LLM fine tuning
- SlideDeck: W14-LLM-FineTuning
- Version: current
- Lead team: team-1
- Blog team: team-5
In this session, our readings cover:
Required Readings:
Recent Large Language Models Reshaping the Open-Source Arena
- https://deci.ai/blog/list-of-large-language-models-in-open-source/
- The release of Meta’s Llama model and the subsequent release of Llama 2 in 2023 kickstarted an explosion of open-source language models, with better and more innovative models being released on what seems like a daily basis. With new open-source models being released on a daily basis, here we dove into the ocean of open-source possibilities to curate a select list of the most intriguing and influential models making waves in recent months, inlcuding Qwen1.5/ Yi/ Smaug/ Mixtral-8x7B-v0.1/ DBRX/ SOLAR-10.7B-v1.0 / Tulu 2 / WizardLM/ Starling 7B/ OLMo-7B/ Gemma and DeciLM-7B.
- Plus the newly avaiable DBRX model https://www.databricks.com/blog/introducing-dbrx-new-state-art-open-llm
Instruction Tuning for Large Language Models: A Survey
- https://arxiv.org/abs/2308.10792
- Shengyu Zhang, Linfeng Dong, Xiaoya Li, Sen Zhang, Xiaofei Sun, Shuhe Wang, Jiwei Li, Runyi Hu, Tianwei Zhang, Fei Wu, Guoyin Wang
- This paper surveys research works in the quickly advancing field of instruction tuning (IT), a crucial technique to enhance the capabilities and controllability of large language models (LLMs). Instruction tuning refers to the process of further training LLMs on a dataset consisting of \textsc{(instruction, output)} pairs in a supervised fashion, which bridges the gap between the next-word prediction objective of LLMs and the users’ objective of having LLMs adhere to human instructions. In this work, we make a systematic review of the literature, including the general methodology of IT, the construction of IT datasets, the training of IT models, and applications to different modalities, domains and applications, along with an analysis on aspects that influence the outcome of IT (e.g., generation of instruction outputs, size of the instruction dataset, etc). We also review the potential pitfalls of IT along with criticism against it, along with efforts pointing out current deficiencies of existing strategies and suggest some avenues for fruitful research. Project page: this http URL
Delta tuning: A comprehensive study of parameter efficient methods for pre-trained language models
- https://arxiv.org/abs/2203.06904
- Despite the success, the process of fine-tuning large-scale PLMs brings prohibitive adaptation costs. In fact, fine-tuning all the parameters of a colossal model and retaining separate instances for different tasks are practically infeasible. This necessitates a new branch of research focusing on the parameter-efficient adaptation of PLMs, dubbed as delta tuning in this paper. In contrast with the standard fine-tuning, delta tuning only fine-tunes a small portion of the model parameters while keeping the rest untouched, largely reducing both the computation and storage costs. Recent studies have demonstrated that a series of delta tuning methods with distinct tuned parameter selection could achieve performance on a par with full-parameter fine-tuning, suggesting a new promising way of stimulating large-scale PLMs. In this paper, we first formally describe the problem of delta tuning and then comprehensively review recent delta tuning approaches. We also propose a unified categorization criterion that divide existing delta tuning methods into three groups: addition-based, specification-based, and reparameterization-based methods. Though initially proposed as an efficient method to steer large models, we believe that some of the fascinating evidence discovered along with delta tuning could help further reveal the mechanisms of PLMs and even deep neural networks. To this end, we discuss the theoretical principles underlying the effectiveness of delta tuning and propose frameworks to interpret delta tuning from the perspective of optimization and optimal control, respectively. Furthermore, we provide a holistic empirical study of representative methods, where results on over 100 NLP tasks demonstrate a comprehensive performance comparison of different approaches. The experimental results also cover the analysis of combinatorial, scaling and transferable properties of delta tuning.
More readings
Gemini: A Family of Highly Capable Multimodal Models
- https://arxiv.org/abs/2312.11805
- This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
QLoRA: Efficient Finetuning of Quantized LLMs
- Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, Luke Zettlemoyer We present QLoRA, an efficient finetuning approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance. QLoRA backpropagates gradients through a frozen, 4-bit quantized pretrained language model into Low Rank Adapters~(LoRA). Our best model family, which we name Guanaco, outperforms all previous openly released models on the Vicuna benchmark, reaching 99.3% of the performance level of ChatGPT while only requiring 24 hours of finetuning on a single GPU. QLoRA introduces a number of innovations to save memory without sacrificing performance: (a) 4-bit NormalFloat (NF4), a new data type that is information theoretically optimal for normally distributed weights (b) double quantization to reduce the average memory footprint by quantizing the quantization constants, and (c) paged optimziers to manage memory spikes. We use QLoRA to finetune more than 1,000 models, providing a detailed analysis of instruction following and chatbot performance across 8 instruction datasets, multiple model types (LLaMA, T5), and model scales that would be infeasible to run with regular finetuning (e.g. 33B and 65B parameter models). Our results show that QLoRA finetuning on a small high-quality dataset leads to state-of-the-art results, even when using smaller models than the previous SoTA. We provide a detailed analysis of chatbot performance based on both human and GPT-4 evaluations showing that GPT-4 evaluations are a cheap and reasonable alternative to human evaluation. Furthermore, we find that current chatbot benchmarks are not trustworthy to accurately evaluate the performance levels of chatbots. A lemon-picked analysis demonstrates where Guanaco fails compared to ChatGPT. We release all of our models and code, including CUDA kernels for 4-bit training.
related: LoRA: Low-Rank Adaptation of Large Language Models
- https://arxiv.org/abs/2106.09685
- An important paradigm of natural language processing consists of large-scale pre-training on general domain data and adaptation to particular tasks or domains. As we pre-train larger models, full fine-tuning, which retrains all model parameters, becomes less feasible. Using GPT-3 175B as an example – deploying independent instances of fine-tuned models, each with 175B parameters, is prohibitively expensive. We propose Low-Rank Adaptation, or LoRA, which freezes the pre-trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks. Compared to GPT-3 175B fine-tuned with Adam, LoRA can reduce the number of trainable parameters by 10,000 times and the GPU memory requirement by 3 times. LoRA performs on-par or better than fine-tuning in model quality on RoBERTa, DeBERTa, GPT-2, and GPT-3, despite having fewer trainable parameters, a higher training throughput, and, unlike adapters, no additional inference latency. We also provide an empirical investigation into rank-deficiency in language model adaptation, which sheds light on the efficacy of LoRA. We release a package that facilitates the integration of LoRA with PyTorch models and provide our implementations and model checkpoints for RoBERTa, DeBERTa, and GPT-2 at this https URL.
Astraios: Parameter-Efficient Instruction Tuning Code Large Language Models
- https://arxiv.org/abs/2401.00788
- Terry Yue Zhuo, Armel Zebaze, Nitchakarn Suppattarachai, Leandro von Werra, Harm de Vries, Qian Liu, Niklas Muennighoff
- The high cost of full-parameter fine-tuning (FFT) of Large Language Models (LLMs) has led to a series of parameter-efficient fine-tuning (PEFT) methods. However, it remains unclear which methods provide the best cost-performance trade-off at different model scales. We introduce Astraios, a suite of 28 instruction-tuned OctoCoder models using 7 tuning methods and 4 model sizes up to 16 billion parameters. Through investigations across 5 tasks and 8 different datasets encompassing both code comprehension and code generation tasks, we find that FFT generally leads to the best downstream performance across all scales, and PEFT methods differ significantly in their efficacy based on the model scale. LoRA usually offers the most favorable trade-off between cost and performance. Further investigation into the effects of these methods on both model robustness and code security reveals that larger models tend to demonstrate reduced robustness and less security. At last, we explore the relationships among updated parameters, cross-entropy loss, and task performance. We find that the tuning effectiveness observed in small models generalizes well to larger models, and the validation loss in instruction tuning can be a reliable indicator of overall downstream performance.
This site was built using GitHub Pages.
Blog:
Session Blog (LLM fine tuning)
Instruction Tuning for Large Language Models: A Survey
In recent years, large language models (LLMs) have demonstrated remarkable capabilities across a wide range of natural language tasks. However, a significant challenge lies in aligning the next-word prediction objective of LLMs with the user’s goal of having the models follow human instructions. Instruction tuning has emerged as a powerful technique to bridge this gap, enabling LLMs to understand and adhere to human instructions more effectively. In this comprehensive blog article, we delve into the various aspects of instruction tuning, including its methodology, dataset construction, tuned models, multi-modality applications, domain-specific use cases, and efficient tuning techniques.
Methodology of Instruction Tuning
Instruction tuning involves further training LLMs on datasets consisting of (INSTRUCTION, OUTPUT) pairs in a supervised manner. The process can be broken down into two main steps:
-
Instruction Dataset Construction: In this step, (INSTRUCTION, OUTPUT) pairs are collected or generated. The instructions provide a natural language description of the task to be performed, while the outputs represent the desired response that follows the given instruction. Datasets can be created by transforming existing text-label pairs into the (INSTRUCTION, OUTPUT) format using templates or by leveraging powerful LLMs to generate outputs based on manually curated or expanded instructions.
-
Instruction Tuning: Once the instruction dataset is prepared, the LLM undergoes fine-tuning using the collected (INSTRUCTION, OUTPUT) pairs. The model learns to generate the appropriate output based on the provided instruction, thus aligning its behavior with the user’s expectations. This fine-tuning process allows the LLM to internalize the patterns and nuances of following human instructions.

Construction of Instruction Tuning Datasets
The quality and diversity of instruction tuning datasets play a crucial role in the effectiveness of the tuned models. There are two primary approaches to constructing these datasets:
-
Data Integration from Annotated Natural Language Datasets: This approach involves transforming existing annotated datasets, which typically consist of text-label pairs, into the (INSTRUCTION, OUTPUT) format. By applying carefully designed templates, the original text-label pairs are converted into instructions and their corresponding outputs. Datasets like Flan and P3 have been constructed using this strategy, leveraging a wide range of existing NLP benchmarks.
-
Generating Outputs using LLMs: An alternative approach is to utilize powerful LLMs, such as GPT-3.5 or GPT-4, to generate outputs based on manually collected or expanded instructions. In this case, a set of seed instructions is manually curated, and then expanded using the LLMs to produce a larger and more diverse set of instructions. The generated instructions are then fed back into the LLMs to obtain the corresponding outputs. Datasets like InstructWild and Self-Instruct have been created following this approach, harnessing the generative capabilities of state-of-the-art LLMs.

Instruction Tuned Models
The development of instruction-tuned LLMs has led to significant performance gains across various tasks. Some notable models include:
-
InstructGPT: Developed by OpenAI, InstructGPT is fine-tuned on human instructions, resulting in improved performance on a range of NLP tasks and better alignment with user expectations.
-
Flan-T5: Flan-T5 is fine-tuned on the FLAN dataset, which consists of a diverse set of instructions and outputs. It has demonstrated strong performance on tasks such as natural language inference, question answering, and summarization.
-
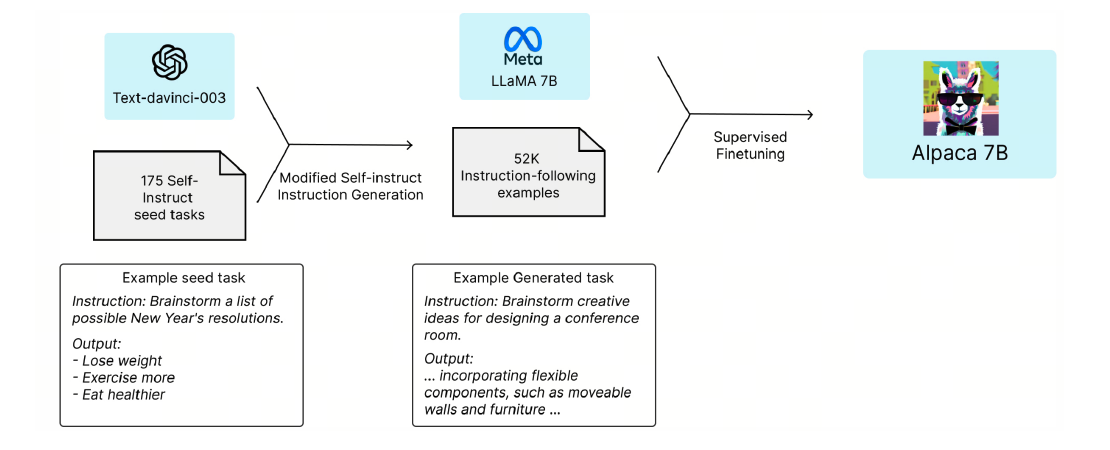
Alpaca: Alpaca is an instruction-tuned model based on the LLaMA architecture. It is fine-tuned on a dataset generated by GPT-3, showcasing the potential of leveraging powerful LLMs for instruction tuning.
-
Vicuna: Vicuna is a model fine-tuned on conversations with ChatGPT, an advanced conversational AI system. By learning from the patterns and behaviors of ChatGPT, Vicuna exhibits improved conversational abilities and coherence.
-
WizardLM: WizardLM is fine-tuned on the Evol-Instruct dataset, which is created using an evolutionary approach to generate diverse and complex instructions. It has shown promising results in following multi-step instructions and engaging in open-ended conversations.
Multi-Modality Instruction Finetuning
Instruction tuning has expanded beyond the realm of text-only tasks, enabling LLMs to process and generate outputs involving various modalities such as images, speech, and video. This multi-modal instruction tuning has opened up new possibilities for LLMs to understand and respond to instructions that span different modalities. Key multi-modal instruction tuning datasets include:
-
MULTIINSTRUCT: This dataset consists of a diverse set of multimodal tasks, covering image captioning, visual question answering, and text-to-image generation. It provides a comprehensive benchmark for evaluating the multi-modal capabilities of instruction-tuned models.
-
PMC-VQA: PMC-VQA is a large-scale medical visual question-answering dataset, containing image-question pairs across various modalities and diseases. It enables the development of instruction-tuned models for medical image understanding and diagnosis.
-
Vision-Flan: Vision-Flan is an extensive dataset for vision-language instruction tuning, comprising a wide range of tasks such as image captioning, visual reasoning, and text-to-image generation. It serves as a valuable resource for training models that can understand and follow instructions involving visual content.
-
ALLaVA: ALLaVA is a large-scale dataset specifically designed for fine-tuning visual question-answering models. It includes detailed captions, instructions, and comprehensive answers generated by advanced models like GPT-4.
-
ShareGPT4V: ShareGPT4V is a collection of highly descriptive image-text pairs, generated by GPT-4 and a pre-trained model. It covers various aspects such as global knowledge, object attributes, spatial relationships, and aesthetic evaluations, enabling the development of visually-aware instruction-tuned models.
Models like InstructPix2Pix, LLaVA, Video-LLaMA, and InstructBLIP have demonstrated strong performance on multi-modal tasks by leveraging these datasets and incorporating visual encoders alongside language models.

Applications in Different Domains
Instruction tuning has found applications across a wide range of domains, showcasing its versatility and potential for domain-specific tasks. Some notable examples include:
-
Dialogue: Models like InstructDial have been developed to improve the conversational abilities of LLMs in task-oriented and open-ended dialogue settings. By fine-tuning on instruction datasets specific to dialogue, these models can engage in more natural and coherent conversations.
-
Intent Classification and Slot Tagging: LINGUIST is an instruction-tuned model designed for intent classification and slot tagging tasks. It leverages instruction tuning to improve performance on recognizing user intents and extracting relevant entities from utterances.
-
Information Extraction: InstructUIE is a unified framework for information extraction tasks, utilizing instruction tuning to adapt LLMs to various extraction scenarios. It has shown promising results in zero-shot and few-shot settings, outperforming traditional approaches.
-
Sentiment Analysis: IT-MTL is an instruction tuning framework specifically designed for aspect-based sentiment analysis. By transforming the task into a set of question-answering instructions, IT-MTL achieves strong performance in both few-shot and full fine-tuning scenarios.
-
Writing Assistance: Models like Writing-Alpaca-7B and CoEdIT leverage instruction tuning to provide writing assistance and improve the quality of generated text. They can follow instructions related to style transfer, grammatical error correction, and content generation.
-
Medical Tasks: Instruction tuning has been applied to various medical tasks, such as radiology report generation (Radiology-GPT) and medical dialogue systems (ChatDoctor). These models demonstrate the potential of instruction tuning in domain-specific applications with high-stakes implications.
-
Math and Coding: Models like Goat and WizardCoder showcase the effectiveness of instruction tuning in math problem-solving and code generation tasks. By fine-tuning on instruction datasets specifically curated for these domains, the models can understand and generate solutions to mathematical and programming challenges.
Efficient Tuning Techniques
As LLMs continue to grow in size, the computational cost of instruction tuning becomes a significant challenge. To address this, several efficient tuning techniques have been proposed:
-
LoRA (Low-Rank Adaptation): LoRA introduces low-rank updates to the model parameters, significantly reducing the number of trainable parameters while maintaining performance. It allows for efficient adaptation of LLMs to downstream tasks without requiring full fine-tuning.
-
HINT (Hypernetwork Instruction Tuning): HINT combines the concept of hypernetworks with instruction tuning. It generates parameter-efficient modules based on natural language instructions and few-shot examples, enabling fast adaptation to new tasks without the need for repeated processing of lengthy instructions.
-
QLORA (Quantized LoRA): QLORA incorporates quantization and memory optimization techniques to further reduce the computational cost of instruction tuning. It enables the fine-tuning of large models on a single GPU with minimal performance degradation compared to full-precision fine-tuning.
-
LOMO (LOw-Memory Optimization): LOMO introduces a fusion of gradient computation and parameter updates, avoiding the need to store full gradient tensors. This reduces the memory footprint during the fine-tuning process, enabling the tuning of larger models with limited computational resources.
-
Delta-tuning: Delta-tuning provides a theoretical framework for efficient instruction tuning by restricting the tuning process to a low-dimensional manifold. It optimizes a small set of parameters that act as controllers, guiding the model’s behavior on downstream tasks.
Instruction tuning has emerged as a powerful paradigm for enhancing the capabilities and controllability of large language models. By aligning the models’ objectives with human instructions, instruction tuning enables LLMs to understand and follow complex tasks across various domains and modalities. As the field of instruction tuning continues to evolve, ongoing research efforts focus on further improving the quality and diversity of instruction datasets, developing more advanced tuning techniques, and exploring new applications across various domains. The potential of instruction tuning to unlock the full capabilities of large language models and enable more human-aligned and controllable AI systems is immense, and it holds great promise for shaping the future of natural language processing and artificial intelligence as a whole.
Delta Tuning: A Comprehensive Study of Parameter Efficient Methods for Pre-trained Language Models
Pre-trained language models (PLMs) have revolutionized the field of natural language processing (NLP), achieving state-of-the-art performance on a wide range of tasks. However, the ever-increasing size of these models presents challenges in terms of computational resources and storage requirements when fine-tuning them for specific downstream tasks. Delta tuning has emerged as a promising solution to efficiently adapt large PLMs while maintaining performance comparable to full fine-tuning. In this blog post, we dive into the comprehensive study “Delta Tuning: A Comprehensive Study of Parameter Efficient Methods for Pre-trained Language Models” by Ning Ding et al., which explores the landscape of delta tuning methods and provides valuable insights into their effectiveness and theoretical underpinnings.
An Overview of Delta Tuning


The authors propose a categorization criterion that divides existing delta tuning methods into three groups based on their underlying mechanisms:
-
Addition-based methods: These methods introduce additional trainable neural modules or parameters that are not present in the original PLM. Two notable examples are adapter-based tuning and prompt-based tuning. Adapter-based methods, such as Houlsby Adapter and Parallel Adapter, insert small trainable neural networks (adapters) between layers of the PLM, while keeping the original parameters frozen. Prompt-based methods, like prefix-tuning and prompt tuning, prepend learnable continuous prompts to the input or hidden states of the PLM.
-
Specification-based methods: These methods specify a subset of the original PLM’s parameters to be trainable while freezing the rest. Examples include BitFit, which only updates the bias terms, and diff pruning, which learns a sparse diff vector to modify the original parameters. These methods aim to identify the most relevant parameters for a given task and update them accordingly.
-
Reparameterization-based methods: These methods reparameterize the original PLM’s parameters into a more parameter-efficient form through mathematical transformations. A prominent example is LoRA (Low-Rank Adaptation), which learns low-rank decomposition matrices to modify the attention weights in the PLM. This approach capitalizes on the intrinsic low-rank structure of the weight differences between the pre-trained and fine-tuned models.
By carefully designing the trainable components and updating only a small fraction of the PLM’s parameters, delta tuning methods can significantly reduce the computational and memory requirements during adaptation while maintaining performance comparable to full fine-tuning.
Theoretical Perspectives of Delta Tuning
The authors propose two theoretical frameworks to analyze delta tuning methods from the perspectives of optimization and optimal control. These frameworks provide valuable insights into the underlying principles and mechanisms of delta tuning.
-
Optimization Perspective: The optimization perspective justifies the designs of existing delta tuning methods and explains various empirical observations. The authors argue that the effectiveness of delta tuning can be attributed to the intrinsic low dimensionality of the optimization problems in PLM adaptation. They show that delta tuning methods essentially perform optimization in a low-dimensional subspace, either in the solution space or the functional space. This perspective provides a unified view of different delta tuning methods and sheds light on their success in reducing the number of trainable parameters while maintaining performance.
-
Optimal Control Perspective: The optimal control perspective interprets delta tuning as a process of finding the optimal controllers for PLMs. The authors propose an optimal control framework that unifies different delta tuning approaches by formulating them as control problems. In this framework, the PLM is treated as a dynamical system, and the delta tuning methods are viewed as controllers that steer the system towards the desired output. The optimization of delta parameters is equivalent to solving for the optimal control policy. This perspective offers a principled way to design and analyze delta tuning methods and opens up new possibilities for developing more advanced and efficient adaptation techniques.
These theoretical perspectives not only deepen our understanding of delta tuning but also provide guidance for designing novel and more effective methods in the future. By leveraging the insights from optimization and optimal control theories, researchers can develop principled approaches to further improve the efficiency and performance of PLM adaptation.
Comparisons and Experimental Discoveries
The authors conduct extensive experiments across over 100 diverse NLP tasks to compare the performance, convergence, and efficiency of different delta tuning methods. They also explore the combinability, scaling behavior, and transferability of these methods. The key experimental findings are summarized below:
-
Performance: Despite using significantly fewer trainable parameters, delta tuning methods can achieve performance comparable to full fine-tuning in most cases. Among the evaluated methods, LoRA, Adapter, and prefix-tuning generally outperform prompt tuning, especially when the PLM’s size is relatively small. However, as the model size increases, the performance gap between different methods narrows, suggesting that the choice of delta tuning method becomes less critical for larger PLMs.
-
Convergence: The convergence speed of delta tuning methods is generally slower than full fine-tuning, with the ranking of convergence rates being: full fine-tuning > Adapter ≈ LoRA > prefix-tuning > prompt tuning. However, the convergence speed improves as the PLM’s size increases, indicating that the power of scale can benefit both performance and convergence.
-
Efficiency: Delta tuning methods can significantly reduce the computational and memory requirements during adaptation. Experiments show that delta tuning can save up to 75% of GPU memory usage compared to full fine-tuning, especially when the batch size is small. However, the actual efficiency gains may vary depending on the specific delta tuning method and the PLM’s size.
-
Combinability: Combining multiple delta tuning methods can often lead to better performance than using a single method alone. The optimal combination may vary depending on the PLM’s architecture, the downstream task, and the available training data. Experimental results suggest that adding BitFit to the combination generally improves performance, while prompt tuning may not always be compatible with other methods.
These experimental discoveries provide valuable insights into the practical application of delta tuning methods and guide the selection of appropriate methods for different scenarios. The findings also highlight the potential of combining multiple delta tuning methods and leveraging the power of scale to further improve the efficiency and effectiveness of PLM adaptation.
Applications
Delta tuning has significant potential for a wide range of real-world applications, particularly in scenarios where computational resources and storage are limited. The authors discuss several promising application areas where delta tuning can make a substantial impact:
-
Fast Training and Shareable Checkpoints: Delta tuning enables faster training of large PLMs by updating only a small fraction of the parameters. This not only reduces the computational cost but also allows for more efficient sharing of the trained delta parameters. Instead of sharing the entire fine-tuned PLM, which can be prohibitively large, researchers and practitioners can share only the learned delta parameters, significantly reducing storage and transmission requirements. This facilitates collaboration and knowledge sharing within the NLP community.
-
Multi-Task Learning: Delta tuning is particularly well-suited for multi-task learning scenarios, where a single PLM needs to be adapted to multiple downstream tasks simultaneously. By learning task-specific delta parameters for each task, the PLM can effectively capture the unique characteristics of each task while sharing the common knowledge encoded in the frozen parameters. This approach enables more efficient and scalable multi-task learning compared to full fine-tuning of separate models for each task.
-
Mitigating Catastrophic Forgetting: Catastrophic forgetting is a common challenge in sequential fine-tuning of PLMs, where the model tends to forget the knowledge learned from previous tasks when adapted to new tasks. Delta tuning can help mitigate this issue by keeping the original PLM’s parameters fixed and learning only the task-specific delta parameters. This allows the model to retain its general knowledge while adapting to new tasks, thus reducing the impact of catastrophic forgetting.
-
Improved Fairness and Bias Mitigation: PLMs are known to inherit biases from the training data, which can lead to unfair or discriminatory outputs when applied to downstream tasks. Delta tuning offers a potential solution to mitigate these biases by adapting the model to more balanced and diverse datasets. By carefully designing the delta parameters and the adaptation process, researchers can aim to reduce the biases present in the original PLM and promote fairness in the model’s outputs.
As delta tuning continues to evolve and mature, it is expected to find even more applications across various domains where efficient adaptation of large PLMs is crucial. The authors encourage further research and development efforts to unlock the full potential of delta tuning and make PLMs more accessible, efficient, and effective for a wide range of real-world problems.
DoRA: Weight-Decomposed Low-Rank Adaptation
As the scale of pre-trained models continues to grow, the computational cost of fine-tuning these models on downstream tasks becomes increasingly prohibitive. Parameter-efficient fine-tuning (PEFT) methods have emerged as a solution to this challenge, enabling effective adaptation of large models with only a small number of trainable parameters. Among PEFT techniques, Low-Rank Adaptation (LoRA) has gained significant popularity due to its simplicity and ability to avoid additional inference costs. However, there often remains a performance gap between LoRA and full fine-tuning (FT). In the paper “DoRA: Weight-Decomposed Low-Rank Adaptation”, Liu et al. introduce a novel PEFT method called DoRA that aims to bridge this gap. By decomposing pre-trained weights into magnitude and direction components, DoRA enhances the learning capacity and training stability of LoRA while maintaining inference efficiency.
An overview of DoRA


Comparison with LoRA and FT
To understand the differences between DoRA, LoRA, and FT, the authors conduct a weight decomposition analysis. They decompose the weights learned by each method and examine the changes in magnitude and direction relative to the pre-trained weights. The analysis reveals distinct learning patterns:
-
FT exhibits diverse behaviors, with the ability to make significant changes in either magnitude or direction while keeping the other component relatively unchanged.
-
LoRA shows a proportional relationship between magnitude and direction changes, lacking the flexibility to make independent updates.
-
DoRA demonstrates a learning pattern more closely resembling FT, with the capability to make substantial directional updates with minimal magnitude changes, or vice versa.
These differences suggest that DoRA has a higher learning capacity compared to LoRA, which may explain its superior performance on downstream tasks.
Experiments on DoRA
The authors validate the effectiveness of DoRA through extensive experiments on various tasks and model architectures:
-
Commonsense Reasoning: DoRA outperforms LoRA and other PEFT baselines when fine-tuning LLaMA-7B/13B on 8 commonsense reasoning datasets. Even with half the trainable parameters (DoRA†), DoRA surpasses LoRA by significant margins.
-
Image/Video-Text Understanding: On multi-task image-text and video-text benchmarks, DoRA consistently improves upon LoRA while adapting a similar number of parameters. DoRA achieves accuracy comparable to FT on certain tasks.
-
Visual Instruction Tuning: DoRA surpasses both LoRA and FT when tuning LLaVA-1.5-7B on a range of vision-language tasks.
-
Compatibility with LoRA Variants: DoRA demonstrates compatibility with VeRA, a variant of LoRA that uses fixed random matrices. The combined approach, DVoRA, outperforms both VeRA and LoRA while using fewer parameters.
Additional experiments highlight the robustness of DoRA across different rank settings and its ability to maintain high performance with fewer trainable parameters by selectively updating the magnitude and directional components of certain layers.
DoRA presents a novel PEFT method that enhances the learning capacity of LoRA by decomposing pre-trained weights into magnitude and direction components. Through a weight decomposition analysis, the authors demonstrate that DoRA exhibits learning patterns more similar to full fine-tuning compared to LoRA. Extensive experiments across various tasks and model architectures showcase the superior performance of DoRA over LoRA and other PEFT baselines. DoRA consistently improves accuracy while maintaining a similar level of parameter efficiency and inference speed as LoRA. The compatibility of DoRA with LoRA variants like VeRA further highlights its flexibility and potential for future research. As the demand for efficient adaptation of large pre-trained models continues to grow, DoRA offers a promising approach to bridge the performance gap between parameter-efficient methods and full fine-tuning.
Recent Large Language Models Reshaping the Open-Source Arena
The world of open-source large language models (LLMs) is experiencing a rapid evolution, with innovative models being released at an unprecedented pace. Since the release of Meta’s Llama model and its successor, Llama 2, in 2023, the open-source landscape has been transformed by a wave of powerful and versatile LLMs. This article delves into the most influential open-source models making waves in 2024, examining their unique architectures, training approaches, and performance across various benchmarks.
The world of open-source large language models (LLMs) is experiencing a rapid evolution, with innovative models being released at an unprecedented pace. Since the release of Meta’s Llama model and its successor, Llama 2, in 2023, the open-source landscape has been transformed by a wave of powerful and versatile LLMs. This article delves into the most influential open-source models making waves in 2024, examining their unique architectures, training approaches, and performance across various benchmarks.
-
Qwen1.5 Developed by Alibaba Cloud, Qwen1.5 is a family of base and chat-tuned models available in sizes ranging from 0.5B to 72B parameters. Built on the Transformer architecture, these models incorporate SwiGLU activation, attention QKV bias, Grouped Query Attention (GQA), and combine sliding window attention with full attention. Qwen1.5 models support 12 languages and a context window of 32k tokens. Their instruction following capabilities have been enhanced through Direct Preference Optimization (DPO) and Proximal Policy Optimization (PPO). Qwen1.5-72B-Chat stands out for its impressive performance on human and LLM judge evaluations like MT Bench and AlpacaEval.
-
Yi The Yi model series, developed by 01.AI, offers base and chat-tuned models in 6B, 9B, and 34B parameter sizes. These models employ a modified Transformer architecture with GQA, adjusted SwiGLU activation, and RoPE with Adjusted Base Frequency to support context windows up to 200k tokens. Yi models underwent an extensive data cleaning pipeline and were fine-tuned using a diversity-focused approach with fewer than 10K multi-turn instruction-response pairs. Yi-34B delivers near GPT-3.5 level performance.
-
Smaug Abacus.AI’s Smaug series includes 34B and 72B parameter models fine-tuned using DPO-Positive (DPOP), a variant of DPO designed to address specific failure modes. Smaug-72B surpassed an average score of 80% on the Open LLM Leaderboard, benefiting from training datasets tailored for downstream tasks like GSM8K, ARC, and HellaSwag.
-
Mixtral-8x7B Mistral’s Mixtral-8x7B models feature a sparse Mixture of Experts (MoE) architecture with 46.7B total parameters but only 12.9B active parameters per token. These models support English, French, Italian, German, and Spanish, and have a 32k context window. Mixtral-8x7b-instruct-v0.1 achieves competitive scores on MT Bench and Chatbot Arena leaderboards.
-
DBRX Databricks’ DBRX models boast 132B total parameters and 36B active parameters per input, leveraging a fine-grained MoE architecture with 4 out of 16 experts per input. The base models underwent pre-training on 12T tokens with curriculum learning, while the instruction-tuned variants demonstrate strong performance on MT Bench and Open LLM Leaderboard.
-
SOLAR-10.7B Upstage AI’s SOLAR-10.7B models were developed using an innovative Depth up-scaling (DUS) approach, starting from a 32-layer Mistral 7B base model and expanding its depth through duplication, layer removal, and recombination, followed by continued pre-training. The instruction-tuned and DPO-aligned variants show competitive performance on various benchmarks.
-
TÜLU v2 The Allen Institute for AI’s TÜLU v2 models, available in 7B, 13B, and 70B parameter sizes, were developed by fine-tuning and aligning Llama 2 models using a diverse dataset mix. The DPO-aligned 70B variant achieves notable scores on MT Bench and Chatbot Arena leaderboards.
-
WizardLM Developed by a Microsoft research team, the WizardLM series includes base and instruction-tuned models in 7B, 13B, and 70B parameter sizes. These models were fine-tuned using the Evol-Instruct approach, which employs LLMs to autonomously generate diverse and complex instruction sets. WizardLM-70B demonstrates competitive performance on high-complexity tasks and human evaluations.
-
Starling-LM-7B Starling-LM-7B, developed by Berkeley researchers, was trained from Openchat 3.5 using Reinforcement Learning from AI Feedback (RLAIF) and a GPT-4 labeled ranking dataset called Nectar. This model achieves impressive scores on MT Bench, surpassing all models except GPT-4 and GPT-4 Turbo at the time of its release.
-
OLMo The Allen Institute for AI’s OLMo models, available in 1B and 7B parameter sizes, were pre-trained on the Dolma dataset and further enhanced through supervised fine-tuning and DPO alignment. The OLMo-7B-Instruct variant demonstrates notable improvements in reasoning tasks and safety metrics.
-
Gemma Google DeepMind’s Gemma models, in 2B and 7B parameter sizes, leverage Multi-head Attention (MHA) or Multi-query Attention (MQA), GeGLU activations, RoPE embeddings, and RMSNorm. Trained on web documents, mathematics, and code, these models excel in tasks like GSM8K and MATH benchmarks.
-
DeciLM-7B Deci.AI’s DeciLM-7B stands out for its high efficiency and speed, featuring an 8192 context window and Variable GQA. Developed using Deci’s AutoNAC neural architecture search technology, DeciLM-7B underwent instruction tuning with LoRA on the SlimOrca dataset. Combined with the Infery-LLM SDK, DeciLM-7B achieves impressive throughput and high-speed inference.
The rapid advancements in open-source LLMs have transformed the AI landscape, making powerful language models more accessible and spurring innovation across various domains. As these models continue to evolve and new contenders emerge, the open-source arena remains a dynamic and exciting space to watch. Researchers, developers, and businesses alike can harness the potential of these models to push the boundaries of natural language processing and develop groundbreaking applications.