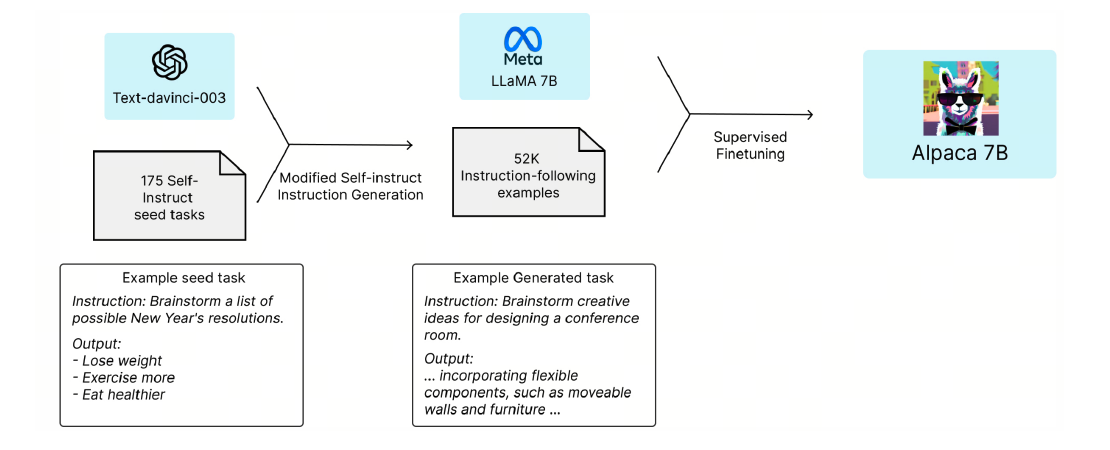
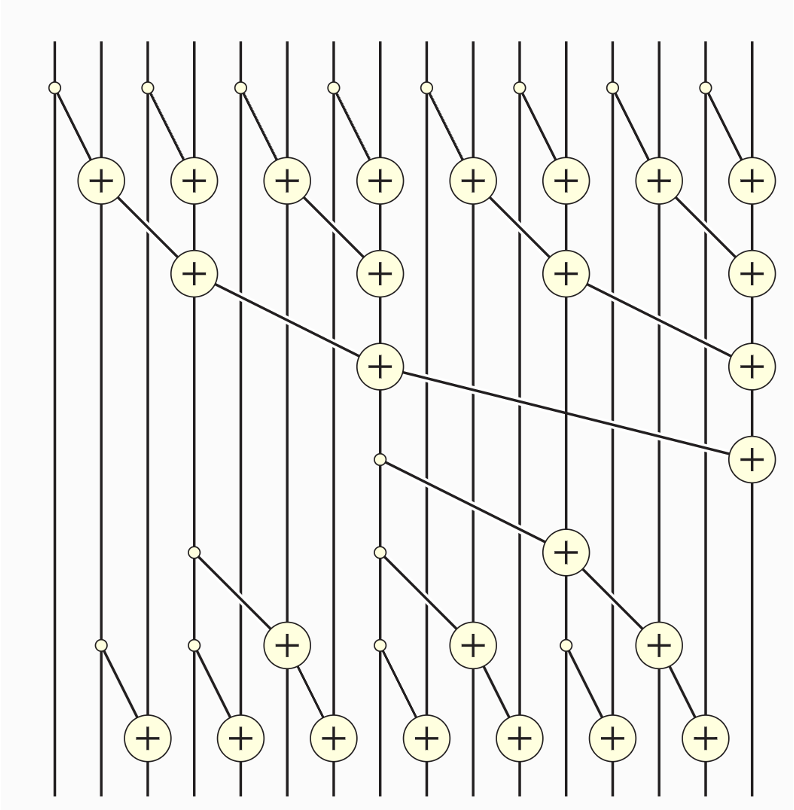
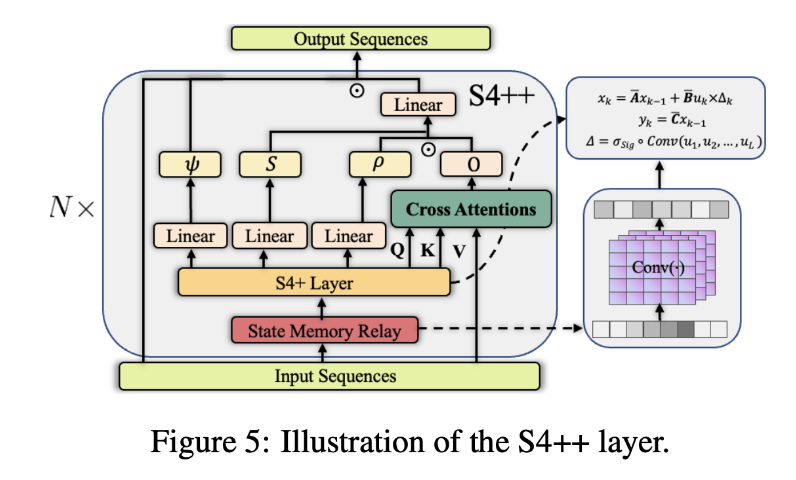
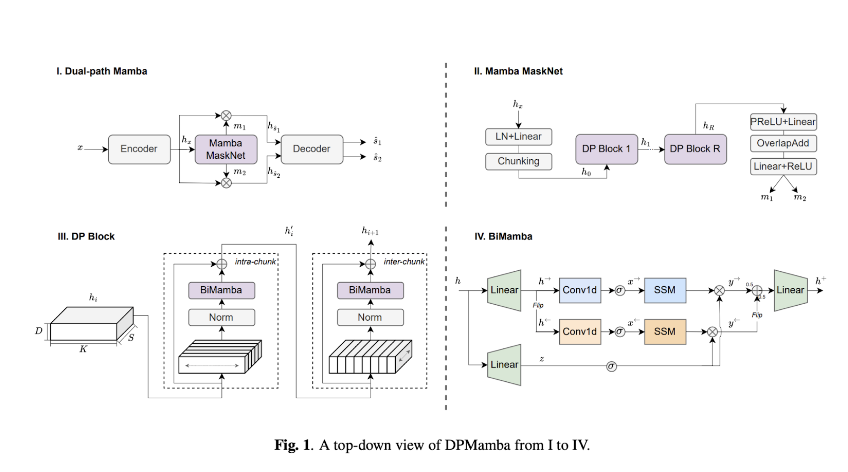
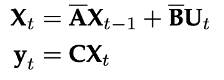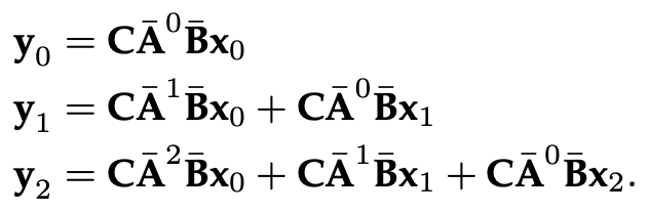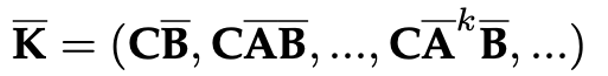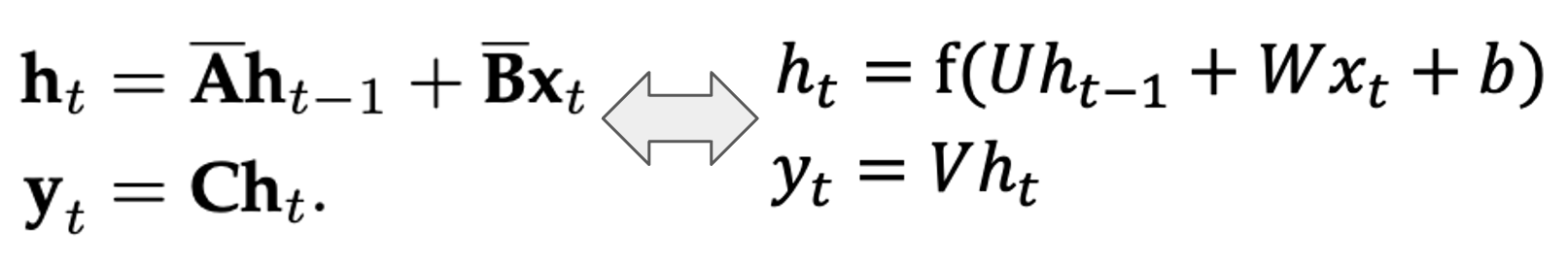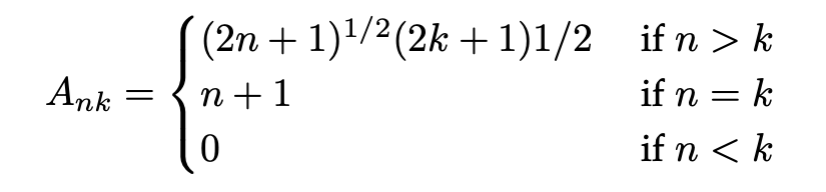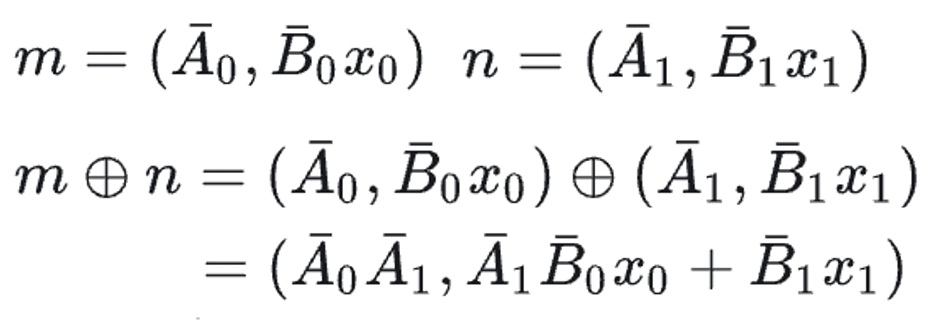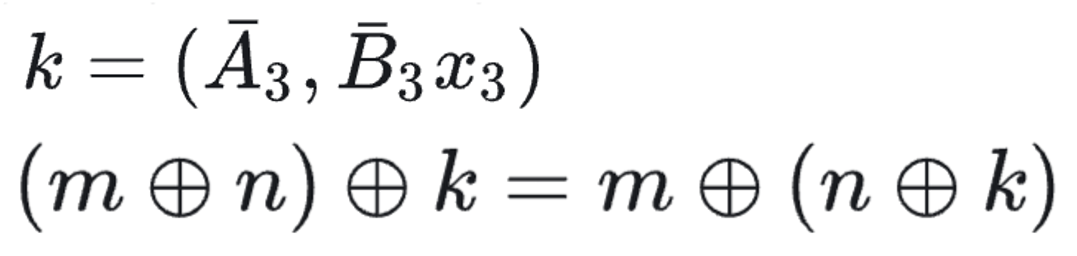“an ability to be emergent if it is not present in smaller models but is present in larger models. Thus, emergent abilities cannot be predicted simply by extrapolating the performance of smaller models.”
“GPT-3, 175B autoregerssive LLM; show that scaling up language models greatly improves task-agnostic, few-shot performance, sometimes even reaching competitiveness with prior state-of-the-art fine-tuning approaches.”
Extra Readings:
A survey of Generative AI Applications
https://arxiv.org/abs/2306.02781
Generative AI has experienced remarkable growth in recent years, leading to a wide array of applications across diverse domains. In this paper, we present a comprehensive survey of more than 350 generative AI applications, providing a structured taxonomy and concise descriptions of various unimodal and even multimodal generative AIs. The survey is organized into sections, covering a wide range of unimodal generative AI applications such as text, images, video, gaming and brain information. Our survey aims to serve as a valuable resource for researchers and practitioners to navigate the rapidly expanding landscape of generative AI, facilitating a better understanding of the current state-of-the-art and fostering further innovation in the field.
ChatGPT is not all you need. A State of the Art Review of large Generative AI models
Roberto Gozalo-Brizuela, Eduardo C. Garrido-Merchan
https://arxiv.org/abs/2301.04655
During the last two years there has been a plethora of large generative models such as ChatGPT or Stable Diffusion that have been published. Concretely, these models are able to perform tasks such as being a general question and answering system or automatically creating artistic images that are revolutionizing several sectors. Consequently, the implications that these generative models have in the industry and society are enormous, as several job positions may be transformed. For example, Generative AI is capable of transforming effectively and creatively texts to images, like the DALLE-2 model; text to 3D images, like the Dreamfusion model; images to text, like the Flamingo model; texts to video, like the Phenaki model; texts to audio, like the AudioLM model; texts to other texts, like ChatGPT; texts to code, like the Codex model; texts to scientific texts, like the Galactica model or even create algorithms like AlphaTensor. This work consists on an attempt to describe in a concise way the main models are sectors that are affected by generative AI and to provide a taxonomy of the main generative models published recently.
A Survey of Large Language Models
https://arxiv.org/abs/2303.18223
Language is essentially a complex, intricate system of human expressions governed by grammatical rules. It poses a significant challenge to develop capable AI algorithms for comprehending and grasping a language. As a major approach, language modeling has been widely studied for language understanding and generation in the past two decades, evolving from statistical language models to neural language models. Recently, pre-trained language models (PLMs) have been proposed by pre-training Transformer models over large-scale corpora, showing strong capabilities in solving various NLP tasks. Since researchers have found that model scaling can lead to performance improvement, they further study the scaling effect by increasing the model size to an even larger size. Interestingly, when the parameter scale exceeds a certain level, these enlarged language models not only achieve a significant performance improvement but also show some special abilities that are not present in small-scale language models. To discriminate the difference in parameter scale, the research community has coined the term large language models (LLM) for the PLMs of significant size. Recently, the research on LLMs has been largely advanced by both academia and industry, and a remarkable progress is the launch of ChatGPT, which has attracted widespread attention from society. The technical evolution of LLMs has been making an important impact on the entire AI community, which would revolutionize the way how we develop and use AI algorithms. In this survey, we review the recent advances of LLMs by introducing the background, key findings, and mainstream techniques. In particular, we focus on four major aspects of LLMs, namely pre-training, adaptation tuning, utilization, and capacity evaluation. Besides, we also summarize the available resources for developing LLMs and discuss the remaining issues for future directions.
On the Opportunities and Risks of Foundation Models
https://arxiv.org/abs/2108.07258
” a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations).”
Please click each post's URL shown below to check out its full contents.
The stunning qualitative improvement of recent text-to-image models has led to their widespread attention and adoption. However, we lack a comprehensive quantitative understanding of their capabilities and risks. To fill this gap, we introduce a new benchmark, Holistic Evaluation of Text-to-Image Models (HEIM). Whereas previous evaluations focus mostly on text-image alignment and image quality, we identify 12 aspects, including text-image alignment, image quality, aesthetics, originality, reasoning, knowledge, bias, toxicity, fairness, robustness, multilinguality, and efficiency. We curate 62 scenarios encompassing these aspects and evaluate 26 state-of-the-art text-to-image models on this benchmark. Our results reveal that no single model excels in all aspects, with different models demonstrating different strengths. We release the generated images and human evaluation results for full transparency at this https URL and the code at this https URL, which is integrated with the HELM codebase.
Evaluating Large Language Models: A Comprehensive Survey
https://arxiv.org/abs/2310.19736
This survey endeavors to offer a panoramic perspective on the evaluation of LLMs. We categorize the evaluation of LLMs into three major groups: knowledge and capability evaluation, alignment evaluation and safety evaluation. In addition to the comprehensive review on the evaluation methodologies and benchmarks on these three aspects, we collate a compendium of evaluations pertaining to LLMs’ performance in specialized domains, and discuss the construction of comprehensive evaluation platforms that cover LLM evaluations on capabilities, alignment, safety, and applicability.
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
https://arxiv.org/abs/2312.06674
We introduce Llama Guard, an LLM-based input-output safeguard model geared towards Human-AI conversation use cases. Our model incorporates a safety risk taxonomy, a valuable tool for categorizing a specific set of safety risks found in LLM prompts (i.e., prompt classification). This taxonomy is also instrumental in classifying the responses generated by LLMs to these prompts, a process we refer to as response classification. For the purpose of both prompt and response classification, we have meticulously gathered a dataset of high quality. Llama Guard, a Llama2-7b model that is instruction-tuned on our collected dataset, albeit low in volume, demonstrates strong performance on existing benchmarks such as the OpenAI Moderation Evaluation dataset and ToxicChat, where its performance matches or exceeds that of currently available content moderation tools. Llama Guard functions as a language model, carrying out multi-class classification and generating binary decision scores. Furthermore, the instruction fine-tuning of Llama Guard allows for the customization of tasks and the adaptation of output formats. This feature enhances the model’s capabilities, such as enabling the adjustment of taxonomy categories to align with specific use cases, and facilitating zero-shot or few-shot prompting with diverse taxonomies at the input. We are making Llama Guard model weights available and we encourage researchers to further develop and adapt them to meet the evolving needs of the community for AI safety.
More Readings:
Not what you’ve signed up for: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection
[Submitted on 23 Feb 2023 (v1), last revised 5 May 2023 (this version, v2)]
https://arxiv.org/abs/2302.12173
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, Mario Fritz
Large Language Models (LLMs) are increasingly being integrated into various applications. The functionalities of recent LLMs can be flexibly modulated via natural language prompts. This renders them susceptible to targeted adversarial prompting, e.g., Prompt Injection (PI) attacks enable attackers to override original instructions and employed controls. So far, it was assumed that the user is directly prompting the LLM. But, what if it is not the user prompting? We argue that LLM-Integrated Applications blur the line between data and instructions. We reveal new attack vectors, using Indirect Prompt Injection, that enable adversaries to remotely (without a direct interface) exploit LLM-integrated applications by strategically injecting prompts into data likely to be retrieved. We derive a comprehensive taxonomy from a computer security perspective to systematically investigate impacts and vulnerabilities, including data theft, worming, information ecosystem contamination, and other novel security risks. We demonstrate our attacks’ practical viability against both real-world systems, such as Bing’s GPT-4 powered Chat and code-completion engines, and synthetic applications built on GPT-4. We show how processing retrieved prompts can act as arbitrary code execution, manipulate the application’s functionality, and control how and if other APIs are called. Despite the increasing integration and reliance on LLMs, effective mitigations of these emerging threats are currently lacking. By raising awareness of these vulnerabilities and providing key insights into their implications, we aim to promote the safe and responsible deployment of these powerful models and the development of robust defenses that protect users and systems from potential attacks.
Subjects: Cryptography and Security (cs.CR); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computers and Society (cs.CY)
Baseline Defenses for Adversarial Attacks Against Aligned Language Models
https://github.com/neelsjain/baseline-defenses
Please click each post's URL shown below to check out its full contents.
The Flan Collection: Designing Data and Methods for Effective Instruction Tuning
https://arxiv.org/abs/2301.13688
We study the design decisions of publicly available instruction tuning methods, and break down the development of Flan 2022 (Chung et al., 2022). Through careful ablation studies on the Flan Collection of tasks and methods, we tease apart the effect of design decisions which enable Flan-T5 to outperform prior work by 3-17%+ across evaluation settings. We find task balancing and enrichment techniques are overlooked but critical to effective instruction tuning, and in particular, training with mixed prompt settings (zero-shot, few-shot, and chain-of-thought) actually yields stronger (2%+) performance in all settings. In further experiments, we show Flan-T5 requires less finetuning to converge higher and faster than T5 on single downstream tasks, motivating instruction-tuned models as more computationally-efficient starting checkpoints for new tasks. Finally, to accelerate research on instruction tuning, we make the Flan 2022 collection of datasets, templates, and methods publicly available at this https URL.
DPO Direct Preference Optimization: Your Language Model is Secretly a Reward Model
https://arxiv.org/abs/2305.18290
https://huggingface.co/blog/dpo-trl
While large-scale unsupervised language models (LMs) learn broad world knowledge and some reasoning skills, achieving precise control of their behavior is difficult due to the completely unsupervised nature of their training. Existing methods for gaining such steerability collect human labels of the relative quality of model generations and fine-tune the unsupervised LM to align with these preferences, often with reinforcement learning from human feedback (RLHF). However, RLHF is a complex and often unstable procedure, first fitting a reward model that reflects the human preferences, and then fine-tuning the large unsupervised LM using reinforcement learning to maximize this estimated reward without drifting too far from the original model. In this paper we introduce a new parameterization of the reward model in RLHF that enables extraction of the corresponding optimal policy in closed form, allowing us to solve the standard RLHF problem with only a simple classification loss. The resulting algorithm, which we call Direct Preference Optimization (DPO), is stable, performant, and computationally lightweight, eliminating the need for sampling from the LM during fine-tuning or performing significant hyperparameter tuning. Our experiments show that DPO can fine-tune LMs to align with human preferences as well as or better than existing methods. Notably, fine-tuning with DPO exceeds PPO-based RLHF in ability to control sentiment of generations, and matches or improves response quality in summarization and single-turn dialogue while being substantially simpler to implement and train.
Training language models to follow instructions with human feedback
https://arxiv.org/abs/2203.02155)
“further fine-tune this supervised model using reinforcement learning from human feedback. We call the resulting models InstructGPT.”
Deep reinforcement learning from human preferences
https://openreview.net/forum?id=GisHNaleWiA
“explore goals defined in terms of (non-expert) human preferences between pairs of trajectory segments. We show that this approach can effectively solve complex RL tasks without access to the reward function”
Please click each post's URL shown below to check out its full contents.
We introduce Mistral 7B v0.1, a 7-billion-parameter language model engineered for superior performance and efficiency. Mistral 7B outperforms Llama 2 13B across all evaluated benchmarks, and Llama 1 34B in reasoning, mathematics, and code generation. Our model leverages grouped-query attention (GQA) for faster inference, coupled with sliding window attention (SWA) to effectively handle sequences of arbitrary length with a reduced inference cost. We also provide a model fine-tuned to follow instructions, Mistral 7B – Instruct, that surpasses the Llama 2 13B – Chat model both on human and automated benchmarks. Our models are released under the Apache 2.0 license.
More Readings:
OLMo: Accelerating the Science of Language Models
https://arxiv.org/abs/2402.00838
Language models (LMs) have become ubiquitous in both NLP research and in commercial product offerings. As their commercial importance has surged, the most powerful models have become closed off, gated behind proprietary interfaces, with important details of their training data, architectures, and development undisclosed. Given the importance of these details in scientifically studying these models, including their biases and potential risks, we believe it is essential for the research community to have access to powerful, truly open LMs. To this end, this technical report details the first release of OLMo, a state-of-the-art, truly Open Language Model and its framework to build and study the science of language modeling. Unlike most prior efforts that have only released model weights and inference code, we release OLMo and the whole framework, including training data and training and evaluation code. We hope this release will empower and strengthen the open research community and inspire a new wave of innovation.
Mixtral of Experts
https://arxiv.org/abs/2401.04088
We introduce Mixtral 8x7B, a Sparse Mixture of Experts (SMoE) language model. Mixtral has the same architecture as Mistral 7B, with the difference that each layer is composed of 8 feedforward blocks (i.e. experts). For every token, at each layer, a router network selects two experts to process the current state and combine their outputs. Even though each token only sees two experts, the selected experts can be different at each timestep. As a result, each token has access to 47B parameters, but only uses 13B active parameters during inference. Mixtral was trained with a context size of 32k tokens and it outperforms or matches Llama 2 70B and GPT-3.5 across all evaluated benchmarks. In particular, Mixtral vastly outperforms Llama 2 70B on mathematics, code generation, and multilingual benchmarks. We also provide a model fine-tuned to follow instructions, Mixtral 8x7B - Instruct, that surpasses GPT-3.5 Turbo, Claude-2.1, Gemini Pro, and Llama 2 70B - chat model on human benchmarks. Both the base and instruct models are released under the Apache 2.0 license.
- Llama 2: Open Foundation and Fine-Tuned Chat Models
In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed-source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
https://arxiv.org/abs/2101.00027
Recent work has demonstrated that increased training dataset diversity improves general cross-domain knowledge and downstream generalization capability for large-scale language models. With this in mind, we present \textit{the Pile}: an 825 GiB English text corpus targeted at training large-scale language models. The Pile is constructed from 22 diverse high-quality subsets – both existing and newly constructed – many of which derive from academic or professional sources. Our evaluation of the untuned performance of GPT-2 and GPT-3 on the Pile shows that these models struggle on many of its components, such as academic writing. Conversely, models trained on the Pile improve significantly over both Raw CC and CC-100 on all components of the Pile, while improving performance on downstream evaluations. Through an in-depth exploratory analysis, we document potentially concerning aspects of the data for prospective users. We make publicly available the code used in its construction.
Please click each post's URL shown below to check out its full contents.
TrustLLM: Trustworthiness in Large Language Models
https://arxiv.org/abs/2401.05561
Large language models (LLMs), exemplified by ChatGPT, have gained considerable attention for their excellent natural language processing capabilities. Nonetheless, these LLMs present many challenges, particularly in the realm of trustworthiness. Therefore, ensuring the trustworthiness of LLMs emerges as an important topic. This paper introduces TrustLLM, a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. Our findings firstly show that in general trustworthiness and utility (i.e., functional effectiveness) are positively related. Secondly, our observations reveal that proprietary LLMs generally outperform most open-source counterparts in terms of trustworthiness, raising concerns about the potential risks of widely accessible open-source LLMs. However, a few open-source LLMs come very close to proprietary ones. Thirdly, it is important to note that some LLMs may be overly calibrated towards exhibiting trustworthiness, to the extent that they compromise their utility by mistakenly treating benign prompts as harmful and consequently not responding. Finally, we emphasize the importance of ensuring transparency not only in the models themselves but also in the technologies that underpin trustworthiness. Knowing the specific trustworthy technologies that have been employed is crucial for analyzing their effectiveness.
A Survey on Large Language Model (LLM) Security and Privacy: The Good, the Bad, and the Ugly
Large Language Models (LLMs), such as ChatGPT and Bard, have revolutionized natural language understanding and generation. They possess deep language comprehension, human-like text generation capabilities, contextual awareness, and robust problem-solving skills, making them invaluable in various domains (e.g., search engines, customer support, translation). In the meantime, LLMs have also gained traction in the security community, revealing security vulnerabilities and showcasing their potential in security-related tasks. This paper explores the intersection of LLMs with security and privacy. Specifically, we investigate how LLMs positively impact security and privacy, potential risks and threats associated with their use, and inherent vulnerabilities within LLMs. Through a comprehensive literature review, the paper categorizes the papers into “The Good” (beneficial LLM applications), “The Bad” (offensive applications), and “The Ugly” (vulnerabilities of LLMs and their defenses). We have some interesting findings. For example, LLMs have proven to enhance code security (code vulnerability detection) and data privacy (data confidentiality protection), outperforming traditional methods. However, they can also be harnessed for various attacks (particularly user-level attacks) due to their human-like reasoning abilities. We have identified areas that require further research efforts. For example, Research on model and parameter extraction attacks is limited and often theoretical, hindered by LLM parameter scale and confidentiality. Safe instruction tuning, a recent development, requires more exploration. We hope that our work can shed light on the LLMs’ potential to both bolster and jeopardize cybersecurity
https://arxiv.org/abs/2312.02003
More Readings:
Survey of Vulnerabilities in Large Language Models Revealed by Adversarial Attacks
https://arxiv.org/abs/2212.14834
Large Language Models (LLMs) are swiftly advancing in architecture and capability, and as they integrate more deeply into complex systems, the urgency to scrutinize their security properties grows. This paper surveys research in the emerging interdisciplinary field of adversarial attacks on LLMs, a subfield of trustworthy ML, combining the perspectives of Natural Language Processing and Security. Prior work has shown that even safety-aligned LLMs (via instruction tuning and reinforcement learning through human feedback) can be susceptible to adversarial attacks, which exploit weaknesses and mislead AI systems, as evidenced by the prevalence of `jailbreak’ attacks on models like ChatGPT a
Ignore This Title and HackAPrompt: Exposing Systemic Vulnerabilities of LLMs through a Global Scale Prompt Hacking Competition
https://arxiv.org/abs/2311.16119
Large Language Models (LLMs) are deployed in interactive contexts with direct user engagement, such as chatbots and writing assistants. These deployments are vulnerable to prompt injection and jailbreaking (collectively, prompt hacking), in which models are manipulated to ignore their original instructions and follow potentially malicious ones. Although widely acknowledged as a significant security threat, there is a dearth of large-scale resources and quantitative studies on prompt hacking. To address this lacuna, we launch a global prompt hacking competition, which allows for free-form human input attacks. We elicit 600K+ adversarial prompts against three state-of-the-art LLMs. We describe the dataset, which empirically verifies that current LLMs can indeed be manipulated via prompt hacking. We also present a comprehensive taxonomical ontology of the types of adversarial prompts.
Even More:
ACL 2024 Tutorial: Vulnerabilities of Large Language Models to Adversarial Attacks
https://llm-vulnerability.github.io/
Generative AI and ChatGPT: Applications, challenges, and AI-human collaboration
Existing foundation models are trained on copyrighted material. Deploying these models can pose both legal and ethical risks when data creators fail to receive appropriate attribution or compensation. In the United States and several other countries, copyrighted content may be used to build foundation models without incurring liability due to the fair use doctrine. However, there is a caveat: If the model produces output that is similar to copyrighted data, particularly in scenarios that affect the market of that data, fair use may no longer apply to the output of the model. In this work, we emphasize that fair use is not guaranteed, and additional work may be necessary to keep model development and deployment squarely in the realm of fair use. First, we survey the potential risks of developing and deploying foundation models based on copyrighted content. We review relevant U.S. case law, drawing parallels to existing and potential applications for generating text, source code, and visual art. Experiments confirm that popular foundation models can generate content considerably similar to copyrighted material. Second, we discuss technical mitigations that can help foundation models stay in line with fair use. We argue that more research is needed to align mitigation strategies with the current state of the law. Lastly, we suggest that the law and technical mitigations should co-evolve. For example, coupled with other policy mechanisms, the law could more explicitly consider safe harbors when strong technical tools are used to mitigate infringement harms. This co-evolution may help strike a balance between intellectual property and innovation, which speaks to the original goal of fair use. But we emphasize that the strategies we describe here are not a panacea and more work is needed to develop policies that address the potential harms of foundation models.
Extracting Training Data from Diffusion Models
Nicholas Carlini, Jamie Hayes, Milad Nasr, Matthew Jagielski, Vikash Sehwag, Florian Tramèr, Borja Balle, Daphne Ippolito, Eric Wallace
Image diffusion models such as DALL-E 2, Imagen, and Stable Diffusion have attracted significant attention due to their ability to generate high-quality synthetic images. In this work, we show that diffusion models memorize individual images from their training data and emit them at generation time. With a generate-and-filter pipeline, we extract over a thousand training examples from state-of-the-art models, ranging from photographs of individual people to trademarked company logos. We also train hundreds of diffusion models in various settings to analyze how different modeling and data decisions affect privacy. Overall, our results show that diffusion models are much less private than prior generative models such as GANs, and that mitigating these vulnerabilities may require new advances in privacy-preserving training.
A Comprehensive Survey of AI-Generated Content (AIGC): A History of Generative AI from GAN to ChatGPT
https://arxiv.org/abs/2303.04226
Recently, ChatGPT, along with DALL-E-2 and Codex,has been gaining significant attention from society. As a result, many individuals have become interested in related resources and are seeking to uncover the background and secrets behind its impressive performance. In fact, ChatGPT and other Generative AI (GAI) techniques belong to the category of Artificial Intelligence Generated Content (AIGC), which involves the creation of digital content, such as images, music, and natural language, through AI models. The goal of AIGC is to make the content creation process more efficient and accessible, allowing for the production of high-quality content at a faster pace. AIGC is achieved by extracting and understanding intent information from instructions provided by human, and generating the content according to its knowledge and the intent information. In recent years, large-scale models have become increasingly important in AIGC as they provide better intent extraction and thus, improved generation results. With the growth of data and the size of the models, the distribution that the model can learn becomes more comprehensive and closer to reality, leading to more realistic and high-quality content generation. This survey provides a comprehensive review on the history of generative models, and basic components, recent advances in AIGC from unimodal interaction and multimodal interaction. From the perspective of unimodality, we introduce the generation tasks and relative models of text and image. From the perspective of multimodality, we introduce the cross-application between the modalities mentioned above. Finally, we discuss the existing open problems and future challenges in AIGC.
More Readings:
Audio Deepfake Detection: A Survey
https://arxiv.org/abs/2308.14970
Audio deepfake detection is an emerging active topic. A growing number of literatures have aimed to study deepfake detection algorithms and achieved effective performance, the problem of which is far from being solved. Although there are some review literatures, there has been no comprehensive survey that provides researchers with a systematic overview of these developments with a unified evaluation. Accordingly, in this survey paper, we first highlight the key differences across various types of deepfake audio, then outline and analyse competitions, datasets, features, classifications, and evaluation of state-of-the-art approaches. For each aspect, the basic techniques, advanced developments and major challenges are discussed. In addition, we perform a unified comparison of representative features and classifiers on ASVspoof 2021, ADD 2023 and In-the-Wild datasets for audio deepfake detection, respectively. The survey shows that future research should address the lack of large scale datasets in the wild, poor generalization of existing detection methods to unknown fake attacks, as well as interpretability of detection results.
Copyright Plug-in Market for The Text-to-Image Copyright Protection
https://openreview.net/forum?id=pSf8rrn49H
The images generated by text-to-image models could be accused of the copyright infringement, which has aroused heated debate among AI developers, content creators, legislation department and judicature department. Especially, the state-of-the-art text-to-image models are capable of generating extremely high-quality works while at the same time lack the ability to attribute credits to the original creators, which brings anxiety to the artists’ community. In this paper, we propose a conceptual framework – copyright Plug-in Market – to address the tension between the users, the content creators and the generative models. We introduce three operations in the \copyright Plug-in Market: addition, extraction and combination to facilitate proper credit attribution in the text-to-image procedure and enable the digital copyright protection. For the addition operation, we train a \copyright plug-in for a specific copyrighted concept and add it to the generative model and then we are able to generate new images with the copyrighted concept, which abstract existing solutions of portable LoRAs. We further introduce the extraction operation to enable content creators to claim copyrighted concept from infringing generative models and the combination operation to enable users to combine different \copyright plug-ins to generate images with multiple copyrighted concepts. We believe these basic operations give good incentives to each participant in the market, and enable enough flexibility to thrive the market. Technically, we innovate an inverse LoRA’’ approach to instantiate the extraction operation and propose a data-ignorant layer-wise distillation’’ approach to combine the multiple extractions or additions easily. To showcase the diverse capabilities of copyright plug-ins, we conducted experiments in two domains: style transfer and cartoon IP recreation. The results demonstrate that copyright plug-ins can effectively accomplish copyright extraction and combination, providing a valuable copyright protection solution for the era of generative AIs.
Membership Inference Attacks against Language Models via Neighbourhood Comparison
Are Large Pre-Trained Language Models Leaking Your Personal Information?
https://arxiv.org/abs/2205.12628
Jie Huang, Hanyin Shao, Kevin Chen-Chuan Chang
Are Large Pre-Trained Language Models Leaking Your Personal Information? In this paper, we analyze whether Pre-Trained Language Models (PLMs) are prone to leaking personal information. Specifically, we query PLMs for email addresses with contexts of the email address or prompts containing the owner’s name. We find that PLMs do leak personal information due to memorization. However, since the models are weak at association, the risk of specific personal information being extracted by attackers is low. We hope this work could help the community to better understand the privacy risk of PLMs and bring new insights to make PLMs safe.
We find the text embeddings from general-purpose language models would capture much sensitive information from the plain text. Once being accessed by the adversary, the embeddings can be reverse-engineered to disclose sensitive information of the victims for further harassment. Although such a privacy risk can impose a real threat to the future leverage of these promising NLP tools, there are neither published attacks nor systematic evaluations by far for the mainstream industry-level language models. To bridge this gap, we present the first systematic study on the privacy risks of 8 state-of-the-art language models with 4 diverse case studies. By constructing 2 novel attack classes, our study demonstrates the aforementioned privacy risks do exist and can impose practical threats to the application of general-purpose language models on sensitive data covering identity, genome, healthcare and location. For example, we show the adversary with nearly no prior knowledge can achieve about 75% accuracy when inferring the precise disease site from Bert embeddings of patients’ medical descriptions. As possible countermeasures, we propose 4 different defenses (via rounding, different…
More Readings:
Privacy in Large Language Models: Attacks, Defenses and Future Directions
https://arxiv.org/abs/2310.10383
The advancement of large language models (LLMs) has significantly enhanced the ability to effectively tackle various downstream NLP tasks and unify these tasks into generative pipelines. On the one hand, powerful language models, trained on massive textual data, have brought unparalleled accessibility and usability for both models and users. On the other hand, unrestricted access to these models can also introduce potential malicious and unintentional privacy risks. Despite ongoing efforts to address the safety and privacy concerns associated with LLMs, the problem remains unresolved. In this paper, we provide a comprehensive analysis of the current privacy attacks targeting LLMs and categorize them according to the adversary’s assumed capabilities to shed light on the potential vulnerabilities present in LLMs. Then, we present a detailed overview of prominent defense strategies that have been developed to counter these privacy attacks. Beyond existing works, we identify upcoming privacy concerns as LLMs evolve. Lastly, we point out several potential avenues for future exploration.
ProPILE: Probing Privacy Leakage in Large Language Models
https://arxiv.org/abs/2307.01881
Siwon Kim, Sangdoo Yun, Hwaran Lee, Martin Gubri, Sungroh Yoon, Seong Joon Oh
The rapid advancement and widespread use of large language models (LLMs) have raised significant concerns regarding the potential leakage of personally identifiable information (PII). These models are often trained on vast quantities of web-collected data, which may inadvertently include sensitive personal data. This paper presents ProPILE, a novel probing tool designed to empower data subjects, or the owners of the PII, with awareness of potential PII leakage in LLM-based services. ProPILE lets data subjects formulate prompts based on their own PII to evaluate the level of privacy intrusion in LLMs. We demonstrate its application on the OPT-1.3B model trained on the publicly available Pile dataset. We show how hypothetical data subjects may assess the likelihood of their PII being included in the Pile dataset being revealed. ProPILE can also be leveraged by LLM service providers to effectively evaluate their own levels of PII leakage with more powerful prompts specifically tuned for their in-house models. This tool represents a pioneering step towards empowering the data subjects for their awareness and control over their own data on the web.
Please click each post's URL shown below to check out its full contents.
Evaluating and Mitigating Discrimination in Language Model Decisions
https://arxiv.org/abs/2312.03689
As language models (LMs) advance, interest is growing in applying them to high-stakes societal decisions, such as determining financing or housing eligibility. However, their potential for discrimination in such contexts raises ethical concerns, motivating the need for better methods to evaluate these risks. We present a method for proactively evaluating the potential discriminatory impact of LMs in a wide range of use cases, including hypothetical use cases where they have not yet been deployed. Specifically, we use an LM to generate a wide array of potential prompts that decision-makers may input into an LM, spanning 70 diverse decision scenarios across society, and systematically vary the demographic information in each prompt. Applying this methodology reveals patterns of both positive and negative discrimination in the Claude 2.0 model in select settings when no interventions are applied. While we do not endorse or permit the use of language models to make automated decisions for the high-risk use cases we study, we demonstrate techniques to significantly decrease both positive and negative discrimination through careful prompt engineering, providing pathways toward safer deployment in use cases where they may be appropriate. Our work enables developers and policymakers to anticipate, measure, and address discrimination as language model capabilities and applications continue to expand. We release our dataset and prompts at this https URL
More Readings:
Learning from Red Teaming: Gender Bias Provocation and Mitigation in Large Language Models
https://arxiv.org/abs/2310.11079
Machine Learning in development: Let’s talk about bias!
https://huggingface.co/blog/ethics-soc-2
https://huggingface.co/blog/evaluating-llm-bias
Exploring Social Bias in Chatbots using Stereotype Knowledge WNLP@ACL2019
Bias and Fairness in Large Language Models: A Survey
https://arxiv.org/abs/2309.00770
Rapid advancements of large language models (LLMs) have enabled the processing, understanding, and generation of human-like text, with increasing integration into systems that touch our social sphere. Despite this success, these models can learn, perpetuate, and amplify harmful social biases. In this paper, we present a comprehensive survey of bias evaluation and mitigation techniques for LLMs. We first consolidate, formalize, and expand notions of social bias and fairness in natural language processing, defining distinct facets of harm and introducing several desiderata to operationalize fairness for LLMs. We then unify the literature by proposing three intuitive taxonomies, two for bias evaluation, namely metrics and datasets, and one for mitigation. Our first taxonomy of metrics for bias evaluation disambiguates the relationship between metrics and evaluation datasets, and organizes metrics by the different levels at which they operate in a model: embeddings, probabilities, and generated text. Our second taxonomy of datasets for bias evaluation categorizes datasets by their structure as counterfactual inputs or prompts, and identifies the targeted harms and social groups; we also release a consolidation of publicly-available datasets for improved access. Our third taxonomy of techniques for bias mitigation classifies methods by their intervention during pre-processing, in-training, intra-processing, and post-processing, with granular subcategories that elucidate research trends. Finally, we identify open problems and challenges for future work. Synthesizing a wide range of recent research, we aim to provide a clear guide of the existing literature that empowers researchers and practitioners to better understand and prevent the propagation of bias in LLMs.
A Survey on Fairness in Large Language Models
https://arxiv.org/abs/2308.10149
Large language models (LLMs) have shown powerful performance and development prospect and are widely deployed in the real world. However, LLMs can capture social biases from unprocessed training data and propagate the biases to downstream tasks. Unfair LLM systems have undesirable social impacts and potential harms. In this paper, we provide a comprehensive review of related research on fairness in LLMs. First, for medium-scale LLMs, we introduce evaluation metrics and debiasing methods from the perspectives of intrinsic bias and extrinsic bias, respectively. Then, for large-scale LLMs, we introduce recent fairness research, including fairness evaluation, reasons for bias, and debiasing methods. Finally, we discuss and provide insight on the challenges and future directions for the development of fairness in LLMs.
Please click each post's URL shown below to check out its full contents.
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
https://arxiv.org/abs/2402.04249
Automated red teaming holds substantial promise for uncovering and mitigating the risks associated with the malicious use of large language models (LLMs), yet the field lacks a standardized evaluation framework to rigorously assess new methods. To address this issue, we introduce HarmBench, a standardized evaluation framework for automated red teaming. We identify several desirable properties previously unaccounted for in red teaming evaluations and systematically design HarmBench to meet these criteria. Using HarmBench, we conduct a large-scale comparison of 18 red teaming methods and 33 target LLMs and defenses, yielding novel insights. We also introduce a highly efficient adversarial training method that greatly enhances LLM robustness across a wide range of attacks, demonstrating how HarmBench enables codevelopment of attacks and defenses. We open source HarmBench at this https URL.
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
Humans are capable of strategically deceptive behavior: behaving helpfully in most situations, but then behaving very differently in order to pursue alternative objectives when given the opportunity. If an AI system learned such a deceptive strategy, could we detect it and remove it using current state-of-the-art safety training techniques? To study this question, we construct proof-of-concept examples of deceptive behavior in large language models (LLMs). For example, we train models that write secure code when the prompt states that the year is 2023, but insert exploitable code when the stated year is 2024. We find that such backdoor behavior can be made persistent, so that it is not removed by standard safety training techniques, including supervised fine-tuning, reinforcement learning, and adversarial training (eliciting unsafe behavior and then training to remove it). The backdoor behavior is most persistent in the largest models and in models trained to produce chain-of-thought reasoning about deceiving the training process, with the persistence remaining even when the chain-of-thought is distilled away. Furthermore, rather than removing backdoors, we find that adversarial training can teach models to better recognize their backdoor triggers, effectively hiding the unsafe behavior. Our results suggest that, once a model exhibits deceptive behavior, standard techniques could fail to remove such deception and create a false impression of safety.
More Readings:
SafeText: A Benchmark for Exploring Physical Safety in Language Models
https://arxiv.org/abs/2210.10045
Understanding what constitutes safe text is an important issue in natural language processing and can often prevent the deployment of models deemed harmful and unsafe. One such type of safety that has been scarcely studied is commonsense physical safety, i.e. text that is not explicitly violent and requires additional commonsense knowledge to comprehend that it leads to physical harm. We create the first benchmark dataset, SafeText, comprising real-life scenarios with paired safe and physically unsafe pieces of advice. We utilize SafeText to empirically study commonsense physical safety across various models designed for text generation and commonsense reasoning tasks. We find that state-of-the-art large language models are susceptible to the generation of unsafe text and have difficulty rejecting unsafe advice. As a result, we argue for further studies of safety and the assessment of commonsense physical safety in models before release.
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!
https://arxiv.org/abs/2310.03693
Lessons learned on language model safety and misuse
Cheating Suffix: Targeted Attack to Text-To-Image Diffusion Models with Multi-Modal Priors
Dingcheng Yang, Yang Bai, Xiaojun Jia, Yang Liu, Xiaochun Cao, Wenjian Yu
Diffusion models have been widely deployed in various image generation tasks, demonstrating an extraordinary connection between image and text modalities. However, they face challenges of being maliciously exploited to generate harmful or sensitive images by appending a specific suffix to the original prompt. Existing works mainly focus on using single-modal information to conduct attacks, which fails to utilize multi-modal features and results in less than satisfactory performance. Integrating multi-modal priors (MMP), i.e. both text and image features, we propose a targeted attack method named MMP-Attack in this work. Specifically, the goal of MMP-Attack is to add a target object into the image content while simultaneously removing the original object. The MMP-Attack shows a notable advantage over existing works with superior universality and transferability, which can effectively attack commercial text-to-image (T2I) models such as DALL-E 3. To the best of our knowledge, this marks the first successful attempt of transfer-based attack to commercial T2I models. Our code is publicly available at ….
A Pilot Study of Query-Free Adversarial Attack against Stable Diffusion
https://ieeexplore.ieee.org/document/10208563
Despite the record-breaking performance in Text-to-Image (T2I) generation by Stable Diffusion, less research attention is paid to its adversarial robustness. In this work, we study the problem of adversarial attack generation for Stable Diffusion and ask if an adversarial text prompt can be obtained even in the absence of end-to-end model queries. We call the resulting problem ‘query-free attack generation’. To resolve this problem, we show that the vulnerability of T2I models is rooted in the lack of robustness of text encoders, e.g., the CLIP text encoder used for attacking Stable Diffusion. Based on such insight, we propose both untargeted and targeted query-free attacks, where the former is built on the most influential dimensions in the text embedding space, which we call steerable key dimensions. By leveraging the proposed attacks, we empirically show that only a five-character perturbation to the text prompt is able to cause the significant content shift of synthesized images using Stable Diffusion. Moreover, we show that the proposed target attack can precisely steer the diffusion model to scrub the targeted image content without causing much change in untargeted image content.
More Readings:
Visual Instruction Tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, Yong Jae Lee
Instruction tuning large language models (LLMs) using machine-generated instruction-following data has improved zero-shot capabilities on new tasks, but the idea is less explored in the multimodal field. In this paper, we present the first attempt to use language-only GPT-4 to generate multimodal language-image instruction-following data. By instruction tuning on such generated data, we introduce LLaVA: Large Language and Vision Assistant, an end-to-end trained large multimodal model that connects a vision encoder and LLM for general-purpose visual and language understanding.Our early experiments show that LLaVA demonstrates impressive multimodel chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 85.1% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. When fine-tuned on Science QA, the synergy of LLaVA and GPT-4 achieves a new state-of-the-art accuracy of 92.53%. We make GPT-4 generated visual instruction tuning data, our model and code base publicly available.
GOAT-Bench: Safety Insights to Large Multimodal Models through Meme-Based Social Abuse
https://arxiv.org/abs/2401.01523
Misusing Tools in Large Language Models With Visual Adversarial Examples
https://arxiv.org/abs/2310.03185
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
https://arxiv.org/abs/2209.07858
Please click each post's URL shown below to check out its full contents.
On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?
https://dl.acm.org/doi/10.1145/3442188.3445922
The past 3 years of work in NLP have been characterized by the development and deployment of ever larger language models, especially for English. BERT, its variants, GPT-2/3, and others, most recently Switch-C, have pushed the boundaries of the possible both through architectural innovations and through sheer size. Using these pretrained models and the methodology of fine-tuning them for specific tasks, researchers have extended the state of the art on a wide array of tasks as measured by leaderboards on specific benchmarks for English. In this paper, we take a step back and ask: How big is too big? What are the possible risks associated with this technology and what paths are available for mitigating those risks? We provide recommendations including weighing the environmental and financial costs first, investing resources into curating and carefully documenting datasets rather than ingesting everything on the web, carrying out pre-development exercises evaluating how the planned approach fits into research and development goals and supports stakeholder values, and encouraging research directions beyond ever larger language models.
More Readings:
Low-Resource Languages Jailbreak GPT-4
AI safety training and red-teaming of large language models (LLMs) are measures to mitigate the generation of unsafe content. Our work exposes the inherent cross-lingual vulnerability of these safety mechanisms, resulting from the linguistic inequality of safety training data, by successfully circumventing GPT-4’s safeguard through translating unsafe English inputs into low-resource languages. On the AdvBenchmark, GPT-4 engages with the unsafe translated inputs and provides actionable items that can get the users towards their harmful goals 79% of the time, which is on par with or even surpassing state-of-the-art jailbreaking attacks. Other high-/mid-resource languages have significantly lower attack success rate, which suggests that the cross-lingual vulnerability mainly applies to low-resource languages. Previously, limited training on low-resource languages primarily affects speakers of those languages, causing technological disparities. However, our work highlights a crucial shift: this deficiency now poses a risk to all LLMs users. Publicly available translation APIs enable anyone to exploit LLMs’ safety vulnerabilities. Therefore, our work calls for a more holistic red-teaming efforts to develop robust multilingual safeguards with wide language coverage.
A Survey of Safety and Trustworthiness of Large Language Models through the Lens of Verification and Validation
https://arxiv.org/abs/2305.11391
Large Language Models (LLMs) have exploded a new heatwave of AI for their ability to engage end-users in human-level conversations with detailed and articulate answers across many knowledge domains. In response to their fast adoption in many industrial applications, this survey concerns their safety and trustworthiness. First, we review known vulnerabilities and limitations of the LLMs, categorising them into inherent issues, attacks, and unintended bugs. Then, we consider if and how the Verification and Validation (V&V) techniques, which have been widely developed for traditional software and deep learning models such as convolutional neural networks as independent processes to check the alignment of their implementations against the specifications, can be integrated and further extended throughout the lifecycle of the LLMs to provide rigorous analysis to the safety and trustworthiness of LLMs and their applications. Specifically, we consider four complementary techniques: falsification and evaluation, verification, runtime monitoring, and regulations and ethical use. In total, 370+ references are considered to support the quick understanding of the safety and trustworthiness issues from the perspective of V&V. While intensive research has been conducted to identify the safety and trustworthiness issues, rigorous yet practical methods are called for to ensure the alignment of LLMs with safety and trustworthiness requirements.
Even More
ToxicChat: Unveiling Hidden Challenges of Toxicity Detection in Real-World User-AI Conversation / EMNLP2023
Despite remarkable advances that large language models have achieved in chatbots nowadays, maintaining a non-toxic user-AI interactive environment has become increasingly critical nowadays. However, previous efforts in toxicity detection have been mostly based on benchmarks derived from social media contents, leaving the unique challenges inherent to real-world user-AI interactions insufficiently explored. In this work, we introduce ToxicChat, a novel benchmark constructed based on real user queries from an open-source chatbot. This benchmark contains the rich, nuanced phenomena that can be tricky for current toxicity detection models to identify, revealing a significant domain difference when compared to social media contents. Our systematic evaluation of models trained on existing toxicity datasets has shown their shortcomings when applied to this unique domain of ToxicChat. Our work illuminates the potentially overlooked challenges of toxicity detection in real-world user-AI conversations. In the future, ToxicChat can be a valuable resource to drive further advancements toward building a safe and healthy environment for user-AI interactions.
OpenAI on LLM generated bio-x-risk
Building an early warning system for LLM-aided biological threat creation
Retrieval-Augmented Generation for AI-Generated Content: A Survey
https://arxiv.org/abs/2402.19473v1
The development of Artificial Intelligence Generated Content (AIGC) has been facilitated by advancements in model algorithms, scalable foundation model architectures, and the availability of ample high-quality datasets. While AIGC has achieved remarkable performance, it still faces challenges, such as the difficulty of maintaining up-to-date and long-tail knowledge, the risk of data leakage, and the high costs associated with training and inference. Retrieval-Augmented Generation (RAG) has recently emerged as a paradigm to address such challenges. In particular, RAG introduces the information retrieval process, which enhances AIGC results by retrieving relevant objects from available data stores, leading to greater accuracy and robustness. In this paper, we comprehensively review existing efforts that integrate RAG technique into AIGC scenarios. We first classify RAG foundations according to how the retriever augments the generator. We distill the fundamental abstractions of the augmentation methodologies for various retrievers and generators. This unified perspective encompasses all RAG scenarios, illuminating advancements and pivotal technologies that help with potential future progress. We also summarize additional enhancements methods for RAG, facilitating effective engineering and implementation of RAG systems. Then from another view, we survey on practical applications of RAG across different modalities and tasks, offering valuable references for researchers and practitioners. Furthermore, we introduce the benchmarks for RAG, discuss the limitations of current RAG systems, and suggest potential directions for future research. Project: this https URL
Retrieval-Augmented Generation for Large Language Models: A Survey
https://arxiv.org/abs/2312.10997
Large language models (LLMs) demonstrate powerful capabilities, but they still face challenges in practical applications, such as hallucinations, slow knowledge updates, and lack of transparency in answers. Retrieval-Augmented Generation (RAG) refers to the retrieval of relevant information from external knowledge bases before answering questions with LLMs. RAG has been demonstrated to significantly enhance answer accuracy, reduce model hallucination, particularly for knowledge-intensive tasks. By citing sources, users can verify the accuracy of answers and increase trust in model outputs. It also facilitates knowledge updates and the introduction of domain-specific knowledge. RAG effectively combines the parameterized knowledge of LLMs with non-parameterized external knowledge bases, making it one of the most important methods for implementing large language models. This paper outlines the development paradigms of RAG in the era of LLMs, summarizing three paradigms: Naive RAG, Advanced RAG, and Modular RAG. It then provides a summary and organization of the three main components of RAG: retriever, generator, and augmentation methods, along with key technologies in each component. Furthermore, it discusses how to evaluate the effectiveness of RAG models, introducing two evaluation methods for RAG, emphasizing key metrics and abilities for evaluation, and presenting the latest automatic evaluation framework. Finally, potential future research directions are introduced from three aspects: vertical optimization, horizontal scalability, and the technical stack and ecosystem of RAG.
More Readings:
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Sora is a text-to-video generative AI model, released by OpenAI in February 2024. The model is trained to generate videos of realistic or imaginative scenes from text instructions and show potential in simulating the physical world. Based on public technical reports and reverse engineering, this paper presents a comprehensive review of the model’s background, related technologies, applications, remaining challenges, and future directions of text-to-video AI models. We first trace Sora’s development and investigate the underlying technologies used to build this “world simulator”. Then, we describe in detail the applications and potential impact of Sora in multiple industries ranging from film-making and education to marketing. We discuss the main challenges and limitations that need to be addressed to widely deploy Sora, such as ensuring safe and unbiased video generation. Lastly, we discuss the future development of Sora and video generation models in general, and how advancements in the field could enable new ways of human-AI interaction, boosting productivity and creativity of video generation.
A Comprehensive Study of Knowledge Editing for Large Language Models
https://arxiv.org/abs/2401.01286
Large Language Models (LLMs) have shown extraordinary capabilities in understanding and generating text that closely mirrors human communication. However, a primary limitation lies in the significant computational demands during training, arising from their extensive parameterization. This challenge is further intensified by the dynamic nature of the world, necessitating frequent updates to LLMs to correct outdated information or integrate new knowledge, thereby ensuring their continued relevance. Note that many applications demand continual model adjustments post-training to address deficiencies or undesirable behaviors. There is an increasing interest in efficient, lightweight methods for on-the-fly model modifications. To this end, recent years have seen a burgeoning in the techniques of knowledge editing for LLMs, which aim to efficiently modify LLMs’ behaviors within specific domains while preserving overall performance across various inputs. In this paper, we first define the knowledge editing problem and then provide a comprehensive review of cutting-edge approaches. Drawing inspiration from educational and cognitive research theories, we propose a unified categorization criterion that classifies knowledge editing methods into three groups: resorting to external knowledge, merging knowledge into the model, and editing intrinsic knowledge. Furthermore, we introduce a new benchmark, KnowEdit, for a comprehensive empirical evaluation of representative knowledge editing approaches. Additionally, we provide an in-depth analysis of knowledge location, which can give a deeper understanding of the knowledge structures inherent within LLMs. Finally, we discuss several potential applications of knowledge editing, outlining its broad and impactful implications.
Even More
A Survey of Table Reasoning with Large Language Models
Xuanliang Zhang, Dingzirui Wang, Longxu Dou, Qingfu Zhu, Wanxiang Che
https://arxiv.org/abs/2402.08259
Table reasoning, which aims to generate the corresponding answer to the question following the user requirement according to the provided table, and optionally a text description of the table, effectively improving the efficiency of obtaining information. Recently, using Large Language Models (LLMs) has become the mainstream method for table reasoning, because it not only significantly reduces the annotation cost but also exceeds the performance of previous methods. However, existing research still lacks a summary of LLM-based table reasoning works. Due to the existing lack of research, questions about which techniques can improve table reasoning performance in the era of LLMs, why LLMs excel at table reasoning, and how to enhance table reasoning abilities in the future, remain largely unexplored. This gap significantly limits progress in research. To answer the above questions and advance table reasoning research with LLMs, we present this survey to analyze existing research, inspiring future work. In this paper, we analyze the mainstream techniques used to improve table reasoning performance in the LLM era, and the advantages of LLMs compared to pre-LLMs for solving table reasoning. We provide research directions from both the improvement of existing methods and the expansion of practical applications to inspire future research.
Please click each post's URL shown below to check out its full contents.
A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions
https://arxiv.org/abs/2311.05232
The emergence of large language models (LLMs) has marked a significant breakthrough in natural language processing (NLP), leading to remarkable advancements in text understanding and generation. Nevertheless, alongside these strides, LLMs exhibit a critical tendency to produce hallucinations, resulting in content that is inconsistent with real-world facts or user inputs. This phenomenon poses substantial challenges to their practical deployment and raises concerns over the reliability of LLMs in real-world scenarios, which attracts increasing attention to detect and mitigate these hallucinations. In this survey, we aim to provide a thorough and in-depth overview of recent advances in the field of LLM hallucinations. We begin with an innovative taxonomy of LLM hallucinations, then delve into the factors contributing to hallucinations. Subsequently, we present a comprehensive overview of hallucination detection methods and benchmarks. Additionally, representative approaches designed to mitigate hallucinations are introduced accordingly. Finally, we analyze the challenges that highlight the current limitations and formulate open questions, aiming to delineate pathways for future research on hallucinations in LLMs.
More Readings:
LLMs as Factual Reasoners: Insights from Existing Benchmarks and Beyond
https://arxiv.org/abs/2305.14540
With the recent appearance of LLMs in practical settings, having methods that can effectively detect factual inconsistencies is crucial to reduce the propagation of misinformation and improve trust in model outputs. When testing on existing factual consistency benchmarks, we find that a few large language models (LLMs) perform competitively on classification benchmarks for factual inconsistency detection compared to traditional non-LLM methods. However, a closer analysis reveals that most LLMs fail on more complex formulations of the task and exposes issues with existing evaluation benchmarks, affecting evaluation precision. To address this, we propose a new protocol for inconsistency detection benchmark creation and implement it in a 10-domain benchmark called SummEdits. This new benchmark is 20 times more cost-effective per sample than previous benchmarks and highly reproducible, as we estimate inter-annotator agreement at about 0.9. Most LLMs struggle on SummEdits, with performance close to random chance. The best-performing model, GPT-4, is still 8\% below estimated human performance, highlighting the gaps in LLMs’ ability to reason about facts and detect inconsistencies when they occur.
Survey of Hallucination in Natural Language Generation
https://arxiv.org/abs/2202.03629
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Yejin Bang, Delong Chen, Ho Shu Chan, Wenliang Dai, Andrea Madotto, Pascale Fung
Natural Language Generation (NLG) has improved exponentially in recent years thanks to the development of sequence-to-sequence deep learning technologies such as Transformer-based language models. This advancement has led to more fluent and coherent NLG, leading to improved development in downstream tasks such as abstractive summarization, dialogue generation and data-to-text generation. However, it is also apparent that deep learning based generation is prone to hallucinate unintended text, which degrades the system performance and fails to meet user expectations in many real-world scenarios. To address this issue, many studies have been presented in measuring and mitigating hallucinated texts, but these have never been reviewed in a comprehensive manner before. In this survey, we thus provide a broad overview of the research progress and challenges in the hallucination problem in NLG. The survey is organized into two parts: (1) a general overview of metrics, mitigation methods, and future directions; (2) an overview of task-specific research progress on hallucinations in the following downstream tasks, namely abstractive summarization, dialogue generation, generative question answering, data-to-text generation, machine translation, and visual-language generation; and (3) hallucinations in large language models (LLMs). This survey serves to facilitate collaborative efforts among researchers in tackling the challenge of hallucinated texts in NLG.
Do Language Models Know When They’re Hallucinating References?
https://arxiv.org/abs/2305.18248
Trustworthy LLMs: a Survey and Guideline for Evaluating Large Language Models’ Alignment
https://arxiv.org/abs/2308.05374
Please click each post's URL shown below to check out its full contents.
Large Language Models for Software Engineering: A Systematic Literature Review
Large Language Models (LLMs) have significantly impacted numerous domains, including Software Engineering (SE). Many recent publications have explored LLMs applied to various SE tasks. Nevertheless, a comprehensive understanding of the application, effects, and possible limitations of LLMs on SE is still in its early stages. To bridge this gap, we conducted a systematic literature review on LLM4SE, with a particular focus on understanding how LLMs can be exploited to optimize processes and outcomes. We collect and analyze 229 research papers from 2017 to 2023 to answer four key research questions (RQs). In RQ1, we categorize different LLMs that have been employed in SE tasks, characterizing their distinctive features and uses. In RQ2, we analyze the methods used in data collection, preprocessing, and application highlighting the role of well-curated datasets for successful LLM for SE implementation. RQ3 investigates the strategies employed to optimize and evaluate the performance of LLMs in SE. Finally, RQ4 examines the specific SE tasks where LLMs have shown success to date, illustrating their practical contributions to the field. From the answers to these RQs, we discuss the current state-of-the-art and trends, identifying gaps in existing research, and flagging promising areas for future study.
More Readings:
Large language models generate functional protein sequences across diverse families
https://pubmed.ncbi.nlm.nih.gov/36702895/
Deep-learning language models have shown promise in various biotechnological applications, including protein design and engineering. Here we describe ProGen, a language model that can generate protein sequences with a predictable function across large protein families, akin to generating grammatically and semantically correct natural language sentences on diverse topics. The model was trained on 280 million protein sequences from >19,000 families and is augmented with control tags specifying protein properties. ProGen can be further fine-tuned to curated sequences and tags to improve controllable generation performance of proteins from families with sufficient homologous samples. Artificial proteins fine-tuned to five distinct lysozyme families showed similar catalytic efficiencies as natural lysozymes, with sequence identity to natural proteins as low as 31.4%. ProGen is readily adapted to diverse protein families, as we demonstrate with chorismate mutase and malate dehydrogenase.
Large Language Models in Law: A Survey
https://arxiv.org/abs/2312.03718
The advent of artificial intelligence (AI) has significantly impacted the traditional judicial industry. Moreover, recently, with the development of AI-generated content (AIGC), AI and law have found applications in various domains, including image recognition, automatic text generation, and interactive chat. With the rapid emergence and growing popularity of large models, it is evident that AI will drive transformation in the traditional judicial industry. However, the application of legal large language models (LLMs) is still in its nascent stage. Several challenges need to be addressed. In this paper, we aim to provide a comprehensive survey of legal LLMs. We not only conduct an extensive survey of LLMs, but also expose their applications in the judicial system. We first provide an overview of AI technologies in the legal field and showcase the recent research in LLMs. Then, we discuss the practical implementation presented by legal LLMs, such as providing legal advice to users and assisting judges during trials. In addition, we explore the limitations of legal LLMs, including data, algorithms, and judicial practice. Finally, we summarize practical recommendations and propose future development directions to address these challenges.
ChemLLM: A Chemical Large Language Model
https://arxiv.org/abs/2402.06852
Large language models (LLMs) have made impressive progress in chemistry applications, including molecular property prediction, molecular generation, experimental protocol design, etc. However, the community lacks a dialogue-based model specifically designed for chemistry. The challenge arises from the fact that most chemical data and scientific knowledge are primarily stored in structured databases, and the direct use of these structured data compromises the model’s ability to maintain coherent dialogue. To tackle this issue, we develop a novel template-based instruction construction method that transforms structured knowledge into plain dialogue, making it suitable for language model traini…
FunSearch: Making new discoveries in mathematical sciences using Large Language Models
We introduce the Segment Anything (SA) project: a new task, model, and dataset for image segmentation. Using our efficient model in a data collection loop, we built the largest segmentation dataset to date (by far), with over 1 billion masks on 11M licensed and privacy respecting images. The model is designed and trained to be promptable, so it can transfer zero-shot to new image distributions and tasks. We evaluate its capabilities on numerous tasks and find that its zero-shot performance is impressive – often competitive with or even superior to prior fully supervised results. We are releasing the Segment Anything Model (SAM) and corresponding dataset (SA-1B) of 1B masks and 11M images at this https URL to foster research into foundation models for computer vision.
EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions
In this work, we tackle the challenge of enhancing the realism and expressiveness in talking head video generation by focusing on the dynamic and nuanced relationship between audio cues and facial movements. We identify the limitations of traditional techniques that often fail to capture the full spectrum of human expressions and the uniqueness of individual facial styles. To address these issues, we propose EMO, a novel framework that utilizes a direct audio-to-video synthesis approach, bypassing the need for intermediate 3D models or facial landmarks. Our method ensures seamless frame transitions and consistent identity preservation throughout the video, resulting in highly expressive and lifelike animations. Experimental results demonsrate that EMO is able to produce not only convincing speaking videos but also singing videos in various styles, significantly outperforming existing state-of-the-art methodologies in terms of expressiveness and realism.
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Sora is a text-to-video generative AI model, released by OpenAI in February 2024. The model is trained to generate videos of realistic or imaginative scenes from text instructions and show potential in simulating the physical world. Based on public technical reports and reverse engineering, this paper presents a comprehensive review of the model’s background, related technologies, applications, remaining challenges, and future directions of text-to-video AI models. We first trace Sora’s development and investigate the underlying technologies used to build this “world simulator”. Then, we describe in detail the applications and potential impact of Sora in multiple industries ranging from film-making and education to marketing. We discuss the main challenges and limitations that need to be addressed to widely deploy Sora, such as ensuring safe and unbiased video generation. Lastly, we discuss the future development of Sora and video generation models in general, and how advancements in the field could enable new ways of human-AI interaction, boosting productivity and creativity of video generation.
BloombergGPT: A Large Language Model for Finance
https://arxiv.org/abs/2303.17564
The use of NLP in the realm of financial technology is broad and complex, with applications ranging from sentiment analysis and named entity recognition to question answering. Large Language Models (LLMs) have been shown to be effective on a variety of tasks; however, no LLM specialized for the financial domain has been reported in literature. In this work, we present BloombergGPT, a 50 billion parameter language model that is trained on a wide range of financial data. We construct a 363 billion token dataset based on Bloomberg’s extensive data sources, perhaps the largest domain-specific dataset yet, augmented with 345 billion tokens from general purpose datasets. We validate BloombergGPT on standard LLM benchmarks, open financial benchmarks, and a suite of internal benchmarks that most accurately reflect our intended usage. Our mixed dataset training leads to a model that outperforms existing models on financial tasks by significant margins without sacrificing performance on general LLM benchmarks. Additionally, we explain our modeling choices, training process, and evaluation methodology. We release Training Chronicles (Appendix C) detailing our experience in training BloombergGPT.
Emu Video: Factorizing Text-to-Video Generation by Explicit Image Conditioning
https://arxiv.org/abs/2311.10709
We present Emu Video, a text-to-video generation model that factorizes the generation into two steps: first generating an image conditioned on the text, and then generating a video conditioned on the text and the generated image. We identify critical design decisions–adjusted noise schedules for diffusion, and multi-stage training–that enable us to directly generate high quality and high resolution videos, without requiring a deep cascade of models as in prior work. In human evaluations, our generated videos are strongly preferred in quality compared to all prior work–81% vs. Google’s Imagen Video, 90% vs. Nvidia’s PYOCO, and 96% vs. Meta’s Make-A-Video. Our model outperforms commercial solutions such as RunwayML’s Gen2 and Pika Labs. Finally, our factorizing approach naturally lends itself to animating images based on a user’s text prompt, where our generations are preferred 96% over prior work.
Please click each post's URL shown below to check out its full contents.
Editing Large Language Models: Problems, Methods, and Opportunities
https://arxiv.org/abs/2305.13172
Yunzhi Yao, Peng Wang, Bozhong Tian, Siyuan Cheng, Zhoubo Li, Shumin Deng, Huajun Chen, Ningyu Zhang
Despite the ability to train capable LLMs, the methodology for maintaining their relevancy and rectifying errors remains elusive. To this end, the past few years have witnessed a surge in techniques for editing LLMs, the objective of which is to efficiently alter the behavior of LLMs within a specific domain without negatively impacting performance across other inputs. This paper embarks on a deep exploration of the problems, methods, and opportunities related to model editing for LLMs. In particular, we provide an exhaustive overview of the task definition and challenges associated with model editing, along with an in-depth empirical analysis of the most progressive methods currently at our disposal. We also build a new benchmark dataset to facilitate a more robust evaluation and pinpoint enduring issues intrinsic to existing techniques. Our objective is to provide valuable insights into the effectiveness and feasibility of each editing technique, thereby assisting the community in making informed decisions on the selection of the most appropriate method for a specific task or context. Code and datasets are available at this https URL.
Comments: EMNLP 2023. Updated with new experiments
More Readings:
Tuning Language Models by Proxy
Alisa Liu, Xiaochuang Han, Yizhong Wang, Yulia Tsvetkov, Yejin Choi, Noah A. Smith
Submitted on 16 Jan 2024]
Despite the general capabilities of large pretrained language models, they consistently benefit from further adaptation to better achieve desired behaviors. However, tuning these models has become increasingly resource-intensive, or impossible when model weights are private. We introduce proxy-tuning, a lightweight decoding-time algorithm that operates on top of black-box LMs to achieve the result of directly tuning the model, but by accessing only its prediction over the output vocabulary. Our method instead tunes a smaller LM, then applies the difference between the predictions of the small tuned and untuned LMs to shift the original predictions of the base model in the direction of tuning, while retaining the benefits of larger scale pretraining. In experiments, when we apply proxy-tuning to Llama2-70B using proxies of only 7B size, we can close 88% of the gap between Llama2-70B and its truly-tuned chat version, when evaluated across knowledge, reasoning, and safety benchmarks. Interestingly, when tested on TruthfulQA, proxy-tuned models are actually more truthful than directly tuned models, possibly because decoding-time guidance better retains the model’s factual knowledge. We then demonstrate the generality of proxy-tuning by applying it for domain adaptation on code, and task-specific finetuning on question-answering and math problems. Our work demonstrates the promise of using small tuned LMs to efficiently customize large, potentially proprietary LMs through decoding-time guidance.
A Survey of Machine Unlearning
https://arxiv.org/abs/2209.02299
Today, computer systems hold large amounts of personal data. Yet while such an abundance of data allows breakthroughs in artificial intelligence, and especially machine learning (ML), its existence can be a threat to user privacy, and it can weaken the bonds of trust between humans and AI. Recent regulations now require that, on request, private information about a user must be removed from both computer systems and from ML models, i.e. ``the right to be forgotten’’). While removing data from back-end databases should be straightforward, it is not sufficient in the AI context as ML models often `remember’ the old data. Contemporary adversarial attacks on trained models have proven that we can learn whether an instance or an attribute belonged to the training data. This phenomenon calls for a new paradigm, namely machine unlearning, to make ML models forget about particular data. It turns out that recent works on machine unlearning have not been able to completely solve the problem due to the lack of common frameworks and resources. Therefore, this paper aspires to present a comprehensive examination of machine unlearning’s concepts, scenarios, methods, and applications. Specifically, as a category collection of cutting-edge studies, the intention behind this article is to serve as a comprehensive resource for researchers and practitioners seeking an introduction to machine unlearning and its formulations, design criteria, removal requests, algorithms, and applications. In addition, we aim to highlight the key findings, current trends, and new research areas that have not yet featured the use of machine unlearning but could benefit greatly from it. We hope this survey serves as a valuable resource for ML researchers and those seeking to innovate privacy technologies. Our resources are publicly available at this https URL.
AI Model Disgorgement: Methods and Choices
https://arxiv.org/abs/2304.03545
Alessandro Achille, Michael Kearns, Carson Klingenberg, Stefano Soatto
Responsible use of data is an indispensable part of any machine learning (ML) implementation. ML developers must carefully collect and curate their datasets, and document their provenance. They must also make sure to respect intellectual property rights, preserve individual privacy, and use data in an ethical way. Over the past few years, ML models have significantly increased in size and complexity. These models require a very large amount of data and compute capacity to train, to the extent that any defects in the training corpus cannot be trivially remedied by retraining the model from scratch. Despite sophisticated controls on training data and a significant amount of effort dedicated to ensuring that training corpora are properly composed, the sheer volume of data required for the models makes it challenging to manually inspect each datum comprising a training corpus. One potential fix for training corpus data defects is model disgorgement – the elimination of not just the improperly used data, but also the effects of improperly used data on any component of an ML model. Model disgorgement techniques can be used to address a wide range of issues, such as reducing bias or toxicity, increasing fidelity, and ensuring responsible usage of intellectual property. In this paper, we introduce a taxonomy of possible disgorgement methods that are applicable to modern ML systems. In particular, we investigate the meaning of “removing the effects” of data in the trained model in a way that does not require retraining from scratch.
Please click each post's URL shown below to check out its full contents.
Interpretable machine learning has exploded as an area of interest over the last decade, sparked by the rise of increasingly large datasets and deep neural networks. Simultaneously, large language models (LLMs) have demonstrated remarkable capabilities across a wide array of tasks, offering a chance to rethink opportunities in interpretable machine learning. Notably, the capability to explain in natural language allows LLMs to expand the scale and complexity of patterns that can be given to a human. However, these new capabilities raise new challenges, such as hallucinated explanations and immense computational costs. In this position paper, we start by reviewing existing methods to evaluate the emerging field of LLM interpretation (both interpreting LLMs and using LLMs for explanation). We contend that, despite their limitations, LLMs hold the opportunity to redefine interpretability with a more ambitious scope across many applications, including in auditing LLMs themselves. We highlight two emerging research priorities for LLM interpretation: using LLMs to directly analyze new datasets and to generate interactive explanations.
We introduce Claude 3, a new family of large multimodal models – Claude 3 Opus, our most capable offering, Claude 3 Sonnet, which provides a combination of skills and speed,
and Claude 3 Haiku, our fastest and least expensive model. All new models have vision
capabilities that enable them to process and analyze image data. The Claude 3 family
demonstrates strong performance across benchmark evaluations and sets a new standard on
measures of reasoning, math, and coding. Claude 3 Opus achieves state-of-the-art results
on evaluations like GPQA [1], MMLU [2], MMMU [3] and many more. Claude 3 Haiku
performs as well or better than Claude 2 [4] on most pure-text tasks, while Sonnet and
Opus significantly outperform it. Additionally, these models exhibit improved fluency in
non-English languages, making them more versatile for a global audience. In this report,
we provide an in-depth analysis of our evaluations, focusing on core capabilities, safety,
societal impacts, and the catastrophic risk assessments we committed to in our Responsible
Scaling Policy [5].
More Readings:
Knowledge Conflicts for LLMs: A Survey
https://arxiv.org/abs/2403.08319
This survey provides an in-depth analysis of knowledge conflicts for large language models (LLMs), highlighting the complex challenges they encounter when blending contextual and parametric knowledge. Our focus is on three categories of knowledge conflicts: context-memory, inter-context, and intra-memory conflict. These conflicts can significantly impact the trustworthiness and performance of LLMs, especially in real-world applications where noise and misinformation are common. By categorizing these conflicts, exploring the causes, examining the behaviors of LLMs under such conflicts, and reviewing available solutions, this survey aims to shed light on strategies for improving the robustness
Transformer Debugger
https://github.com/openai/transformer-debugger
Transformer Debugger (TDB) is a tool developed by OpenAI’s Superalignment team with the goal of supporting investigations into specific behaviors of small language models. The tool combines automated interpretability techniques with sparse autoencoders. TDB enables rapid exploration before needing to write code, with the ability to intervene in the forward pass and see how it affects a particular behavior. It can be used to answer questions like, “Why does the model output token A instead of token B for this prompt?” or “Why does attention head H attend to token T for this prompt?” It does so by identifying specific components (neurons, attention heads, autoencoder latents) that contribute to the behavior, showing automatically generated explanations of what causes those components to activate most strongly, and tracing connections between components to help discover circuits.
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning
In this paper, we use a weak dictionary learning algorithm called a sparse autoencoder to generate learned features from a trained model that offer a more monosemantic unit of analysis than the model’s neurons themselves. Our approach here builds on a significant amount of prior work, especially in using dictionary learning and related methods on neural network activations , and a more general allied literature on disentanglement. We also note interim reports which independently investigated the sparse autoencoder approach in response to Toy Models, culminating in the recent manuscript of Cunningham et al.
related post: Decomposing Language Models Into Understandable Components https://www.anthropic.com/news/decomposing-language-models-into-understandable-components
As large language models become more powerful and their risks become clearer, there is increasing value to figuring out what makes them tick. In our previous work, we have found that large language models change along many personality and behavioral dimensions as a function of both scale and the amount of fine-tuning. Understanding these changes requires seeing how models work, for instance to determine if a model’s outputs rely on memorization or more sophisticated processing. Understanding the inner workings of language models will have substantial implications for forecasting AI capabilities as well as for approaches to aligning AI systems with human preferences.
Mechanistic interpretability takes a bottom-up approach to understanding ML models: understanding in detail the behavior of individual units or small-scale circuits such as induction heads. But we also see value in a top-down approach, starting with a model’s observable behaviors and generalization patterns and digging down to see what neurons and circuits are responsible. An advantage of working top-down is that we can directly study high-level cognitive phenomena of interest which only arise at a large scale, such as reasoning and role-playing. Eventually, the two approaches should meet in the middle.
Language models can explain neurons in language models
Language models have become more capable and more widely deployed, but we do not understand how they work. Recent work has made progress on understanding a small number of circuits and narrow behaviors,[1][2] but to fully understand a language model, we’ll need to analyze millions of neurons. This paper applies automation to the problem of scaling an interpretability technique to all the neurons in a large language model. Our hope is that building on this approach of automating interpretability [3][4][5] will enable us to comprehensively audit the safety of models before deployment.
Please click each post's URL shown below to check out its full contents.
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, Dario Amodei
We study empirical scaling laws for language model performance on the cross-entropy loss. The loss scales as a power-law with model size, dataset size, and the amount of compute used for training, with some trends spanning more than seven orders of magnitude. Other architectural details such as network width or depth have minimal effects within a wide range. Simple equations govern the dependence of overfitting on model/dataset size and the dependence of training speed on model size. These relationships allow us to determine the optimal allocation of a fixed compute budget. Larger models are significantly more sample-efficient, such that optimally compute-efficient training involves training very large models on a relatively modest amount of data and stopping significantly before convergence.
Large Language Models (LLMs) have demonstrated remarkable capabilities in important tasks such as natural language understanding, language generation, and complex reasoning and have the potential to make a substantial impact on our society. Such capabilities, however, come with the considerable resources they demand, highlighting the strong need to develop effective techniques for addressing their efficiency this http URL this survey, we provide a systematic and comprehensive review of efficient LLMs research. We organize the literature in a taxonomy consisting of three main categories, covering distinct yet interconnected efficient LLMs topics from model-centric, data-centric, and framework-centric perspective, respectively. We have also created a GitHub repository where we compile the papers featured in this survey at this https URL, and will actively maintain this repository and incorporate new research as it emerges. We hope our survey can serve as a valuable resource to help researchers and practitioners gain a systematic understanding of the research developments in efficient LLMs and inspire them to contribute to this important and exciting field.
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
Recent research, such as BitNet [23], is paving the way for a new era of 1-bit Large Language Models (LLMs). In this work, we introduce a 1-bit LLM variant, namely BitNet b1.58, in which every single parameter (or weight) of the LLM is ternary {-1, 0, 1}. It matches the full-precision (i.e., FP16 or BF16) Transformer LLM with the same model size and training tokens in terms of both perplexity and end-task performance, while being significantly more cost-effective in terms of latency, memory, throughput, and energy consumption. More profoundly, the 1.58-bit LLM defines a new scaling law and recipe for training new generations of LLMs that are both high-performance and cost-effective. Furthermore, it enables a new computation paradigm and opens the door for designing specific hardware optimized for 1-bit LLMs.
More Readings:
An Expert is Worth One Token: Synergizing Multiple Expert LLMs as Generalist via Expert Token Routing
Ziwei Chai, Guoyin Wang, Jing Su, Tianjie Zhang, Xuanwen Huang, Xuwu Wang, Jingjing Xu, Jianbo Yuan, Hongxia Yang, Fei Wu, Yang Yang
We present Expert-Token-Routing, a unified generalist framework that facilitates seamless integration of multiple expert LLMs. Our framework represents expert LLMs as special expert tokens within the vocabulary of a meta LLM. The meta LLM can route to an expert LLM like generating new tokens. Expert-Token-Routing not only supports learning the implicit expertise of expert LLMs from existing instruction dataset but also allows for dynamic extension of new expert LLMs in a plug-and-play manner. It also conceals the detailed collaboration process from the user’s perspective, facilitating interaction as though it were a singular LLM. Our framework outperforms various existing multi-LLM collaboration paradigms across benchmarks that incorporate six diverse expert domains, demonstrating effectiveness and robustness in building generalist LLM system via synergizing multiple expert LLMs.
LIMA: Less Is More for Alignment /
https://arxiv.org/abs/2305.11206
Large language models are trained in two stages: (1) unsupervised pretraining from raw text, to learn general-purpose representations, and (2) large scale instruction tuning and reinforcement learning, to better align to end tasks and user preferences. We measure the relative importance of these two stages by training LIMA, a 65B parameter LLaMa language model fine-tuned with the standard supervised loss on only 1,000 carefully curated prompts and responses, without any reinforcement learning or human preference modeling. LIMA demonstrates remarkably strong performance, learning to follow specific response formats from only a handful of examples in the training data, including complex queries that range from planning trip itineraries to speculating about alternate history. Moreover, the model tends to generalize well to unseen tasks that did not appear in the training data. In a controlled human study, responses from LIMA are either equivalent or strictly preferred to GPT-4 in 43% of cases; this statistic is as high as 58% when compared to Bard and 65% versus DaVinci003, which was trained with human feedback. Taken together, these results strongly suggest that almost all knowledge in large language models is learned during pretraining, and only limited instruction tuning data is necessary to teach models to produce high quality output.
Please click each post's URL shown below to check out its full contents.
Unleashing the potential of prompt engineering in Large Language Models: a comprehensive review
https://arxiv.org/abs/2310.14735
Banghao Chen, Zhaofeng Zhang, Nicolas Langrené, Shengxin Zhu / This paper delves into the pivotal role of prompt engineering in unleashing the capabilities of Large Language Models (LLMs). Prompt engineering is the process of structuring input text for LLMs and is a technique integral to optimizing the efficacy of LLMs. This survey elucidates foundational principles of prompt engineering, such as role-prompting, one-shot, and few-shot prompting, as well as more advanced methodologies such as the chain-of-thought and tree-of-thoughts prompting. The paper sheds light on how external assistance in the form of plugins can assist in this task, and reduce machine hallucination by retrieving external knowledge. We subsequently delineate prospective directions in prompt engineering research, emphasizing the need for a deeper understanding of structures and the role of agents in Artificial Intelligence-Generated Content (AIGC) tools. We discuss how to assess the efficacy of prompt methods from different perspectives and using different methods. Finally, we gather information about the application of prompt engineering in such fields as education and programming, showing its transformative potential. This comprehensive survey aims to serve as a friendly guide for anyone venturing through the big world of LLMs and prompt engineering.
More Readings:
Skeleton-of-Thought: Large Language Models Can Do Parallel Decoding
This work aims at decreasing the end-to-end generation latency of large language models (LLMs). One of the major causes of the high generation latency is the sequential decoding approach adopted by almost all state-of-the-art LLMs. In this work, motivated by the thinking and writing process of humans, we propose Skeleton-of-Thought (SoT), which first guides LLMs to generate the skeleton of the answer, and then conducts parallel API calls or batched decoding to complete the contents of each skeleton point in parallel. Not only does SoT provide considerable speed-ups across 12 LLMs, but it can also potentially improve the answer quality on several question categories. SoT is an initial attempt at data-centric optimization for inference efficiency, and further underscores the potential of pushing LLMs to think more like a human for answer quality.
Topologies of Reasoning: Demystifying Chains, Trees, and Graphs of Thoughts
The field of natural language processing (NLP) has witnessed significant progress in recent years, with a notable focus on improving large language models’ (LLM) performance through innovative prompting techniques. Among these, prompt engineering coupled with structures has emerged as a promising paradigm, with designs such as Chain-of-Thought, Tree of Thoughts, or Graph of Thoughts, in which the overall LLM reasoning is guided by a structure such as a graph. As illustrated with numerous examples, this paradigm significantly enhances the LLM’s capability to solve numerous tasks, ranging from logical or mathematical reasoning to planning or creative writing. To facilitate the understanding of this growing field and pave the way for future developments, we devise a general blueprint for effective and efficient LLM reasoning schemes. For this, we conduct an in-depth analysis of the prompt execution pipeline, clarifying and clearly defining different concepts. We then build the first taxonomy of structure-enhanced LLM reasoning schemes. We focus on identifying fundamental classes of harnessed structures, and we analyze the representations of these structures, algorithms executed with these structures, and many others. We refer to these structures as reasoning topologies, because their representation becomes to a degree spatial, as they are contained within the LLM context. Our study compares existing prompting schemes using the proposed taxonomy, discussing how certain design choices lead to different patterns in performance and cost. We also outline theoretical underpinnings, relationships between prompting and others parts of the LLM ecosystem such as knowledge bases, and the associated research challenges. Our work will help to advance future prompt engineering techniques.
Please click each post's URL shown below to check out its full contents.
Grégoire Mialon, Roberto Dessì, Maria Lomeli, Christoforos Nalmpantis, Ram Pasunuru, Roberta Raileanu, Baptiste Rozière, Timo Schick, Jane Dwivedi-Yu, Asli Celikyilmaz, Edouard Grave, Yann LeCun, Thomas Scialom
This survey reviews works in which language models (LMs) are augmented with reasoning skills and the ability to use tools. The former is defined as decomposing a potentially complex task into simpler subtasks while the latter consists in calling external modules such as a code interpreter. LMs can leverage these augmentations separately or in combination via heuristics, or learn to do so from demonstrations. While adhering to a standard missing tokens prediction objective, such augmented LMs can use various, possibly non-parametric external modules to expand their context processing ability, thus departing from the pure language modeling paradigm. We therefore refer to them as Augmented Language Models (ALMs). The missing token objective allows ALMs to learn to reason, use tools, and even act, while still performing standard natural language tasks and even outperforming most regular LMs on several benchmarks. In this work, after reviewing current advance in ALMs, we conclude that this new research direction has the potential to address common limitations of traditional LMs such as interpretability,
Self-Consistency Improves Chain of Thought Reasoning in Language Models
https://arxiv.org/abs/2203.11171
Chain-of-thought prompting combined with pre-trained large language models has achieved encouraging results on complex reasoning tasks. In this paper, we propose a new decoding strategy, self-consistency, to replace the naive greedy decoding used in chain-of-thought prompting. It first samples a diverse set of reasoning paths instead of only taking the greedy one, and then selects the most consistent answer by marginalizing out the sampled reasoning paths. Self-consistency leverages the intuition that a complex reasoning problem typically admits multiple different ways of thinking leading to its unique correct answer. Our extensive empirical evaluation shows that self-consistency boosts the performance of chain-of-thought prompting with a striking margin on a range of popular arithmetic and commonsense reasoning benchmarks, including GSM8K (+17.9%), SVAMP (+11.0%), AQuA (+12.2%), StrategyQA (+6.4%) and ARC-challenge (+3.9%).
If LLM Is the Wizard, Then Code Is the Wand: A Survey on How Code Empowers Large Language Models to Serve as Intelligent Agents
https://arxiv.org/abs/2401.00812
Ke Yang, Jiateng Liu, John Wu, Chaoqi Yang, Yi R. Fung, Sha Li, Zixuan Huang, Xu Cao, Xingyao Wang, Yiquan Wang, Heng Ji, Chengxiang Zhai
The prominent large language models (LLMs) of today differ from past language models not only in size, but also in the fact that they are trained on a combination of natural language and formal language (code). As a medium between humans and computers, code translates high-level goals into executable steps, featuring standard syntax, logical consistency, abstraction, and modularity. In this survey, we present an overview of the various benefits of integrating code into LLMs’ training data. Specifically, beyond enhancing LLMs in code generation, we observe that these unique properties of code help (i) unlock the reasoning ability of LLMs, enabling their applications to a range of more complex natural language tasks; (ii) steer LLMs to produce structured and precise intermediate steps, which can then be connected to external execution ends through function calls; and (iii) take advantage of code compilation and execution environment, which also provides diverse feedback for model improvement. In addition, we trace how these profound capabilities of LLMs, brought by code, have led to their emergence as intelligent agents (IAs) in situations where the ability to understand instructions, decompose goals, plan and execute actions, and refine from feedback are crucial to their success on downstream tasks. Finally, we present several key challenges and future directions of empowering LLMs with code.
More Readings:
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, Yuan Cao
While large language models (LLMs) have demonstrated impressive capabilities across tasks in language understanding and interactive decision making, their abilities for reasoning (e.g. chain-of-thought prompting) and acting (e.g. action plan generation) have primarily been studied as separate topics. In this paper, we explore the use of LLMs to generate both reasoning traces and task-specific actions in an interleaved manner, allowing for greater synergy between the two: reasoning traces help the model induce, track, and update action plans as well as handle exceptions, while actions allow it to interface with external sources, such as knowledge bases or environments, to gather additional information. We apply our approach, named ReAct, to a diverse set of language and decision making tasks and demonstrate its effectiveness over state-of-the-art baselines, as well as improved human interpretability and trustworthiness over methods without reasoning or acting components. Concretely, on question answering (HotpotQA) and fact verification (Fever), ReAct overcomes issues of hallucination and error propagation prevalent in chain-of-thought reasoning by interacting with a simple Wikipedia API, and generates human-like task-solving trajectories that are more interpretable than baselines without reasoning traces. On two interactive decision making benchmarks (ALFWorld and WebShop), ReAct outperforms imitation and reinforcement learning methods by an absolute success rate of 34% and 10% respectively, while being prompted with only one or two in-context examples. Project site with code: this https URL
Comments: v3 is the ICLR camera ready version with some typos fixed. Project site with code: this https URL
Towards Reasoning in Large Language Models: A Survey
Jie Huang, Kevin Chen-Chuan Chang
Reasoning is a fundamental aspect of human intelligence that plays a crucial role in activities such as problem solving, decision making, and critical thinking. In recent years, large language models (LLMs) have made significant progress in natural language processing, and there is observation that these models may exhibit reasoning abilities when they are sufficiently large. However, it is not yet clear to what extent LLMs are capable of reasoning. This paper provides a comprehensive overview of the current state of knowledge on reasoning in LLMs, including techniques for improving and eliciting reasoning in these models, methods and benchmarks for evaluating reasoning abilities, findings and implications of previous research in this field, and suggestions on future directions. Our aim is to provide a detailed and up-to-date review of this topic and stimulate meaningful discussion and future work.
Comments: ACL 2023 Findings, 15 pages
Large Language Models Can Self-Improve
Jiaxin Huang, Shixiang Shane Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu, Jiawei Han / Large Language Models (LLMs) have achieved excellent performances in various tasks. However, fine-tuning an LLM requires extensive supervision. Human, on the other hand, may improve their reasoning abilities by self-thinking without external inputs. In this work, we demonstrate that an LLM is also capable of self-improving with only unlabeled datasets. We use a pre-trained LLM to generate “high-confidence” rationale-augmented answers for unlabeled questions using Chain-of-Thought prompting and self-consistency, and fine-tune the LLM using those self-generated solutions as target outputs. We show that our approach improves the general reasoning ability of a 540B-parameter LLM (74.4%->82.1% on GSM8K, 78.2%->83.0% on DROP, 90.0%->94.4% on OpenBookQA, and 63.4%->67.9% on ANLI-A3) and achieves state-of-the-art-level performance, without any ground truth label. We conduct ablation studies and show that fine-tuning on reasoning is critical for self-improvement.
https://arxiv.org/abs/2210.11610
Orca 2: Teaching Small Language Models How to Reason /
https://arxiv.org/abs/2311.11045
Orca 1 learns from rich signals, such as explanation traces, allowing it to outperform conventional instruction-tuned models on benchmarks like BigBench Hard and AGIEval. In Orca 2, we continue exploring how improved training signals can enhance smaller LMs’ reasoning abilities. Research on training small LMs has often relied on imitation learning to replicate the output of more capable models. We contend that excessive emphasis on imitation may restrict the potential of smaller models. We seek to teach small LMs to employ different solution strategies for different tasks, potentially different from the one used by the larger model. For example, while larger models might provide a direct answer to a complex task, smaller models may not have the same capacity. In Orca 2, we teach the model various reasoning techniques (step-by-step, recall then generate, recall-reason-generate, direct answer, etc.). More crucially, we aim to help the model learn to determine the most effective solution strategy for each task. We evaluate Orca 2 using a comprehensive set of 15 diverse benchmarks (corresponding to approximately 100 tasks and over 36,000 unique prompts). Orca 2 significantly surpasses models of similar size and attains performance levels similar or better to those of models 5-10x larger, as assessed on complex tasks that test advanced reasoning abilities in zero-shot settings. make Orca 2 weights publicly available at this http URL to support research on the development, evaluation, and alignment of smaller LMs
Please click each post's URL shown below to check out its full contents.
A Survey on Large Language Model based Autonomous Agents
https://arxiv.org/abs/2308.11432
Autonomous agents have long been a prominent research focus in both academic and industry communities. Previous research in this field often focuses on training agents with limited knowledge within isolated environments, which diverges significantly from human learning processes, and thus makes the agents hard to achieve human-like decisions. Recently, through the acquisition of vast amounts of web knowledge, large language models (LLMs) have demonstrated remarkable potential in achieving human-level intelligence. This has sparked an upsurge in studies investigating LLM-based autonomous agents. In this paper, we present a comprehensive survey of these studies, delivering a systematic review of the field of LLM-based autonomous agents from a holistic perspective. More specifically, we first discuss the construction of LLM-based autonomous agents, for which we propose a unified framework that encompasses a majority of the previous work. Then, we present a comprehensive overview of the diverse applications of LLM-based autonomous agents in the fields of social science, natural science, and engineering. Finally, we delve into the evaluation strategies commonly used for LLM-based autonomous agents. Based on the previous studies, we also present several challenges and future directions in this field. To keep track of this field and continuously update our survey, we maintain a repository of relevant references at this https URL.
More Readings:
Position Paper: Agent AI Towards a Holistic Intelligence
Recent advancements in large foundation models have remarkably enhanced our understanding of sensory information in open-world environments. In leveraging the power of foundation models, it is crucial for AI research to pivot away from excessive reductionism and toward an emphasis on systems that function as cohesive wholes. Specifically, we emphasize developing Agent AI – an embodied system that integrates large foundation models into agent actions. The emerging field of Agent AI spans a wide range of existing embodied and agent-based multimodal interactions, including robotics, gaming, and healthcare systems, etc. In this paper, we propose a novel large action model to achieve embodied intelligent behavior, the Agent Foundation Model. On top of this idea, we discuss how agent AI exhibits remarkable capabilities across a variety of domains and tasks, challenging our understanding of learning and cognition. Furthermore, we discuss the potential of Agent AI from an interdisciplinary perspective, underscoring AI cognition and consciousness within scientific discourse. We believe that those discussions serve as a basis for future research directions and encourage broader societal engagement.
an overview of tool use in LLMs, including a formal definition of the tool-use paradigm, scenarios where LLMs leverage tool usage, and for which tasks this approach works well; it also provides an analysis of complex tool usage and summarize testbeds and evaluation metrics across LM tooling works
Agentic AI systems—AI systems that can pursue complex goals with limited direct supervision— are likely to be broadly useful if we can integrate them responsibly into our society. While such systems have substantial potential to help people more efficiently and effectively achieve their own goals, they also create risks of harm. In this white paper, we suggest a definition of agentic AI systems and the parties in the agentic AI system life-cycle, and highlight the importance of agreeing on a set of baseline responsibilities and safety best practices for each of these parties. As our primary contribution, we offer an initial set of practices for keeping agents’ operations safe and accountable, which we hope can serve as building blocks in the development of agreed baseline best practices. We enumerate the questions and uncertainties around operationalizing each of these practices that must be addressed before such practices can be codified. We then highlight categories of indirect impacts from the wide-scale adoption of agentic AI systems, which are likely to necessitate additional governance frameworks.
Emergent autonomous scientific research capabilities of large language models
https://arxiv.org/abs/2304.05332
Transformer-based large language models are rapidly advancing in the field of machine learning research, with applications spanning natural language, biology, chemistry, and computer programming. Extreme scaling and reinforcement learning from human feedback have significantly improved the quality of generated text, enabling these models to perform various tasks and reason about their choices. In this paper, we present an Intelligent Agent system that combines multiple large language models for autonomous design, planning, and execution of scientific experiments. We showcase the Agent’s scientific research capabilities with three distinct examples, with the most complex being the successful performance of catalyzed cross-coupling reactions. Finally, we discuss the safety implications of such systems and propose measures to prevent their misuse.
What Makes a Dialog Agent Useful?
https://huggingface.co/blog/dialog-agents
Please click each post's URL shown below to check out its full contents.
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V. Chawla, Olaf Wiest, Xiangliang Zhang
Large Language Models (LLMs) have achieved remarkable success across a wide array of tasks. Due to the impressive planning and reasoning abilities of LLMs, they have been used as autonomous agents to do many tasks automatically. Recently, based on the development of using one LLM as a single planning or decision-making agent, LLM-based multi-agent systems have achieved considerable progress in complex problem-solving and world simulation. To provide the community with an overview of this dynamic field, we present this survey to offer an in-depth discussion on the essential aspects of multi-agent systems based on LLMs, as well as the challenges. Our goal is for readers to gain substantial insights on the following questions: What domains and environments do LLM-based multi-agents simulate? How are these agents profiled and how do they communicate? What mechanisms contribute to the growth of agents’ capacities? For those interested in delving into this field of study, we also summarize the commonly used datasets or benchmarks for them to have convenient access. To keep researchers updated on the latest studies, we maintain an open-source GitHub repository, dedicated to outlining the research on LLM-based multi-agent systems.
More Readings:
Understanding the planning of LLM agents: A survey
https://arxiv.org/abs/2402.02716
As Large Language Models (LLMs) have shown significant intelligence, the progress to leverage LLMs as planning modules of autonomous agents has attracted more attention. This survey provides the first systematic view of LLM-based agents planning, covering recent works aiming to improve planning ability. We provide a taxonomy of existing works on LLM-Agent planning, which can be categorized into Task Decomposition, Plan Selection, External Module, Reflection and Memory. Comprehensive analyses are conducted for each direction, and further challenges for the field of research are discussed.
LLM Agents can Autonomously Hack Websites
Richard Fang, Rohan Bindu, Akul Gupta, Qiusi Zhan, Daniel Kang
In recent years, large language models (LLMs) have become increasingly capable and can now interact with tools (i.e., call functions), read documents, and recursively call themselves. As a result, these LLMs can now function autonomously as agents. With the rise in capabilities of these agents, recent work has speculated on how LLM agents would affect cybersecurity. However, not much is known about the offensive capabilities of LLM agents. In this work, we show that LLM agents can autonomously hack websites, performing tasks as complex as blind database schema extraction and SQL injections without human feedback. Importantly, the agent does not need to know the vulnerability beforehand. This capability is uniquely enabled by frontier models that are highly capable of tool use and leveraging extended context. Namely, we show that GPT-4 is capable of such hacks, but existing open-source models are not. Finally, we show that GPT-4 is capable of autonomously finding vulnerabilities in websites in the wild. Our findings raise questions about the widespread deployment of LLMs.
Agent-FLAN: Designing Data and Methods of Effective Agent Tuning for Large Language Models
Open-sourced Large Language Models (LLMs) have achieved great success in various NLP tasks, however, they are still far inferior to API-based models when acting as agents. How to integrate agent ability into general LLMs becomes a crucial and urgent problem. This paper first delivers three key observations: (1) the current agent training corpus is entangled with both formats following and agent reasoning, which significantly shifts from the distribution of its pre-training data; (2) LLMs exhibit different learning speeds on the capabilities required by agent tasks; and (3) current approaches have side-effects when improving agent abilities by introducing hallucinations. Based on the above findings, we propose Agent-FLAN to effectively Fine-tune LANguage models for Agents. Through careful decomposition and redesign of the training corpus, Agent-FLAN enables Llama2-7B to outperform prior best works by 3.5\% across various agent evaluation datasets. With comprehensively constructed negative samples, Agent-FLAN greatly alleviates the hallucination issues based on our established evaluation benchmark. Besides, it consistently improves the agent capability of LLMs when scaling model sizes while slightly enhancing the general capability of LLMs. The code will be available at this https URL.
Humanoid Locomotion as Next Token Prediction
Ilija Radosavovic, Bike Zhang, Baifeng Shi, Jathushan Rajasegaran, Sarthak Kamat, Trevor Darrell, Koushil Sreenath, Jitendra Malik
We cast real-world humanoid control as a next token prediction problem, akin to predicting the next word in language. Our model is a causal transformer trained via autoregressive prediction of sensorimotor trajectories. To account for the multi-modal nature of the data, we perform prediction in a modality-aligned way, and for each input token predict the next token from the same modality. This general formulation enables us to leverage data with missing modalities, like video trajectories without actions. We train our model on a collection of simulated trajectories coming from prior neural network policies, model-based controllers, motion capture data, and YouTube videos of humans. We show that our model enables a full-sized humanoid to walk in San Francisco zero-shot. Our model can transfer to the real world even when trained on only 27 hours of walking data, and can generalize to commands not seen during training like walking backward. These findings suggest a promising path toward learning challenging real-world control tasks by generative modeling of sensorimotor trajectories.
Please click each post's URL shown below to check out its full contents.
Towards Efficient Generative Large Language Model Serving: A Survey from Algorithms to Systems
https://arxiv.org/abs/2312.15234
In the rapidly evolving landscape of artificial intelligence (AI), generative large language models (LLMs) stand at the forefront, revolutionizing how we interact with our data. However, the computational intensity and memory consumption of deploying these models present substantial challenges in terms of serving efficiency, particularly in scenarios demanding low latency and high throughput. This survey addresses the imperative need for efficient LLM serving methodologies from a machine learning system (MLSys) research perspective, standing at the crux of advanced AI innovations and practical system optimizations. We provide in-depth analysis, covering a spectrum of solutions, ranging from cutting-edge algorithmic modifications to groundbreaking changes in system designs. The survey aims to provide a comprehensive understanding of the current state and future directions in efficient LLM serving, offering valuable insights for researchers and practitioners in overcoming the barriers of effective LLM deployment, thereby reshaping the future of AI.
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling
https://arxiv.org/abs/2304.01373
How do large language models (LLMs) develop and evolve over the course of training? How do these patterns change as models scale? To answer these questions, we introduce \textit{Pythia}, a suite of 16 LLMs all trained on public data seen in the exact same order and ranging in size from 70M to 12B parameters. We provide public access to 154 checkpoints for each one of the 16 models, alongside tools to download and reconstruct their exact training dataloaders for further study. We intend \textit{Pythia} to facilitate research in many areas, and we present several case studies including novel results in memorization, term frequency effects on few-shot performance, and reducing gender bias. We demonstrate that this highly controlled setup can be used to yield novel insights toward LLMs and their training dynamics. Trained models, analysis code, training code, and training data can be found at \url{this https URL}.
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
https://arxiv.org/abs/2403.09611
Multimodal LLM Pre-training - provides a comprehensive overview of methods, analysis, and insights into multimodal LLM pre-training; studies different architecture components and finds that carefully mixing image-caption, interleaved image-text, and text-only data is key for state-of-the-art performance; it also proposes a family of multimodal models up to 30B parameters that achieve SOTA in pre-training metrics and include properties such as enhanced in-context learning, multi-image reasoning, enabling few-shot chain-of-thought prompting.
More Readings:
Sparks of Large Audio Models: A Survey and Outlook
Siddique Latif, Moazzam Shoukat, Fahad Shamshad, Muhammad Usama, Yi Ren, Heriberto Cuayáhuitl, Wenwu Wang, Xulong Zhang, Roberto Togneri, Erik Cambria, Björn W. Schuller
This survey paper provides a comprehensive overview of the recent advancements and challenges in applying large language models to the field of audio signal processing. Audio processing, with its diverse signal representations and a wide range of sources–from human voices to musical instruments and environmental sounds–poses challenges distinct from those found in traditional Natural Language Processing scenarios. Nevertheless, \textit{Large Audio Models}, epitomized by transformer-based architectures, have shown marked efficacy in this sphere. By leveraging massive amount of data, these models have demonstrated prowess in a variety of audio tasks, spanning from Automatic Speech Recognition and Text-To-Speech to Music Generation, among others. Notably, recently these Foundational Audio Models, like SeamlessM4T, have started showing abilities to act as universal translators, supporting multiple speech tasks for up to 100 languages without any reliance on separate task-specific systems. This paper presents an in-depth analysis of state-of-the-art methodologies regarding \textit{Foundational Large Audio Models}, their performance benchmarks, and their applicability to real-world scenarios. We also highlight current limitations and provide insights into potential future research directions in the realm of \textit{Large Audio Models} with the intent to spark further discussion, thereby fostering innovation in the next generation of audio-processing systems. Furthermore, to cope with the rapid development in this area, we will consistently update the relevant repository with relevant recent articles and their open-source implementations at this https URL.
Please click each post's URL shown below to check out its full contents.
The release of Meta’s Llama model and the subsequent release of Llama 2 in 2023 kickstarted an explosion of open-source language models, with better and more innovative models being released on what seems like a daily basis. With new open-source models being released on a daily basis, here we dove into the ocean of open-source possibilities to curate a select list of the most intriguing and influential models making waves in recent months, inlcuding Qwen1.5/ Yi/ Smaug/ Mixtral-8x7B-v0.1/ DBRX/ SOLAR-10.7B-v1.0 / Tulu 2 / WizardLM/ Starling 7B/ OLMo-7B/ Gemma and DeciLM-7B.
Plus the newly avaiable DBRX model https://www.databricks.com/blog/introducing-dbrx-new-state-art-open-llm
Instruction Tuning for Large Language Models: A Survey
This paper surveys research works in the quickly advancing field of instruction tuning (IT), a crucial technique to enhance the capabilities and controllability of large language models (LLMs). Instruction tuning refers to the process of further training LLMs on a dataset consisting of \textsc{(instruction, output)} pairs in a supervised fashion, which bridges the gap between the next-word prediction objective of LLMs and the users’ objective of having LLMs adhere to human instructions. In this work, we make a systematic review of the literature, including the general methodology of IT, the construction of IT datasets, the training of IT models, and applications to different modalities, domains and applications, along with an analysis on aspects that influence the outcome of IT (e.g., generation of instruction outputs, size of the instruction dataset, etc). We also review the potential pitfalls of IT along with criticism against it, along with efforts pointing out current deficiencies of existing strategies and suggest some avenues for fruitful research. Project page: this http URL
Delta tuning: A comprehensive study of parameter efficient methods for pre-trained language models
https://arxiv.org/abs/2203.06904
Despite the success, the process of fine-tuning large-scale PLMs brings prohibitive adaptation costs. In fact, fine-tuning all the parameters of a colossal model and retaining separate instances for different tasks are practically infeasible. This necessitates a new branch of research focusing on the parameter-efficient adaptation of PLMs, dubbed as delta tuning in this paper. In contrast with the standard fine-tuning, delta tuning only fine-tunes a small portion of the model parameters while keeping the rest untouched, largely reducing both the computation and storage costs. Recent studies have demonstrated that a series of delta tuning methods with distinct tuned parameter selection could achieve performance on a par with full-parameter fine-tuning, suggesting a new promising way of stimulating large-scale PLMs. In this paper, we first formally describe the problem of delta tuning and then comprehensively review recent delta tuning approaches. We also propose a unified categorization criterion that divide existing delta tuning methods into three groups: addition-based, specification-based, and reparameterization-based methods. Though initially proposed as an efficient method to steer large models, we believe that some of the fascinating evidence discovered along with delta tuning could help further reveal the mechanisms of PLMs and even deep neural networks. To this end, we discuss the theoretical principles underlying the effectiveness of delta tuning and propose frameworks to interpret delta tuning from the perspective of optimization and optimal control, respectively. Furthermore, we provide a holistic empirical study of representative methods, where results on over 100 NLP tasks demonstrate a comprehensive performance comparison of different approaches. The experimental results also cover the analysis of combinatorial, scaling and transferable properties of delta tuning.
More readings
Gemini: A Family of Highly Capable Multimodal Models
https://arxiv.org/abs/2312.11805
This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
QLoRA: Efficient Finetuning of Quantized LLMs
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, Luke Zettlemoyer
We present QLoRA, an efficient finetuning approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance. QLoRA backpropagates gradients through a frozen, 4-bit quantized pretrained language model into Low Rank Adapters~(LoRA). Our best model family, which we name Guanaco, outperforms all previous openly released models on the Vicuna benchmark, reaching 99.3% of the performance level of ChatGPT while only requiring 24 hours of finetuning on a single GPU. QLoRA introduces a number of innovations to save memory without sacrificing performance: (a) 4-bit NormalFloat (NF4), a new data type that is information theoretically optimal for normally distributed weights (b) double quantization to reduce the average memory footprint by quantizing the quantization constants, and (c) paged optimziers to manage memory spikes. We use QLoRA to finetune more than 1,000 models, providing a detailed analysis of instruction following and chatbot performance across 8 instruction datasets, multiple model types (LLaMA, T5), and model scales that would be infeasible to run with regular finetuning (e.g. 33B and 65B parameter models). Our results show that QLoRA finetuning on a small high-quality dataset leads to state-of-the-art results, even when using smaller models than the previous SoTA. We provide a detailed analysis of chatbot performance based on both human and GPT-4 evaluations showing that GPT-4 evaluations are a cheap and reasonable alternative to human evaluation. Furthermore, we find that current chatbot benchmarks are not trustworthy to accurately evaluate the performance levels of chatbots. A lemon-picked analysis demonstrates where Guanaco fails compared to ChatGPT. We release all of our models and code, including CUDA kernels for 4-bit training.
related: LoRA: Low-Rank Adaptation of Large Language Models
https://arxiv.org/abs/2106.09685
An important paradigm of natural language processing consists of large-scale pre-training on general domain data and adaptation to particular tasks or domains. As we pre-train larger models, full fine-tuning, which retrains all model parameters, becomes less feasible. Using GPT-3 175B as an example – deploying independent instances of fine-tuned models, each with 175B parameters, is prohibitively expensive. We propose Low-Rank Adaptation, or LoRA, which freezes the pre-trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks. Compared to GPT-3 175B fine-tuned with Adam, LoRA can reduce the number of trainable parameters by 10,000 times and the GPU memory requirement by 3 times. LoRA performs on-par or better than fine-tuning in model quality on RoBERTa, DeBERTa, GPT-2, and GPT-3, despite having fewer trainable parameters, a higher training throughput, and, unlike adapters, no additional inference latency. We also provide an empirical investigation into rank-deficiency in language model adaptation, which sheds light on the efficacy of LoRA. We release a package that facilitates the integration of LoRA with PyTorch models and provide our implementations and model checkpoints for RoBERTa, DeBERTa, and GPT-2 at this https URL.
Astraios: Parameter-Efficient Instruction Tuning Code Large Language Models
https://arxiv.org/abs/2401.00788
Terry Yue Zhuo, Armel Zebaze, Nitchakarn Suppattarachai, Leandro von Werra, Harm de Vries, Qian Liu, Niklas Muennighoff
The high cost of full-parameter fine-tuning (FFT) of Large Language Models (LLMs) has led to a series of parameter-efficient fine-tuning (PEFT) methods. However, it remains unclear which methods provide the best cost-performance trade-off at different model scales. We introduce Astraios, a suite of 28 instruction-tuned OctoCoder models using 7 tuning methods and 4 model sizes up to 16 billion parameters. Through investigations across 5 tasks and 8 different datasets encompassing both code comprehension and code generation tasks, we find that FFT generally leads to the best downstream performance across all scales, and PEFT methods differ significantly in their efficacy based on the model scale. LoRA usually offers the most favorable trade-off between cost and performance. Further investigation into the effects of these methods on both model robustness and code security reveals that larger models tend to demonstrate reduced robustness and less security. At last, we explore the relationships among updated parameters, cross-entropy loss, and task performance. We find that the tuning effectiveness observed in small models generalizes well to larger models, and the validation loss in instruction tuning can be a reliable indicator of overall downstream performance.
Instruction Tuning for Large Language Models: A Survey
In recent years, large language models (LLMs) have demonstrated remarkable capabilities across a wide range of natural language tasks. However, a significant challenge lies in aligning the next-word prediction objective of LLMs with the user’s goal of having the models follow human instructions. Instruction tuning has emerged as a powerful technique to bridge this gap, enabling LLMs to understand and adhere to human instructions more effectively. In this comprehensive blog article, we delve into the various aspects of instruction tuning, including its methodology, dataset construction, tuned models, multi-modality applications, domain-specific use cases, and efficient tuning techniques.
Methodology of Instruction Tuning
Instruction tuning involves further training LLMs on datasets consisting of (INSTRUCTION, OUTPUT) pairs in a supervised manner. The process can be broken down into two main steps:
Instruction Dataset Construction: In this step, (INSTRUCTION, OUTPUT) pairs are collected or generated. The instructions provide a natural language description of the task to be performed, while the outputs represent the desired response that follows the given instruction. Datasets can be created by transforming existing text-label pairs into the (INSTRUCTION, OUTPUT) format using templates or by leveraging powerful LLMs to generate outputs based on manually curated or expanded instructions.
Instruction Tuning: Once the instruction dataset is prepared, the LLM undergoes fine-tuning using the collected (INSTRUCTION, OUTPUT) pairs. The model learns to generate the appropriate output based on the provided instruction, thus aligning its behavior with the user’s expectations. This fine-tuning process allows the LLM to internalize the patterns and nuances of following human instructions.
General pipeline of instruction tuning
Construction of Instruction Tuning Datasets
The quality and diversity of instruction tuning datasets play a crucial role in the effectiveness of the tuned models. There are two primary approaches to constructing these datasets:
Data Integration from Annotated Natural Language Datasets: This approach involves transforming existing annotated datasets, which typically consist of text-label pairs, into the (INSTRUCTION, OUTPUT) format. By applying carefully designed templates, the original text-label pairs are converted into instructions and their corresponding outputs. Datasets like Flan and P3 have been constructed using this strategy, leveraging a wide range of existing NLP benchmarks.
Generating Outputs using LLMs: An alternative approach is to utilize powerful LLMs, such as GPT-3.5 or GPT-4, to generate outputs based on manually collected or expanded instructions. In this case, a set of seed instructions is manually curated, and then expanded using the LLMs to produce a larger and more diverse set of instructions. The generated instructions are then fed back into the LLMs to obtain the corresponding outputs. Datasets like InstructWild and Self-Instruct have been created following this approach, harnessing the generative capabilities of state-of-the-art LLMs.
An example of INSTRUCTIONS and INSTANCES in the Natural Instruction dataset.
Instruction Tuned Models
The development of instruction-tuned LLMs has led to significant performance gains across various tasks. Some notable models include:
InstructGPT: Developed by OpenAI, InstructGPT is fine-tuned on human instructions, resulting in improved performance on a range of NLP tasks and better alignment with user expectations.
Flan-T5: Flan-T5 is fine-tuned on the FLAN dataset, which consists of a diverse set of instructions and outputs. It has demonstrated strong performance on tasks such as natural language inference, question answering, and summarization.
Alpaca: Alpaca is an instruction-tuned model based on the LLaMA architecture. It is fine-tuned on a dataset generated by GPT-3, showcasing the potential of leveraging powerful LLMs for instruction tuning.
Vicuna: Vicuna is a model fine-tuned on conversations with ChatGPT, an advanced conversational AI system. By learning from the patterns and behaviors of ChatGPT, Vicuna exhibits improved conversational abilities and coherence.
WizardLM: WizardLM is fine-tuned on the Evol-Instruct dataset, which is created using an evolutionary approach to generate diverse and complex instructions. It has shown promising results in following multi-step instructions and engaging in open-ended conversations.
An overview of LLMs tuned on IT datasets
Multi-Modality Instruction Finetuning
Instruction tuning has expanded beyond the realm of text-only tasks, enabling LLMs to process and generate outputs involving various modalities such as images, speech, and video. This multi-modal instruction tuning has opened up new possibilities for LLMs to understand and respond to instructions that span different modalities. Key multi-modal instruction tuning datasets include:
MULTIINSTRUCT: This dataset consists of a diverse set of multimodal tasks, covering image captioning, visual question answering, and text-to-image generation. It provides a comprehensive benchmark for evaluating the multi-modal capabilities of instruction-tuned models.
PMC-VQA: PMC-VQA is a large-scale medical visual question-answering dataset, containing image-question pairs across various modalities and diseases. It enables the development of instruction-tuned models for medical image understanding and diagnosis.
Vision-Flan: Vision-Flan is an extensive dataset for vision-language instruction tuning, comprising a wide range of tasks such as image captioning, visual reasoning, and text-to-image generation. It serves as a valuable resource for training models that can understand and follow instructions involving visual content.
ALLaVA: ALLaVA is a large-scale dataset specifically designed for fine-tuning visual question-answering models. It includes detailed captions, instructions, and comprehensive answers generated by advanced models like GPT-4.
ShareGPT4V: ShareGPT4V is a collection of highly descriptive image-text pairs, generated by GPT-4 and a pre-trained model. It covers various aspects such as global knowledge, object attributes, spatial relationships, and aesthetic evaluations, enabling the development of visually-aware instruction-tuned models.
Models like InstructPix2Pix, LLaVA, Video-LLaMA, and InstructBLIP have demonstrated strong performance on multi-modal tasks by leveraging these datasets and incorporating visual encoders alongside language models.
Overall architecture of InstructBLIP
Applications in Different Domains
Instruction tuning has found applications across a wide range of domains, showcasing its versatility and potential for domain-specific tasks. Some notable examples include:
Dialogue: Models like InstructDial have been developed to improve the conversational abilities of LLMs in task-oriented and open-ended dialogue settings. By fine-tuning on instruction datasets specific to dialogue, these models can engage in more natural and coherent conversations.
Intent Classification and Slot Tagging: LINGUIST is an instruction-tuned model designed for intent classification and slot tagging tasks. It leverages instruction tuning to improve performance on recognizing user intents and extracting relevant entities from utterances.
Information Extraction: InstructUIE is a unified framework for information extraction tasks, utilizing instruction tuning to adapt LLMs to various extraction scenarios. It has shown promising results in zero-shot and few-shot settings, outperforming traditional approaches.
Sentiment Analysis: IT-MTL is an instruction tuning framework specifically designed for aspect-based sentiment analysis. By transforming the task into a set of question-answering instructions, IT-MTL achieves strong performance in both few-shot and full fine-tuning scenarios.
Writing Assistance: Models like Writing-Alpaca-7B and CoEdIT leverage instruction tuning to provide writing assistance and improve the quality of generated text. They can follow instructions related to style transfer, grammatical error correction, and content generation.
Medical Tasks: Instruction tuning has been applied to various medical tasks, such as radiology report generation (Radiology-GPT) and medical dialogue systems (ChatDoctor). These models demonstrate the potential of instruction tuning in domain-specific applications with high-stakes implications.
Math and Coding: Models like Goat and WizardCoder showcase the effectiveness of instruction tuning in math problem-solving and code generation tasks. By fine-tuning on instruction datasets specifically curated for these domains, the models can understand and generate solutions to mathematical and programming challenges.
Efficient Tuning Techniques
As LLMs continue to grow in size, the computational cost of instruction tuning becomes a significant challenge. To address this, several efficient tuning techniques have been proposed:
LoRA (Low-Rank Adaptation): LoRA introduces low-rank updates to the model parameters, significantly reducing the number of trainable parameters while maintaining performance. It allows for efficient adaptation of LLMs to downstream tasks without requiring full fine-tuning.
HINT (Hypernetwork Instruction Tuning): HINT combines the concept of hypernetworks with instruction tuning. It generates parameter-efficient modules based on natural language instructions and few-shot examples, enabling fast adaptation to new tasks without the need for repeated processing of lengthy instructions.
QLORA (Quantized LoRA): QLORA incorporates quantization and memory optimization techniques to further reduce the computational cost of instruction tuning. It enables the fine-tuning of large models on a single GPU with minimal performance degradation compared to full-precision fine-tuning.
LOMO (LOw-Memory Optimization): LOMO introduces a fusion of gradient computation and parameter updates, avoiding the need to store full gradient tensors. This reduces the memory footprint during the fine-tuning process, enabling the tuning of larger models with limited computational resources.
Delta-tuning: Delta-tuning provides a theoretical framework for efficient instruction tuning by restricting the tuning process to a low-dimensional manifold. It optimizes a small set of parameters that act as controllers, guiding the model’s behavior on downstream tasks.
Instruction tuning has emerged as a powerful paradigm for enhancing the capabilities and controllability of large language models. By aligning the models’ objectives with human instructions, instruction tuning enables LLMs to understand and follow complex tasks across various domains and modalities. As the field of instruction tuning continues to evolve, ongoing research efforts focus on further improving the quality and diversity of instruction datasets, developing more advanced tuning techniques, and exploring new applications across various domains. The potential of instruction tuning to unlock the full capabilities of large language models and enable more human-aligned and controllable AI systems is immense, and it holds great promise for shaping the future of natural language processing and artificial intelligence as a whole.
Delta Tuning: A Comprehensive Study of Parameter Efficient Methods for Pre-trained Language Models
Pre-trained language models (PLMs) have revolutionized the field of natural language processing (NLP), achieving state-of-the-art performance on a wide range of tasks. However, the ever-increasing size of these models presents challenges in terms of computational resources and storage requirements when fine-tuning them for specific downstream tasks. Delta tuning has emerged as a promising solution to efficiently adapt large PLMs while maintaining performance comparable to full fine-tuning. In this blog post, we dive into the comprehensive study “Delta Tuning: A Comprehensive Study of Parameter Efficient Methods for Pre-trained Language Models” by Ning Ding et al., which explores the landscape of delta tuning methods and provides valuable insights into their effectiveness and theoretical underpinnings.
An Overview of Delta Tuning
The categorization criterion of delta tuning, where Θ denote the pre-trained parameters, and Θ′ represent the well-tuned parameters.
The authors propose a categorization criterion that divides existing delta tuning methods into three groups based on their underlying mechanisms:
Addition-based methods: These methods introduce additional trainable neural modules or parameters that are not present in the original PLM. Two notable examples are adapter-based tuning and prompt-based tuning. Adapter-based methods, such as Houlsby Adapter and Parallel Adapter, insert small trainable neural networks (adapters) between layers of the PLM, while keeping the original parameters frozen. Prompt-based methods, like prefix-tuning and prompt tuning, prepend learnable continuous prompts to the input or hidden states of the PLM.
Specification-based methods: These methods specify a subset of the original PLM’s parameters to be trainable while freezing the rest. Examples include BitFit, which only updates the bias terms, and diff pruning, which learns a sparse diff vector to modify the original parameters. These methods aim to identify the most relevant parameters for a given task and update them accordingly.
Reparameterization-based methods: These methods reparameterize the original PLM’s parameters into a more parameter-efficient form through mathematical transformations. A prominent example is LoRA (Low-Rank Adaptation), which learns low-rank decomposition matrices to modify the attention weights in the PLM. This approach capitalizes on the intrinsic low-rank structure of the weight differences between the pre-trained and fine-tuned models.
By carefully designing the trainable components and updating only a small fraction of the PLM’s parameters, delta tuning methods can significantly reduce the computational and memory requirements during adaptation while maintaining performance comparable to full fine-tuning.
Theoretical Perspectives of Delta Tuning
The authors propose two theoretical frameworks to analyze delta tuning methods from the perspectives of optimization and optimal control. These frameworks provide valuable insights into the underlying principles and mechanisms of delta tuning.
Optimization Perspective: The optimization perspective justifies the designs of existing delta tuning methods and explains various empirical observations. The authors argue that the effectiveness of delta tuning can be attributed to the intrinsic low dimensionality of the optimization problems in PLM adaptation. They show that delta tuning methods essentially perform optimization in a low-dimensional subspace, either in the solution space or the functional space. This perspective provides a unified view of different delta tuning methods and sheds light on their success in reducing the number of trainable parameters while maintaining performance.
Optimal Control Perspective: The optimal control perspective interprets delta tuning as a process of finding the optimal controllers for PLMs. The authors propose an optimal control framework that unifies different delta tuning approaches by formulating them as control problems. In this framework, the PLM is treated as a dynamical system, and the delta tuning methods are viewed as controllers that steer the system towards the desired output. The optimization of delta parameters is equivalent to solving for the optimal control policy. This perspective offers a principled way to design and analyze delta tuning methods and opens up new possibilities for developing more advanced and efficient adaptation techniques.
These theoretical perspectives not only deepen our understanding of delta tuning but also provide guidance for designing novel and more effective methods in the future. By leveraging the insights from optimization and optimal control theories, researchers can develop principled approaches to further improve the efficiency and performance of PLM adaptation.
Comparisons and Experimental Discoveries
The authors conduct extensive experiments across over 100 diverse NLP tasks to compare the performance, convergence, and efficiency of different delta tuning methods. They also explore the combinability, scaling behavior, and transferability of these methods. The key experimental findings are summarized below:
Performance: Despite using significantly fewer trainable parameters, delta tuning methods can achieve performance comparable to full fine-tuning in most cases. Among the evaluated methods, LoRA, Adapter, and prefix-tuning generally outperform prompt tuning, especially when the PLM’s size is relatively small. However, as the model size increases, the performance gap between different methods narrows, suggesting that the choice of delta tuning method becomes less critical for larger PLMs.
Convergence: The convergence speed of delta tuning methods is generally slower than full fine-tuning, with the ranking of convergence rates being: full fine-tuning > Adapter ≈ LoRA > prefix-tuning > prompt tuning. However, the convergence speed improves as the PLM’s size increases, indicating that the power of scale can benefit both performance and convergence.
Efficiency: Delta tuning methods can significantly reduce the computational and memory requirements during adaptation. Experiments show that delta tuning can save up to 75% of GPU memory usage compared to full fine-tuning, especially when the batch size is small. However, the actual efficiency gains may vary depending on the specific delta tuning method and the PLM’s size.
Combinability: Combining multiple delta tuning methods can often lead to better performance than using a single method alone. The optimal combination may vary depending on the PLM’s architecture, the downstream task, and the available training data. Experimental results suggest that adding BitFit to the combination generally improves performance, while prompt tuning may not always be compatible with other methods.
These experimental discoveries provide valuable insights into the practical application of delta tuning methods and guide the selection of appropriate methods for different scenarios. The findings also highlight the potential of combining multiple delta tuning methods and leveraging the power of scale to further improve the efficiency and effectiveness of PLM adaptation.
Applications
Delta tuning has significant potential for a wide range of real-world applications, particularly in scenarios where computational resources and storage are limited. The authors discuss several promising application areas where delta tuning can make a substantial impact:
Fast Training and Shareable Checkpoints: Delta tuning enables faster training of large PLMs by updating only a small fraction of the parameters. This not only reduces the computational cost but also allows for more efficient sharing of the trained delta parameters. Instead of sharing the entire fine-tuned PLM, which can be prohibitively large, researchers and practitioners can share only the learned delta parameters, significantly reducing storage and transmission requirements. This facilitates collaboration and knowledge sharing within the NLP community.
Multi-Task Learning: Delta tuning is particularly well-suited for multi-task learning scenarios, where a single PLM needs to be adapted to multiple downstream tasks simultaneously. By learning task-specific delta parameters for each task, the PLM can effectively capture the unique characteristics of each task while sharing the common knowledge encoded in the frozen parameters. This approach enables more efficient and scalable multi-task learning compared to full fine-tuning of separate models for each task.
Mitigating Catastrophic Forgetting: Catastrophic forgetting is a common challenge in sequential fine-tuning of PLMs, where the model tends to forget the knowledge learned from previous tasks when adapted to new tasks. Delta tuning can help mitigate this issue by keeping the original PLM’s parameters fixed and learning only the task-specific delta parameters. This allows the model to retain its general knowledge while adapting to new tasks, thus reducing the impact of catastrophic forgetting.
Improved Fairness and Bias Mitigation: PLMs are known to inherit biases from the training data, which can lead to unfair or discriminatory outputs when applied to downstream tasks. Delta tuning offers a potential solution to mitigate these biases by adapting the model to more balanced and diverse datasets. By carefully designing the delta parameters and the adaptation process, researchers can aim to reduce the biases present in the original PLM and promote fairness in the model’s outputs.
As delta tuning continues to evolve and mature, it is expected to find even more applications across various domains where efficient adaptation of large PLMs is crucial. The authors encourage further research and development efforts to unlock the full potential of delta tuning and make PLMs more accessible, efficient, and effective for a wide range of real-world problems.
DoRA: Weight-Decomposed Low-Rank Adaptation
As the scale of pre-trained models continues to grow, the computational cost of fine-tuning these models on downstream tasks becomes increasingly prohibitive. Parameter-efficient fine-tuning (PEFT) methods have emerged as a solution to this challenge, enabling effective adaptation of large models with only a small number of trainable parameters. Among PEFT techniques, Low-Rank Adaptation (LoRA) has gained significant popularity due to its simplicity and ability to avoid additional inference costs. However, there often remains a performance gap between LoRA and full fine-tuning (FT). In the paper “DoRA: Weight-Decomposed Low-Rank Adaptation”, Liu et al. introduce a novel PEFT method called DoRA that aims to bridge this gap. By decomposing pre-trained weights into magnitude and direction components, DoRA enhances the learning capacity and training stability of LoRA while maintaining inference efficiency.
An overview of DoRA
An overview of our proposed DoRA, which decomposes the pre-trained weight into magnitude and direction components for fine-tuning, especially with LoRA to efficiently update the direction component
Comparison with LoRA and FT
To understand the differences between DoRA, LoRA, and FT, the authors conduct a weight decomposition analysis. They decompose the weights learned by each method and examine the changes in magnitude and direction relative to the pre-trained weights. The analysis reveals distinct learning patterns:
FT exhibits diverse behaviors, with the ability to make significant changes in either magnitude or direction while keeping the other component relatively unchanged.
LoRA shows a proportional relationship between magnitude and direction changes, lacking the flexibility to make independent updates.
DoRA demonstrates a learning pattern more closely resembling FT, with the capability to make substantial directional updates with minimal magnitude changes, or vice versa.
These differences suggest that DoRA has a higher learning capacity compared to LoRA, which may explain its superior performance on downstream tasks.
Experiments on DoRA
The authors validate the effectiveness of DoRA through extensive experiments on various tasks and model architectures:
Commonsense Reasoning: DoRA outperforms LoRA and other PEFT baselines when fine-tuning LLaMA-7B/13B on 8 commonsense reasoning datasets. Even with half the trainable parameters (DoRA†), DoRA surpasses LoRA by significant margins.
Image/Video-Text Understanding: On multi-task image-text and video-text benchmarks, DoRA consistently improves upon LoRA while adapting a similar number of parameters. DoRA achieves accuracy comparable to FT on certain tasks.
Visual Instruction Tuning: DoRA surpasses both LoRA and FT when tuning LLaVA-1.5-7B on a range of vision-language tasks.
Compatibility with LoRA Variants: DoRA demonstrates compatibility with VeRA, a variant of LoRA that uses fixed random matrices. The combined approach, DVoRA, outperforms both VeRA and LoRA while using fewer parameters.
Additional experiments highlight the robustness of DoRA across different rank settings and its ability to maintain high performance with fewer trainable parameters by selectively updating the magnitude and directional components of certain layers.
DoRA presents a novel PEFT method that enhances the learning capacity of LoRA by decomposing pre-trained weights into magnitude and direction components. Through a weight decomposition analysis, the authors demonstrate that DoRA exhibits learning patterns more similar to full fine-tuning compared to LoRA. Extensive experiments across various tasks and model architectures showcase the superior performance of DoRA over LoRA and other PEFT baselines. DoRA consistently improves accuracy while maintaining a similar level of parameter efficiency and inference speed as LoRA. The compatibility of DoRA with LoRA variants like VeRA further highlights its flexibility and potential for future research. As the demand for efficient adaptation of large pre-trained models continues to grow, DoRA offers a promising approach to bridge the performance gap between parameter-efficient methods and full fine-tuning.
Recent Large Language Models Reshaping the Open-Source Arena
The world of open-source large language models (LLMs) is experiencing a rapid evolution, with innovative models being released at an unprecedented pace. Since the release of Meta’s Llama model and its successor, Llama 2, in 2023, the open-source landscape has been transformed by a wave of powerful and versatile LLMs. This article delves into the most influential open-source models making waves in 2024, examining their unique architectures, training approaches, and performance across various benchmarks.
The world of open-source large language models (LLMs) is experiencing a rapid evolution, with innovative models being released at an unprecedented pace. Since the release of Meta’s Llama model and its successor, Llama 2, in 2023, the open-source landscape has been transformed by a wave of powerful and versatile LLMs. This article delves into the most influential open-source models making waves in 2024, examining their unique architectures, training approaches, and performance across various benchmarks.
Qwen1.5
Developed by Alibaba Cloud, Qwen1.5 is a family of base and chat-tuned models available in sizes ranging from 0.5B to 72B parameters. Built on the Transformer architecture, these models incorporate SwiGLU activation, attention QKV bias, Grouped Query Attention (GQA), and combine sliding window attention with full attention. Qwen1.5 models support 12 languages and a context window of 32k tokens. Their instruction following capabilities have been enhanced through Direct Preference Optimization (DPO) and Proximal Policy Optimization (PPO). Qwen1.5-72B-Chat stands out for its impressive performance on human and LLM judge evaluations like MT Bench and AlpacaEval.
Yi
The Yi model series, developed by 01.AI, offers base and chat-tuned models in 6B, 9B, and 34B parameter sizes. These models employ a modified Transformer architecture with GQA, adjusted SwiGLU activation, and RoPE with Adjusted Base Frequency to support context windows up to 200k tokens. Yi models underwent an extensive data cleaning pipeline and were fine-tuned using a diversity-focused approach with fewer than 10K multi-turn instruction-response pairs. Yi-34B delivers near GPT-3.5 level performance.
Smaug
Abacus.AI’s Smaug series includes 34B and 72B parameter models fine-tuned using DPO-Positive (DPOP), a variant of DPO designed to address specific failure modes. Smaug-72B surpassed an average score of 80% on the Open LLM Leaderboard, benefiting from training datasets tailored for downstream tasks like GSM8K, ARC, and HellaSwag.
Mixtral-8x7B
Mistral’s Mixtral-8x7B models feature a sparse Mixture of Experts (MoE) architecture with 46.7B total parameters but only 12.9B active parameters per token. These models support English, French, Italian, German, and Spanish, and have a 32k context window. Mixtral-8x7b-instruct-v0.1 achieves competitive scores on MT Bench and Chatbot Arena leaderboards.
DBRX
Databricks’ DBRX models boast 132B total parameters and 36B active parameters per input, leveraging a fine-grained MoE architecture with 4 out of 16 experts per input. The base models underwent pre-training on 12T tokens with curriculum learning, while the instruction-tuned variants demonstrate strong performance on MT Bench and Open LLM Leaderboard.
SOLAR-10.7B
Upstage AI’s SOLAR-10.7B models were developed using an innovative Depth up-scaling (DUS) approach, starting from a 32-layer Mistral 7B base model and expanding its depth through duplication, layer removal, and recombination, followed by continued pre-training. The instruction-tuned and DPO-aligned variants show competitive performance on various benchmarks.
TÜLU v2
The Allen Institute for AI’s TÜLU v2 models, available in 7B, 13B, and 70B parameter sizes, were developed by fine-tuning and aligning Llama 2 models using a diverse dataset mix. The DPO-aligned 70B variant achieves notable scores on MT Bench and Chatbot Arena leaderboards.
WizardLM
Developed by a Microsoft research team, the WizardLM series includes base and instruction-tuned models in 7B, 13B, and 70B parameter sizes. These models were fine-tuned using the Evol-Instruct approach, which employs LLMs to autonomously generate diverse and complex instruction sets. WizardLM-70B demonstrates competitive performance on high-complexity tasks and human evaluations.
Starling-LM-7B
Starling-LM-7B, developed by Berkeley researchers, was trained from Openchat 3.5 using Reinforcement Learning from AI Feedback (RLAIF) and a GPT-4 labeled ranking dataset called Nectar. This model achieves impressive scores on MT Bench, surpassing all models except GPT-4 and GPT-4 Turbo at the time of its release.
OLMo
The Allen Institute for AI’s OLMo models, available in 1B and 7B parameter sizes, were pre-trained on the Dolma dataset and further enhanced through supervised fine-tuning and DPO alignment. The OLMo-7B-Instruct variant demonstrates notable improvements in reasoning tasks and safety metrics.
Gemma
Google DeepMind’s Gemma models, in 2B and 7B parameter sizes, leverage Multi-head Attention (MHA) or Multi-query Attention (MQA), GeGLU activations, RoPE embeddings, and RMSNorm. Trained on web documents, mathematics, and code, these models excel in tasks like GSM8K and MATH benchmarks.
DeciLM-7B
Deci.AI’s DeciLM-7B stands out for its high efficiency and speed, featuring an 8192 context window and Variable GQA. Developed using Deci’s AutoNAC neural architecture search technology, DeciLM-7B underwent instruction tuning with LoRA on the SlimOrca dataset. Combined with the Infery-LLM SDK, DeciLM-7B achieves impressive throughput and high-speed inference.
The rapid advancements in open-source LLMs have transformed the AI landscape, making powerful language models more accessible and spurring innovation across various domains. As these models continue to evolve and new contenders emerge, the open-source arena remains a dynamic and exciting space to watch. Researchers, developers, and businesses alike can harness the potential of these models to push the boundaries of natural language processing and develop groundbreaking applications.
Please click each post's URL shown below to check out its full contents.
Advancing Transformer Architecture in Long-Context Large Language Models: A Comprehensive Survey
https://arxiv.org/abs/2311.12351
Transformer-based Large Language Models (LLMs) have been applied in diverse areas such as knowledge bases, human interfaces, and dynamic agents, and marking a stride towards achieving Artificial General Intelligence (AGI). However, current LLMs are predominantly pretrained on short text snippets, which compromises their effectiveness in processing the long-context prompts that are frequently encountered in practical scenarios. This article offers a comprehensive survey of the recent advancement in Transformer-based LLM architectures aimed at enhancing the long-context capabilities of LLMs throughout the entire model lifecycle, from pre-training through to inference. We first delineate and analyze the problems of handling long-context input and output with the current Transformer-based models. We then provide a taxonomy and the landscape of upgrades on Transformer architecture to solve these problems. Afterwards, we provide an investigation on wildly used evaluation necessities tailored for long-context LLMs, including datasets, metrics, and baseline models, as well as optimization toolkits such as libraries, frameworks, and compilers to boost the efficacy of LLMs across different stages in runtime. Finally, we discuss the challenges and potential avenues for future research. A curated repository of relevant literature, continuously updated, is available at this https URL.
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, Christopher Ré
Paper: https://arxiv.org/abs/2205.14135
Transformers are slow and memory-hungry on long sequences, since the time and memory complexity of self-attention are quadratic in sequence length. Approximate attention methods have attempted to address this problem by trading off model quality to reduce the compute complexity, but often do not achieve wall-clock speedup. We argue that a missing principle is making attention algorithms IO-aware – accounting for reads and writes between levels of GPU memory. We propose FlashAttention, an IO-aware exact attention algorithm that uses tiling to reduce the number of memory reads/writes between GPU high bandwidth memory (HBM) and GPU on-chip SRAM. We analyze the IO complexity of FlashAttention, showing that it requires fewer HBM accesses than standard attention, and is optimal for a range of SRAM sizes. We also extend FlashAttention to block-sparse attention, yielding an approximate attention algorithm that is faster than any existing approximate attention method. FlashAttention trains Transformers faster than existing baselines: 15% end-to-end wall-clock speedup on BERT-large (seq. length 512) compared to the MLPerf 1.1 training speed record, 3$\times$ speedup on GPT-2 (seq. length 1K), and 2.4$\times$ speedup on long-range arena (seq. length 1K-4K). FlashAttention and block-sparse FlashAttention enable longer context in Transformers, yielding higher quality models (0.7 better perplexity on GPT-2 and 6.4 points of lift on long-document classification) and entirely new capabilities: the first Transformers to achieve better-than-chance performance on the Path-X challenge (seq. length 16K, 61.4% accuracy) and Path-256 (seq. length 64K, 63.1% accuracy).
Introducing Jamba: AI21’s Groundbreaking SSM-Transformer Model
Debuting the first production-grade Mamba-based model delivering best-in-class quality and performance.
March 28, 2024
https://www.ai21.com/blog/announcing-jamba
We are thrilled to announce Jamba, the world’s first production-grade Mamba based model. By enhancing Mamba Structured State Space model (SSM) technology with elements of the traditional Transformer architecture, Jamba compensates for the inherent limitations of a pure SSM model. Offering a 256K context window, it is already demonstrating remarkable gains in throughput and efficiency—just the beginning of what can be possible with this innovative hybrid architecture. Notably, Jamba outperforms or matches other state-of-the-art models in its size class on a wide range of benchmarks.
More readings:
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu, Tri Dao
https://arxiv.org/abs/2312.00752
Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module. Many subquadratic-time architectures such as linear attention, gated convolution and recurrent models, and structured state space models (SSMs) have been developed to address Transformers’ computational inefficiency on long sequences, but they have not performed as well as attention on important modalities such as language. We identify that a key weakness of such models is their inability to perform content-based reasoning, and make several improvements. First, simply letting the SSM parameters be functions of the input addresses their weakness with discrete modalities, allowing the model to selectively propagate or forget information along the sequence length dimension depending on the current token. Second, even though this change prevents the use of efficient convolutions, we design a hardware-aware parallel algorithm in recurrent mode. We integrate these selective SSMs into a simplified end-to-end neural network architecture without attention or even MLP blocks (Mamba). Mamba enjoys fast inference (5× higher throughput than Transformers) and linear scaling in sequence length, and its performance improves on real data up to million-length sequences. As a general sequence model backbone, Mamba achieves state-of-the-art performance across several modalities such as language, audio, and genomics. On language modeling, our Mamba-3B model outperforms Transformers of the same size and matches Transformers twice its size, both in pretraining and downstream evaluation.
Efficient Memory Management for Large Language Model Serving with PagedAttention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, Ion Stoica
High throughput serving of large language models (LLMs) requires batching sufficiently many requests at a time. However, existing systems struggle because the key-value cache (KV cache) memory for each request is huge and grows and shrinks dynamically. When managed inefficiently, this memory can be significantly wasted by fragmentation and redundant duplication, limiting the batch size. To address this problem, we propose PagedAttention, an attention algorithm inspired by the classical virtual memory and paging techniques in operating systems. On top of it, we build vLLM, an LLM serving system that achieves (1) near-zero waste in KV cache memory and (2) flexible sharing of KV cache within and across requests to further reduce memory usage. Our evaluations show that vLLM improves the throughput of popular LLMs by 2-4× with the same level of latency compared to the state-of-the-art systems, such as FasterTransformer and Orca. The improvement is more pronounced with longer sequences, larger models, and more complex decoding algorithms. vLLM’s source code is publicly available at this https URL
Attention Mechanisms in Computer Vision: A Survey
Meng-Hao Guo, Tian-Xing Xu, Jiang-Jiang Liu, Zheng-Ning Liu, Peng-Tao Jiang, Tai-Jiang Mu, Song-Hai Zhang, Ralph R. Martin, Ming-Ming Cheng, Shi-Min Hu
https://arxiv.org/abs/2111.07624
Humans can naturally and effectively find salient regions in complex scenes. Motivated by this observation, attention mechanisms were introduced into computer vision with the aim of imitating this aspect of the human visual system. Such an attention mechanism can be regarded as a dynamic weight adjustment process based on features of the input image. Attention mechanisms have achieved great success in many visual tasks, including image classification, object detection, semantic segmentation, video understanding, image generation, 3D vision, multi-modal tasks and self-supervised learning. In this survey, we provide a comprehensive review of various attention mechanisms in computer vision and categorize them according to approach, such as channel attention, spatial attention, temporal attention and branch attention; a related repository this https URL is dedicated to collecting related work. We also suggest future directions for attention mechanism research.
State Space Model for New-Generation Network Alternative to Transformers: A Survey
Motivation
Pros and Cons of Attention
Self-attention mechanism has successfully enabled transformer to learn long-range feature representations well.
However, Transformer-based models require high-end GPU with larger memory for training and testing/deployment.
Hence, We need a model that not only requires less computing cost but also is still able to capture long-range dependencies while maintaining high performance.
That’s what State Space Model (SSM) wants to solve.
Formulation of SSM
SSM is a commonly used model in control theory and is used in Kalman simulation and hidden Markov models. Its basic formulation is shown in the figure below.
Normally, we would omit the parameter D (assume D=0 becuase the term Du can be viewed as a skip connection and is easy to compute). So a more common formulation we would see in most state space model would be as:
Discretization
As a continuous system, it is hard for SSM to be used in modern deep learning algorithm. In practice, we always deal with discrete data, such as text. This requires us to discretize the SSM, transforming our continuous parameters A, B, C into discrete parameters $\hat{A}, \hat{B}$ using zero-order hold rule (ZOH) as shown in Figure below. Readers can refer to the paper for detailed derivation.
In conclusion, the discretized version of SSM is like:
Convolutional Form
Unlike RNN, SSM here doesn’t have non-linear functions. So we can try to expand $y_t$ and surprisingly find SSM can be written in convolutional form.
Looking at the result of the expansion above, we can see that the coefficient of each $x_t$ can be extracted out and write a convolutional kernel:
Hence, we can write our SSM formulation as:
It’s easy to find that SSM is very similar to RNN. Comparing the formulation of SSM and RNN below, we can find the main reason why RNN can’t be written in convolutional form and thus can’t be trained efficiently is the non-linear funciton $f$.
Structured State Space Model (S4)
Similar to RNNs, SSM also suffers from the vanishing/exploding gradients problem when modeling longer sequences.
To solve this problem, HiPPO matrices is introduced which combines the concepts of Recurrent Memory and Optimal Polynomial Projections, thus can significantly improve the performance of recursive memory.
In practice, we would use HiPPO matrix to initial like matrix A.
Note the “Structured” comes from the HiPPO matrix. And we usually can the vallila SSM with HiPPO matrix :S4 model in short which will be seen in most SSM related papers.
From S4 to Mamba (S6)
The problem of S4:
S4 does not have selectivity
Those discrete parameters are constant
Those problem will result in the S4 treat all part of the input exactly the same like the Figure shown below.
Mamba makes these parameters vary based on the input, like the formulation below:
By doing so, model has the ability to focus on certain words, like the Figure shown below.
Parallization of Mamba
In S4, we are able to precompute this kernel, save it, and multiply it with the input x.
However, in Mamba, these matrices change depending on the input.
If we want selectivity, we’ll need to train Mamba with RNN mode.
Mamba is able to solve this problem through parallel scan.
Parallel Scan
Whether an operation can be done in parallel depends on associative property. Mamba’s recurrence was very similar to a scan algorithm, also known as a prefix sum.
We can verify its associative property with a new variable k:
Figure below shows how parallel scan works. We can pick any vertical line and start from the top of this line and move to the bottom, tracing each addition back to the array’s first few items. By the time we reach the bottom, we should have the sum of all items to the left of this line.
Variations of SSM
Language Modeling
S4+++:
-State Memory Relay.
-Integrate complex dependency bias via an interactive cross-validation mechanism.
Voice Task
DP-Mamba
-Bidirectional Dependency Modeling: Simultaneously models both short-term and long-term forward and backward dependencies of speech signals.
-Selective State Space: Enhances model capability through a selectively utilized state space.
-Performance: Achieves comparable results to the dual-path Transformer model Sepformer.
SP-Mamba:
Utilizes TF-GridNet.
Replaces the Transformer module with a bidirectional Mamba module.
Result: Captures a wider range of language information, leading to broader comprehension.
Variations in Computer Vision
VMamba
VMamba uses linear complexity to capture the full range of sensory fields, introduces traversal of spatial information across scan blocks, and converts non-causal visual images into ordered patch sequences.
Vision Mamba
The Vim model divides the input image into chunks and then projects the chunks into tokens at the begining. These tokens are then fed into the Vim encoder. For tasks like ImageNet classification, an additional learnable classification token is added to the sequence of token labels (this labels are used consistently in this way from the beginning of heavy BERT). Unlike the Mamba model used for modeling text sequences, the Vim encoder processes the token sequence in both the forward and reverse directions.
And the Vim encoder will be shown in the figure below
Mamba Variations in different Task
Classification task: Vim VMamba
Detection task: MiM-ISTD
Segmentation task
Medical image segmentation: VM-UNet
Medical tasks
Registration task: MambaMorph
Restoration task: MambdaIR
Generation task: ZigMa
Video understanding:ViS4mer, Video Mamba
Variations in Graph
GraphS4mer: Using the S4 architecture to capture long-range dependencies and includes a dynamic graph structure learning layer for spatial correlations.
GMN: Based on selective State Space Models, tackling the limitations of traditional GNNs in capturing long-range dependencies and computational efficiency.
Variations in Multi-modality and Multi-media
S4ND Model:
Extends State Space Models to multidimensional signals.
Effective in large-scale visual data modeling across 1D, 2D, and 3D dimensions.
Proven applications in image and video classification.
VL-Mamba:
First implementation of the state-space model Mamba in multimodal tasks.
Aims to address high computational costs in Transformer architectures.
CMViM:
Focuses on multimodal learning for 3D high-resolution medical images, specifically Alzheimer’s disease.
Utilizes the MAE framework, replacing the ViT module with a simpler Vim module to reduce computational complexity from quadratic to linear.
Enhances modeling capabilities through intra-modality and inter-modality contrastive learning, improving feature discrimination and aligning representations across different modalities.
Limitations of Transformer Architecture in Handling Long Contexts
Attention Complexity
Computational Complexity: In scenarios where sequence length 𝐿 far exceeds dimension 𝑑
The complexity becomes quadratic
Time Complexity: 𝑂(𝐿^2*d) Space Complexity: 𝑂(𝐿^2)
In-context Memory Limitations
Statelessness of Transformers: Lacks a mechanism to retain state between calls, relying only on the KV cache
Impact on Applications: This design limits effectiveness in applications requiring long-term memory(chatbots)
Max-Length Constraint
Training and Inference: Engineers set a maximum sequence length 𝐿𝑚𝑎𝑥 to prevent memory overflow
As a hyper-parameter, typically between 1K, 2K 4K tokens
Performance degradation: observed when handling inputs longer than 𝐿𝑚𝑎𝑥 resulting in implausible outputs
Roadmap of Enhancements for Long-Context Capabilities in LLMs
Section 3: Efficient Attention Mechanisms
Goal: Addressing the computational bottleneck of attention mechanisms in Transformers
Impact: Expanding the context length boundary for LLMs during both pre training and inference phases
Category
Local Attention
Hierarchical Attention
Sparse Attention
Approximated Attention
IO-Aware Attention
Local Attention
Redefining Attention Mechanisms
Traditional Global Attention: Each token attends to all others, leading to 𝑂(𝐿^2𝑑) complexities
Local Attention: Focuses on neighboring tokens, reducing time and space complexities
Approaches
Block-wise Attention
Divides input into non-overlapping blocks, each attending within itself(e.g. BlockBERT)
Sliding Window Attention
Each token attends within a fixed-size window, inspired by CNN techniques(e.g. Longformer)
Global-Local Hybrid Attention
Combines local attention with global tokens for broader context (e.g. LongLM)
LSH Attention
Utilizes locality-sensitive hashing for efficient neighbor token selection
Hierarchical Attention
Goal: Merge higher-level global information with lower-level local attention for efficient and scalable processing
Impact
Complexity Reduction: Achieves sub-quadratic computational and memory costs while preserving the expressiveness of full attention
Contextual Balance: Maintains a balance between local and global context for inherent locality principle
Approaches
Two-Level Hierarchy
Uses self-attention across two levels: word-to-sentence and sentence-to-document (e.g. HAN)
Multi-Level Hierarchy
**Introduces fine-to-coarse attention via **binary partitioning**, formalizing as a graph neural network(e.g BPT)
Controls attention span with a soft attention mask (e.g. Adaptive Span Transformer)
Advanced Hierarchical Mechanisms
Partitions attention matrix into blocks with different low-rank ranges (e.g. H-Transformer-1D)
Combines full-attention approximation with structured factorization (e.g. Combiner)
Approximated Attention
Goal: Reduce the full attention computation by leveraging sparsity and low-rankness with linear complexity, optimizing precision trade-offs
Impact: Provides sub-quadratic computation and memory complexity while maintaining the expressiveness of full attention
Techniques
Low-Rank Approximation
Linformer: Utilizes SVD for a low-rank approximation of the attention matrix, reducing complexity to 𝑂(𝐿𝑘𝑑)
Nested Attention
Luna: Combines pack and unpack attention strategies to handle sequences of varying lengths without compromising parallelism
Kernelized Approximation
Linear Transformer & Performer: Introduces kernel-based attention approximations, significantly cutting down on computational resources
Hybrid Approaches
Sparse-Kernelized Hybrid
Scatterbrain: combines sparse matrices and kernelized feature maps for enhanced efficiency and precision
IO-Aware Attention
Different
Previous attention methods trade off some attention quality for lower computation
But IO-aware methods maintain exactness of attention calculations while optimizing computational resources
Offer exact attention computations with significantly reduced memory and time consumptionA leap forward in the optimization of Transformer models for large-scale applications
Techniques
Memory-Efficient Attention: Utilizes lazy softmax algorithm for numerically stable attention
Flash Attention: Achieves up to 7.6x speedup and 20x memory efficiency with exact attention computation
Paged AttentionAddresses inference memory bottlenecks by managing KV cache memory with virtual memory paging techniques, improving efficiency and flexibility for batched requests
Innovations and ImprovementsSparse Clustered Factorization Attention: Extends Flash Attention to accommodate diverse sparsity patterns, leading to 2 to 3.3 times training speedup
Virtual Large Language Models: Proposes techniques to manage growing KV cache memory
Section 4: Long-Term Memory
Because of in-context working memory, the Transformer architecture often struggles with capturing long-term dependencies. The researchers propose two main avenues to address this challenge: (1) Internal MemoryCache; (2) External MemoryBank.
Section 4: Long-Term Memory
Internal MemoryCache
For Internal MemoryCache, there are different types:
Segment-Level Recurrence.
It caches the output of 𝑚 previous consecutive segments in the last layer and concatenates them into the current segment in the present layer to extend the context for the current query.
Retrospective Recurrence.
It concatenates the output hidden states of previous segments in the same layer, instead of the last layer.
Continuous-Signal Memory.
The ∞-former model uses a continuous signal representation to achieve unbounded long-term memory.
External MemoryBank
For External MemoryBank, there are different types:
Cosine-Based Retrieval Criteria.
LangChain is an open-source framework designed for chatbots, which processes local documentation into a memory bank using LLMs and retrieves context using cosine similarity to enhance interaction and response generation.
Heuristic Retrieval Criteria.
It’s used for enhancing large language models with memory banks, enabling more efficient and context-aware data handling and retrieval in applications like chatbots and knowledge-based systems.
Learnable Retrieval Criteria.
REALM use MLM to train a neural knowledge retriever
LongMem decouples the memory retrieval process using a SideNet.
FOT introduces a novel contrast training method to refine the key-value space and enhance retrieval accuracy as the size of the memory bank expands.
In summary, Internal MemoryCache trades space for time by using caching mechanisms to reduce computation. However, after model training is completed, it is difficult to update the internal knowledge, which is why such methods are rarely used nowadays. Instead, the External Memory Bank method is mainly used.
Section 5: Extrapolative PEs
The meaning of PEs is Extrapolative Positional Encodings. Current PEs play the undeniable role in length generalization in more general scenarios.
Enhancing Understanding
Rethinking PEs as 𝛽-Encoding.
Length Extrapolation Dilemma.
Attention Bias
As alternative mechanisms to explicitly encoding positional information, attention bias have been explored to capture the sequentiality and temporality of natural language incorporated into the attention kernel.
Extended RoPE
Several research works have aimed to extend RoPE using various strategies to enhance its length extrapolation capabilities, including Scaling Strategies, Truncation Strategies, and Rearrangement Strategies.
Section 6: Context Processing
There are three different strategies:
Context Selection
Various strategies employed by different models to effectively manage long text segments within the limited context window of LLMs, involving segment partitioning, scoring based on selection criteria, and iterative or simultaneous selection processes to prioritize the most relevant segments for processing.
Context Aggregation
Extracting and integrating information from all context segments to generate a coherent final answer, through techniques like Fusion-in-Decoder, Map Reduce, Refinement.
Handling parallel context windows, each with different strategies for encoding, merging, and refining the information from multiple segments.
Context Compression
Methods for compressing long contexts to fit within the maximum sequence length constraints of LLMs.
Soft compression: create condensed and abstract representations through embedded learning.
Hard Compression: eliminate redundancies using metrics like self-information and perplexity to optimize input quality before processing.
Section 7: Miscellaneous Solution
The miscellaneous solution talked in the part are not be exhaustive or specific to Transformer-based models. Many of these techniques are applicable universally to any model equipped with deep neural networks, albeit particularly crucial for large-scale LLMs. Some solutions are as follows:
Specific Objectives
Recent research explores tailored approaches to adapt pretraining for specific tasks, aiming to enhance LLMs’ effectiveness in capturing intricate long-range dependencies and discourse structures in longer texts compared to shorter ones. (XLNet, ERNIE-Doc, DANCE, PEGASUS, PRIMERA)
Mixture of Experts
Mixture of Experts (MoE) enhances large language models by incorporating specialized expert modules and dynamic gating mechanisms to optimize task performance, reduce computational demands, and improve efficiency and effectiveness in handling large-scale contexts.
Parallelism
Leveraging modern aggregated GPU memory within and across nodes, recent research has introduced various parallelism strategies to scale up model sizes and extend sequence length, including Data Parallelism (DP), Tensor Parallelism (TP), Pipeline Parallelism (PP), Sequence Parallelism (SP), Expert Parallelism (EP).
Weight Compression
Various methods enhance memory efficiency in large-scale LLMs through weight compression techniques, including pruning, factorization, quantization, partitioning, and distillation.
The researchers explore evaluation necessities for assessing long-context capabilities of LLMs, including datasets, metrics, and baseline models. And they investigate popular optimization toolkits, such as libraries, frameworks, and compilers, to enhance LLM efficiency and effectiveness during development.
For Datasets, detailed information on each dataset is available in Table 1, covering language, task types, length statistics, quality, splits, count and format.
For Metrics, Table 2 provides a summary of nine categories of general evaluation metrics commonly employed across ten NLP task types, encompassing language modeling, question answering, summarization, math solving, code generation, and open-ended writing, among others.
For Baselines, Table 3 gathers a list of pretrained/finetuned LLMs commonly, serving as baselines for evaluating long-context capabilities across various downstream tasks.
For Toolkit, Table 4 collects a diverse array of valuable toolkits to optimize the efficiency and effectiveness of LLMs across their development lifecycle.
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
Motivation
Transformers based on current attention architectures do not perform well when context length is beyond a threshold. The first motivation of this work is that designing a transformer architecture that can model longer sequence data has the following potential applications:
In NLP tasks, a large context allows the LLM to read books, plays and instruction manuals before generating a response.
In computer vision, higher resolution images require the attention architecture to be capable of handling longer sequences. In the case of high resolution MRI as shown in the slide below, if the transformer is able to generate a high resolution image, it can improve the performance of downstream tasks such as pathology detection or tissue segmentation.
Other types of natural sequence data such as time-series data, audio data, video data and medical imaging also require the transformer to perform well on much longer sequences.
The second motivation of the work is that the attention computation is bottlenecked by the I/O from High Bandwidth Memory (HBM), which is large in size but relatively slow compared to SRAM. As an example, A100 offers 40GB HBM or 80GB HBM, but its bandwidth is only 1/10 of that of SRAM. The standard attention computation, as shown in the slide below, however, requires numerous writing to and reading from HBM for intermediate values such as the attention matrix throughout the computation, which makes I/O from HBM the bottleneck of the attention computation.
FlashAttention Algorithm
FlashAttention is fast, memory efficient and an exact computation of attention. FlashAttention is I/O aware and aims to reduce number of times needed to read and write to HBM. It computes the attention block by block. When computing each output block, all four blocks from Q, K, V and Output can be stored in SRAM. So we do not need to store the intermediate values to HBM. In addition, the overall SRAM memory footprint depends only on block size and head dimension and is not related to length. Instead of the entire attention matrix, since only a block is calculated each time, it can also handle longer sequences.
Flashattention is based on safe softmax and online softmax, which are simpler methods that may help us understand flashattention. To avoid numerical overflow, safe softmax subtracts m from the exponent which is the max over all input x, so that the exponential in softmax is less or equal to zero and safe to compute.
Safe Softmax requires a total of three passes. The first pass iteratively calculates a local maximum of the softmax imput, using the result from the previous iteration. When the for loop ends, the result will be the global maximum over all x. The second pass iteratively calculates the denominator using the global maximum from the previous pass. The final pass calculates the softmax using the denominator and the global max.
The online softmax reduces the computation from 3 passes to 2 passes. When updating the denominator of softmax, If we replace the global max and use the local max at iteration i with a scaling factor, we can calculate the max and the denominator together in 1 pass.
FlashAttention aims to reduce the calculation to 1 pass, and outputs attention instead of softmax in the previous two algorithms. Attention requires an additional calculation: a matrix multiplication of softmax and value V to obtain the output O. FlashAttention perform such calculation by breaking down softmax into smaller softmax. Here in the slide below, the output is updated in two terms. The first term is the output computed from the previous iteration times a scaling factor. The second term can be considered as a small softmax times a row of V. By updating the output in this iterative manner, FlashAttention can further reduce the computation to 1 pass.
This only calculating one row of Q, V and one column of K each time. To make full use of the SRAM fast cache memory, we can treat many rows together as blocks, and calculate the attention block by block. We are using a largest block size that can fit four blocks of Q, K, V, O onto the SRAM. For a particular block from Q, we iterate through all blocks from K transpose and V, while maintaining two columns of max and denominator. After the iterations, the result will obtain an exact block of output. In this procedure, FlashAttention calculates the attention in a block by block manner.
Evaluation
When both training a BERT-large model on a single node, FlashAttention is demonstrated to require 15% less training time than Nvidia’s attention implementation.
When training GPT-2 small, compared to Megatron-LM, FlashAttention supports 4 times longer the context length, is still being 30% faster while achieving 0.7 better perplexity.
Being an exact attention implementation, FlashAttention is not only faster than PyTorch Attention, but also faster than OpenAI Sparse Attention, when the context length is less than 4096. It is slower than Linformer Attention, which is an approximation method using low-rank matrix. In terms of memory usage, it requires 2x less memory than Linformer Attention, and 20x less memory than Pytorch Attention.
Limitations and Future Directions
Compiling to CUDA. The current implementation requires writing a new CUDA kernel in low-level language use, and may not transfer to other GPU architectures. These limitations suggest a need to write attention algorithms in high-level language such as PyTorch.
IO-Aware Deep Learning. The IO-aware approach can be potentially extend to every layer in a deep network.
Multi-GPU IO-Aware Methods. The current algorithm is designed for a single GPU node and does not take data transfer across multiple GPU into consideration. The authors hope to inspire future work to design attention computation that is parallelizable across multiple GPUs.
Please click each post's URL shown below to check out its full contents.
The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning
Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D. Li, Ann-Kathrin Dombrowski, Shashwat Goel, Long Phan, Gabriel Mukobi, Nathan Helm-Burger, Rassin Lababidi, Lennart Justen, Andrew B. Liu, Michael Chen, Isabelle Barrass, Oliver Zhang, Xiaoyuan Zhu, Rishub Tamirisa, Bhrugu Bharathi, Adam Khoja, Zhenqi Zhao, Ariel Herbert-Voss, Cort B. Breuer, Andy Zou, Mantas Mazeika, Zifan Wang, Palash Oswal, Weiran Liu, Adam A. Hunt, Justin Tienken-Harder, Kevin Y. Shih, Kemper Talley, John Guan, Russell Kaplan, Ian Steneker, David Campbell, Brad Jokubaitis, Alex Levinson, Jean Wang, William Qian, Kallol Krishna Karmakar, Steven Basart, Stephen Fitz, Mindy Levine, Ponnurangam Kumaraguru, Uday Tupakula, Vijay Varadharajan, Yan Shoshitaishvili, Jimmy Ba, Kevin M. Esvelt, Alexandr Wang, Dan Hendrycks
The White House Executive Order on Artificial Intelligence highlights the risks of large language models (LLMs) empowering malicious actors in developing biological, cyber, and chemical weapons. To measure these risks of malicious use, government institutions and major AI labs are developing evaluations for hazardous capabilities in LLMs. However, current evaluations are private, preventing further research into mitigating risk. Furthermore, they focus on only a few, highly specific pathways for malicious use. To fill these gaps, we publicly release the Weapons of Mass Destruction Proxy (WMDP) benchmark, a dataset of 4,157 multiple-choice questions that serve as a proxy measurement of hazardous knowledge in biosecurity, cybersecurity, and chemical security. WMDP was developed by a consortium of academics and technical consultants, and was stringently filtered to eliminate sensitive information prior to public release. WMDP serves two roles: first, as an evaluation for hazardous knowledge in LLMs, and second, as a benchmark for unlearning methods to remove such hazardous knowledge. To guide progress on unlearning, we develop CUT, a state-of-the-art unlearning method based on controlling model representations. CUT reduces model performance on WMDP while maintaining general capabilities in areas such as biology and computer science, suggesting that unlearning may be a concrete path towards reducing malicious use from LLMs. We release our benchmark and code publicly at this https URL
Must know tools for training/finetuning/serving LLM’s -
Torchtune - Build on top of Pytorch, for training and finetuning LLM’s. Uses yaml based configs for easily running experiments. Github -
axolotl - Built on top on Huggigface peft and transformer library, supports fine-tuning a large number for models like Mistral, LLama etc. Provides support for techniques like RLHF, DPO, LORA, qLORA etc. Github
LitGPT - Build on nanoGPT and Megatron, support pre-training and fine-tuning, has examples like Starcoder, TinyLlama etc. Github -
Maxtext - Jax based library for training LLM’s on Google TPU’s with configs for models like Gemma, Mistral and LLama2 etc. Github
LLM orchestration framework to build customizable, production-ready LLM applications. Connect components (models, vector DBs, file converters) to pipelines or agents that can interact with your data. With advanced retrieval methods, it’s best suited for building RAG, question answering, semantic search or conversational agent chatbots.
LlamaIndex
https://docs.llamaindex.ai/en/stable/
LlamaIndex supports Retrieval-Augmented Generation (RAG). Instead of asking LLM to generate an answer immediately, LlamaIndex:
retrieves information from your data sources first, / adds it to your question as context, and / asks the LLM to answer based on the enriched prompt.
This paper presents a comprehensive and practical guide for practitioners and end-users working with Large Language Models (LLMs) in their downstream natural language processing (NLP) tasks. We provide discussions and insights into the usage of LLMs from the perspectives of models, data, and downstream tasks. Firstly, we offer an introduction and brief summary of current GPT- and BERT-style LLMs. Then, we discuss the influence of pre-training data, training data, and test data. Most importantly, we provide a detailed discussion about the use and non-use cases of large language models for various natural language processing tasks, such as knowledge-intensive tasks, traditional natural language understanding tasks, natural language generation tasks, emergent abilities, and considerations for specific tasks.We present various use cases and non-use cases to illustrate the practical applications and limitations of LLMs in real-world scenarios. We also try to understand the importance of data and the specific challenges associated with each NLP task. Furthermore, we explore the impact of spurious biases on LLMs and delve into other essential considerations, such as efficiency, cost, and latency, to ensure a comprehensive understanding of deploying LLMs in practice. This comprehensive guide aims to provide researchers and practitioners with valuable insights and best practices for working with LLMs, thereby enabling the successful implementation of these models in a wide range of NLP tasks. A curated list of practical guide resources of LLMs, regularly updated, .
https://github.com/Mooler0410/LLMsPracticalGuide
Retentive Network: A Successor to Transformer for Large Language Models
In this work, we propose Retentive Network (RetNet) as a foundation architecture for large language models, simultaneously achieving training parallelism, low-cost inference, and good performance. We theoretically derive the connection between recurrence and attention. Then we propose the retention mechanism for sequence modeling, which supports three computation paradigms, i.e., parallel, recurrent, and chunkwise recurrent. Specifically, the parallel representation allows for training parallelism. The recurrent representation enables low-cost $O(1)$ inference, which improves decoding throughput, latency, and GPU memory without sacrificing performance. The chunkwise recurrent representation… Show more
RWKV: Reinventing RNNs for the Transformer Era
Transformers have revolutionized almost all natural language processing (NLP) tasks but suffer from memory and computational complexity that scales quadratically with sequence length. In contrast, recurrent neural networks (RNNs) exhibit linear scaling in memory and computational requirements but struggle to match the same performance as Transformers due to limitations in parallelization and scalability. We propose a novel model architecture, Receptance Weighted Key Value (RWKV), that combines the efficient parallelizable training of transformers with the efficient inference of RNNs.
Our approach leverages a linear attention mechanism and allows us to formulate the model as either a Transfor… Show more
Please click each post's URL shown below to check out its full contents.