm commonly used in deep learning. Additionally, the Zero Redundancy Optimizer (ZeRO) is employed, which is an optimization technique aimed at reducing memory consumption and improving training efficiency, particularly for large-scale models.
-
Batch size: The batch size used during training is 1024 samples, with a sequence length of 2048 tokens per sample. This results in a total of 2,097,152 tokens per batch.
-
Epoch: All models are trained for approximately 300 billion tokens, corresponding to a duration of training known as an “epoch.” This large number of tokens indicates extensive training to ensure the model learns from a vast amount of data.
-
GPU configuration: The training is conducted on GPUs (Graphics Processing Units), specifically A100s, each with 40 GiB (gibibytes) of VRAM (Video Random Access Memory). These GPUs are known for their high performance and are well-suited for training large deep learning models like GPT-3.
Overall, this training setup is optimized for efficiency and scalability, allowing for the effective training of large language models on powerful GPU hardware.
Evaluation of Pythia
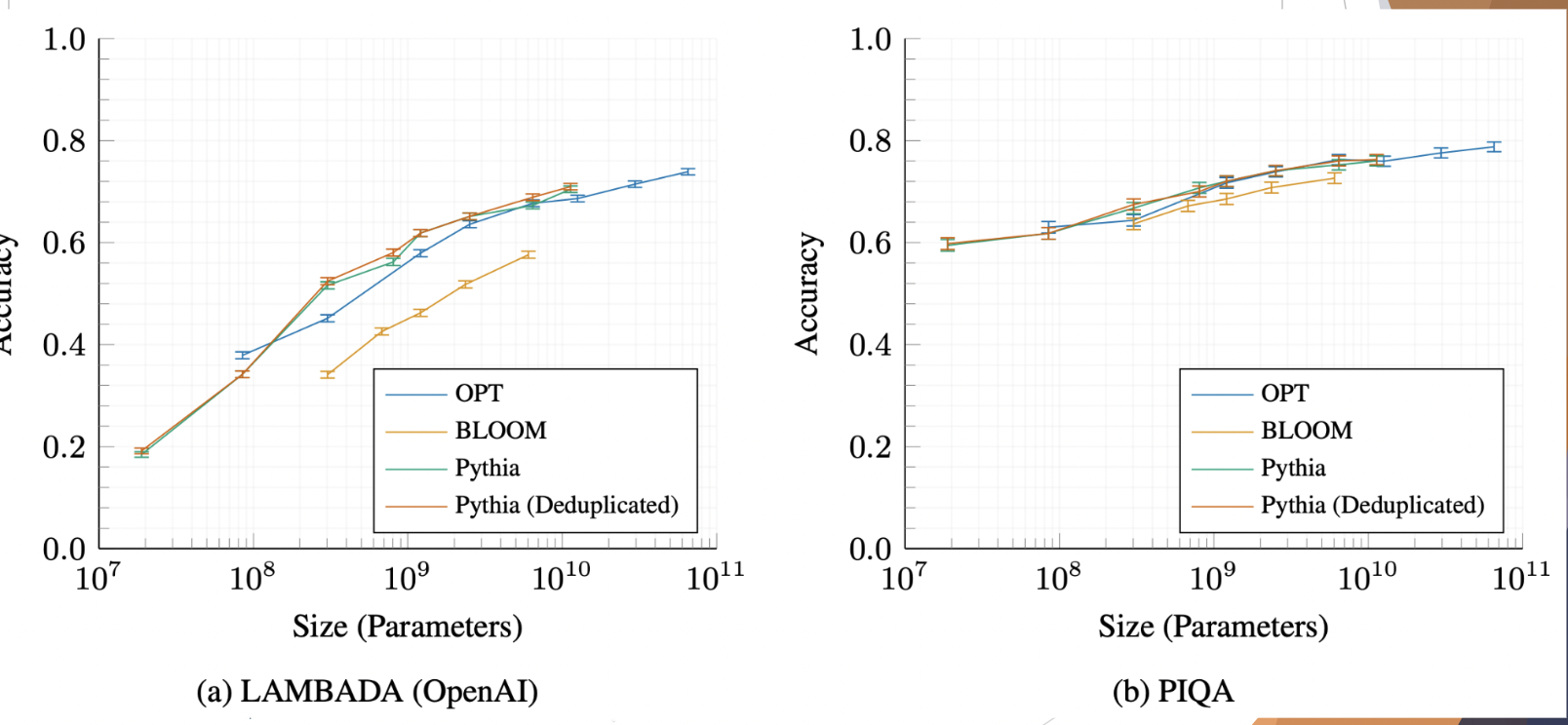
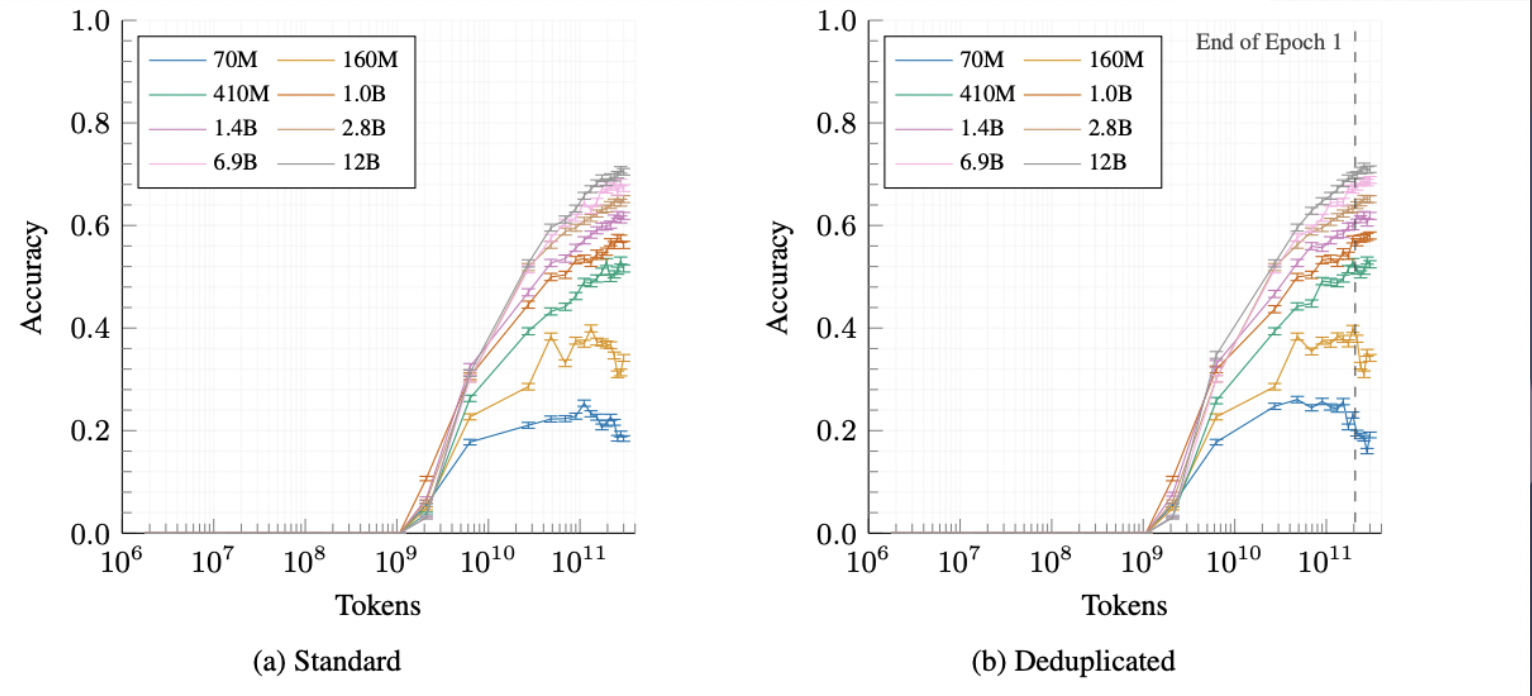
Case Study: How Does Data Bias Influence Learned Behaviors?
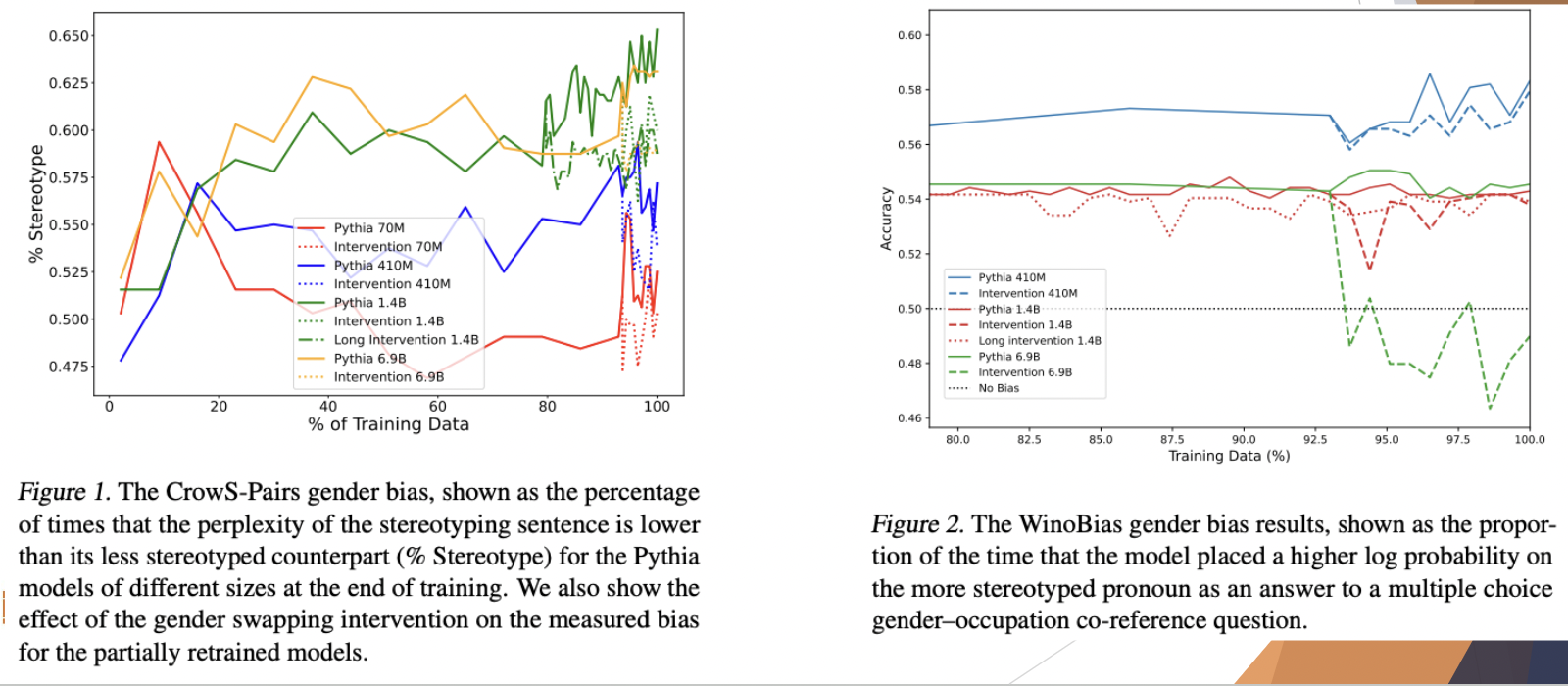
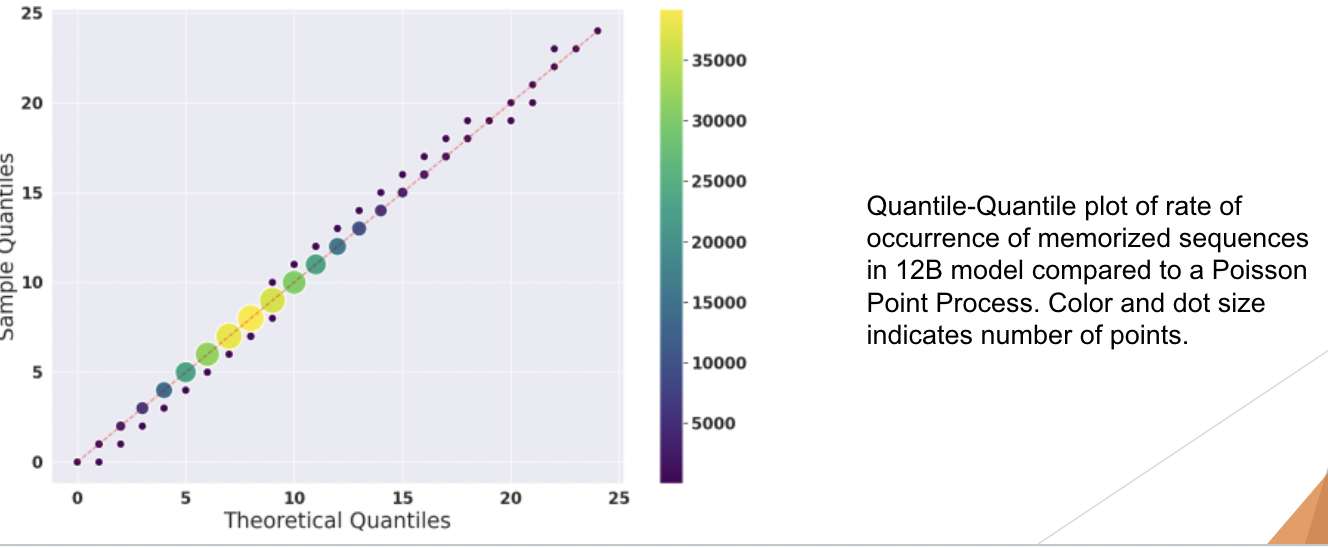
Case Study: Does Training Order Influence Memorization?
The hypothesis posits that data encountered later in the training process will be memorized more by the model. To test this hypothesis, the researchers designed a method where they measured the memorization of an initial segment of each sequence in the training corpus. However, the results of their experiment contradicted the hypothesis. They found that the order in which data was encountered during training had little impact on the memorization patterns observed in the model. This unexpected result suggests that factors other than the chronological order of data presentation may play a more significant role in determining memorization behavior in large language models. Further research may be needed to explore these factors and their implications for model training and performance.
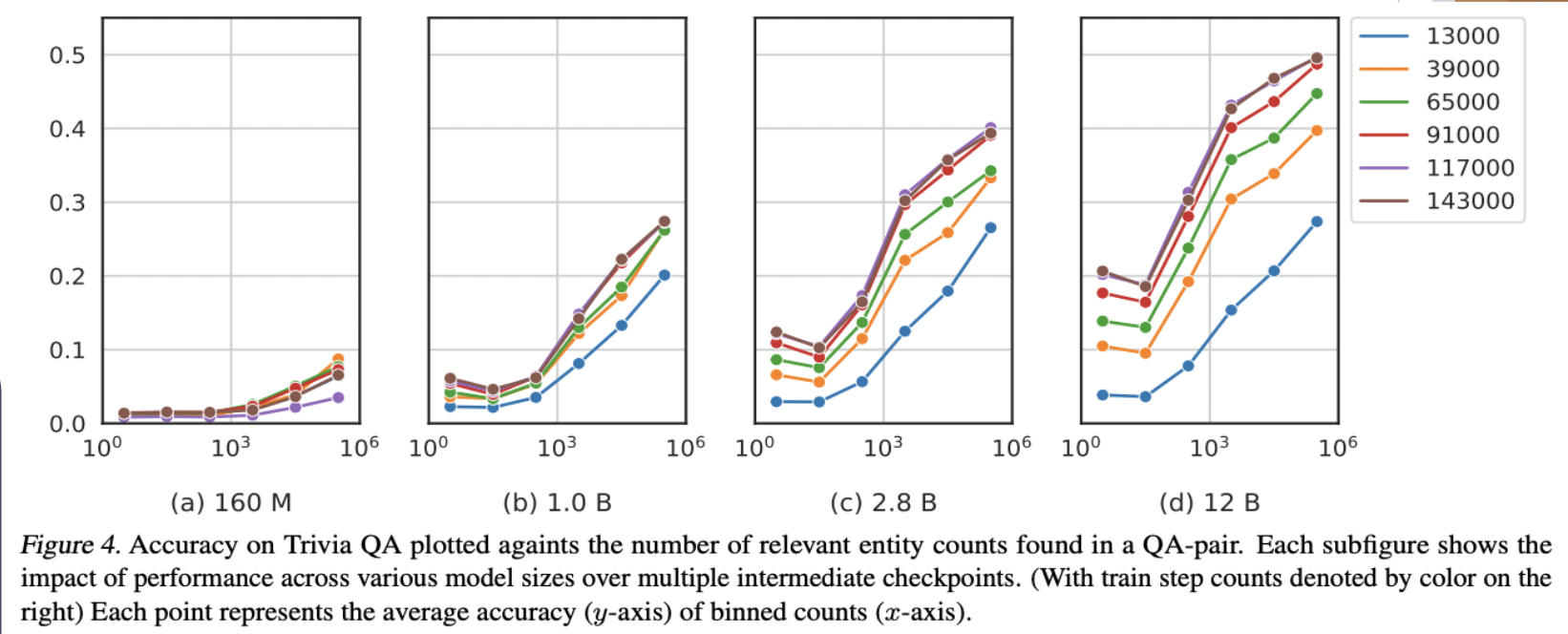
Case Study: Do Pretraining Term Frequencies Influence Task Performance Throughout Training?
The correlation between average performance and term frequencies varies depending on the size of the model. Interestingly, this correlation becomes more pronounced in larger models, suggesting that it is an emergent property that becomes more prominent as the model size increases. This finding underscores the importance of considering model size when analyzing the relationship between model performance and the frequency of terms in the data. It implies that larger models may exhibit different behavior in this regard compared to smaller models, highlighting the need for careful consideration of model architecture and scale in natural language processing tasks.
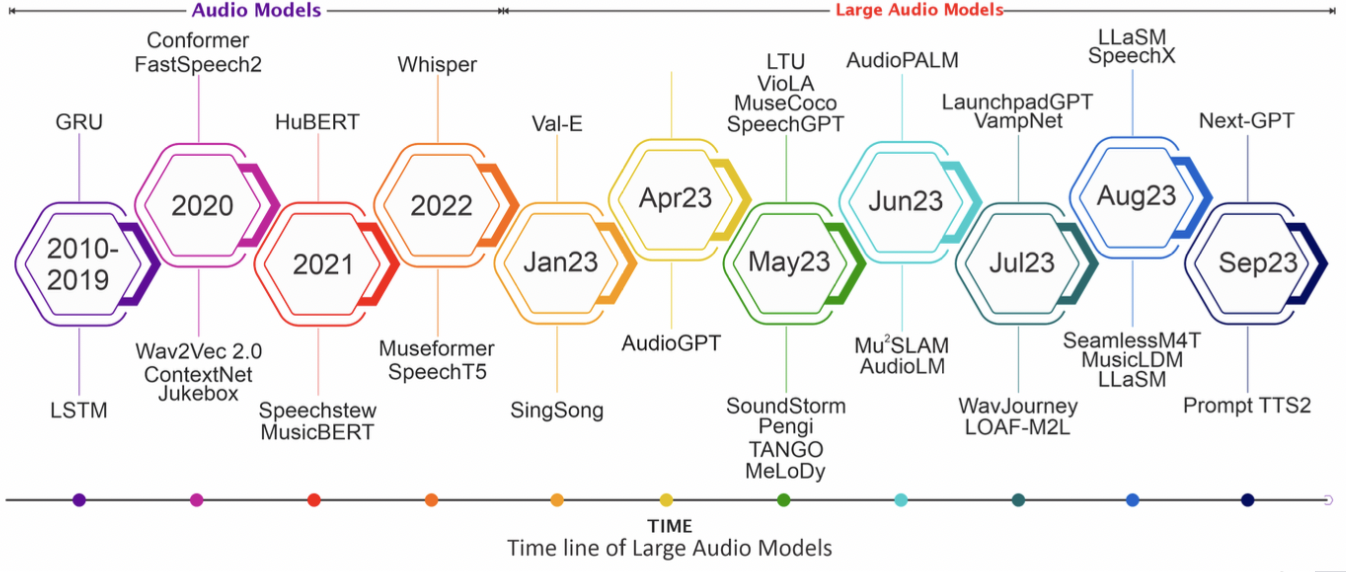
Sparks of Large Audio Models: A Survey and Outlook
Motivation
-
Exploring large audio models is crucial due to the significance of audio processing across various real-world applications. Audio plays a pivotal role in technologies such as voice-activated assistants, transcription services, and hearing aids, among others. These applications rely on advanced audio processing techniques to accurately recognize and interpret spoken language, making large audio models indispensable for achieving high performance and accuracy.
-
For instance, voice-activated assistants like Siri, Alexa, and Google Assistant use sophisticated audio models to understand and respond to user commands and queries. Similarly, transcription services leverage audio models to convert spoken language into text with high accuracy, facilitating tasks such as closed captioning, subtitling, and transcription of audio recordings.
-
Hearing aids equipped with advanced audio processing capabilities can enhance the auditory experience for individuals with hearing impairments by amplifying sounds, reducing background noise, and improving speech clarity. These devices rely on powerful audio models to process and enhance audio signals in real-time, enabling users to better communicate and engage with their surroundings.
Foundational Audio Models
This model aggregates information from diverse data modalities, allowing it to capture a wide range of audio features and patterns. Once trained, it can be customized or fine-tuned to address various downstream audio tasks, such as speech recognition, speaker identification, emotion detection, and sound classification. By leveraging its ability to learn from multiple data sources and modalities, the model can adapt to different contexts and applications, making it versatile and adaptable for a variety of audio processing tasks.
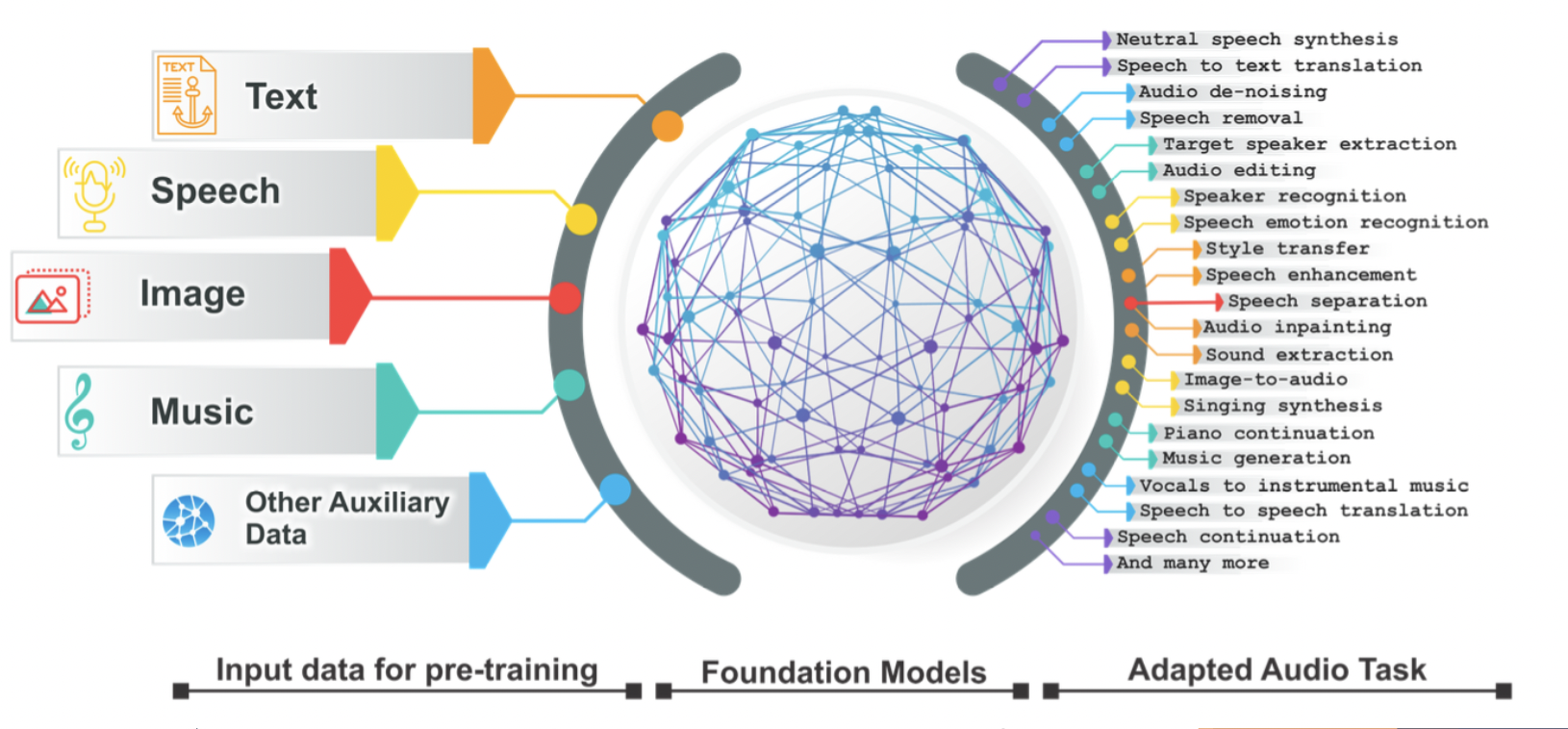
Large Audio Models
Application
Speech processing:
- Automatic Speech Recognition (ASR): Involves converting spoken language into text, which is crucial for various applications such as voice-controlled devices, transcription services, and virtual assistants like Siri and Alexa.
- Text-To-Speech (TTS): Refers to the process of generating human-like speech from written text, commonly used in applications like audiobooks, navigation systems, and accessibility tools for visually impaired individuals.
- Speech Translation (ST): Enables the real-time translation of spoken language from one language to another, facilitating communication across language barriers in scenarios such as international conferences and multilingual customer support.
- Spoken Dialogue Systems (SDSs): Interactive systems that allow users to engage in natural language conversations, often implemented in chatbots, virtual agents, and customer service interfaces.
Challenges:
- Handling variations in accents: Speech recognition systems need to be robust enough to accurately understand and transcribe speech from different regions and cultures, accounting for variations in pronunciation, intonation, and dialects.
- Dealing with background noise: Ensuring that speech recognition systems can filter out unwanted sounds from the environment, such as traffic noise or background chatter, to maintain accuracy and reliability.
- Ensuring accurate transcription and synthesis of speech: Overcoming challenges related to accurately transcribing speech with diverse vocabulary, accents, and speaking styles, as well as generating natural-sounding speech output that mimics human speech patterns and intonation.
Music signal processing:
- Music generation: Involves using computational algorithms to create new musical compositions or audio sequences autonomously, which can be utilized in music production, film scoring, and game development.
- Analyzing musical patterns: Refers to the extraction of meaningful insights and features from audio data to understand musical structures, genres, and trends, aiding in tasks such as music recommendation systems and genre classification.
- Enhancing music composition: Utilizes computational techniques to assist composers and musicians in composing, arranging, and editing music, offering tools for generating melodies, harmonies, and rhythms.
Challenges:
- Modeling complex musical structures: Developing algorithms capable of understanding and replicating the intricate patterns and relationships found in music, including harmony, melody, rhythm, and instrumentation.
- Capturing emotional and creative aspects of music: Incorporating elements of human expression, emotion, and creativity into algorithmic music generation to produce compositions that resonate with listeners on an emotional level.
- Ensuring coherence and sophistication in generated music: Creating algorithmic music that exhibits coherence, structure, and aesthetic appeal, similar to compositions by human musicians, while also allowing for flexibility and creativity in the generated output.
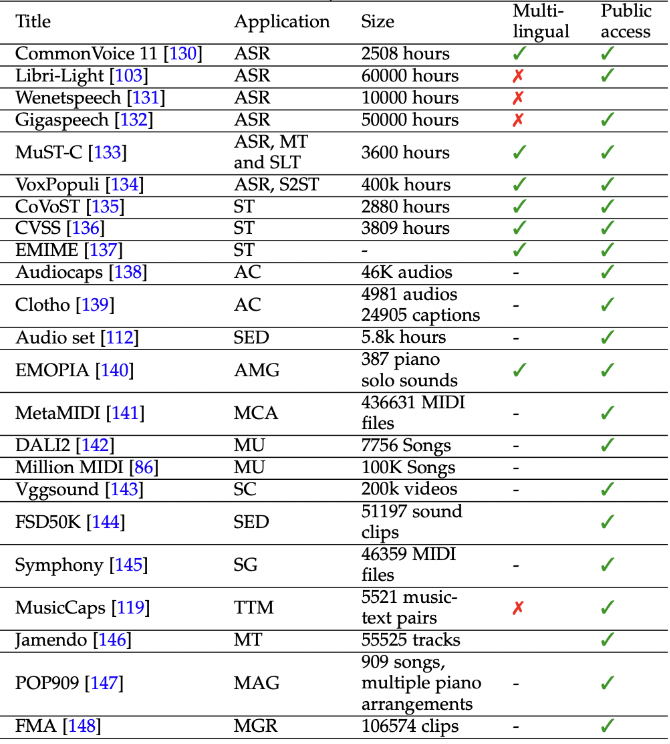
Audio tasks
- ASR: automatic speech recognition
- ST: speech translation
- MT: machine translation
- AC: audio classification
- SED: sound event detection
- AMG: affective music generation
- MAG: music analysis and generation
- MU: music understanding
- SC: sound classification
- SG: symphony generation
- TTM: text to music
- MT: music tagging
- MAG: Music Arrangement Generation
- MGR: Music Genre Recognition
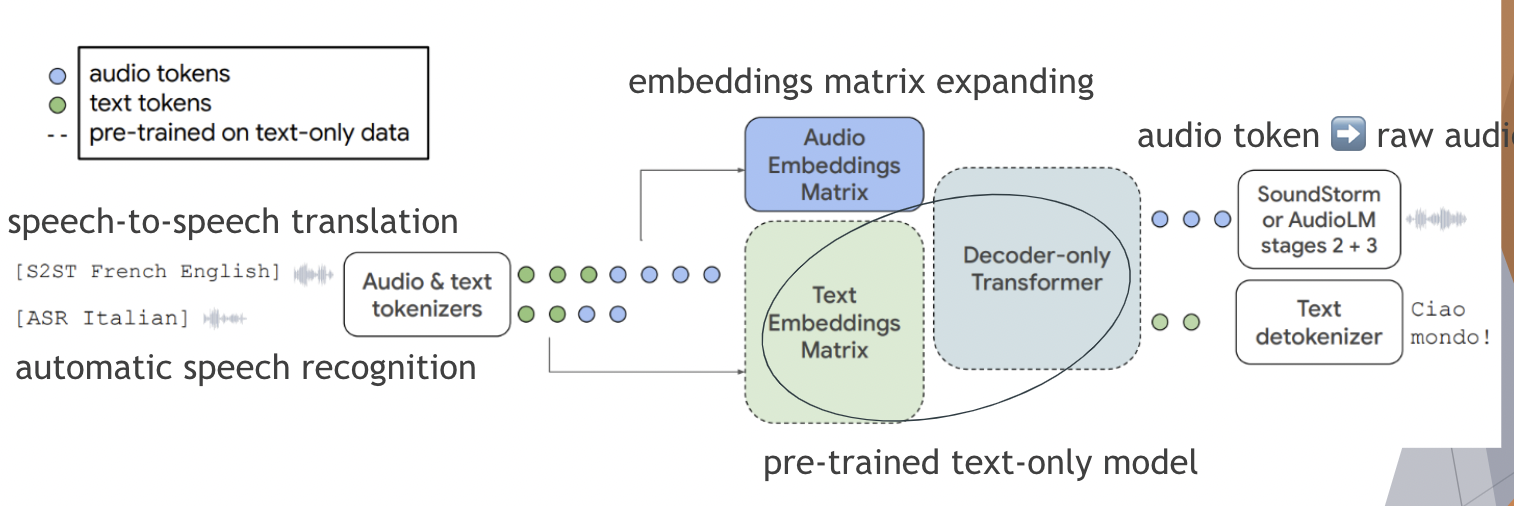
Speech Processing – AudioPalm
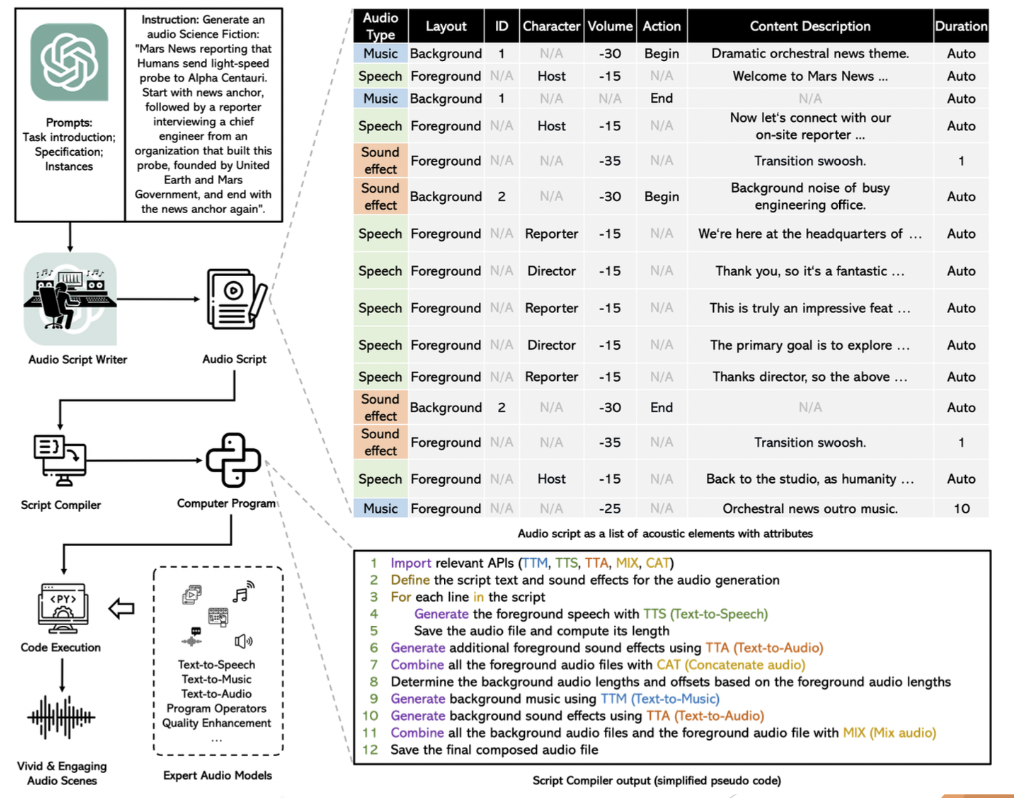
Music Signal Processing – WavJourney
Challenges
Data Issues (pre-training period):
- Duplicated data instances: Repetitive data instances in the pre-training dataset can lead to model memorization, reducing the effectiveness of the model and causing performance degradation over time.
- Data contamination: The presence of unwanted elements such as background noise, audio distortion, or offensive content in the training data can adversely affect the performance of large audio models (LAMs) during pre-training.
- Concerns of personally identifiable information: Privacy concerns arise when pre-training data contains personally identifiable information (PII), necessitating measures to ensure data anonymization or careful handling of sensitive information.
- Need for diverse pre-training data: To improve model generalization and robustness, it’s essential to include a diverse range of audio samples representing different accents, languages, dialects, and speaking styles in the pre-training dataset.
Tokenization:
- Variations in pronunciations and overlapping speech: Tokenization methods must account for variations in pronunciations and instances of overlapping speech, ensuring accurate segmentation of audio data into meaningful units for processing.
- Multilingual speech: Tokenization techniques need to accommodate multilingual speech data by effectively handling code-switching, language mixing, and transliteration across different languages.
- Emotion tokenization and information loss: Capturing emotional cues and nuances in speech during tokenization is crucial to prevent information loss and preserve the expressive qualities of audio data.
Computational Cost and Energy Requirements:
- Pre-training: Large-scale pre-training of audio models requires significant computational resources and energy consumption due to the intensive processing involved in training deep neural networks on vast amounts of audio data.
- Fine-tuning: Fine-tuning LAMs for specific tasks may also incur substantial computational costs and energy requirements, particularly when optimizing model parameters and conducting iterative training cycles to achieve desired performance levels.
Limited context length:
- Difficulty in understanding long-term dependencies and relationships: LAMs may struggle to capture and comprehend complex long-term dependencies and relationships in audio data due to constraints on context length, limiting their ability to contextualize information effectively.
- Understanding paralinguistic information: Paralinguistic cues such as emotions, prosody, and other non-verbal elements play a crucial role in speech and music comprehension but may be challenging for LAMs to interpret accurately within limited context windows.
Prompt Sensitivity:
- Vulnerable to prompt variations: LAMs are sensitive to variations in input prompts, which can significantly influence model behavior and output. Inconsistent or ambiguous prompts may lead to unpredictable model responses or misinterpretations of user intent.
Hallucination:
- Misinterpretations of audio sources: LAMs may generate erroneous or misleading content, known as hallucinations, by incorrectly inferring information or introducing random noise into audio outputs. This phenomenon can occur due to inherent biases in the training data or limitations in model architecture.
- Introduction of random noise: In some cases, LAMs may introduce unintended noise or artifacts into generated audio samples, resulting in distortions or inaccuracies in the synthesized output.
Ethics:
- Bias: LAMs trained on biased or unrepresentative datasets may perpetuate or amplify existing biases in society, leading to unfair or discriminatory outcomes in audio processing tasks. Addressing bias in LAMs requires careful consideration of dataset composition, model design, and evaluation metrics.
- Privacy concerns: The collection and use of audio data raise significant privacy concerns, particularly regarding the potential identification of individuals or sensitive personal information contained within audio recordings. Ethical guidelines and data protection measures are essential to safeguard user privacy and prevent unauthorized access or misuse of audio data.
- Misuse: LAMs have the potential to be misused for malicious purposes, such as generating deepfake audio content or impersonating individuals’ voices without consent. Responsible AI practices and regulatory frameworks are necessary to mitigate the risks of misuse and ensure ethical use of LAM technology.
Towards Efficient Generative Large Language Model Serving: A Survey from Algorithms to Systems
Overview
- Recent advancements in LLM serving and inference.
- Systematic review and categorization of existing techniques.
- Highlight strengths and limitations of each method.
Background of LLM Serving
- Transformer-based LLM
- GPU and Other Accelerators
- LLM Inference
Challenges
- Latency & Response Time
- Memory Footprint & Model Size
- Scalability & Throughput
- Hardware Compatibility & Acceleration
- Accuracy vs. Efficiency
Taxonomy of LLM inference Advancements
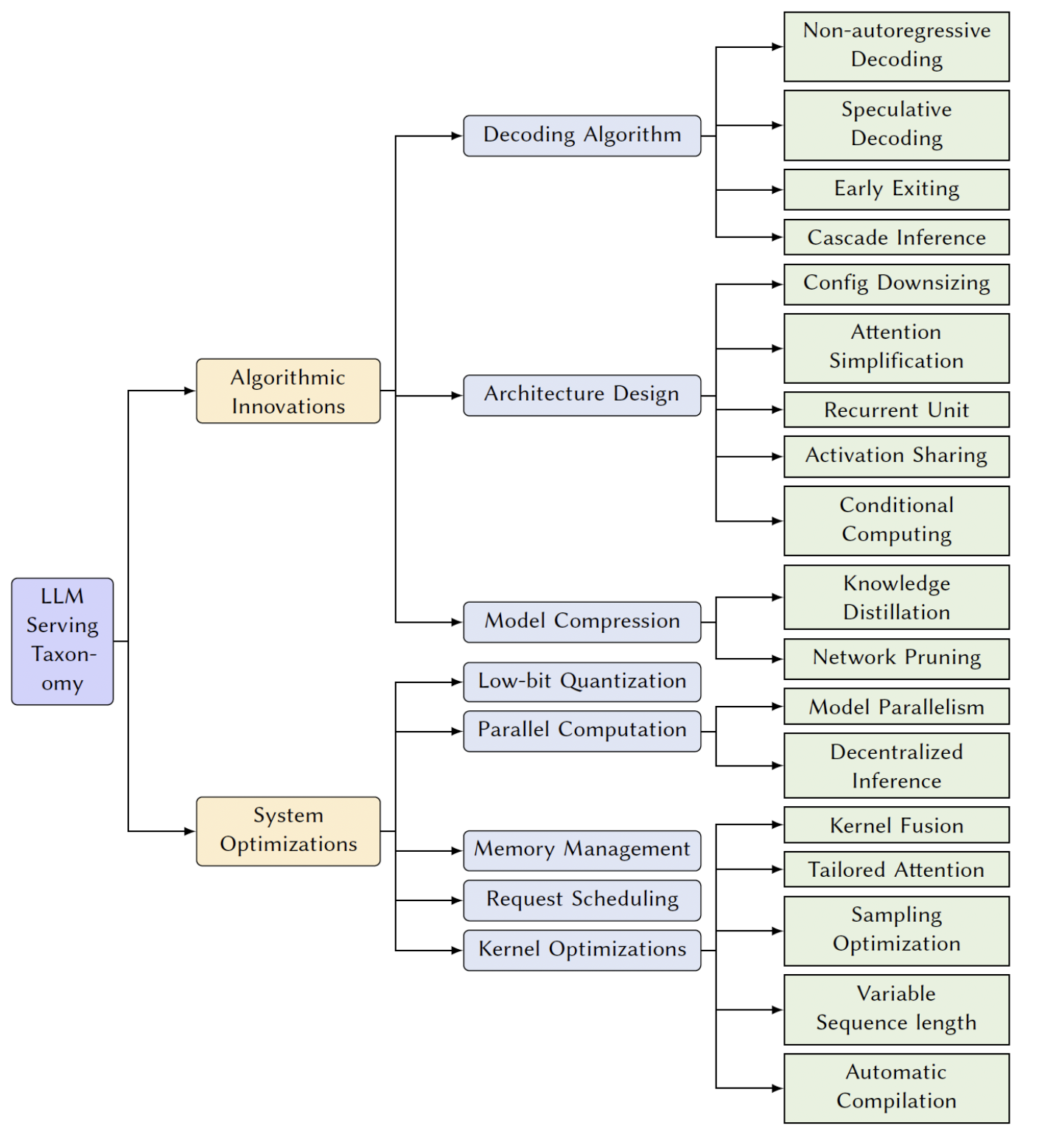
Decoding Algorithm
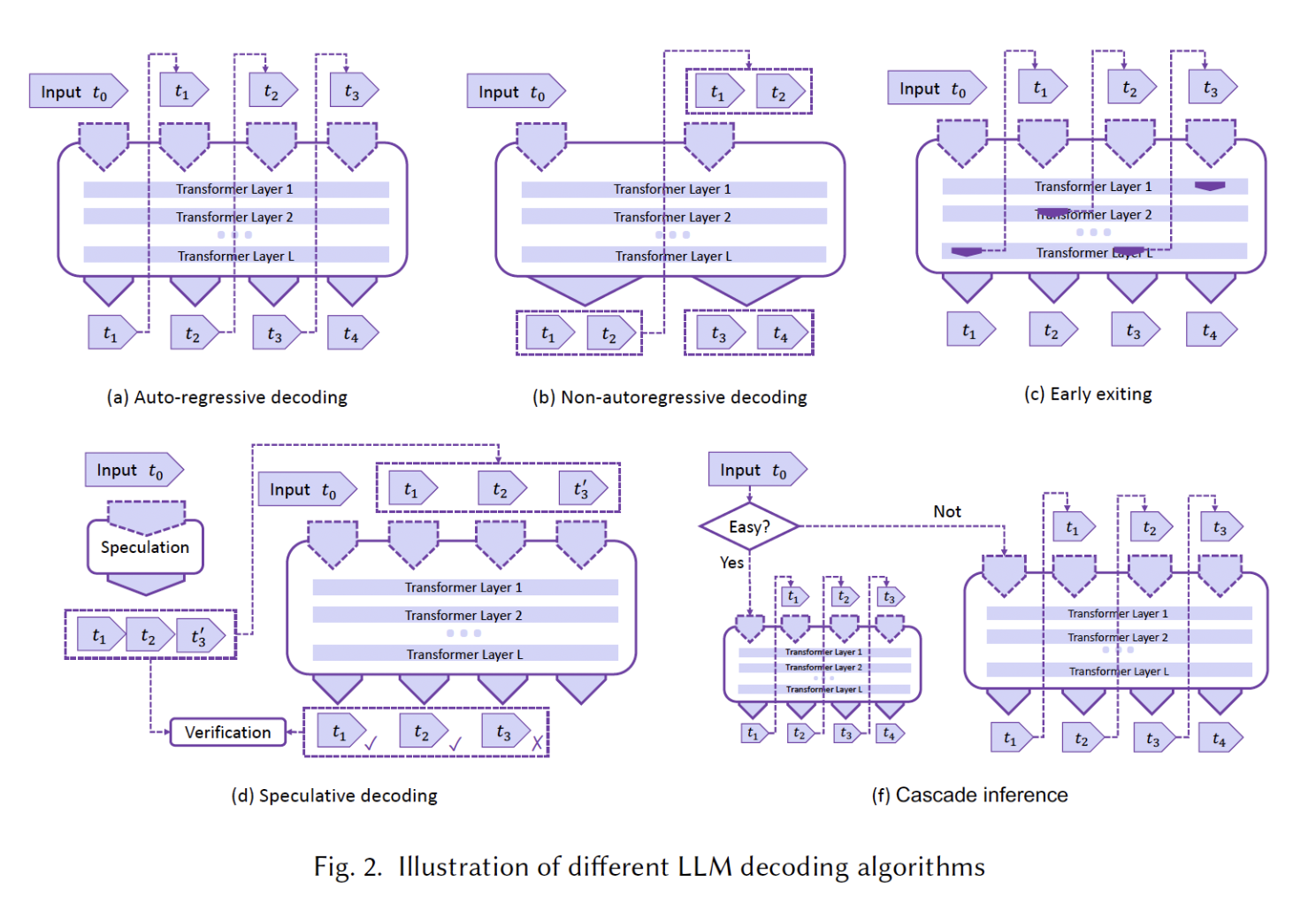
- Auto-regressive Decoding
- Sequentially predicting the next token in a sequence, given all the previous ones
- Decode output tokens in parallel (Not as reliable as auto-regressive models)
- Breaking or modelling word dependencies
- Early Exiting
- Utilize multi-layer architecture of existing LLMs
- Adaptive Computation: Emit predictions based on internal classifiers instead of running the whole LLM
- Insufficient Information: May not faithfully make accurate predictions
- Speculative Decoding
- Uses smaller draft model
- Allows parallel decoding
- Verification and Fallback mechanism
- Cascade Inference
- Internal classifiers organizes queries in a cascade manner
- Adaptively select proper model based on the difficulty level
Architecture Design

Model Compression
- Knowledge Distillation
- Network Pruning
System Optimization
- Low-bit Quantization
- Quantize-Aware Training (QAT)
- Post-Training Quantization (PTQ)
- Parallel Computation
- Model Parallelism
- Decentralized Inference
- Memory Management
- Request Scheduling
- Kernel Optimization
Future Direction
- Developing and Enhancing Hardware Accelerators
- Designing Efficient and Effective Decoding Algorithms
- Optimizing Long Context/Sequence Scenarios
- Investigating Alternative Architectures
- Exploration of Deployment in Complex Environments
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
Section based on the paper of the same name
Motivations
There are has great development in multi-modal large language models (MLLMs) in the past few years.
- Flamingo
- GPT-4V
- Gemini
- LLaVA

What are the best design choices when developing a MLLM?
- Best architecture design?
- Best training procedure?
- Best data to use?
Contributions
To answer these questions the authors conducts a fine-grained ablation across:
- Model architecture
- Type of data
- Training procedure
Based on their findings, they also create their family of MM1 models, which exhibit SOTA performance on captioning and visual question answering (VQA).

Ablation Setup
- Base configuration
- Ablate on component (either model architecture or data source) at a time.
- Evaluate design decision in both a zero-shot and few-shot setting on various image captioning and VQA tasks.
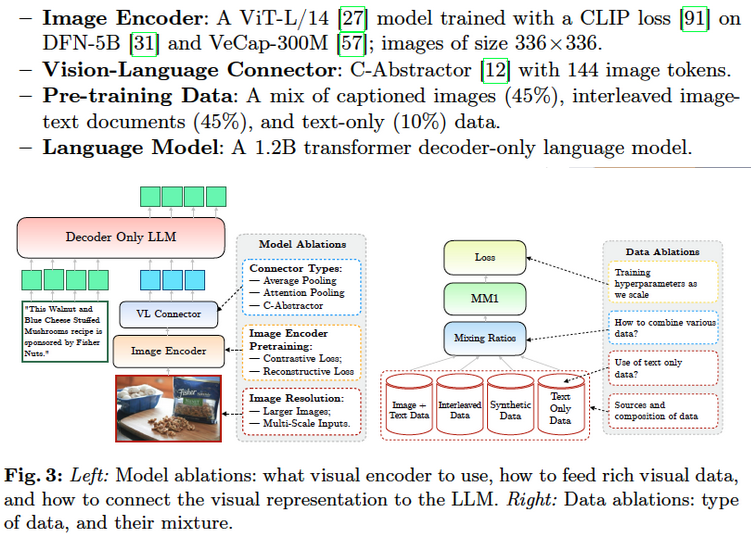
Ablation Motivations:
- How to best pre-train a visual encoder?
- How to bridge visual features to the LLM space?
Ablation Testing and Results
- Image-enoder projects images with their captions into a visual space.
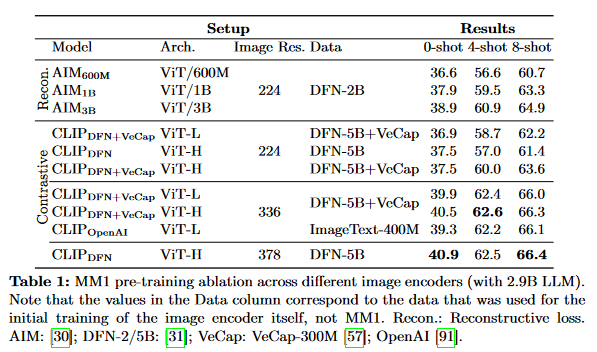
- Let’s look at the effect that contrastive loss, reconstructive loss, and image resolution has:
- Image resolutions has the biggest impact…
- Higher resolution -> better
- then model size….
- Larger model -> better
- and finally training data composition.
- Adding a synthetic caption dataset
- (VeCap-300M) helped increase performance
- Image resolutions has the biggest impact…
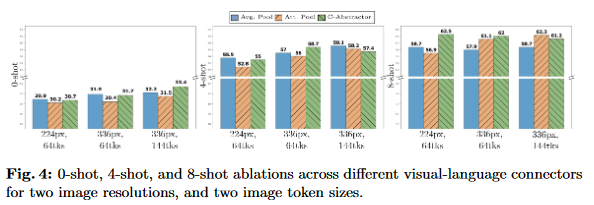
Model Architecture Ablations: Vision-Language Connector
- The vision-language connector projects the visual representation into the same space as the LLM.
- Let’s see the effect of the number of visual tokens, the image resolution, average pooling, attention pooling, and convolutional mapping has:
- Authors found that:
- The number of visual tokens and image resolution matter most! (More the better)
- The type of VL connector has little effect.
Model Architecture Ablations: Pre-training Data
- Let’s see the effect captioned images, interleaved images and text, and only text has on pre-training.
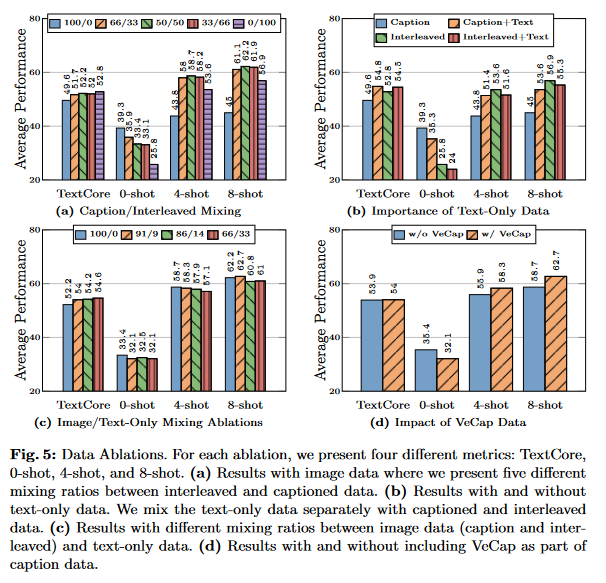
As seen in 5.a (above):
- Interleaved data is vital for few-shot and text-only performance
- Caption data improves zero-shot performance
As seen in 5.b (above):
- Text-only data only improves few-shot and text-only performance. As seen in 5.c (above):
- Thoughtfully mixing text and image data can lead to optimal multi-modal performance while maintaining text performance. As seen in 5.d (above): Synthetic data helps with few-shot learning
The MM1 Model
Building the Model
Image-encoder:
- ViT-H model with 378x378 resolution, pre-trained with CLIP objective on DFN-5B dataset
- (motivated by importance of high image resolution) Vision-language connector:
- C-abstractor with 144 tokens.
- (Motivated by importance of many image tokens). Data:
- 45% interleaved image-text documents
- 45% image-text pair documents
- 10% text-only documents
- (Motivated to maintain a balance between zero-shot and few-shot performance)
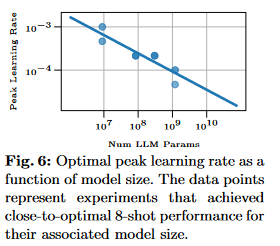
Model Scaling
Initial Grid Search at Smaller Scales:
- Conducted a grid search for optimal learning rates at smaller model sizes (9M, 85M, 302M, 1.2B parameters) to gather data efficiently without excessive computational costs.
Utilized linear regression in log space based on smaller models to predict optimal learning rates for larger scales, resulting in the formula:
- η = exp(−0.4214 ln(N ) − 0.5535)
Replaced traditional validation loss metrics with direct 8-shot task performance to optimize learning rates, focusing on real-world applicability.
Simple Scaling Rule for Weight Decay:
- Adopted a simple rule to scale weight decay proportionally to the learning rate, setting λ=0.1η, ensuring consistency across different model sizes.
Introducing MoE to the scaling
- Mixture-of-Experts (MoE) scales up the total number of model parameters while maintaining constant activated parameters per instance, enhancing model capacity without significantly impacting inference speed.
- Two specific models were designed:
- a 3B-MoE with 64 experts and a
- 7B-MoE with 32 experts
- To convert a dense model to MoE, only the dense language decoder is replaced with an MoE decoder, while other components like the image encoder remain unchanged.
- MoE models use the same training hyperparameters and conditions as the dense models, ensuring consistency in the training process.
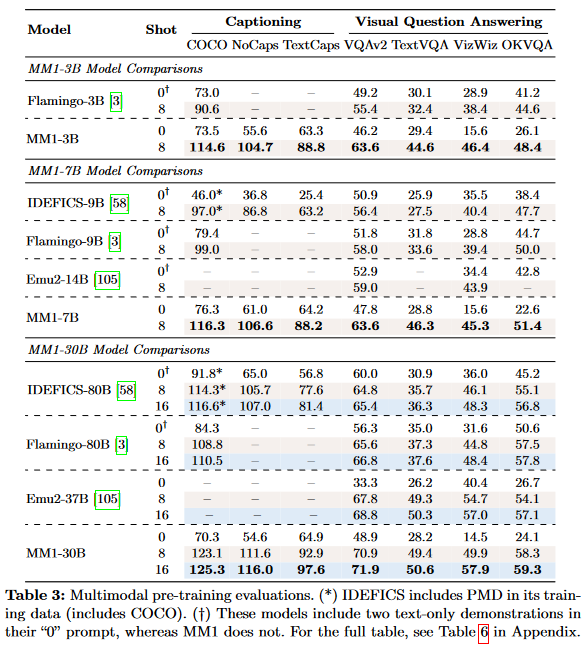
Pre-Training Results
- The family of MM1 models beat baselines in both Caption and VQA.
- Notably, MM1-30B can beat Flamingo 80B
Supervised Fine-Tuning (SFT)
Supervised Fine-Tuning Data Mixture:
- Utilizes approximately 1.45M SFT examples from a diverse set of datasets.
- Data includes instruction-response pairs generated by GPT-4, vision-language (VL) datasets for natural and text-rich images, and document/chart understanding.
- Includes a text-only dataset for text instruction-following capabilities.
- Datasets are formatted for instruction-following and mixed for random sampling during training.
SFT Configuration and Evaluation:
- Both the image encoder and the language model backbone are kept active (unfrozen) during SFT.
Models are evaluated across 12 MLLM benchmarks
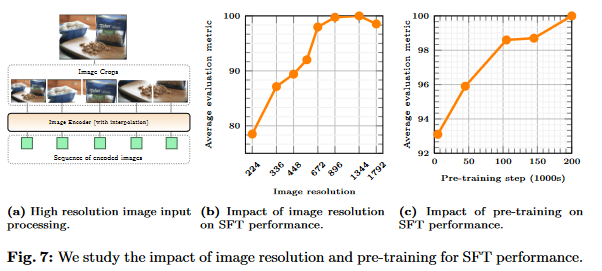
Scaling to Higher Image Resolutions:
- Positional embedding interpolation is used to adapt the vision transformer backbone for higher resolutions (448x448 to 672x672 pixels).
- Supports image resolutions up to 672x672, with a representation of 2,304 image tokens due to a patch size of 14x14.
Sub-image Decomposition for Even Higher Resolutions:
- For ultra-high resolutions (e.g., 1344x1344), the image is first downscaled to 672x672 for a high-level representation.
- The same high-resolution image is also divided into four 672x672 sub-images to capture detailed visual information.
- Positional embedding interpolation is applied to each sub-image, enabling support for resolutions as high as 1792x1792 in experiments.
SFT Results
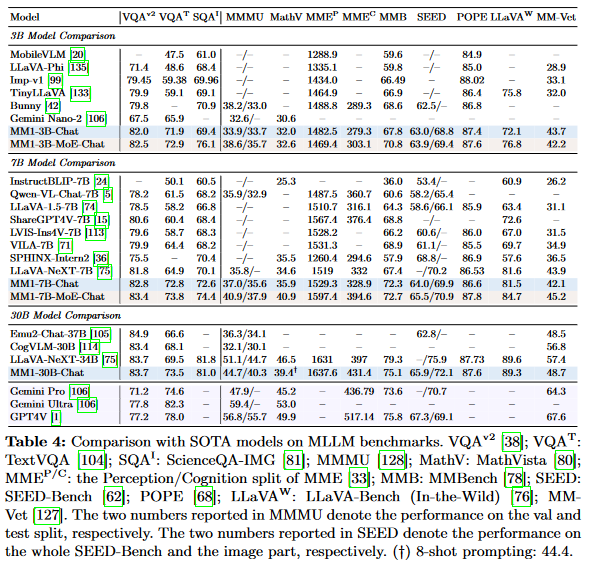
- Competitive results with current SOTA
- MoE models tend to work better
- Higher image resolution and pre-training steps has a positive impact on SFT performance.
- Lessons for pre-training do transfer to SFT
- Pre-training with caption-only data improves SFT metrics, and
- Different VL connector architectures have negligible impact on final results.
Conclusion
- For MLLMs, authors explore the most optimal combination of:
- Model architecture
- Type of data
- Training procedure
- They also create their family of MM1 models, based on the optimal combination they found. The MM1 models exhibit SOTA performance on captioning and visual question answering (VQA).
- Authors also find their optimal configuration also applies when models face SFT.